第13篇:调度延迟与性能指标:系统为什么"慢"但 CPU 不高?
Linux 调度子系统技术文档系列 · 第 13 篇
你有没有见过:"CPU 使用率只有 30%,但用户反馈下单接口响应从 200ms 飙到了 3s。" 这不是个例——在性能排查的一线,"系统慢但 CPU 不高"是最令人困惑的现场之一。CPU 明明有空闲,任务为什么在排队?那些消失的时间去了哪里?
答案不在 CPU 使用率里,而在调度器等待队列的缝隙中。本文追踪调度延迟的内核测量路径,揭示从 enqueue 到真正上 CPU 这段时间发生了什么,以及如何用 perf 和 /proc 接口把这些隐藏的延迟抓出来。
一、调度延迟是什么?它由哪些部分组成?
调度延迟的核心定义很朴素:一个任务从就绪(Runnable)到真正获得 CPU 执行的时间差。但它不等同于简单的"排队时间",因为内核中存在多层等待。
调度延迟的组成部分如下:
| | |
|---|
| 运行队列等待延迟 | | wait_sum |
| 睡眠唤醒延迟 | | sleep_start |
| 阻塞延迟 | | block_start |
| IO 等待延迟 | | iowait_sum |
| 迁移延迟 | | |
用一个隐喻来理解:CPU 是一个餐厅的厨师,调度延迟就是"从你拿着菜单站进排队区,到厨师开始炒你的菜"的这段时间。CPU 使用率只告诉你厨师有多忙,却告诉你前面排了多少人、你是什么时候进来的、以及中间有没有被插队。
为什么调度延迟难以直接测量? 因为内核态与用户态之间存在一条不可逾越的边界。调度器在 dequeue_task 和 schedule() 之间完成了所有决策,而这些操作发生在内核上下文中。用户空间看到的只是系统调用的返回时间——这个时间混合了 IO 延迟、锁竞争、上下文切换和调度延迟。要把调度延迟单独剥离出来,必须深入内核的统计路径。
二、核心数据结构:sched_statistics 与 PELT
2.1 sched_statistics:延迟的度量衡
sched_statistics 是调度器为每个调度实体(sched_entity)维护的统计结构。它的核心字段 wait_start、wait_sum、wait_count 构成了调度延迟的测量三角:
这段代码记录了等待的起点。rq_clock(rq) 是当前运行队列的时钟,prev_wait_start 用于处理任务被多次重新入队的情况——如果之前已经记录过等待起点,新值需要减去旧值,以避免在迁移场景下重复计算。
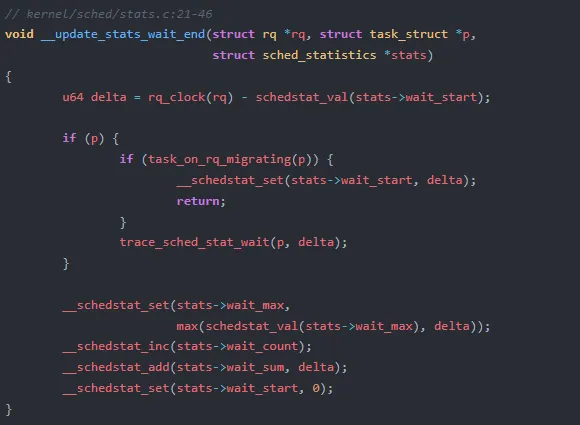
等待结束的逻辑更为关键。delta 就是从 wait_start 到当前时刻的等待时长。这里有一个精妙的细节:迁移任务的处理——如果任务正在迁移(task_on_rq_migrating),内核不会清零 wait_start,而是保存 delta,这样迁移到新 CPU 后可以继续累加。这是内核保证跨 CPU 延迟统计不丢失的核心机制。
三个核心字段的职责分工:
wait_start:时间戳,标记等待开始时刻(或迁移过程中的累积值)wait_sum:历史等待总时间,除以 wait_count 即平均等待延迟wait_count
2.2 PELT 的 util_avg / load_avg:指数衰减的数学直觉
sched_avg 是 PELT(Per-Entity Load Tracking)的核心结构。它的 util_avg 和 load_avg 字段使用指数衰减算法来更新:
为什么 PELT 用指数衰减而不是简单平均? 简单平均对所有历史采样点一视同仁,这意味着一个任务十秒前的行为和一毫秒前的行为权重相同。但调度器需要的是"此刻的负载画像"——最近的行为更能预测未来。指数衰减通过半衰期机制,让旧数据的贡献随时间自然消退:
PELT 的时间窗口是 32ms 的半衰期。每次更新时,内核计算距离上次更新经过了多少个 32ms 周期,然后对历史值进行等比衰减。这种设计让 util_avg 能快速响应任务的负载变化,同时又不会因为瞬时尖刺而剧烈波动——它本质上是一个低通滤波器。
util_avg 和 load_avg 的区别在于:
load_avgutil_avg 反映任务的实际 CPU 利用率(用于 CPU 频率调节和 NUMA 负载均衡)
2.3 CONFIG_SCHEDSTATS:开关的代价
stats.h 中的 schedstat_enabled() 是一个 static key:
static_branch_unlikely 是内核的静态分支优化。默认关闭时,所有统计代码编译为零开销的 NOP;开启时,通过运行时补丁动态插入统计逻辑。这就是为什么生产环境默认不打开 schedstat——每次数值更新都需要额外的原子操作和时钟读取,在高调度频率的服务器上可能带来 1-3% 的开销。
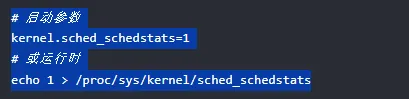
开启方式:
当依赖的 tracepoint(如 sched_stat_wait)被激活时,内核会自动强制开启 schedstat,并发出告警提示。
三、关键执行路径:wait_runtime 的测量之旅
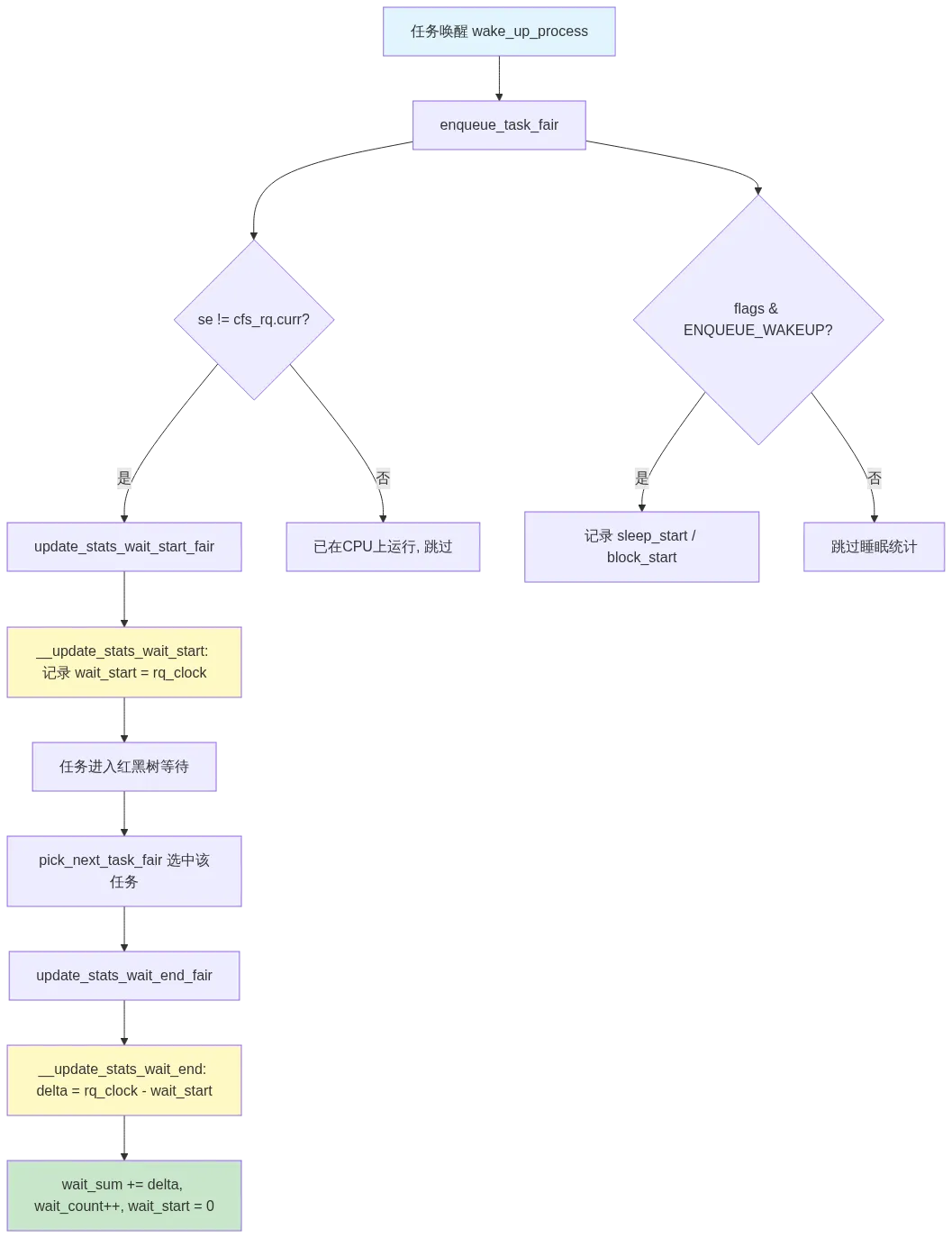
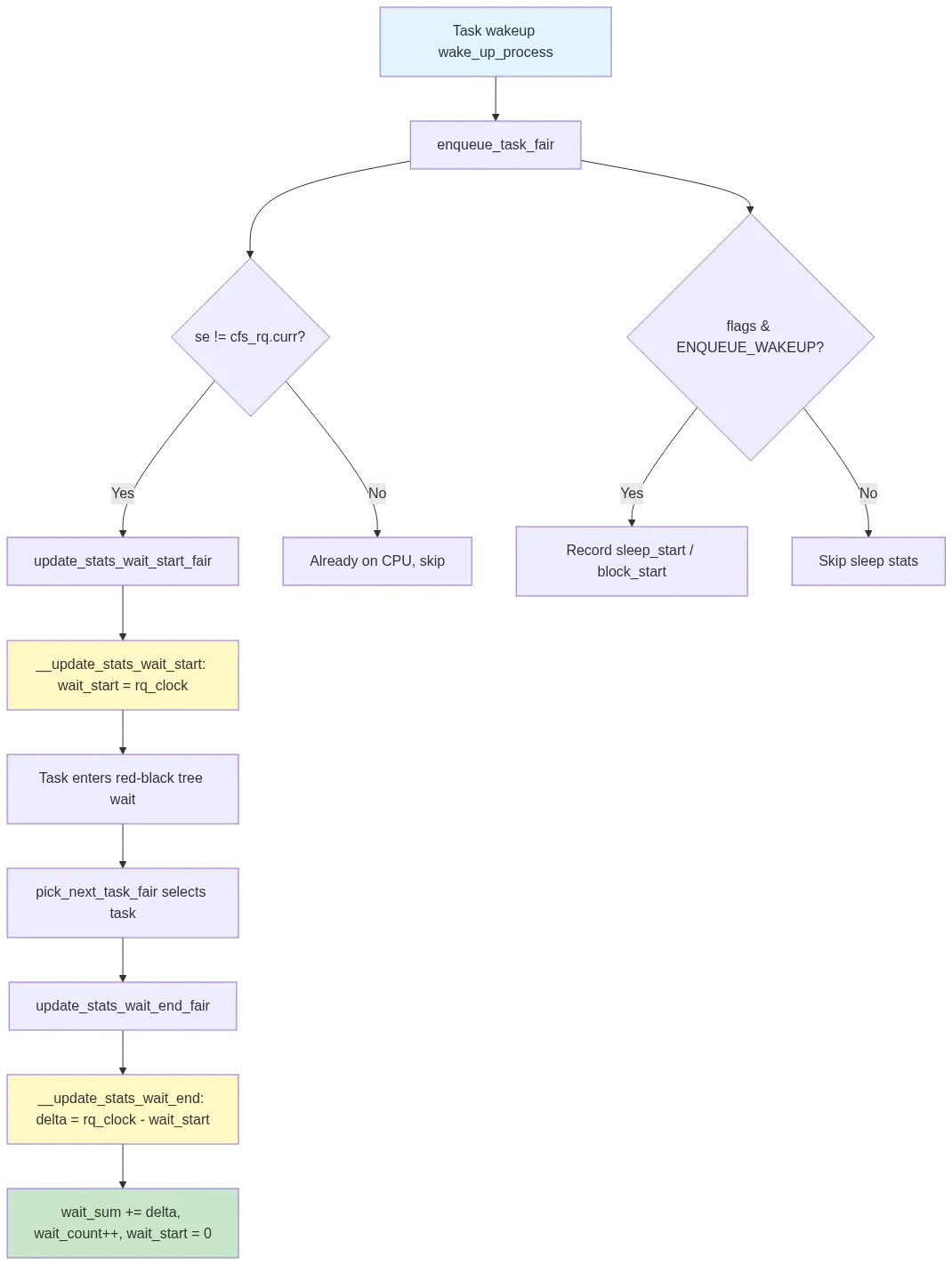
调度延迟的测量贯穿 enqueue 和 dequeue 的完整生命周期。让我们追踪一条任务从睡眠唤醒到获得 CPU 的路径。
3.1 Enqueue:等待计时开始
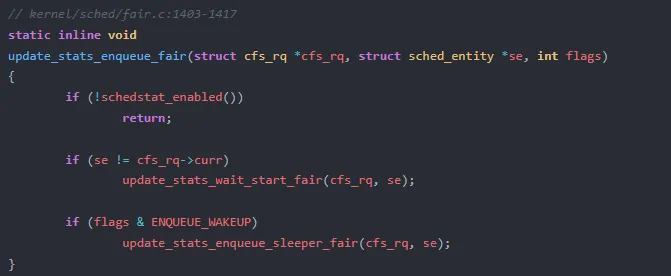
当任务被唤醒并入队,enqueue_task_fair 调 update_stats_enqueue_fair:
逻辑分为两步:
se != cfs_rq->curr:如果入队的不是当前正在 CPU 上运行的任务,说明它需要等待,于是调用 update_stats_wait_start_fair 记录等待起点ENQUEUE_WAKEUP:如果是唤醒操作,还会调用 update_stats_enqueue_sleeper_fair 记录睡眠/阻塞时长
3.2 Dequeue:等待计时结束
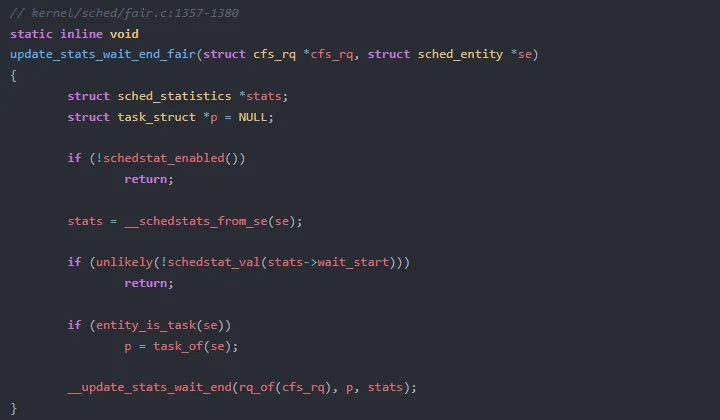
当调度器选中该任务并切换到它时,update_stats_wait_end_fair 被调用:
这里有一个防御性检查:wait_start 为 0 时直接返回。这发生在 schedstat 动态开启的场景——已经排在队列中的任务,其 wait_start 可能是 0,此时无法计算有效的 delta,必须跳过以避免脏数据。
3.3 完整路径图
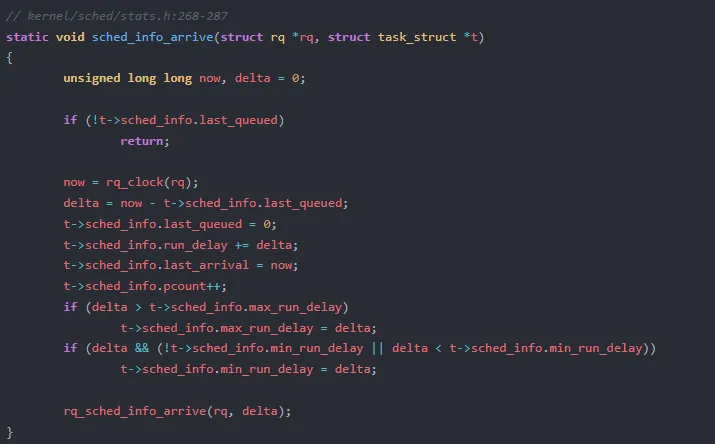
3.4 sched_info 的辅助统计
sched_info 提供了另一层统计,关注的是"从首次入队到上 CPU"的全局延迟:
与 wait_sum 不同,run_delay 包含了从 enqueue 到 CPU 执行的完整路径时间,且额外维护了 max_run_delay 和 min_run_delay——这对分析延迟抖动(jitter)极为有用。
为什么 wait_sum 与实际用户体验延迟存在差距?wait_sum 只统计了任务在运行队列上"可见"的等待时间。但从用户角度看,延迟还包括:用户态系统调用陷入内核的时间、唤醒信号传递的延迟(ttwu)、甚至 NUMA 跨节点内存访问的额外开销。wait_sum 是调度延迟的下界,实际感知延迟只会更长。
四、用户空间工具:从指标到诊断
内核收集了这么多统计数据,用户空间如何消费?
4.1 perf sched latency
perf sched latency 是分析调度延迟的首选工具。它利用 sched_switch 和 sched_stat_* tracepoint 重建每个任务的等待历史:
输出关键字段解读:
- Average delay ms:该任务所有调度等待事件的平均延迟(即
wait_sum / wait_count) - Maximum delay ms
- Maximum delay at
如果平均延迟超过 1ms,说明该任务存在明显的调度等待问题;如果最大延迟超过 10ms,可能是 CPU 亲和性绑定不当或存在 CPU 饥饿场景。
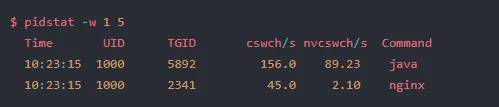
4.2 pidstat -w:上下文切换视角
- cswch/s(voluntary context switches):自愿切换次数,通常因等待 IO 或锁触发。高频自愿切换说明任务频繁阻塞,此时调度延迟往往不高(因为切换是主动的)。
- nvcswch/s(involuntary context switches):非自愿切换次数,因时间片耗尽或被高优先级任务抢占。这个值高才是调度延迟问题的信号——任务频繁被抢走 CPU,意味着它在运行队列中排队的时间在累积。
关键判断逻辑:如果 nvcswch/s 高但 CPU 使用率不高,说明任务每次获得 CPU 的时间很短就被抢占,大量时间浪费在队列等待上。
4.3 vmstat cs:系统级调度频率
cs(context switches per second)反映系统的整体调度频率。与调度延迟的关系:
- cs 值异常高(如 > 100,000/s):大量短任务频繁切换,每个任务的
wait_sum 可能不大,但累积延迟显著 - cs 值低但延迟高:说明调度器在长任务之间切换,被抢占的任务在队列中等待时间很长——这是"CPU 不高但系统慢"的典型场景
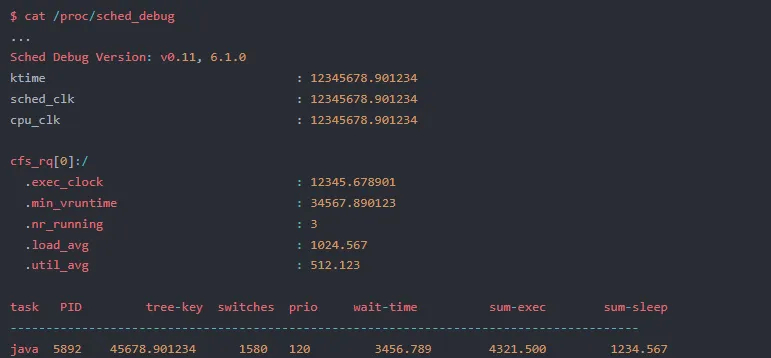
4.4 /proc/sched_debug:调试窗口
关键字段:
- wait-time
- sum-exec:累计执行时间,与
wait-time 比值可计算 CPU 利用率 - tree-key
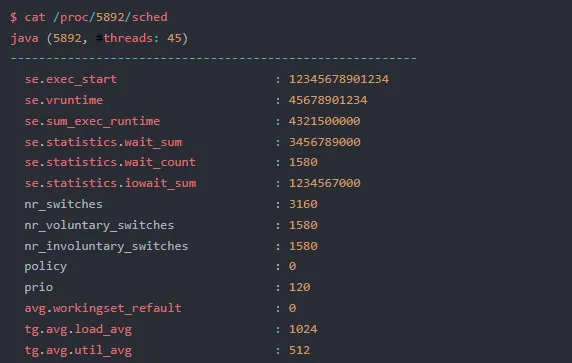
4.5 /proc//sched:单任务视角
这是一个任务维度的全景视图。wait_sum 与 sum_exec_runtime 的比值(3456ms / 4321ms ≈ 80%)告诉我们:这个任务等待的时间比它执行的时间还长!这就是"CPU 不高但系统慢"的量化证据。
五、架构总结:延迟视角下的调度器
回顾本文的核心要点:
- 调度延迟的测量依赖于 CONFIG_SCHEDSTATS,默认关闭以避免性能开销。排查性能问题时需要主动开启
wait_start → wait_sum → wait_count 构成了延迟测量的闭环,迁移场景下通过保留 delta 保证跨 CPU 统计的一致性- PELT 的指数衰减设计让
util_avg 成为反映任务实时负载的低通滤波器,而非简单的算术平均 wait_sum 是调度延迟的下界nvcswch/s 高 + CPU 使用率低 = 典型的调度延迟问题
调度延迟本质上是一个排队论问题:CPU 是服务台,就绪队列是等待线,任务在队列中的停留时间取决于到达率和处理率的差值。当到达率接近处理率时,即使 CPU 没有满载,队列长度也会急剧增长——这正是 Little's Law 在操作系统中的体现。
下次遇到"系统慢但 CPU 不高"的场景,不要只盯着 CPU 百分比。打开 /proc//sched,看看 wait_sum 和 sum_exec_runtime 的比值——数字不会说谎。
互动问题:你的生产环境中,平均调度延迟(wait_sum / wait_count)通常在什么范围?在容器场景下,cgroup 的 cpu.cfs_quota_us 设置是否加剧了调度延迟?欢迎在评论区分享你的排查经验。
本系列文章基于 Linux 6.19.13 内核源码
采用 CC BY-NC-SA 4.0 协议,转载请注明出处






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
