学Python爬虫,别一上来就啃复杂项目。
这次整理了一份Python公开音频资源保存模板,非常适合新手练习爬虫完整流程。
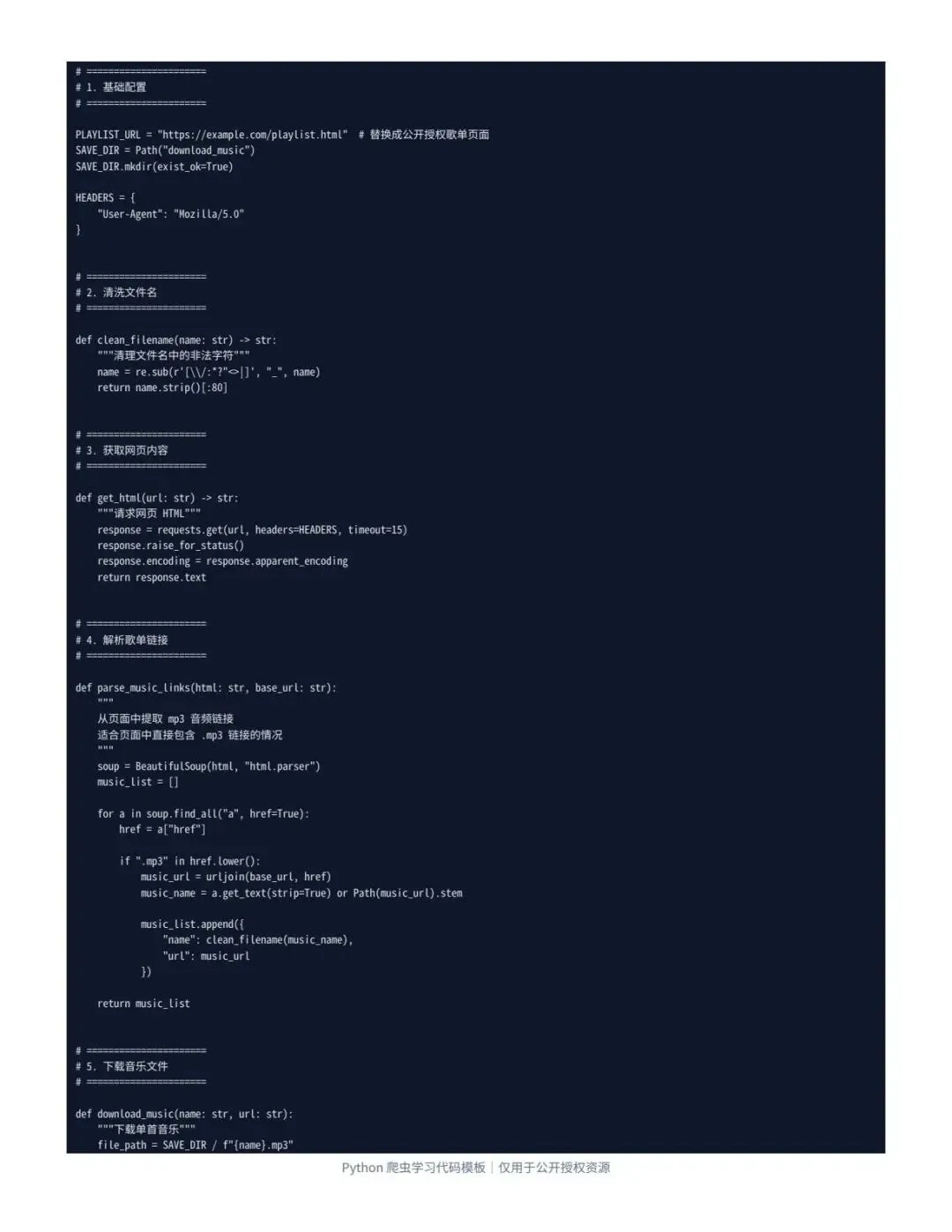
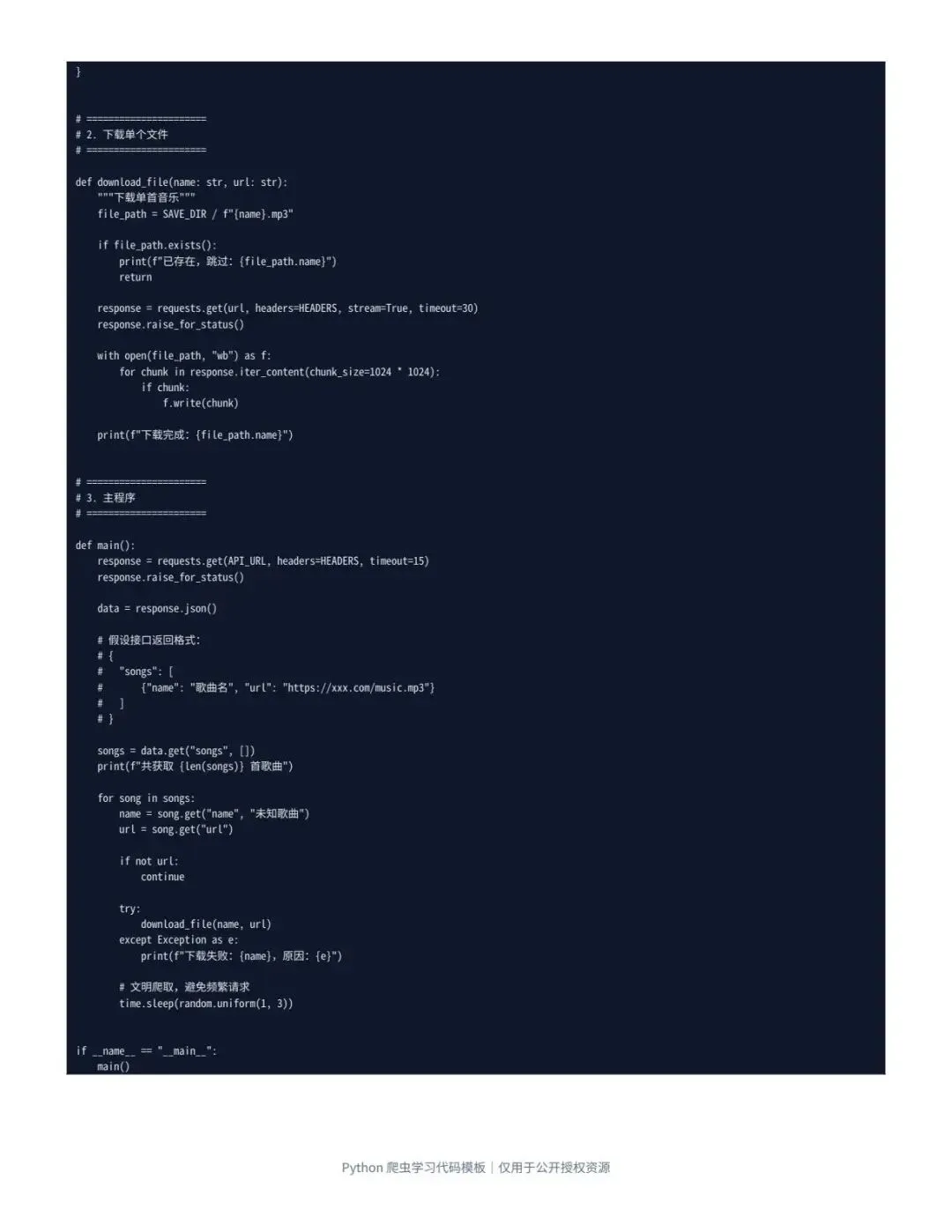
核心内容包括:
请求网页:用 requests 获取页面或接口数据解析数据:用 BeautifulSoup / JSON 提取音频链接批量保存:循环下载并保存到本地文件夹异常处理:处理请求失败、文件名错误、链接为空等问题
这份模板真正适合练的是:
网页请求、数据解析、文件保存、循环处理、异常捕获。
学会之后,不只是会“下载文件”,而是能理解一个 Python 爬虫项目从 0 到运行的完整流程。
注意:仅用于公开授权音频、自建资源和学习练习,不要用于付费音乐、会员资源或未授权内容。