Syslog日志是网络排障的金矿,但原始日志太碎,不用工具分析根本看不出规律。我用了pandas之后,排查效率提升了好几倍。
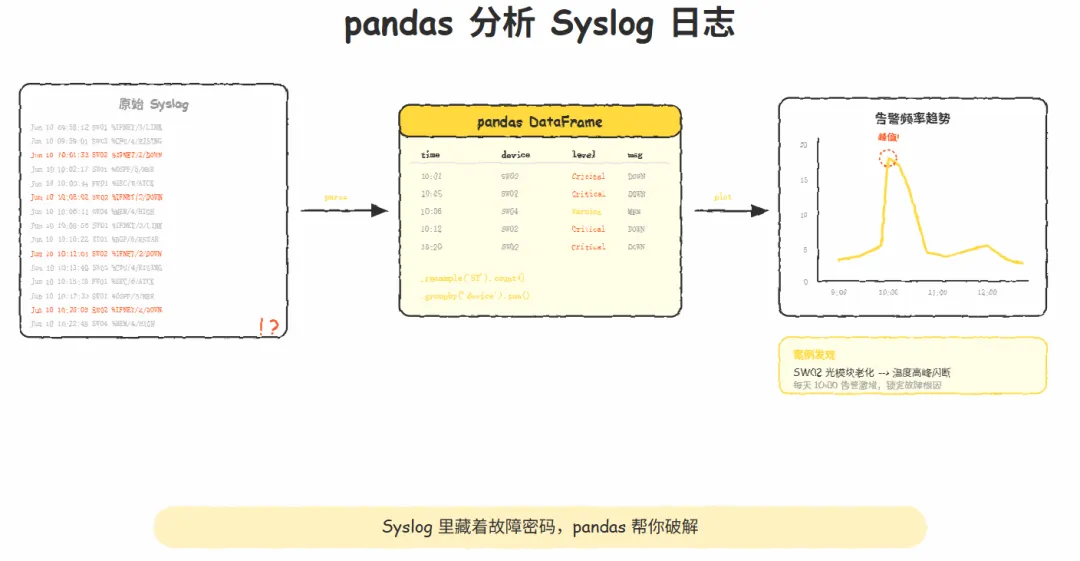
核心思路是把Syslog日志解析成DataFrame,按时间、设备、告警级别分组统计。比如某台设备每周五下午CPU告警,人工翻日志要翻几百行,用pandas的resample和groupby,几行代码就出结果。
解析Syslog有个坑,不同厂商的日志格式不一样。华为的Syslog格式是"时间戳 设备名 告警级别 告警ID:描述",华三的又不同。我一般先写个正则把公共字段提取出来:时间、设备名、告警级别、告警内容。
有一次遇到全网随机断线的故障,翻日志翻了两天没找到根因。后来用pandas把一周的Syslog全部读进来,按时间resample成5分钟间隔,统计每个时间段的告警数量。结果发现每天上午10点左右告警数量激增,进一步按设备分组,锁定是一台接入交换机的光模块老化,到了温度高峰就频繁闪断。
pandas的resample函数特别适合时间序列化。把时间列设成index,resample('5T')就是按5分钟聚合,再接count()就能画出告警频率曲线。配合matplotlib画个图,给领导汇报的时候特别直观。
groupby也一样好用。按设备名groupby,统计每台设备的告警总数,排名前三的就是重点排查对象。按告警级别groupby,看看有没有Critical级别的告警被漏掉。
内存方面要注意,如果Syslog文件特别大(几百MB),一次性read_csv会爆内存。我的一般做法是分块读取:pd.read_csv('syslog.log', chunksize=10000),逐块处理再合并结果。
还要提一句,Syslog的时间戳要统一格式。有些设备发过来的时间戳是本地时间,有些是UTC,不统一的话resample会出问题。我一般在解析阶段就把所有时间转成UTC+8,存成datetime格式,后面分析就省心了。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
