封面
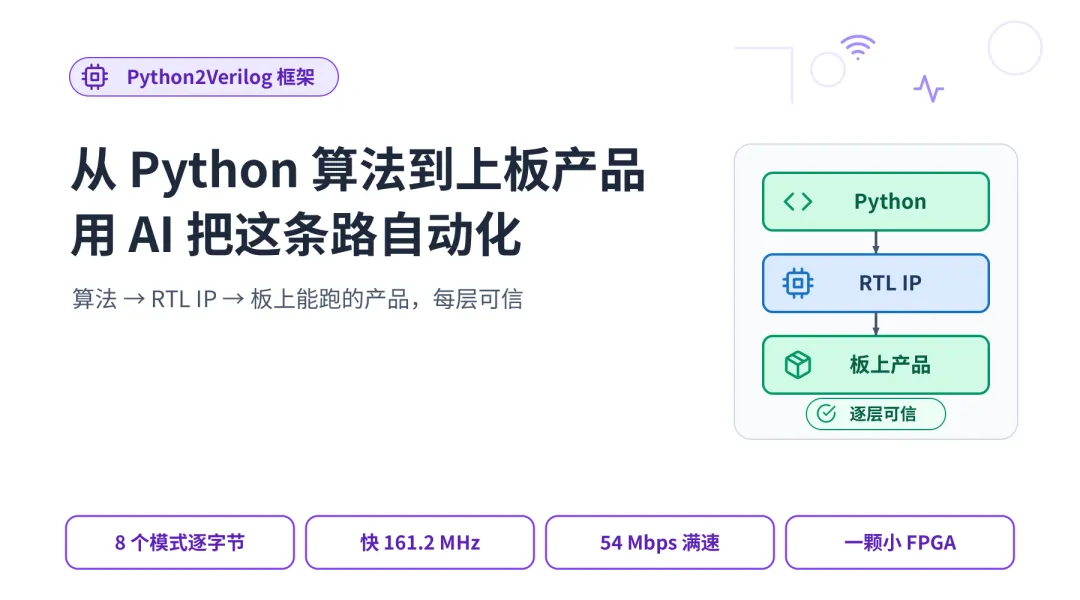
一个完整的 802.11a WiFi 接收机,从 BPSK 到 64-QAM 全部 8 个模式逐字节正确
RTL 由 AI 从 Python 算法生成,芯片太小装不下整机,前端后端分两段上板验证
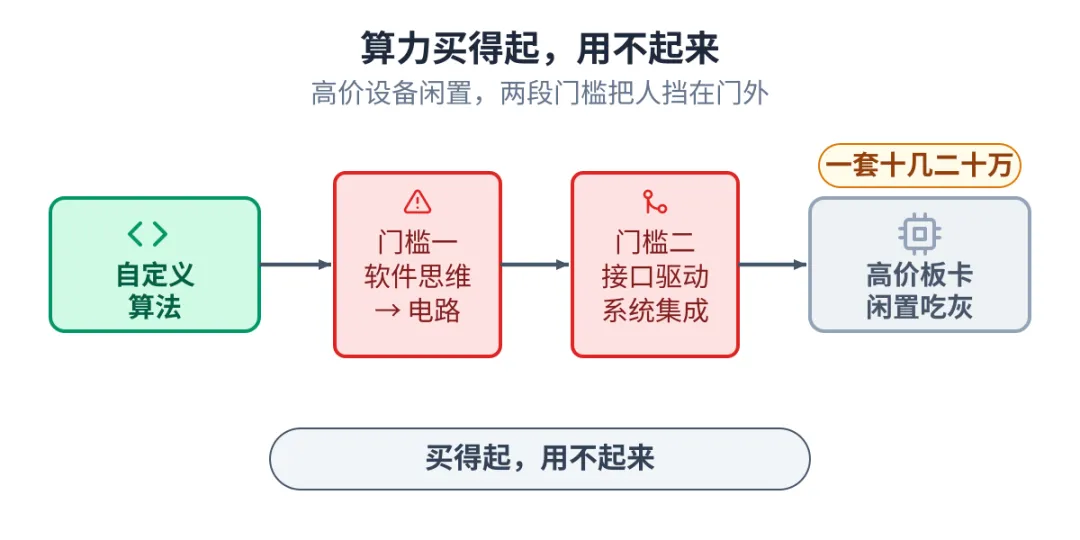
我在国内和国外的大学都工作过,看到一个普遍现象:高性能设备和 FPGA 板卡,利用率都不高。USRP、RFSoC、Alveo 这类板卡一套十几二十万,买的时候花了不少钱,买回来大多时间闲置,或者只用来做简单的数据收发,很少能做有深度的算法定制开发。着实有点浪费。
不是大家不想用,是用起来太难。这篇想讲清楚难在哪,以及我们正在做的一件事:用 AI 搭一套自动化工具,把"Python 算法到能上板运行的产品"这条路自动完成了。
算力不是缺,是用不起来。门槛太高,愿意碰硬件的人反而越来越少。
1算力买得起,用不起来
把一个自定义算法真正跑到这些板卡上,门槛来自两段,缺一段都不行。
第一段是把软件算法变成高效的逻辑电路。CPU 上是一条一条指令顺着跑,FPGA 上是成百上千个运算同一拍并行发生,两种思维方式跨度很大。同一个算法,写成能跑的电路和写成又快又省的电路,完全是两回事。
第二段更磨人,是把电路真正集成到板子上,连通外围数据通路整个软硬件系统跑起来。接口要调试,模块要互联,还要写驱动、写上层应用,既要懂底层硬件又要懂上层软件。中间出了问题,往往还很难定位是哪一环。
这两段叠在一起,把高价设备的深度使用挡在了门外。结果是设备在吃灰,愿意沉下心学硬件的人也越来越少。
高价设备闲置,两段门槛把人挡在门外
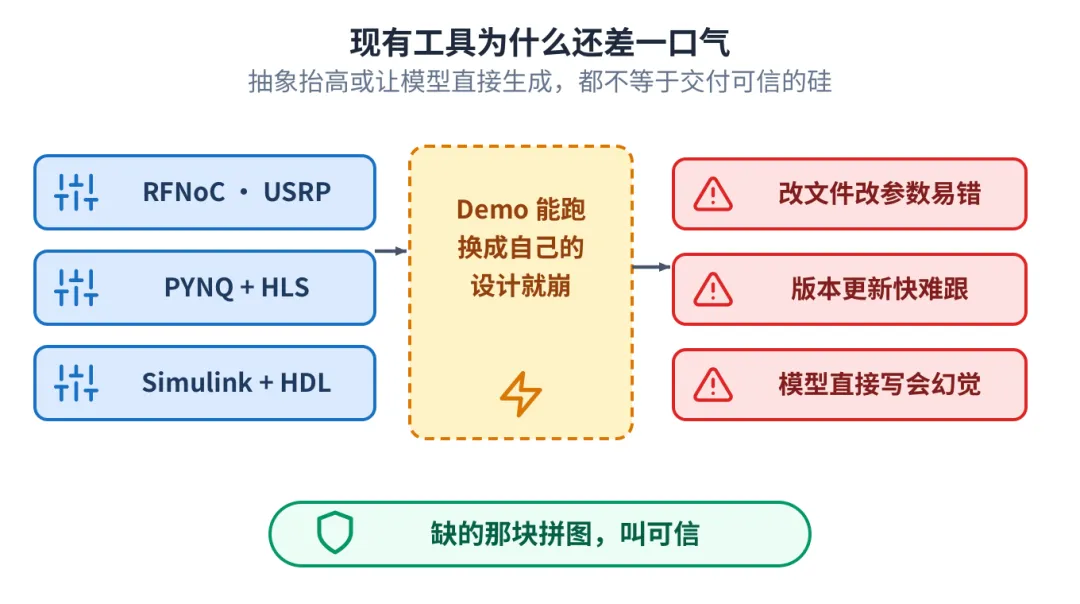
2现有工具为什么还差一口气
为了降低门槛,厂商做了很多工作。USRP 有 RFNoC,方便把自定义硬件模块嵌进完整系统。AMD/Xilinx 有 PYNQ,配合 HLS 能较快地做算法核和系统开发。MATLAB 也有 Simulink 加 HDL Coder 这条路。
有这些工具是好事,但真上手会发现一个共同的体验:Demo 能跑,换成自己的设计就出各种问题。而且过程里要大量手动改文件、改参数,繁琐又容易出错。工具版本更新还快,学不同工具的不同版本,本身就很耗精力。
这不只是我们的体感。把抽象层抬高的 HLS,被反复记录有一个生产率和性能的剪刀差:写起来是省事了,但要选对那些优化指令,以及重构对硬件友好的 HLS C 代码,依然需要很深的硬件经验,软件工程师也很难用起来,跟手写 RTL 还有一段实打实的效率差距。
另一条更新的路,是直接让大模型写 Verilog,这两年很热。但它有个绕不过去的问题:模型会一本正经地生成看着合理、实际功能是错的硬件代码。学术界做了很多办法,把功能正确率从六成多提到九成多。但剩下的那部分还是错的,没有一种能彻底消除。
把抽象层抬高,或者让模型直接生成代码,都不等于能交付可信的硅。缺的那块拼图,叫可信。
Demo 能跑到自己设计就崩,手动繁琐,模型还会幻觉
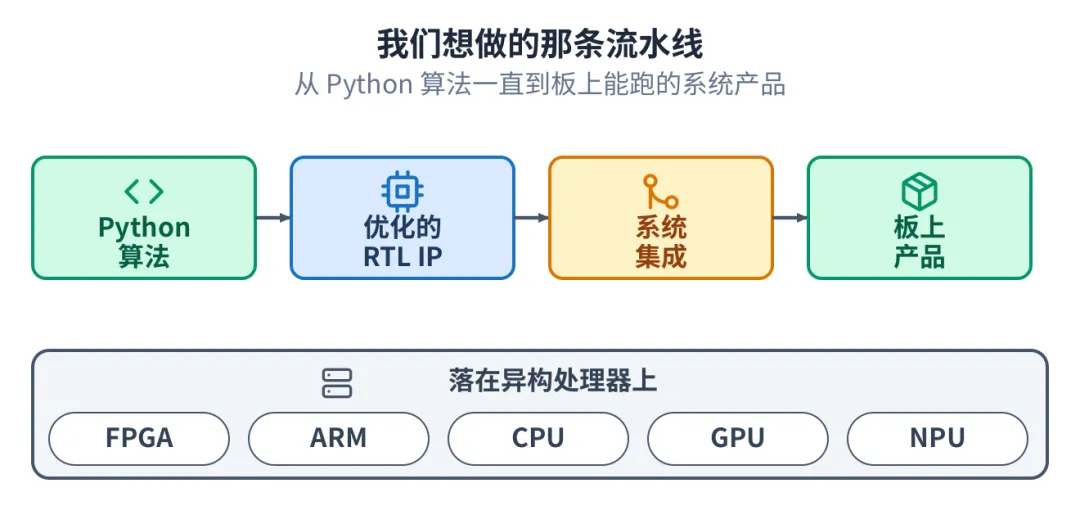
3我们想做的那条流水线
能不能有这样一套自动化工具:自动把软件算法做成优化好的 RTL IP,同时自动完成在目标板卡上的软硬件集成,直接交付一个在真实硬件上能跑的产品。不只支持 FPGA,也支持 CPU、ARM、GPU、NPU 这些异构处理器协同。
这就是我们一直想做、也正在做的事。到目前为止,我们已经走通了几段:
- ▶算法到 IP 把 Python 算法生成优化过的 RTL IP,MATLAB 代码到 HLS C 也做过了
- ▶自动收敛 FPGA 设计里绕不开的时序收敛、资源优化这些关键环节自动完成
- ▶自动上板 在通用硬件平台上做自动化的系统集成、前仿后仿和板上测试
把这几段串起来,就是一条从 Python 一直到板上产品的流水线。算法在最前面,板上能跑的系统在最后面,中间那些又难又琐碎的环节,交给框架和 AI。
算法到 RTL IP 到系统集成到板上产品,落在异构处理器上
4一个真实的例子:Pluto 上的 WiFi 接收机
光说方法不够,得有个真东西证明它走得通。我们选了 ADALM-Pluto 这块 SDR,板上是一颗入门级的小芯片 Zynq-7010,让框架生成一个完整的 802.11a WiFi 接收机。
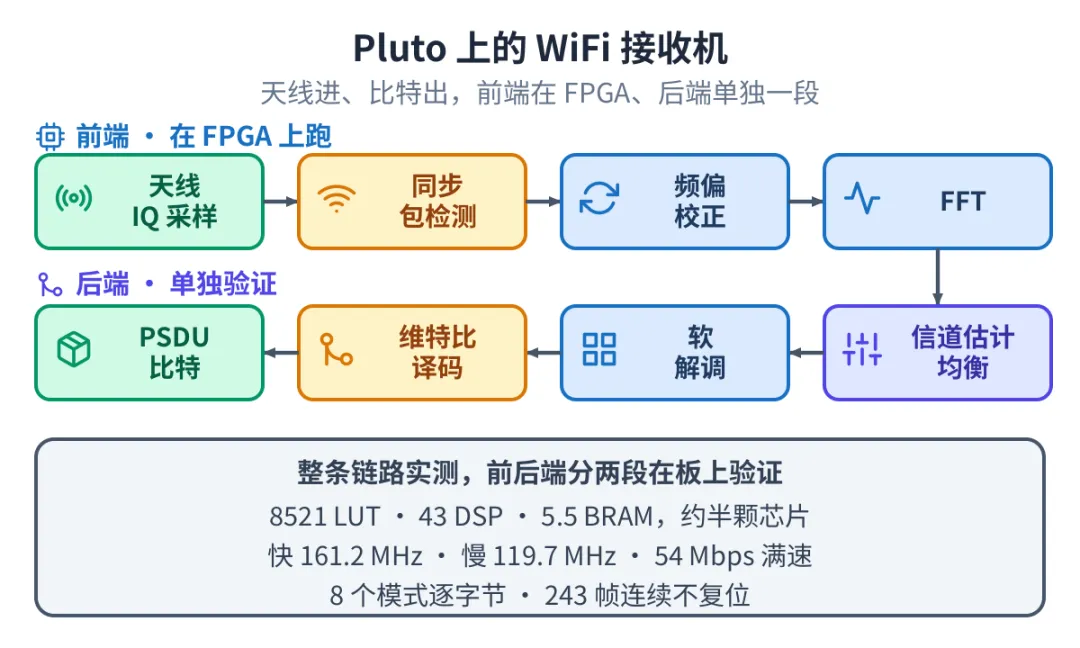
它做的是一件完整的事:天线进来的 IQ 采样,一路做包检测、载波频偏估计与校正、定时同步、FFT、信道估计、均衡、软解调、解交织、解删余、维特比译码、解扰,最后吐出 PSDU 比特。整条链路都是框架从 Python 周期模型生成的 RTL。
天线到比特的接收链路,前端在 FPGA、后端单独一段
这颗 7010 很小。接收机本身的逻辑约 8521 个查找表,可一块真正能用的 SDR 还得在同一颗芯片上放下射频接口和数据搬运,全部加起来就超过了这颗芯片放得下的量。所以我们顺着信号走向把接收机切成两段:前面的信号处理前端留在 FPGA 上、直接吃天线进来的采样,后面的纠错译码后端放到主机 CPU 上跑。这正好用上前面说的异构协同:一颗芯片装不下,就让 FPGA 和主机各干一段,两段对同一个金标准都验到逐字节一致。
后端跑在主机上,不代表它离不开主机。我们还另做了一个设计,把后端的 RTL 单独放到 Pluto 的 FPGA 上,用板上抓下来的真实数据喂进去,在芯片上把译码这一段也验了一遍,8 个模式同样逐字节正确。
把测出来的数字摆一摆:
- ▶跑得动 整条链路布局布线后,快时钟到 161.2 MHz、慢时钟 119.7 MHz,满足 20 Msps 的 54 Mbps 满速
- ▶算得对 从 BPSK 到 64-QAM 全部 8 个模式,对周期模型逐字节一致
- ▶经得起连续 后端连续跑 243 帧、中间不复位,每帧自己重新起弧,8 个模式全过
- ▶上得了天线 部署后连续跑 90 秒、1390 个包零差错,收到的包不管有线还是天线,8 个模式都逐字节正确
5上板不是靠运气,是靠方法
同一个设计,之前的尝试没能让它在板上跑起来,这一次跑通了,差别不在某个聪明的技巧,在方法。
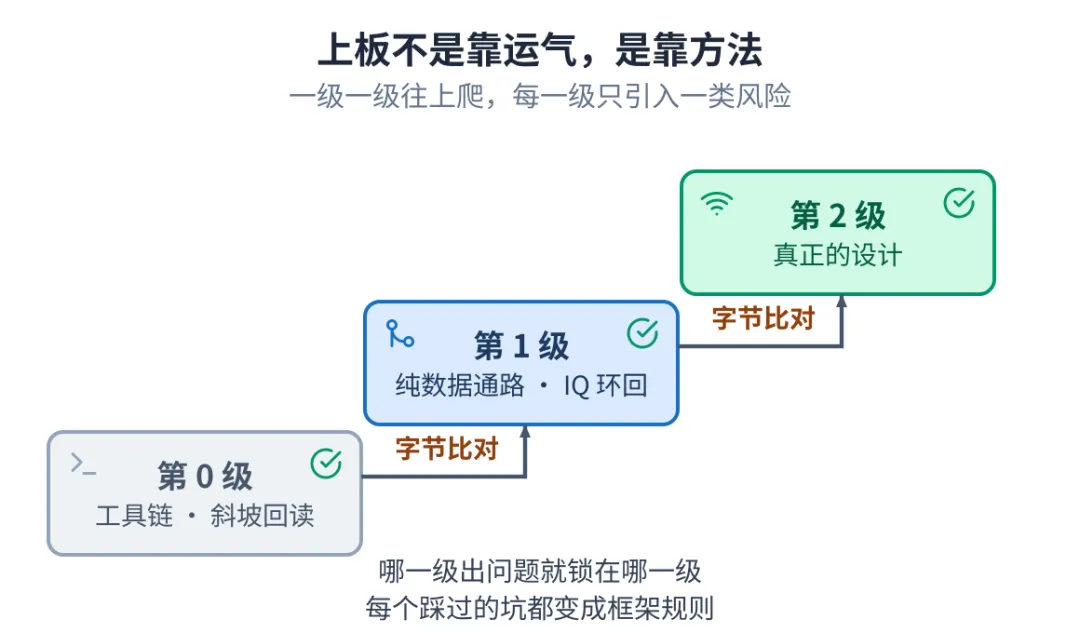
把整机直接拍到板上调,最容易把"集成管线的问题"和"计算逻辑的问题"搅在一起,谁也分不清。我们改成一级一级往上爬,每一级只引入一类新风险,过了才往上走:
- ▶第 0 级 先用一个确定的斜坡数据走通工具链,从生成比特流到烧录回读,证明这条路本身没问题
- ▶第 1 级 再把 IQ 采样原样环回,证明采样时钟、跨时钟域、接口都对,这一级里一行设计逻辑都不加
- ▶第 2 级 最后才把真正的设计加上去,逐级跟标准模型逐字节比对
哪一级出问题,问题就被锁死在那一级,好查也好修。每一次踩的坑,最后都变成框架里的一条规则,下次不再踩。
从工具链到纯数据通路再到真正的设计,逐级字节比对
6接下来
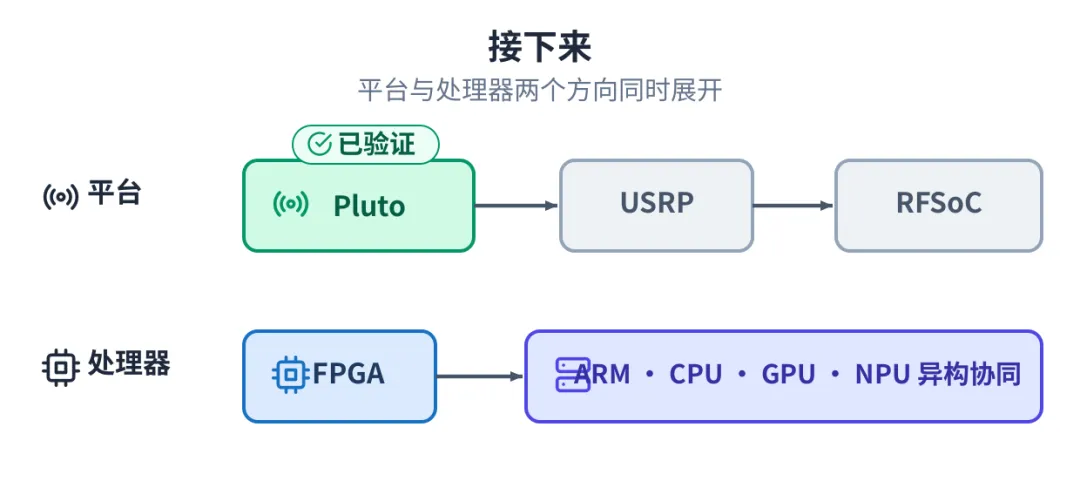
Pluto 上的 WiFi 接收机,验证的是整套方法走得通:算法到 RTL IP,到系统集成,到板上能跑的产品,每一层都对得上、可信。
往下走有两个方向。一个是平台,从 Pluto 推到 USRP、RFSoC 这些更大的设备上。一个是处理器,从 FPGA 延伸到 CPU、ARM、GPU、NPU 的异构协同。
两个方向:平台从 Pluto 到 USRP 到 RFSoC,处理器从 FPGA 到异构协同
把那些又难又琐碎的环节交给框架和 AI,让做研究、做产品的人,能把买回来的算力真正用起来,而不是让它吃灰。这是我们想做的事。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
