为什么同一块 RDMA 网卡,在 Linux 里会有两个名字?
- 2026-07-02 16:26:39
这里是「算力网络架构手记」北京
专注 AI 集群网络架构与性能优化
深入 GPU×RoCE×NCCL×K8s 跨层瓶颈
只拆真实问题,不写概念科普
👇 试听内容
00
故事从刚开始说起
刚接触 RDMA 网卡,会被一个问题卡住:
明明是同一张网卡,为什么在 Linux 里看到的是:
ens257f0np0ens257f1np1
到了 RDMA 工具里,又变成了:
mlx5_0mlx5_1
再看 NCCL 文档,又冒出来两个变量:
NCCL_SOCKET_IFNAMENCCL_IB_HCA
一个要填 ens257f0np0一个要填 mlx5_0
这时候有点懵:
这到底是不是同一块网卡?
为什么不能统一叫一个名字?
我做 RoCE 实验,到底该看哪个?
我跑 NCCL,到底该绑哪个?
我查交换机端口,又该对哪个?
同一块 RDMA 网卡有两个名字,不是 Linux 乱了,而是你同时站在两个不同的系统视角里看它。
01
ip a 里找不到 mlx5_0
很多人排查 RDMA 问题,第一步会敲:ip a
然后看到:
ens257f0np0ens257f1np1
但是手册里写的是:
ib_write_bw -d mlx5_0
于是他开始找:
ip a | grep mlx5
结果什么都没有。
然后就慌了:
是不是 RDMA 驱动没装好?
是不是网卡没识别?
是不是 mlx5_0 丢了?
是不是系统命名错了?
其实不是。
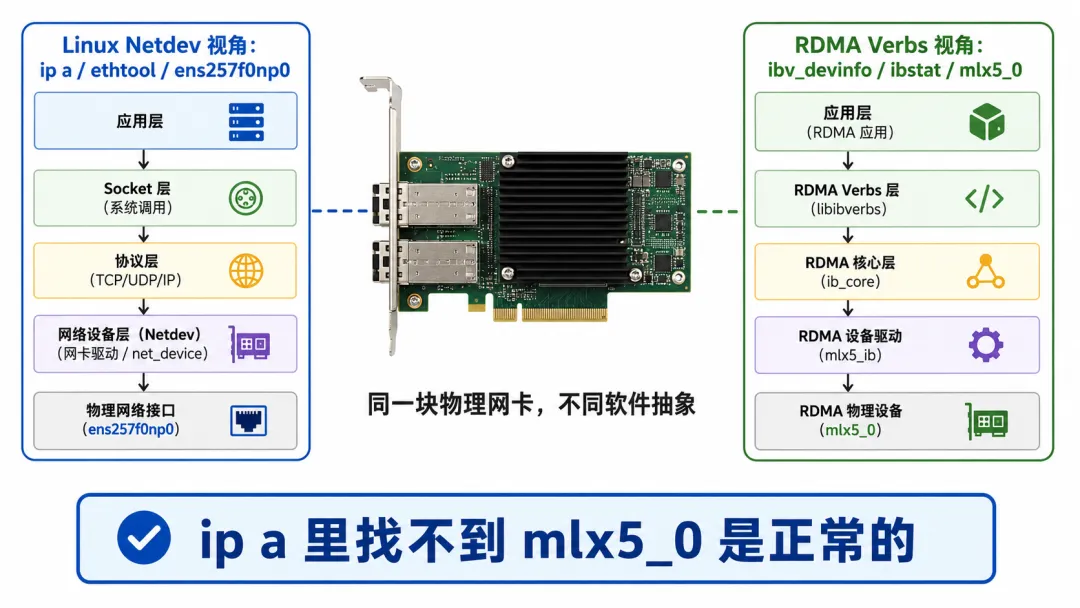
因为 ip a 看的是Linux 网络接口。
而 mlx5_0 是RDMA verbs 设备名。
它们不是同一个命名空间。
ens257f0np0 是 Linux 网络栈看到的接口。mlx5_0 是 RDMA 子系统看到的 HCA / RDMA 设备。
一个偏向 IP / Ethernet / netdev。一个偏向 RDMA / verbs / QP / HCA。
在 ip a 里找不到 mlx5_0,是正常的。在 ibv_devinfo 里找不到 ens257f0np0,也是正常的。
Linux 的可预测网络接口命名由 systemd/udev 体系管理,常见名字包括 eno、ens、enp 等,用来替代过去容易变化的 eth0、eth1 传统命名方式。
ens257f0np0是 Linux 网络接口名,mlx5_0是 RDMA 设备名;它们可能指向同一块物理网卡,但不是同一种名字。
02
两个名字背后,是两套“看网卡的方式”
如果把 RDMA 网卡只理解成“高级网卡”,很容易混乱。
更准确地说,它同时活在两个世界里。
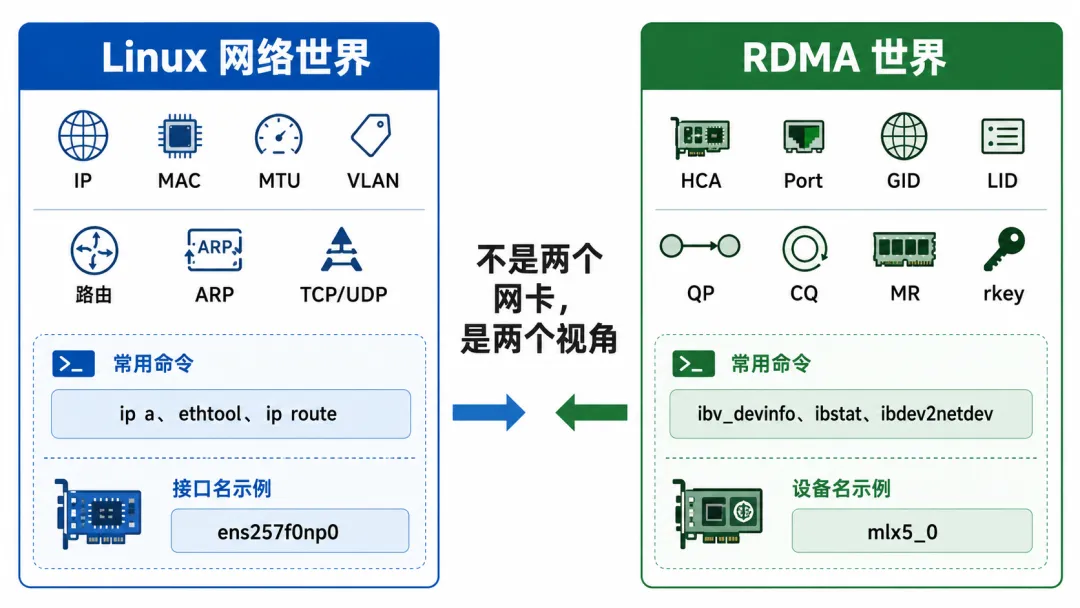
第一个世界,是 Linux 网络世界
这里关心的是:
IP 地址MAC 地址MTUVLAN路由表ARPTCP/UDP网卡收发包统计
所以你用这些命令看它:
ip aip linkethtoolethtool -iip route
看到的名字通常是:
ens257f0np0enp65s0f0np0eth0
第二个世界,是 RDMA 世界
这里关心的是:
HCARDMA PortGIDLIDQPCQMRrkeyMTULink Layer
所以你用这些命令看它:
- ibv_devinfo- ibstat- ibdev2netdev- rdma link
看到的名字通常是:
mlx5_0mlx5_1mlx5_2
这不是重复。
这是分层。
Linux 网络接口负责把它当“网卡”看。RDMA 子系统负责把它当“RDMA 通信设备”看。
ibv_devinfo 这类工具就是用来显示 RDMA 设备信息的,很多发行版会把它放在 libibverbs-utils 或 ibverbs-utils 相关软件包中。
一个名字回答“这块网卡怎么走 IP”,另一个名字回答“这块 HCA 怎么跑 RDMA”。
03
为什么 RDMA 不能只用 Linux 接口名?
有人会问:
既然 Linux 已经有 ens257f0np0 了,为什么 RDMA 不直接用它?为什么还要搞一个 mlx5_0?
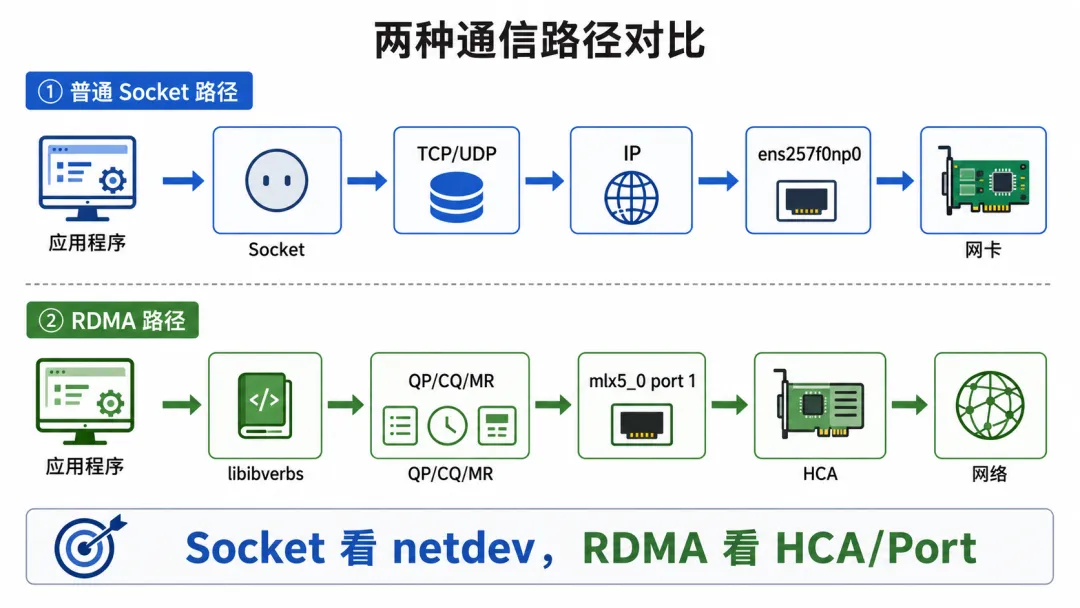
因为 RDMA 的通信模型,不是普通 Socket 模型。
普通网络应用通常是:
应用程序 → Socket → TCP/UDP → IP → 网卡驱动 → 网卡
而 RDMA 通信更接近:
应用程序 → libibverbs / RDMA API → QP / CQ / MR → HCA → 网络
RDMA 关心的不是“我从哪个 IP 接口发包”这么简单。它还要关心:
用哪个 HCA?
用这个 HCA 的哪个 Port?
用哪个 GID?
使用 RoCE 还是 InfiniBand?
QP 怎么建立?
内存怎么注册?
Completion 怎么回来?
所以,RDMA 需要自己的设备抽象。
mlx5_0 不是为了让你多记一个名字,它是为了让 RDMA 软件栈明确知道:
我要操作哪一个 RDMA 设备
我要打开哪一个 HCA
我要在哪个 Port 上创建通信资源
如果只用 ens257f0np0,它表达的是 Linux netdev。而 RDMA 需要的是 verbs 设备。
Linux 接口名解决的是“网络接口是谁”,RDMA 设备名解决的是“我要打开哪个 HCA 做零拷贝通信”。
04
RoCE 场景下
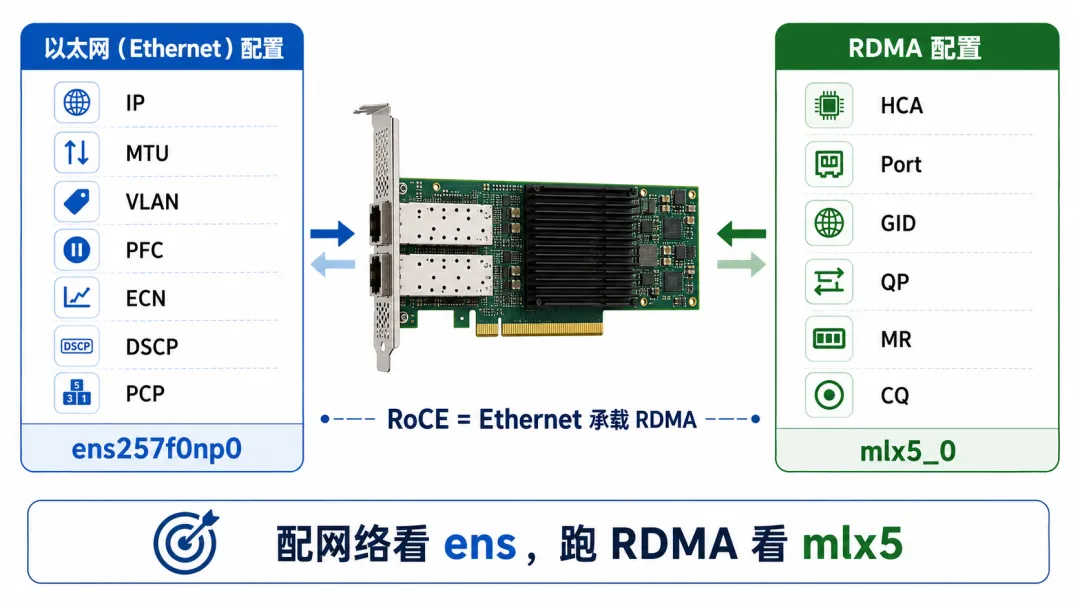
在 RoCE 里,这个问题尤其容易混乱。
因为 RoCE 本质上是 RDMA over Ethernet。
也就是说,底层链路是 Ethernet。所以它一定会有 Linux 网络接口。
你会看到:
ip aens257f0np0
你也会看到:
ibv_devinfomlx5_0
这两个都是真的。
RoCE 的数据包走 Ethernet。所以你要配置 IP、MTU、VLAN、PFC、ECN、DSCP、PCP、TC。
但是 RDMA 应用创建 QP、注册内存、选择 HCA 时,又要通过 RDMA verbs 设备,也就是 mlx5_0 这类名字。
所以在 RoCE 场景下,两个名字经常同时出现。
例如:
你要看 IP 地址,用:
ip a show ens257f0np0
你要看网卡驱动,用:
ethtool -i ens257f0np0
你要跑 RDMA 带宽测试,可能会用:
ib_write_bw -d mlx5_0 -i 1
你要看 RDMA 设备信息,用:
ibv_devinfo -d mlx5_0
要确认 mlx5_0 现在是 Ethernet 还是 InfiniBand Link Layer,可以看 ibstat 或 ibv_devinfo 的 Link Layer 字段。NVIDIA 文档也特别提醒,判断当前模式应看 Link Layer;示例里 mlx5_0 可以是 Ethernet,mlx5_1 可以是 InfiniBand,而 transport 字段不应该被简单当成端口模式判断依据。
RoCE 最容易让人混乱,因为它既要走 Ethernet 的网络接口,又要使用 RDMA 的 verbs 设备。
05
InfiniBand 场景下
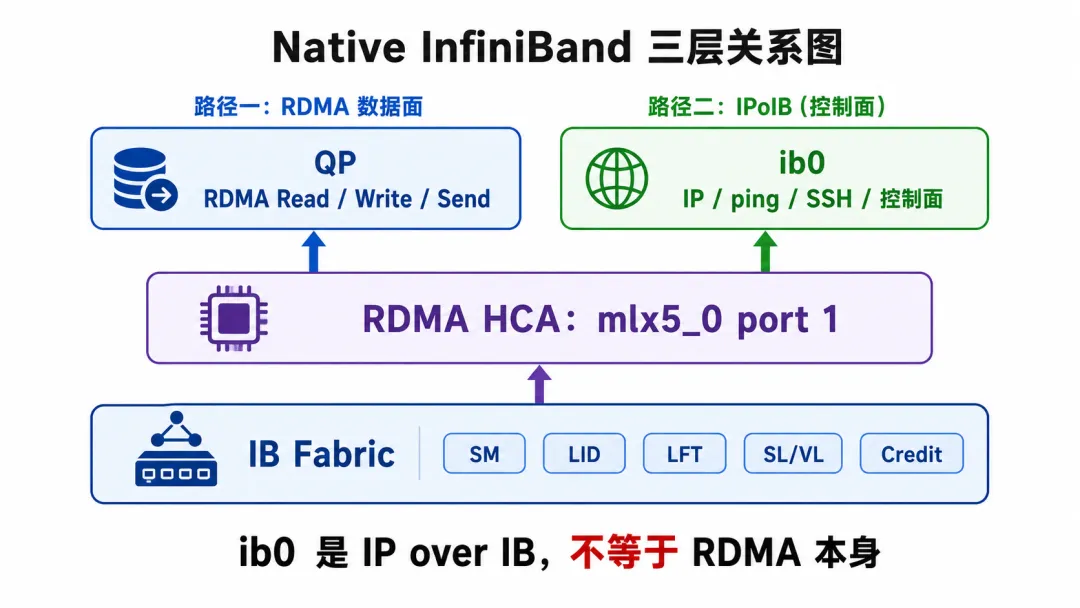
如果是 Native InfiniBand,问题还会多一个角色:
ib0
很多人看到 ib0,又懵了:
那
ib0是什么?它和
mlx5_0又是什么关系?是不是 RDMA 必须靠
ib0才能通信?
这里要分清楚。
mlx5_0 是 RDMA / IB 设备。它代表 HCA 设备。Native IB 的 RDMA 通信可以直接基于 IB Fabric、LID、QP 等机制完成。
ib0 通常是 IPoIB 接口。它的作用是让你在 InfiniBand Fabric 上跑 IP。
也就是说,ib0 是:IP over InfiniBand。
它让你可以在 IB 网络上做一些 IP 相关事情,比如:
SSH
ping
管理连接
某些程序的控制面通信
某些测试工具的地址交换
但不能把它理解成:
“没有 ib0,RDMA 数据面就完全跑不了。”
RDMA 数据面和 IPoIB 不是一回事。
这也是为什么有时候你会看到:
ibv_devinfo 能看到 mlx5_0、ibstat 显示端口 Active,但是 ip a 里没有 ib0
这不一定说明 IB 端口不能跑 RDMA。它可能只是说明你没有启用或配置 IPoIB。
IPoIB 是让 IB 网络承载 IP,不是 RDMA 数据面的本体。
06
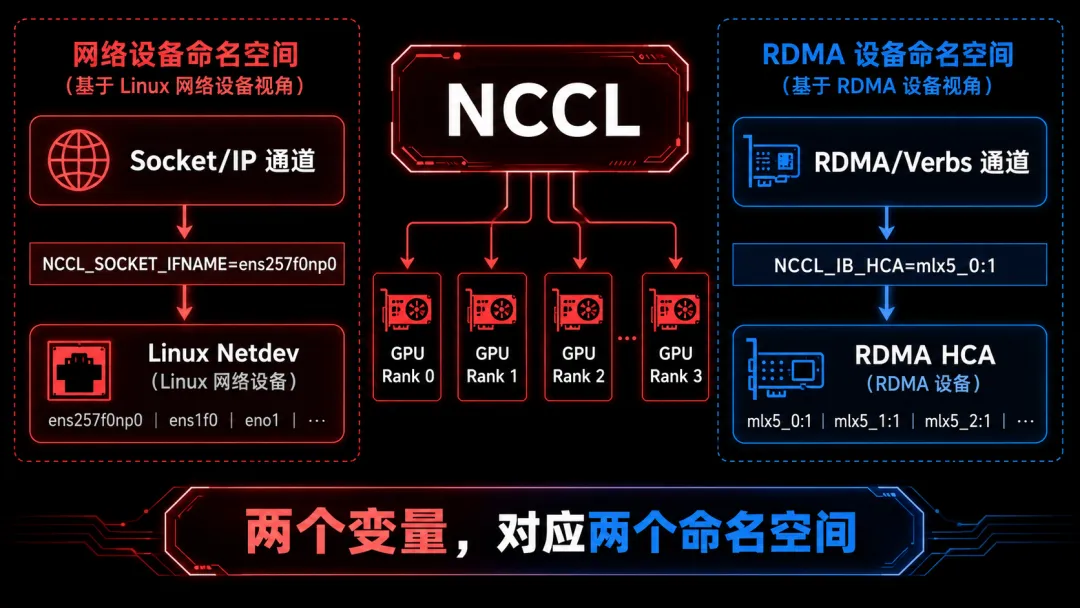
NCCL 里为什么也有两个变量?
这个问题到了 NCCL 里,会变得更典型。
很多人看到这两个变量:
NCCL_SOCKET_IFNAMENCCL_IB_HCA
然后直接乱填。
比如:
exportNCCL_SOCKET_IFNAME=mlx5_0
或者:
exportNCCL_IB_HCA=ens257f0np0
这就容易出问题。
因为这两个变量指向的对象不是一类东西。
NCCL_SOCKET_IFNAME 指的是 IP 网络接口。它应该匹配类似 eth0、ens257f0np0、ib0 这样的接口名。
NCCL_IB_HCA 指的是 RDMA HCA / verbs 设备。它应该匹配类似 mlx5_0、mlx5_1,或者带端口的 mlx5_0:1 这类名字。
NVIDIA NCCL 文档中,NCCL_SOCKET_IFNAME 用于指定 IP interfaces;而 NCCL_IB_HCA 用于指定 RDMA interfaces / HCA,这正好对应了我们前面说的两个命名空间。
所以要记住:
# 选择 Linux IP 接口NCCL_SOCKET_IFNAME=ens257f0np0# 选择 RDMA HCANCCL_IB_HCA=mlx5_0
当然,真实生产环境里怎么设置,要看你的拓扑、网卡数量、NCCL 版本、插件、容器网络、IB/RoCE 模式和调度方式。
但原则不会变:
一个是 socket / IP 接口。一个是 RDMA / HCA 设备。
NCCL_SOCKET_IFNAME 不是填mlx5_0,NCCL_IB_HCA 也不是填 ens257f0np0。
07
perftest 为什么也容易配错?
做 RDMA 实验时,很多人会跑:
ib_write_bwib_read_bwib_send_bw
这里也会碰到两个名字。
比如:
ib_write_bw -d mlx5_0 -i 1 192.168.30.102
这个命令里:
-d mlx5_0 选择的是 RDMA 设备。-i 1 选择的是 RDMA 设备的端口。后面的 192.168.30.102 通常用于两端建立测试连接、交换通信信息。
所以你会发现:
一个命令里,既出现 RDMA 设备名,又出现 IP 地址。
这很正常。
因为很多 RDMA 测试工具需要先让两端“认识彼此”:
QP 号是多少?
LID / GID 是什么?
PSN 是多少?
rkey 是什么?
buffer 信息是什么?
这些信息要先交换。
交换信息这一步,经常会借助 IP 连接。真正的数据压测,再走 RDMA 数据路径。
所以你不能看到命令里有 IP 地址,就认为:
“RDMA 数据一定走 Linux TCP/IP 协议栈。”
也不能看到 -d mlx5_0,就忽略 IP 连通性。
现场常见问题就是:
RDMA 设备没选错,但 IP 控制连接不通。或者 IP 能 ping 通,但 RDMA GID / PFC / ECN / MTU / Link Layer 有问题。
结果就是:
ping 正常,RDMA 不通。或者 RDMA 设备存在,测试连不上。或者带宽跑起来了,但跑不到预期。
perftest 里出现 IP 地址,不代表 RDMA 数据面退回了 TCP/IP;它往往只是控制信息交换的一部分。

08
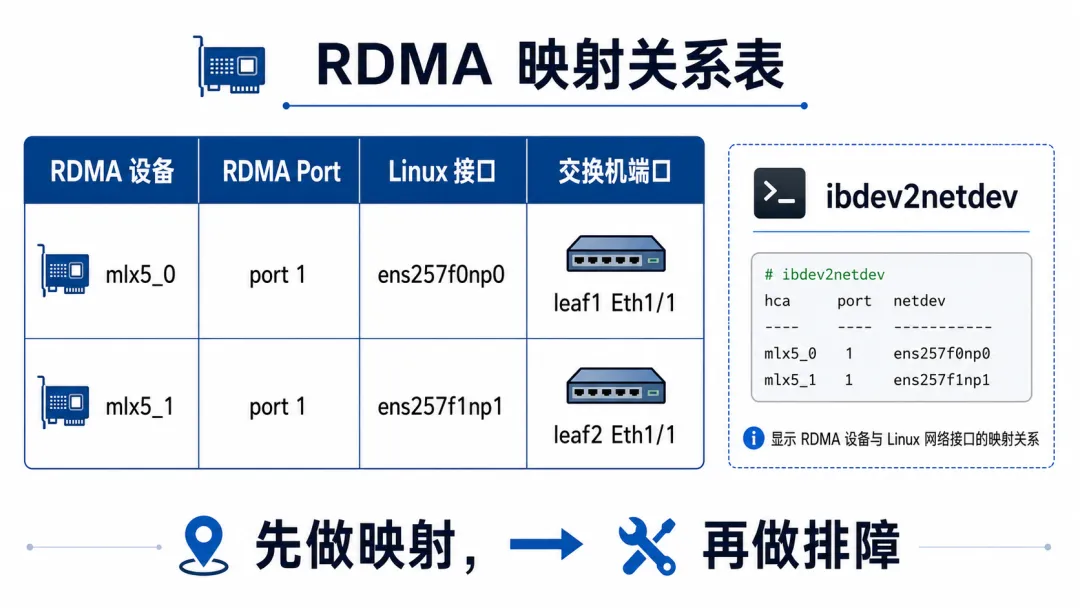
ibdev2netdev
既然有两个名字,最重要的是建立映射关系。
你要知道:
mlx5_0对应哪个 Linux 接口?ens257f0np0对应哪个 RDMA 设备?这个设备是 port 1 还是 port 2?
这根线接到了哪台交换机的哪个端口?
命令是:
ibdev2netdev
你可能会看到类似输出:
mlx5_0 port 1 ==> ens257f0np0 (Up)mlx5_1 port 1 ==> ens257f1np1 (Up)
mlx5_0 port 1 是 RDMA 世界。ens257f0np0 是 Linux 网络世界。Up 是当前接口状态。
有了这层映射,你才能继续往下查:
NCCL 选的是哪个 HCA?
这个 HCA 对应哪个 Linux 接口?
这个 Linux 接口的 IP 是什么?
这个接口接到交换机哪个端口?
交换机上哪个端口有 ECN / PFC / 错误计数?
没有映射关系,排障就会乱。
你看 NCCL 日志里的 mlx5_0。交换机同事问你是哪根线。你去服务器上看 ip a,只看到 ens257f0np0。三边对不上,排障就会卡住。
RDMA 排障第一步,不是跑压测,而是把 mlx5_x、ens/enp、PCIe BDF、交换机端口对齐。
09
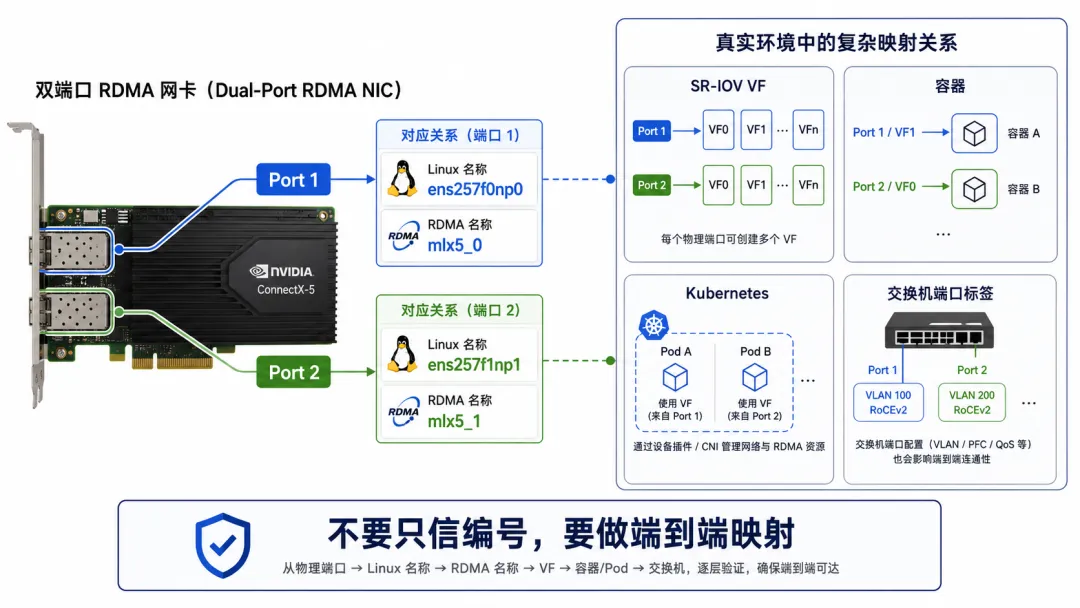
为什么同一张双口网卡,名字还会更多?
如果是双口 RDMA 网卡,事情会更复杂。
一张物理卡,可能有两个物理端口。
Linux 里可能看到:
ens257f0np0ens257f1np1
RDMA 里可能看到:
mlx5_0mlx5_1
也可能一个 RDMA 设备下面有多个 port。不同驱动版本、固件、系统、PCIe 拓扑、SR-IOV 配置下,展示方式可能不完全一样。
如果再叠加 SR-IOV,可能还有 VF。如果在 Kubernetes 里,可能还有容器内设备。如果是 BlueField、DPU、Representor,名字会更多。
所以生产环境里,千万不要只靠“编号顺序”来判断。
不要看到 mlx5_0,就武断认为它一定是第一张卡第一个口。不要看到 ens257f0np0,就认为它一定接了某台交换机。不要换完卡、升级驱动、重启系统后,仍然沿用旧映射。
有些发布说明也会提醒,RDMA 设备名在特定场景下可能变化,工程上应使用更可预测的命名或持久化映射方式。
现场最稳妥的做法是:
用 PCIe BDF 对齐
用 MAC 对齐
用
ibdev2netdev对齐用交换机 LLDP / 端口标签对齐
把服务器槽位、网卡端口、交换机端口写进交付文档
在多卡、多口、SR-IOV、容器环境里,名字只是入口,映射关系才是事实。
10
这件事和 RoCE 排障有什么关系?
RoCE 排障经常要横跨四个地方:
服务器 Linux 接口
RDMA 设备
NCCL / perftest
交换机端口
比如你发现训练慢了,怀疑某个 Rank 的 RDMA 通信有问题。
NCCL 日志里看到:
mlx5_2
你接下来必须知道:
mlx5_2对应哪个ens...?这个
ens...的 IP 是多少?它的 DSCP / PCP / TC 映射是否正确?
它接到交换机哪个端口?
那个端口有没有 ECN marked?
有没有 PFC Pause?
有没有队列水位尖刺?
有没有 no buffer discard?
如果你连 mlx5_2 和 ens... 都对不上,就谈不上后面的因果分析。
很可能会出现这种尴尬:
NCCL 慢的是
mlx5_2你却去查了
ens257f0np0实际问题在
ens257f1np1交换机端口也查错了
最后结论当然会错。
RoCE 排障不是只看服务器,也不是只看交换机,而是把 Rank、HCA、netdev、交换机端口串成一条链。

11
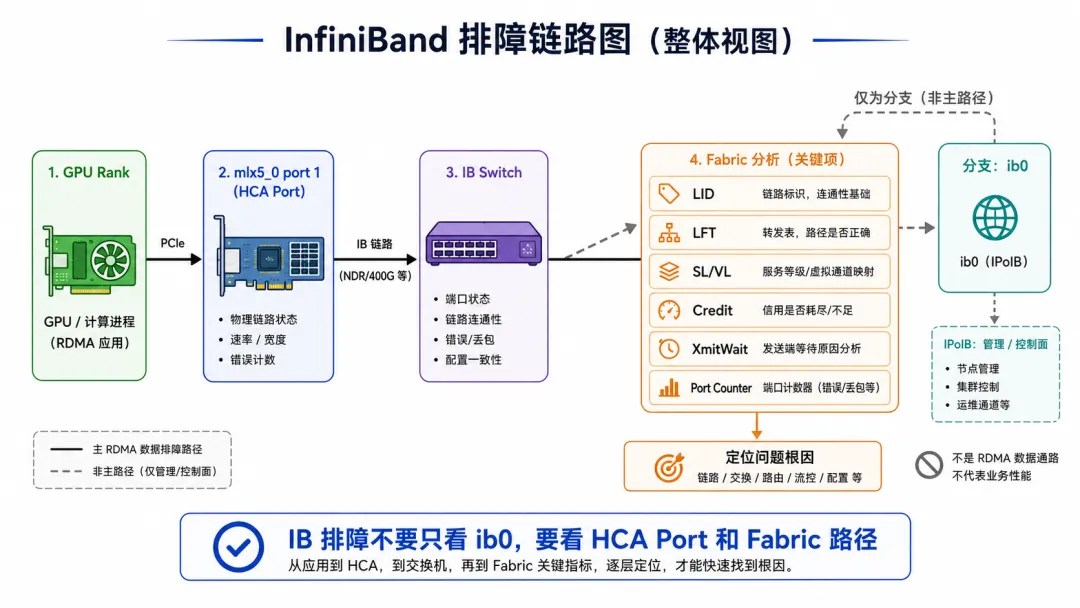
这件事和 InfiniBand 排障有什么关系?
如果是 Native InfiniBand,也一样重要。
只不过你看的指标不同。
RoCE 里你经常看:
ECN
PFC
CNP
DSCP / PCP
TC
Buffer
InfiniBand 里你更常看:
LID
LFT
SL / VL
Credit
XmitWait
Port Counter
SM 状态
P_Key
但你仍然要先知道:
哪个 Rank 对应哪个 HCA?
哪个 HCA 对应哪个 IB Port?
这个 Port 接到哪个 IB Switch?
LID 是多少?
走哪条路径?
哪个端口 XmitWait 高?
哪个端口有 Symbol Error?
如果你只知道 Linux 里有个 ib0,但不知道它背后的 mlx5_0 port 1,排障还是会断。
尤其在训练集群里,慢 Rank 经常不是“单点坏了”那么简单。
它可能是某条 IB 路径等待 Credit。也可能是某个端口错误计数异常。也可能是路由不均衡。也可能是某个 Rail 上流量集中。
所以 IB 排障同样要做映射。
只是映射的终点从 Ethernet 交换机端口,变成了 IB Fabric 路径。
RoCE 看队列和拥塞反馈,IB 看 Credit 和 Fabric 健康;但第一步都是把 Rank 对到 HCA 和端口。
12
该怎么记忆?
凡是 IP、路由、MTU、VLAN、PFC、ECN,先看 Linux netdev 名;
凡是 QP、GID、LID、RDMA Port、NCCL_IB_HCA,先看 RDMA 设备名。
ens / enp / eth / ib0 → Linux 网络接口mlx5_0 / mlx5_1 → RDMA verbs 设备
例如:
GPU0 → NIC0 → mlx5_0 port 1 → ens257f0np0 → Leaf1 Eth1/1GPU1 → NIC1 → mlx5_1 port 1 → ens257f1np1 → Leaf2 Eth1/1
再把这些信息补上:
PCIe BDF
MAC 地址
IP 地址
交换机端口
线缆标签
机柜位置
Rail 编号
NCCL 绑定策略
RDMA 网络不是从命令开始的,是从映射关系开始的。

13
敲黑板
同一块 RDMA 网卡,在 Linux 里为什么会有两个名字?
因为它同时属于两个世界。
在 Linux 网络世界里,它是一个 netdev。所以你看到 ens257f0np0、enp65s0f0np0、eth0、ib0。
在 RDMA verbs 世界里,它是一个 HCA。所以你看到 mlx5_0、mlx5_1、mlx5_2。
这两个名字不是互相替代。而是互相补充。
你做 IP、MTU、VLAN、PFC、ECN,看 Linux 接口名。你做 RDMA、QP、GID、LID、NCCL HCA 绑定,看 RDMA 设备名。
你做训练性能排障,就必须把它们映射起来。
很多现场问题,不是网卡真的坏了。而是人把名字看乱了。
NCCL 绑错。perftest 选错。交换机端口查错。RoCE 队列对错。IB Fabric 路径对错。
最后把一个简单的命名问题,变成了复杂的性能事故。
所以,RDMA 入门第一课,不是先背 PFC、ECN、DCQCN。也不是先背 QP、CQ、MR。
而是先搞清楚:
这张卡在 Linux 里叫什么?
在 RDMA 里叫什么?
它接在哪个交换机端口?
它服务哪张 GPU?
它被 NCCL 选中了没有?
名字对不上,排障一定乱;映射关系对上了,RDMA 问题才有入口。
👉 AI 训练网络全路径拆解 → 私信:AI网络
👉 AI 推理网络全路径拆解 → 私信:推理
👉 AI 算力网络架构系统(真机实验环境) → 私信:系统
👉 AI 算力网络架构专家(真机实验环境) → 私信:专家
👉 AI 网络架构工程指南手册 → 私信:工程指南
👉 日常工作1对1答疑 → 私信:答疑
如果你也在做 AI 集群架构
欢迎关注「算力网络架构手记」
长期拆解真实算力网络问题
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 用Python给自己搭了个私人AI助手,每天省下1小时
- 《Python 从入门到精通》100|高级语法总结:从“会写”走向“写得漂亮”
- 用Python造个自用的文件自动整理工具(UI版)
- 【python3.7.0setup】python3.7.0setup激活教程,零基础轻松上手! 激活安装
- Debian12 Linux每天固定时间自动关机
- Linux 打包压缩实战甲方要日志,我打了一个 zip 发过去,他打开全是乱码
- Python教程(23)turtle库综合案例:绘制太极图
- 少儿编程 ‖ 从Python开始学编程-1
- 学Python只搞Web太单一?结合网络自动化和运维脚本,成为复合型人才
- Linux内核脏克隆漏洞允许本地攻击者获得root权限
