32岁零基础学Python量化 第7周(下) AI量化基础之深层神经网络(预备篇)
- 2026-07-02 16:28:46
深层神经网络知识点预备
本篇内容是下一篇内容的重要知识点预备内容,重点记录了深层神经网络的构建所需要的重要函数模块,为下一篇深层神经网络的构建做准备,下一篇将手动复现深层神经网络实现对猫图的识别。
原理大纲
深层神经网络按如下5大步骤进行:
1.初始化参数
2.前向传播
前向传播0~L-1层(隐藏层):
1.线性传播
2.激活函数(ReLU)
前向传播L层(输出层):
1.线性传播
2.激活函数(Sigmoid)
3.计算成本cost
4.反向传播求各层参数梯度
5.更新参数
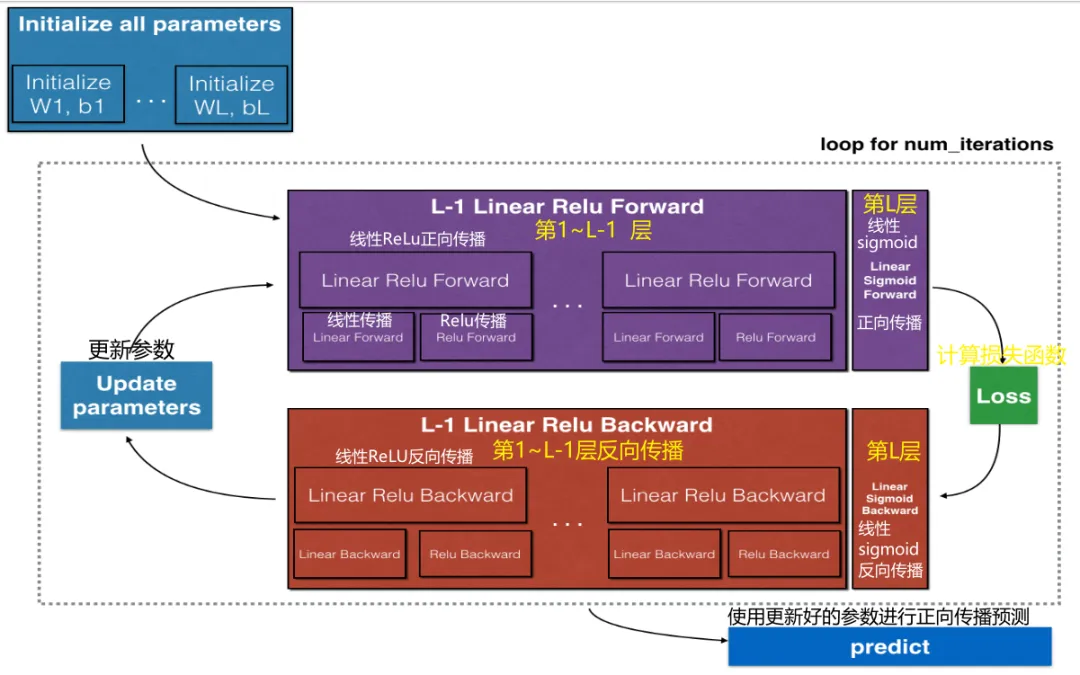
示意图
1.初始化参数
尺寸:
对 L 层神经网络进行参数初始化,特别是矩阵维度的匹配。
由于深层 L 层神经网络包含更多的权重矩阵和偏置向量,其初始化过程比浅层网络要复杂得多。在编写参数初始化函数时,必须确保每一层之间的维度能够正确匹配。
回顾一下, 代表第 层中的神经元(单元)数量。因此,举个例子,假设我们的输入数据 的维度是 (其中包含 209 个样本),那么各层的维度如下表所示:
| W 的形状 (Shape) | b 的形状 (Shape) | 激活值公式 | 激活值 A 的形状 (Shape) | |
|---|---|---|---|---|
| 第 1 层 | ||||
| 第 2 层 | ||||
| 第 L-1 层 | ||||
| 第 L 层 |
关于广播机制 (Broadcasting) 的补充说明:
当我们在 Python 中计算 时,NumPy 会自动执行广播机制。例如,如果 的形状是 ,而 的形状是 ,那么 会在列方向上自动复制 次,使得最终 的形状依然为 。
总结:
在这个表格中,最重要的规律:
1. 权重矩阵 的形状永远是 (当前层神经元数量, 上一层神经元数量),即 。2. 偏置向量 的形状永远是 (当前层神经元数量, 1),即 。
代码:
# GRADED FUNCTION: initialize_parameters_deep
def initialize_parameters_deep(layer_dims):
"""
形参layer_dims: layer dimensions 的缩写,译为层维度,也就是隐藏层每层的节点数(list)。
返回parameters:包含所有参数的字典 "W1", "b1", ..., "WL", "bL":
Wl:第L层的权重矩阵
bl:第L层的偏置矩阵
"""
np.random.seed(3)
parameters = {}
L = len(layer_dims) # 字符串长度,比如layer_dims=[2,3,1],那么L=3)
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l],layer_dims[l-1])*0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l],1))
assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))
assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters2.前向传播
公式
线性传播:
激活函数:
ReLU: .
Sigmoid: .
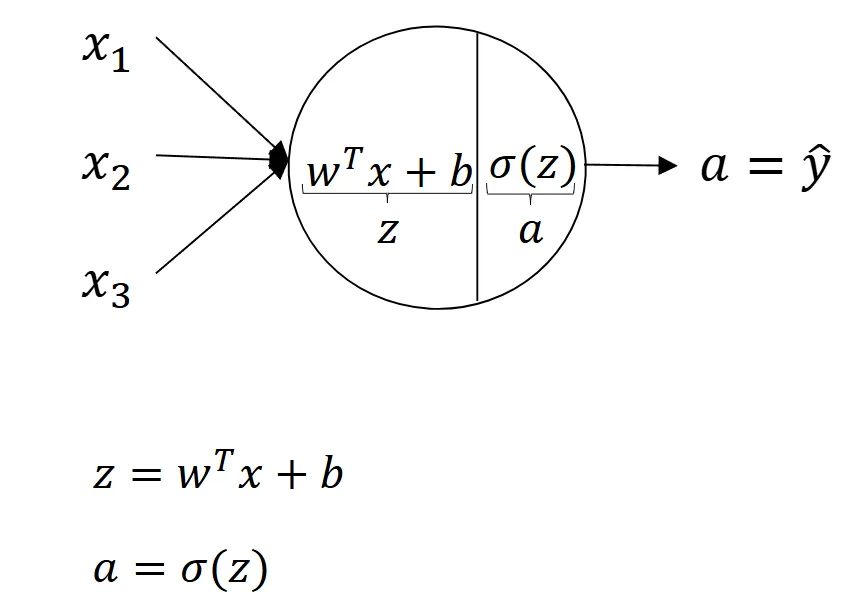
一个神经节点示意图
解析:
因为识猫程序是一个二分类问题,sigmoid区间在0~1之间,可以表示概率分布,而中间层选择ReLU激活函数的原因是中间层(隐藏层)的任务是“提取特征”,我们需要非线性来拟合复杂的数据分布,所以 ReLU (max(0,z))是最佳选择,它的导数恒为1,梯度在反向传播时可以毫无衰减第传递到前面层,其计算成本极低,有利于速度的提升,
(注:ReLU激活函数虽然看着是由直线段组成的,在两个区间甚至局部表现为线性,但整体而言它是绝对的非线性函数,
1.从数学定义角度:线性函数必须同时满足可加性 和齐次性
均不满足
2.从神经网络角度:如果神经网络中的激活函数都是线性的,那么无论你的网络有多少层,最终的输出都会被合并成一个简单的线性方程,这就意味着无论多深的网络,其表达能力都等同于一个单层线性回归模型,正因为ReLU函数在原点处有个‘折角’(即Z=0处的不可导点)打破了这种线性叠加的规律,这种分段非线性的特性使得神经网络能够拟合世界中极其复杂的非线性数据分布)
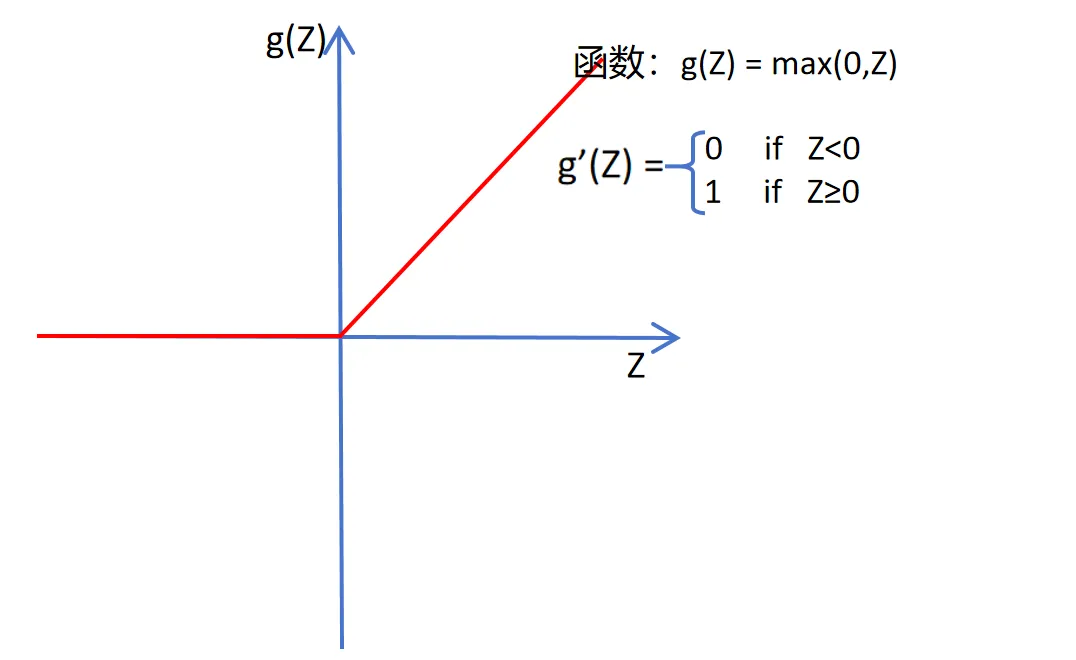
ReLu函数图片
代码:
#线性前向传播部分
def linear_forward(A, W, b):
"""
Implement the linear part of a layer's forward propagation.
Arguments:
A -- 前一层的输出数据
W -- 权重矩阵
b -- 偏置向量
Returns:
Z -- 激活函数的输入
cache(缓存) -- 包含 "A", "W" 和 "b" 的字典; 用于计算反向传播中的梯度
"""
Z = np.dot(W,A)+b
assert(Z.shape == (W.shape[0], A.shape[1]))
cache = (A, W, b)
return Z, cache
#线性激活部分
def linear_activation_forward(A_prev, W, b, activation):
if activation == "sigmoid":
# 输入: "A_prev, W, b". 输出: "A, activation_cache".
Z, linear_cache =linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation == "relu":
# 输入: "A_prev, W, b". 输出: "A, activation_cache".
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
assert (A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
#前向传播整合模块
def L_model_forward(X, parameters):
"""
实现 [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID 计算过程的前向传播
参数:
X - 数据,numpy数组,维度为(输入节点数量,示例数)
parameters - initialize_parameters_deep()的输出
返回:
AL - 最后的激活值
caches - 包含以下内容的缓存列表:
linear_relu_forward()的每个cache(有L-1个,索引为从0到L-2)
linear_sigmoid_forward()的cache(只有一个,索引为L-1)
"""
caches = []
A = X
L = len(parameters) // 2 # 因为parameters包含了W,b,所以长度是L的两倍
for l in range(1, L):
A_prev = A
A, cache = linear_activation_forward(A_prev, parameters['W'+str(l)], parameters['b'+str(l)], activation = 'relu')
caches.append(cache)
AL, cache = linear_activation_forward(A,parameters['W'+str(L)], parameters['b'+str(L)], activation = 'sigmoid')
caches.append(cache)
assert(AL.shape == (1,X.shape[1]))
return AL, caches3.求成本函数cost
公式:
计算交叉熵的成本函数:
解析:
用来衡量预测值与真实值的差距,最终目标是该值尽可能小
代码:
def compute_cost(AL, Y):
"""
参数:
AL -- 预测标签相应的概率向量
Y -- true "label" vector标签的真实值
返回:
cost -- cross-entropy cost 交叉熵成本
"""
m = Y.shape[1]
cost =(-1/m)*np.sum(np.multiply(Y,np.log(AL))+np.multiply(1-Y,np.log(1-AL)))
cost = np.squeeze(cost) #确保cost是我们需要的尺寸
assert(cost.shape == ())
return cost4.反向传播求梯度
公式:
用输入 计算3个输出 值:
解析:
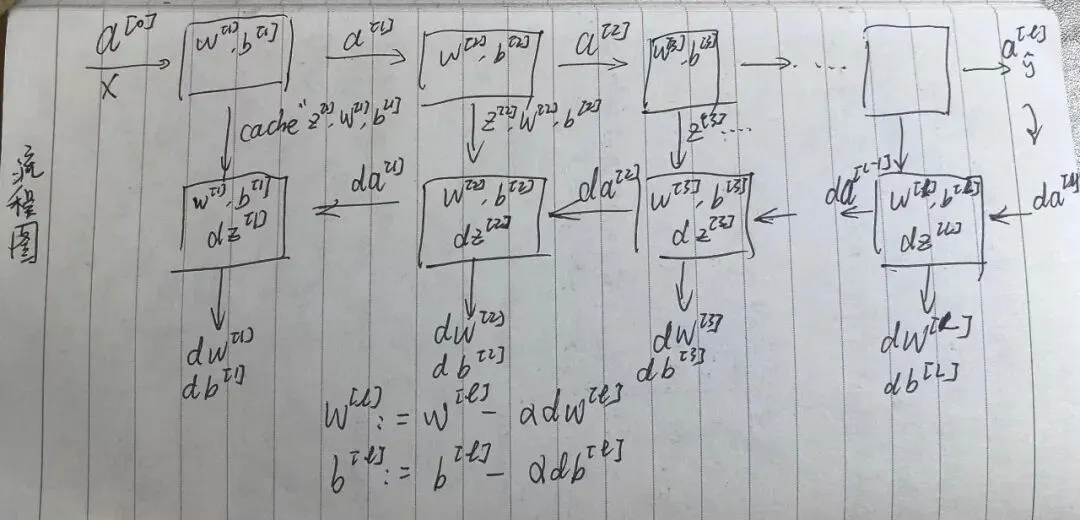
手画的流程示意图,将就看下...
代码
# 1.线性反向传播(由dZ求dW,db,dA_prev)
def linear_backward(dZ, cache):
"""
为单层实现反向传播的线性部分(第l层)
参数:
dZ - 相对于(当前第l层的)线性输出的成本梯度
cache - 来自当前层前向传播的值的元组(A_prev,W,b)
返回:
dA_prev - 相对于激活(前一层l-1)的成本梯度,与A_prev维度相同
dW - 相对于W(当前层l)的成本梯度,与W的维度相同
db - 相对于b(当前层l)的成本梯度,与b维度相同
"""
A_prev, W, b = cache
m = A_prev.shape[1]
dW = np.dot(dZ,A_prev.T)/m
db = np.sum(dZ,axis = 1,keepdims = True)/m
dA_prev = np.dot(W.T,dZ)
assert (dA_prev.shape == A_prev.shape)
assert (dW.shape == W.shape)
assert (db.shape == b.shape)
return dA_prev, dW, db#顺序要和下面一样
# 2.线性激活反向传播(求前一步所需要的dZ,由dA和激活函数的导数求得)
def linear_activation_backward(dA, cache, activation):
"""
实现LINEAR-> ACTIVATION层的后向传播。
参数:
dA - 当前层l的激活后的梯度值
cache - 我们存储的用于有效计算反向传播的值的元组(值为linear_cache,activation_cache)
activation - 要在此层中使用的激活函数名,字符串类型,【"sigmoid" | "relu"】
返回:
dA_prev - 相对于激活(前一层l-1)的成本梯度值,与A_prev维度相同
dW - 相对于W(当前层l)的成本梯度值,与W的维度相同
db - 相对于b(当前层l)的成本梯度值,与b的维度相同
"""
linear_cache, activation_cache = cache
if activation == "relu":
dZ =relu_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
# 反向传播模块整合
def L_model_backward(AL, Y, caches):
"""
实现[LINEAR->RELU] * (L-1) -> LINEAR -> SIGMOID group的反向传播
形参:
AL --概率向量,前向传播的输出(L_model_forward())
Y --真实‘标签’向量(包含0和1 分别对应非猫和猫)
caches -- 缓存列表包含以下内容:
1.前0~L-2层所有的‘relu’前向传播的缓存
2.第L-1层sigmoid前向传播的缓存
返回值(return):
grads -- 包含梯度的字典:
grads["dA" + str(l)] = ...
grads["dW" + str(l)] = ...
grads["db" + str(l)] = ...
"""
grads = {}
L = len(caches) # 层数
m = AL.shape[1] # 样本数量
Y = Y.reshape(AL.shape) # 让Y和AL尺寸一致
# 初始化反向传播:
dAL =-(np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) # cost函数对AL的导数,np.divide()等同于Python中的/运算符的作用
# 利用上面激活后的梯度dAL继续向后传递,计算第L层的梯度,同时会使用到L_model_forward函数中的缓存caches列表中的值
current_caches = caches[L-1] #这里就是第L层的缓存,因为索引问题所以要减1
grads["dA" + str(L)],grads["dW" + str(L)],grads["db" + str(L)] = linear_activation_backward(dAL, current_caches, activation = 'sigmoid')
#利用for循环遍历剩余所有层,调用Linear->ReLU的反向传播函数,将遍历过程中每一层的梯度值缓存至grads字典中。
for l in reversed(range(L - 1)):#range(5)=[0,1,2,3,4],不包括5,相当于[0,5),这里的range(L-1)就是[0,1,2,3,4....,L-2], reversed:使列表颠倒
current_cache = caches[l]
grads["dA" + str(l + 1)] , grads["dW" + str(l + 1)] , grads["db" + str(l + 1)] = linear_activation_backward(grads["dA" + str(l + 2)], current_cache, activation = 'relu')
return grads5.更新参数
公式:
解析:
使用计算出的梯度更新参数,其中 是学习率(learning rate)
代码:
def update_parameters(parameters, grads, learning_rate):
"""
使用梯度更新参数
形参:
parameters -- 包含参数的字典
grads -- 包含梯度的字典,是反向传播的输出值
返回值:
parameters -- 更新后的参数字典:
parameters["W" + str(l)] = ...
parameters["b" + str(l)] = ...
"""
L = len(parameters) // 2 # 计算神经网络的层数
# 使用for循环更新每层参数
for l in range(L):
parameters["W" + str(l+1)] -= learning_rate*grads['dW'+str(l+1)]
parameters["b" + str(l+1)] -= learning_rate*grads['db'+str(l+1)]
return parameters小结
本篇内容是作为下一篇内容的准备内容,是深层神经网络的地基,对于本篇各位同学和前辈有什么心得或建议欢迎留言一起交流。另外最近天气太热了,大家伙开空调注意别受凉感冒了。谢谢看完,晚安~~
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python Web开发:从调用API到开发API,思维大转变!
- 我计算机二级Python报完名才发现大家都说通过率很低有没有高效备考的野路子?
- 我愿称之为这是 Python最伟大的学习网站:
- 这是我见过含金量最高的Python自学路径了!
- 接下来两个月--跟着菜菜学python
- httpimport:突破本地限制,让Python直接从远程加载模块,提升开发效率
- NOAI中国站金奖选手揭秘:Python与机器学习备考路径,附真题资料包
- Manim,一个直观的python项目!
- Python学习【198】:Presto 单机部署与使用指南
- Python顶级模块合集!
