同一个 AI 编程工具,写 Python 很顺,换成冷门语言就露馅。论文里的 MoonBit 和 Gleam,在最难测试里一度只有 0% 到 1% 的 pass@1。问题不是语言不行,而是模型可能根本没真正学过它。
这里先划清边界。原论文测的是大模型代码生成,不是 Claude Code、Cursor 或某个 Agent 产品的官方评测。
但它对开发者很有用。因为你平时让 AI 写的,未必都是 Python、JavaScript 这种高资源语言。也可能是公司内部 DSL、冷门 SDK、新框架,或者文档刚发布两个月的私有 API。
真正要看的不是模型总榜,而是你的技术栈有没有被模型见过、练过、测过。
1先看它测了什么
这篇论文叫《No Resource, No Benchmarks, No Problem?Evaluating and Improving LLMs for Code Generation in No-Resource Languages》。原文提到,它已在 arXiv 发布,并标注被 IEEE Transactions on Software Engineering 接收。
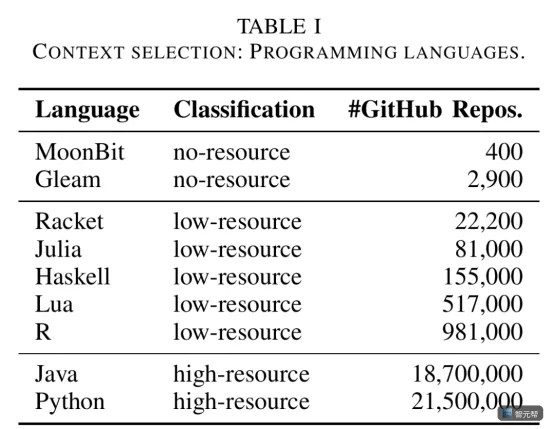
研究对象不是 Python、Java 这种成熟语言,而是 MoonBit 和 Gleam。论文把它们称为 no-resource programming languages。
no-resource 可以先理解成「公开语料很少的编程语言」。不是语言能力差,而是公开代码、教程、问答、项目样例还不够多。模型预训练时,很可能没充分见过。
AI 写代码不是凭空理解一门语言。它会受训练语料影响。Python、JavaScript 到处都是,模型见得多,写起来就稳。冷门语言样例少,模型可能连语法边界都没摸熟。
对开发者来说,这就是第一个检查项:你让 AI 写的东西,是互联网高频语料,还是团队内部才有人用的东西?
2测试台怎么搭
论文构建了三个代码生成 benchmark:HumanEval、MBPP 和 McEval-Hard。
benchmark 可以先理解成「统一考卷」。同一类题发给不同模型、不同语言,再看一次生成能不能通过测试。
评价指标主要是 pass@1。
pass@1 的意思很简单:模型只有一次机会。一次写出的代码能通过测试,就算成功;否则失败。
论文对比了三类语言。
高资源语言:Python、Java。
低资源语言:R、Lua、Haskell、Julia、Racket。
无资源语言:MoonBit、Gleam。
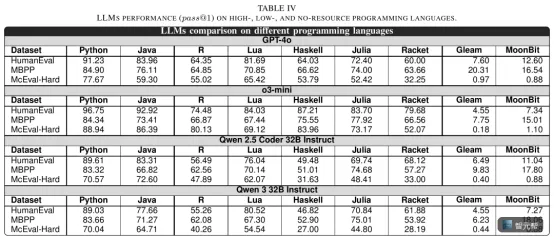
参与模型包括 GPT-4o、o3-mini、Qwen 2.5 Coder、Qwen 3 等。HumanEval 和 MBPP 被翻译到 MoonBit、Gleam;McEval-Hard 则基于更难的函数级任务构建。
这不是随便问模型几道题,而是把语言资源差异拉到同一张考卷上。
看到这里,团队选型已经有了一个方向:不要只问「这个模型会不会写代码」,要问「它在我的语言、框架、测试方式里会不会写代码」。
3第一组数字很难看
最刺眼的是 McEval-Hard。
原文写到,高资源语言的 pass@1 大约在 59% 到 89% 之间,低资源语言大约在 27% 到 84% 之间。
到了 MoonBit、Gleam 这类无资源语言,只有 0% 到 1%。
这不是小幅掉点。
这是能力断崖。
论文还指出,无资源语言在多个模型和 benchmark 上的表现通常处于 0% 到 20% 之间,平均约 9%。
对普通用户来说,这组数字解释了一个常见错觉:你看到 AI 写主流语言很厉害,不代表它写所有技术栈都厉害。
对开发者来说,这意味着冷门技术栈上最危险的不是「效果差一点」,而是你以为模型懂,模型其实在猜。
如果它猜的是变量名,最多跑不通。
如果它猜的是 SDK 行为、权限边界、错误处理,就可能把问题埋进生产代码。
4真正翻车点不是算法题
更关键的是失败类型。
原文提到,在 Gleam 和 MoonBit 上,大量失败来自语法错误。也就是说,模型经常连合法代码都生成不出来。
这一步值得停一下。
如果模型输在算法思路,那说明它「会语言,但题没解好」。如果输在语法,那说明它可能连语言规则都没站稳。
换句话说,这不是 MoonBit 或 Gleam 不行。更准确的说法是:模型还没有被足够教过这些语言。
这和你在公司里遇到的内部框架很像。
文档写了 30 页,接口也很清楚,但公开 GitHub 上没有项目,Stack Overflow 上没有问答,中文博客也没人写。你把它丢给 AI,模型可能会把相似框架的写法拼过来。
表面看像答案。
一跑测试,全是错。
所以这里不能得出「冷门语言不适合 AI」这个结论,只能得出更窄的结论:没有足够代码、文档、测试和反馈,模型很难稳定支持冷门语言。
5塞文档有用,但不够
论文也测试了两种常见补救办法:few-shot 和 RAG。
few-shot,就是在 prompt 里放几个代码示例,让模型照着写。
RAG,可以理解成「先从文档里检索相关片段,再塞进上下文」。很多团队做内部知识库、代码助手,走的就是这条路。
两种方法都有提升。原文提到,在 MoonBit 的 12 组比较里,few-shot 有 8 组优于 RAG。作者推测,面对陌生语言时,模型从代码示例里抓语法,往往比从文档片段里理解规则更直接。
这点对做 Agent 工作流的人很实用。
如果你的技术栈很冷,别只给模型塞一段抽象文档。更应该给它可运行的最小样例:函数怎么写、错误怎么处理、测试怎么跑、常见输入输出长什么样。
但这也不是万能药。
临时把几段示例塞进 prompt,只能补局部语法。它不能让模型真正掌握整门语言,也不能保证复杂任务里不串用别的语言习惯。
到这一步,结论收窄了:RAG 和 few-shot 适合救急,不适合把一个冷门技术栈直接变成可靠生产能力。
6真正有效的是系统性训练
论文里更明显的提升,来自继续预训练。
继续预训练可以理解成:不是让模型临时查资料,而是继续用某门语言的代码和官方文档训练它。
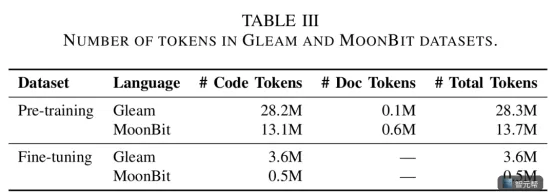
原文给出的 MoonBit 数据规模是约 1310 万 code tokens,加 60 万 documentation tokens。总计约 1370 万 tokens。相比之下,可用于 fine-tuning 的 MoonBit 数据约 50 万 tokens。
token 可以先理解成模型读文本时的基本计量单位。代码、注释、文档都会被切成 token。数量越大,不代表一定越好,但至少说明模型有更多机会反复见到语言结构。
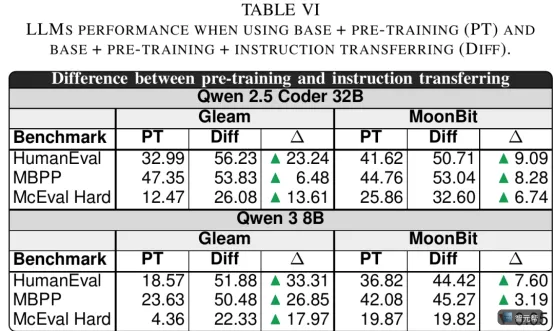
继续预训练之后,Qwen 2.5 Coder 32B Base 在 MoonBit 上的 pass@1 达到:
HumanEval:41.62%。
MBPP:44.76%。
McEval-Hard:25.86%。
这组数字不是说 MoonBit 已经超过主流语言。
它真正说明的是:新语言并不只能等大模型自然学会。只要有代码、文档、测试任务和训练路线,模型能力可以被主动拉上来。
对开发者来说,这意味着 AI 友好的技术栈不是玄学。它需要基础设施:公开样例、官方文档、可运行测试、错误反馈、benchmark。
7还要会听懂开发者
继续预训练解决的是「懂语言」。
但真实 AI 编程助手还要解决另一个问题:听懂人。
你不会只让它补一个函数。你还会说:解释这个类型错误、重构这段逻辑、补测试、按反馈修改实现、别动某个目录。
所以论文进一步用了 instruction transferring。
instruction transferring 可以理解成「把指令跟随能力迁移给已经学过这门语言的模型」。先让 base model 学会 MoonBit,再把 instruct model 那种听指令、跟对话的能力迁回来。
8结果是论文中最强的一组 MoonBit 数字:
HumanEval:50.71%。
MBPP:53.04%。
McEval-Hard:32.60%。
尤其是 McEval-Hard,从零样本接近 0,提升到 32.60%。
这对 Claude Code、Cursor、API Agent 这类场景的启发很直接。真正能干活的 AI 编程助手,不只是会吐代码。它还要懂项目约束、能按测试修正、能听懂「不要改这个文件」这类人话。
如果你只补文档,不补测试和任务反馈,它最多像一个会查资料的助手。
如果你连样例和 benchmark 都没有,它可能只是一个很自信的猜测器。
9开发者该怎么用这个结论
如果你正在判断 Claude Code、Cursor 或自己的 Agent 能不能接某个冷门技术栈,不要只看模型总榜。
先问这 5 个问题。
公开代码够不够多:GitHub 上有没有真实项目,而不是只有语法介绍。
官方文档能不能被模型消化:有没有最小示例、错误示例、迁移指南、API 边界。
有没有可运行测试:没有测试,模型写得像不像都很难判断。
错误反馈是否清楚:编译器、类型系统、lint、日志越明确,AI 越容易改。
有没有小型 benchmark:哪怕只是团队内部 20 道常见任务,也比凭感觉判断可靠。
这就是这篇论文最值得转给团队看的地方。
AI 时代选技术栈,除了性能、生态、类型系统和工具链,还要多看一项:模型是否容易学会它。
如果你的语言或框架很新,那不是不能用 AI。只是别指望大模型天然会。
更稳的路线是:给它代码样例,给它官方文档,给它可运行测试,给它一套能暴露错误的任务集。
个人尝鲜,可以先用 few-shot 加测试跑小任务。
团队落地,至少先做一套内部 benchmark,再决定能不能把它放进生产流程。
如果只是想低成本验证 Claude Code、Cursor 或 API Agent 在冷门技术栈上的表现,可以