大家好,我是木木。
今天给大家分享一个成熟的数据分析的 Python 库,pandas。
pandas
pandas 是 Python 数据分析领域最常见的基础库之一,负责把表格数据、时间序列、清洗转换、聚合统计这些日常工作压到一个统一的 DataFrame 模型里。它不是最新鲜的选择,却仍然是很多数据脚本、BI 辅助流程、机器学习特征准备的共同语言。对团队来说,pandas 的价值不只在 API 丰富,更在于生态、文档和人员经验都非常稳定。
项目地址:https://github.com/pandas-dev/pandas
官方文档:https://pandas.pydata.org/docs/
三大特点
接口稳定
DataFrame、Series、groupby、merge、pivot 这些接口长期稳定,协作成本低。
清洗顺手
缺失值、类型转换、时间序列和文本列处理都能在一个链路里完成。
生态扎实
Jupyter、NumPy、Matplotlib、scikit-learn 等工具都能自然衔接。
最佳实践
安装方式:pip install pandas。如果是数据科学环境,也可以通过 Anaconda、uv、poetry 等工具固定版本。
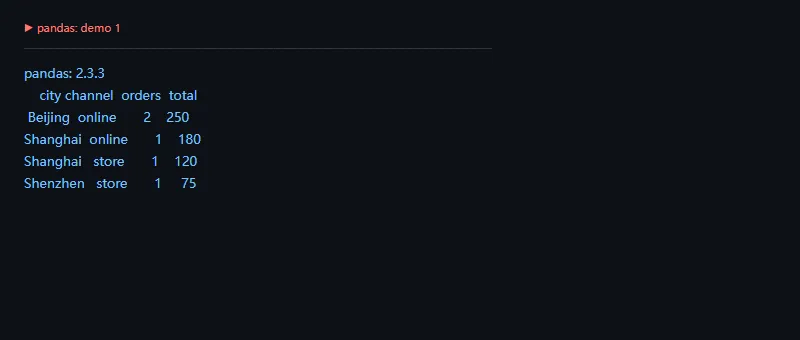
第一段代码解决的问题是:把原始订单按城市和渠道聚合,得到每组订单数和销售额。
importpandasaspdsales=pd.DataFrame({"city":["Shanghai","Beijing","Shanghai","Shenzhen","Beijing"],"channel":["store","online","online","store","online"],"amount":[120,90,180,75,160],})summary=(sales.groupby(["city","channel"],as_index=False).agg(orders=("amount","size"),total=("amount","sum")).sort_values(["city","channel"]))print("pandas:",pd.__version__)print(summary.to_string(index=False))
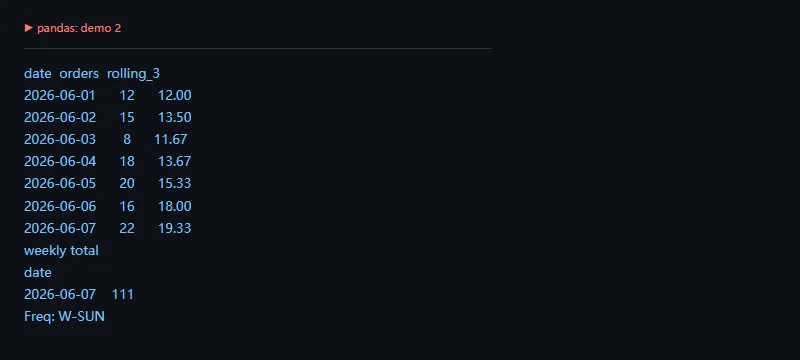
第二段代码解决的问题是:处理日期列,并用滚动窗口观察最近 3 天的订单走势。
importpandasaspddaily=pd.DataFrame({"date":pd.date_range("2026-06-01",periods=7,freq="D"),"orders":[12,15,8,18,20,16,22],})daily["rolling_3"]=daily["orders"].rolling(3,min_periods=1).mean().round(2)weekly=daily.resample("W-SUN",on="date")["orders"].sum()print(daily[["date","orders","rolling_3"]].to_string(index=False))print("weekly total")print(weekly.to_string())
环境与版本信息
本文示例使用 Python 3.11.0、pandas 2.3.3。示例数据是小样本;生产场景要关注内存占用、列类型和中间 DataFrame 的复制成本。
高级功能
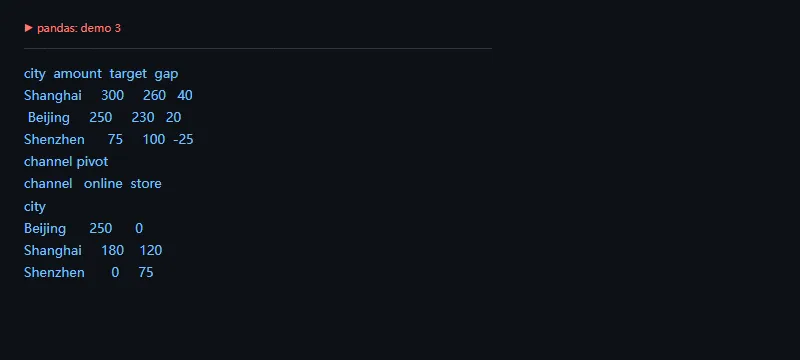
pandas 的高级能力不一定是“更复杂的函数”,而是把多个常用操作组合得清楚:先聚合,再合并目标,再做透视,最后给业务方一个可核对的表。
importpandasaspdsales=pd.DataFrame({"city":["Shanghai","Beijing","Shanghai","Shenzhen","Beijing"],"channel":["store","online","online","store","online"],"amount":[120,90,180,75,160],})targets=pd.DataFrame({"city":["Shanghai","Beijing","Shenzhen"],"target":[260,230,100]})city=sales.groupby("city",as_index=False)["amount"].sum().merge(targets,on="city")city["gap"]=city["amount"]-city["target"]pivot=sales.pivot_table(index="city",columns="channel",values="amount",aggfunc="sum",fill_value=0)print(city.sort_values("gap",ascending=False).to_string(index=False))print("channel pivot")print(pivot.to_string())
适用场景
适合中小规模表格数据分析、CSV/Excel 清洗、报表前处理、特征工程原型、一次性排查脚本。
不适用场景
不适合单机内存放不下的数据,也不适合需要持续流处理、强并发服务或严格事务语义的场景。
上线检查
- 固定 pandas 和 numpy 版本。2. 对关键结果保留样例断言。3. 明确日期时区和缺失值策略。4. 数据量增长后评估 DuckDB、Polars、Spark 或数据库下推。
总结
pandas 的优势是成熟和通用。只要把数据规模、类型和中间结果控制好,它仍然是 Python 数据工作的第一把稳刀。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
