基于Linux和 R 的数据分析,欢迎进群
- 2026-07-16 03:29:58
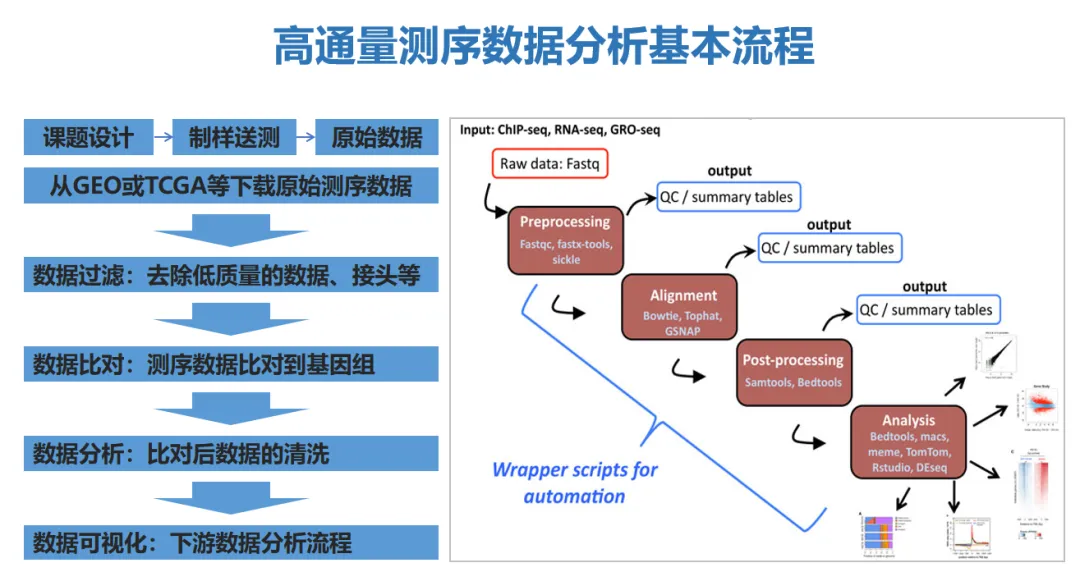
工欲善其事,必先利其器!①对于简单的在线平台,平时所用的电脑就都能满足要求。②如果已经学习 R,处理芯片数据、二代测序数据和单细胞测序数据,一般来说肯定是配置越高越好,但也要综合考虑,而且相同价位下台式机优于笔记本。③如果是专门做大数据挖掘,数据级别更加庞大,所用技能更多,比如Linux和Python,就要用服务器了。

说来很早就想做Linux的教程,但都由于时间等原因半途而废。树高千尺,其根必深。对于部分生信分析的小伙伴来说,掌握Linux的操作还是很有必要的。如果你有这方面的需求,欢迎扫码进群交流,或者后台留言进群。大家一起学习,共同成长。
####----向量Vector是一维数据----####a <- c(1, 2, 5, 3, 6, -2, 4) #数值型,直接输入,不用双引号b <- c("one", "two", "three", "ten") #字符型,有双引号c <- c(TRUE, TRUE, FALSE, TRUE, FALSE) #逻辑型,判断真假用的,属于逻辑判断## 只有一个元素的向量,叫做标量,用于保存常量,很少用到。d <- -3f <-"five"g <- TRUE## 用方括号给定位置,从而访问向量中的元素a <- c(1, 2, 5, 3, 6, -2, 4) #数值型向量a中有7个元素a[3] #访问一个元素a[c(1, 3, 5)] #访问不连续的元素a[c(2:5)] #访问连续的元素a <-c(1:20) #冒号用处大,可用于生成连续的数值变量
矩阵(Matrix)是二维数据,通过函数matrix ()创建。一个矩阵可以有多个元素,元素之间可以数据类型不同,但是一个元素只有一种类型,数值型、字符型和逻辑型均可。
#### ----矩阵Matrix是二维数据----###### 一个矩阵可以有多个元素,元素之间可以数据类型不同,但是一个元素只有一种类型## matrix的一般使用格式:Matrix <- matrix(vector, nrow = number_of_rows, ncol = number_of_columns,byrow = logical_value,dimnames = list(char_vector_rownames, char_vector_colnames))## vector指矩阵的向量元素,nrow和ncol指定行和列的维数## dimnames包含可选的、以字符型向量表示的行名和列名## byrow表明矩阵是按行填充(byrow=TRUE)还是按列填充(byrow=FALSE)## 举例子Matrix1<-matrix(1:20, nrow = 5, ncol = 4) #创建一个5x4的简单矩阵vector2 <- c(1,26,24,68,12, 100) #创建一个数值型向量rnames <- c("R1", "R2", "R3") #行的命名cnames <- c("C1", "C2") #列的命名Matrix2 <- matrix(vector2, nrow = 3, ncol = 2,byrow = TRUE,dimnames = list(rnames,cnames)) #按行填充的3x2矩阵Matrix3 <- matrix(vector2, nrow = 3, ncol = 2,byrow = FALSE,dimnames = list(rnames,cnames)) #按列填充的3x2矩阵## 同样,用下标和方括号可以给定位置,从而访问向量中的元素x<-matrix(1:20, nrow = 5) #创建一个名称为“x"的5x4简单矩阵x #展示x矩阵的数据x[2,] #访问x矩阵的第2行x[,2] #访问x矩阵的第2列x[2,2] #访问x矩阵的第2行,第2列x[1,c(2,3)] #访问第1行的第2列和第3列
####----数组Array是多维数据(二维及其以上)---###### array的一般使用格式:Array <- array (vector, dimensions, dimnames)## vector包含数组中的数据,dimensions是一个数值型变量,给出各个维度下标的最大值## dimnames是可选的、各维度标签的列表## 数组与矩阵类似,只是处理的行、列数增多而已## 举例子dim1 <- c("A1", "A2", "A3", "A4")dim2 <- c("b1", "b2", "b3")dim3 <- c("C1", "C2")y <- array(1:36, c(4,3,2),dimnames = list(dim1,dim2,dim3)) #创建数组y #展示数组的数据## 跟矩阵一样,可以用下标和方括号给定位置,访问向量中的元素
数据框(Dataframe)是在R中最常处理的数据结构。数据框可以处理不同列、不同数据结构(数值型、字符型等)的数据,与我们通常在SAS、SPSS和Stata中看到的数据类似。数据框通过函数data.frame ()来创建。
####----数据框Dataframe处理不同类型数据--###### data.frame的一般使用格式:Dataframe <- data.frame(col1,col2,col3,...)## 列向量col1、col2、col3等可为任何类型(如字符型、逻辑性和数字型等)## 每一列的名称可以用函数names指定## 数据框每一列的数据必须唯一,但是可以将多个模式的不同列放到一起组成数据框## 举例子patientID <- c(1,2,3,4)age <- c(15,34,28,52)diabetes <- c("Type1","Type2","Type1","Type1")status <- c("Poor", "Improved","Excellent","Poor")z <- data.frame(patientID, age, diabetes, status) #创建数据框z #展示数据框## 数据框的数据如何访问?可以用下标的方法,但是很繁琐,不推荐## 推荐直接指明列名z$age #直接范文z数据框的age变量
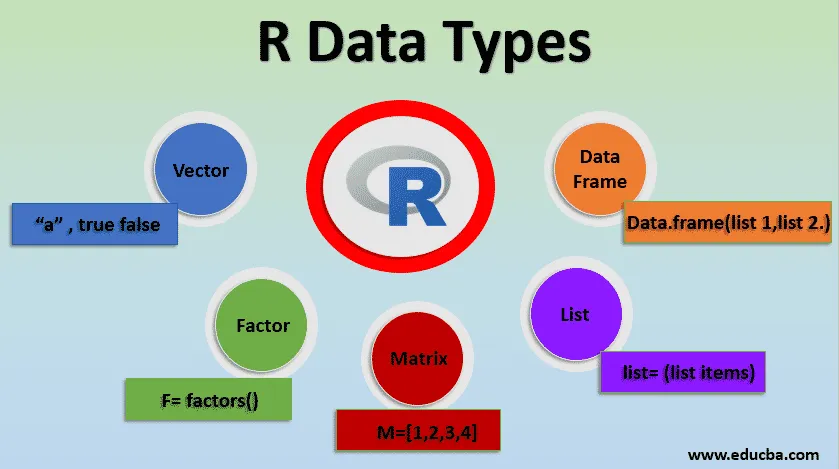
以上关于向量,矩阵、数组和数据框的内容,相对来说比较容易,能够应对数据比较少的情况,对于GEO芯片或者二代测序的高通量数据,上述数据类型就极不方便。因此,我们还需要掌握更高级的数据类型处理函数,比如因子(Factor)和列表(List)。
####----因子Factor处理不同变量--###### 函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[1...k]## 用一个由字符串组成的内部向量将映射到这些整数上## 对于字符型向量,因子的水平默认依字母顺序创建,也可以通过指定levels覆盖默认排序## 数值型变量可以用levels和labels来编码成因子## 举例子patientID <- c(1,2,3,4)age <- c(15,34,28,52)diabetes <- c("Type1","Type2","Type1","Type1")status <- c("Poor", "Improved","Excellent","Poor") #以向量形式创建数据diabetes <- factor(status, ordered = TRUE)patientdata <-data.frame(patientID, age, diabetes, status)str(patientdata) #显示数据的结构summary(patientdata) #显示数据的统计概要
列表(List)是R语言中最复杂的数据类型,它包含不同类型的元素,可能是若干向量、矩阵、数据框,甚至其他列表的组合。使用list ()函数创建列表。对象可以是上述任何结构。
####----列表List处理任何数据--###### 列表list()是最为复杂的数据类型,可以整合各种数据类型到单个对象下。## list的一般使用格式:List <-list(object1, object2, object3, ...)## 或者List2 <- list(name1=object1, name2=object2,...)## 举例子g <- "Mango List"h <- c(25, 26, 18, 39)j <- matrix(1:10, nrow = 5)k <- c ("one", "two", "three")list1 <- list(title=g, ages=h, j, k) #创建列表list1 #显示列表$title #显示列表的成分$ages[[3]]list1[[2]]list1[["ages"]]
处理数据对象的函数


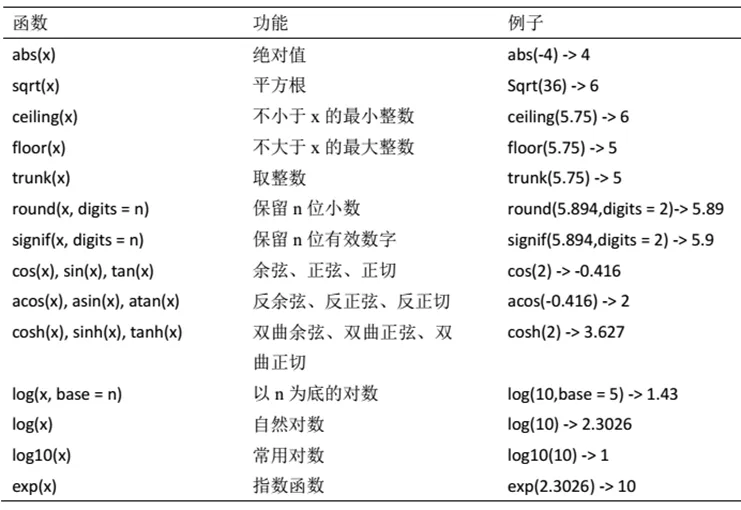
数学函数
统计函数

图形函数
plot()是R中为对象作图的一个泛型函数(输出根据绘制对象的类型) 。
par( )是修改图形参数的函数。
用于指定符号和线条类型的函数
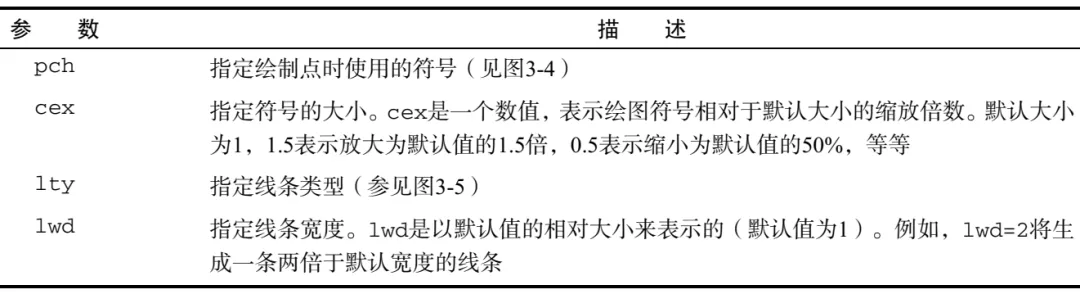
pch指定的绘图符号类型
Ity指定的线条类型

用于指定颜色的函数

用于指定文本大小、字体的函数


坐标轴选项

算术运算符

逻辑运算符

日期格式

类型转换函数


