Python | scikit-learn数据建模
- 2026-06-28 11:00:39
功能介绍
scikit-learn,又写作sklearn,是一个开源的基于Python语言的机器学习工具包。它通过NumPy、SciPy和Matplotlib等Python数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
数据分析的算法
为了研究Y与X之间的函数关系,对X、Y进行多次观察,得到一组样本数据:
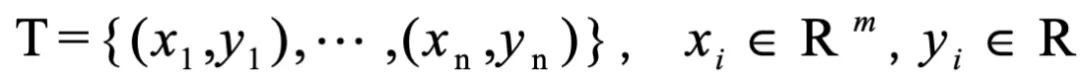
所谓建立模型,就是根据样本数据集T,建立从集合A到集合D上,x与y的一种函数关系:
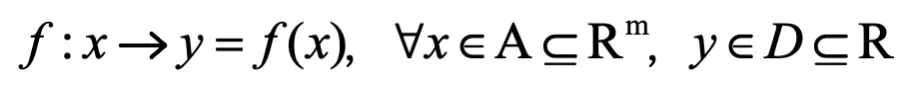
在数学建模中,自变量x 与因变量 y 之间的关系主要分2种:
1.精确关系:x与y之间有精确的表达式
2.相关关系:给定x值时,y的值不能完全确定,只能通过一定的概率分布来描述
所谓算法,就是模型建立后,通过样本数据集T,从数学推导上,寻找一种优化方法,确立模型中的参数,使模型中变量之间的关系,尽可能接近真实的函数关系,即:使损失(误差)最小。
sklearn库的常用模块
Ø分类(Classification):logistic回归、支持向量机(SVM)、神经网络(ANN)、k-nearest neighbors(k近邻)
Ø回归(Regression):线性回归、ridge regression(岭回归)、Lasso(拉索)、主成分分析(PCA)、神经网络
Ø聚类(Clustering):k-Means(k-均值)、DBSCAN(密度)
Ø模型选择及评估:选择参数和模型
Ø预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction
加载datasets模块中的数据集

from sklearn import datasets
b = datasets.load_boston() # 加载boston数据
print(b.keys())
# dict_keys(['data','target','feature_names','DESCR','filename'])
X_data = b['data'] # 二维矩阵数据:(13个指标,506次观察)
Y_target = b['target'] # 取出数据集的标签:506次观察平均房价数据
feature_names = b['feature_names'] # 取出数据集的特征名,13个指标名称
数据标准化的种类
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。常用的变换方法有下面3种:
离差标准化(Min-maxnormalization,min-max标准化):
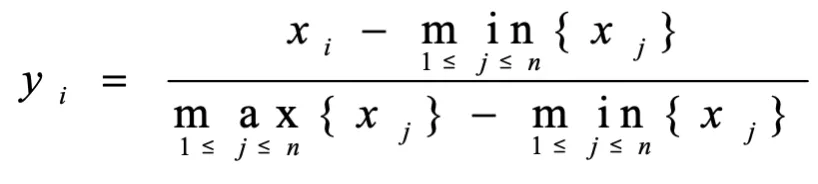
标准差标准化(zero-meannormalization,z-score):
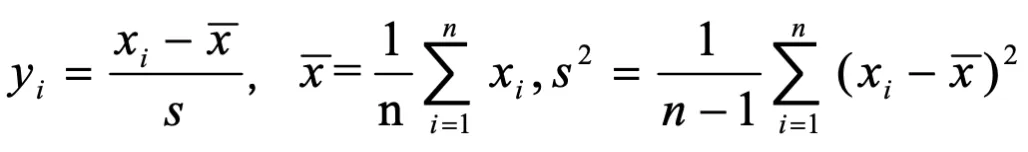
向量归一化(Scaling to unit length):将向量的长度归一:
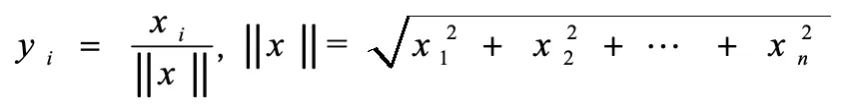
sklearn数据预处理:数据标准化、降维

from sklearn.preprocessing import MinMaxScaler
Scaler = MinMaxScaler().fit(x_train) # 生成规则
x_trainScaler = Scaler.transform(x_train) # 将规则应用于训练集
x_testScaler = Scaler.transform(x_test) # 将规则应用于测试集
将数据集划分为训练集和测试集
在数据分析过程中,为了保证模型在实际系统中能够起到预期作用,一般需要将样本分成独立的三部分:
训练集(train set):用于估计模型。
验证集(validation set):用于确定网络结构或者控制模型复杂程度的参数。
测试集(test set):用于检验最优的模型的性能。
sklearn的model_selection模块提供了train_test_split函数,能够对数据集进行拆分,其使用格式为:sklearn.model_selection.train_test_split(*arrays, **options)

from sklearn import datasets
from sklearn.model_selection import train_test_split
breast = datasets.load_breast_cancer()
x_data = breast['data']
y_target = breast['target']
x_train,x_test,y_train,y_test=train_test_split(x_data,y_target,test_size=0.2,random_state=8)
模型评估:sklearn.metrics常用库
sklearn.metrics模块包含了常用的评价指标。
1.分类评估指标
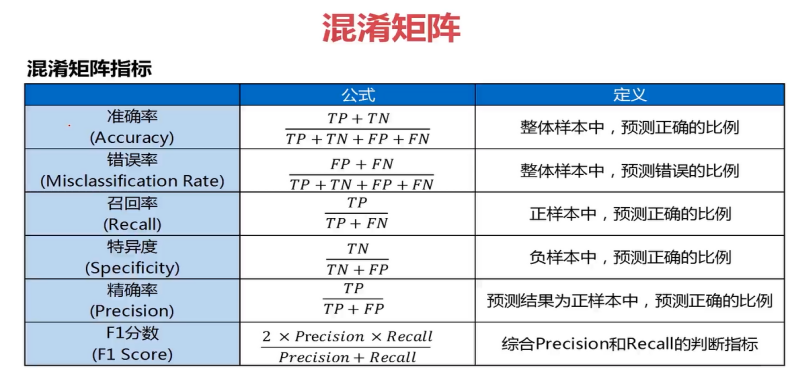
fromsklearn.metrics import roc_curve,roc_auc_score,auc,accuracy_scorefrom sklearn.metrics import f1_score,classification_reportfrom sklearn.metrics import confusion_matrixfrom sklearn.metrics import precision_score,recall_score,average_precision_score
1)accuracy_score(y_true,y_pre):分类预测正确率= 预测正确个数 / 预测总数
2)auc(x,y,reorder=False):ROC曲线下的面积;较大的AUC代表了较好的performance。
3)confusion_matrix(y_true,y_pred,labels=None,sample_weight=None):通过计算混淆矩阵来评估分类的准确性,返回混淆矩阵
2.回归评估指标
fromsklearn.metrics import mean_squared_error,median_absolute_errorfrom sklearn.metrics import r2_scorefrom sklearn.metrics import explained_variance_score,mean_absolute_error
4)mean_squared_error(y_true, y_pred, multioutput='uniform_average'):均方差;
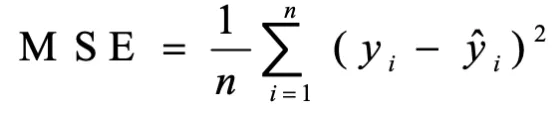
5)r2_score(y_true,y_pred, multioutput='uniform_average'):R平方值;
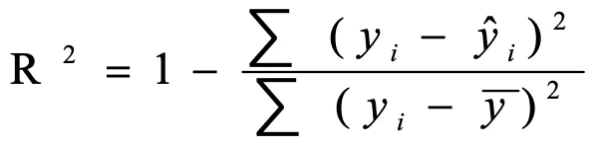
总结:利用sklearn进行数据建模的步骤
(1)读取数据:加载sklearn下的数据集,或通过别的方法读取数据;
from sklearn import datasets
(2)数据预处理,包括数据标准化、数据降维;
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.decomposition import PCA
(3)将数据划分为训练集、测试集;
from sklearn.model_selection import train_test_split
(4)选择一种适当的模型,进行建模;
from sklearn.linear_model import LinearRegression # 多元线性回归
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.neural_network import MLPClassifier # 神经网络多分类
from sklearn.neural_network import MLPRegressor # 神经网络非线性回归
from sklearn.svm import SVC, SVR # 支持向量机分类, 回归
from sklearn.cluster import Kmeans, DBSCAN # k-means聚类,密度聚类
(5)模型评估:fromsklearn importmetrics
数据建模之线性回归
数据建模之logistic回归
数据建模之神经网络
数据建模之支持向量机
支持向量机是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器;支持向量机由于使用核技巧,使它称为实质上的非线性分类器。
支持向量机的学习策略是间隔最大化,它的学习算法是求解凸二次规划的最优化算法。现已被广泛地应用于文本分类、图像处理、语音识别、时间序列预测和函数估计等领域。
sklearn中SVM的算法库分为两类,一类是分类,包括SVC、NuSVC、LinearSVC3个类。另一类是回归,包括SVR、NuSVR、LinearSVR 3个类。相关的类都包裹在sklearn.svm模块之中。
分类函数SVC()
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0,
shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None,
verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
1)C:C-SVC的惩罚参数,默认值是1.0;C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强;
2)kernel:核函数,默认是rbf,可以是‘linear’(线性核), ‘poly’(多项式), ‘rbf’(高斯核), ‘sigmoid’(逻辑斯蒂), ‘precomputed’(预先计算的);
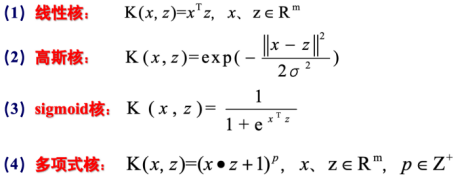
3)degree:多项式poly函数的维度,默认是3,选择其他核函数时会被忽略;
4)gamma:‘rbf’,‘poly’和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features;
5)coef0:核函数的常数项,对于‘poly’和‘sigmoid’有用;
6)probability:是否采用概率估计,默认为False;
7)shrinking:是否采用shrinking heuristic方法,默认为true;
8)tol:停止训练的误差值大小,默认为1e-3;
9)max_iter:最大迭代次数,-1为无限制;
10)decision_function_shape:决策函数形状,‘ovo’(one v one,即将类别两两之间进行划分)、‘ovr’(one v rest,即一个类别与其他类别进行划分)、None,默认为default=None;
11)random_state:数据清洗时的随机种子数,取int值;
主要调节的参数有:C、kernel、degree、gamma、coef0。
回归函数SVR()
sklearn.svm.SVR(kernel ='rbf',degree=3,gamma ='auto',
coef0 = 0.0,tol = 0.001,C=1.0,epsilon=0.1,shrinking=True,
cache_size=200,verbose=False,max_iter = -1)
1)degree:int,多项式核函数的次数('poly'),默认=3,其他内核忽略;
2)coef0:float,默认值0.0,核函数中的独立项。它在'poly'和'sigmoid'中重要;
3)tol:float,默认值= 1e-3,容忍停止标准;
4)cache_size:float,指定内核缓存的大小(以MB为单位);
5)max_iter:int,求解器内迭代的最大迭代次数,默认值为-1表示无限制;
属性:
1)support_:(array-like, shape = [n_SV])
支持向量的索引;
2)support_vectors_:(array-like, shape = [nSV, n_features])
支持向量本身;
3)dual_coef_:(array, shape = [1, n_SV])
决策函数中支持向量的系数;
4)coef_:(array, shape = [1, n_features])
分配给特征的权重,仅在线性核函数时可用。它是从dual_coef_和support_vectors_推导出的只读属性;
5)intercept_:(array, shape = [1])
决策函数中的常数项。
方法:
fit(X, y) →训练模型(学习支持向量和参数)
predict(X) →对新数据进行预测
score(X, y) →返回模型在测试集上的准确率(分类任务)或 R²(回归任务)
【例】用SVC对“鸢尾花数据集”多分类建模
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets,metrics
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target,
test_size=0.2, random_state=0)
p = []
c = np.arange(0.01,0.2,0.005) # 惩罚参数
for i in np.arange(len(c)):
#svc = SVC(C=c[i], kernel='linear', decision_function_shape='ovr')
svc=SVC(C=c[i],kernel='rbf',gamma='auto',decision_function_shape='ovr')
svc.fit(x_train, y_train) # 模型训练
y_fit = svc.predict(x_test) # 预测数据
a_score = metrics.accuracy_score(y_test,y_fit) #预测正确率
p.append(a_score)
plt.title('基于SVC的鸢尾花数据集多分类',fontsize=13)
plt.xlabel('惩罚参数C')
plt.ylabel('预测正确率')
plt.plot(c,p)
plt.show()
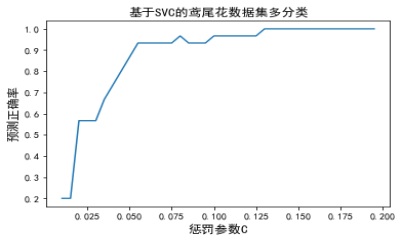
调试时,kernel='linear'时为线性核,C越大分类效果越好,但有可能会过拟合(defaut C=1);kernel='rbf'时为高斯核,gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
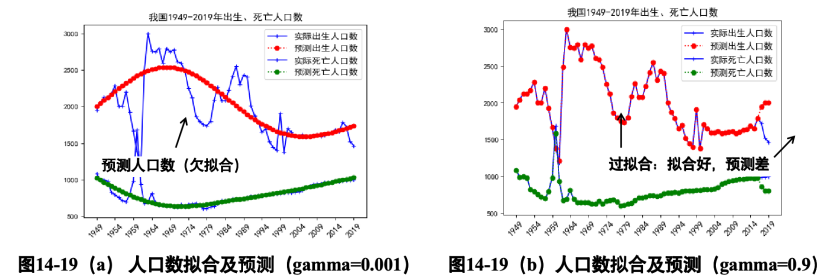
【例】用SVM模型,对人口出生数、死亡数进行回归建模

数据建模之数据聚类

