python计算RPS数据
- 2026-07-13 23:01:20
python计算RPS数据RPS(相对强度排名)是欧奈尔模式的重要工具 上篇写了把通达信本地K线前复权处理 python读取通达信日K线并前复权 本篇继续基于前复权数据,完善RPS基础数据。 RPS本质是相对强度排名,一般使用涨幅衡量强度,所以计算RPS只需2步,一是计算涨幅,二是把涨幅转换成百分位排名。 假设我们需要需要计算RPS的板块名为:【上市一年以上】,通达信自定板块文件存放在目录T0002\blocknew\下的.blk文件中,blk是文本,解析如下 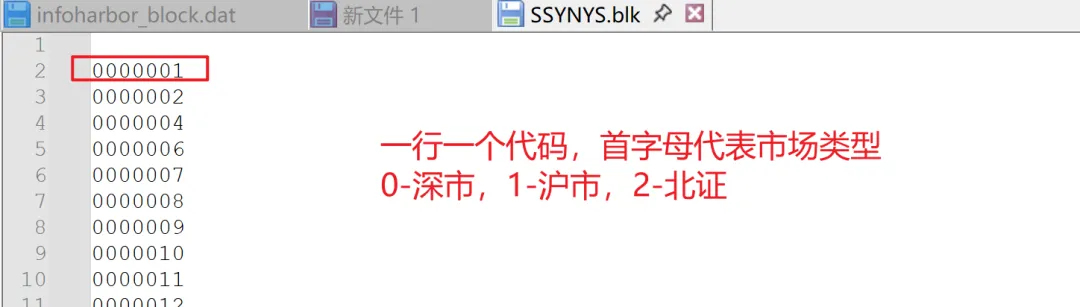
1. 读取【上市一年以上】板块中所有股票的K线构造成一个名为k_bar_df_dict的字典,字典的key=股票代码,value=对应个股前复权K线DataFrame 
2.计算N日RPS 宽表kb_df的索引是日期,列名是股票代码,每行值是n日的涨幅 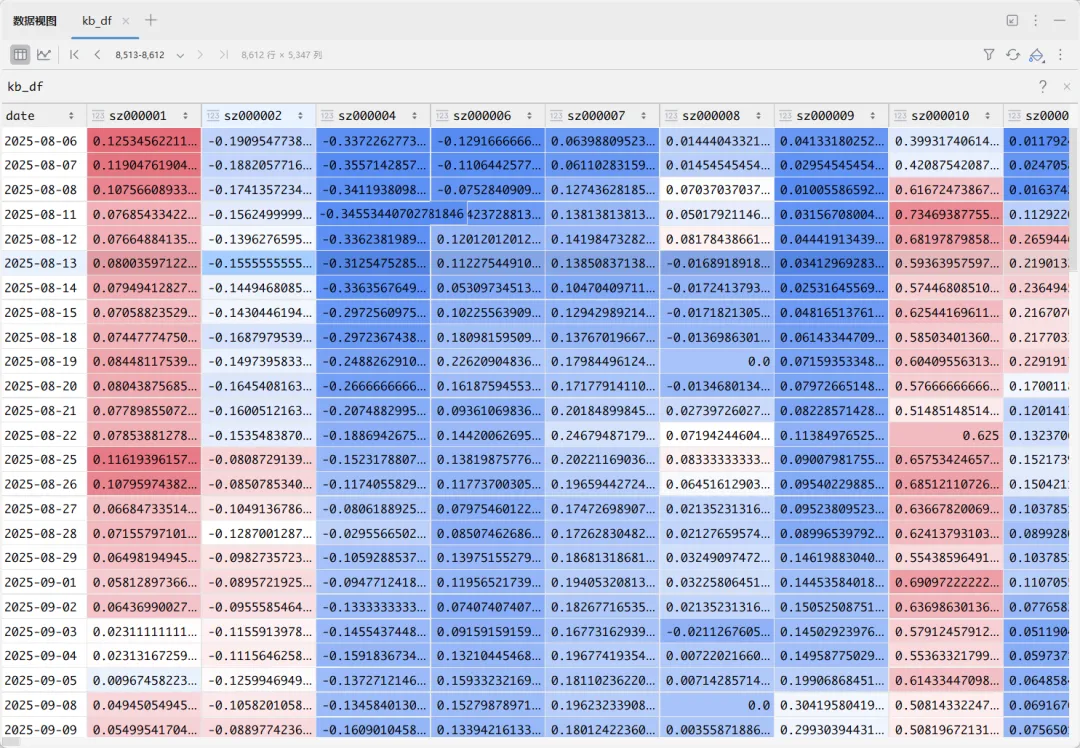
kb_df每行就是每只股票当日的n日涨幅,对每行百分位排名即RPS,每行需对NaN值进行剔除,因为停牌,或后面上市的股票会造成空值,空值排名会影响最终RPS。 3.有了计算n日RPS的函数,依次计算10,20,50,120,250日的RPS,把上面RPS函数的返回值组成列表ret_list,按个股重组ret_list得到每只个股的RPS数据 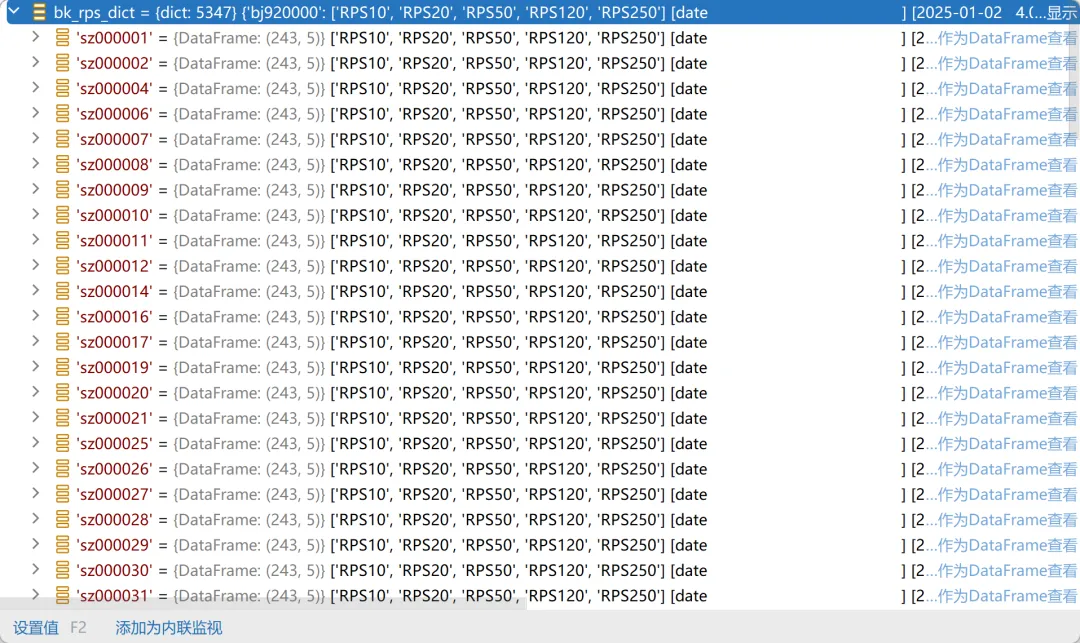
个股301550的RPS 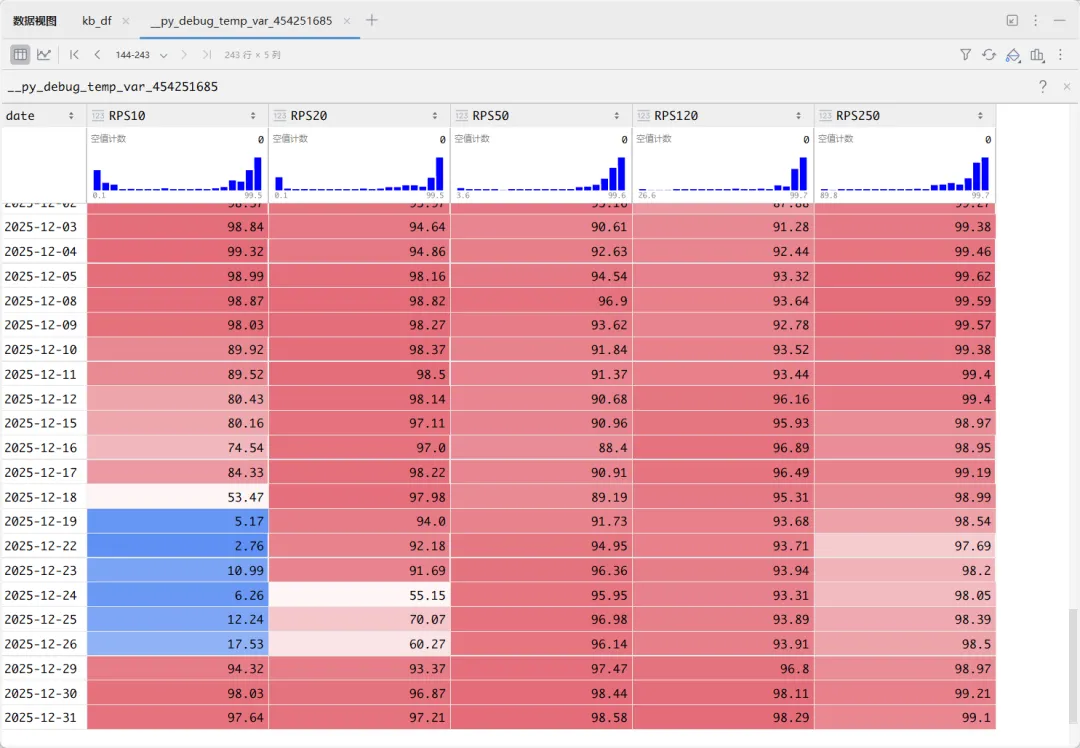
4. 将个股的RPS DataFrame写入文件,后面选股,板块轮动分析就可以直接读取调用了。 
csv文件内容就是RPS 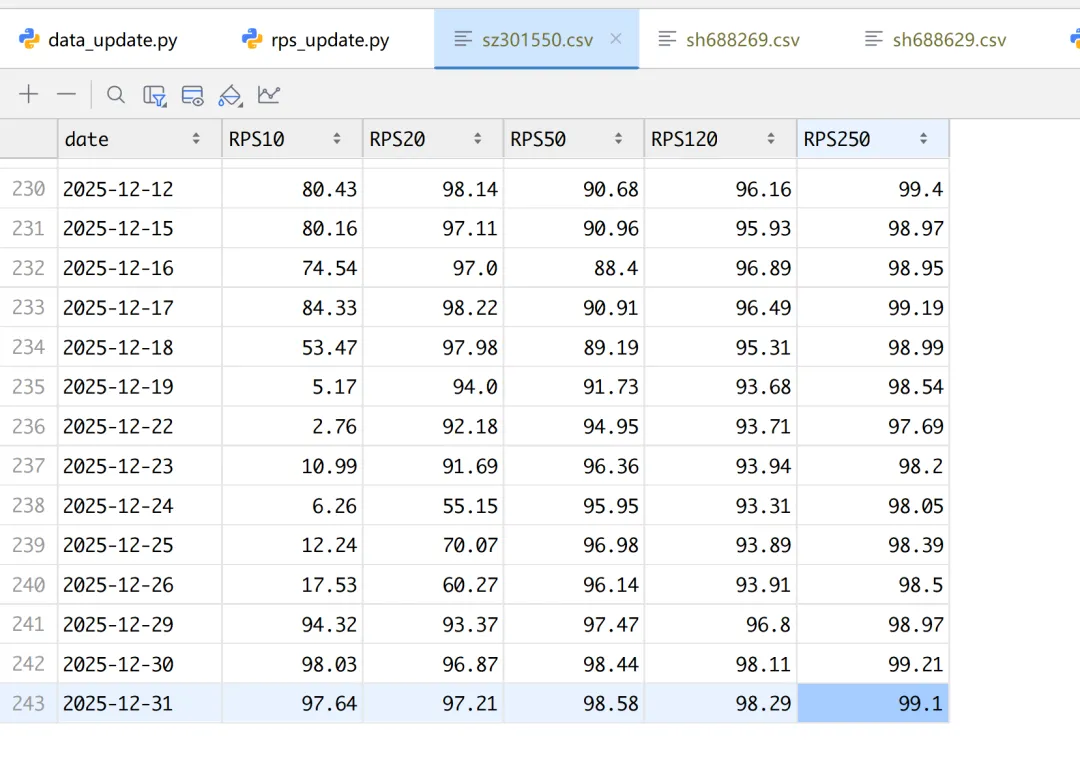
以上就是RPS计算并存储的全部过程,当然还可以根据交易日优化,刷新时只更新新增的K线,节省计算时间。
def _rank_row_ignore_nan(row: pd.Series) -> pd.Series:"""只对非 NaN 值算 rank(pct=True),NaN 保持 NaN"""non_nan_mask = row.notna()if not non_nan_mask.any():return row # 全 NaN,原样返回# 对非 NaN 值单独 rank,分母 = 非 NaN 个数ranked = row[non_nan_mask].rank(pct=True, method="min")# 把结果写回原位置result = row.copy()result[non_nan_mask] = rankedreturn resultdef _calc_rps_n(self, k_bar_df_dict: dict, n, start_date="", end_date=""):"""计算n周期的RPS:param k_bar_df_dict: 板块下所有股票的K线字典,key是代码,value是K线df:param n: n是正整数,n=10表示计算10日RPS"""start_date = start_date if start_date != "" else self.df_399106.index[0]end_date = end_date if end_date != "" else self.df_399106.index[-1]# 构造宽表,列是股票代码,索引是日期,值是n日涨幅kb_df: pd.DataFrame = pd.concat({code: k_bar_df["close"].pct_change(n) for code, k_bar_df in k_bar_df_dict.items()}, axis=1)# 提取指定日期kb_df = kb_df.loc[start_date:end_date]# 把涨幅换算成RPSrps_df = (kb_df.apply(_rank_row_ignore_nan, axis=1) * 100).round(2)# 把n和rps作为元组返回return n, rps_df
def _convert_kb_to_df(ret_list: list) -> dict:"""rps宽表重组对_calc_rps_n的结果列表转换成按股票的df:param ret_list: _calc_rps_n返回值元组构成的列表:return: 按代码重组,每个股所有的RPS一个df"""bk_rps_dict = {}for t in ret_list:rps_n, rps_df = tfor code in rps_df.columns:# 单个票的N日RPS dfrps_n_code_df = rps_df.loc[:, [code]].copy().rename(columns={code: "RPS" + str(rps_n)})if code not in bk_rps_dict:bk_rps_dict[code] = rps_n_code_dfelse:bk_rps_dict[code] = pd.concat([bk_rps_dict[code], rps_n_code_df], axis=1)return bk_rps_dict
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

