关于代码使用: 使用浏览器打开,再进行利用,注意看评论,有一些优化和纠正,以及同学的讨论 准备考试的话,重点建议复习上一章内容,这一章内容总体比较难,适合你锻炼思维和探索,不过先看看我对上一期的补充,对一些题目又进行了一些说明
关于上一期python代码的补充:
在32题(密码),给了any和re两种办法,也可以采用大家课内学过的办法:
n = int(input())a = [input() for _ in range(n)]for i in range(n): b = [0, 0, 0, 0] for c in a[i]: if c.isupper(): b[0] = 1 if c.islower(): b[1] = 1 if c.isdigit(): b[2] = 1 if c in ['~','!','@','#','$','%','^']: b[3] = 1 if sum(b) >= 3 and 8 <= len(a[i]) <= 16: print("YES") else: print("NO")
c.isupper就是c是upper,大写字母,当然可以用'A'<=c<='Z',用这个和isupper一个效果,大家了解一下
在41题(整数数列求和)我采用了差分数组,虽然看起来很妙,但也没必要,还是最淳朴的办法最好,而且时间很短,大家就普及一下前缀和和差分这两个概念就好
下面是41题常规打法:
n,a = map(int,input().split())s = 0b = afor i in range(n): s += b b = b*10+aprint(s)
直接做加法即可
老规矩再普及一下基础知识,这里会普及上一章涉及到但没细说的细节,如果只应对考试,带星号的知识点可以不看
1.字典排序知识
score = {"Zhang San": 45, "Li Si": 70, "Wang Hu": 40}b = list(score.items()) b.sort(key=lambda x: x[1])print(b[-1][1]) #打印最大的value
b是一个列表,存储的是一堆元组,元组的组成是(键,键值)
即b = [('Wang Hu', 40), ('Zhang San', 45), ('Li Si', 70)]
之后对b进行排序,sort括号里面是排序规则,这个key的意思不是字典里面的键,而是按照那个变量排序,这个时候要用到lambda匿名函数,表示的是x=x[1],还可以表明更复杂的规则,比如
b.sort(key=lambda x: (-x[1], x[0]))
这个元组表示的是先按成绩降序排列,再按姓名的首字母排序
排序默认升序,想要降序,就是:
b.sort(key=lambda x: x[1], reverse=True)
2.进制转换
num = 10# 十进制转二进制bin_1 = bin(num) # '0b1010'(返回字符串)bin_2 = f'{num:b}' # '1010'(不带前缀)# 十进制转八进制oct_1 = oct(num) # '0o12'oct_2 = f'{num:o}' # '12'# 十进制转十六进制hex_1 = hex(num) # '0xa'hex_lower = f'{num:x}' # 'a'(小写)hex_upper = f'{num:X}' # 'A'(大写)n = 255print(f'{n:x}') # 'ff'print(f'{n:04x}') # '00ff'(占4位,用0填充)print(f'{n:#04x}') # '0xff'(有前缀)# ############################### ## int()函数转换a = int('1010', 2) # 10(二进制转十进制)a = int('12', 8) # 10(八进制转十进制)a = int('A', 16) # 10(十六进制转十进制)# 带前缀的字符串转换a = int('0b1010', 0) # 10(自动识别进制)a = int('0o12', 0) # 10a = int('0xA', 0) # 10
这个上一章节也涉及到了,我没有细讲
3.定义二维列表
map = [[0 for _ in range(col)]for _ in range(row)]
0是二维列表每个元素的初始值,col表示列数,row表示行数,列在内层,行在外层,逻辑是把一行的每一列都赋值0,然后每一行都这么赋值。
用map = [[0]*col]*row]的定义方法是错误的,此时map表示row个相同的列表组成的列表,只要你改一行中的一个元素(比如第n个,那么每一行的第n个都会改变)
4.for循环设置步长
for i in range(50,-1,-2):
上面表示从0到50的所有偶数倒着遍历一遍,设置步长在后面的题目经常用到,是在for循环的第三个参数,不设置表示从第一个参数开始每次循环i+1,设置多少就加多少(设置-2就是加(-2),即减2)这个注意
*5.关于 CSV 和 json 那些事
CSV文件你就想象成表格,第一行是表头,对应json的key,从第二行开始就是键值。列与列是按逗号分开的。我们的思路是把每一行用split(',')分开并存入列表,然后通过dict(zip(表头列表,行列表))打包成一个字典,加入另一个列表中,就像下面这样:
a, b = [], []try: while True: a.append(input().split(','))except EOFError: for i in range(1, len(a)): b.append(dict(zip(a[0], a[i]))) print(b)# 输入:# 1,2,3# 4,5,6# 7,8,9# 输出:# [{'1': '4', '2': '5', '3': '6'}, {'1': '7', '2': '8', '3': '9'}]
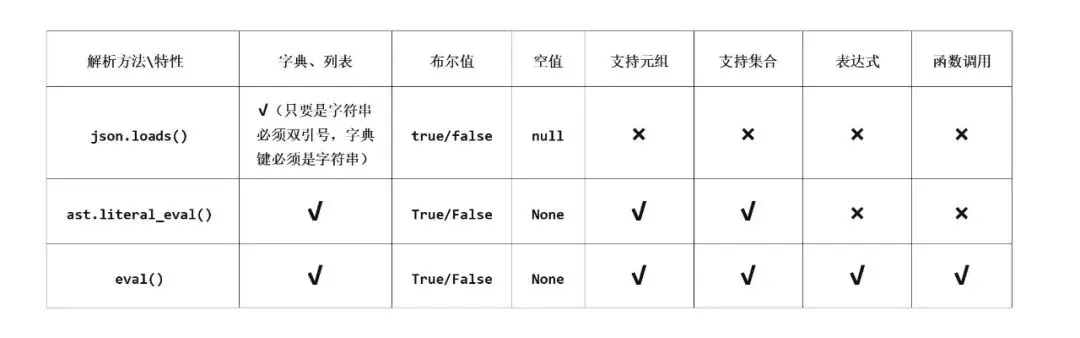
在python里面它跟字典差不多,只是键必须是字符串,必须是双引号,键值中的True和False首字母得小写,None得写成null,知道这些就行。json就是特殊的字典。
json用途很广泛,可以跨多种编程语言进行交流,用来存储游戏进度、api数据集、网页表单数据等等。
json的语法:
1. json.loads (load后面加s表示string,处理的是字符串而不是文件)
表示将json格式转化为Python里面的类型,可以用eval代替,json.load,ast.literal_eval(),eval()都可以处理字符串中的列表和字典,规则如下:
import jsonjsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';text = json.loads(jsonData)print(text)# 运行结果:{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
注意jsonData里面的key必须是双引号,要符合json规范,OJ上的题都是双引号,所以这方面无需考虑。
2. json.dumps
这个可以处理字典和列表,元组、字符串、数字都可以,一般处理列表里面套多个字典的形式,并美化输出(之前29题实现过)
import jsondata = [{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}]print(json.dumps(data, indent=4, sort_keys=True))
想要排序,字典键的类型必须一致,不能有些字符串有些是数字,当然不管什么类型,dumps过后字典的键都变成了字符串并且双引号。
*6.正则表达式
正则表达式(Regex)是一种强大的文本模式匹配工具,用于对字符串进行搜索、替换和验证。正则表达式想要完全掌握所有内容太多了,这里介绍几种常见的,足够日常使用和做题了。
(1)re.findall 查找所有匹配项,用r''的形式防止识别转义字符,例如\n,\s等等,如果你特意要识别就删掉r。
text = "苹果12个,香蕉5根,橙子8个"numbers = re.findall(r'\d+', text) # 查找所有数字print(numbers)
\d+表示多个数字,+表示大于等于1个。数字还有很多:
import retext = "Pi约3.14159,价格$99.50,电话13800138000,验证码2468"# 1. 找特定个数的数字four_digits = re.findall(r'\d{4}', text) # 找4位数字phone = re.findall(r'\d{11}', text) # 找11位手机号# 2. 找浮点数floats = re.findall(r'\d+\.\d+', text) # 找带小数点的数字print("4位数字:", four_digits) # ['1380', '0138', '0000', '2468']print("手机号:", phone) # ['13800138000']print("浮点数:", floats) # ['3.14159', '99.50']
在爬虫中经常用到下面这个,不限制
import retext = "<h1>标题</h1><p>段落内容</p>"# 1. 贪婪模式(默认)result_greedy = re.findall(r'<.*>', text)print("贪婪模式:", result_greedy)# 输出: ['<h1>标题</h1><p>段落内容</p>']# 从第一个 < 匹配到最后一个 ># 2. 非贪婪模式(加 ?)result_lazy = re.findall(r'<.*?>', text)print("非贪婪模式:", result_lazy)# 输出: ['<h1>', '</h1>', '<p>', '</p>']# 匹配到最近的 > 就停止
.*表示匹配0个或多个任意字符(换行符除外)
import retext = "AbC 123 !@#"print("数字:", re.findall(r'\d+', text))# 数字: ['123']print("大写:", re.findall(r'[A-Z]', text))# 大写: ['A', 'C']print("小写:", re.findall(r'[a-z]', text))# 小写: ['b']print("所有字母:", re.findall(r'[A-Za-z]', text))# 所有字母: ['A', 'b', 'C']print("特殊:", re.findall(r'[!@#$%^&*(),.?":{}|<>]', text))# 特殊: ['!', '@', '#']
(2)re.sub是找到了之后替换
import retext = "这里有6666666666个[苹果]和666个[香蕉]"# 1. 替换连续8个或更多6r1 = re.sub(r'6{8,}', '很多', text)print(r1) # 这里有很多个[苹果]和666个[香蕉]# 2. 去掉所有[]及内容r2 = re.sub(r'\[.*?\]', '', text)print(r2) # 这里有66666666个和666个# 3. 把"苹果"换成"橘子"r3 = re.sub(r'苹果', '橘子', text)print(r3) # 这里有66666666个[橘子]和666个[香蕉]
(3)re.search搜索字符串中第一个匹配正则表达式的位置
import retext = "电话:13800138000"a = re.search(r'\d{11}', text)if a: # 判断是否找到 print("手机号:", a.group()) # 手机号: 13800138000else: print("没找到手机号")
(4)re.split 用于按正则表达式分割字符串,返回分割后的列表。
import re# 1. 按数字分割text1 = "苹果5香蕉3橙子8"result1 = re.split(r'\d+', text1)print(result1) # ['苹果', '香蕉', '橙子', '']# 2. 按多个分隔符分割text2 = "苹果,香蕉;橙子 ;桃子"result2 = re.split(r'[,\s;]+', text2)print(result2) # ['苹果', '香蕉', '橙子', '桃子']# 3. 限制分割次数(只分割2次)text3 = "a,b,c,d,e,f"result3 = re.split(r',', text3, maxsplit=2)print(result3) # ['a', 'b', 'c,d,e,f']
第二个方法最强大,任意个空格或逗号分号都能隔开
接下来是后40题的代码解析
51.统计工龄
n = int(input())a = list(map(int, input().split()))b = {}for i in a: b[i] = b.get(i, 0) + 1for j in sorted(b.keys()): print(f'{j}:{b[j]}')
字典里面的get(i,0)用法,对于i,有就是它对应的value,没有就输出0,然后b[i]就是对i的value进行赋值 当然也可以通过集合将每个元素对应value都初始化0,然后+=1,但是get更简洁, 可以直接设置初始值
52.经典逆序对问题
n = int(input())a = list(map(int, input().split()))lst = [0]*(max(a)+1)x = 0for i in a: lst[i] += 1 x += sum(lst[i+1:])print(x)
这个题想要节约时间,难度就非常大了,上面这种方法非常巧妙,总体方案是lst表示0~最大的数出现次数分别记录在lst[0]~lst[max],在遍历每一个数的时候,对该数对应的次数加一,同时x加上大于该数的数的总次数,就是该数作为较小数对应的逆序对次数。无需担心超范围, i+1 超过列表长度时,lst[i+1:] 返回空列表,sum=0 。
看了我的解释估计你可能蒙圈,举例子是最好的办法,比如[9,3,3,1]
因为最大的数是9,所以lst有10个0
lst=[0,0,0,0,0,0,0,0,0,0]
第一个数9 lst=[0,0,0,0,0,0,0,0,0,1]
没有比9大的数,此时x=0
第二个数3 lst=[0,0,0,1,0,0,0,0,0,1]
9比3大,此时x+=1
第三个数3 lst=[0,0,0,2,0,0,0,0,0,1]
9比3大,此时x+=1
第三个数1 lst=[0,1,0,2,0,0,0,0,0,1]
1个9,2个3都比1大,此时x+=3
这下就很直观了
53.跟奥巴马一起画方块
import mathvalues = input().split()col = int(values[0])a = values[1]row = math.ceil(col/2)map = [[0 for _ in range(col)]for _ in range(row)]for i in range(row): for j in range(col): map[i][j] = afor i in range(row): for j in range(col): print(map[i][j], end='') print()
输入也可以用map(str,input()split())简洁度差不多,math.ceil向上取整
54.IP的计算
a = []try: while True: a.append(int(input())+2)except EOFError: passfor i in a: b = [] x = 32 - (len(bin(i))-2) c = '1'*x+'0'*(32-x) for j in range(0,32,8): b.append(int(c[j:j+8],2)) print('.'.join(map(str,b)))
这个题这么写在oj上是对的,思路:
用户输入主机个数,我们把这个数+2,原因是要包括网络地址和广播地址,才是一个完整的局域网,之后把这个数转换为2进制看它有多少位,比如主机个数是12,加上2是14,14转换为二进制是0b1110,总共4位,但实际字符串长度有6位,所以要减去2,因此这个局域网的网络号是:11111111 11111111 11111111 11110000 , 现在的任务是把它转化成十进制,每8位进行转换,所以这个时候我们要调整for循环的步长,这个题就解了。
但仔细一想发现出题人不严谨,这个题答案这么写是有误的,假定主机数量是14,+2之后是16,16的二进制是10000,按上面这个思路就得5位,但事实上4位就够了,从0000到1111一共有2^4=16种取值(已经包含了网络地址和广播地址),所以最开始用户输入的主机数量+1再转换成2进制就可以了。验证:主机数量为0,那0+1=1,1转换为2进制是0b1,有1位,因此网络号是11111111 11111111 11111111 11111110,显然是对的,网络地址最后一位给0,广播地址最后一位给1,就ok了。正确的思路大家明白就好,还是按上面这个代码提交才可以过OJ的。
55.个位数统计
a = input()b = {}for i in a: b[i] = b.get(i, 0) + 1for j in sorted(b): print(f'{j}:{b[j]}')
get(<key>,<default>)表示的是拿到key对应的value(字典键值),如果这个key在字典中不存在,则拿到的是第二个参数default,你可以理解为这个字典的初始值。sorted默认对key排序,想对value排序就用sorted(b.values())
58.Cut Integer
n = int(input())a = []for i in range(n): a.append(input())for i in range(n): x = int(a[i][:len(a[i])//2]) y = int(a[i][len(a[i])//2:]) if y==0: print('No') continue if int(a[i]) % (x*y): print('No') else: print('Yes')
要注意题干提示的拆分后会有0的出现,毕竟是数字应该是后面为0,这里必须使用双斜杠(即使输入偶数位数),否则位数是浮点格式会报错
66.列表排序
n1 = int(input())a = [int(input()) for _ in range(n1)]n2 = int(input())b = [int(input()) for _ in range(n2)]a.sort()for i in b: print(a[i])
OJ系统上的提示给的list.sort(cmp=None, key=None, reverse=False),第一个参数cmp表示比较参数,这个参数python3已经弃用了,key和reverse默认就是None和False,既然默认是这样就可以不输入,直接a.sort()
69.梅森质数
n = int(input())a = 2**n - 1c = a % (10**500)b = f'{c:0500}'print(len(str(a)))for i in range(0,500,50): print(b[i:i+50])print(str(a)[0])
整除10的500次方自然是后500位数;f'{}'这种形式常见于print里面,但也可以当字符串用,然后50位50位打印
73.寻找目标
import sysa = sys.stdin.read().splitlines()b = a[0].split(',')if 'target' not in b: print('File is not OK!')else: target_idx = b.index('target') for line in a[1:]: if line.split(',')[target_idx] == '1': print(line)
这个题注意先用split(',')分隔开再检查target是否存在,直接检测target是否存在过不了OJ...因为它认定target前后没有空格才算存在
74.星际迷航
lst = [[ 0,-1, 1, 1,-1], [ 1, 0,-1, 1,-1], [-1, 1, 0,-1, 1], [-1,-1, 1, 0, 1], [ 1, 1,-1,-1, 0]]n,a,b = map(int,input().split())A1 = list(map(int,input().split()))B1 = list(map(int,input().split()))A2 = n//a*A1 + A1[:n%a]B2 = n//b*B1 + B1[:n%b]score = sum(lst[A2[i]][B2[i]] for i in range(n))print(score,-score)
石头剪刀布的升级版,把每个情况是0/-1/1列出来,列出二维表格,因为表格是甲对乙的结果,即行对列的结果,所以行是小A,列是小B(是在分不清你试就行了,反了就反着输出来)
75.寻找目标2
import jsona,b = [],[]try: while True: a.append(input().split(','))except EOFError: if 'target' not in a[0]: print('File is not OK!') else: for i in a[1:]: if i[a[0].index('target')] == '1': b.append(dict(zip(a[0], i))) print(json.dumps(b, indent=4))
跟29题差不多,只不过这个题对字典内容有要求,那就新建一个列表b存字典就行,规矩还是一样,先逗号分隔再检测‘target'
76.扫雷问题
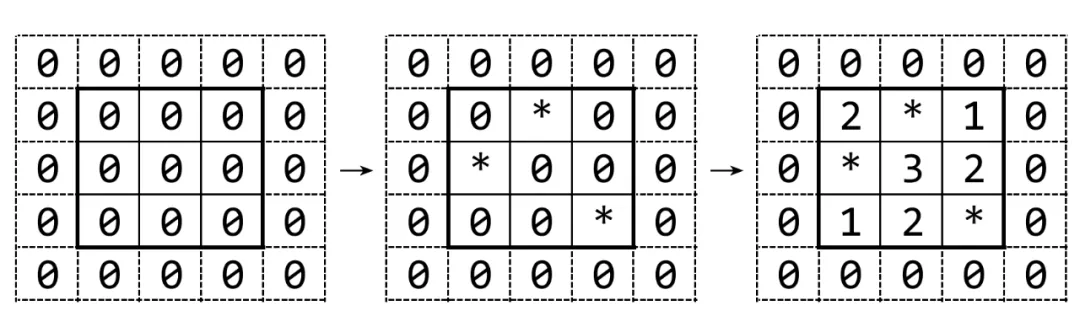
ROW, COL = map(int, input().split())map = [[0 for _ in range(COL+2)]for _ in range(ROW+2)]b = [input() for _ in range(ROW)]for i in range(ROW): for j in range(COL): if b[i][j] == '*': map[i+1][j+1] = '*'for i in range(1, ROW+1): for j in range(1, COL+1): if map[i][j] != '*': for m in range(i - 1, i + 2): for n in range(j - 1, j + 2): if map[m][n] == '*': map[i][j] += 1for i in range(1, ROW+1): for j in range(1, COL+1): print(map[i][j], end='') print()
上面这个方法是辅助行列处理边界问题,建立二维数组多建了两行两列,辅助行和辅助列默认是0,自然没有星号,如图所示,3×3的扫雷图,外面多的一圈就是辅助行列。
当然初始的时候都是0,之后我们只需要把有*的地方替换0即可,最后计数,时间是1.3秒,遍历的次数比较多,但是是有必要的,print()表示输出回车
下面这个不用辅助行的方法也可以,但要判断边界条件,所以时间更长,已经达到2秒
ROW, COL = map(int, input().split())map = [[0 for _ in range(COL)]for _ in range(ROW)]b = [input() for _ in range(ROW)]for i in range(ROW): for j in range(COL): if b[i][j] == '*': map[i][j] = '*'for i in range(ROW): for j in range(COL): if map[i][j] != '*': for m in range(i - 1, i + 2): for n in range(j - 1, j + 2): if 0 <= m < ROW and 0 <= n < COL: if map[m][n] == '*': map[i][j] += 1for i in range(ROW): for j in range(COL): print(map[i][j], end='') print()
77.说反话
a = list(map(str, input().split()))if not a: print("\n")else: print(' '.join(list(reversed(a))))
对列表用reversed函数就可以实现反向
79.JSON 文件转换成 CSV 文件
import jsona = json.loads(input())num = list(a[0].keys())print(','.join(num))for i in a: print(','.join(i.values()))
读取文件是json.load,读取字符串是json.loads,表示把字符串处理成json格式,你不想用json完全可以,用eval完全可以解析。
num = list(a[0].keys()),这个.keys()可以不写,默认列表就是键的列表,写上更清楚。
80.JSON 文件转换成 CSV 文件2
import jsonimport sysdata = sys.stdin.read()a = json.loads(data)b = list(a[0].keys())print(','.join(b))for i in a: print(','.join(i.values()))
比上一个题多了个多行输入,当然也可以用eval
81.寻找目标3
a = eval(input())b,c = map(int, input().split())for j in a: if b<=j["Value"]<=c: print(j["ID"])
82.图像中值滤波
row, col, a, b, x = map(int,input().split())output = []for _ in range(row): line = list(map(int, input().split())) ROW = [] for i in line: if a <= i <= b: i = x ROW.append(f'{i:03}') output.append(ROW)for i in output: print(' '.join(i))
要想明白什么时候创建空列表
85.RGB 和十六进制颜色字符串转换
a = []try: while True: a.append(input())except EOFError: for i in a: if i[0] == '#': r, g, b = (int(i[j:j + 2], 16) for j in range(1, 7, 2)) print(f'rgb({r}, {g}, {b})') else: r, g, b = map(int, i[4:-1].split(', ')) print(f'#{r:02x}{g:02x}{b:02x}'.upper())
注意逗号后面有空格,要split(', ') ,其他的注意观察就行
86.寻找目标4-json
def f(x): i = 2 while i*i <= x: if x%i == 0: return 0 i += 1 return 1a = eval(input())for j in a: if f(j["Value"]): print(j["ID"])
用json.loads也可以,建议两种方法都试一下,前面已经介绍过了。反复判断,就像判断素数一样,用函数更方便
87.数字添加序数词
a = []special = {'1':'st','2':'nd','3':'rd'}try: while True: a.append(input())except EOFError: for i in a: if i[-1] in special and int(i)%100 not in [11,12,13]: print(i+special[i[-1]]) else: print(i+'th')
不管OJ系统查的是否全面(其实不全面),我们把所有情况都要考虑进去,1st,2nd,3rd在十位不是1的时候成立。
88.列表递归降维
x = []def f(a,b): for i in a: if not isinstance(i,(list,tuple)): b.append(i) else: f(i,b) return btry: while True: x.append(eval(input()))except EOFError: for j in x: print(f(j,[]))
只可能是列表或元组,所以可利用递归函数,判断它的数据类型就行,用不上OJ所提到的第三方库,还能避免字符串被递归的情况,但下面是OJ推荐的办法,默认没有字符串
from collections.abc import Iterabledef flatten_deep(lst): for i in lst: if isinstance(i, Iterable) and not isinstance(i, (str, bytes)): yield from flatten_deep(i) else: yield ix = []try: while True: x.append(eval(input()))except EOFError: for j in x: print(list(flatten_deep(j)))
第三方库注意要写from collections.abc import Iterable,python更新了。字符串是Iterable的,就是可迭代的,迭代成单个字符,单个字符本身可以迭代,迭代成长度是1的字符串,然后无限迭代下去……Python里面没有字符这个概念,这跟c语言不同。所以要排除str或者bytes的情况(在本程序第4行),当然这个OJ系统里面你不排除也能过,测试用例里面没有字符串形式。简单bytes知识在下面,具体的感兴趣在网上了解即可。
b1 = b'hello' # ASCII字符字节串b2 = b'\x68\x65\x6c\x6c\x6f' # 十六进制表示的字节串print(b1 == b2) # True,两者等价
89.派送蛋糕(模拟考试题目)
import mathN = int(input())a = list(map(int, input().split()))b = sum(math.ceil(x / 10) for x in a)print(b)
这个大概就是考试难度吧。
90.装饰水果
n = int(input())a = list(map(int, input().split()))error = 0for i in a: if i==0 or n<=i: error = 1if error: print('Error!')else: print(n//max(a))
这个题重点在于揣测出题人意图:不能装饰蛋糕就是只要有一样没有,就没法装饰了(幽默);装饰蛋糕为0就是水果不够用,买的水果还不够一个蛋糕。利用error作标志位,比较容易操作。
92.URL 中提取域名、路径和参数列表
from urllib.parse import urlparseurl = []try: while True: a = input() url.append(urlparse(a))except EOFError: passfor i in url: result = {'hostname': i.hostname} if i.port: result['port'] = str(i.port) result.update({'protocol': i.scheme, 'query': i.query, 'fragment': i.fragment}) print(result)
urllib.parse里面的urlparse这个函数是将URL字符串解析为ParseResult对象,可以直接通过点的形式引用即可,因为
from urllib.parse import urlparseurl = 'http://blog.csdn.net/test/page/a.php?language=python#12121'print(urlparse(url))print(urlparse(url).hostname)# 打印结果如下:# ParseResult(scheme='http', netloc='blog.csdn.net', path='/test/page/a.php', params='', query='language=python', fragment='12121')# blog.csdn.net
由于题目要求如果没有端口信息则不在字典里面输出端口,所以要进行判断是否为空,然后还要必须含指定顺序,所以需要如上这么写,update可以更新多个字典键和键值,而且直接加在后面,就无需一个一个赋值了。
except EOFError:这个后面可以不用pass直接写主程序,都可以,不用纠结。
94.Bit Soccer
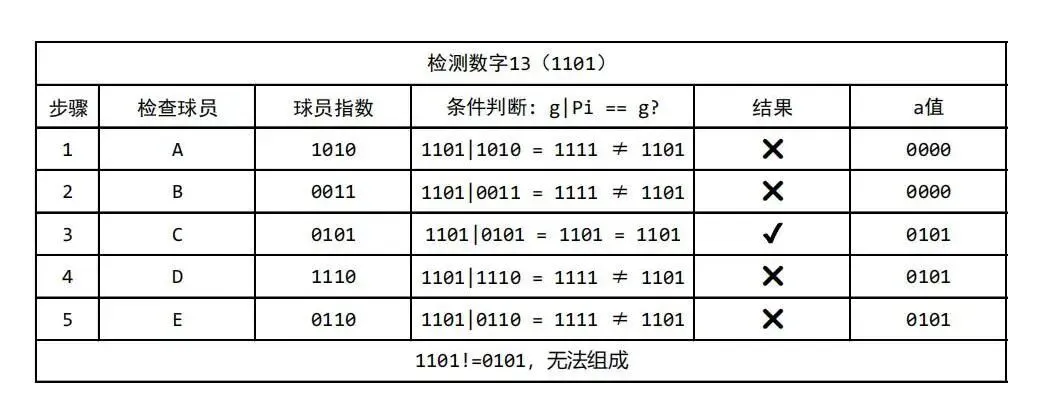
N = int(input())P = set(map(int, input().split()))Q = int(input())G = [int(input()) for _ in range(Q)]for g in G: a = 0 for Pi in P: if g | Pi == g: a |= Pi print('YES' if a == g else 'NO')
这个英文题目的意思是,一个球员在一场比赛中表现好就是1,表现不好就是0,比如A球员在第一场和第三场表现的好,那他的表现指数就是5(101),用二进制的形式表示球员的表现,B球员如果是3(011),那么这个A和B组成的团队得分就是3和5进行或运算,就是7(111)。
第一行输入这个队伍球员个数,第二行输入每个球员的表现指数,然后现在我想从这个队伍里面选若干个人组成一个新队伍,新队伍有一个新的表现指数,那么这个题的任务是输入表现指数,看能不能组一个新的队伍,让这个新的队伍的表现指数等于我输入的这个表现指数,如果能就输出YES,否则输出NO。(第三行输入检测次数,第四行开始输入要检测的表现指数)
P用set的形式存储为集合,避免了重复判断,也节省了内存。
我的方法就是从输入的这个队伍表现指数出发,和每个成员进行或运算,求或之后等于这个队伍表现指数,就把它组成全新的一堆,最后看看全新的这个队的指数等不等于我输入的这个队伍表现指数就行。这个题如果用正向思维,把所有可能的队伍指数全部存起来,内存会超限,所以必须逆向思维,节省内存也节省了时间。
100.求素数
def f(x): i = 2 while i * i <= x: if x % i == 0: return 0 i += 1 return 1a = int(input())for j in range(a,1,-1): if f(j): print(j) break
从大往小地找就行,省时间
102.Python, 我们能过
print('Python, we can pass.')
104.(3n+1)猜想
a = int(input())if a == 1: print('OK')while a != 1: if a % 2 == 0: a //= 2 else: a = 3 * a + 1 print(a)
106.计算时间
import timex = int(input())result = time.ctime(x + 8*3600)print(result)
可能自己运行不需要加8*3600就已经是8点了,但是OJ系统默认从0点开始,所以还得加上。
拓展一下,想要当前时间是这样的:
from datetime import datetimecurrent_time = datetime.now().strftime("%Y-%m-%d%H:%M:%S")print(current_time)
108.质因数分解
def f(x): i = 2 while i*i<=x: if x%i==0: return 0 i+=1 return 1n = int(input())j = 2while j*j<=n: if n%j==0 and f(j): print(j if j > n//j else n//j) break
注意在判断的时候,and前面的语句一旦不对,后面的语句就不会执行,所以想省时间,就把f(j)放在后面,最后一旦找到直接break,最后加一行j+=1
110.查验身份证(模拟考试题目)
n = int(input())a = [input() for n in range(n)]b = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]Z = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]M = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2']d = []for i in a: if i[:-1].isdigit(): c = sum(int(i[j])*b[j] for j in range(17)) % 11 if M[Z.index(c)] == i[-1]: d.append(i)if len(d) == len(a): print('All passed')else: for i in a: if i not in d: print(i)
要做到一一对应,你可以使用字典,我是觉得用字典比较长,用表格更可以看出对应关系。M这个表格的元素都用字符串的格式会更方便。index的用法是:表格.index(元素),找的是元素的位置(也是从0开始),如果有多个这样的元素,找到的是第一个这样的元素的位置。
这种题一定注意审题,输出的是不符合条件的。
111.孪生素数
def f(x): j = 2 while j * j <= x: if x % j == 0: return 0 else: j += 1 return 1n = int(input())m = int(input())empty = 1for i in range(2, n+1): if f(i) and f(i+m): print(i, i+m) empty = 0if empty: print('Empty')
这个题出题人的意思是,两个素数都不超过n+m就行了,也就是说较小的数不超过n(用的是开头的那个条件)
113.跳舞机
a = input()b = input()c = 0for i in range(len(a)): if a[i] == b[i]: c += 20 elif c != 0: c -= 10print(c)
看两个列表对应字符是否一样就行
115.Xplore
import jsonn = int(input())jsons = [json.loads(input()) for _ in range(n)]a = {}for json in jsons: for i in json['authors']['authors']: name = i['full_name'] if name not in a: a[name] = [] a[name].append(json['citing_paper_count'])for person in a: number = sorted(a[person], reverse=True) index = 1 for j in range(len(number)): if number[j] >= j+1: index = j+1 else: break a[person] = indexitems = list(a.items())items.sort(key=lambda x: (-x[1], x[0]))for item in items: print(item[0], item[1])
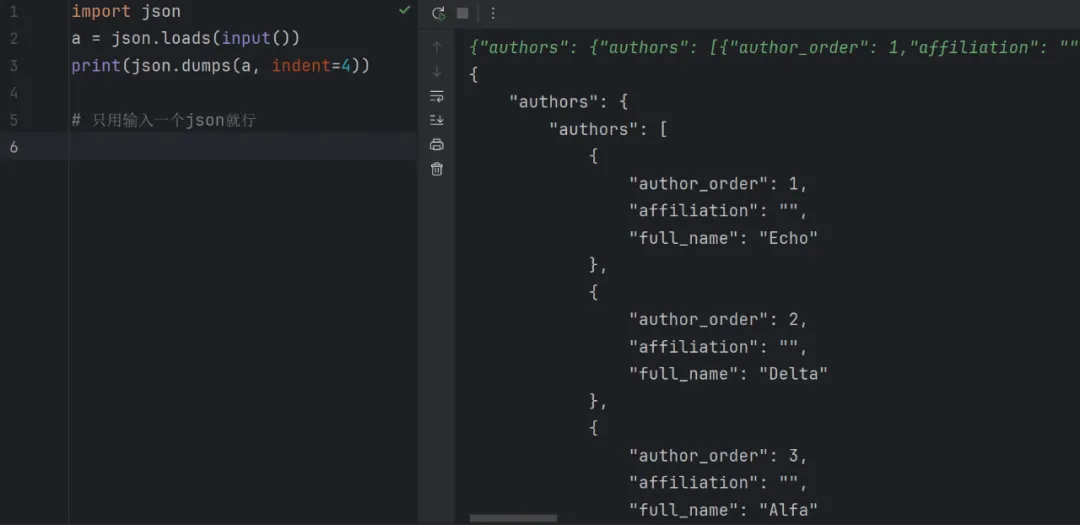
这个题的题目输入那块比较长得划来划去,这个时候可以用你已知的知识让这些json更好看,那么如下图:
这样需要什么参数,它在哪一层这些问题,就非常清晰了(学以致用)这个题意思比较直白,就是根据它给你的一堆json,统计每个作者的每篇论文引用次数,要注意一篇文章有好几个作者,一个作者会反复在不同的json出现。最后对这个作者论文引用次数排序,比如看OJ上面的示例:列表中,作者Charlie有7篇论文,文章引用次数依次为9、4、9、5、6、9和4。将这些论文按引用次数降序排列,得到序列:9, 9, 9, 6, 5, 4, 4。根据h指数的定义,Charlie的h指数是5,因为他有5篇论文的引用次数不少于5次。同样的计算方法也适用于其他作者,如Echo、Alfa、Bravo和Delta。然后将这些作者按h指数排序其中,Alfa、Bravo和Delta的h指数相同,因此在排序时,他们按姓名的字母顺序排列。在求h指数要考虑到结尾了break语句仍未执行,所以引入变量index记录,比如(9,9,9),就是3篇文章引用次数不少于3次。
116.BeautifulSoup 库的使用1 (题目错误)
理论上就应该这么打,他推荐的文档网站也是这么写的,但是OJ的系统输出没有更新,应该还是按老版本的格式,所以这个题没法做对,大家知道怎么打就行。
import sysfrom bs4 import BeautifulSouphtml = sys.stdin.read()soup = BeautifulSoup(html, 'html.parser')print(soup.prettify())
118.求指定层的元素个数
a = eval(input())n = int(input())def f(lst, x, y): num = 0 y += 1 if y<x: for i in lst: if isinstance(i, list): num += f(i, x, y) else: for i in lst: if isinstance(i, int): num += 1 return numprint(f(a, n, 0))
注意指定层是表格中所有范围内,而不是第一个,比如[1,[2,3],[3,[6,9]]]第二层就是[2,3],[3,[6,9]]两个列表,数字元素个数就是3个
还是用递归的方式进行实现,只不过要增加条件判断限制递归次数
119.列表元素个数的加权和
a = eval(input())def f(a,m): num = 0 for i in a: if isinstance(i,list): num += f(i,m+1) else: num += m return numprint(f(a,1))
函数的第二个参数就表示的权重
120.按位取反
a,b = map(int,input().split())a ^= 2**b-1print(a)
这个方法比较妙,用的按位异或,相同为0,不同为1
122.这句谢谢,献给你
print('zhe ju xie xie, xian gei ni')
感谢支持!