我的Python100天打卡:53/100
- 2026-07-12 18:41:35

上次笔记,给第十四章Numpy数组的索引和切片开了个头,用自己的方式理解了“索引”所包含的“升维”和“降维”是什么意思,以及它的数学含义和编程意义是什么。
昨天的学习比较匆忙😂,也许打卡到现在心态发生了些变化,今天重新调整一下,用更加认真的态度完成第十四章的剩余内容,具体内容如下:
14-2-3 一维数组的切片
14-2-4 一维数组的【整数】索引和切片
14-2-5 一维数组的【布尔】索引和切片
--
首先在学新知之前,复习下昨天关于“行向量”和“列向量”可视作二维数组的观点,以及如何在代码中实现“升维”和“降维”,提供具体代码和结果进行参考(具体回顾方向,见下方AI编程教练建议):

1. 思考下方示例代码,并用我自己的语言进行回答:
# 示例,验证自己的理解:arr = np.array([1, 2, 3, 4, 5])# 问题:# 1. arr.shape 是什么? (5,)# arr.shape 是 (5,)。这是一个一维数组,有5个元素。# 2. arr[np.newaxis, :].shape 是什么? (1, 5)# arr[np.newaxis, :] 相当于在第一个维度上增加一个维度,变成二维数组。# 原来的一维数组变成了一个行向量(1行5列)。所以形状是(1, 5)。# 3. arr[:, np.newaxis].shape 是什么? (5, 1)# 4. 这三种形状在矩阵乘法中如何表现?# 如果你无法立即回答,说明你对维度的理解是表面的
问题:


--
14-2-3 一维数组的切片
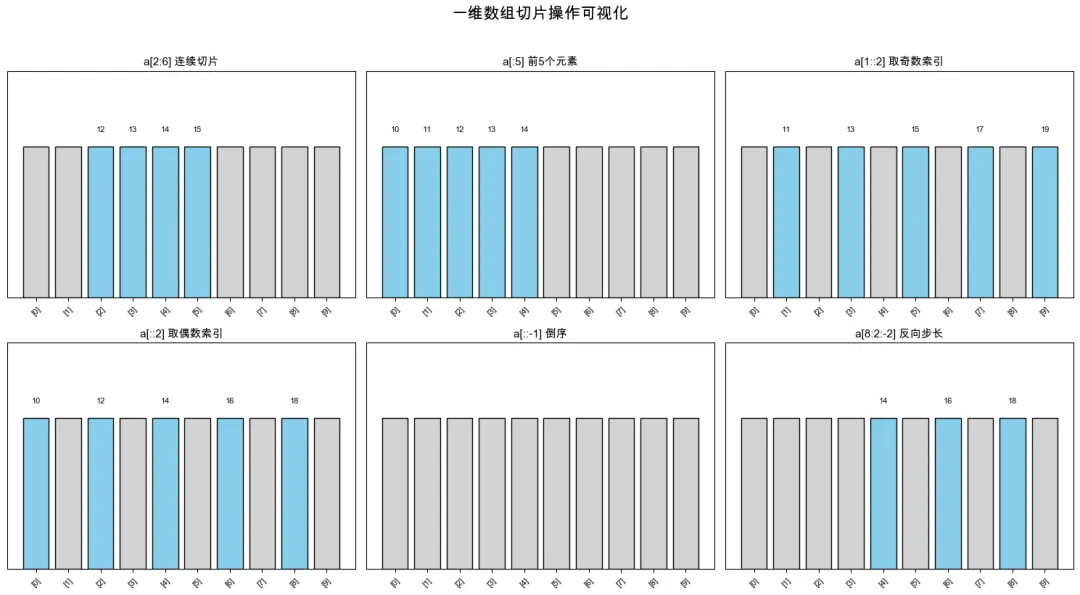
# 1.1.1 连续切片print_section("1.1 连续切片", 2)slice1 = a[2:6] # 索引2到5(包含2,不包含6)print("a[2:6]:", slice1) # 12, 13, 14, 15# 1.1.2 省略开始/结束索引print("\n1.2 省略开始/结束索引")print("a[:5]:", a[:5]) # 前5个元素: 10, 11, 12, 13, 14print("a[5:]:", a[5:]) # 从索引5开始: 15, 16, 17, 18, 19print("a[:]:", a[:]) # 整个数组# 1.2 固定步长切片print_section("1.2 固定步长切片", 2)# 步长为2(取偶数索引元素)print("步长为2(每隔一个取一个):")print("a[::2]:", a[::2]) # 10, 12, 14, 16, 18# 从索引1开始,步长为2(取奇数索引元素)print("\n从索引1开始,步长为2(取奇数索引元素):")print("a[1::2]:", a[1::2]) # 11, 13, 15, 17, 19# 1.3 倒序切片print_section("1.3 倒序切片", 2)print("a[::-1]:", a[::-1]) # 倒序: 19, 18, 17, ..., 10print("a[8:2:-2]:", a[8:2:-2]) # 从索引8到2,步长为-2: 18, 16, 14
-
14-2-4 一维数组的【整数】索引和切片
14-2-5 一维数组的【布尔】索引和切片
1️⃣这两个点一起来做笔记。
整数索引和布尔索引,是一些比较高级的索引方式。
整数索引,允许通过整数或整数数组来访问多个元素;
布尔索引,允许通过条件来筛选元素。
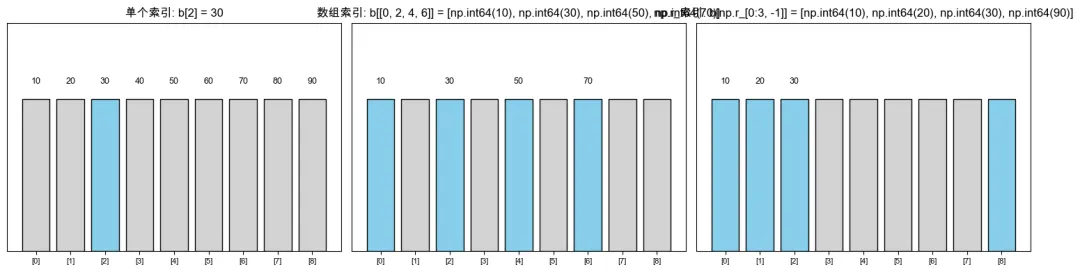
# 2.1 单个整数索引print_section("2.1 单个整数索引", 2)print("b[0]:", b[0]) # 第一个元素: 10print("b[-1]:", b[-1]) # 最后一个元素: 90print("b[2]:", b[2]) # 第三个元素: 30# 2.2 整数数组索引print_section("2.2 整数数组索引", 2)indices = [0, 2, 4, 6] # 要提取的索引print(f"索引数组: {indices}")print(f"b[indices]: {b[indices]}") # 10, 30, 50, 70# 2.3 使用np.r_构造索引print_section("2.3 使用np.r_构造索引", 2)# np.r_可以将切片对象转换为数组print("np.r_[0:3]:", np.r_[0:3]) # [0, 1, 2]print("np.r_[0:3, -1]:", np.r_[0:3, -1]) # [0, 1, 2, -1]print("b[np.r_[0:3, -1]]:", b[np.r_[0:3, -1]]) # 10, 20, 30, 90# 2.4 修改元素print_section("2.4 修改元素", 2)c = b.copy() # 创建副本c[2] = 300c[[0, 4]] = [100, 500]print("修改后数组 c:", c)print("原始数组 b (未改变):", b)
# 3.1 基本布尔索引print_section("3.1 基本布尔索引", 2)bool_mask = d > 0print("布尔掩码 (d > 0):", bool_mask)print("d[d > 0]:", d[d > 0]) # 所有大于0的元素# 3.2 多个条件print_section("3.2 多个条件", 2)print("d[(d > 1) & (d < 5)]:", d[(d > 1) & (d < 5)]) # 大于1且小于5print("d[(d < 0) | (d > 3)]:", d[(d < 0) | (d > 3)]) # 小于0或大于3print("d[~(d > 0)]:", d[~(d > 0)]) # 不大于0的元素(即<=0)# 3.3 条件修改print_section("3.3 条件修改", 2)e = d.copy()e[e < 0] = 0 # 将所有负数替换为0print("将负数替换为0后:", e)
2. 布尔索引:
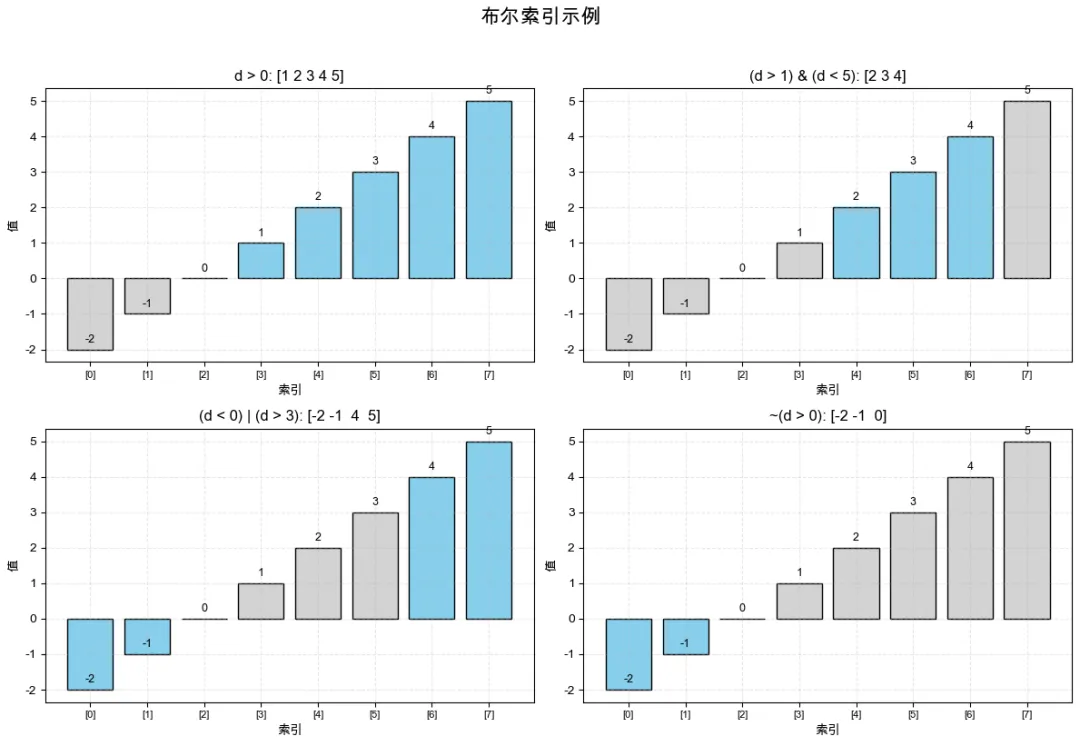
--
14-2-6 视图和副本
1️⃣视图和副本,是理解Numpy数组内存的重要概念。其中:
1. 视图:“共享”内存,如果修改视图,会影响原来的数组;
2. 副本:我理解为“另存为”,修改副本不影响原数组。
2️⃣关键代码:
# 4.1 创建示例print_section("4.1 视图与副本的区别", 2)original = np.array([1, 2, 3, 4, 5, 6])print("原始数组 original:", original)# 创建视图(切片)view = original[1:4] # 视图,共享数据print("\n创建视图: view = original[1:4]")print("视图 view:", view)# 创建副本copy = original[1:4].copy() # 副本,独立数据print("创建副本: copy = original[1:4].copy()")print("副本 copy:", copy)# 4.2 修改视图会影响原始数组print_section("4.2 修改视图会影响原始数组", 2)view[0] = 200print("修改 view[0] = 200 后:")print("视图 view:", view)print("原始数组 original:", original) # 原始数组被修改了!# 4.3 修改副本不会影响原始数组print_section("4.3 修改副本不会影响原始数组", 2)copy[0] = 888print("修改 copy[0] = 888 后:")print("副本 copy:", copy)print("原始数组 original:", original) # 原始数组不变# 4.4 检查内存共享print_section("4.4 检查内存共享", 2)print("np.may_share_memory(original, view):",np.may_share_memory(original, view)) # Trueprint("np.may_share_memory(original, copy):",np.may_share_memory(original, copy)) # False
3️⃣运行结果:
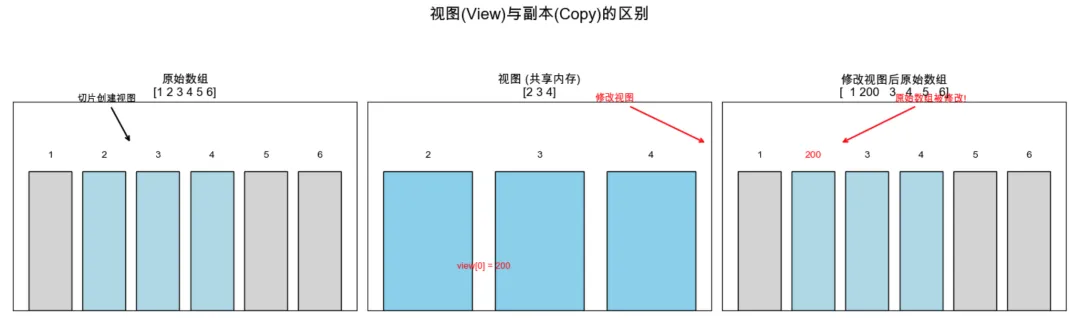
-
14-2-7 二维数组的索引和切片
1️⃣二维数组的索引和切片,与一维数组的类似,也可以通过【行的索引】以及【列的索引】来获取元素、行、列或子矩阵。
# 5.1 取出单一元素print_section("5.1 取出单一元素", 2)print("arr_2d[0, 0]:", arr_2d[0, 0]) # 第1行第1列: 1print("arr_2d[2, 3]:", arr_2d[2, 3]) # 第3行第4列: 12print("arr_2d[-1, -1]:", arr_2d[-1, -1]) # 最后一行最后一列: 16# 两种方式的区别print("\n两种索引方式的区别:")print("arr_2d[0][0]:", arr_2d[0][0]) # 先取行,再取列print("arr_2d[0, 0]:", arr_2d[0, 0]) # 直接行列索引print("两者结果相同,但 arr_2d[0][0] 实际上是两个操作")# 5.2 取出行print_section("5.2 取出行", 2)print("arr_2d[0]:", arr_2d[0]) # 第1行: [1, 2, 3, 4]print("arr_2d[0, :]:", arr_2d[0, :]) # 同上print("arr_2d[-1]:", arr_2d[-1]) # 最后一行: [13, 14, 15, 16]# 取多行print("\n取多行:")print("arr_2d[[0, 2]]:\n", arr_2d[[0, 2]]) # 第1行和第3行print("arr_2d[0:2]:\n", arr_2d[0:2]) # 第1行到第2行(不包含第3行)# 5.3 取出列print_section("5.3 取出列", 2)print("arr_2d[:, 0]:", arr_2d[:, 0]) # 第1列: [1, 5, 9, 13]print("arr_2d[:, -1]:", arr_2d[:, -1]) # 最后一列: [4, 8, 12, 16]# 取多列print("\n取多列:")print("arr_2d[:, [0, 2]]:\n", arr_2d[:, [0, 2]]) # 第1列和第3列print("arr_2d[:, 1:3]:\n", arr_2d[:, 1:3]) # 第2列到第3列# 5.4 取出子矩阵print_section("5.4 取出子矩阵", 2)print("arr_2d[1:3, 1:3]:\n", arr_2d[1:3, 1:3]) # 2x2子矩阵print("arr_2d[::2, ::2]:\n", arr_2d[::2, ::2]) # 隔行隔列取样
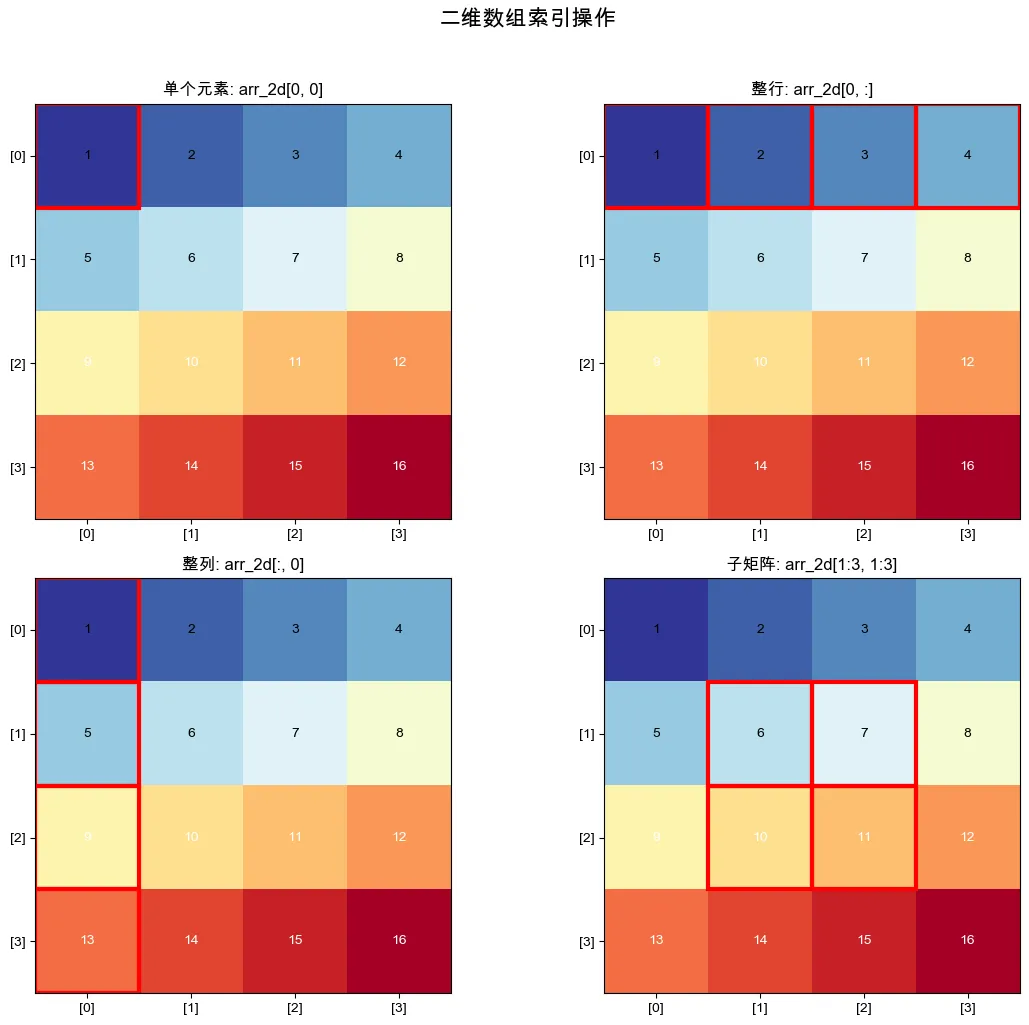
-
14-2-8 附:一些高级索引技巧
1️⃣一些技巧,可以让切片更加高效方便。举例:
1. 省略号(用于高维数组简化索引)
2. np.ix_(用于生成网格索引)
# 6.1 使用省略号(...)print_section("6.1 使用省略号(...)", 2)# 创建三维数组arr_3d = np.arange(24).reshape(2, 3, 4)print("三维数组 arr_3d 形状:", arr_3d.shape)print("第一个二维切片:")print(arr_3d[0])print("\n使用省略号:")print("arr_3d[..., 0]: 所有维度的第一个元素")print(arr_3d[..., 0])print("\narr_3d[0, ...]: 第一维的第一个元素")print(arr_3d[0, ...])# 6.2 使用np.ix_()进行网格索引print_section("6.2 使用np.ix_()进行网格索引", 2)matrix = np.array([[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]])
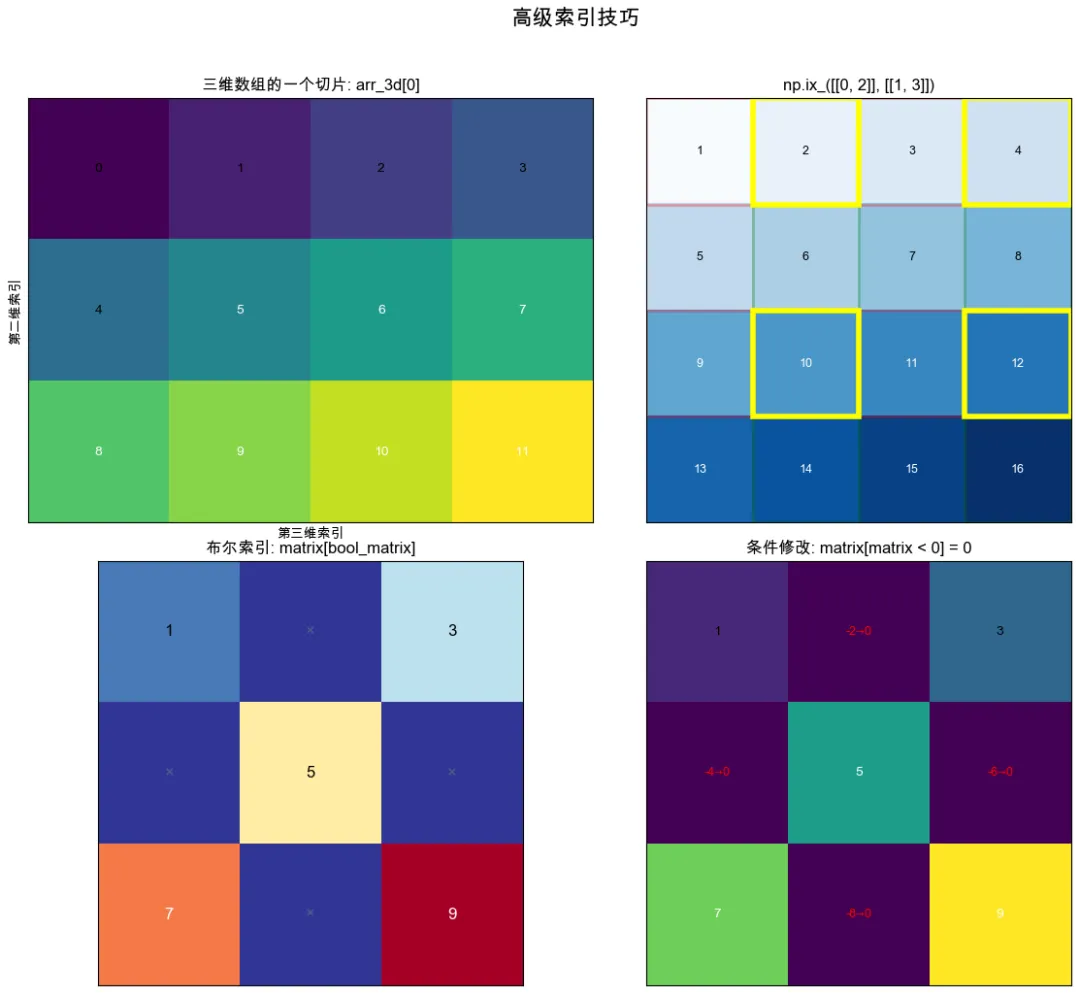
-
以上应用的#完整代码:见下方小程序码

--
学到这里,基本上第十四章的内容就结束了。
不难,但我还想知道:
Numpy 的索引和切片,在现实生活中还有什么作用?区分“视图”和“副本”有什么用?为什么要故意区分两者,所有都“另存为”不就足够安全了吗?
1️⃣求助AI编程教练,得到回复如下:

也就是说,对于不同的场景,的确有不同的需求,使用不同的工具,也就顺理成章了。
2️⃣接下来,了解一下现实生活中应用Numpy切片和索引的场景,包括以下场景:
1. 数据分析:可以用于Excel等电子表格的数据处理(筛选;找出大于某数的订单;按城市分类等)
2. 图像处理:可以用于裁剪和图片变化等(提取特定颜色;反转图片等)
3. 科学计算:可以用于处理实验数据(找出异常值、计算平均值、找出最热的一周等)
4. 游戏开发:确定地图和角色位置(例如用数组创建一个简单地图,然后玩家的位置就可以通过更新特定坐标,作为定位;也可以随机刷新地图数据周边属性,达到寻宝的效果)
3️⃣详细的伪代码实现,见小程序码:

4️⃣AI编程教练对以上概念的比喻小结:


--
今天就写到这里,果然练习生活实际去练习代码,理解和掌握的程度会更深一层。
另外,Head down,按部就班做好每天的练习,倦怠和疲惫是正常的,这也是每天的枯燥练习的意义所在,不锻炼无法增长肉体和思维的肌肉,继续期待量变导致质变的一天~
写于2026年1月6日00:38:29。
--
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 用 Rust 写加载器,用 Python 画界面;签名、沙箱、杀软,一条龙绕过.
- 【AI基石】Python 基础篇:AI 工程师眼中的“方言” —— 从列表到张量的思维跃迁
- 下载!“新课家”第3次活动【Python环境与项目实例】
- 案例合集│Python漫游数学王国——离散数学与组合数学
- Python入门教程(非常详细)从零基础入门到精通,看完这一篇就够了
- 使用Python合并PDF文件
- Python在数学上的应用:零基础也能玩转的实用技巧
- 小白学 Python 计算:除法、取模、四舍五入的小规则
- Python Flask 模板传值给前端页面
- Python版_Leetcode_hot100系列(10)--回溯
