1. 引言
Linux 图形与显示是一套分层清晰、模块化程度极高的复杂分层系统,其设计的核心优势在于能够灵活适配从低功耗嵌入式设备到高性能图形工作站的各类硬件平台,其核心使命是充当应用程序与图形硬件之间的桥梁,它负责高效地传递渲染指令、管理图形缓冲区、配置显示模式,并最终将绚丽的图像呈现在屏幕上。
Linux 图形与显示系统通过标准化的图形 API(如 OpenGL, Vulkan)和统一的内核驱动接口(DRM/KMS),实现了对多样化硬件和显示系统(如 X11, Wayland)的广泛支持。无论是进行图形与显示驱动开发、优化应用性能,还是定位渲染与显示问题,深入理解这一架构都至关重要。
本文将从宏观视角出发,系统性地剖析 Linux 图形与显示系统,内容涵盖:
2. 软件栈架构
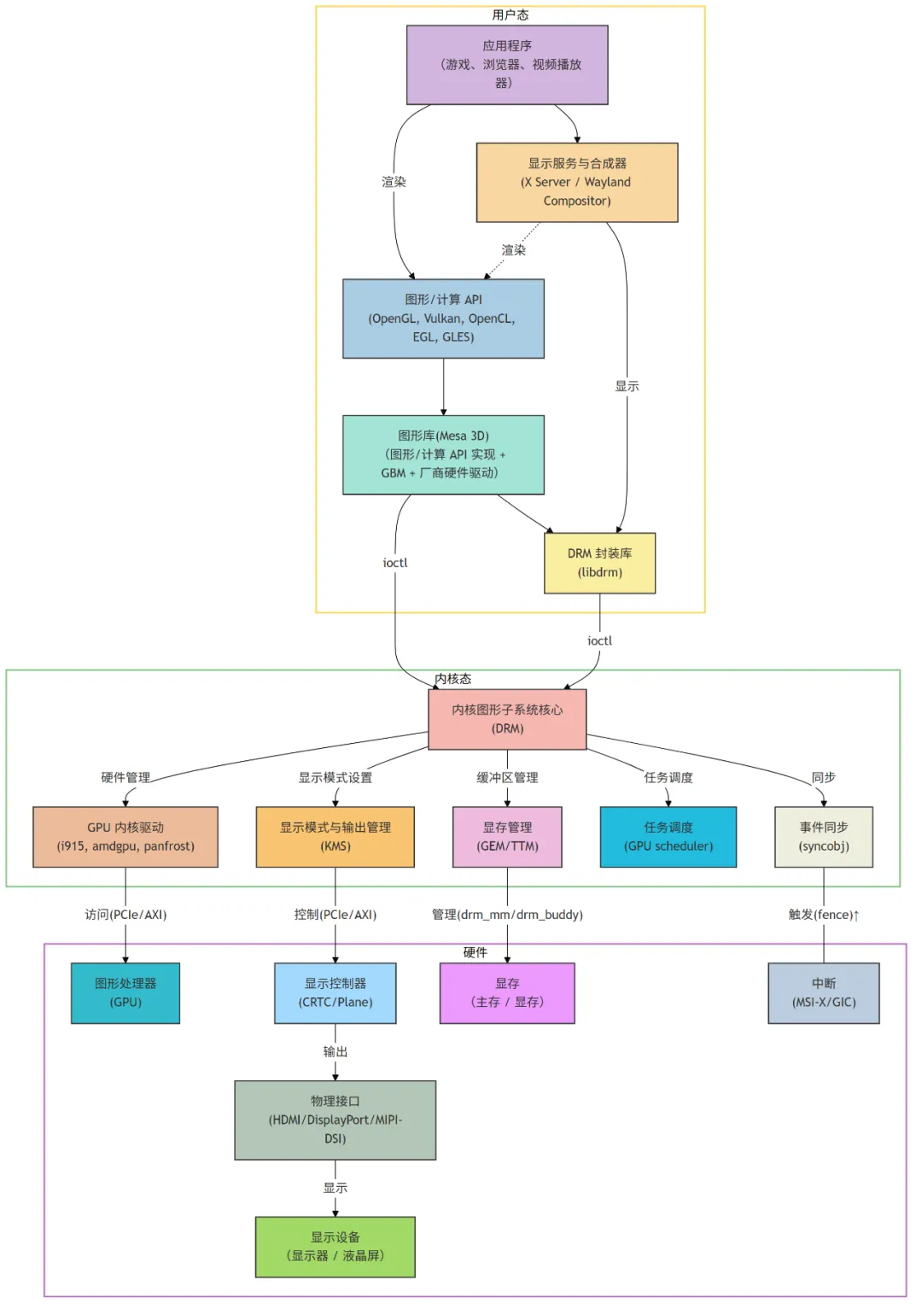
Linux 图形栈在逻辑上被清晰地划分为 用户态(User Space) 和 内核态(Kernel Space) 两大部分,每一部分都包含多个协同工作的组件,二者通过稳定的系统调用(主要是 ioctl)进行通信。
- 用户态:面向应用程序,提供图形 API 库、显示服务和 DRM 封装库。它负责将应用的渲染需求(例如:“画一个三角形”)转换为具体的硬件指令。
- 内核态:作为硬件的直接管理者,负责执行最终的硬件操作,包含 DRM 框架和各个硬件厂商的 GPU/DPU 驱动。它处理显存管理、显示模式设置、GPU 命令提交和中断响应,并确保多任务环境下的资源安全与隔离。
Linux 图形栈架构分层图:
3. 核心组件详解
IOCTL 接口:用户态(如 Mesa)与 DRM 内核驱动之间通信的主要方式。所有的操作,如提交渲染指令、申请显存、设置显示模式等,都是通过 ioctl 系统调用完成的。
DRM(Direct Rendering Manager):DRM 是 Linux 内核中图形与显示驱动的总框架。它为用户态提供了一个统一的、安全的接口,用于提交渲染命令、管理图形缓冲区和设置显示模式。
KMS(Kernel Mode Setting):作为 DRM 的一部分,KMS 负责管理所有的显示功能。这包括枚举显示器、查询支持的分辨率和刷新率、设置显示模式(Mode Setting)以及控制 CRTC、Encoder 和 Connector 等显示管线对象。将模式设置移入内核是现代 Linux 图形栈的基石,它带来了更快的启动画面、更可靠的热插拔和更高的安全性。
- FB(Framebuffer):一块内存,存储了要显示的像素数据。
- Plane:一个硬件图层,可以从 Framebuffer 中拾取数据进行显示。现代 GPU 通常有多个 Plane,可以实现硬件级别的画面叠加(Overlay)。
- CRTC(CRT Controller):一个显示控制器(Display Controller(DC)/Display Processing Unit(DPU)),它绑定一个或多个 Plane,从这些 Plane 中合成最终画面,并按照设定的分辨率和刷新率(Mode),生成视频时序信号。
- Encoder:将 CRTC 生成的数字视频信号编码成特定格式(如 HDMI 或 DisplayPort)。
- Connector:代表一个物理输出端口。它负责探测显示器的连接状态和支持的模式(EDID)。
显存管理:GEM(Graphics Execution Manager)/TTM(Translation Table Maps)是 DRM 内核框架中的两大内存管理器,负责高效、安全地分配、释放和共享显存缓冲区。
- GEM:设计相对简单,主要用于管理和共享图形数据缓冲(Buffer Object),在集成显卡中广泛使用。
- TTM:功能更复杂,设计初衷是同时管理独立显存和系统内存,在独立显卡中更为常见。它们共同的目标是为用户态安全、高效地分配和共享显存。
- drm_mm:DRM 子系统中一种通用内存管理器,用于管理设备内存(如 GPU 显存)的动态分配和释放。
- drm_buddy:基于伙伴内存分配算法(Buddy Allocator)的内存管理器实现,用于 DRM 子系统中管理 GPU 内存。
GPU Scheduler:GPU Scheduler(GPU 调度器)用于管理和调配 GPU 计算资源,主要负责协调多个 GPU 任务/作业的执行顺序和资源分配,以保证 GPU 高效、合理、公平地被多个应用程序或进程使用。
事件同步:DRM Syncobj(同步对象)是 DRM 子系统提供的一种同步原语,用于在 GPU 驱动、用户空间和不同进程之间实现显式的同步操作。
显示服务:显示服务是指系统层面管理显示设备、图层数据、窗口管理和图形输出的模块。它协调应用程序与底层显示硬件之间的交互,确保内容正确显示在屏幕上。
- Xserver:早期和主流的 Linux 桌面图形显示服务,管理窗口、图层、输入事件等。
- Wayland:现代 Linux 图形协议,取代传统 X11 的显示服务,实现更高效和安全的窗口管理。
- Framebuffer(fbdev):最基础的 Linux 显示驱动,只实现简单的帧缓冲显示,缺乏高级窗口和图层管理。
合成器(Compositor):合成器负责将多个应用窗口或图层的数据合成到最终输出帧,是现代显示架构中的关键环节。
- Xserver:通过扩展(composite extension,compiz、xcompmgr 等)实现窗口合成、特效渲染。Xserver 自身只做基本管理,复杂合成由扩展和窗口管理器实现。
- Wayland:Wayland 协议下核心组件,如 Weston、KWin、Mutter 等,不仅做窗口管理,还直接负责图层合成输出。Wayland 合成器多使用 OpenGL/ES 或 Vulkan 做 GPU 加速合成。
- Framebuffer(fbdev):一般无专门合成器,应用直接写帧缓冲,画面合成依赖上层应用。
Mesa 3D:这是一个开源的用户态图形驱动集合,它实现了 OpenGL、Vulkan 等多个图形 API。当应用程序调用 glDraw* 时,Mesa 会将其翻译成特定 GPU 的硬件指令,然后通过 DRM 接口提交给内核执行。
OpenGL 驱动:大部分现代 OpenGL 驱动构建于 Gallium3D 框架之上。Gallium 提供了一套统一的中间层(IR),使得为新硬件编写驱动更加便捷。例如,Intel 的 Iris 驱动、AMD 的 RadeonSI 驱动。
Vulkan 驱动:Vulkan 驱动不使用 Gallium 框架,它们是独立的、更接近硬件的实现,以获得更高的性能和更低的开销。例如,Intel 的 ANV 和 AMD 的 RADV。
GBM(Generic Buffer Management):这是 Mesa 提供的一个重要的 API,它提供了一种“无窗口”的、通用的方式来申请和管理可用于渲染的图形缓冲区(Buffer)。Wayland 合成器严重依赖 GBM 来从客户端获取渲染好的内容进行合成。
libdrm:一个用户态库,它封装了对 DRM 驱动的 ioctl 调用,为 Mesa 等上层库提供了更便捷的函数式 API,避免了直接操作复杂的 ioctl 命令。
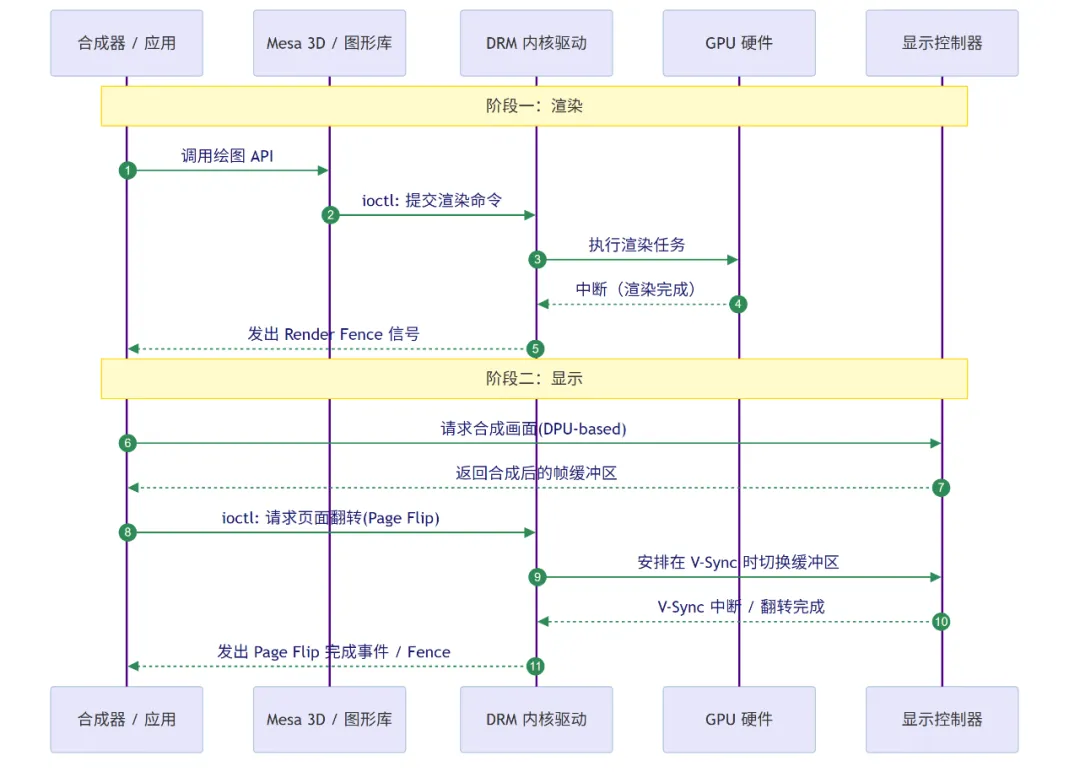
4. 渲染与显示完整流程
Linux 图形栈中一次完整的“绘制并显示”交互,可分为两大阶段:渲染阶段和显示阶段。二者通过同步对象(Fence)衔接,确保在画面渲染完成后才将其送去显示。
让我们通过一个简化的例子(Wayland 场景),将所有组件串联起来,看看一个 3D 应用的画面是如何最终显示在屏幕上的:
阶段一:渲染阶段(生成画面)
此阶段的目标是让 GPU 执行绘图指令,生成一帧新的画面。
- 初始化:应用程序启动,通过
EGL API 连接到合成器(Compositor)。Compositor 通过 GBM 为应用程序创建一个可供渲染的共享缓冲区(gbm_bo)。Mesa 的 EGL 实现内部通过 DRM 的 ioctl 调用,在显存中分配了这块缓冲区,并将其句柄(dma-buf fd)返回给 Compositor。 - 命令构建:应用程序(如游戏)或合成器调用 OpenGL/Vulkan API(例如
glDrawArrays())进行场景绘制。Mesa 3D 库接收这些调用,对应的 GPU 驱动(如 Iris)将这些 API 调用翻译成 GPU 硬件指令,并写入一个命令缓冲区(Command Buffer)。 - 提交内核:Mesa 通过 libdrm 库调用
ioctl 接口,将命令缓冲以及相关的图形资源(如纹理、顶点数据)的引用提交给内核中的 DRM 驱动。 - 硬件执行:内核驱动验证命令后,通过 GEM/TTM 管理器,将命令缓冲和资源映射到 GPU 可访问的地址空间。随后,驱动命令 GPU 开始执行渲染任务。
- 渲染完成通知:GPU 完成渲染后,将结果写入之前分配好的共享缓冲区中,产生一个硬件中断。内核驱动捕获此中断,并触发一个与该渲染任务关联的渲染围栏(Render Fence),标志着该帧画面已在内存中准备就绪。
阶段二:显示阶段(送上屏幕)
此阶段的目标是将已渲染好的画面缓冲区(Framebuffer)提交给显示控制器,让其显示在屏幕上。
- 提交与合成:应用程序渲染完成后,通知合成器(Compositor):“我已经画完了,可以显示了”。合成器(Compositor) 收到通知,知道这个应用程序的窗口内容已经更新。Compositor 自身也是一个图形应用(通常是 OpenGL ES),它会将所有可见窗口(包括我们刚渲染完的那个)以及它自己的 UI 元素(如面板、鼠标指针)合成为最终的一帧画面。合成器决定由 DPU 还是 GPU 来完成合成任务,如果设备有 DPU,合成任务优先交给 DPU 完成,提高能效和性能,如果没有专用 DPU,则合成任务可能由 GPU 继续完成。合成过程不涉及复杂 3D 渲染,更多是 2D 图层混合操作。
- 请求页面翻转:用户态的合成器(Compositor)或应用在确认“渲染围栏”已触发后,向 DRM 驱动发起一个页面翻转(Page Flip)的
ioctl 请求,本质上是告诉 KMS:“请将屏幕 CRTC 的 Plane 指向这个新的、已经合成好的帧缓冲(Framebuffer)区”。此请求包含了新画面的缓冲区地址,并指定在下一个垂直同步信号(V-Sync)到来时执行。 - 调度显示任务:DRM/KMS 驱动收到请求后,不会立即改变显示内容,而是将这个“页面翻转”任务进行排程,等待显示硬件的 V-Sync 信号。
- 执行页面翻转:当下一次显示器发送垂直同步(V-Sync)信号时,显示控制器(CRTC)硬件会原子性地切换到读取新的缓冲区地址,开始逐行扫描新画面的内容,并通过 Encoder 和 Connector 发送到显示器进行显示。这避免了画面撕裂。
- 屏幕显示完成:页面翻转操作完成后,内核会触发另一个显示围栏(Display Fence 或 VBlank Event),通知用户态程序本次显示更新已完成。
至此,用户便在屏幕上看到了应用程序渲染出的新一帧画面。整个过程高效地在用户态和内核态之间流转,充分利用了硬件的加速能力。
完整交互时序图:
5. 图形数据的流转路径
从一个像素在代码中定义到它最终在屏幕上亮起,其数据流经了多个环节:
数据流详解:
- 应用 -> 合成器:应用将需要绘制的窗口内容(Buffer)提交给显示服务器(如 Wayland Compositor)。
- 合成器 -> 图形库:合成器负责将所有窗口(来自不同应用)以及 UI 元素(如鼠标指针)组合成最终的一帧画面。这个合成过程本身也是通过调用 OpenGL/Vulkan API,由 Mesa 等图形库来完成的。
- 图形库 -> 驱动:Mesa 将合成任务转换为硬件指令,通过
ioctl 提交给 DRM 驱动。 - 驱动 -> GPU:DRM 驱动命令 GPU 执行渲染,最终的合成画面被写入位于显存中的一块特定区域,即帧缓冲。
- 显存 -> 显示控制器:显示控制器按照 KMS 设定的模式(分辨率、刷新率),周期性地从显存中读取帧缓冲的数据。它还可能执行硬件光标、覆层(Overlay)混合或色彩校正等操作。
- 显示控制器 -> 编码器:显示控制器将像素数据流发送给编码器(Encoder)。
- 编码器 -> 显示器:编码器将像素数据转换为特定显示协议的电信号(如 HDMI、DisplayPort 或 MIPI-DSI 信号),通过物理接口驱动显示器面板发光。
6. SoC 与 PC 平台架构差异
虽然共享同一套 Linux 驱动模型,但面向移动/嵌入式的 SoC 平台与传统的 PC 平台在硬件实现上有显著差异。
| | |
|---|
| GPU 类型 | 高度集成的片上 GPU(Mali, Adreno) | 独立 GPU(dGPU): NVIDIA, AMD;集成 GPU(iGPU): Intel, AMD APU。 |
| 内存架构 | 统一内存架构(UMA):CPU/GPU 共享物理 RAM,访问延迟低。 | dGPU: 独立的板载显存(VRAM) + 系统内存,通过 PCIe 总线通信;iGPU: 与 SoC 类似,采用 UMA 架构共享系统内存。 |
| 显示控制器 | 通常是独立的硬件 IP(称为 DPU 或 DC),与 GPU 解耦。 | |
| 视频编解码 | | 主要由 GPU 内的专用解码/编码模块或 CPU 提供加速 |
| IOMMU/SMMU | 普遍使用,用于隔离和地址翻译,对多媒体处理至关重要。 | dGPU: 通常自带地址转换逻辑,系统 IOMMU(VT-d) 可选使用;iGPU: 使用系统 IOMMU(VT-d)/GTT。 |
| 功耗管理 | 设计核心考量。精细的动态电压频率调整(DVFS)、时钟门控和功耗岛技术。 | |
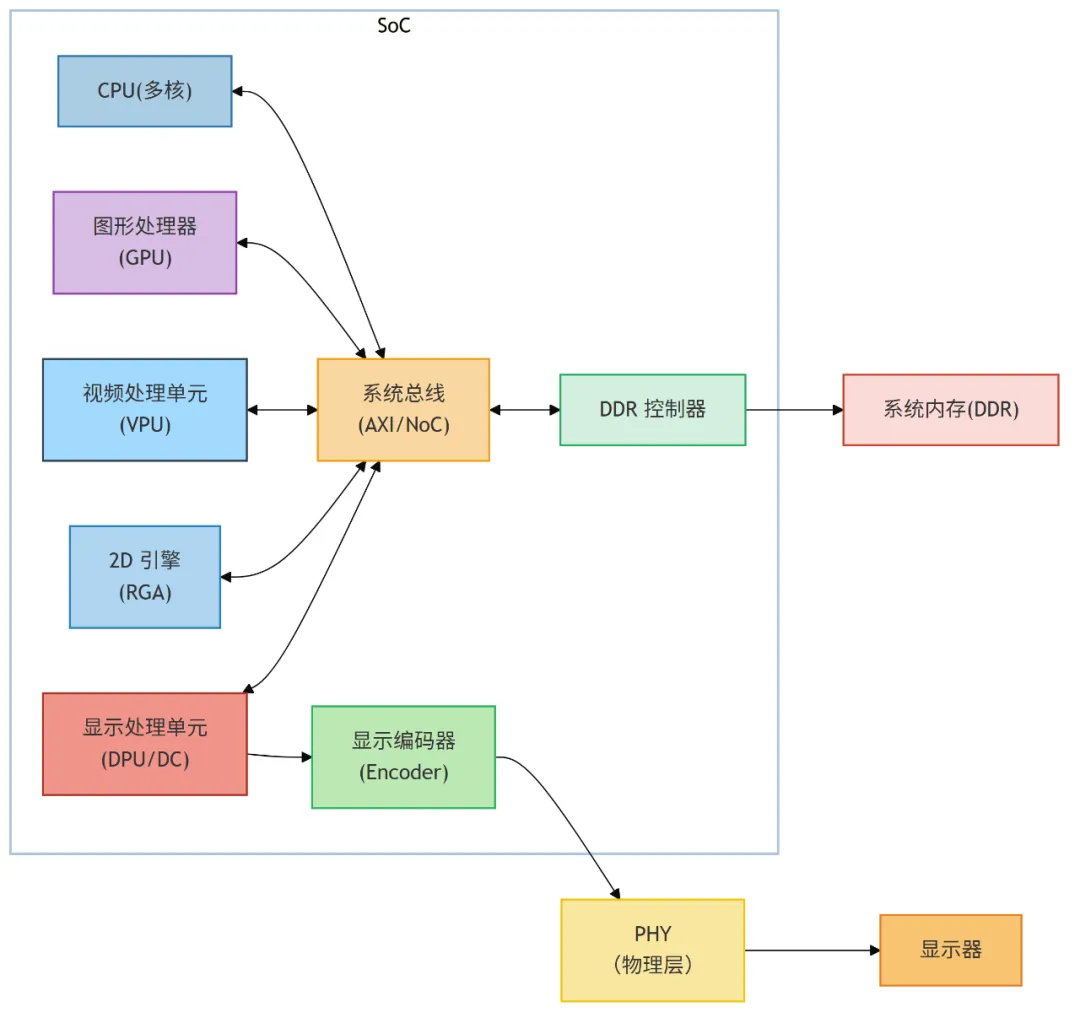
7. SoC 硬件连接拓扑
下图展示了一个典型的嵌入式 SoC(片上系统)内部,围绕图形和显示功能的硬件模块是如何互连的。
核心关系:CPU、GPU、DPU、VPU、RGA 等多个处理单元通过高速总线(如 AXI)共享对系统内存的访问。CPU 负责任务调度和命令提交,GPU 负责图形渲染,VPU 负责视频编解码,RGA 负责 2D 图像加速,DPU 负责最终的画面合成与时序生成。
8. 总结
本文对 Linux 图形与显示架构进行了系统性的梳理和完善,可以总结为以下几点:
- Mesa 为核心:Mesa 3D 是连接上层图形 API 和底层内核驱动的枢纽,其内部的 Gallium3D 架构和 OpenGL/Vulkan 驱动是硬件加速的关键。
- DRM/KMS 为基石:DRM/KMS 框架为整个 Linux 图形显示提供了统一、强大的底层支持,是实现跨硬件平台兼容性的保证。现代架构由内核全面接管模式设置(KMS)和内存管理(GEM/TTM),提升了系统的稳定性和安全性。
- 分层解耦:用户态(应用、合成器、Mesa)与内核态(DRM/KMS)职责分明,用户态负责 API 实现和逻辑控制,内核态负责硬件抽象和资源管理,二者通过
DRM IOCTL 接口高效协作,实现了硬件的抽象和隔离。 - 现代趋势:Wayland 以其更现代、高效和安全的设计,正在全面取代陈旧的 X11 架构。
- 标准化流程:从命令构建、提交、执行到完成通知(Fence),软件与硬件的交互遵循一套标准且高效的模型。
- 平台差异性:SoC 和 PC 平台在内存架构、组件集成度和功耗策略上存在本质区别,但都统一在 DRM 驱动框架之下。
- 数据流清晰:图形数据从应用出发,经由合成器、GPU 渲染生成帧缓冲,最终由显示控制器读取并通过编码器送上屏幕,路径明确。
理解这一整套体系,可以更深刻地把握 Linux 图形系统的运作原理,对于在 Linux 环境下进行图形开发、性能优化或问题排查都至关重要。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
