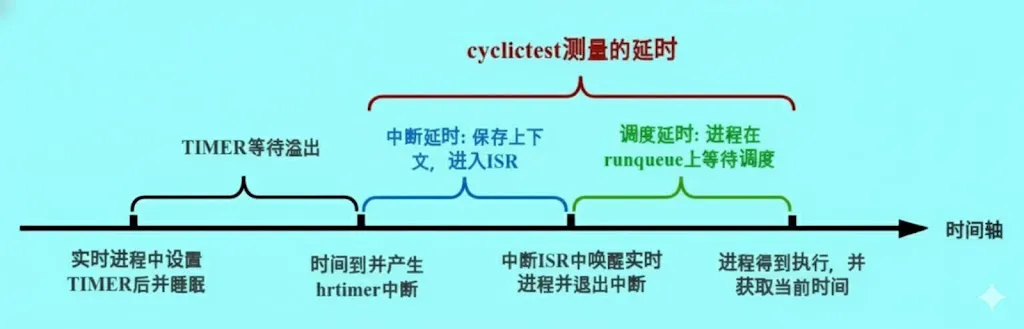
cyclictest 创建指定数量和优先级的实时进程。这些进程会设置一个定时器来周期性地唤醒自己。
从定时器溢出触发中断进入 ISR 调用 wake_up_process() 唤醒实时进程,到进程真正开始运行,这中间的时间就是我们需要测量的延迟。
实时进程恢复运行后,会获取当前系统时间,减去睡眠开始时的时间和睡眠持续时间,即可得到延迟时间。
那么,造成延迟过高的原因有哪些呢?
1. 硬中断干扰或关闭中断。当 cyclictest 应该被唤醒时,CPU 正在执行中断处理函数(会自动关闭中断),或者代码主动关闭了中断,导致延迟过高。2. 调度延迟。cyclictest 已经被唤醒(状态变为 R),但 runqueue 中有优先级更高的线程,导致 cyclictest 无法获得 CPU。3. 关闭抢占。当 cyclictest 应该被唤醒时,定时器中断可以触发,但无法调度到 cyclictest 进程。4. 硬件黑洞。在 ARM64 架构中,内核运行在 EL1,虚拟化运行在 EL2,安全固件运行在 EL3。当系统调用陷入 EL2 或 EL3 时,Linux 内核完全停止运行,且内核无法感知。为了更深入地理解这些场景,我们通过实际操作来重现它们。
硬中断干扰/关闭中断
首先克隆项目:
> git clone https://github.com/hlleng/rt_test_noise> cd irq_noise && make> sudo insmod irq_noise.ko> sudo ./trace_irq_noise.sh
如果缺少某些 event,请在 config 中打开。使用 cyclictest 来测试性能:
> for i in 0 1 2 3; do echo performance > /sys/devices/system/cpu/cpu$i/cpufreq/scaling_governor; done> sudo cyclictest -t 1 -a 0 -p 80 -D 5m -b 3000 --tracemark # 如果没有,请安装rt-tests> echo 3000 | taskset -c 0 tee /proc/inject_irq_latency
逐步解释这三句命令:
第一句:设置调频策略为 performance,防止调频干扰。CPU 数量请根据实际情况修改。如果使用默认的 ondemand策略,CPU 利用率增加时会提高频率,这会增加延迟。
第二句:使用 cyclictest 测试延迟
• -t 1 -a 0:为减少信息量,只启动一个线程,绑定在 CPU0 上• -p 80:设置线程优先级为 80,策略是 SCHED_FIFO• -b 3000 --tracemark:当延迟超过 3000us 时,停止 ftrace 采样和 cyclictest 测试,并在日志中写入tracing_mark_write: hit latency threshold如果没有指定 -i,默认每 1000us 唤醒一次线程
第三句:向 irq_noise 模块写入数据,制造一个 3000us 的延迟。如果没有触发 cyclictest 停止,可以多写入几次,具体原因将在下文解释。
如果一切顺利,会出现以下日志,表明延迟超过了 3000us:
> sudo cyclictest -t 1 -a 0 -p 80 -D 5m -b 3000 --tracemark# /dev/cpu_dma_latency set to 0usINFO: debugfs mountpoint: /sys/kernel/debug/tracing/policy: fifo: loadavg: 0.73 0.91 0.53 2/364 8160T: 0 ( 8148) P:80 I:1000 C: 6003 Min: 30 Act: 49 Avg: 45 Max: 2838# Thread Ids: 08148# Break thread: 8148# Break value: 3157
为了方便阅读,我们将日志导出为 txt 文件:
> cat trace > /tmp/trace_irq.txt
接下来解读几份 trace 日志。
tee-8160 [000] dNh.. 856.208920: sched_wakeup: comm=cyclictest pid=8148 prio=19 target_cpu=000 tee-8160 [000] dNh.. 856.208923: hrtimer_expire_exit: hrtimer=000000005c8f967e tee-8160 [000] dNh.. 856.208926: irq_handler_exit: irq=23 ret=handled tee-8160 [000] d.... 856.208954: sched_switch: prev_comm=tee prev_pid=8160 prev_prio=120 prev_state=R ==> next_comm=cyclictest next_pid=8148 next_prio=19 cyclictest-8148 [000] d.... 856.208990: sched_switch: prev_comm=cyclictest prev_pid=8148 prev_prio=19 prev_state=S ==> next_comm=tee next_pid=8160 next_prio=120 tee-8160 [000] d.h.. 856.209894: irq_handler_entry: irq=23 name=arch_timer tee-8160 [000] d.h.. 856.209898: hrtimer_expire_entry: hrtimer=0000000086669db1 function=timer_callback [irq_noise] now=856211171021 tee-8160 [000] d.h.. 856.212940: hrtimer_expire_exit: hrtimer=0000000086669db1 tee-8160 [000] d.h.. 856.212944: hrtimer_expire_entry: hrtimer=000000005c8f967e function=hrtimer_wakeup now=856214218069 tee-8160 [000] dNh.. 856.212957: sched_wakeup: comm=cyclictest pid=8148 prio=19 target_cpu=000 tee-8160 [000] dNh.. 856.212959: hrtimer_expire_exit: hrtimer=000000005c8f967e tee-8160 [000] dNh.. 856.212961: hrtimer_expire_entry: hrtimer=00000000c5b1b039 function=tick_sched_timer now=856214218069 tee-8160 [000] dNh.. 856.212991: hrtimer_expire_exit: hrtimer=00000000c5b1b039 tee-8160 [000] dNh.. 856.212994: hrtimer_expire_entry: hrtimer=000000009ea9d197 function=hrtimer_wakeup now=856214218069 tee-8160 [000] dNh.. 856.213008: sched_wakeup: comm=cyclictest pid=8147 prio=120 target_cpu=000 tee-8160 [000] dNh.. 856.213010: hrtimer_expire_exit: hrtimer=000000009ea9d197 tee-8160 [000] dNh.. 856.213012: irq_handler_exit: irq=23 ret=handled tee-8160 [000] d.... 856.213036: sched_switch: prev_comm=tee prev_pid=8160 prev_prio=120 prev_state=R ==> next_comm=cyclictest next_pid=8148 next_prio=19 cyclictest-8148 [000] ..... 856.213140: tracing_mark_write: hit latency threshold (3157 > 3000)
sched_wakeup 的发生时机:进程(或线程)从阻塞状态被唤醒,加入可运行队列(runqueue)时触发。
sched_switch 的发生时机:调度器决定将 CPU 从一个进程(prev)切换到另一个进程(next)时触发,next 进程开始在 CPU 上执行。
从日志的最后一行可以看到,线程 cyclictest-8148 的延迟超过了 3000us,因此我们把关键词锁定为 cyclictest-8148。
856.212957: sched_wakeup 将 cyclictest-8148 添加到 runqueue 中。
856.213036: sched_switch 正式执行 cyclictest-8148 线程。
两者的差值为 79us,是一个合理的数值。
接着看上一次的 cyclictest-8148。
856.208920: sched_wakeup 将 cyclictest-8148 添加到 runqueue 中。因为间隔是 1ms(1000us),所以理论上下一次唤醒时间应该是 856.209920 左右。
注意,在 856.209898 时刻,就在 cyclictest 马上要醒来的时候(还差 ~22us),irq_noise 模块触发了,CPU 进入硬中断上下文(d.h..),并开始执行死循环忙等。
irq_noise 的持续时间:856.209898(hrtimer_expire_entry)→ 856.212940(hrtimer_expire_exit)。
差值为 3042us,与我们在用户态输入的 3000us 相差无几。由于回调函数是忙等,在 entry 和 exit 之间没有其他业务执行。
如果上面的文字描述难以阅读,不妨看一下下面的流程图:
[ 上次休眠 sched_switch ] (Timestamp: 856.208990) | | (cyclictest 睡眠,预计 1ms 后唤醒) v . . 时间流逝 ... . |(就在理论唤醒点之前 856.209894) -> [ irq_handler_entry (硬件定时器中断触发) ] |(856.209898) -> [ hrtimer_expire_entry (irq_noise 回调开始) ] | v+=========================================================================+| *** 严重阻塞区域 (硬中断上下文) *** || || [ 理论唤醒点 T_expected (~856.2099xx) ] <-- 本该在此刻唤醒 || (由于下方的高优先级忙等,此唤醒被推迟) || || ..................................................................... || . . || . [ IRQ NOISE 霸占 CPU (死循环忙等) ] . || . . || . 持续时长: 3042 us . || . . || ..................................................................... || |+=========================================================================+ |(856.212940) -> [ hrtimer_expire_exit (irq_noise 回调结束,释放 CPU) ] | v(856.212957) -> [ 实际唤醒 sched_wakeup ] (cyclictest 加入 runqueue) | | (调度延迟: 79us) |(856.213036) -> [ 实际执行 sched_switch ] (cyclictest 开始运行,检测到高延迟)
为什么不是 100% 触发成功呢?这是因为注入的延迟是 3000us,报警阈值(-b)也是 3000us,而 cyclictest 的周期是 1000us。这导致了 相位对齐 问题。
举个简单的例子:
cyclictest 计划在 T=1000 醒来,执行到 T=1001,然后睡眠。cyclictest 在 T=1001 正常运行完,去睡觉,计划下次在 T=2001 醒来。cyclictest 在 T=4002 中断结束后醒来。计算延迟:4002(实际)- 2001(计划)= 2001。结果:延迟只有 2ms 左右,远低于 3000us 阈值。MISS!如果想 100% 触发,需要注入 4500us。这样最坏情况下也是 4.5 - 1 = 3.5ms,必然超过 3000us。
调度延迟/抢占延迟
接下来我们看场景二——调度延迟。这个场景很好理解:
当 cyclictest 的定时器到期时,内核调用 sched_wakeup 将 cyclictest 加入 runqueue。
但由于有更高优先级的线程排在 cyclictest 前面,所以必须先运行高优先级线程,才能轮到 cyclictest。
[ 上次休眠 sched_switch ] (cyclictest 释放 CPU 进入睡眠) | | (cyclictest 睡眠中...) | (此时 CPU 上运行着其他任务,例如一个较低优先级的普通进程) v . . 时间流逝 ... . |(理论唤醒点 T_expected 到达) -> [ 定时器中断触发 ] (内核进入中断处理) | v(中断上下文中) -> [ 核心事件: sched_wakeup (cyclictest) ] | | 说明: 此时 cyclictest 状态由 SLEEPING 变为 RUNNABLE。 | 它被挂入了 CPU 的运行队列 (Runqueue),**准备好**执行了。 | v+=========================================================================+| *** 调度阻塞区域 (Scheduling Blocked Region) *** || || [ 关键冲突 ]:CPU 并未立即切换到 cyclictest。 || || ..................................................................... || . . || . [ 障碍:更高优先级的任务 (Higher Priority Task) 正在运行 ] . || . (例如:一个实时进程,或者内核自身的紧急线程,如 migration/0) . || . . || . ------------------------------------------------------------- . || . >> cyclictest 状态:就绪 (Runnable) . || . >> cyclictest 位置:在运行队列 (Runqueue) 中排队等待 CPU . || . ------------------------------------------------------------- . || . . || ..................................................................... || || (这段等待时间构成了主要的调度延迟) |+=========================================================================+ | | (高优先级任务终于执行完毕,或主动让出了 CPU) v[ 调度器介入 (Scheduler runs) ] (挑选下一个最合适的任务) | v[ 核心事件: sched_switch ] (上下文切换:Prev_High_Prio ==> Next_cyclictest) | v(cyclictest 终于获得 CPU 开始实际执行代码,计算并报告延迟)
我们使用 stress-ng 来模拟:
# stress-ng 使用默认的 SCHED_OTHER (普通进程)> sudo taskset -c 0 stress-ng --cpu 1 --timeout 600s &# 运行 cyclictest> sudo cyclictest -t 1 -a 0 -p 80 -D 5m -b 3000policy: fifo: loadavg: 0.17 0.17 0.10 1/301 1695T: 0 ( 1498) P:80 I:1000 C: 299994 Min: 11 Act: 53 Avg: 31 Max: 698
由于没有打PREEMPT_RT补丁,所以这个数据很一般。
我们在试一下,如果优先级stress-ng优先级高于cyclictest
# stress-ng使用SCHED_FIFO,优先级高于cyclictes> sudo taskset -c 0 stress-ng --cpu 1 --sched fifo --sched-prio 90 --timeout 600s &> sudo cyclictest -t 1 -a 0 -p 80 -D 5m -b 3000 --tracemark
可以看到,cyclictest 基本无法输出数据,因为此时 CPU 被 stress-ng 占满了。直到 stress-ng 进程超时退出,cyclictest 才能运行。
关闭抢占
接下来看一下第三种场景,其实站在用户态而言,两个场景几乎一模一样,它们导致的结果都是:
CPU 处于“不可调度”状态,Cyclictest 即使时间到了、优先级再高,也拿不到 CPU。
不过,从内核实现和排查视角来看,它们有微妙但至关重要的区别。我们可以把这称为“同一种死法,不同的凶手”。
它们到底有什么区别?(内核层),我们可以通过一个“霸权等级金字塔”来理解它们的区别。等级越高,越能打断低等级的执行。
/ \ / \ / Level 1 \ <-- 硬中断 / 关中断 (Hard IRQ) / (最高特权) \ (谁都打不断,导致硬中断延迟) /______________\ / \ / Level 2 \ <-- 关抢占 / 自旋锁 (Preempt Off) / (调度器失效) \ (中断能进,但不能切换任务) /____________________\ / \ / Level 3 \ <-- 普通进程 / 实时进程 / (可被随意抢占) \ (受制于优先级调度) /__________________________\
如果已经clone了rt_test_noise仓库,
> for i in 0 1 2 3; do echo performance > /sys/devices/system/cpu/cpu$i/cpufreq/scaling_governor; done> sudo cyclictest -t 1 -a 0 -p 80 -D 5m -b 3000 --tracemark # 如果没有,请安装rt-tests> sudo ./trace_preemptirqoff.sh> echo 3500 | taskset -c 0 tee /proc/inject_preempt_latency
查看最大的延迟:
> cat tracing_max_latency3507
可以看到,最大延迟是3507,与我们输入3500相差无几。
接下来看下详细的日志,完整日志有点长,放在链接中。
https://pastebin.com/CJfv4VT9
我们将日志分为三个阶段:关闭抢占、中间插曲、开启抢占。
第一阶段:关闭抢占
k_preemp-1645 0...1. 1us : preempt_count_add <-preempt_count_addk_preemp-1645 0...1. 2us : __udelay <-thread_fn
我们需要关注0...1.标志位,其实 1 为 preempt depth,表示现在抢占计数器是 1(即禁止抢占)。
需要注意的是,可以抢占的前提是 preempt pepth 为 0。由于我们绑定在了CPU0,所以日志只显示 CPU0。
第二阶段:中间插曲
在 362us 时,CPU0 触发了一次中断:
k_preemp-1645 0d..1. 362us : irq_enter_rcu <-el1_interrupt...k_preemp-1645 0d.h1. 375us : arch_timer_handler_phys <-handle_percpu_devid_irq
我们可以看到触发了定时器中断,是什么原因触发的定时器中断呢?接着看后面的日志:
k_preemp-1645 0d.h1. 389us : hrtimer_wakeup <-__hrtimer_run_queuesk_preemp-1645 0d.h1. 391us : try_to_wake_up <-wake_up_process...k_preemp-1645 0d.h4. 411us : enqueue_task_rt <-enqueue_task
定时器中断发现 cyclictest 该醒了,于是执行唤醒流程,把它放入了 RT 运行队列 (enqueue_task_rt)
**关键标志位变化:**请注意 433us 这一行:
k_preemp-1645 0dNh4. 433us : task_woken_rt <-ttwu_do_wakeup
N (Need Resched) 标志亮了!N 对应的是TIF_NEED_RESCHED变量,表明当前CPU有任务需要被调度,用白话说就是,内核明确知道“有个比当前进程更重要的任务(cyclictest)想运行,需要调度”。
我们可以在日志里面看到很多次的preempt_count_add和preempt_count_sub,但是不要紧,我们只需要关注preempt depth是否为0,只要不为0,均表明不允许调度。
第三阶段:开启抢占
k_preemp-1645 0.N.1. 3506us : preempt_count_sub <-preempt_count_sub
虽然在关闭抢占的时候,发送了许多事情,比如中断,spin_lock 等,但是这些均没有对调度器产生实质的影响,直到最后一次调用preempt_count_sub,将 preempt depth 减少为 0 。
基于日志,我们可以简单的画一个流程图:
[k_preempt_noise] | | <-- 1us: preempt_disable() [抢占关闭] | | (正在忙等...) | +---- 362us: [硬件中断发生!] -------------------------+ | | | [IRQ Context] | | hrtimer_wakeup -> cyclictest | | 设置 Need_Resched 标志 (N) | | (虽然想调度,但看到抢占关闭) | | | +---- 1002us: [中断返回] -----------------------------+ | | (继续忙等... N标志一直亮着) | | <-- 3505us: preempt_enable() [抢占打开] v[终于发生 Context Switch -> cyclictest]
硬件黑洞
接下来是最后一种场景——"硬件黑洞"。在 ARM64 架构下,内核运行在 EL1,虚拟化运行在 EL2,安全运行在 EL3。当内核调用 时会陷入 EL2,调用 smc 时会陷入 EL3。
其现象是 Linux 内核完全停止运行——时钟中断不响应、调度停滞、甚至 Ftrace 都无法记录。从 trace 的角度看,Trace 文件里什么都没有,但时间戳(Timestamp)会发生诡异的跳变(Time Skip)。
由于我们无法修改 Rockchip 的底层固件(ATF)来制造真实的黑洞,本章不做具体实践。这里分享一个案例:
笔者在虚拟化场景下做 guest 性能测试时,发现延迟非常高。无论如何使用 ftrace 都定位不到延迟信息,笔者怀疑是陷入 EL2 执行时间过长,导致 guest 延迟过高。
[ 正常 Linux 内核执行 (处于 EL1 层级) ](Trace Timestamp: T_point_A, 例如 100.000000) | | (内核运行中,一切正常,Ftrace 持续记录) v[ 触发点事件 ] (例如:需要调用安全服务或虚拟化功能) |(内核执行陷落指令) -> [ 执行 SMC (陷入 EL3) 或 HVC (陷入 EL2) 指令 ] | v /---------------------------------------------------------------------\ | *** 进入硬件黑洞 (Entering the Hardware Black Hole) *** | | [ CPU 执行权移交给固件 (ATF) 或 Hypervisor ] | \---------------------------------------------------------------------/ | v+=========================================================================+| *** 操作系统不可见区域 (OS Invisible Region) *** || || [ Linux 内核状态 (EL1) ]: || >> 完全冻结 (Frozen)。 || >> 时钟中断无法响应 (Timer Interrupts Blocked)。 || >> 调度器停滞。 || >> Ftrace 无法记录任何数据 (Trace is SILENT)。 || || ..................................................................... || . . || . [ 硬件真实状态 (Physical CPU at EL2/EL3) ] . || . >> CPU 正在高负荷执行固件或 Hypervisor 代码。 . || . >> 物理时钟仍在持续走动。 . || . >> (此处可能耗时极长,例如数毫秒甚至更久) . || . . || ..................................................................... || || (这段时间在 Trace 文件中表现为一段“空白”) |+=========================================================================+ | v /---------------------------------------------------------------------\ | *** 离开硬件黑洞 (Exiting the Black Hole) *** | | [ 固件/Hypervisor 执行完毕,执行 ERET 指令返回 Linux ] | \---------------------------------------------------------------------/ | v[ Linux 内核恢复运行 (回到 EL1 层级) ](Trace Timestamp: T_point_B, 例如 100.005000) | v[ 现象确认:诡异的时间跳变 (Time Skip Observed) ]>> 紧邻的两条 Trace 记录之间出现了巨大的时间断层。>> 延迟 = T_point_B - T_point_A = 5ms (而中间无任何记录)
如果怀疑是硬件黑洞,Linux 提供了一个专门的工具叫 hwlatdetect ,hwlatdetect 工具在rt-tests包中,并且需要打开CONFIG_HWLAT_TRACER。
# 运行检测 (检测 10分钟,阈值 10us)sudo hwlatdetect --duration=10m --threshold=10
这个工具的原理非常暴力——它派出一个内核线程疯狂轮询 CPU 硬件时钟,如果发现两次读取之间的时间差远超预期,就说明 CPU 被‘偷走’了。
如果 hwlatdetect 报出了高延迟,而 Ftrace irqsoff/preemptoff 啥也没抓到,那就是实锤的硬件/固件黑洞(ATF, TrustZone, 或者是总线竞争)。
总结
通过以上四种场景的分析,我们可以看到实时性 Linux 延迟问题的根源主要集中在:硬中断干扰、调度延迟、关闭抢占以及硬件黑洞。
在实际调试过程中,ftrace 是我们最强大的武器,通过 function_graph、irqsoff、preemptoff 等 tracer 的组合使用,配合对关键标志位的分析,我们可以精准定位到延迟的根本原因。
我们可以以下脚本抓取基本信息:
cd /sys/kernel/debug/tracingecho 0 > tracing_onecho nop > current_tracerecho 1 > tracing_cpumask # 只抓取cpu0上的信息echo 1 > events/sched/sched_switch/enableecho 1 > events/sched/sched_wakeup/enableecho 1 > events/irq/enableecho 1 > events/timer/enableecho 1 > tracing_on
在按照流程进行排查:
[上一次唤醒] --- (经过 1ms 周期) ---> [理论唤醒点 T_expected] | | <--- 盲区:阶段二 (Pre-Wakeup) | 这里发生 "干扰" | (硬中断/关中断/SMI) | v [实际唤醒 sched_wakeup] | | <--- 明区:阶段一 (Post-Wakeup) | 这里发生 "拥堵" | (高优先级压制/关抢占) | v [实际运行 sched_switch]
实时性优化没有银弹,但有一套科学的方法论。从盲目猜测到通过 Ftrace 精准定位,这不仅是技术的提升,更是思维方式的转变。
希望这套‘抓鬼’指南,能让大家在面对毫秒级延迟时,不再感到无力。
注:本文由笔者自行编写,后期用 AI 润色,图表由 AI 生成。ASCII 图表右侧 | 符号错位的解决方法还未找到。