Python实现拖拽式可视化爬虫
- 2026-07-12 16:39:15
Python实现拖拽式可视化爬虫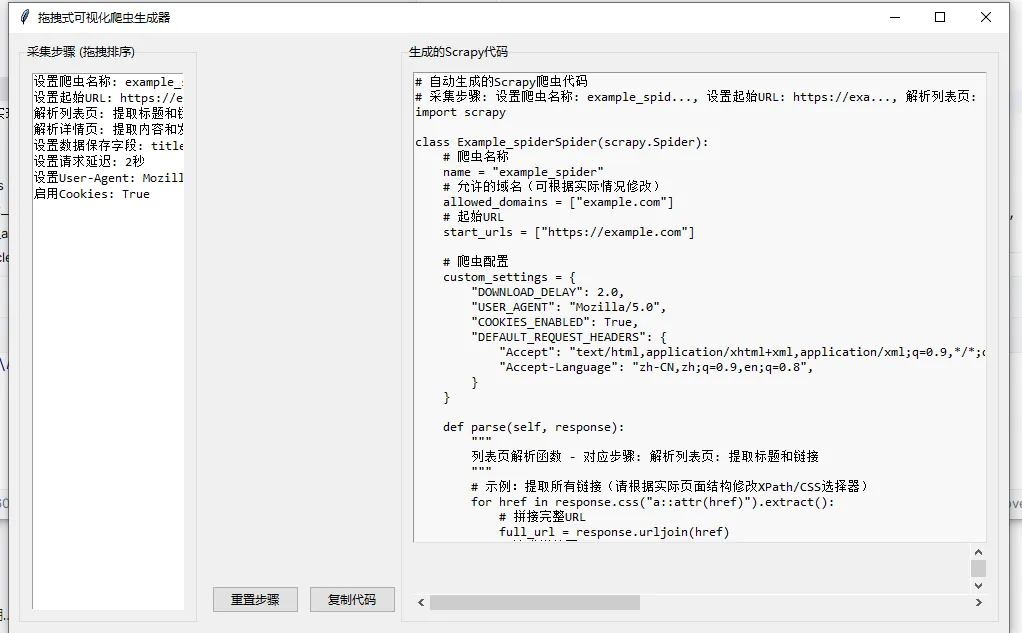
tkinter 实现一个拖拽式的可视化爬虫工具,核心功能是:左侧用 Listbox 展示可拖拽排序的采集步骤,右侧用 Text 控件实时生成对应的 Scrapy 爬虫代码,并且要演示 tkinter 的拖放 API 和代码自动生成逻辑。
下面我为你实现一个完整、可运行的拖拽式可视化爬虫工具,包含步骤拖拽排序、代码实时生成、基础的 Scrapy 代码模板等核心功能:
完整实现代码
import tkinter as tk
from tkinter import ttk, messagebox
classDragDropListbox(tk.Listbox):
"""支持拖拽排序的Listbox控件"""
def__init__(self, master, **kwargs):
super().__init__(master, **kwargs)
self.bind('<Button-1>', self.on_start)
self.bind('<B1-Motion>', self.on_drag)
self.bind('<ButtonRelease-1>', self.on_drop)
self.drag_data = {"index": None, "y_offset": None}
defon_start(self, event):
"""记录拖拽起始位置"""
# 获取点击的列表项索引
self.drag_data["index"] = self.nearest(event.y)
# 计算鼠标相对于列表项的偏移量
self.drag_data["y_offset"] = event.y - self.bbox(self.drag_data["index"])[1]
defon_drag(self, event):
"""拖拽过程中实时显示选中效果"""
# 计算当前鼠标位置对应的列表项
current_index = self.nearest(event.y)
# 如果拖拽到了新位置,更新选中状态
if current_index != self.drag_data["index"]:
# 先取消所有选中
self.selection_clear(0, tk.END)
# 选中当前拖拽到的位置
self.selection_set(current_index)
defon_drop(self, event):
"""释放鼠标完成拖拽排序"""
if self.drag_data["index"] isNone:
return
# 获取释放位置的索引
drop_index = self.nearest(event.y)
# 如果拖拽到了不同位置,执行排序
if drop_index != self.drag_data["index"]:
# 获取拖拽项的文本
item_text = self.get(self.drag_data["index"])
# 删除原位置的项
self.delete(self.drag_data["index"])
# 插入到新位置
self.insert(drop_index, item_text)
# 选中新位置的项
self.selection_set(drop_index)
# 重置拖拽数据
self.drag_data["index"] = None
self.drag_data["y_offset"] = None
classVisualScrapyGenerator:
"""可视化Scrapy代码生成器"""
def__init__(self, root):
self.root = root
self.root.title("拖拽式可视化爬虫生成器")
self.root.geometry("1000x600")
# 初始化采集步骤列表
self.crawl_steps = [
"设置爬虫名称: example_spider",
"设置起始URL: https://example.com",
"解析列表页: 提取标题和链接",
"解析详情页: 提取内容和发布时间",
"设置数据保存字段: title, content, publish_time",
"设置请求延迟: 2秒",
"设置User-Agent: Mozilla/5.0",
"启用Cookies: True"
]
self.setup_ui()
# 初始生成代码
self.generate_scrapy_code()
defsetup_ui(self):
"""设置界面布局"""
# 创建主容器
main_frame = ttk.Frame(self.root, padding="10")
main_frame.pack(fill=tk.BOTH, expand=True)
# 左侧步骤面板
left_frame = ttk.LabelFrame(main_frame, text="采集步骤 (拖拽排序)", padding="10")
left_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=(0, 10))
# 拖拽Listbox
self.step_listbox = DragDropListbox(
left_frame,
font=("Consolas", 10),
selectmode=tk.SINGLE,
activestyle=tk.NONE
)
self.step_listbox.pack(fill=tk.BOTH, expand=True)
# 填充初始步骤
for step in self.crawl_steps:
self.step_listbox.insert(tk.END, step)
# 绑定列表项变化事件
self.step_listbox.bind('<<ListboxSelect>>', self.on_step_change)
# 绑定拖拽完成后的代码更新
self.step_listbox.bind('<ButtonRelease-1>', lambda e: self.generate_scrapy_code())
# 右侧代码面板
right_frame = ttk.LabelFrame(main_frame, text="生成的Scrapy代码", padding="10")
right_frame.pack(side=tk.RIGHT, fill=tk.BOTH, expand=True)
# 代码显示区域
self.code_text = tk.Text(
right_frame,
font=("Consolas", 10),
wrap=tk.NONE,
bg="#f8f8f8"
)
self.code_text.pack(fill=tk.BOTH, expand=True)
# 添加滚动条
code_scroll_x = ttk.Scrollbar(right_frame, orient=tk.HORIZONTAL, command=self.code_text.xview)
code_scroll_y = ttk.Scrollbar(right_frame, orient=tk.VERTICAL, command=self.code_text.yview)
self.code_text.configure(xscrollcommand=code_scroll_x.set, yscrollcommand=code_scroll_y.set)
code_scroll_x.pack(side=tk.BOTTOM, fill=tk.X)
code_scroll_y.pack(side=tk.RIGHT, fill=tk.Y)
# 底部按钮
btn_frame = ttk.Frame(main_frame)
btn_frame.pack(side=tk.BOTTOM, fill=tk.X, pady=10)
# 重置按钮
reset_btn = ttk.Button(btn_frame, text="重置步骤", command=self.reset_steps)
reset_btn.pack(side=tk.LEFT, padx=5)
# 复制代码按钮
copy_btn = ttk.Button(btn_frame, text="复制代码", command=self.copy_code)
copy_btn.pack(side=tk.LEFT, padx=5)
defon_step_change(self, event):
"""步骤列表变化时更新代码"""
self.generate_scrapy_code()
defparse_step(self, step_text):
"""解析单步配置,提取关键信息"""
key = None
value = None
if"设置爬虫名称:"in step_text:
key = "spider_name"
value = step_text.split(":", 1)[1].strip()
elif"设置起始URL:"in step_text:
key = "start_urls"
value = step_text.split(":", 1)[1].strip()
elif"设置请求延迟:"in step_text:
key = "download_delay"
value = step_text.split(":", 1)[1].strip().replace("秒", "")
elif"设置User-Agent:"in step_text:
key = "user_agent"
value = step_text.split(":", 1)[1].strip()
elif"启用Cookies:"in step_text:
key = "cookies_enabled"
value = step_text.split(":", 1)[1].strip()
return key, value
defgenerate_scrapy_code(self):
"""根据步骤生成Scrapy代码"""
# 获取当前排序后的步骤
current_steps = [self.step_listbox.get(i) for i in range(self.step_listbox.size())]
# 解析配置
config = {
"spider_name": "example_spider",
"start_urls": "https://example.com",
"download_delay": 2,
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"cookies_enabled": True
}
for step in current_steps:
key, value = self.parse_step(step)
if key and value:
if key in ["download_delay"]:
config[key] = float(value)
elif key in ["cookies_enabled"]:
config[key] = eval(value)
else:
config[key] = value
# 生成Scrapy代码模板
scrapy_code = f'''# 自动生成的Scrapy爬虫代码
# 采集步骤: {", ".join([s[:20] + "..."if len(s) > 20else s for s in current_steps])}
import scrapy
class {config["spider_name"].capitalize()}Spider(scrapy.Spider):
# 爬虫名称
name = "{config["spider_name"]}"
# 允许的域名(可根据实际情况修改)
allowed_domains = ["{config["start_urls"].split("//")[1].split("/")[0]}"]
# 起始URL
start_urls = ["{config["start_urls"]}"]
# 爬虫配置
custom_settings = {{
"DOWNLOAD_DELAY": {config["download_delay"]},
"USER_AGENT": "{config["user_agent"]}",
"COOKIES_ENABLED": {config["cookies_enabled"]},
"DEFAULT_REQUEST_HEADERS": {{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
}}
}}
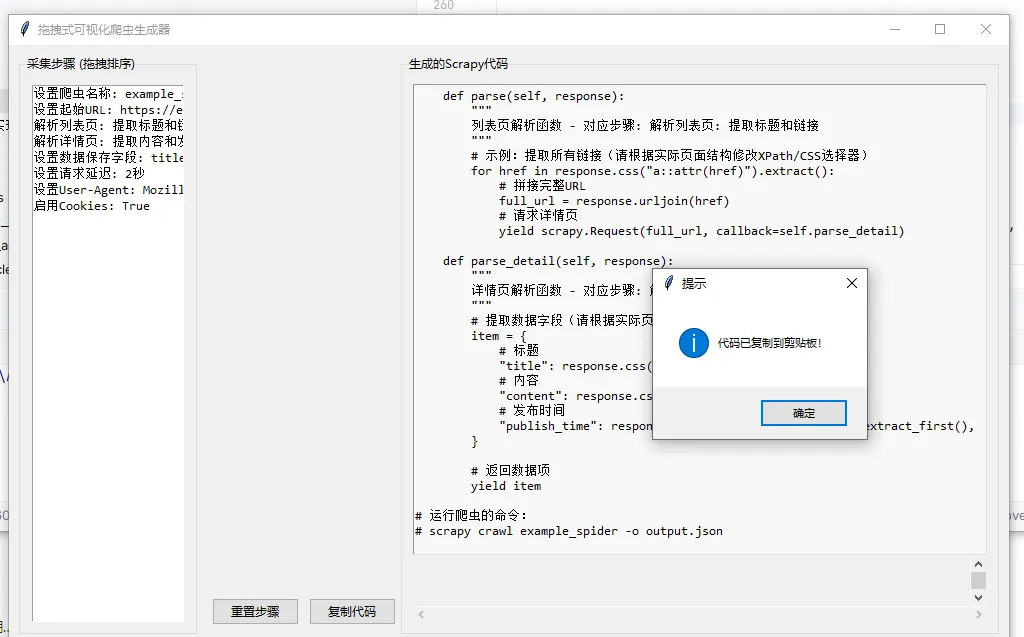
def parse(self, response):
"""
列表页解析函数 - 对应步骤: {[s for s in current_steps if"解析列表页"in s][0] if any("解析列表页"in s for s in current_steps) else"默认解析逻辑"}
"""
# 示例:提取所有链接(请根据实际页面结构修改XPath/CSS选择器)
for href in response.css("a::attr(href)").extract():
# 拼接完整URL
full_url = response.urljoin(href)
# 请求详情页
yield scrapy.Request(full_url, callback=self.parse_detail)
def parse_detail(self, response):
"""
详情页解析函数 - 对应步骤: {[s for s in current_steps if"解析详情页"in s][0] if any("解析详情页"in s for s in current_steps) else"默认解析逻辑"}
"""
# 提取数据字段(请根据实际页面结构修改XPath/CSS选择器)
item = {{
# 标题
"title": response.css("h1::text").extract_first(),
# 内容
"content": response.css(".content::text").extract(),
# 发布时间
"publish_time": response.css(".publish-time::text").extract_first(),
}}
# 返回数据项
yield item
# 运行爬虫的命令:
# scrapy crawl {config["spider_name"]} -o output.json
'''
# 清空并插入新代码
self.code_text.delete(1.0, tk.END)
self.code_text.insert(1.0, scrapy_code)
# 设置代码区域为只读(保留复制功能)
self.code_text.config(state=tk.DISABLED)
defreset_steps(self):
"""重置步骤列表"""
self.step_listbox.delete(0, tk.END)
for step in self.crawl_steps:
self.step_listbox.insert(tk.END, step)
self.generate_scrapy_code()
defcopy_code(self):
"""复制生成的代码到剪贴板"""
# 临时启用编辑状态
self.code_text.config(state=tk.NORMAL)
# 选中所有内容
self.code_text.tag_add(tk.SEL, 1.0, tk.END)
# 复制到剪贴板
self.root.clipboard_clear()
self.root.clipboard_append(self.code_text.get(1.0, tk.END))
# 恢复只读状态
self.code_text.config(state=tk.DISABLED)
# 提示复制成功
messagebox.showinfo("提示", "代码已复制到剪贴板!")
if __name__ == "__main__":
root = tk.Tk()
app = VisualScrapyGenerator(root)
root.mainloop()
代码核心功能解释
拖拽Listbox实现(
DragDropListbox类):重写了 Button-1(鼠标左键按下)、B1-Motion(鼠标拖拽)、ButtonRelease-1(鼠标释放)三个事件on_start:记录拖拽起始位置和偏移量on_drag:拖拽过程中实时高亮显示目标位置on_drop:释放鼠标时完成列表项的删除和重新插入,实现排序代码生成逻辑(
generate_scrapy_code方法):读取当前Listbox中排序后的所有步骤 解析每个步骤中的配置项(爬虫名称、起始URL、延迟等) 根据解析出的配置动态生成完整的Scrapy爬虫代码 代码模板包含了标准的Spider类、列表页解析、详情页解析、自定义配置等核心部分 界面交互功能:
重置按钮:恢复初始步骤顺序 复制按钮:将生成的代码复制到剪贴板 代码区域:使用等宽字体,支持横向/纵向滚动,设置为只读防止误修改
使用说明
环境要求:只需Python内置的tkinter库(Python 3.x 默认自带),无需额外安装依赖 操作步骤: 运行代码后,左侧Listbox显示预设的采集步骤 用鼠标左键按住任意步骤项,拖拽到目标位置后释放,即可完成排序 排序后右侧会实时生成对应的Scrapy代码 点击"重置步骤"可恢复初始顺序 点击"复制代码"可将生成的代码复制到剪贴板,直接用于Scrapy项目
总结
核心实现:通过重写tkinter Listbox的鼠标事件,实现了拖拽排序功能,这是可视化交互的基础 代码生成:基于排序后的采集步骤,动态解析配置并生成结构化的Scrapy代码,实现了可视化到代码的转换 交互体验:提供了重置、复制等辅助功能,代码区域采用只读模式保证安全性,同时保留复制功能
这个工具可以作为基础版本,你还可以扩展更多功能,比如:添加自定义步骤、支持更多Scrapy配置项、实时预览爬虫效果、导出为py文件等。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

