在上一节的分享当中我们讲了Python中文件的写入,还讲了各种模式、关于字符集的问题、with的方式打开一个文件,以及CSV文件格式的特点。那么我们这节课来讲讲文件的读。就是从硬盘文件中把内容显示出来。上课节我们除了分享写文件,已经把读写文件的基础也分享了,这里我们主要来分享点读文件的知识。f = open('example.txt', 'r')content = f.read()print(content)f.close()
with open('example.txt', 'r') as f: content = f.read() print(content)# 文件在此自动关闭,即使发生异常
# 读全部with open('data.txt') as f: data = f.read()# 逐行读(内存友好)with open('large.log') as f: for line in f: process(line.strip()) # 去掉换行符
对于大文件(GB 级),避免 read() 或 readlines(),应使用逐行迭代。讲到这个去掉换行符,我得举个例子来讲讲,我们可以这样来写代码:f = open('city.csv', 'r')c = f.read().strip('\n').split(',')f.close()print(c)
c = f.read().strip('\n').split(',')
1. f.read()读取整个文件内容,返回一个字符串。假设 city.csv 内容是:Beijing,Shanghai,Guangzhou,Shenzhen那么 f.read() 返回 "Beijing,Shanghai,Guangzhou,Shenzhen\n"(末尾可能带换行符)- 如果文件最后一行没有换行符,这步无效;如果有,会去掉末尾 \n。
- 结果:
['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen']
所以 c 是一个包含城市名的列表。
read()、readline()、readlines()区别read()函数 一次性可以读取整个文件,然后返回一个字符串。由此可见,如果对于小文本来说的话那么这个读取操作显然是流畅的,如果对于大文件的读取速度相对比较慢。如果文件大于可用内存,为了保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。# 假设有一个大文件 big_file.txtchunk_size = 1024 # 每次读 1KBwith open('big_file.txt', 'r', encoding='utf-8') as f: while True: chunk = f.read(chunk_size) # 读取最多 1024 个字符(文本模式) if not chunk: # 读到文件末尾,返回空字符串 break # 处理这一块数据(例如打印、写入、分析等) print(f"读取了 {len(chunk)} 个字符") # 这里可以做你的业务逻辑,比如搜索关键词、计算哈希等
readline() 函数一次只读取文件的一行,返回的类型是一个字符串类型。readlines()函数从文件的第一行读取到文件的最后一行,返回的类型是一个列表类型。1. 按块读取(适用于二进制或超大文件)
# 直接打开文件并分块读取file_path = 'huge_file.bin'chunk_size = 1024 # 每次读取 1024 字节(1KB)with open(file_path, 'rb') as f: while True: chunk = f.read(chunk_size) # 读取一块数据 if not chunk: # 如果读到文件末尾(返回空 bytes) break # 跳出循环 # 处理当前数据块 process(chunk) # 替换为你的实际处理逻辑
process(chunk)并不是 Python 的内置函数,而是一个占位符(placeholder),用来表示“在这里对读取到的数据块 chunk 做你想要的处理”。换句话说:你需要把它替换成你自己的实际代码逻辑。2. 日志分析
error_count = 0with open('app.log') as f: for line in f: if 'ERROR' in line: error_count += 1print(f"共 {error_count} 条错误日志")
3. 配置文件加载
# config.ini 内容:# [server]# host = localhost# port = 8080import configparserconfig = configparser.ConfigParser()config.read('config.ini')host = config['server']['host']
import hashlibimport os# 文件路径(请确保当前目录下有 image.jpg,或修改为你的实际路径)file_path = 'image.jpg'# 检查文件是否存在if not os.path.exists(file_path): print(f"错误:文件 {file_path} 不存在!")else: # 以二进制只读模式打开文件 with open(file_path, 'rb') as f: data = f.read() # 一次性读取全部内容,data 是 bytes 类型 # --- 示例 1:计算文件的 MD5 哈希值 --- md5_hash = hashlib.md5(data).hexdigest() print(f"MD5 哈希: {md5_hash}") # --- 示例 2:将读取的数据写入新文件(实现复制)--- output_path = 'copy_of_image.jpg' with open(output_path, 'wb') as out_file: out_file.write(data) print(f"已复制图片到 {output_path}") # --- 示例 3:获取文件大小 --- size = len(data) print(f"文件大小: {size} 字节 ({size / 1024:.2f} KB)") # --- 示例 4:准备用于网络传输(例如模拟发送)--- # 在真实场景中,你可能会用 requests、socket 或上传 SDK 发送 data print(f"数据类型: {type(data)}") # <class 'bytes'> print("前10字节(十六进制):", data[:10].hex()) # 查看文件头(JPEG 通常以 ff d8 开头)
5. 把大文件复制到另一个文件
withopen('output.bin', 'wb') asout: with open('huge_file.bin', 'rb') as f: while True: chunk = f.read(1024) if not chunk: break out.write(chunk) # 写入目标文件
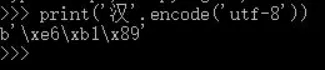
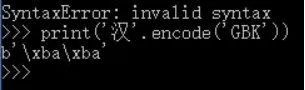
Python中字符汉字在utf-8编码下占三个字节,在gbk编码下占两个字节。next() 是 Python 的一个内置函数(built-in function),用于从**迭代器(iterator)**中手动获取下一个元素。numbers = iter([10, 20, 30]) # 创建一个迭代器print(next(numbers)) # 输出: 10print(next(numbers)) # 输出: 20print(next(numbers)) # 输出: 30# print(next(numbers)) # 报错!StopIteration#后面跟个默认值numbers = iter([1, 2])print(next(numbers, "没了")) # 1print(next(numbers, "没了")) # 2print(next(numbers, "没了")) # "没了" (不再报错)
# 原始 for 循环for item in iterable: print(item)# 理想化版本,实际不可行,仅用于理解流程it = iter(iterable)while True: item = next(it) # ← 此处隐含:当无元素时应自动停止(实际需异常) print(item) # (教学时口头说明:“当没元素时,循环结束”)
只用于理解next只用于理解next只用于理解next。关注,沟通、交流