一、项目及其数据集介绍
本次模型的数据集为国外某地的过往房地产数据集,涵盖80个变量,目标是预测每个房子的价格。
二、模型构建
(一)数据准备及预处理
#1、导入相关pyhton库import pandas as pd #用于数据清洗等预处理from sklearn.ensemble import RandomForestRegressor #随机森林回归模型from sklearn.metrics import mean_absolute_error #均值绝对误差指标,评估结果from sklearn.model_selection import train_test_split #导入数据集划分模型#2、导入数据集train_data = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv')test_data = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/test.csv')sample_submission = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/sample_submission.csv')#3.快速查看数据print("训练集形状:", train_data.shape)print("测试集形状:", test_data.shape)print("\n训练集前几行:")display(train_data.head())print("\n训练集数据信息:")train_data.info()
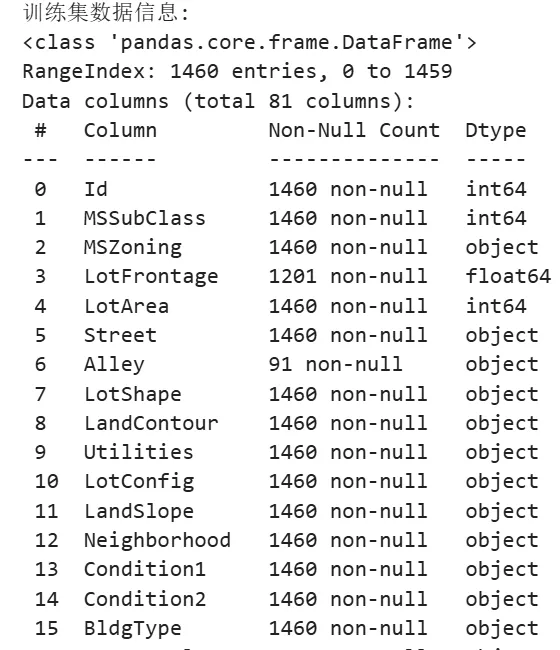
运行完该部分程序后,可以看到数据集信息。
训练集形状: (1460, 81)
测试集形状: (1459, 80)
测试集比训练集缺少的1个目标变量,正是需要预测的。
从以下测试集数据信息中可以看到,测试集中没有“80 SalePrice”列,而这也正是需要模型预测的。
(二)特征选择(降维)
训练集中一共有80个变量,这里选择以下7个变量作为特征变量:
LotArea:房屋面积
YearBuilt:房屋建设时间、
1stFlrSF:一楼面积
2stFlrSF:二楼面积
FullBath: 卫生间数量
BedroomAbvGr:卧室数量
TotRmsAbvGrd:房屋总数量(不包括卫生间)。
这些特征变量没有缺失值和异常值等,无需做预处理。
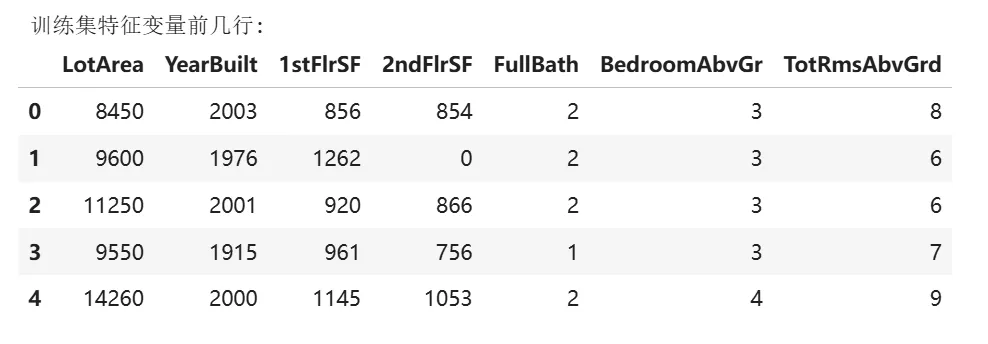
#选择特征变量和目标变量并查看数据features = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']train_X = train_data[features]train_y = train_data.SalePriceprint("\n训练集特征变量前几行:")display(train_X.head())#测试集特征变量test_X=test_data[features]
运行该部分代码后,可看到测试集的特征变量信息。
(三)建模
#定义随机森林模型rf_model = RandomForestRegressor(random_state=1) #固定随机种子,用作复现rf_model.fit(train_X, train_y) #模型拟合训练集rf_test_predictions = rf_model.predict(test_X) #模型预测测试集print({'ID':test_data.Id,'Saleprice':rf_test_predictions})
(四)结果保存及查看
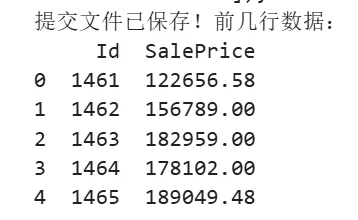
output = pd.DataFrame({'Id': test_data.Id, 'SalePrice': rf_test_predictions})output.to_csv('submission2.csv', index=False)print("提交文件已保存!前几行数据:")print(output.head())
运行以上程序,可以看到最终结果:
序号1461代表的房屋,价格为122656.58.