2月17日农历新年前夕,中国AI创业公司DeepSeek预计发布V4模型,内部基准测试显示其编程能力超越OpenAI ChatGPT和Anthropic Claude,特别是在处理超长代码提示(long coding prompts)方面表现突出。这会是中国AI的又一次"斯普特尼克时刻"吗?
 图1:DeepSeek V4聚焦编程能力,瞄准企业开发者市场
图1:DeepSeek V4聚焦编程能力,瞄准企业开发者市场
1 V4的核心定位:代码生成的精确打击
DeepSeek V4是一个混合模型(reasoning + non-reasoning),目标市场是企业开发者——在这个领域,代码生成的准确性直接转化为收入。The Information援引知情人士消息,V4在内部基准测试中,处理极长编程提示的能力超过Anthropic Claude和OpenAI GPT系列。
这个定位和DeepSeek R1(2025年1月发布的纯推理模型)明显不同。R1专注数学推理,开发成本560万美元,仅为OpenAI o1的1/68,在MATH-500 benchmark上拿到90.2%(Claude 78.3%)。V4走的是另一条路:垂直领域的实用性突破。
Claude Opus 4.5目前在SWE-bench Verified上保持80.9%的记录,这是业界公认的真实软件工程bug解决能力测试。V4要证明自己,必须超过这个门槛。
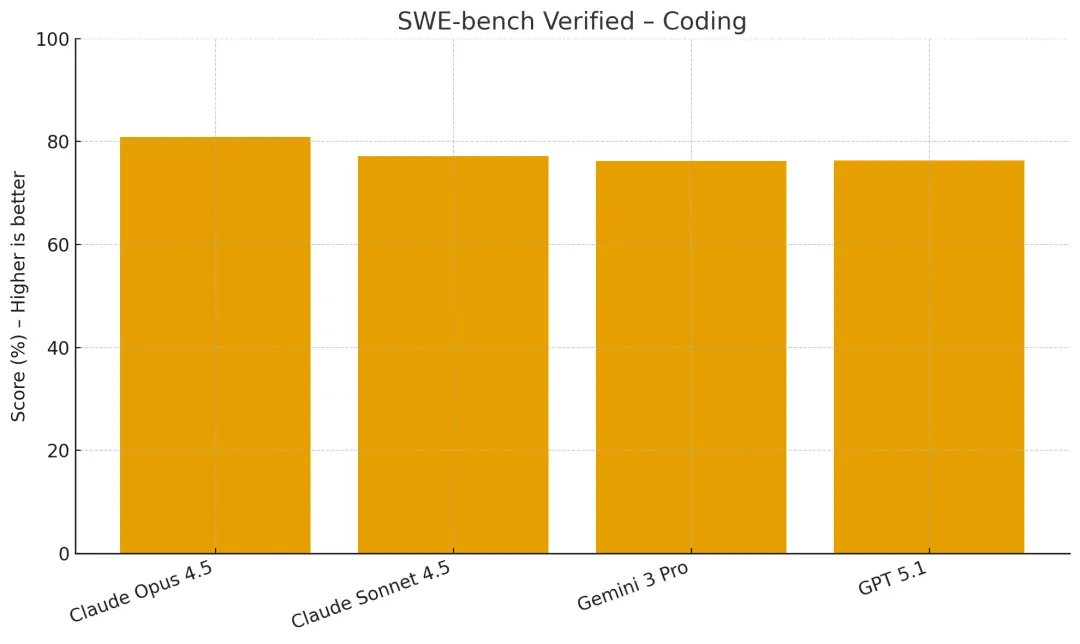 图2:SWE-bench Verified编程基准——Claude Opus 4.5领先,GPT 5.1紧随其后
图2:SWE-bench Verified编程基准——Claude Opus 4.5领先,GPT 5.1紧随其后
问题在哪?V4能否在公开benchmark上复现内部测试的优势。 DeepSeek至今未发布V4的任何公开数据,所有关于性能的说法都来自内部消息。这种情况在AI行业很常见——内部测试环境、数据集选择、评估标准都可能和公开benchmark存在差异。
2 技术突破:mHC架构的效率革命
DeepSeek在1月1日发布了一篇研究论文,介绍了Manifold-Constrained Hyper-Connections(mHC,流形约束超连接)训练方法。这是V4背后的技术基础。
传统架构训练大模型时,所有数据被迫通过单一通道,扩展容量时容易出现训练不稳定。mHC创建多个信息流通道,允许数据在不同路径间交换,同时保持训练稳定性。Counterpoint Research的Wei Sun评价这是"striking breakthrough"(显著突破),让DeepSeek能够"bypass compute bottlenecks and unlock leaps in intelligence"(绕过算力瓶颈,解锁智能跃迁)。
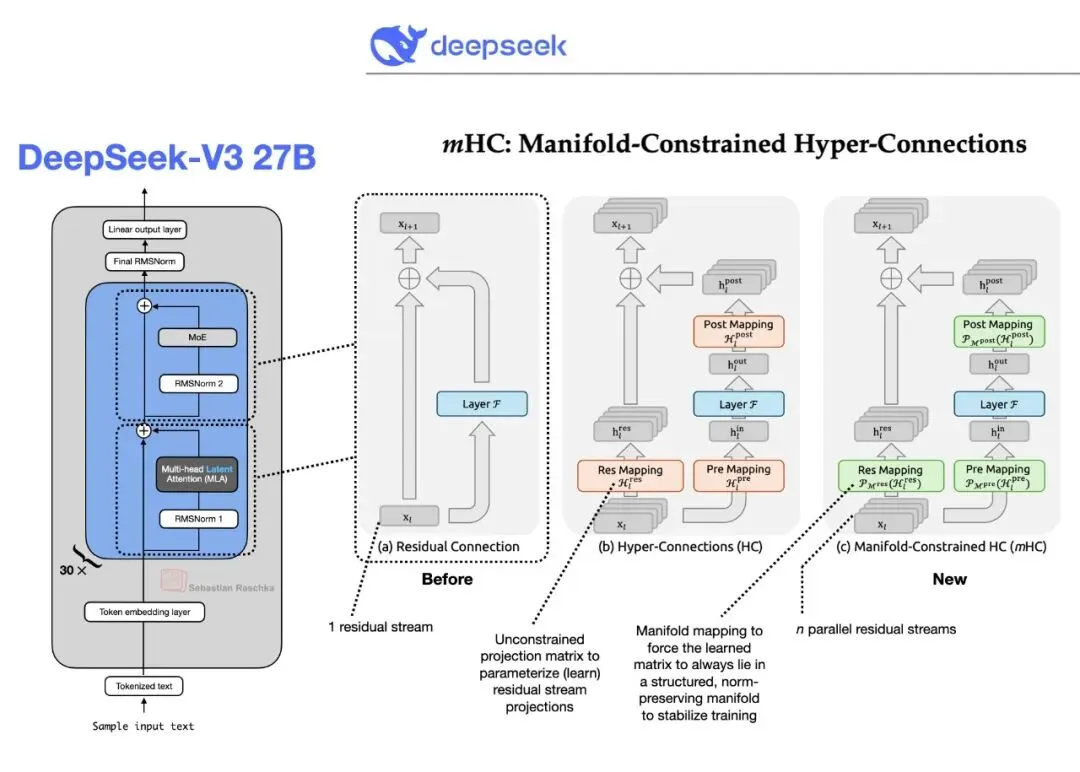 图3:mHC架构对比——从单一残差连接到多流并行,提升训练稳定性
图3:mHC架构对比——从单一残差连接到多流并行,提升训练稳定性
这个突破在美国芯片出口管制背景下尤其重要。DeepSeek V3用了大约2048块Nvidia H800芯片(H100的阉割版),训练成本约600万美元,远低于Meta Llama 3.1的数千万美元和OpenAI GPT-4的7800万美元。V4延续这个路线——用架构创新替代硬件堆砌。
 图4:DeepSeek V3与R1架构——MoE(混合专家)设计实现高效率
图4:DeepSeek V3与R1架构——MoE(混合专家)设计实现高效率
V3使用MoE架构,671B总参数,每次激活37B,256个routed experts中每个token只走top 8,加上1个共享expert。V4预计在此基础上针对代码生成任务做专门优化,可能增加更多专注于代码理解、生成、调试的expert modules。
3 对标Claude和ChatGPT:差距在哪
目前AI编程能力的天花板是Claude Opus 4.5和GPT-5.2 Codex,SWE-bench Verified分别是80.9%和80.0%,基本持平。这两个模型在2025年底发布(Claude 11月25日,GPT 12月19日),代表了2026年初的最高水平。
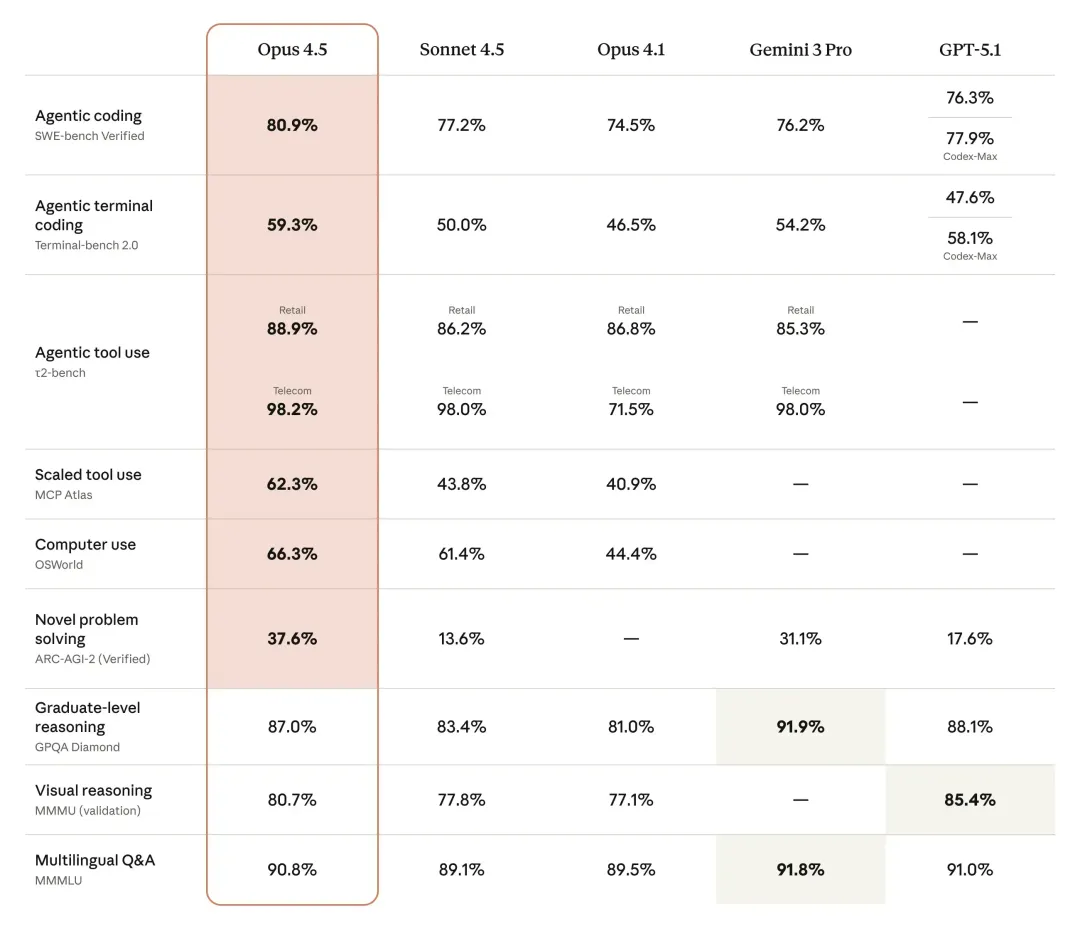 图5:Claude Opus 4.5全面基准测试——编程、推理、工具使用多项领先
图5:Claude Opus 4.5全面基准测试——编程、推理、工具使用多项领先
Claude Opus 4.5的80.9%意味着在500个真实软件bug中能正确解决405个,超过Anthropic内部工程测试中所有人类候选者的表现。GPT-5.2在SWE-bench Pro上拿到56.4%,AIME 2025数学推理满分100%,ARC-AGI-2(抽象推理)52.9%-54.2%,明显高于Opus的37.6%。
两个模型各有侧重:Claude强在实际软件工程,GPT强在抽象推理和数学。 V4要挑战这两位,需要在SWE-bench上超过81%,同时在长上下文编程(10k+ tokens的代码库理解)上建立差异化优势。
The Information的报道强调V4"excels at handling extremely long code prompts"。这是个聪明的切入点。现实开发场景中,工程师经常需要让AI理解整个代码库、几千行的legacy code、复杂的依赖关系,然后提出修改建议或生成新功能。这种长上下文能力是SWE-bench之外的实战需求。
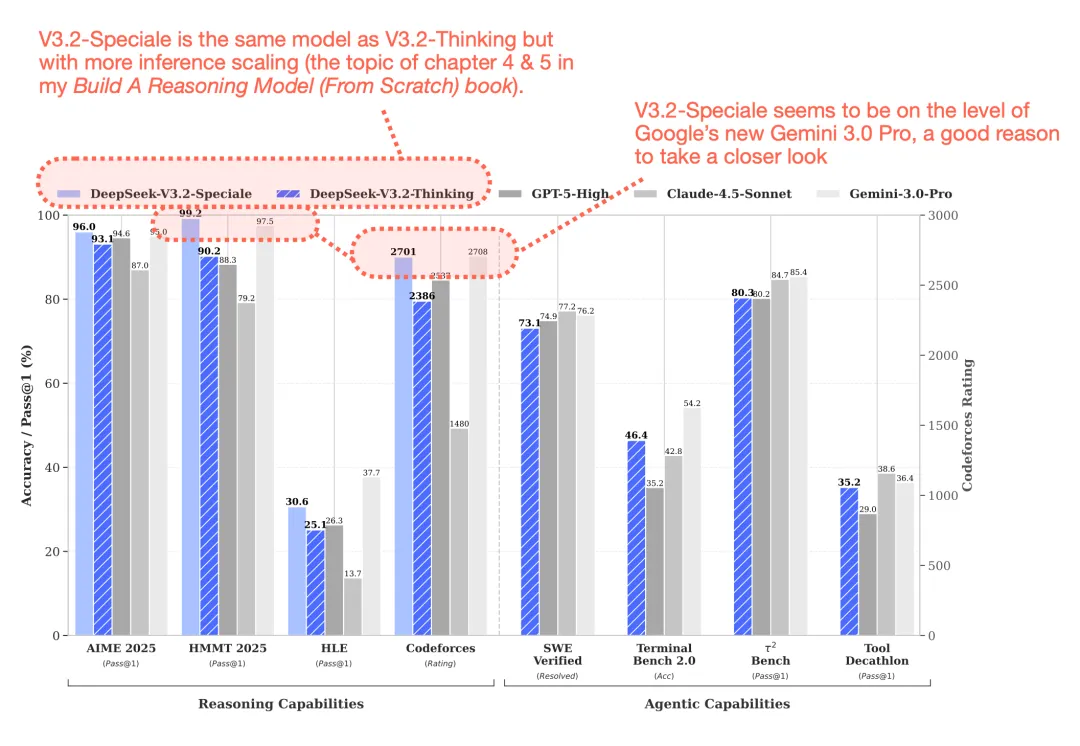 图6:DeepSeek V3与专有模型基准对比——在多项任务上接近GPT-4和Claude
图6:DeepSeek V3与专有模型基准对比——在多项任务上接近GPT-4和Claude
如果V4能在这个细分场景做到明显领先,配合API价格优势(DeepSeek R1官方API是2.19/1M output tokens,比OpenAI o1便宜27倍),就能在企业市场打开缺口。
4 中国AI的垂直突破策略
DeepSeek的路径很清晰:不追求全面超越,而是在垂直领域建立不可替代性。 R1证明了在数学推理上可以用1/68的成本达到o1的水平,V4瞄准的是代码生成这个直接影响开发者生产力的领域。
这个策略背后是现实约束。中国AI公司拿不到最先进的H100/H200芯片,只能用H800或更早的A100。DeepSeek创始人梁文锋(High-Flyer hedge fund)选择的是效率优先——通过MoE架构、mHC训练方法、开源策略(R1用MIT License)建立技术护城河。
Reddit的r/DeepSeek和r/LocalLLaMA社区已经开始囤积API credits,等待V4发布。这种anticipation(期待)在AI社区很罕见,通常只有OpenAI和Anthropic的旗舰模型发布前才会出现。DeepSeek用成本优势和开源友好赢得了开发者信任。
V4如果真的在编程benchmark上超过Claude和GPT,会带来几个连锁反应:
- 企业采购决策改变:80%+的SWE-bench准确率意味着AI可以独立处理大部分bug修复和routine coding tasks,企业会考虑用更便宜的DeepSeek替代GitHub Copilot(基于GPT)或Cursor(集成Claude)
- 开源生态加速:DeepSeek如果延续R1的开源策略,会有大量distilled models和fine-tuned variants出现,进一步压低AI编程工具的成本
- benchmark军备竞赛:OpenAI和Anthropic必然会在2月后发布针对长上下文编程的优化版本,SWE-bench的记录可能在几个月内被刷到85%+
5 V4面临的真实挑战
内部测试和实际部署之间有巨大Gap。V4要证明自己,需要回答几个问题:
数据来源的可持续性。DeepSeek V3和R1的训练数据主要来自公开代码库(GitHub、Stack Overflow等)和合成数据。V4要在长上下文编程上超越竞争对手,可能需要更多真实企业代码库的训练数据——这涉及数据隐私、授权问题,不是简单的技术问题。
benchmark vs. 实战的差异。SWE-bench测试的是isolated bug fixing,真实场景中开发者需要AI理解产品需求、设计架构、写测试、做code review、debug production issues。V4在benchmark上领先不代表在Cursor、Copilot这种IDE集成场景中就能超过GPT和Claude。
推理成本的trade-off。DeepSeek的低成本优势主要来自MoE架构的高效推理。但长上下文处理(10k+ tokens)会显著增加KV cache的内存占用和计算成本。V4如何在保持成本优势的同时支持超长代码提示,是个工程挑战。
中国市场的特殊性。DeepSeek占据中国AI市场89%的份额(2025数据),但国际扩张面临合规、数据主权、审查机制的质疑。V4即使技术领先,在欧美企业市场的adoption speed可能远慢于在中国市场。
写在最后
DeepSeek V4代表了中国AI的一种新策略:用效率和垂直深度对抗硬件劣势。 不追求全面超越GPT-5或Gemini 3,而是在编程、数学等高价值领域做到不可替代。
2月17日能否兑现内部测试的承诺,取决于DeepSeek敢不敢公开完整的benchmark数据、对比测试方法、推理成本细节。如果只是发布一个vague的"outperforms competitors"声明,市场的enthusiasm会很快冷却。
AI编程工具已经从novelty变成necessity,从Copilot到Cursor,从Claude Code到Replit Agent,开发者每天都在用AI写代码。V4如果真的能在长上下文编程上做到明显领先,会直接影响几百万开发者的工作方式。
让我们一起期待2月17日的真相。加油!
⚠️ 本文由 AI 辅助生成,内容可能存在事实性错误或理解偏差,请读者注意甄别核实。
DeepSeek V4这次能否兑现承诺,在编程领域真正超越ChatGPT和Claude?你最期待V4的哪个能力?
如果这篇文章帮你了解了DeepSeek V4的技术突破和市场定位,点个赞👍 和推荐❤️ 让更多开发者知道。
转发给做AI开发的朋友,这个技术突破值得关注。
Sources:
- Insiders Say DeepSeek V4 Will Beat Claude and ChatGPT at Coding, Launch Within Weeks - Decrypt[1]
- DeepSeek V4 rumored to outperform ChatGPT and Claude in long-context coding - Cryptopolitan[2]
- DeepSeek's new AI model could outperform ChatGPT in coding tasks - NewsBytes[3]
- Claude Opus 4.5 Benchmarks - Vellum AI[4]
- DeepSeek v3 and R1 Model Architecture - Fireworks AI[5]
- A Technical Tour of the DeepSeek Models from V3 to V3.2 - Sebastian Raschka[6]
题图来源:Decrypt
引用链接
[1]Insiders Say DeepSeek V4 Will Beat Claude and ChatGPT at Coding, Launch Within Weeks - Decrypt: https://decrypt.co/354177/insiders-say-deepseek-v4-beat-claude-chatgpt-coding-launching-weeks
[2]DeepSeek V4 rumored to outperform ChatGPT and Claude in long-context coding - Cryptopolitan: https://www.cryptopolitan.com/deepseek-v4-chatgpt-and-claude/
[3]DeepSeek's new AI model could outperform ChatGPT in coding tasks - NewsBytes: https://www.newsbytesapp.com/news/science/deepseek-to-launch-coding-focused-ai-model-in-february/story
[4]Claude Opus 4.5 Benchmarks - Vellum AI: https://www.vellum.ai/blog/claude-opus-4-5-benchmarks
[5]DeepSeek v3 and R1 Model Architecture - Fireworks AI: https://fireworks.ai/blog/deepseek-model-architecture
[6]A Technical Tour of the DeepSeek Models from V3 to V3.2 - Sebastian Raschka: https://magazine.sebastianraschka.com/p/technical-deepseek

