作者:MCP Guidebook
日期:2026年1月4日
原文链接:
https://www.dailydoseofds.com/what-is-mcp/
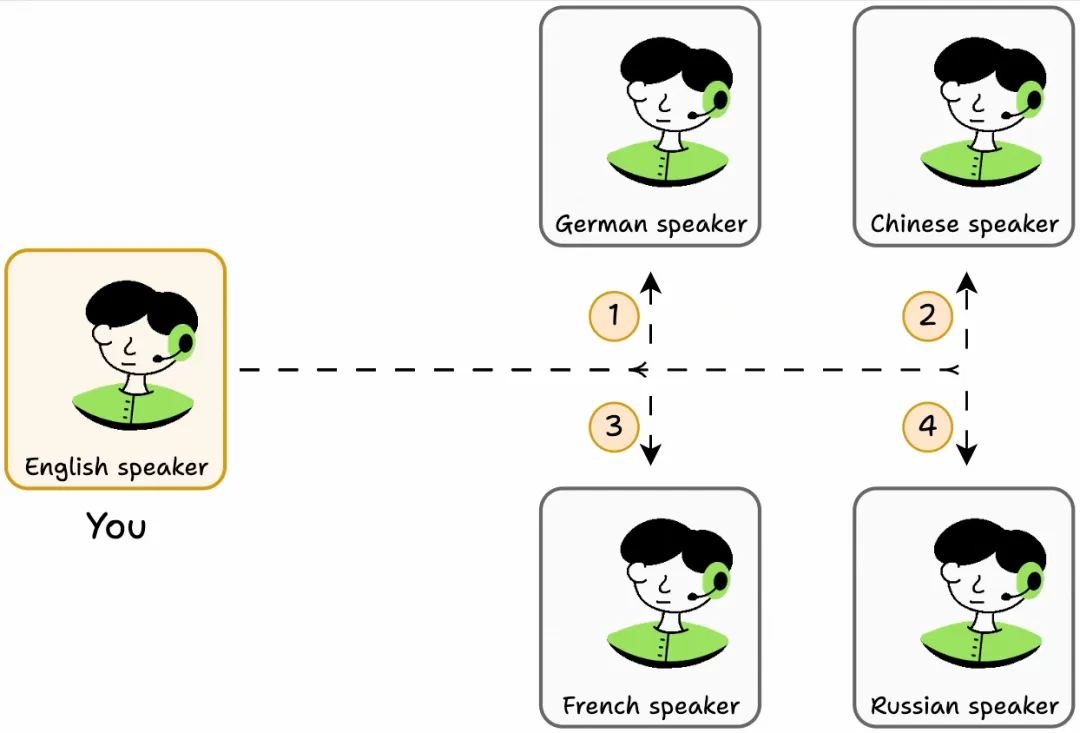
想象一下,您只懂英语。要从一个只懂以下语言的人那里获取信息:法语,您必须学习法语。德语,您必须学习德语。以此类推。在这种设定下,即使学习5种语言对您来说也将是一场噩梦。
但如果您加入一个能理解所有语言的翻译器呢?
这很简单,不是吗?
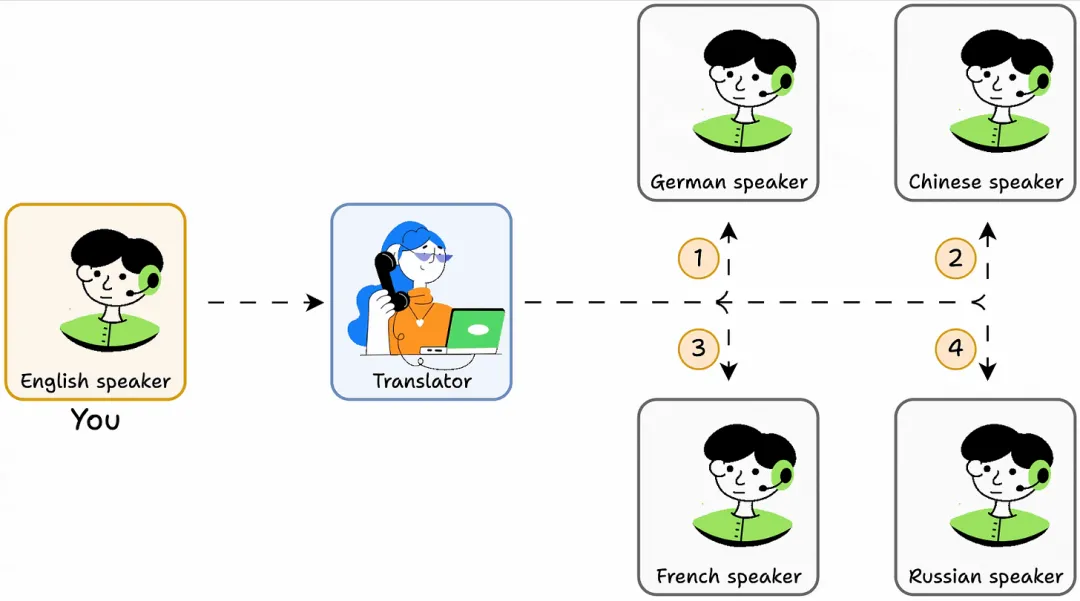
这个翻译器就像 MCP!
它让您(代理)通过一个统一的接口与其他人(工具或其他能力)进行对话。
正式来说,虽然大语言模型拥有令人印象深刻的知识和推理能力,使其能够执行许多复杂任务,但其知识仅限于其初始中训练数据。
如果需要获取实时信息,它们必须自行使用外部工具和资源。
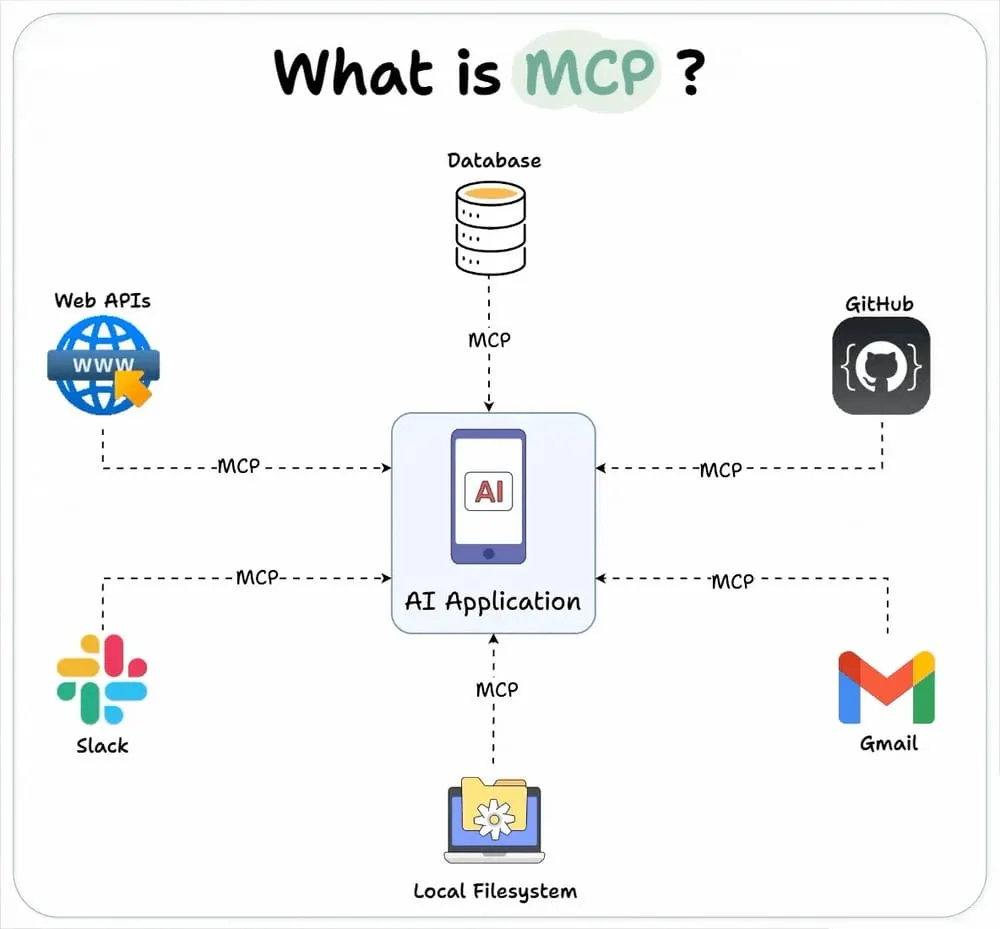
模型上下文协议是一个标准化的接口和框架,它使AI模型能够与外部工具、资源和环境无缝交互。
MCP充当了AI系统与各种能力之间的通用连接器,类似于USB-C标准化了电子设备之间的连接。
模型上下文协议为何被创建?
在没有模型上下文协议的情况下,添加新工具或集成新模型是一件令人头痛的事。
如果你有三个AI应用和三个外部工具,最终可能需要编写九个不同的集成模块,因为缺乏统一标准。这种方式无法扩展。
AI应用的开发者基本上每次都在重复造轮子,而工具提供商也必须支持多个互不兼容的API才能接入不同的AI平台。
让我们详细理解这一点。
问题所在
在模型上下文协议出现之前,连接AI与外部数据和行动的格局看起来就像一堆临时拼凑的解决方案。
你要么为每个工具编写硬编码的逻辑,要么管理那些不够健壮的提示词链,或者使用特定供应商的插件框架。
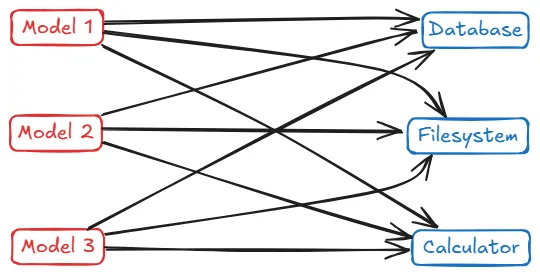
这导致了著名的 M×N 集成问题。
本质上,如果你有 M 个不同的AI应用和 N 个不同的工具/数据源,你可能最终需要 M × N 个定制集成。
下图说明了这种复杂性:每个AI(每个“模型”)可能需要独特的代码来连接到每个外部服务(数据库、文件系统、计算器等),导致出现类似“意大利面条式”的错综复杂连接。
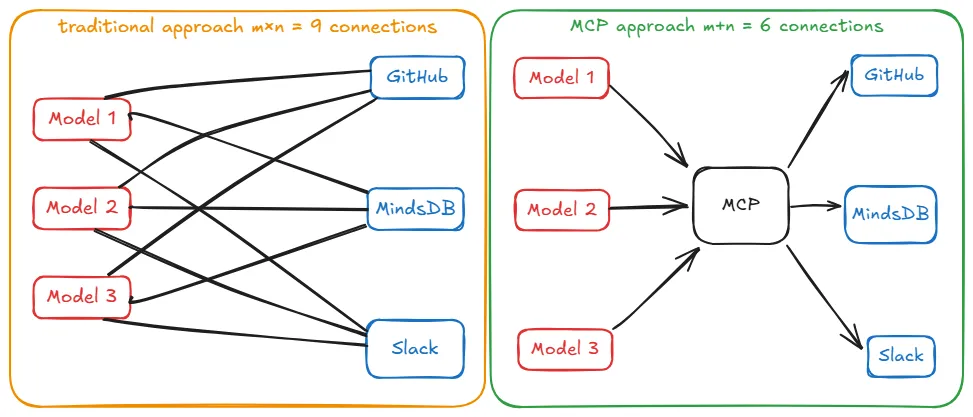
解决方案模型上下文协议通过引入一个标准化的中间接口来解决此问题。我们不再需要 M × N 个直接集成,而是只需实现 M + N 个组件:M 个AI应用中的每一个只需实现一次模型上下文协议的客户端,N 个工具中的每一个只需实现一次模型上下文协议的服务器。
现在,可以说大家都说同一种“语言”了。新的配对组合无需定制代码,因为它们已经通过模型上下文协议实现了相互理解。
下图阐释了这一转变。
左侧(模型上下文协议之前),每个模型都必须与每个工具单独连接。右侧(有了模型上下文协议之后),每个模型和工具都连接到模型上下文协议层,从而极大地简化了连接。你也可以将此与我们之前讨论的翻译器例子联系起来。其核心是,模型上下文协议遵循客户端-服务器架构(非常类似于网络或其他网络协议)。
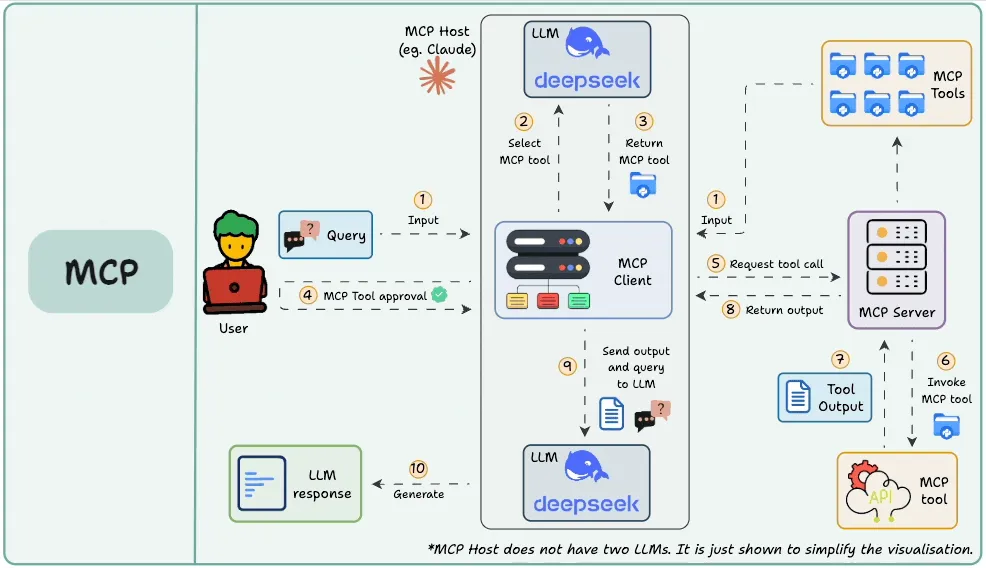
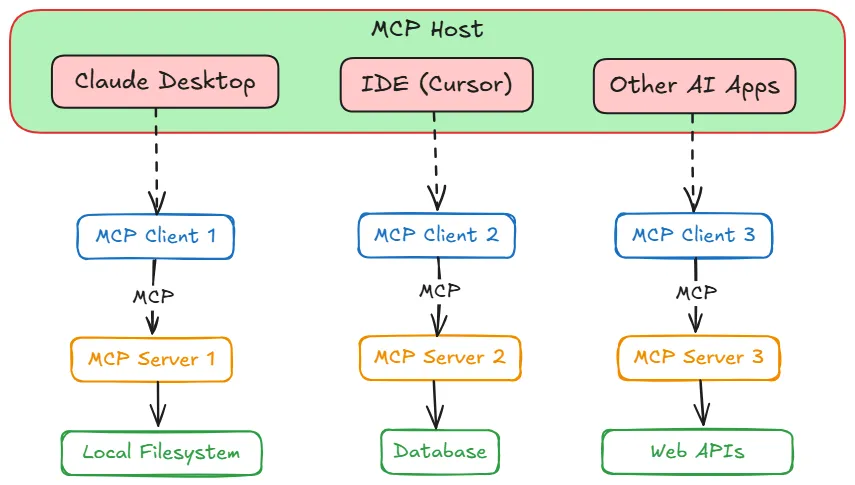
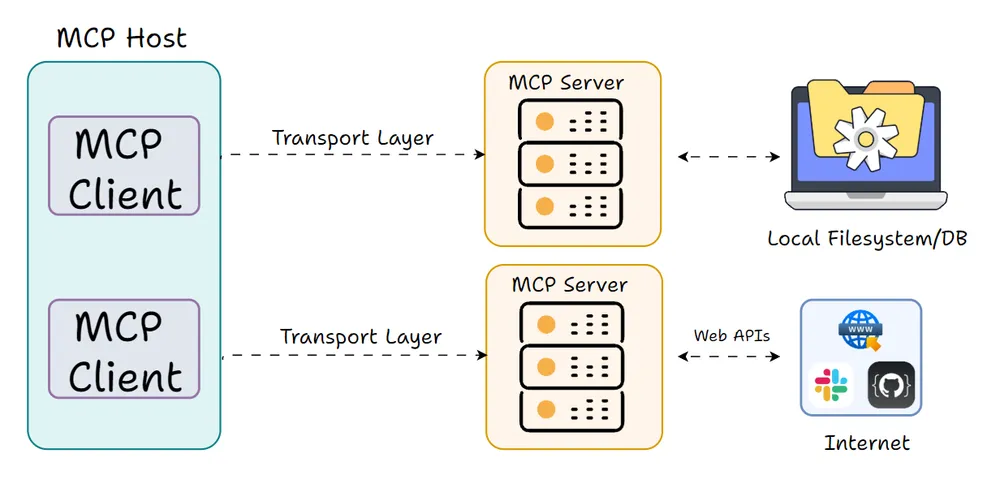
然而,其中的术语是为AI语境量身定制的。需要理解三个主要角色:主机、客户端和服务器。
主机主机是面向用户的AI应用,是AI模型驻留并与用户交互的环境。
这可以是一个聊天应用(例如 OpenAI 的 ChatGPT 界面或 Anthropic 的 Claude 桌面应用)、一个AI增强的集成开发环境(例如 Cursor),或者任何嵌入了AI助手(如 Chainlit)的自定义应用。
主机是在系统需要时,负责发起与可用模型上下文协议服务器连接的一方。它捕获用户输入、保持对话历史并显示模型的回复。
客户端模型上下文协议客户端是主机内部的一个组件,负责处理与模型上下文协议服务器的底层通信。
你可以将客户端视为适配器或信使。主机负责决定要做什么,而客户端则知道如何使用模型上下文协议与服务器通信,以实际执行这些指令。
服务器模型上下文协议服务器是实际为应用提供能力(工具、数据等)的外部程序或服务。
可以将模型上下文协议服务器视为对某些功能进行封装的一层,它以一种标准化的方式公开一组操作或资源,使得任何模型上下文协议客户端都能调用它们。
服务器可以在与主机相同的机器上本地运行,也可以在某个云服务上远程运行,因为模型上下文协议的设计旨在无缝支持这两种场景。关键在于,服务器以标准格式对外通告其功能(以便客户端可以查询并理解可用的工具),并会执行来自客户端的请求,然后返回结果。
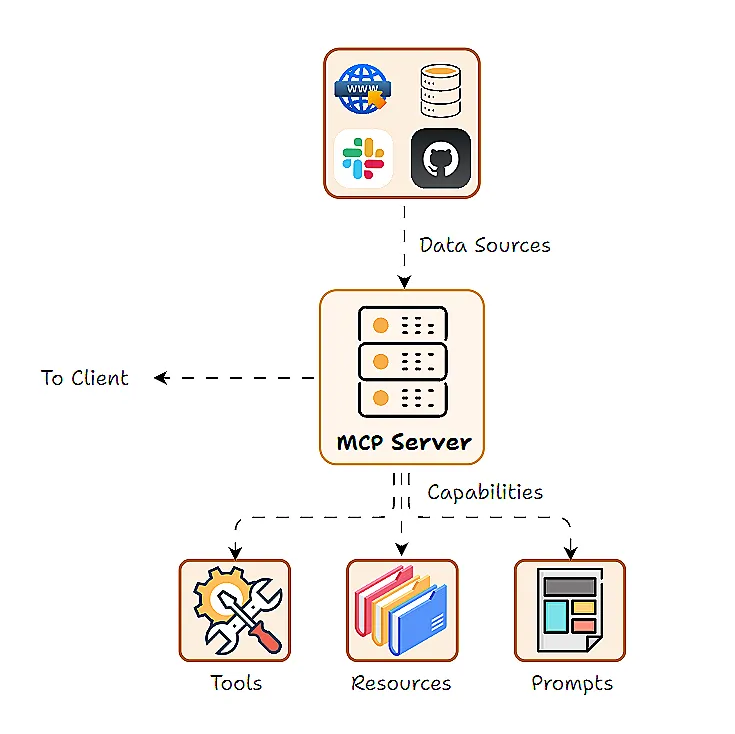
工具、提示词和资源构成了模型上下文协议框架的三个核心能力。能力本质上是服务器提供的功能或特性。
工具:AI可以通过执行的动作或函数,通常会伴随副作用或外部API调用。
资源:AI可以查询的只读数据源,仅用于检索信息,不产生副作用。
提示词:服务器可以提供的预定义提示词模板或工作流程。
工具工具顾名思义:代表AI模型执行某些操作的函数。这些通常是可能产生效果或需要AI自身能力之外计算的操作。
重要的是,工具通常由AI模型的选择触发,这意味着大语言模型通过主机决定在需要该功能时调用工具。
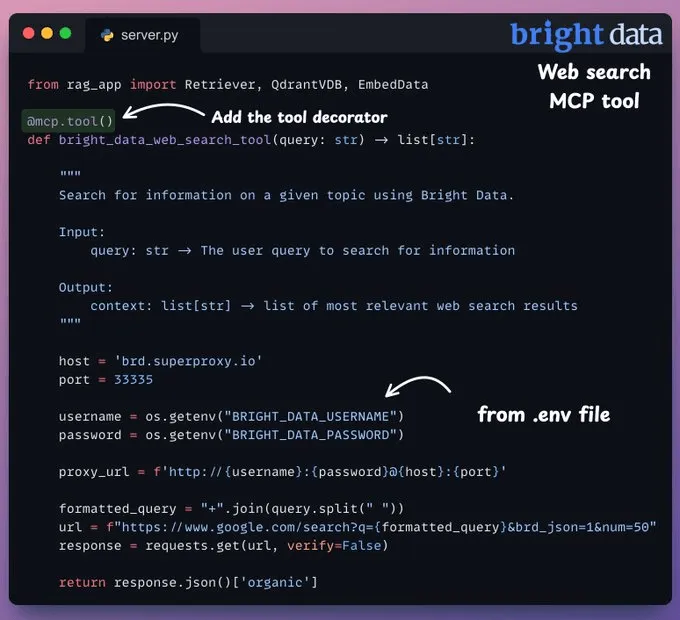
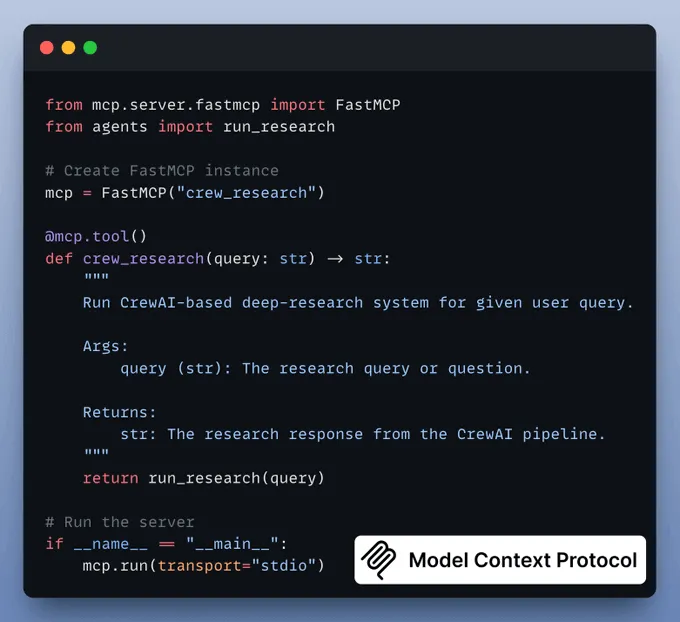
假设我们有一个简单的天气查询工具。在模型上下文协议服务器的代码中,它可能如下所示:
这个用 @mcp.tool() 注册的 Python 函数,可以由 AI 通过 MCP 调用。
当 AI 调用 tools/call 并传入名称 "get_weather" 和参数 {"location": "San Francisco"} 时,服务器将执行 get_weather("San Francisco") 并返回字典结果。
客户端将收到该 JSON 结果,并使其对 AI 可用。注意,该工具返回结构化数据,AI 随后可以使用这些信息或将其语言化以生成回复。
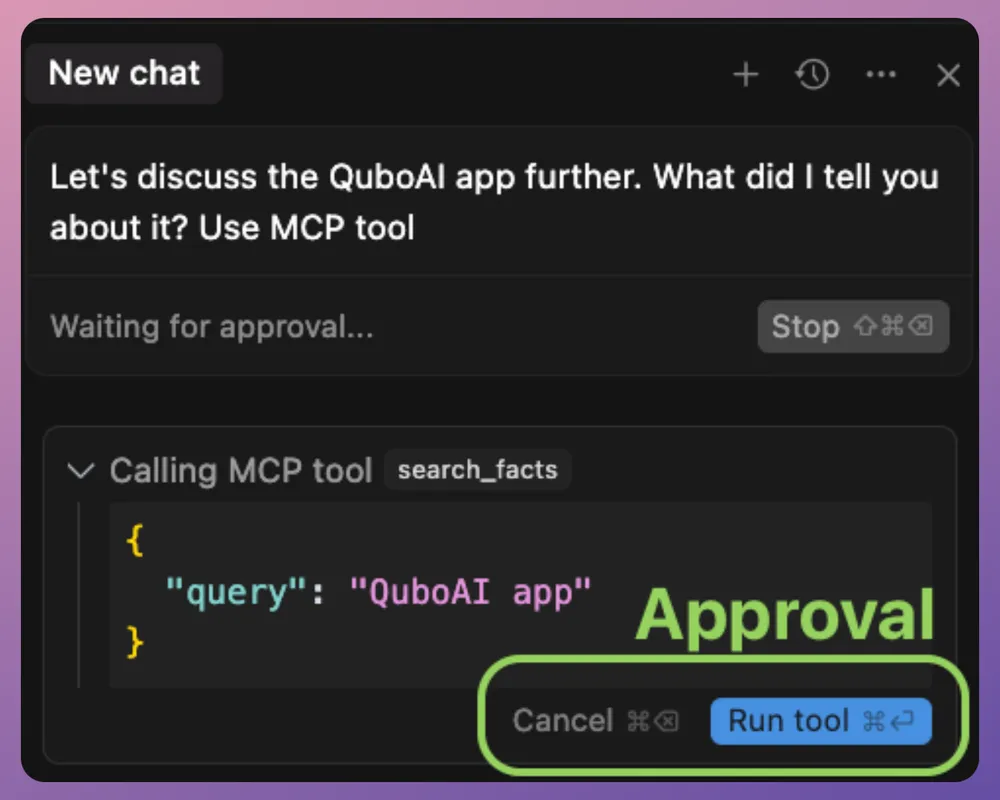
由于工具可以执行文件I/O或网络调用等操作,MCP 的实现通常要求用户允许工具调用
例如,Claude 的客户端可能会在首次使用时弹出提示:“AI 想要使用‘get_weather’工具,是否允许?是/否”,以避免滥用。这确保了人类始终能掌控那些具有强大功能的操作。
工具类似于经典函数调用中的“函数”,但在 MCP 框架下,它们在一个更灵活、动态的上下文中使用。它们由模型控制,但在执行时需要经过开发者或治理规则的批准。
资源资源为AI模型提供只读数据。
这些就像数据库或知识库,AI可以查询以获取信息,但不能修改。
与工具不同,资源通常不涉及大量计算或副作用,因为它们通常只是信息查询。
另一个关键区别在于,资源的访问通常受主机应用程序的控制,而非由模型自发触发。在实践中,这可能意味着主机知道何时为模型获取某个特定的上下文。
例如,如果用户说:“用公司手册来回答我的问题”,主机可能会调用一个资源来获取手册的相关章节,并将其提供给模型。
资源可以包括:本地文件的内容、知识库或文档的片段、数据库查询结果(只读),或任何静态数据,如配置信息。
本质上,就是AI可能需要了解的任何上下文信息。一个AI研究助手可以拥有像“arXiv论文数据库”这样的资源,在被询问时能够检索摘要或参考文献。
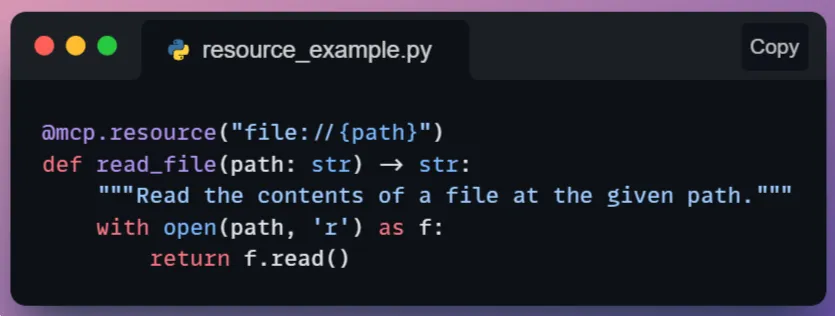
一个简单的资源可以是一个读取文件的函数:
这里我们使用了一个装饰器@mcp.resource("file://{path}"),这可能表示资源URI的一个模板。
AI(或主机)可以向服务器请求resources.get,并使用像file://home/user/notes.txt这样的URI,服务器将调用read_file("/home/user/notes.txt")并返回文本内容。
注意,资源通常由某个标识符(如URI或名称)来标识,而不是自由形式的函数。
它们通常也由应用程序控制,这意味着应用程序决定何时检索它们(以避免模型随意读取所有内容)。
从安全角度来看,由于资源是只读的,危险性较低,但仍需考虑隐私和权限问题(AI不应读取其无权访问的文件)。主机可以规定允许AI访问哪些资源URI,或者服务器可能限制对某些数据的访问。
总之,资源为AI提供知识,但不会交出更改任何内容的权限。
它们相当于模型上下文协议中,在需要时为模型提供参考材料,就像一个通过协议集成的、更智能的按需检索系统。
提示词在模型上下文协议语境中,提示词是一个特殊概念:它们是预定义的提示词模板或对话流程,可以被注入以引导AI的行为。
本质上,提示词能力提供了一套预设的指令或示例对话,有助于引导模型完成特定任务。
但为什么要把提示词作为一种能力呢?
考虑一些重复出现的模式:例如,一个将系统角色设定为“你是一名代码审查员”的提示词,并将用户的代码插入其中进行分析。
与其在主机应用程序中硬编码这些,不如由模型上下文协议服务器来提供。
提示词还可以表示多轮工作流程。
例如,一个提示词可以定义如何与用户进行逐步诊断访谈。通过模型上下文协议公开此功能,任何客户端都可以按需检索并使用这些复杂的提示词。
就控制而言,提示词通常由用户或开发者控制。用户可能从用户界面选择一个提示词/模板(例如,“总结此文档”模板),然后主机从服务器获取它。模型不会像使用工具那样自发决定使用提示词。
相反,提示词在模型开始生成之前就设定了舞台。从这个意义上说,提示词通常在交互开始时或用户选择特定“模式”时被获取。
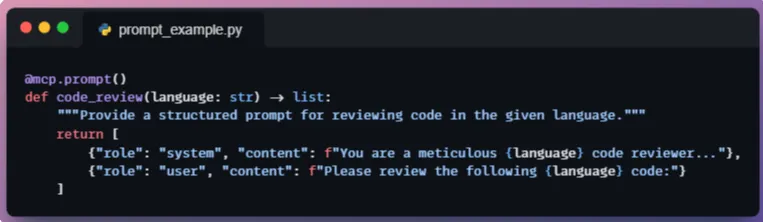
假设我们有一个用于代码审查的提示词模板。模型上下文协议服务器可能包含:
该提示词函数返回一个消息对象列表(采用 OpenAI 格式),用于设置代码审查场景。
当主机调用此提示词时,它会获取这些消息,并可以将待审查的实际代码插入到用户内容中。
然后,它会在模型生成自己的回答之前,将这些消息提供给模型。本质上,服务器是在协助构建对话结构。
虽然我们个人目前尚未看到此功能的广泛应用,但提示词能力的常见用例包括诸如“头脑风暴指南”、“分步问题解决模板”或特定领域的系统角色等。
通过将它们放在服务器上,可以在不更改客户端应用的情况下更新或改进它们,并且不同的服务器可以提供不同的专业提示词。
这里需要注意的重要一点是,提示词作为一种能力,模糊了数据与指令之间的界限。
它们代表了供AI使用的最佳实践或预定义策略。
从某种程度上说,MCP的提示词类似于ChatGPT插件建议查询格式的方式,但在这里它是标准化的,并且可以通过协议进行发现。
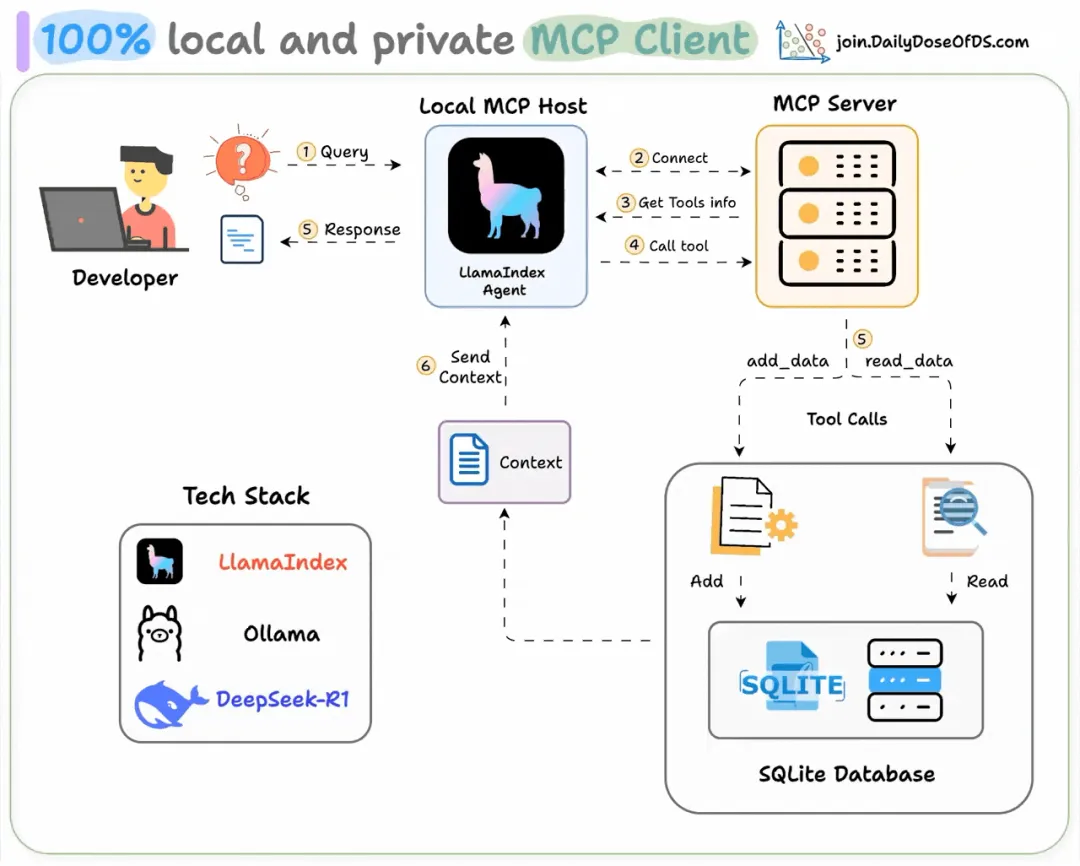
构建一个 100% 本地的 MCP 客户端...包含完整的代码详解与说明引言MCP客户端是AI应用中的一个组件,它通过模型上下文协议建立与外部工具和数据源的标准化连接。今天,我们将展示如何完全在本地构建它。
技术栈:
我们的工作流程如下:
用户提交查询。代理连接到模型上下文协议服务器以发现可用工具。根据查询内容,代理调用合适的工具并获取上下文信息。代理返回基于上下文的响应。本地 MCP 客户端实现让我们开始实现吧!
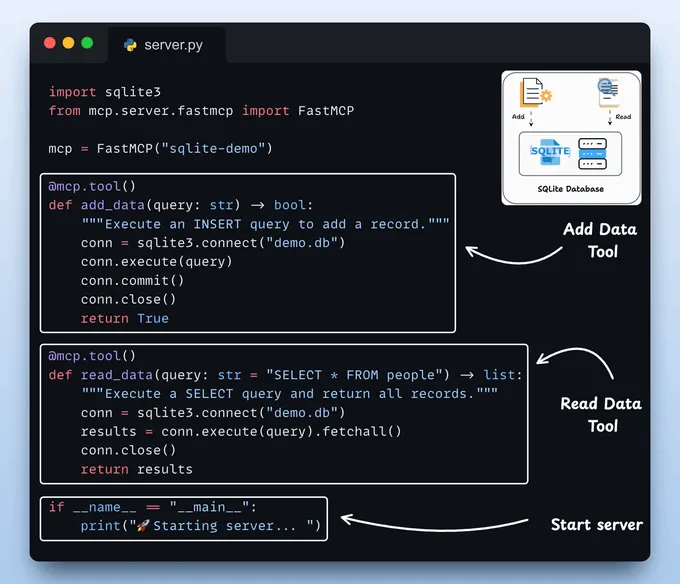
构建一个 SQLite MCP 服务器为了本次演示,我们构建了一个简单的 SQLite 服务器,它提供两个工具:
这样设计是为了保持演示的简洁性,但我们正在构建的客户端能够连接任何现有的模型上下文协议服务器。
设置大语言模型我们将使用通过 Ollama 在本地运行的 Deepseek-R1 作为我们基于模型上下文协议的代理所使用的大语言模型。
定义系统提示词我们为代理定义了指导原则,要求其在回答用户查询之前先使用相关工具。请根据您的需求随意调整此提示词。
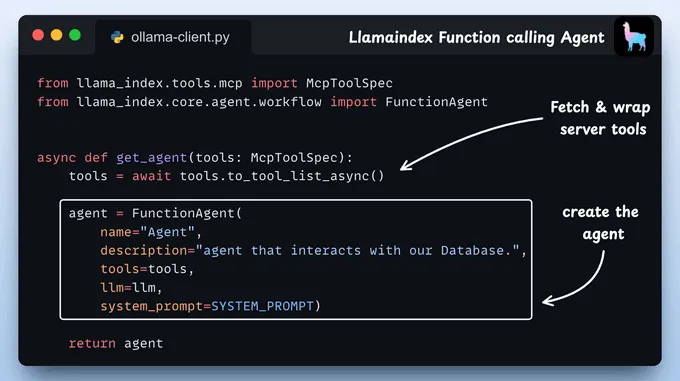
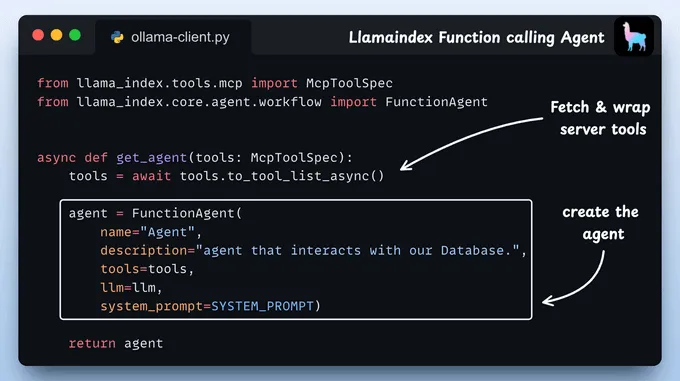
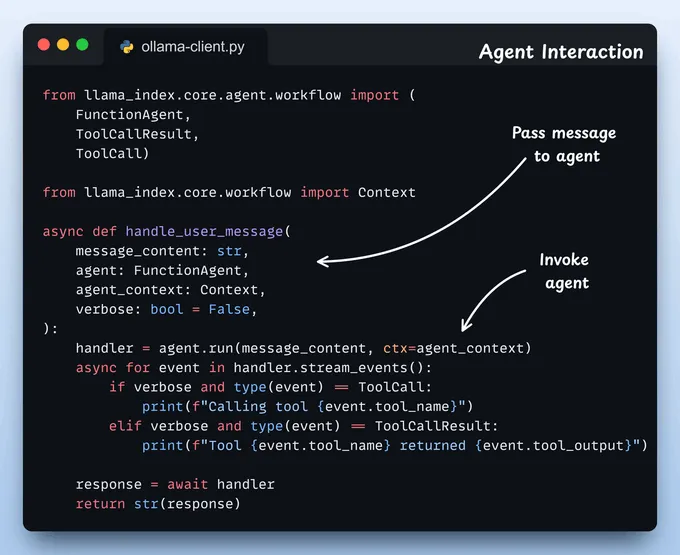
定义代理我们定义了一个函数,该函数使用适当的参数来构建一个典型的 LlamaIndex 代理。
传递给代理的工具是MCP工具,LlamaIndex会将其封装为原生工具,以便我们的FunctionAgent轻松使用。
定义代理交互我们将用户消息传递给FunctionAgent,该代理使用一个共享的上下文来维护记忆、流式处理工具调用,并返回其回复。
我们在此管理所有的聊天历史和工具调用。
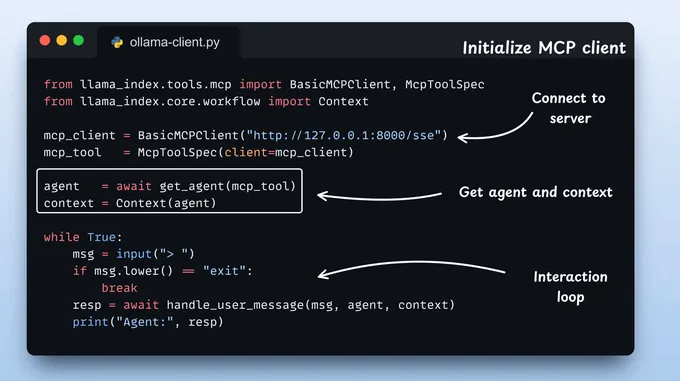
初始化 MCP 客户端与代理启动 MCP 客户端,加载其工具,并将它们封装为适用于 LlamaIndex 中函数调用代理的原生工具。
然后,将这些工具传递给代理,并添加上下文管理器。
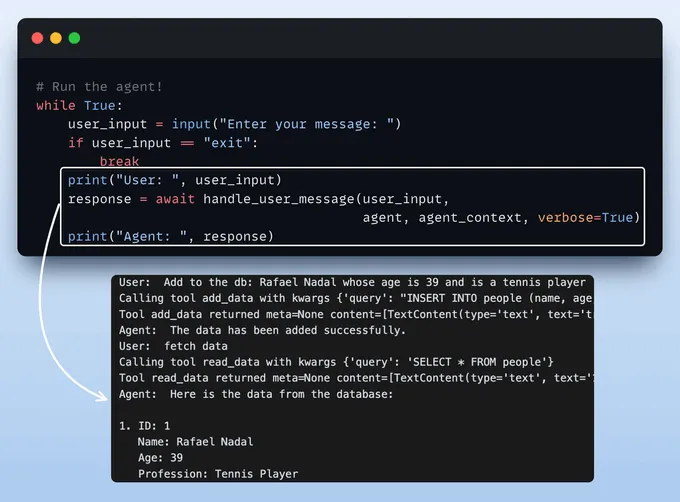
运行代理最后,我们开始与代理交互,并获得对 SQLite MCP 服务器中工具的访问权限。如上所示:
这样,我们就构建好了自己的 100% 本地 MCP 客户端!
相关代码可在以下 Studio 中获取:构建一个 100% 本地的 MCP 客户端。您可以直接复制下方的环境配置并运行,无需任何额外安装:
接下来,我们展示另一个基于 MCP 的演示,它将是一个代理驱动检索增强生成系统。
在下面的视频中,我们构建了一个MCP 驱动的代理驱动检索增强生成系统,它能搜索向量数据库,并在需要时回退到网络搜索。
要构建此系统,我们将使用:
Bright Data进行大规模网页抓取。
Qdrant作为向量数据库。
Cursor作为 MCP 客户端。
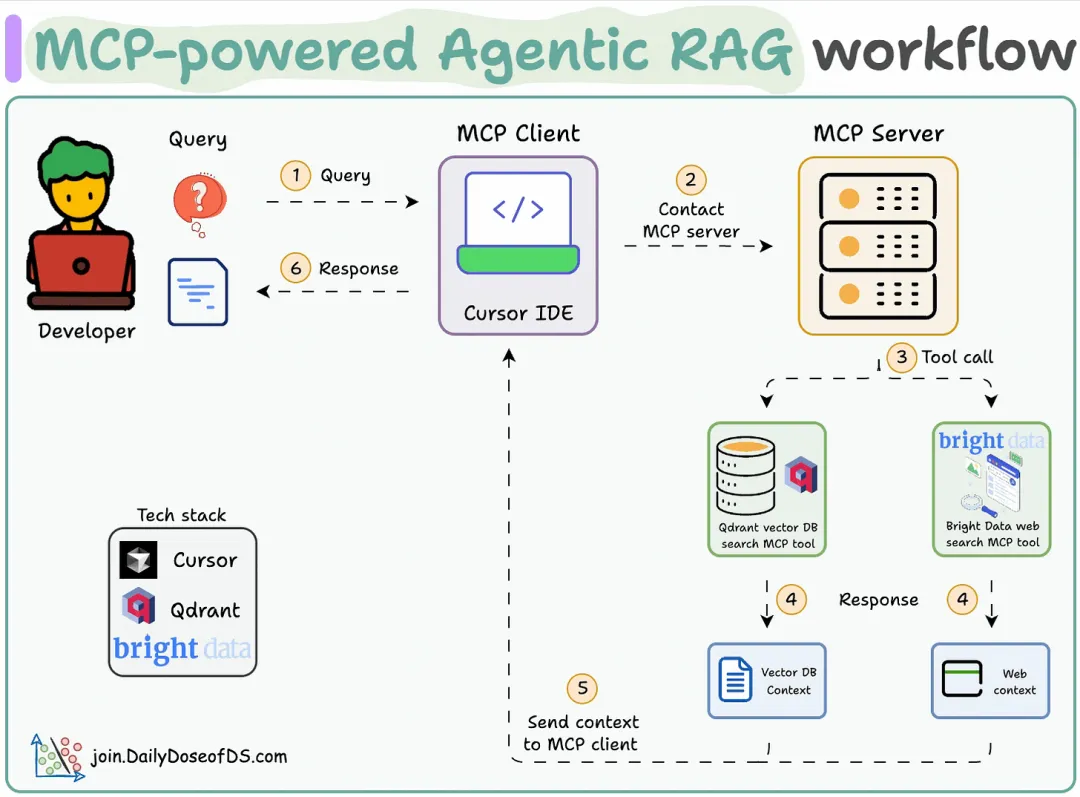
工作流程如下:
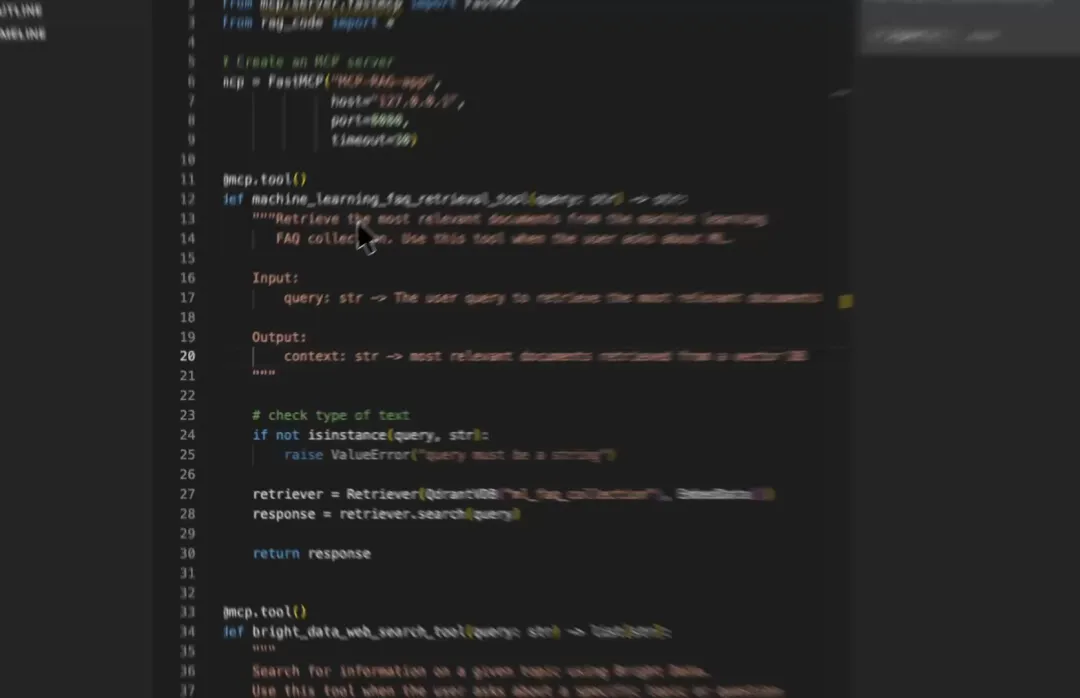
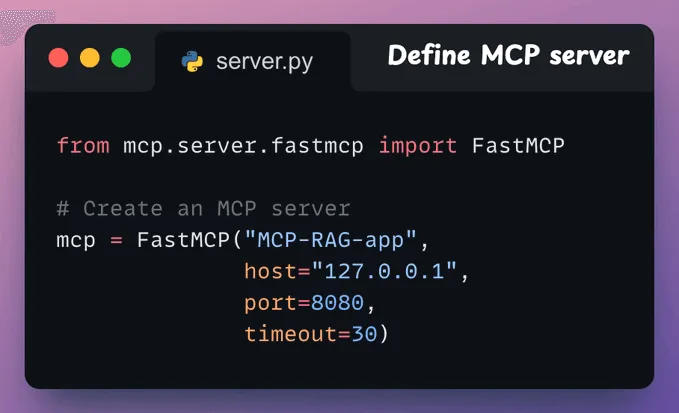
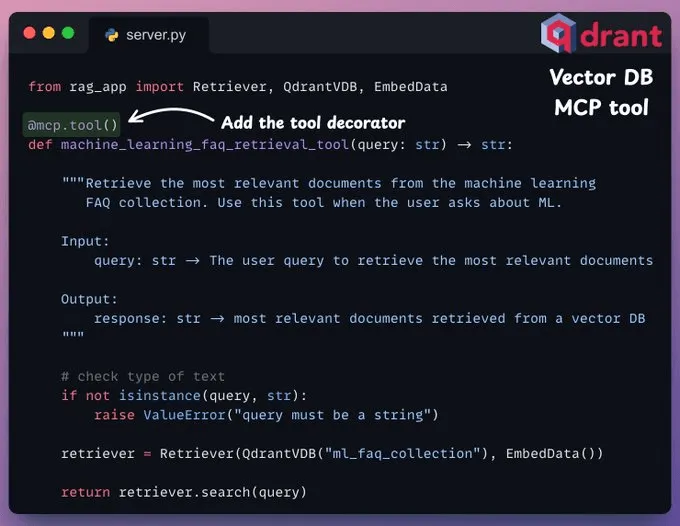
(1)用户通过 MCP 客户端(Cursor)输入查询。(2-3)客户端联系 MCP 服务器以选择合适的工具。(4-6)工具的输出结果返回给客户端,用于生成最终响应。(1) 启动 MCP 服务器首先,我们定义一台 MCP 服务器,并指定其主机 URL 和端口。(2) 向量数据库 MCP 工具通过 MCP 服务器公开的工具必须满足两个要求:接下来,我们将与 MCP 服务器进行交互。
如果查询与机器学习无关,我们需要一个回退机制。
因此,我们转而使用 Bright Data 的 SERP API 进行网络搜索,以大规模抓取多个来源的数据,从而获取相关的上下文信息。
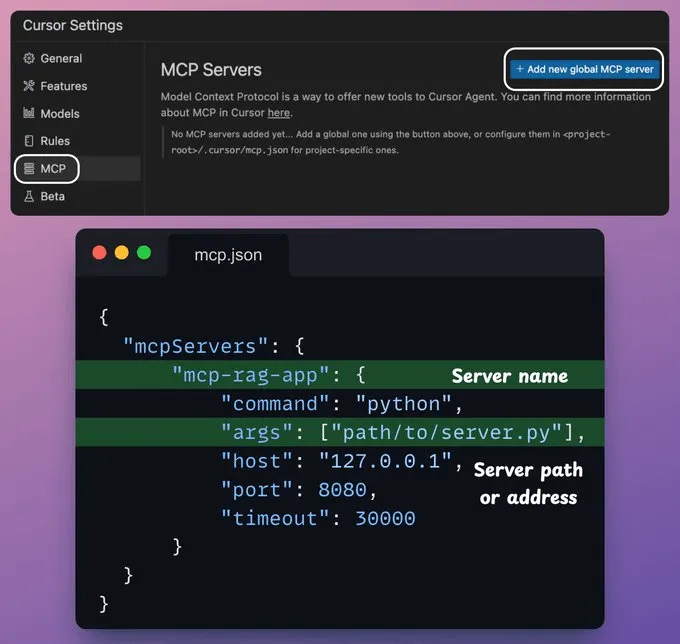
(4) 将 MCP 服务器与 Cursor 集成在我们的设置中,Cursor 是一个 MCP 主机/客户端,它使用 MCP 服务器公开的工具。
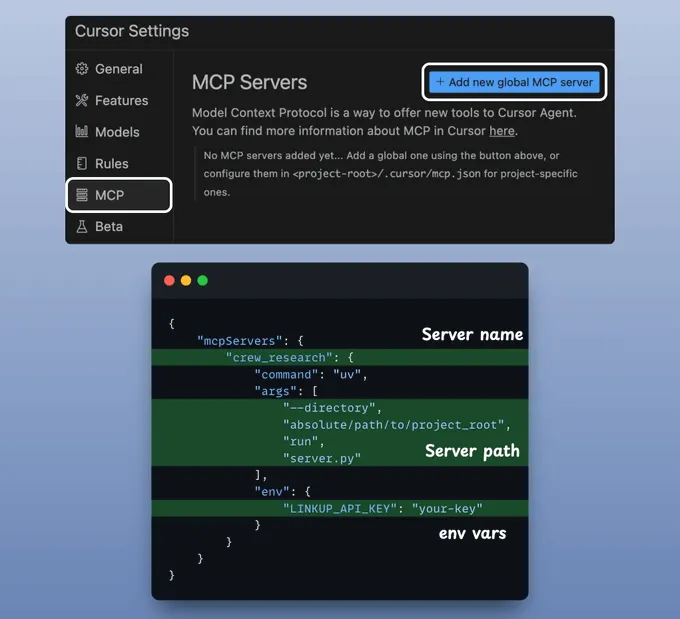
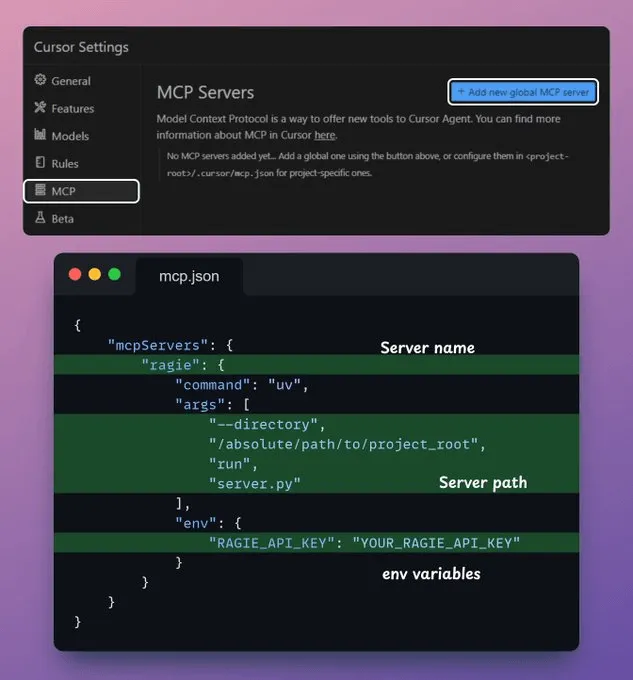
要集成 MCP 服务器,请转到Settings(设置) → MCP → Add new global MCP server(添加新的全局 MCP 服务器)。
在 JSON 文件中,添加如下所示的内容👇
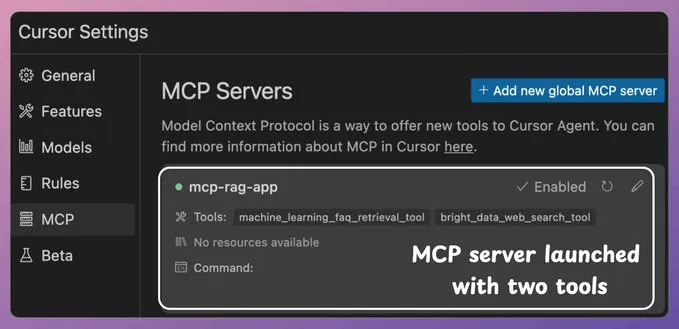
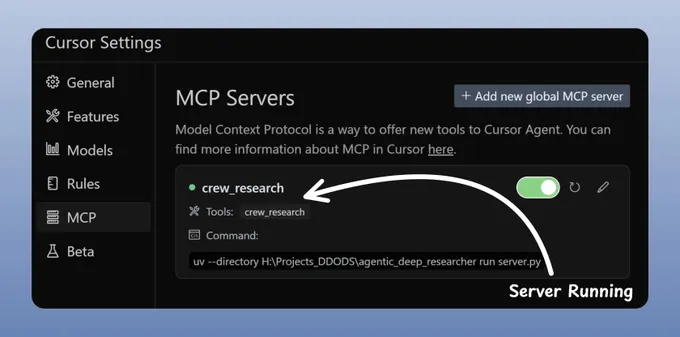
完成!您的本地 MCP 服务器已启动并成功连接到 Cursor 🚀!
它现在拥有两个 MCP 工具:
用于大规模抓取数据的 Bright Data 网络搜索工具。用于查询相关文档的向量数据库搜索工具。
接下来,我们将与 MCP 服务器进行交互。
视频地址:https://www.dailydoseofds.com/content/media/2025/04/Bright-data-Agentic-RAG-MCP.mp4当我们提出一个与机器学习相关的查询时,它会调用向量数据库工具。但是,当我们提出一个通用查询时,它会调用 Bright Data 网络搜索工具,从各种来源大规模地收集网络数据。
当代理使用这些工具时,它们可能会遇到诸如IP封锁、机器人流量检测、验证码等问题,这阻碍了代理的正常执行。
为了解决这个问题,我们在本演示中使用了 Bright Data。
在此获取您的 API_KEY
→brdta.com/dailydoseofds?ref=dailydoseofds.com
它使您能够:
大规模为代理抓取数据且不会被拦截。
使用先进的浏览器工具模拟用户行为。
利用实时和历史网络数据构建代理应用。
相关代码可在此 GitHub 仓库中找到:MCP 实现仓库:https://github.com/patchy631/ai-engineering-hub/tree/main/mcp-agentic-rag?ref=dailydoseofds.com
现在,让我们继续下一个项目!
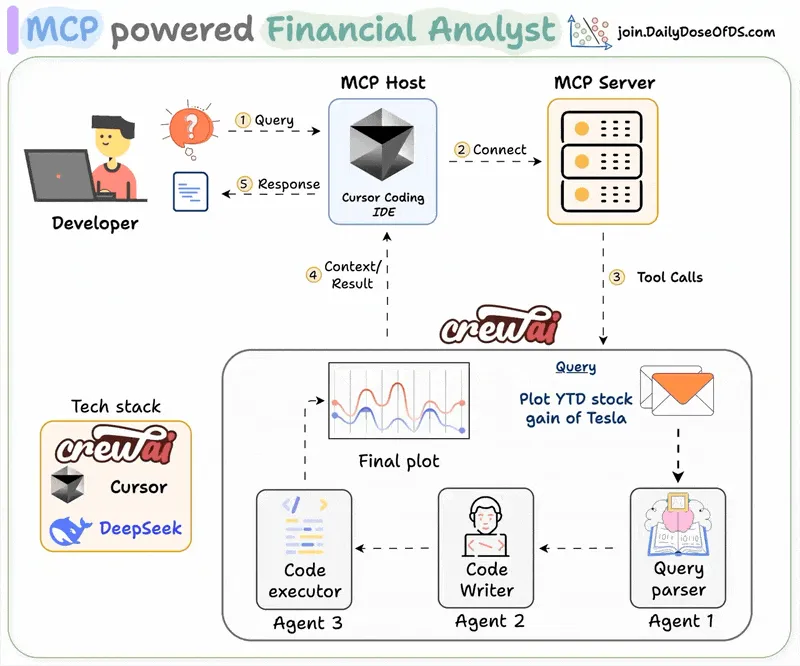
在本章节中,我们将构建一个能够连接到您的 Cursor/Claude 并回答金融相关查询的金融分析师。
下面的视频展示了我们将要构建内容的快速演示!
视频地址:https://www.dailydoseofds.com/content/media/2025/06/UdSkRsEhWNU5XJss.mp4技术栈:
系统概述:
用户提交查询。
MCP代理启动金融分析团队。
该团队进行研究并创建可执行脚本。
代理运行脚本以生成分析图表。
您可以在以下GitHub仓库中找到代码 →https://preview.convertkit-mail2.com/click/dpheh0hzhm/aHR0cHM6Ly9naXRodWIuY29tL3BhdGNoeTYzMS9haS1lbmdpbmVlcmluZy1odWIvdHJlZS9tYWluL2ZpbmFuY2lhbC1hbmFseXN0LWRlZXBzZWVr?ref=dailydoseofds.com
让我们开始构建吧!
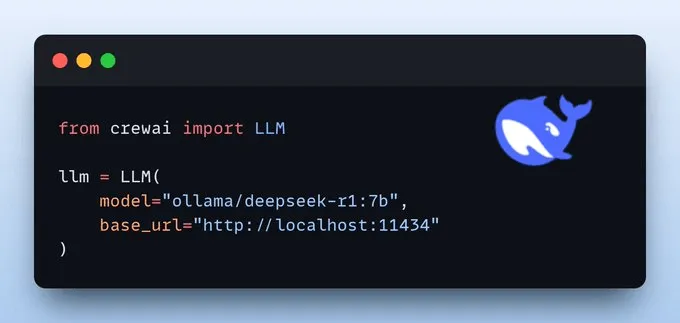
设置LLM我们将使用Deepseek-R1作为LLM,并通过Ollama在本地运行。
现在让我们来设置这个团队。
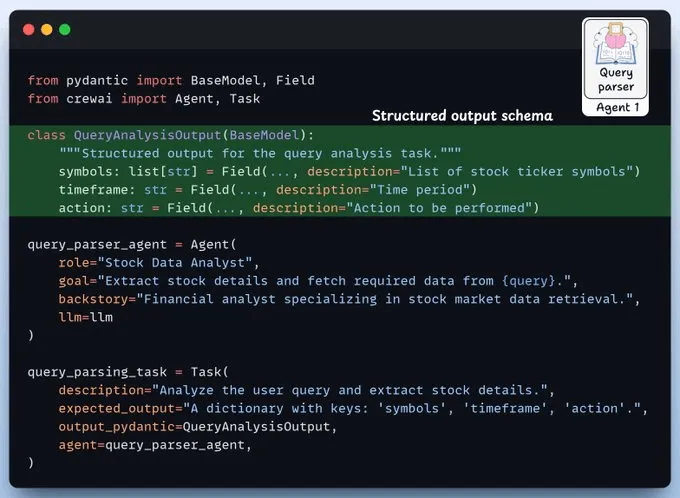
查询解析代理该代理接受自然语言查询,并使用 Pydantic 提取结构化输出。
这确保了后续处理时输入是清晰且结构化的!
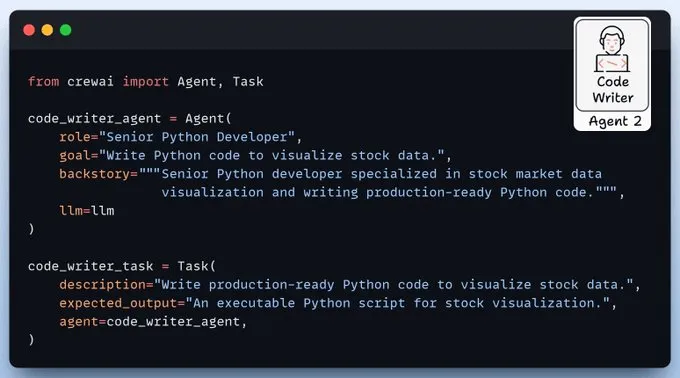
代码编写代理该代理负责编写Python代码,使用Pandas、Matplotlib和Yahoo Finance库来可视化股票数据。
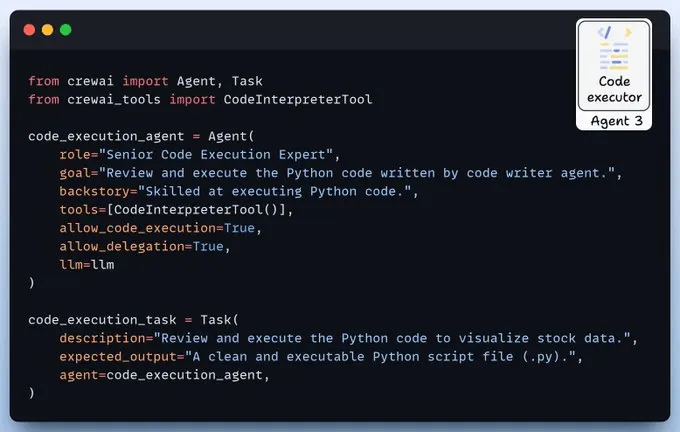
代码执行代理该代理负责审查并执行生成的Python代码,以实现股票数据可视化。
它利用CrewAI的代码解释器工具,在安全沙箱环境中执行代码。
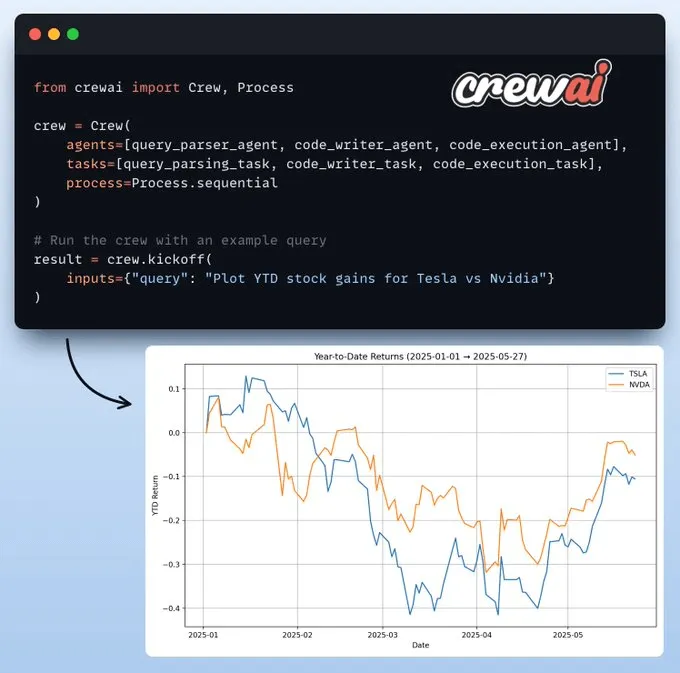
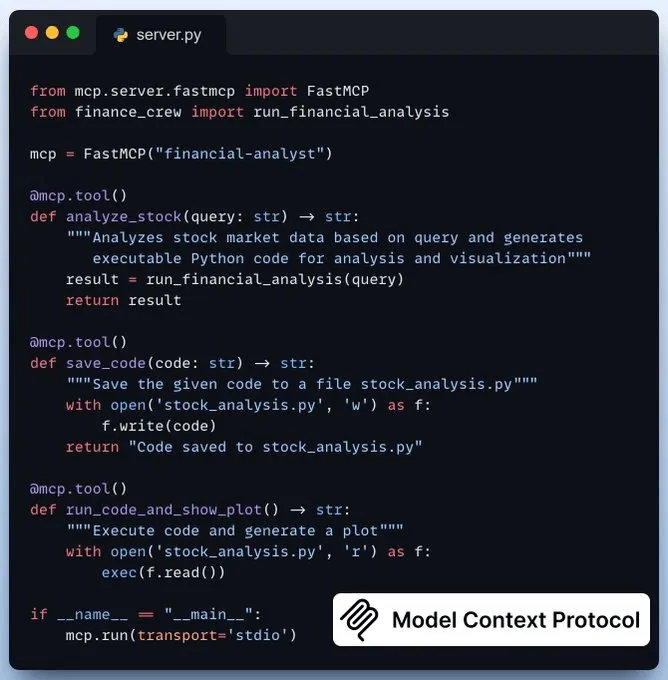
设置团队并启动在定义好我们的代理及其任务后,我们开始设置并启动我们的金融分析团队,以获得如下所示的结果!创建MCP服务器现在,我们将金融分析师功能封装为一个MCP工具,并增添两个额外工具以提升用户体验。save_code-> 将生成的代码保存到本地目录run_code_and_show_plot-> 执行代码并生成图表
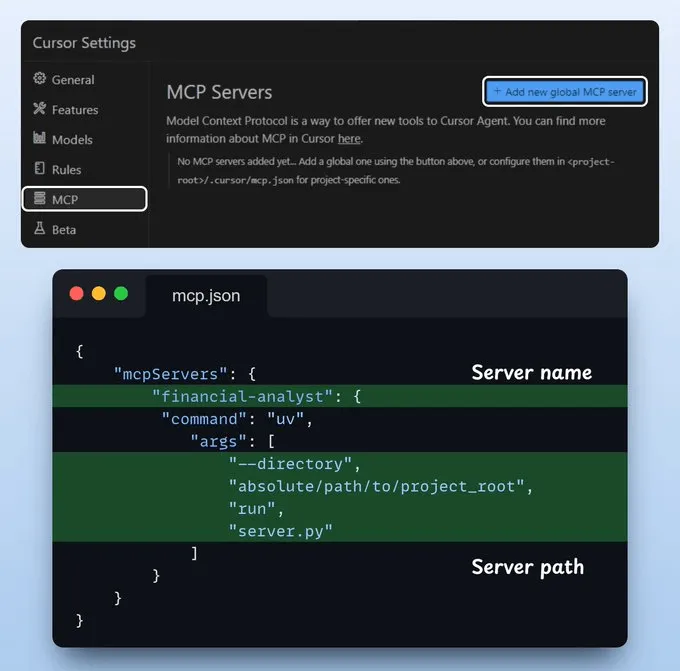
将 MCP 服务器与 Cursor 集成前往:文件 → 首选项 → Cursor 设置 → MCP → 添加新的全局 MCP 服务器。
在 JSON 文件中,添加如下所示内容 👇
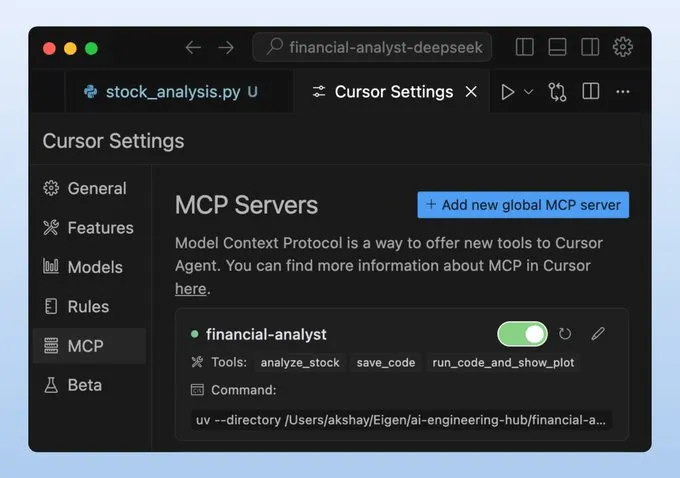
完成!我们的金融分析师 MCP 服务器已启动并成功连接到 Cursor!您可以与它讨论股票数据、请求生成图表等。顶部的视频为您提供了详细的操作演示。
您可以在以下GitHub仓库中找到相关代码 →https://preview.convertkit-mail2.com/click/dpheh0hzhm/aHR0cHM6Ly9naXRodWIuY29tL3BhdGNoeTYzMS9haS1lbmdpbmVlcmluZy1odWIvdHJlZS9tYWluL2ZpbmFuY2lhbC1hbmFseXN0LWRlZXBzZWVr?ref=dailydoseofds.com
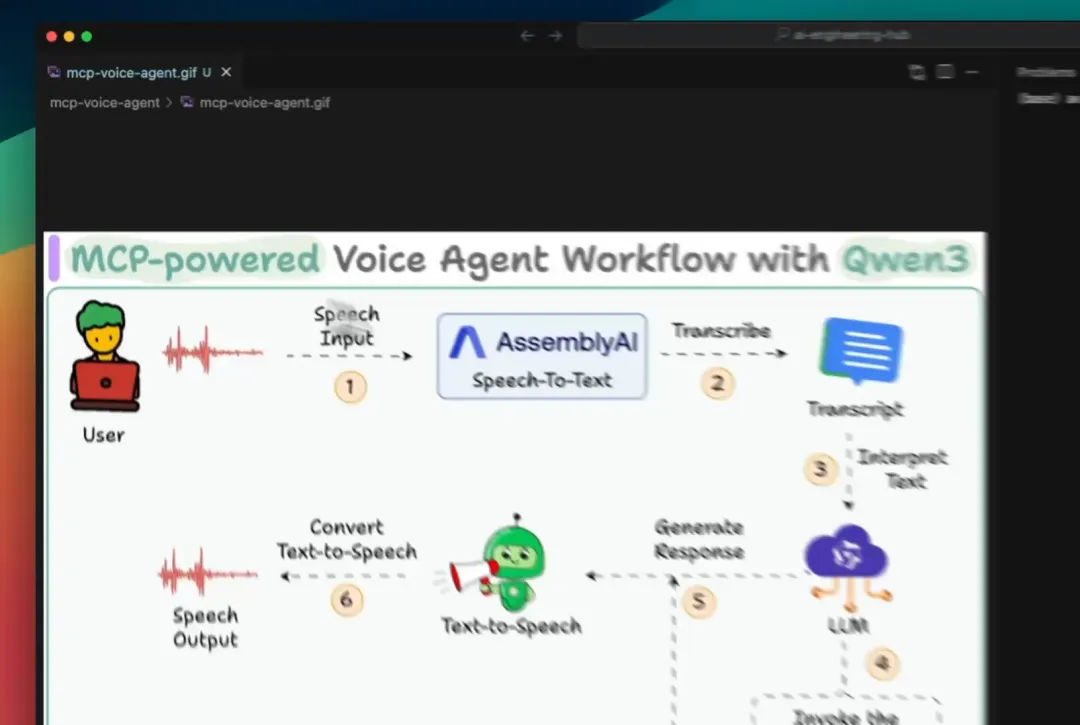
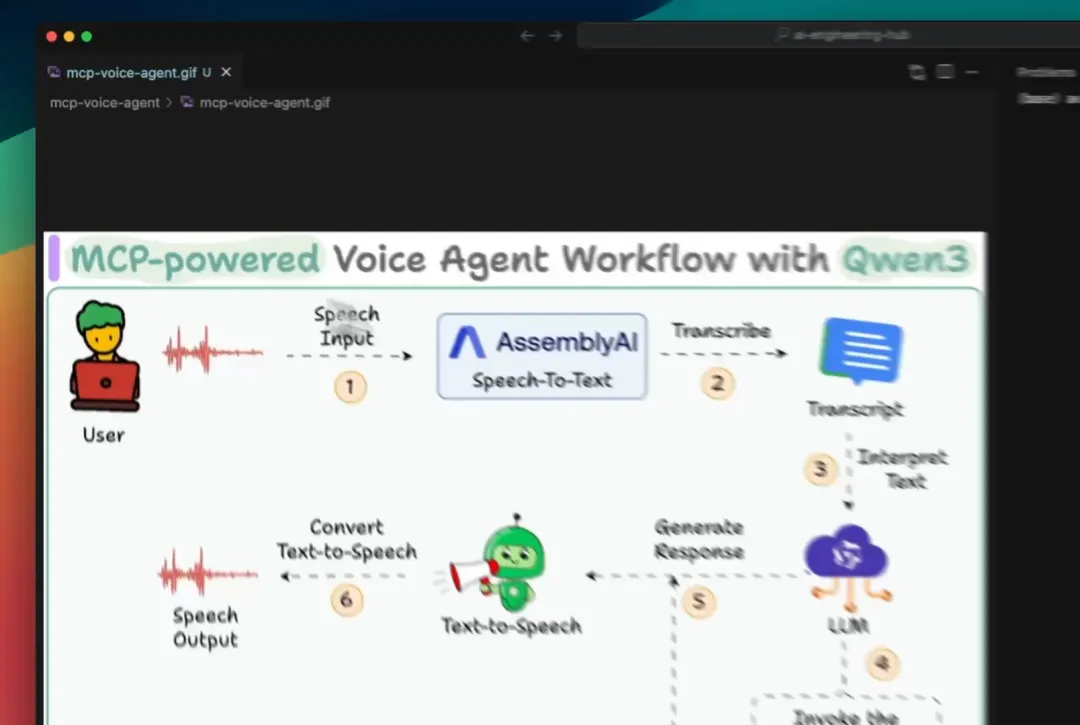
一个由 MCP 驱动的语音代理……搭载 Qwen 3 大语言模型。
在本章节中,我们将进行另一个 MCP 演示:一个由 MCP 驱动的语音代理。它能查询数据库,并在需要时回退到网络搜索。
技术栈如下:
AssemblyAI:用于语音转文本。
Firecrawl:用于网络搜索。
Supabase:作为数据库。
Livekit:用于流程编排。
Qwen3:作为大语言模型。
我们开始吧!
工作流程如下:
用户语音查询通过AssemblyAI转换为文本。
代理发现数据库及网络工具。
LLM 调用相应工具,获取数据并生成响应。
应用通过文本转语音交付响应。
让我们开始实现!
我们已在下方添加视频,完整演示此流程。
视频地址:https://www.dailydoseofds.com/content/media/2025/06/assemblyAI-voice-agent.mp4
包含代码与说明的 GitHub 仓库链接将在本文后续部分提供。
实现细节现在,让我们深入代码部分!
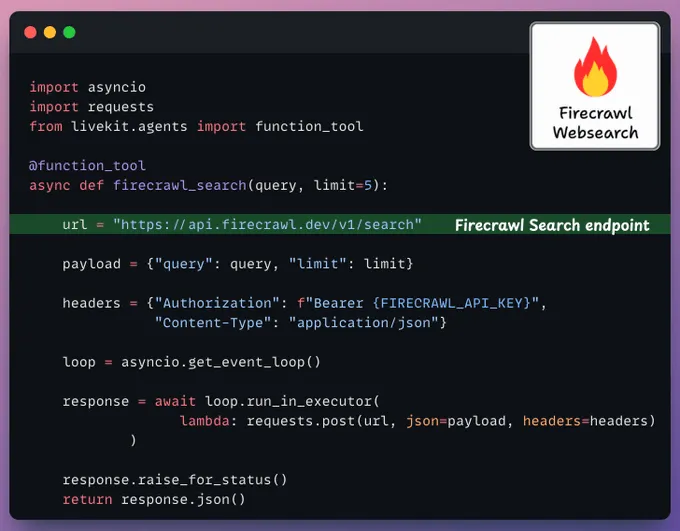
初始化 Firecrawl 与 Supabase我们实例化Firecrawl以启用网络搜索,并启动 MCP 服务器,向我们的代理公开 Supabase 工具。
初始化 Firecrawl 和 Supabase我们实例化Firecrawl以启用网络搜索,并启动我们的 MCP 服务器,以向我们的代理公开 Supabase 工具。
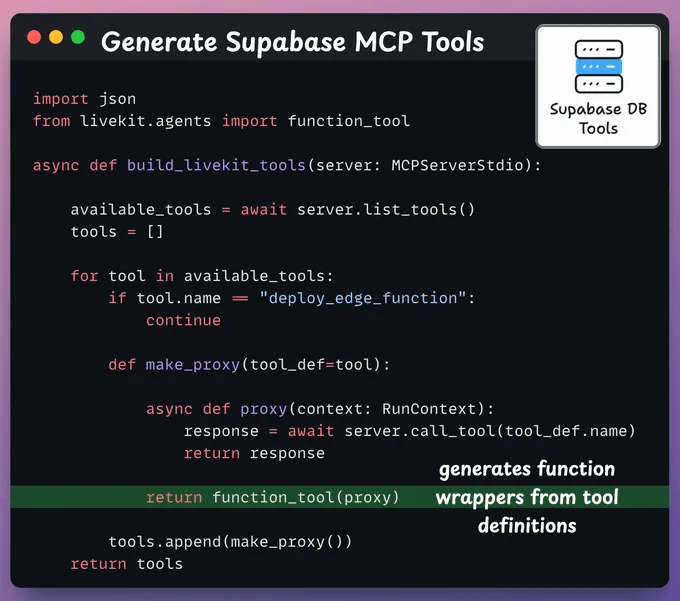
获取 Supabase MCP 工具我们通过 MCP 服务器列出 Supabase 工具,并将它们逐一封装为 LiveKit 工具,以供我们的代理使用。
构建代理我们通过设置指令来配置代理,指导其如何处理用户查询。
同时,我们赋予它访问先前定义好的 Firecrawl 网络搜索工具和 Supabase 工具的权限。
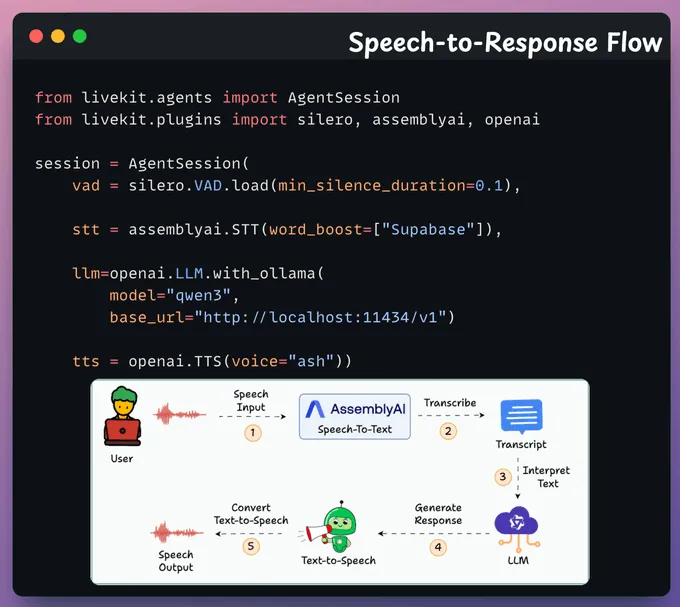
配置从语音到响应的流程
我们使用 AssemblyAI 的语音转文本功能转录用户的语音。由 Ollama 在本地运行的 Qwen 3 大语言模型会调用正确的工具。通过文本转语音生成语音输出。
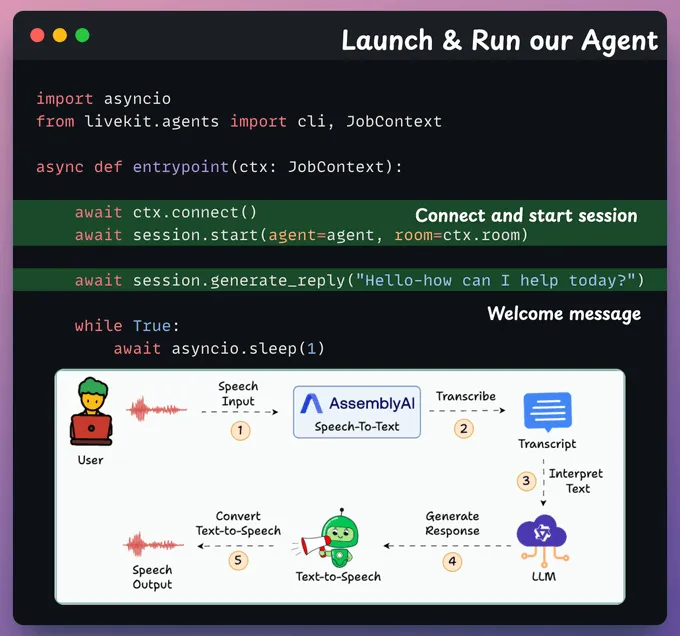
启动代理我们连接到 LiveKit,以问候语开始会话,然后持续监听并响应用户,直至用户结束。
视频地址:https://www.dailydoseofds.com/content/media/2025/06/assemblyAI-voice-agent.mp4
如果查询与数据库相关,它会通过 MCP 工具查询 Supabase。否则,它将通过 Firecrawl 执行网络搜索。
您可以在以下 GitHub 仓库中找到重现此演示的代码
→https://github.com/patchy631/ai-engineering-hub/tree/main/mcp-voice-agent?ref=dailydoseofds.com
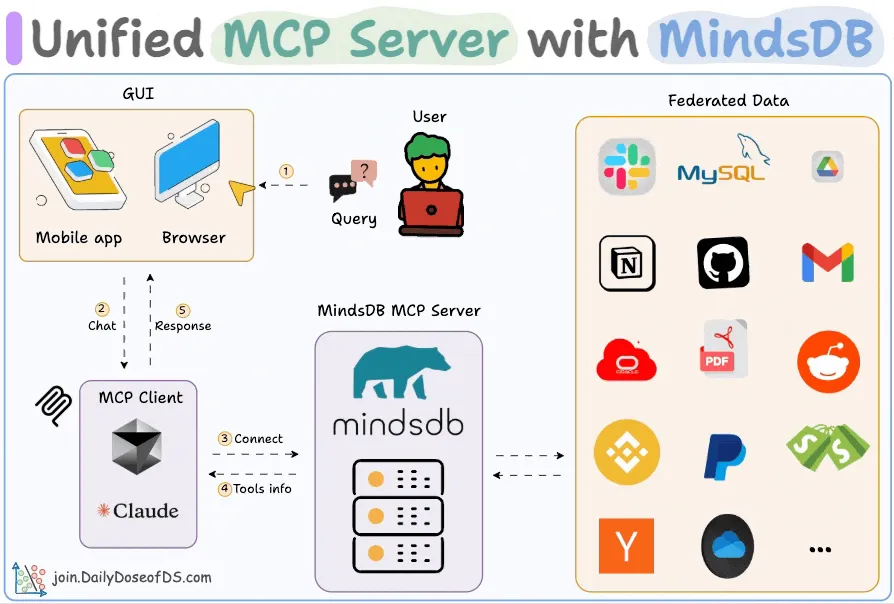
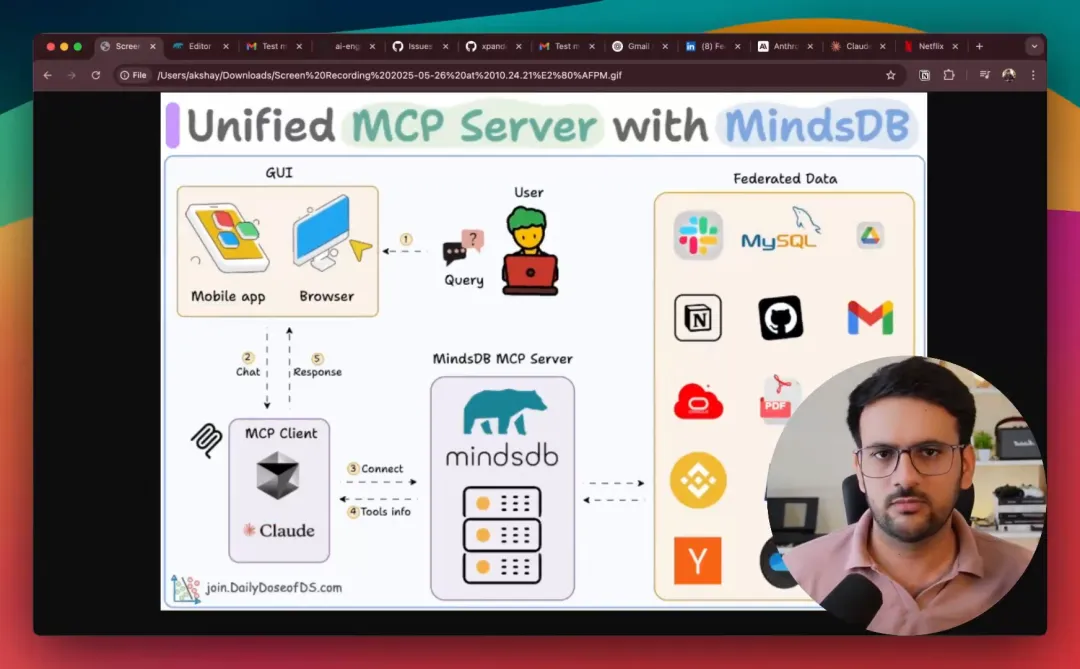
构建一个可连接 200+ 数据源的 MCP 服务器
一个为您的所有数据提供统一接入的 MCP 服务器(100% 本地运行)。
组织的资料散落在各处——Slack、Gmail、SQL、Drive 等等,不一而足!
我们构建了一个能够连接200 多个此类数据源的 MCP 服务器,并且它是100% 本地运行的。
我们的技术栈:
工作流程如下:
用户提交查询。代理连接到 MindsDB MCP 服务器以查找可用工具。代理根据用户查询选择合适的工具并调用它。最终,代理返回一个与上下文相关的响应。
我们已在下方添加视频,完整演示此流程。
视频地址:https://www.dailydoseofds.com/content/media/2025/06/mindsdb-unified-MCP.mp4
包含代码和说明的GitHub仓库链接将在本文后续部分提供。
实现细节现在,让我们深入代码部分!
Docker 设置MindsDB 提供了可在 Docker 容器中运行的 Docker 镜像。
通过在终端中运行以下命令,使用 Docker 镜像在本地安装 MindsDB:
启动 MindsDB 图形用户界面安装 Docker 镜像后,在浏览器中访问127.0.0.1:47334即可进入 MindsDB 编辑器。
通过此界面,您可以连接到200 多个数据源,并对它们运行 SQL 查询。
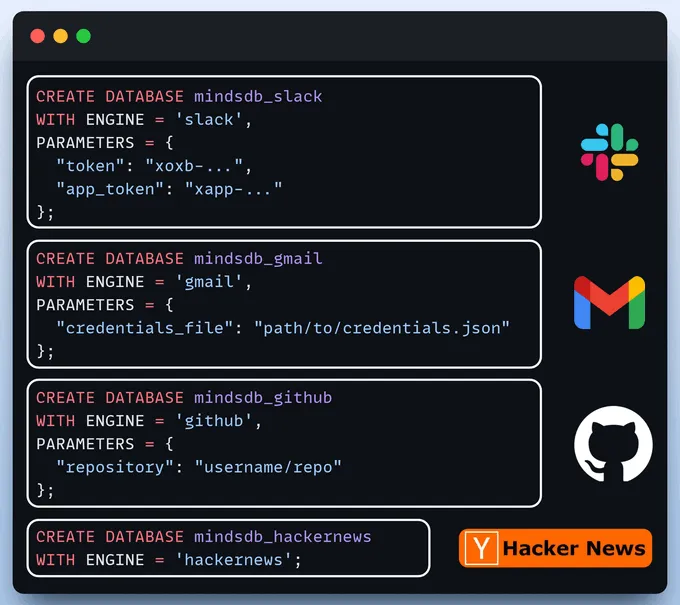
集成数据源让我们开始构建联邦查询引擎,将数据源连接到 MindsDB。
我们使用 Slack、Gmail、GitHub 和 Hacker News 作为联邦数据源。
视频地址:https://www.dailydoseofds.com/content/media/2025/06/mindsdb-mcp-1.mp4将 MCP 服务器与 Cursor 集成构建好联邦查询引擎后,让我们通过将数据源连接到 MindsDB 的 MCP 服务器来实现统一。
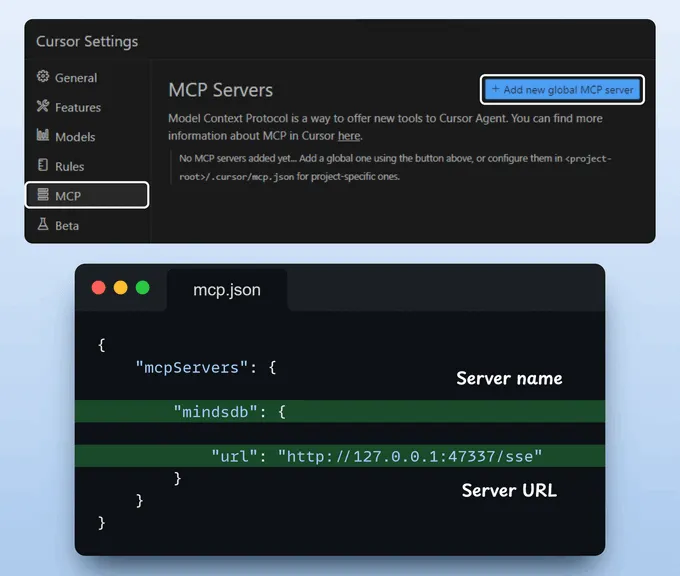
前往:文件 → 首选项 → Cursor 设置 → MCP → 添加新的全局 MCP 服务器
在 JSON 文件中,添加以下内容 👇
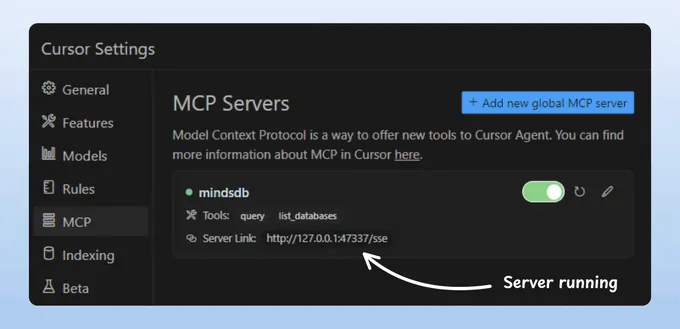
完成!我们的 MindsDB MCP 服务器已启动并成功连接到 Cursor!
该 MCP 服务器提供两个工具:
list_databases:列出所有已连接到 MindsDB 的数据源。query:基于联邦数据回答用户查询。
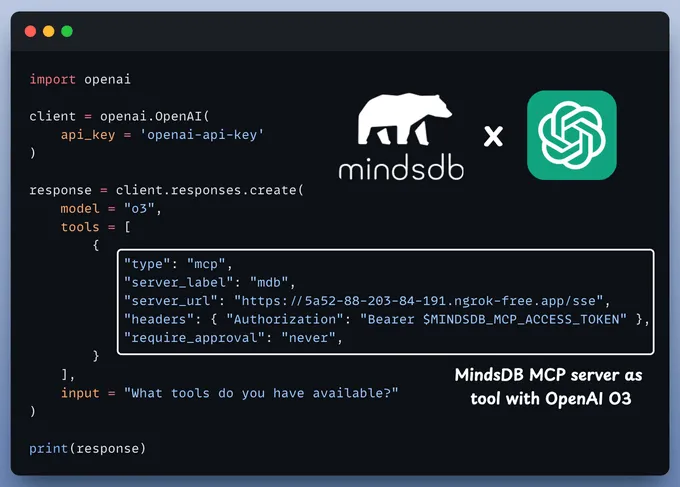
除了 Claude 和 Cursor,MindsDB MCP 服务器也可用于新的 OpenAI MCP 集成:
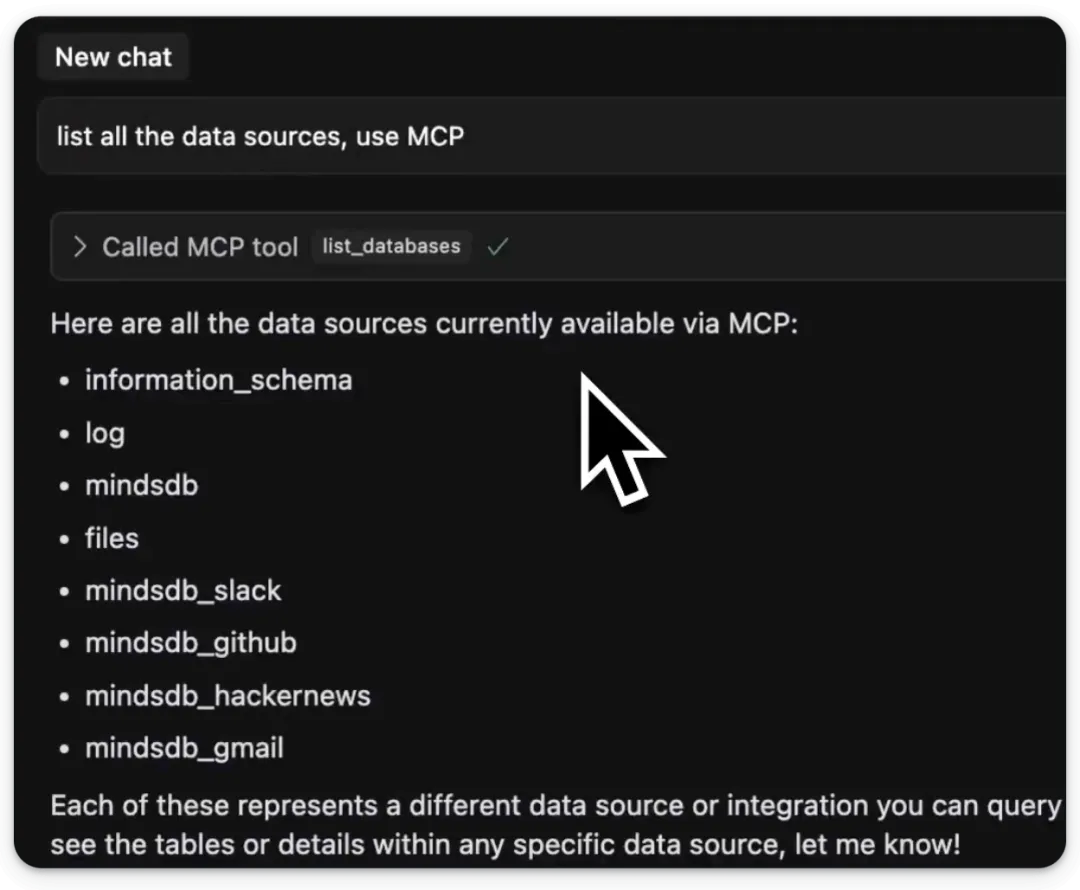
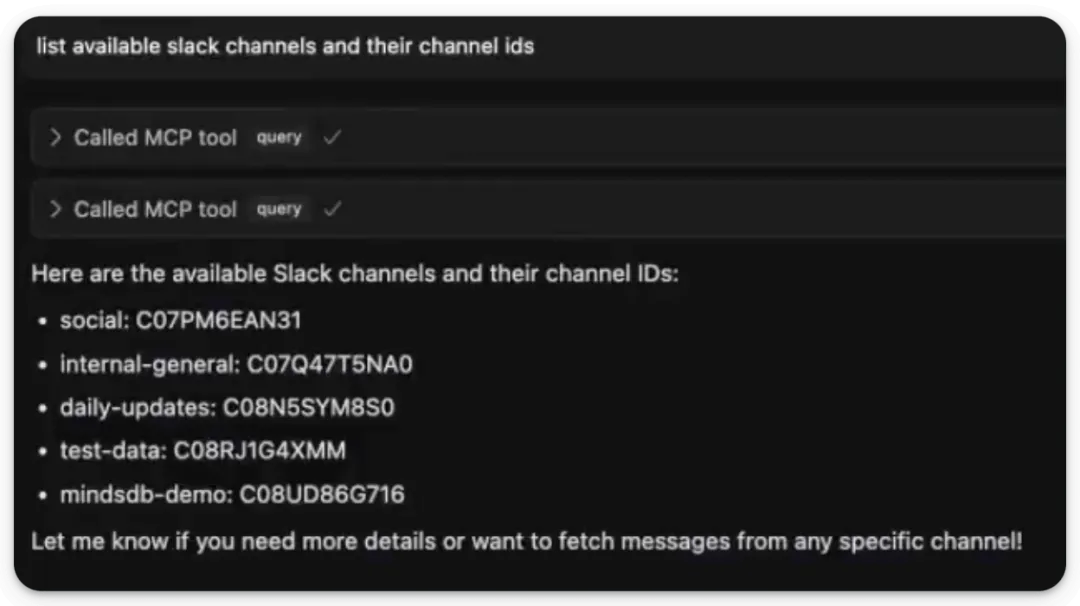
下图展示了list_databases工具的使用情况。我们要求它列出所有可访问的数据源,并成功检索到我们先前连接的四个数据源:下方是另一个使用示例,我们要求它列出可用的 Slack 频道。尽管这个例子相当基础,但我们已在顶部附带的视频中展示了更为复杂和高级的用法。
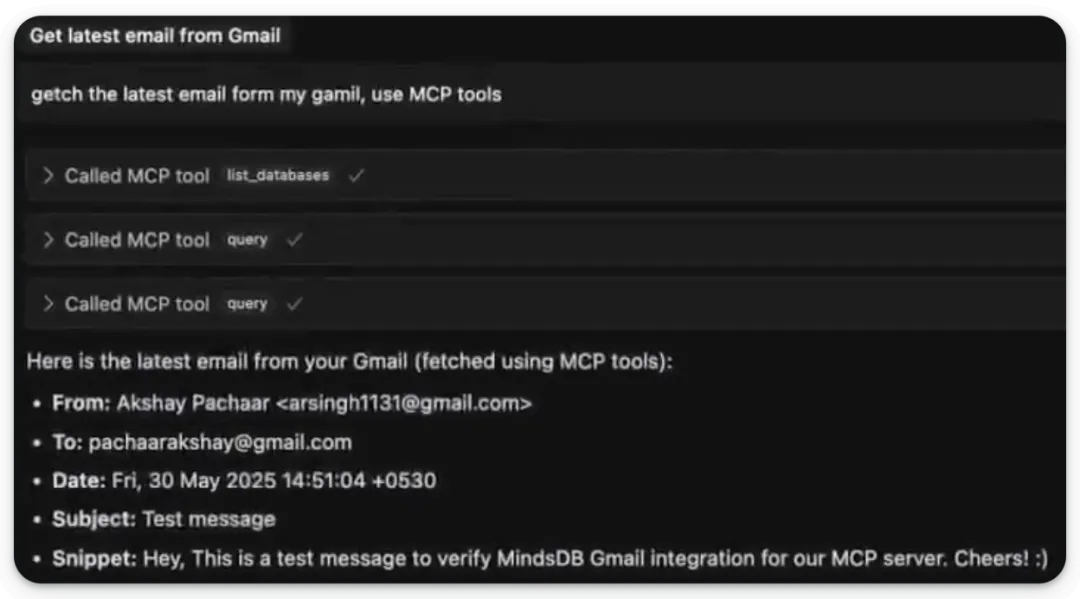
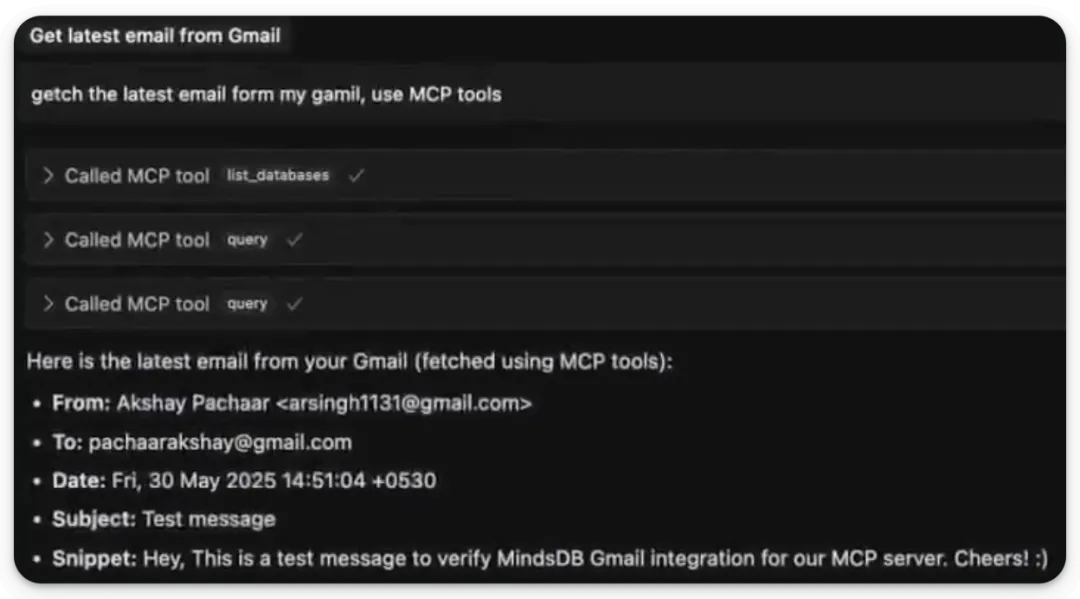
我们从 Hacker News 获取信息。我们生成了格式美观的摘要,并将该摘要作为消息发送到了 Slack。我们要求 MCP 服务器从 Gmail 获取最新的邮件,并且它成功完成了:
尽管这个例子相当基础,但我们已在顶部附带的视频中展示了更为复杂和高级的用法。
视频地址:https://www.dailydoseofds.com/content/media/2025/06/mindsdb-unified-MCP.mp4您可以在 GitHub 仓库中找到重现此演示的代码:→https://github.com/patchy631/ai-engineering-hub/tree/main/mindsdb-mcp?ref=dailydoseofds.com
现在让我们继续下一个项目吧!
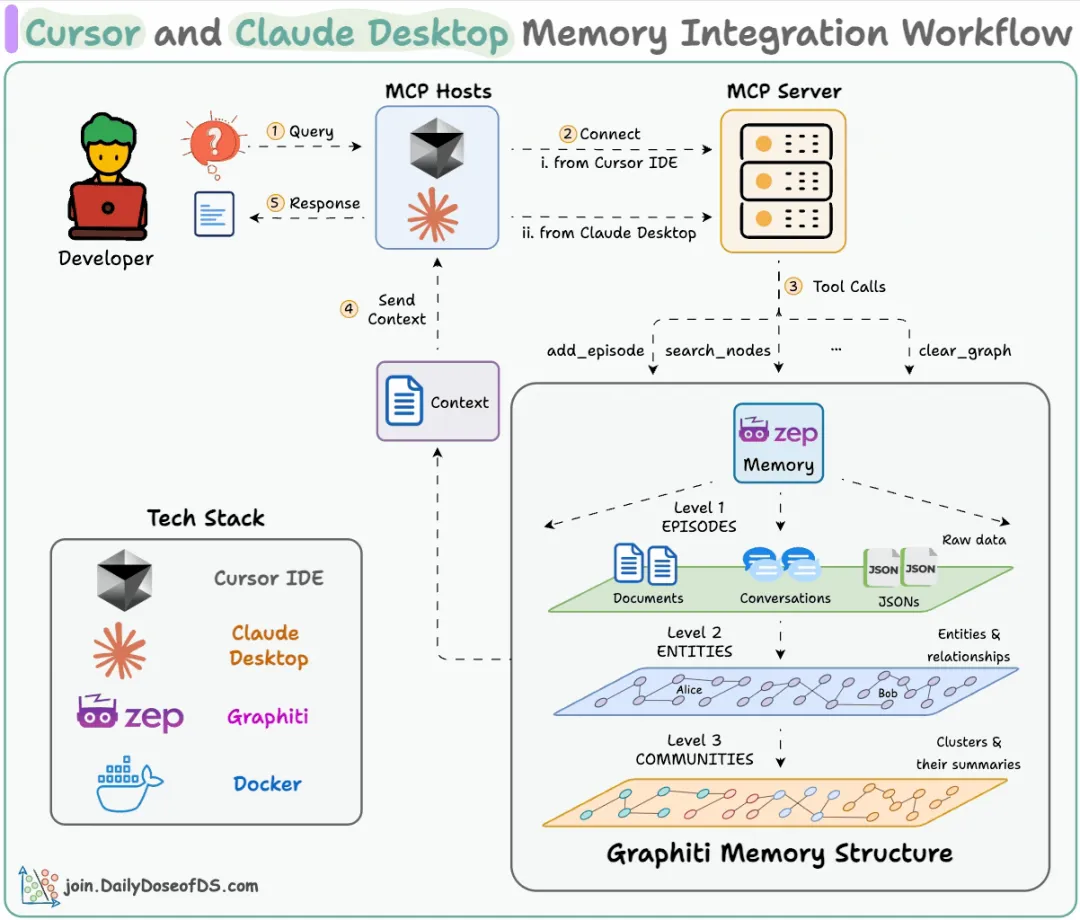
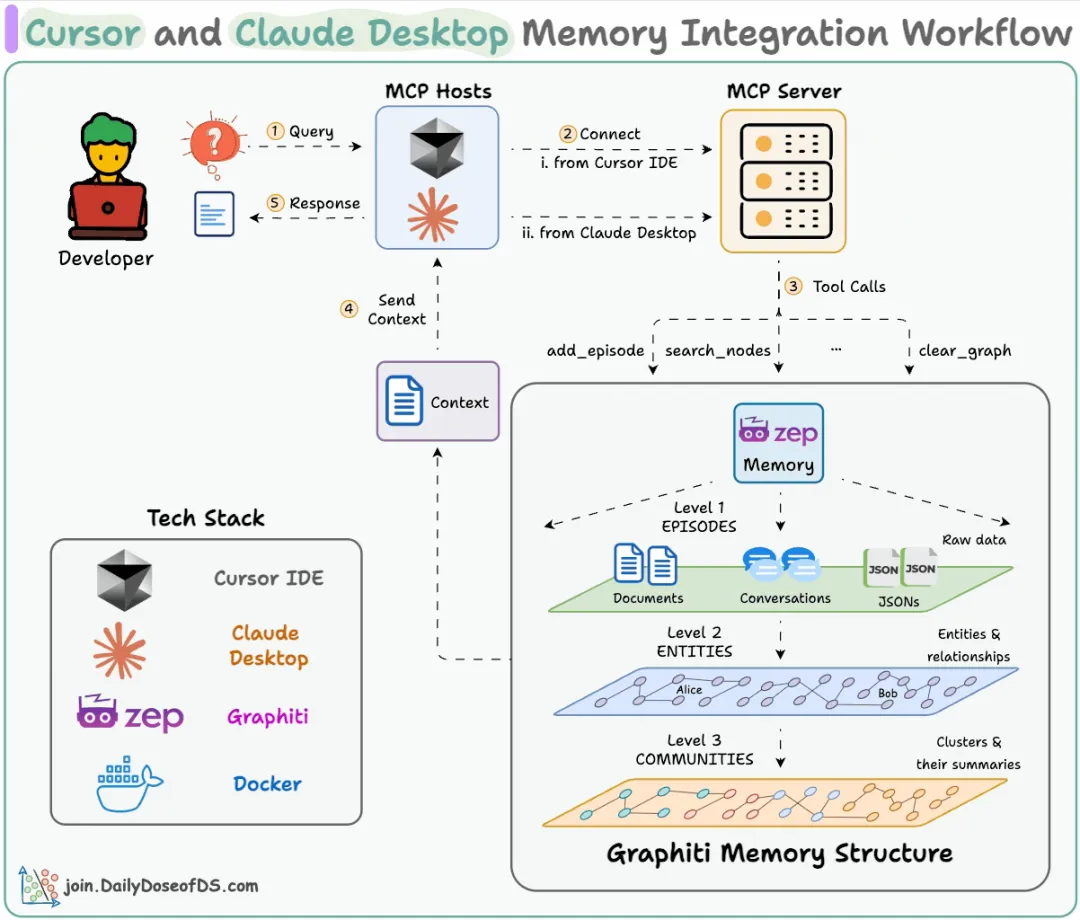
为 Claude Desktop 和 Cursor 构建共享内存100% 本地化开发者通常独立使用 Claude Desktop 和 Cursor,二者之间没有上下文共享或连接。
换句话说,Claude Desktop(一个 MCP 宿主)无法感知你在 Cursor(另一个 MCP 宿主)中的操作,反之亦然。
在本项目中,我们将展示如何为 Claude Desktop 和 Cursor 添加一个公共的内存层,以便您能在不丢失上下文的情况下进行跨应用操作。
我们的技术栈:
工作流程如下:
用户向 Cursor 和 Claude 提交查询。事实/信息通过 Graphiti MCP 存储在一个公共内存层中。在任何交互中如需上下文,则会查询该内存。Graphiti 在多个宿主之间共享内存。
我们已在下方添加视频,演示最终效果:
视频地址:https://www.dailydoseofds.com/content/media/2025/06/zep-claude-cursor-connected-memory-1.mp4实现细节现在,让我们深入代码部分!
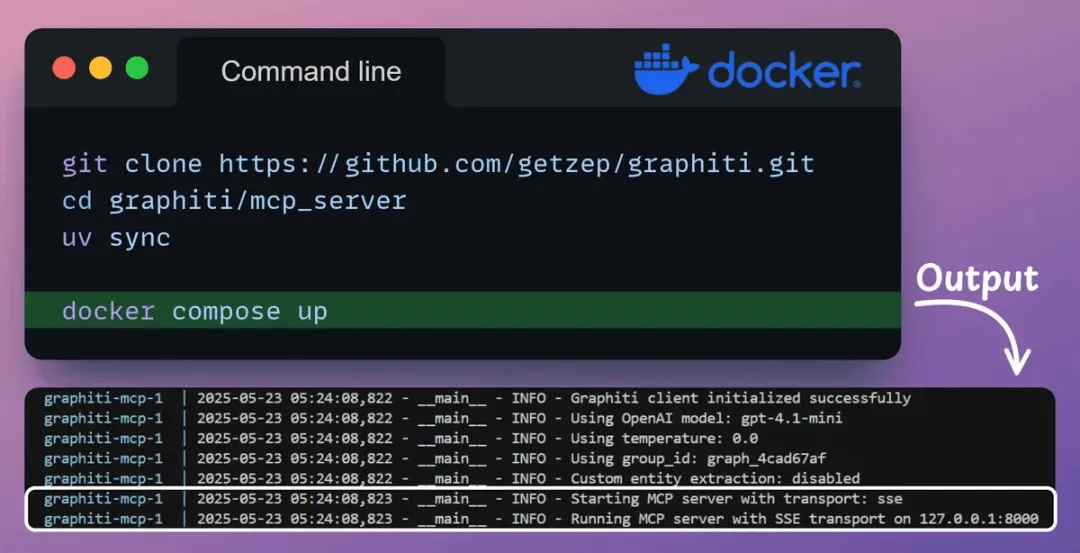
Docker 设置使用 Docker Compose 在本地部署 Graphiti MCP 服务器。此设置将启动支持服务器发送事件传输方式的 MCP 服务器。
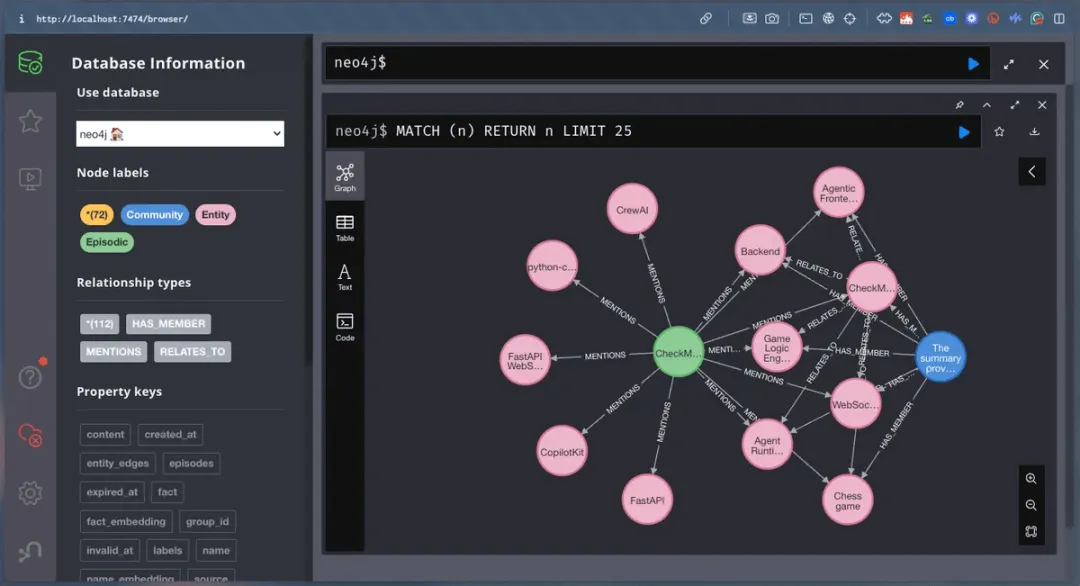
上述 Docker 设置包含一个 Neo4j 容器,它会将数据库作为本地实例启动。
此配置允许您使用 Neo4j 浏览器预览来查询和可视化知识图谱。
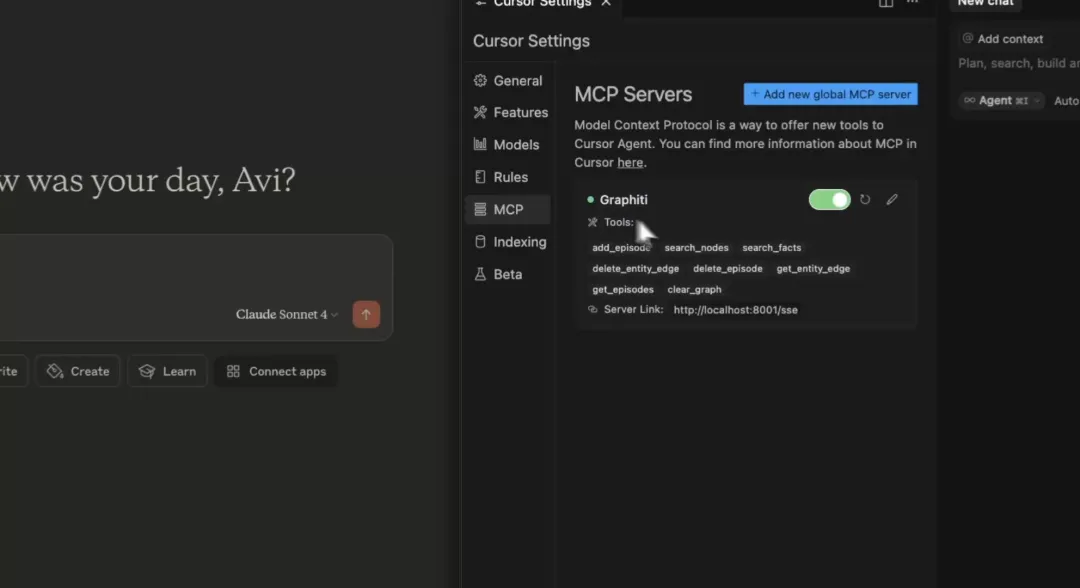
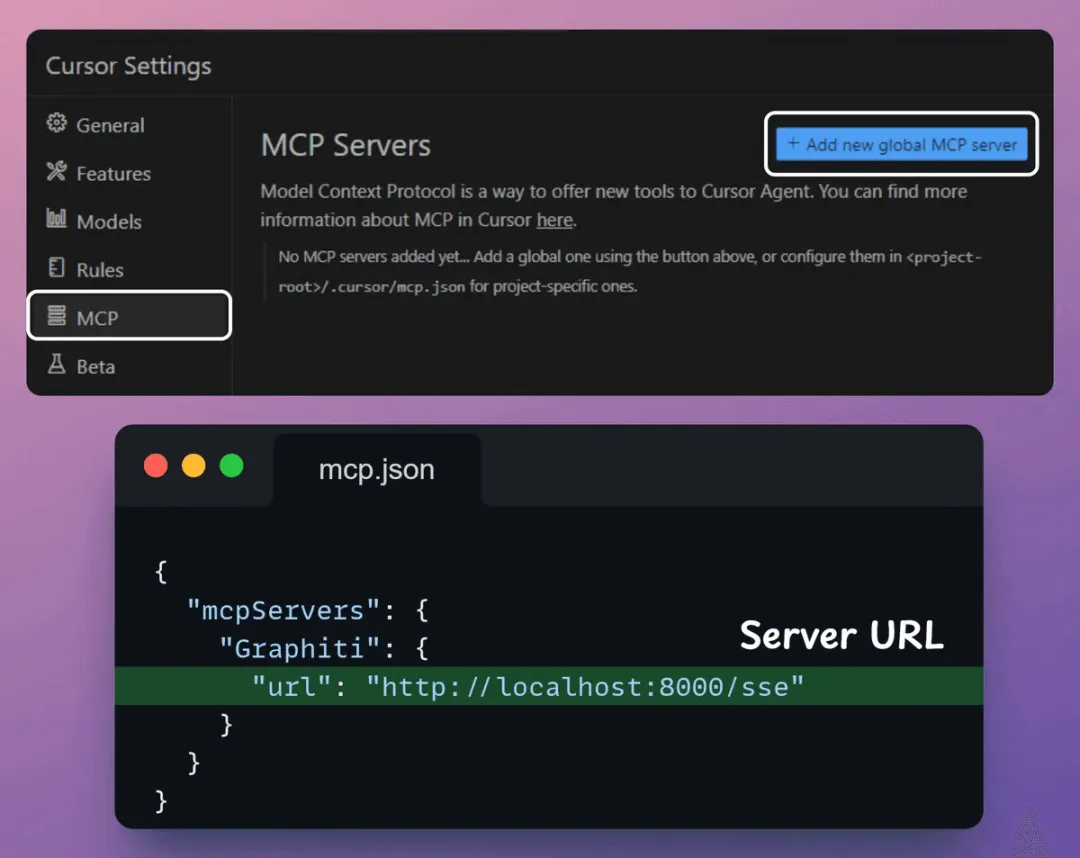
将 MCP 服务器连接至 Cursor工具和服务器准备就绪后,让我们将其集成到 Cursor IDE 中!
前往:文件 → 首选项 → Cursor 设置 → MCP → 添加新的全局 MCP 服务器。
在 JSON 文件中,添加如下所示内容:
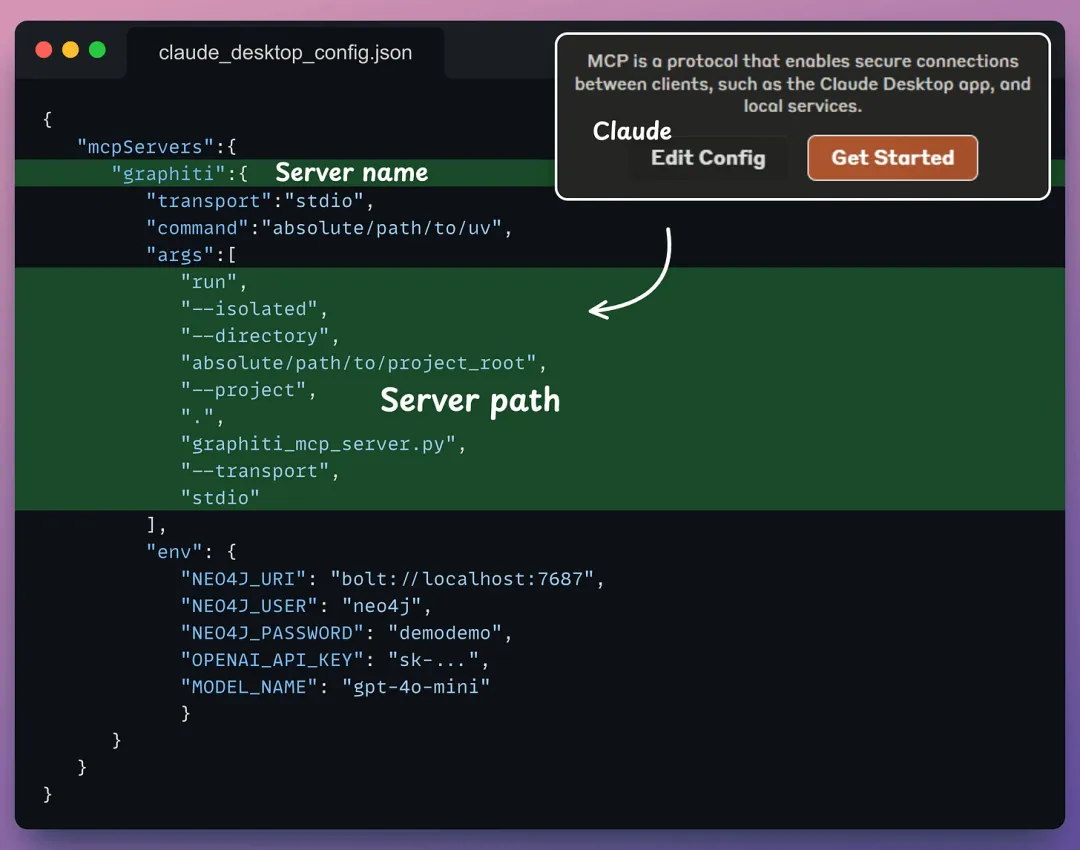
将 MCP 服务器连接至 Claude工具和服务器准备就绪后,让我们将其集成到 Claude Desktop 中!
前往:文件 → 设置 → 开发者 → 编辑配置。
在 JSON 文件中,添加如下所示内容:
完成!
我们的 Graphiti MCP 服务器已启动并成功连接至 Cursor 和 Claude!
现在,您可以与 Claude Desktop 对话、共享事实/信息、将响应存储在内存中,并在 Cursor 中检索它们,反之亦然:
通过这种方式,您可以将 Claude 的洞察直接传递到 Cursor,所有操作都通过单一的 MCP 完成。
总结来说,以下是完整的工作流程,供您参考:
完成!
我们的 Graphiti MCP 服务器已启动并成功连接至 Cursor 和 Claude!
现在,您可以与 Claude Desktop 对话、共享事实/信息、将响应存储在内存中,并在 Cursor 中检索它们,反之亦然:
虽然上述详细步骤应能为您提供帮助,但您可以在Graphiti MCP 自述文件 →https://github.com/getzep/graphiti/tree/main/mcp_server?ref=dailydoseofds.com中找到详细的设置指南。
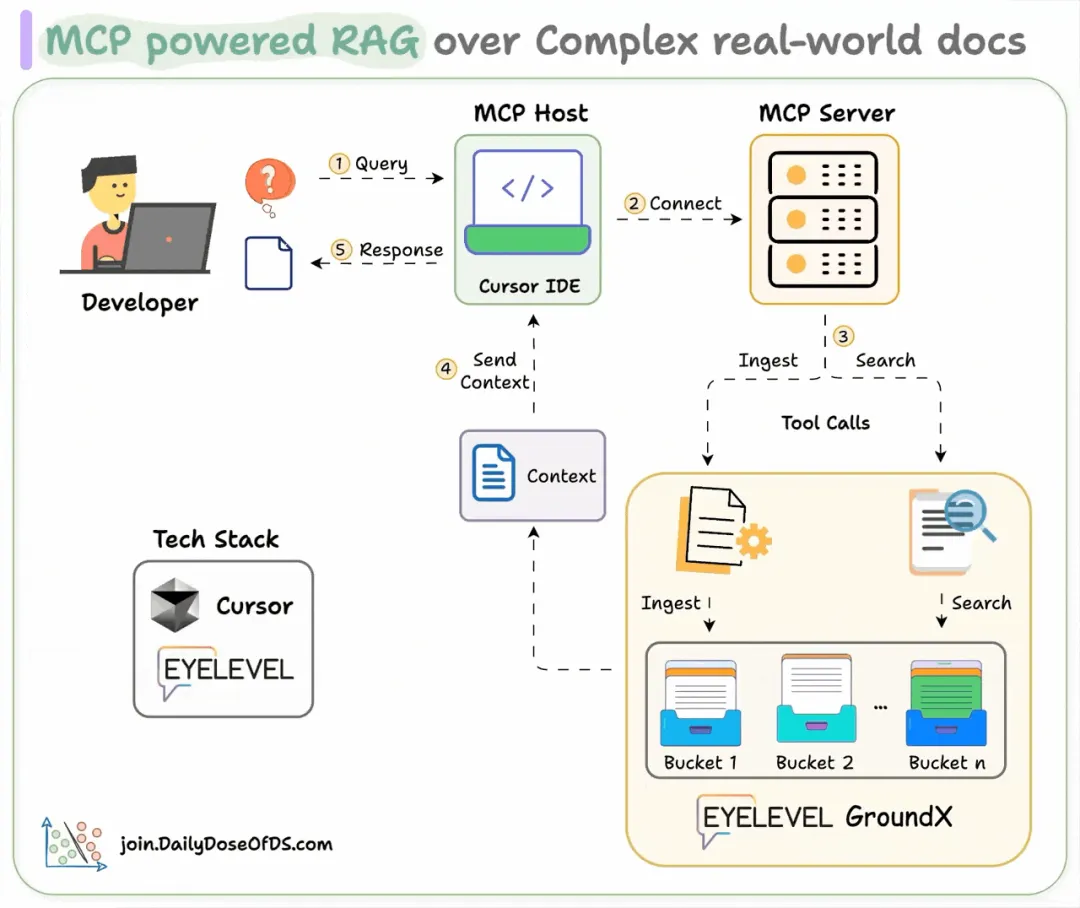
基于 MCP 的复杂文档检索增强生成……含动手实践实现。在本章节中,我们将向您展示我们如何利用 MCP 为复杂文档提供动力的检索增强生成应用。
为了让您有更深入的了解,以下是我们使用的文档:
技术栈如下:
其工作原理如下:
实现细节现在,让我们深入代码部分!包含代码的 GitHub 仓库链接将在本文后续提供。
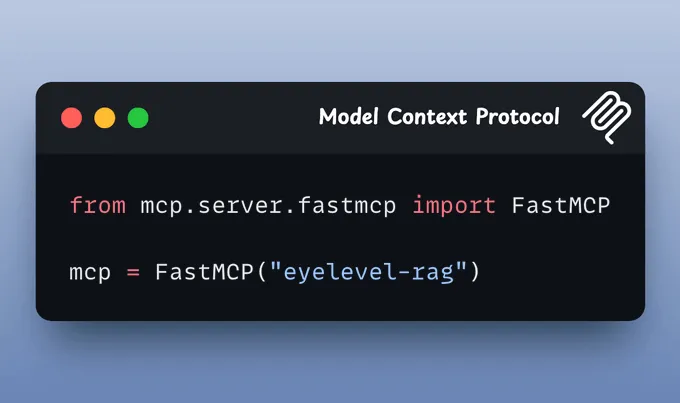
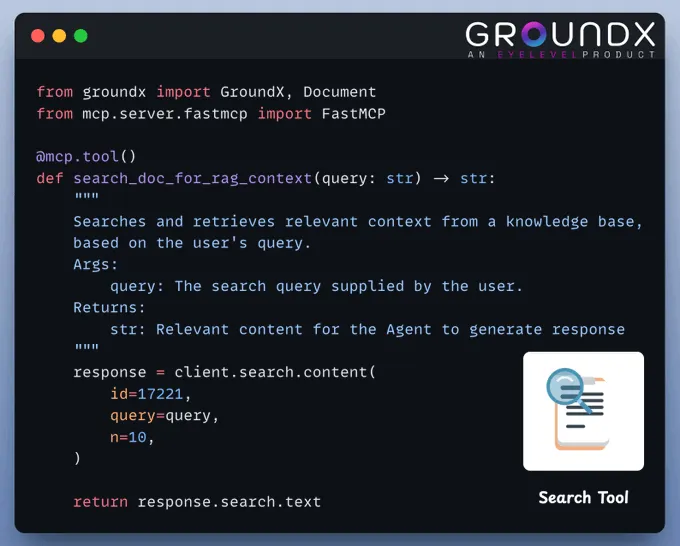
(1) 设置服务器首先,我们使用 FastMCP 设置一个本地 MCP 服务器,并为其提供一个名称。
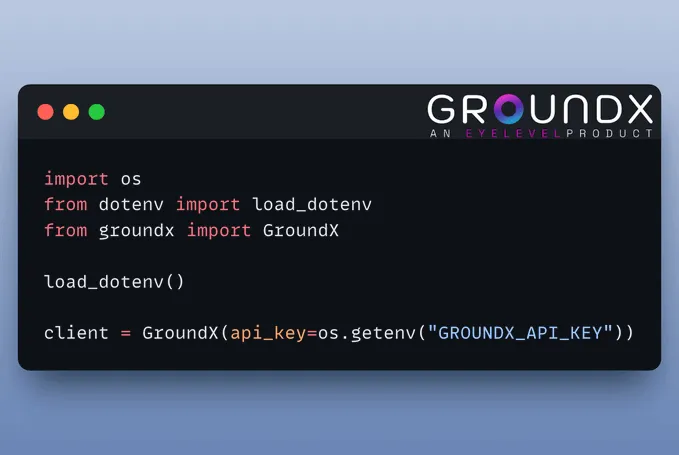
(2) 创建 GroundX 客户端GroundX 为复杂的现实世界文档提供文档搜索和检索能力。您需要在此处获取 API 密钥并将其存储在 .env 文件中。
完成后,按如下方式设置客户端:
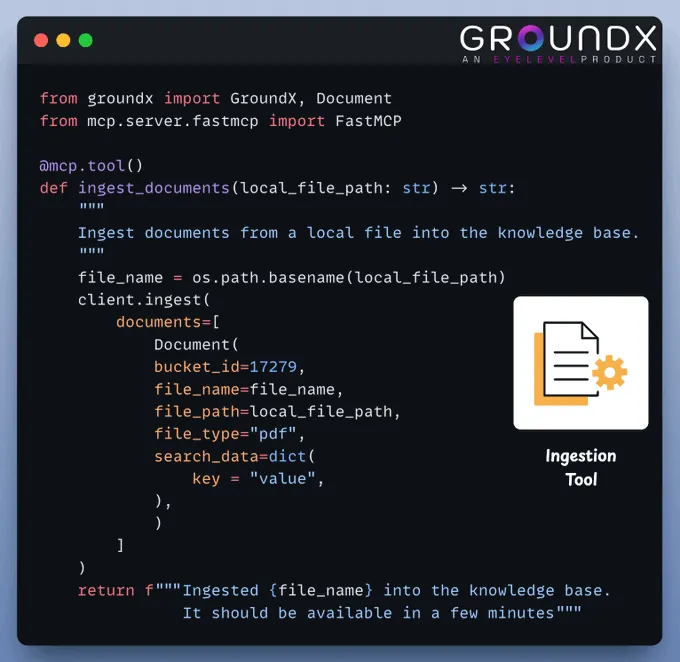
(3) 创建文档摄取工具此工具用于将新文档摄取到知识库中。
用户只需提供待摄取文档的路径即可:
(4) 创建搜索工具该工具利用 GroundX 的高级功能,从复杂的现实世界文档中进行搜索和检索。
其实现方式如下:
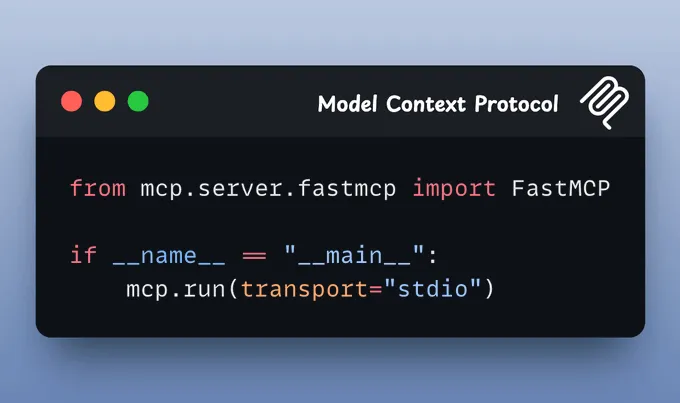
(5) 启动服务器使用标准输入/输出作为传输机制启动 MCP 服务器:(6) 连接到 Cursor在您的 Cursor IDE 中,按照以下步骤操作:
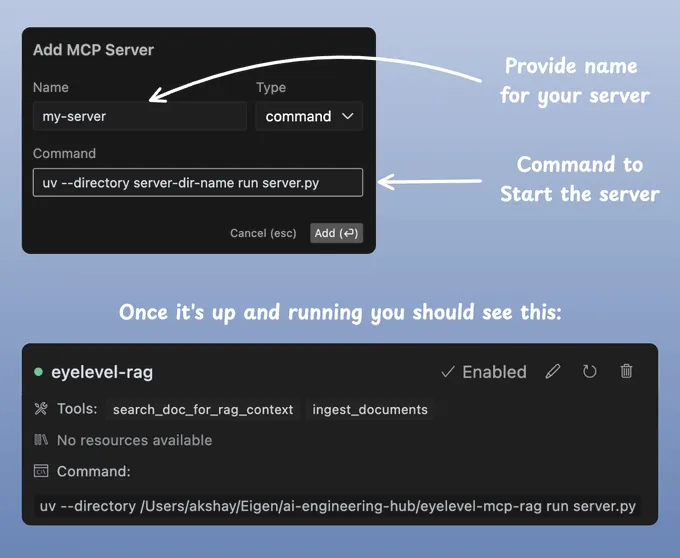
Cursor → 设置 → Cursor 设置 → MCP
然后像这样添加并启动您的服务器:
完成!
现在,您可以直接通过 Cursor IDE 与这些文档进行交互。
下面的视频展示了操作演示:
您可以在此处针对您的复杂文档测试
→https://eyelevel.ai/?ref=dailydoseofds.com
我们在所有复杂用例中都使用 EyeLevel,因为它构建了强大的企业级解析系统,能够智能地分块相关并理解每个块中的内容,无论是文本、图像还是图表,如下图所示:
如上图所示,该系统接收非结构化(文本、表格、图像、流程图)输入,并将其解析为 LLM 易于处理的 JSON 格式,从而构建检索增强生成系统。
此外,本演示的代码可在此 GitHub 仓库 →中找到。
https://github.com/patchy631/ai-engineering-hub/tree/main/eyelevel-mcp-rag?ref=dailydoseofds.com
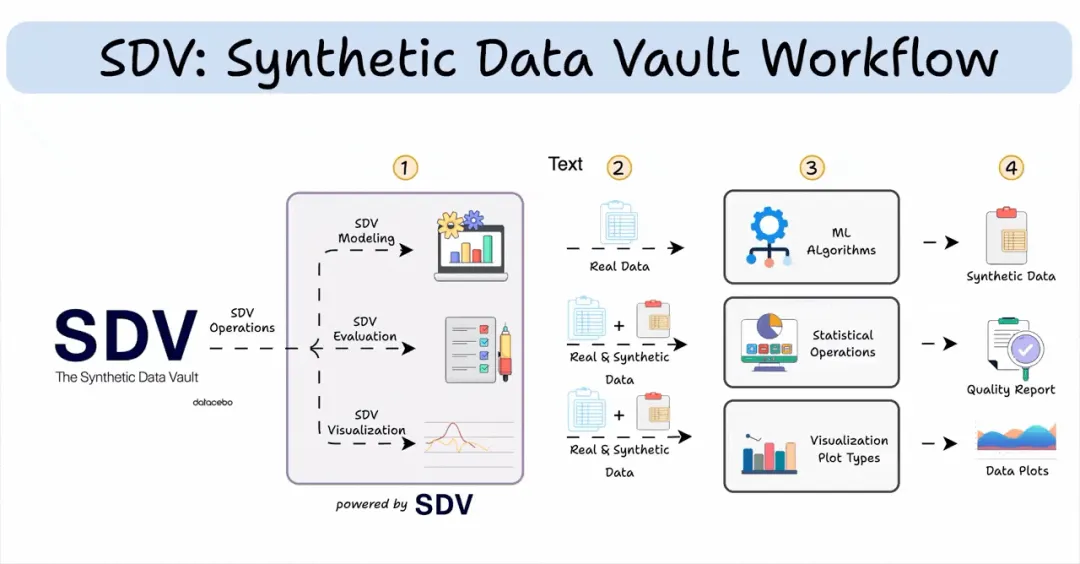
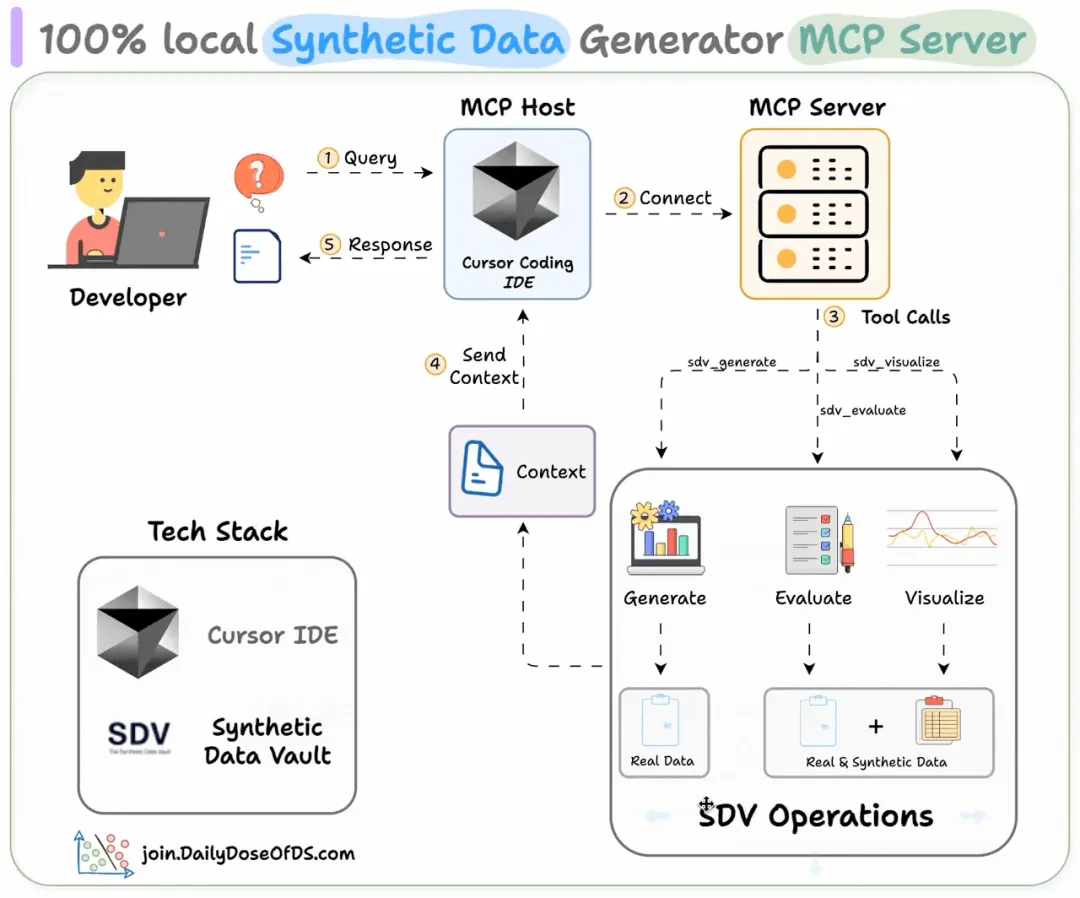
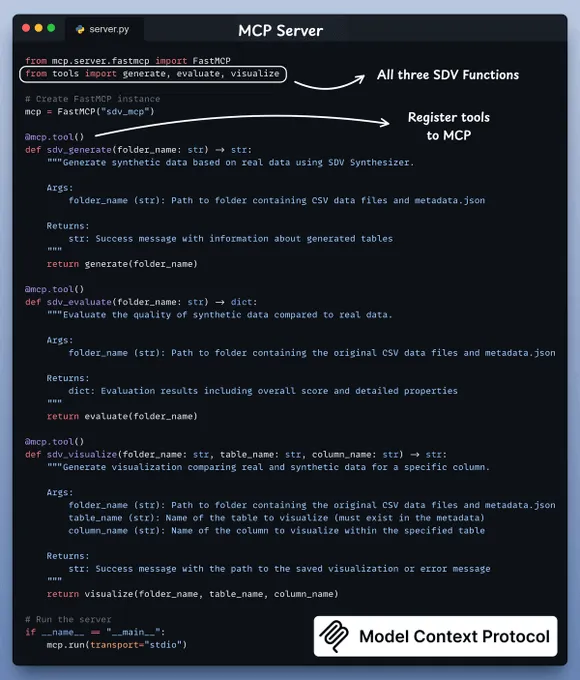
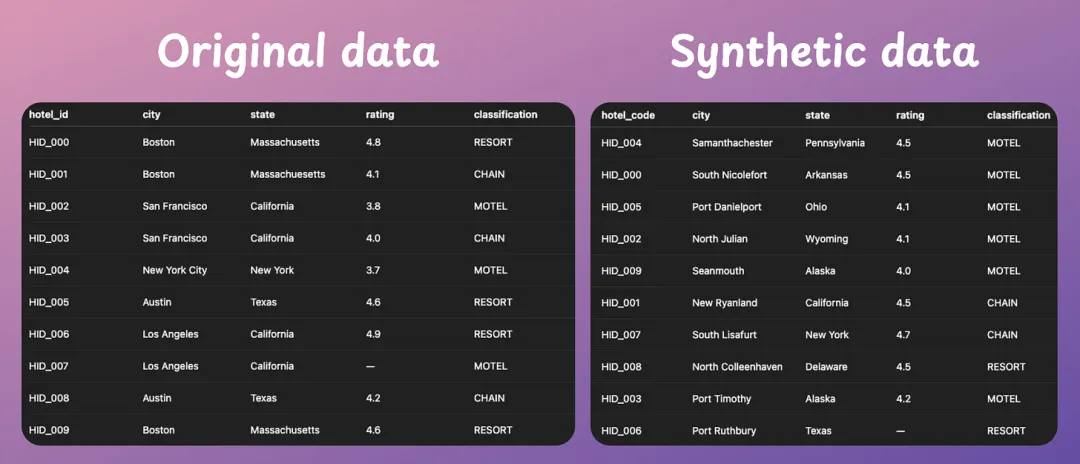
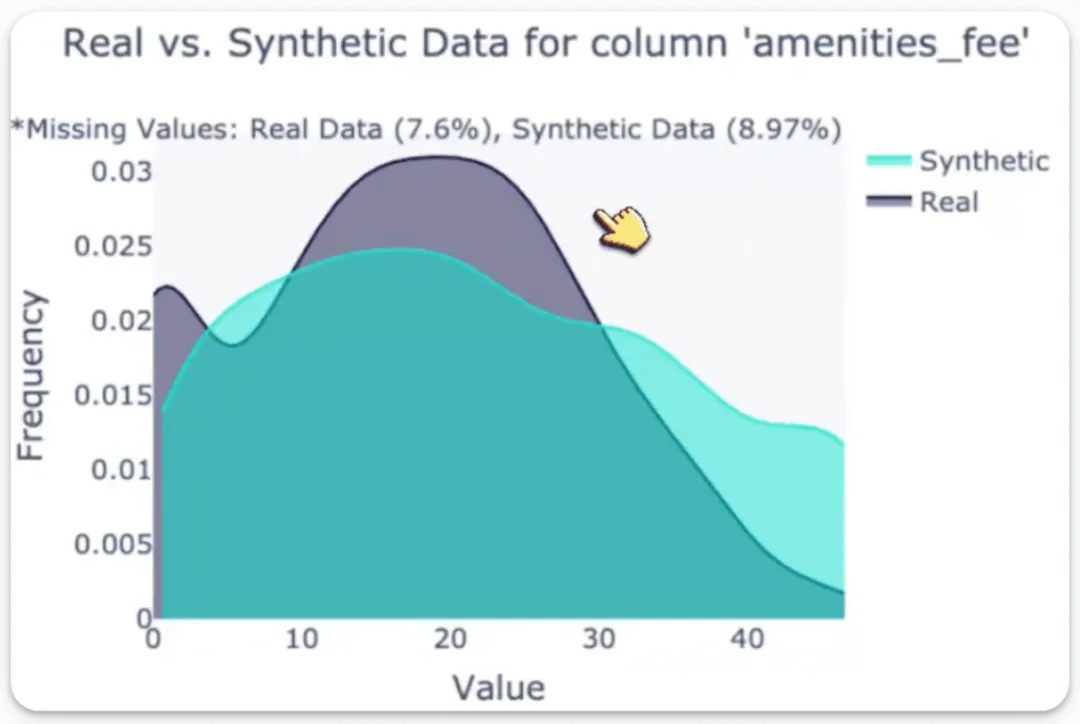
基于 MCP 的合成数据生成器使用现有数据生成逼真数据(100% 本地化)。在本章节中,我们将构建一个所有数据科学家都会喜爱的 MCP 服务器。
这是一个能够生成任何类型合成数据集的 MCP 服务器。
合成数据集非常重要,因为它能让我们从现有样本中获得更多数据,尤其是在现实世界数据有限、不平衡或敏感的情况下。
我们的技术栈如下:
用户提交查询代理连接至 MCP 服务器以查找工具代理根据查询使用合适的工具返回关于合成数据创建、评估或可视化的响应
如果您更喜欢观看视频,这里有一个完整的操作演示:
视频地址:https://www.dailydoseofds.com/content/media/2025/06/sdv-demo-new1.mp4包含代码的 GitHub 仓库链接将在本文后续部分提供。
代码详解让我们开始实现吧!
我们的 MCP 服务器将包含三个工具:
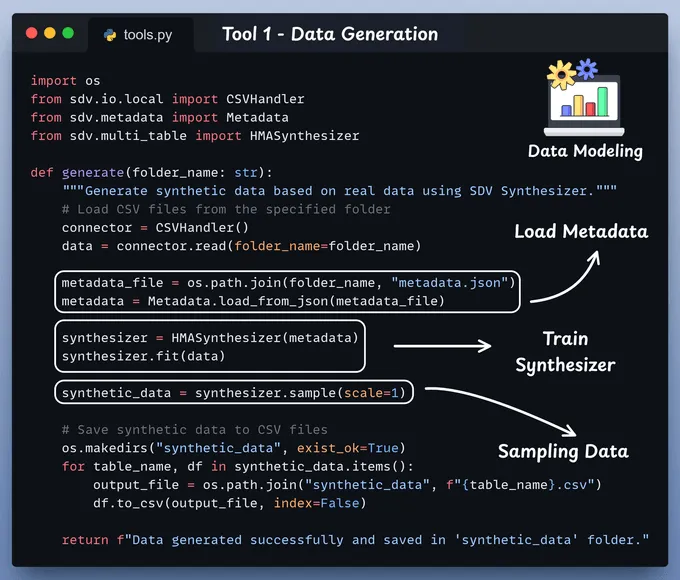
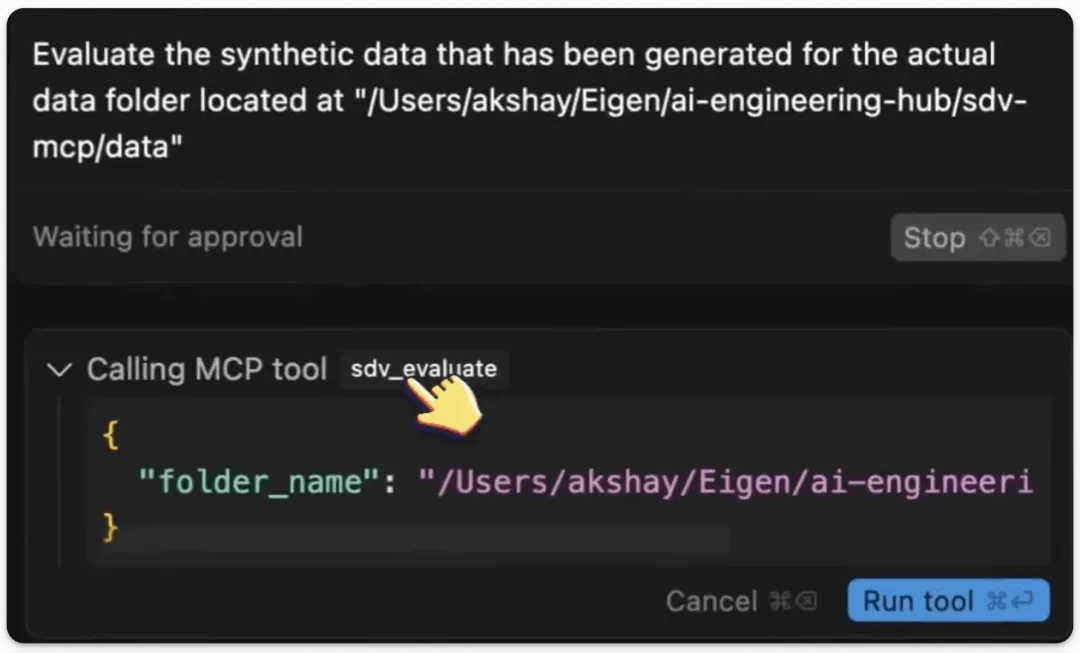
工具 (1) SDV 生成工具此工具利用 SDV 合成器从真实数据中创建合成数据。
SDV 提供多种合成器,每种合成器都利用不同的算法来生成合成数据。
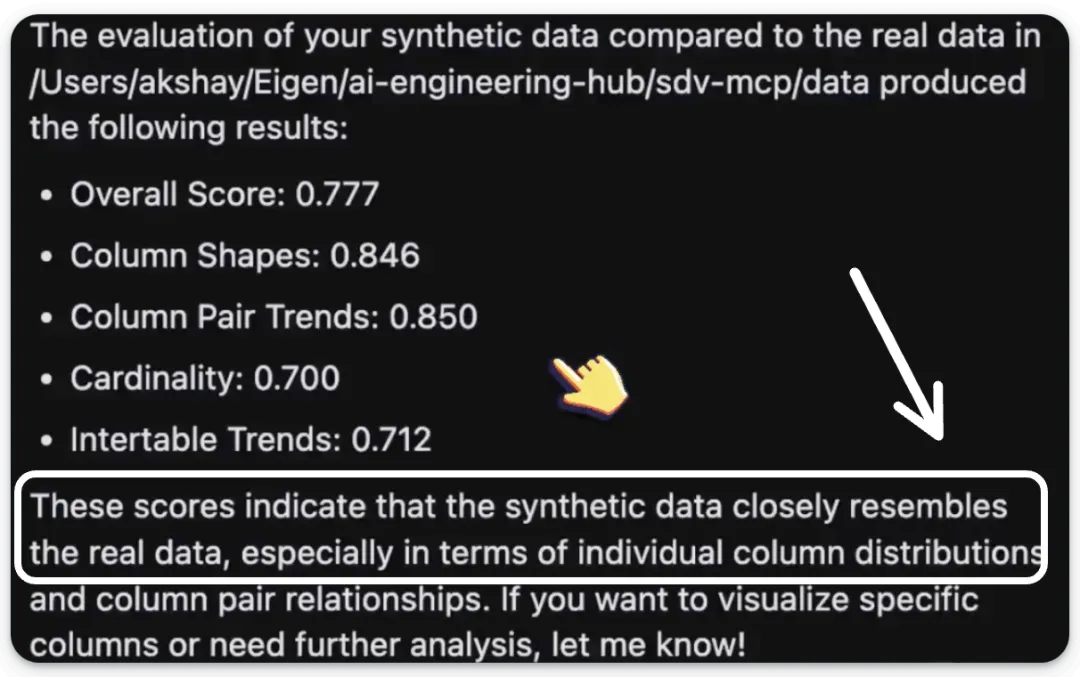
工具 (2) SDV 评估工具此工具用于评估合成数据与真实数据相比的质量。
我们将通过评估统计相似度,以判断合成数据成功捕获了哪些真实数据的模式。
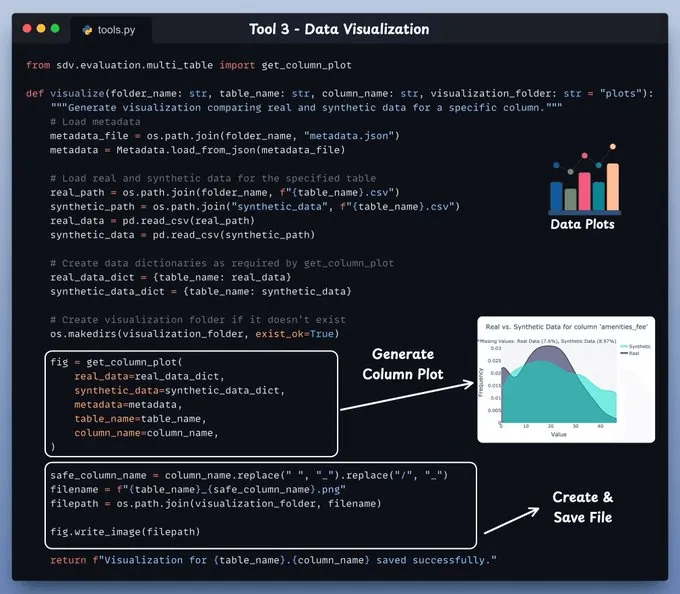
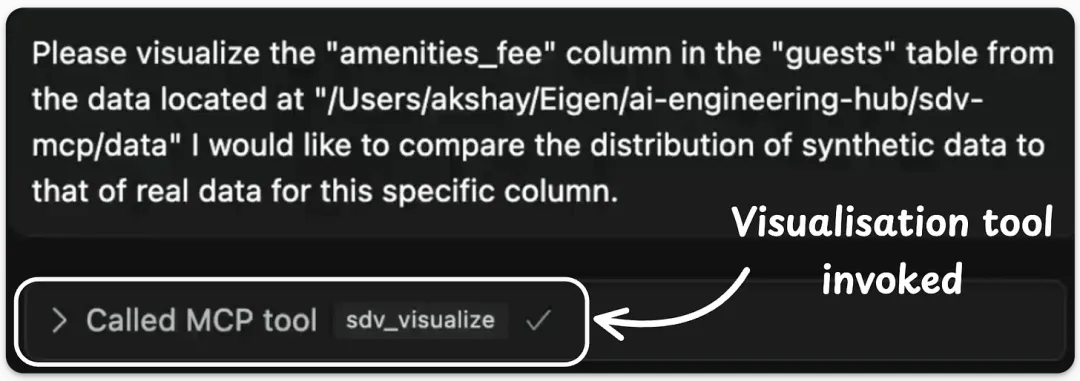
工具 (3) SDV 可视化工具此工具用于生成可视化图表,以比较特定列的真实数据和合成数据。
使用此函数可将真实数据列与其对应的合成数据列进行可视化对比。
如上所述,我们有一个服务器脚本,它通过使用 MCP 库的工具装饰器来装饰函数,从而暴露工具功能。
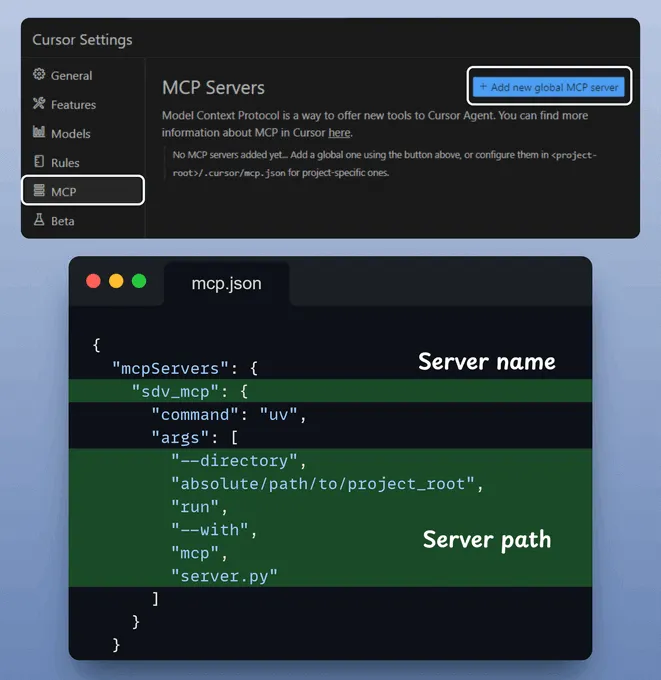
工具和服务器准备就绪后,让我们将其集成到 Cursor IDE 中!
前往:文件 → 首选项 → Cursor 设置 → MCP → 添加新的全局 MCP 服务器。
在 JSON 文件中,添加如下所示内容:
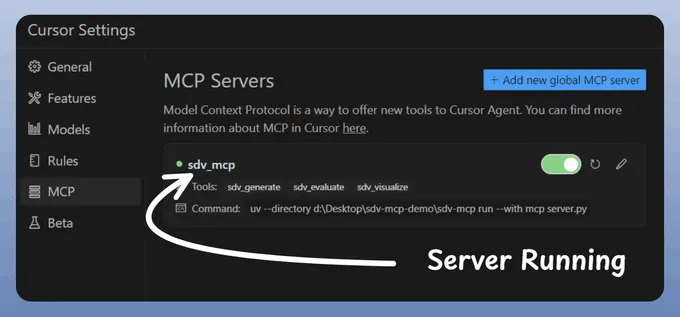
完成!
您的合成数据生成器 MCP 服务器已启动并成功连接到 Cursor!
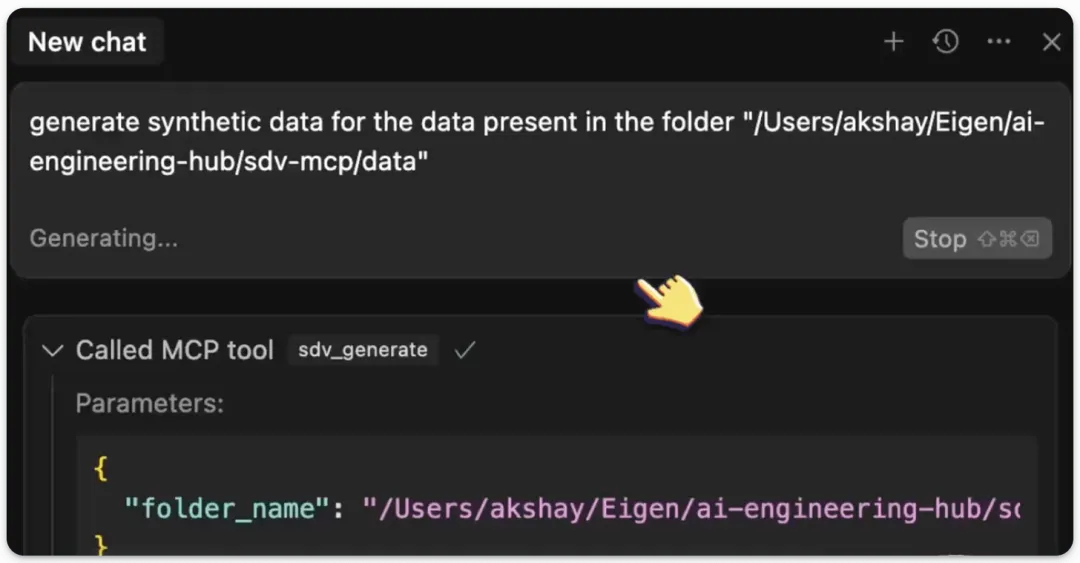
我们在 Cursor 中开启一个新聊天,并让它为可用的种子数据集生成合成数据集,具体如下所示:我们也可以使用之前定义的评估 MCP 工具,通过 SDV 来获取一份量化评估报告。这生成了一份详尽的评估报告,并备注说明生成的数据与原始数据集相似:最后,我们还可以使用可视化工具来生成对比特定列的真实数据和合成数据的可视化图表:太棒了!
我们亲身处理过多个此类合成数据生成用例,并深知其在行业中的实用价值。这也是我们之前提到,这是一个每位数据科学家都会希望拥有的 MCP 服务器的原因。
如果您正面临数据稀缺或类别不平衡的问题,SDV 能让您毫不费力地生成高质量的合成数据。
只需将其指向您的数据集文件夹,它就能在您的 IDE 中,无需动手,为您处理从生成到评估的一切。
在此处查找 SDV GitHub 仓库
→https://docs.sdv.dev/sdv?ref=dailydoseofds.com
在此处查找包含代码的 GitHub 仓库
→https://github.com/patchy631/ai-engineering-hub/tree/main/sdv-mcp?ref=dailydoseofds.com
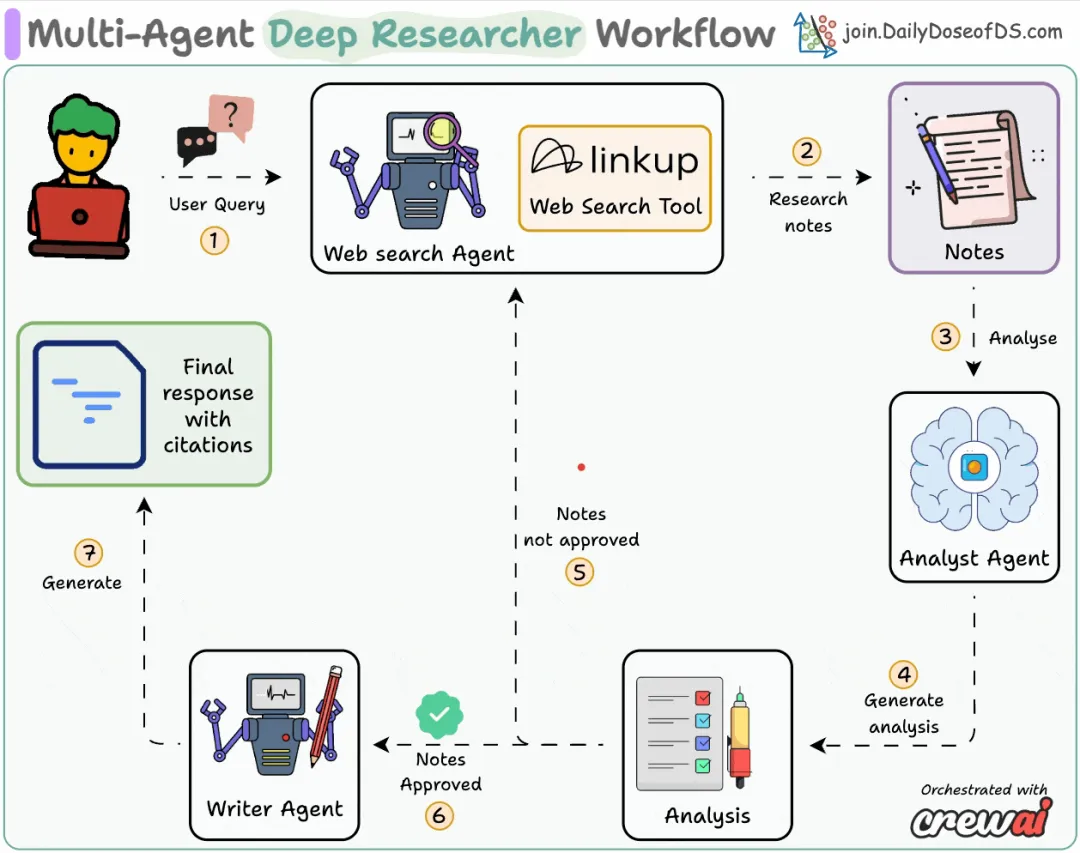
基于 MCP 的深度研究助手多代理协同(100% 本地化)
ChatGPT 具备深度研究功能。它能帮助您获取关于任何主题的详细见解。
在本章节中,我们将向您展示如何构建一个 100% 本地化的替代方案。
技术栈:
系统概述如下:
代码仓库链接将在本文后续部分提供。
实现现在让我们来实现深度研究助手!
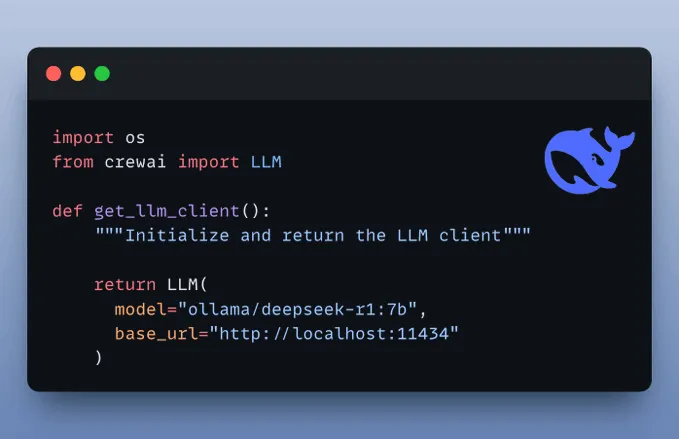
设置大语言模型我们将使用通过 Ollama 在本地运行的 DeepSeek-R1。
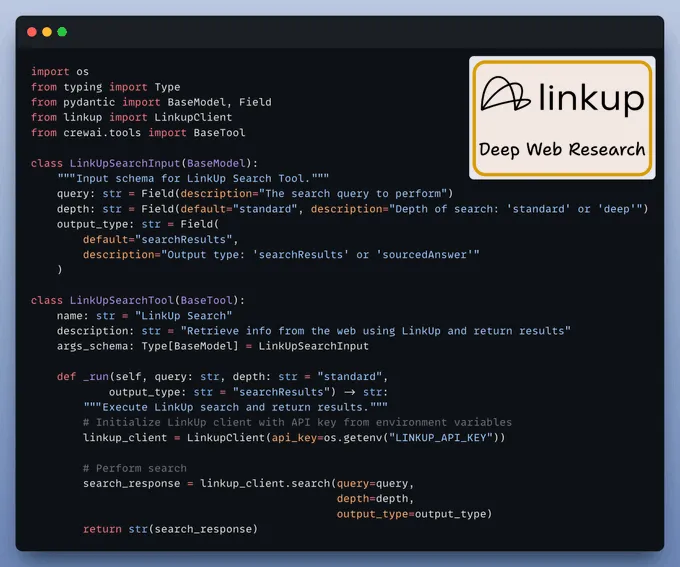
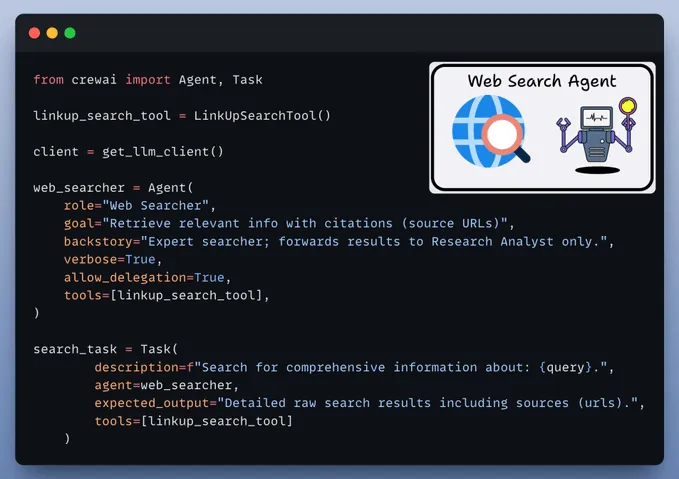
定义网络搜索工具我们将利用 Linkup 强大的搜索能力(可媲美 Perplexity 和 OpenAI)来驱动我们的网络搜索代理。
具体做法是定义一个可供代理使用的自定义工具。
定义网络搜索代理该网络搜索代理根据用户查询,从互联网收集最新信息。
此代理使用我们先前定义的连接工具。
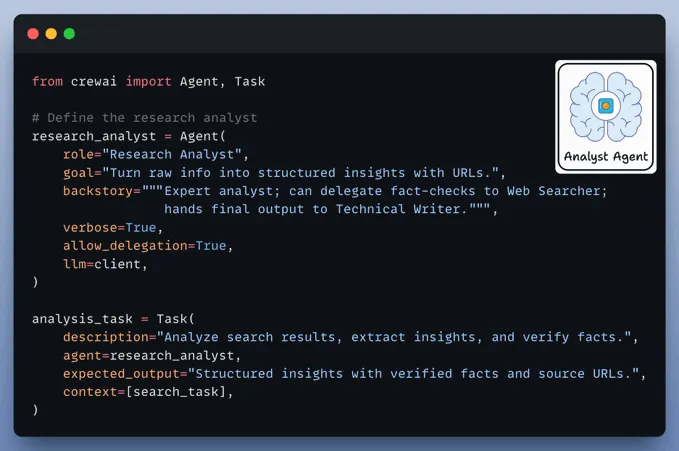
定义研究分析师代理此代理将原始网络搜索结果转化为附有来源URL的结构化见解。
它还可以将任务委派回网络搜索代理,以进行验证和事实核查。
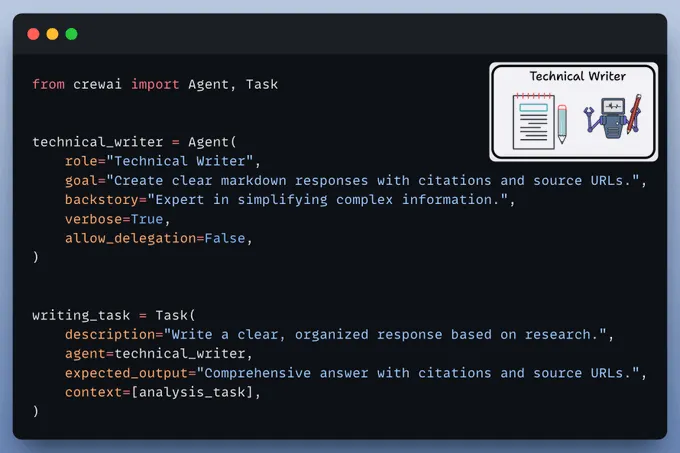
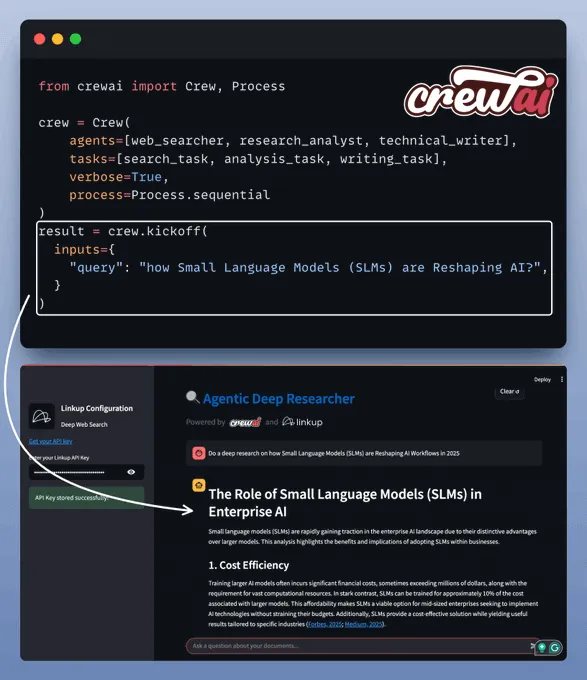
定义技术写作代理它接收来自分析师代理的分析与验证结果,并为最终用户撰写一份带有引用来源的连贯报告。组建团队最后,在我们定义好所有代理和工具后,我们来组建并启动我们的深度研究团队。创建 MCP 服务器现在,我们将把深度研究团队封装在一个 MCP 工具中。仅需几行代码,我们的 MCP 服务器即可准备就绪。
以下是如何将其与 Cursor 连接的方法:
将 MCP 服务器集成到 Cursor前往:文件 → 首选项 → Cursor 设置 → MCP → 添加新的全局 MCP 服务器。
在 JSON 文件中,添加以下内容:
完成!您的深度研究 MCP 服务器已启动并连接到 Cursor(如果您愿意,也可以将其连接到 Claude Desktop)。为了独立使用深度研究功能,我们还创建了一个美观的 Streamlit 用户界面,您可以在此查看关于“小型语言模型”的深度研究报告:视频地址:https://www.dailydoseofds.com/content/media/2025/06/nentx1nj1I7tLq4J.mp4这就是您基于 MCP、完全本地化的深度研究助手!
代码请查看此 GitHub 仓库 →https://www.dailydoseofds.com/content/media/2025/06/nentx1nj1I7tLq4J.mp4
构建基于 MCP 的视频检索增强生成系统支持与视频对话并获取精确时间戳
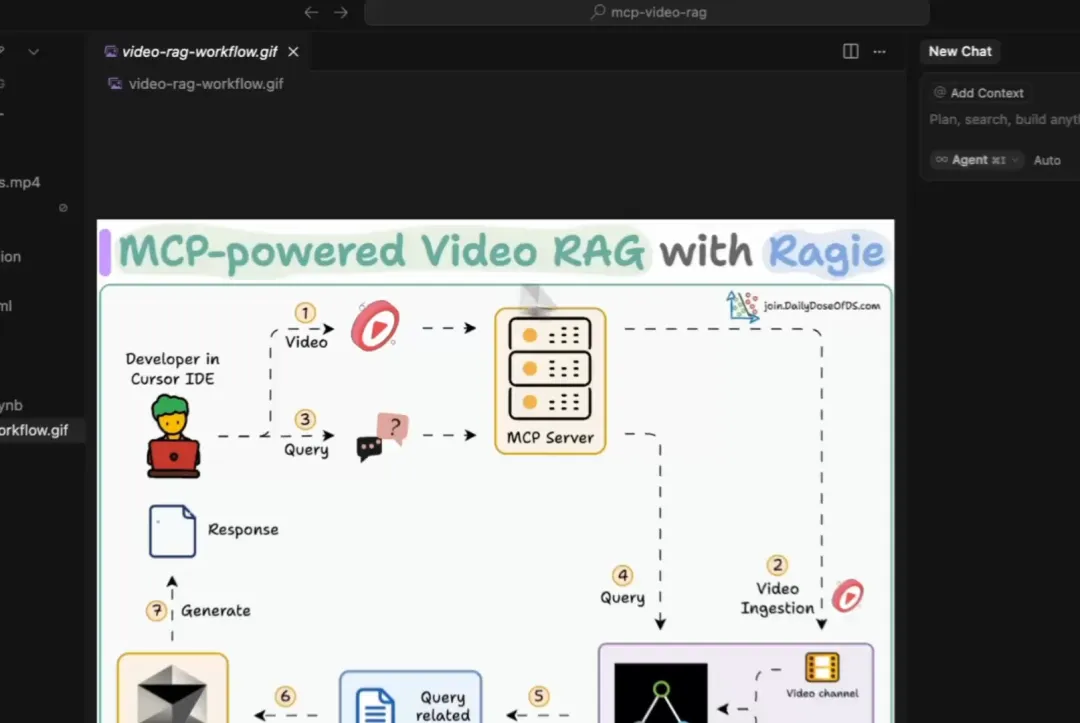
在本章中,我们将构建一个由 MCP 驱动的视频 RAG 系统,该系统能够摄取视频并允许您与其进行对话。
它还能定位到事件发生的精确视频片段。
我们的技术栈如下:
Ragie:用于视频摄取与检索。
Cursor:作为 MCP 宿主。
工作流程如下:
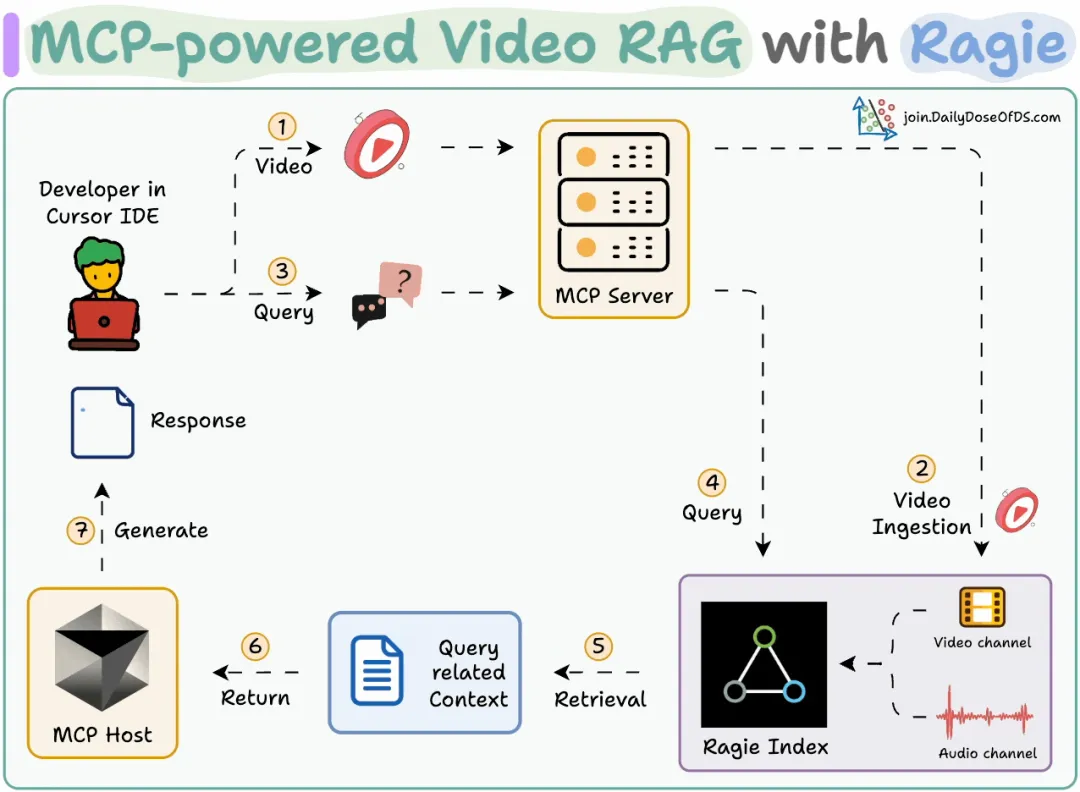
用户指定视频文件并提出查询。摄取工具将视频在 Ragie 中建立索引。查询工具从 Ragie 索引中检索信息,并提供引用来源。展示视频工具返回能解答查询的视频片段。
以下是 MCP 驱动的视频 RAG 系统实际运行效果:
实现细节让我们开始实现(代码链接将在本文后续部分提供)!
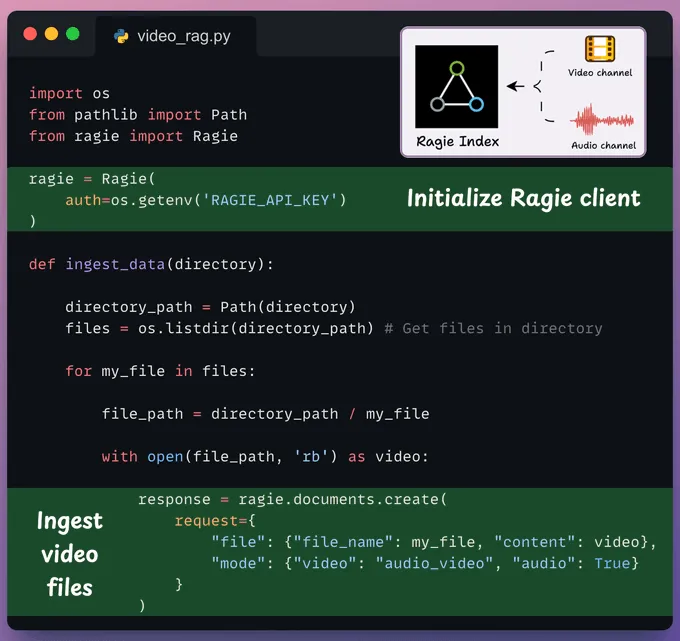
摄取数据我们实现一个方法,将视频文件摄取到 Ragie 索引中。
我们还指定了音频-视频模式,以便在摄取过程中同时加载音频和视频通道。
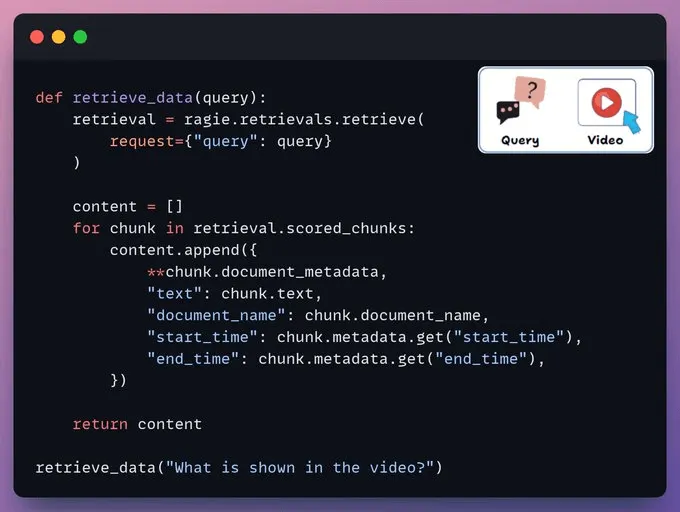
检索数据我们根据用户查询从视频中检索相关片段。
每个片段都包含开始时间、结束时间以及其他一些与视频段落对应的详细信息。
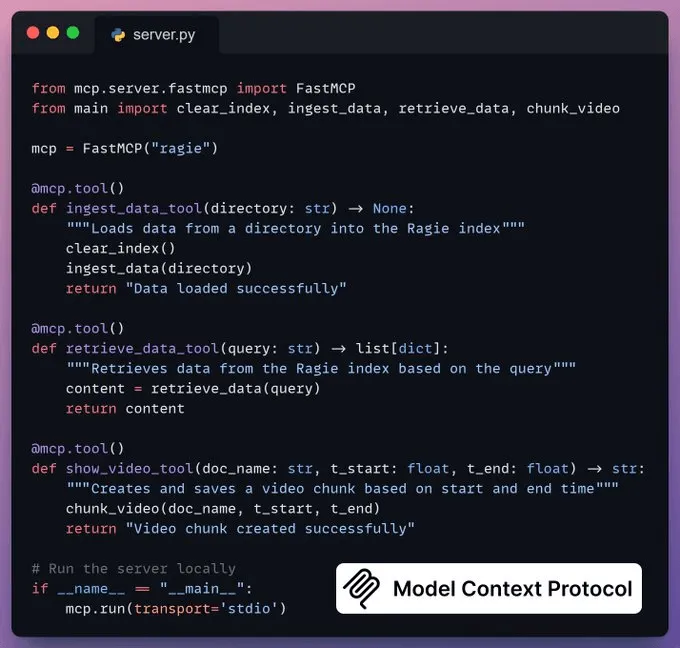
创建 MCP 服务器我们将 RAG 流程集成到一个包含 3 个工具的 MCP 服务器中:ingest_data_tool:将数据摄取到 Ragie 索引中。
retrieve_data_tool:根据用户查询检索数据。
show_video_tool:从原始视频中提取视频片段。
将 MCP 服务器与 Cursor 集成要将 MCP 服务器与 Cursor 集成,请转至设置 → MCP → 添加新的全局 MCP 服务器。
在 JSON 文件中,添加如下所示的内容:
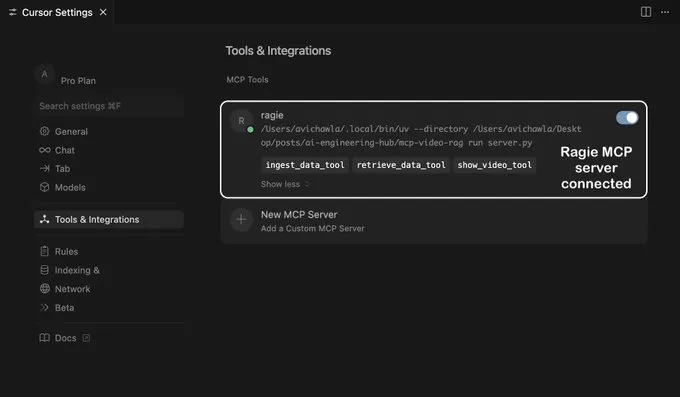
完成!您的本地 Ragie MCP 服务器已成功启动并连接至 Cursor!接下来,我们通过 Cursor 与 MCP 服务器进行交互。
根据查询内容,它可以:
获取现有视频的详细信息。
检索特定事件发生的视频片段。
通过将音频和视频上下文集成到检索增强生成中,开发者能够构建强大的多媒体和多模态生成式 AI 应用。
在此 GitHub 仓库中查找代码 →https://github.com/patchy631/ai-engineering-hub/tree/main/mcp-video-rag?ref=dailydoseofds.com
构建基于 MCP 的视频检索增强生成系统支持与视频对话并获取精确时间戳在本章中,我们将构建一个由 MCP 驱动的视频 RAG 系统,该系统能够摄取视频并允许您与其进行对话。
它还能定位到事件发生的精确视频片段。
我们的技术栈如下:
Ragie:用于视频摄取与检索。
Cursor:作为 MCP 宿主。
工作流程如下:
用户指定视频文件并提出查询。摄取工具将视频在 Ragie 中建立索引。查询工具从 Ragie 索引中检索信息,并提供引用来源。展示视频工具返回能解答查询的视频片段。
以下是 MCP 驱动的视频 RAG 系统实际运行效果:
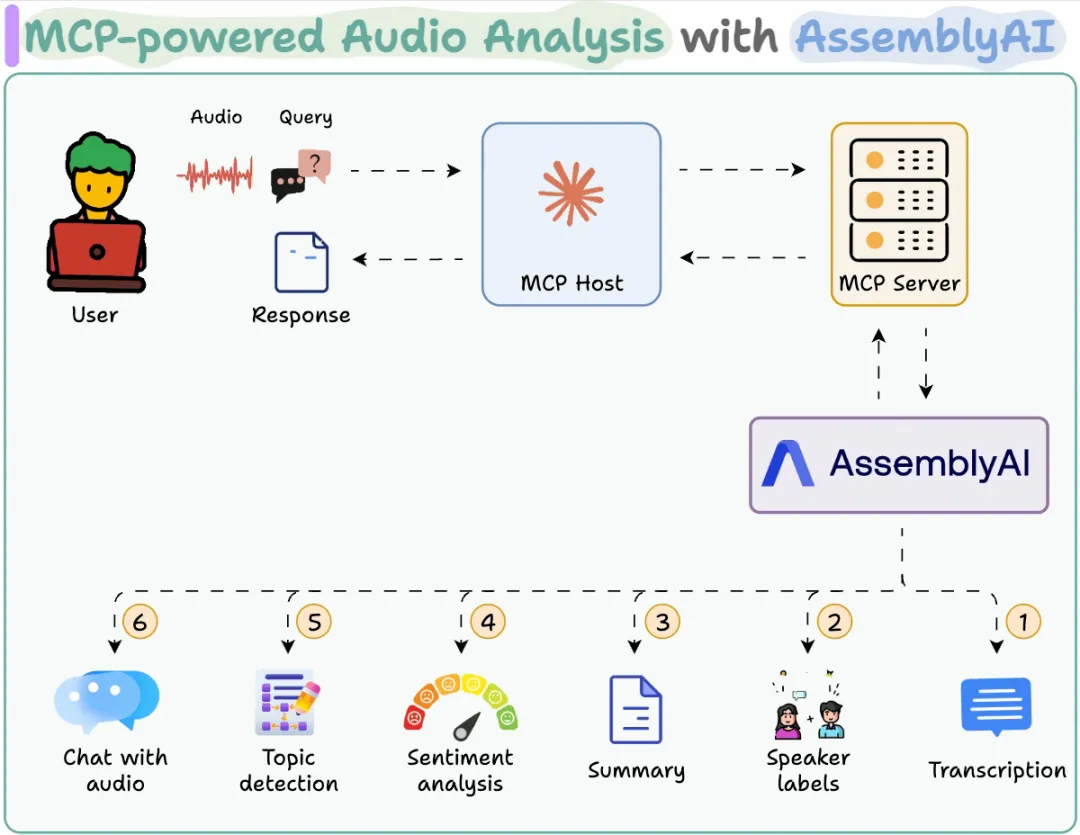
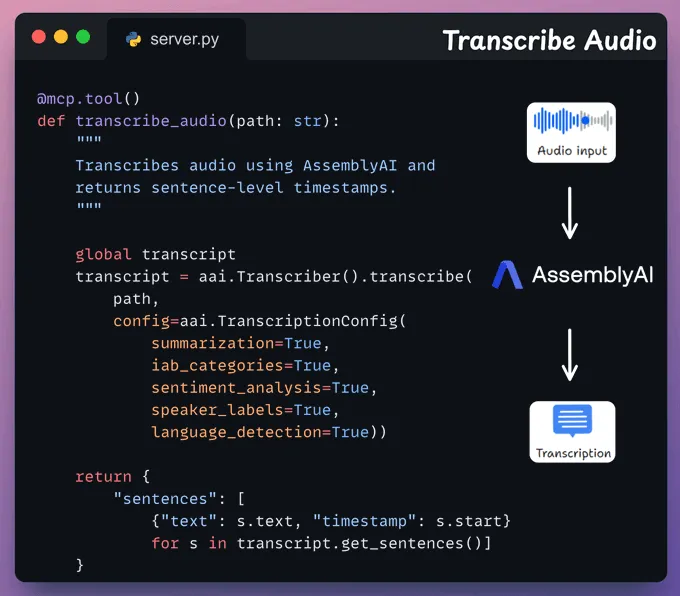
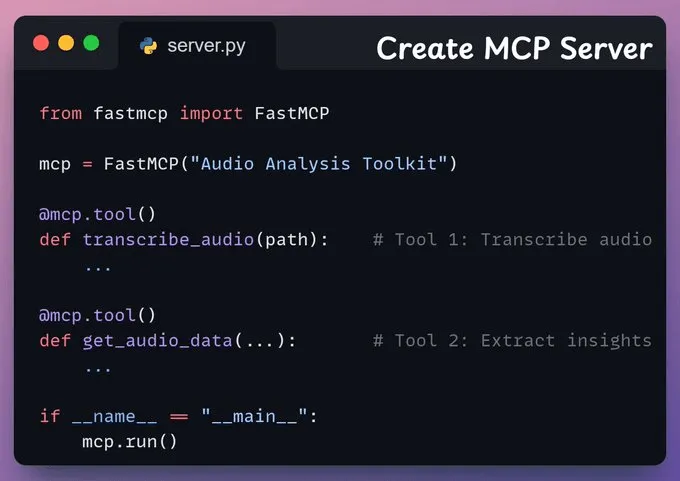
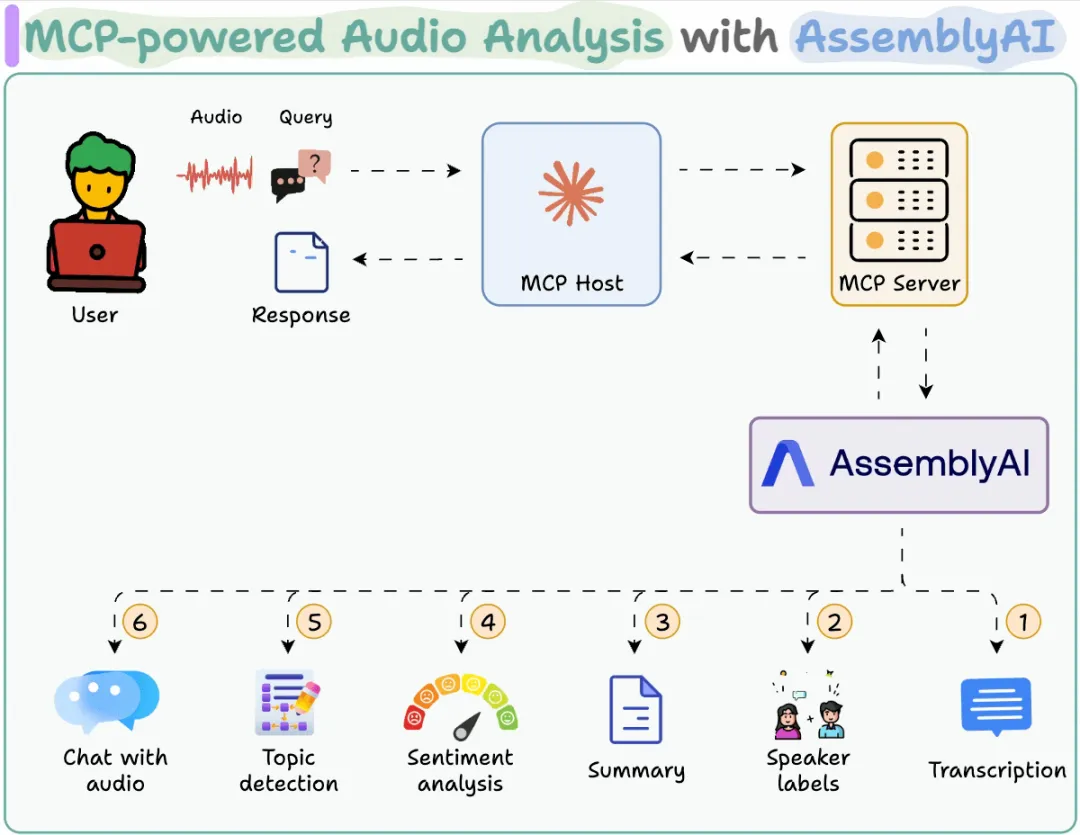
转录 MCP 工具此工具接收用户的音频输入,并利用 AssemblyAI 进行转录。
我们同时会保存完整的转录文本,以便在下一个工具中使用。
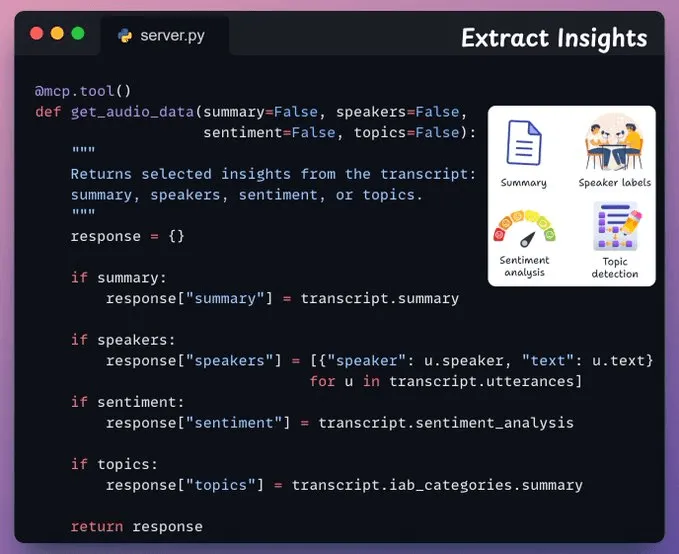
音频分析工具接下来,我们提供一个工具,用于从转录文本中返回特定的分析洞察,例如说话人标签、情感分析、主题识别和内容摘要。
基于用户的输入查询,相应的分析标志将在代理通过 MCP 准备工具调用时自动设置为 True:
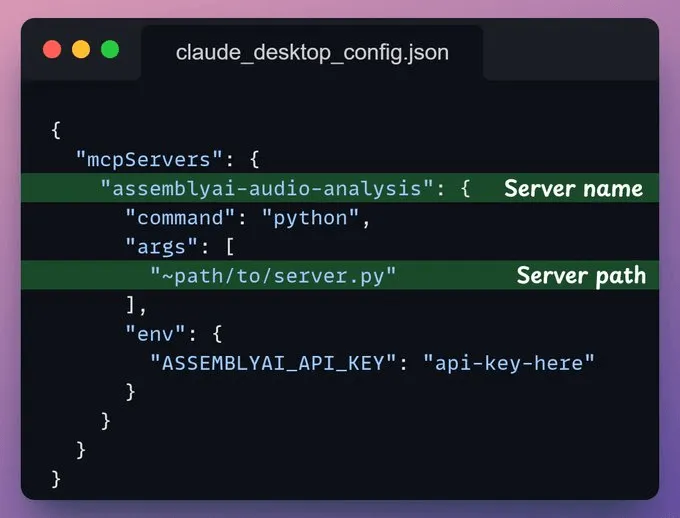
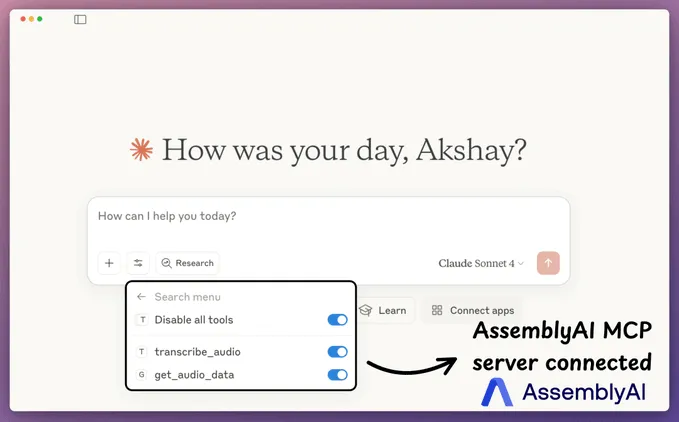
创建 MCP 服务器现在,我们将建立一个 MCP 服务器来使用我们上面创建的工具。将 MCP 服务器集成到 Claude Desktop前往文件 → 设置 → 开发者 → 编辑配置,并添加以下代码。服务器配置完成后,Claude Desktop 将在工具菜单中显示我们之前构建的两个工具:现在您可以与之交互了:
视频地址:https://www.dailydoseofds.com/content/media/2025/06/assemblyai-audio-analysis.mp4此外,我们还为音频分析应用创建了一个Streamlit 用户界面。视频地址:https://www.dailydoseofds.com/content/media/2025/06/assemblyai-audio-analysis-toolkit-streamlit.mp4
您可上传音频,通过 AssemblyAI 的 LeMUR 进行深入分析和对话互动。
这便是我们基于 MCP 的音频分析工具包。
工作流程再次呈现,供您参考:
用户提供的音频通过 MCP 服务器发送至 AssemblyAI。AssemblyAI 处理音频,MCP 宿主返回所需洞察。(代码可在此仓库中查找 →)https://github.com/patchy631/ai-engineering-hub/tree/main/audio-analysis-toolkit?ref=dailydoseofds.com
关于和通AI
和通AI专注于AI前沿技术教育和培训,涵盖AI概念启蒙、素养提升、场景应用、技能实训、战略规划全系列高质量AI课程培训体系,服务千行百业智能化转型升级。是专业的AI教育内容提供商和AI教育软件服务商,秉持以AI技术赋能AI教育理念,研发了多款基于大模型的AI教育软件,如AI教学编程、AI教学英语等,为AI教育、Al+教育提供⼀搅子解决方案。
以下是和通AI-大模型技术交流群,欢迎大家进入群聊讨论交流技术相关的问题。