“ 在真实软件工程环境中,漏洞检测模型往往面临一个核心挑战:训练项目 ≠ 测试项目。现有深度学习漏洞检测方法大多依赖于大量同分布标注数据,一旦模型被应用到全新项目或未知代码库,检测性能便会急剧下降。
为解决这个“跨项目泛化”难题,研究者提出了一种 Zero-Shot框架,在不依赖目标项目任何标注数据的前提下,实现对未知项目代码漏洞的有效检测 。”- 📄 论文标题:A Zero-Shot Framework for Cross-Project Vulnerability Detection in Source Code
- 📅 发表时间:Empirical Software Engineering, 2025
💡开源代码:
https://github.com/Radowan98/ZSVulD
方法介绍
该框架的核心目标是:学习“与项目无关”的漏洞语义表示,从而实现跨项目零样本迁移。
整体方法可以概括为三个关键阶段:
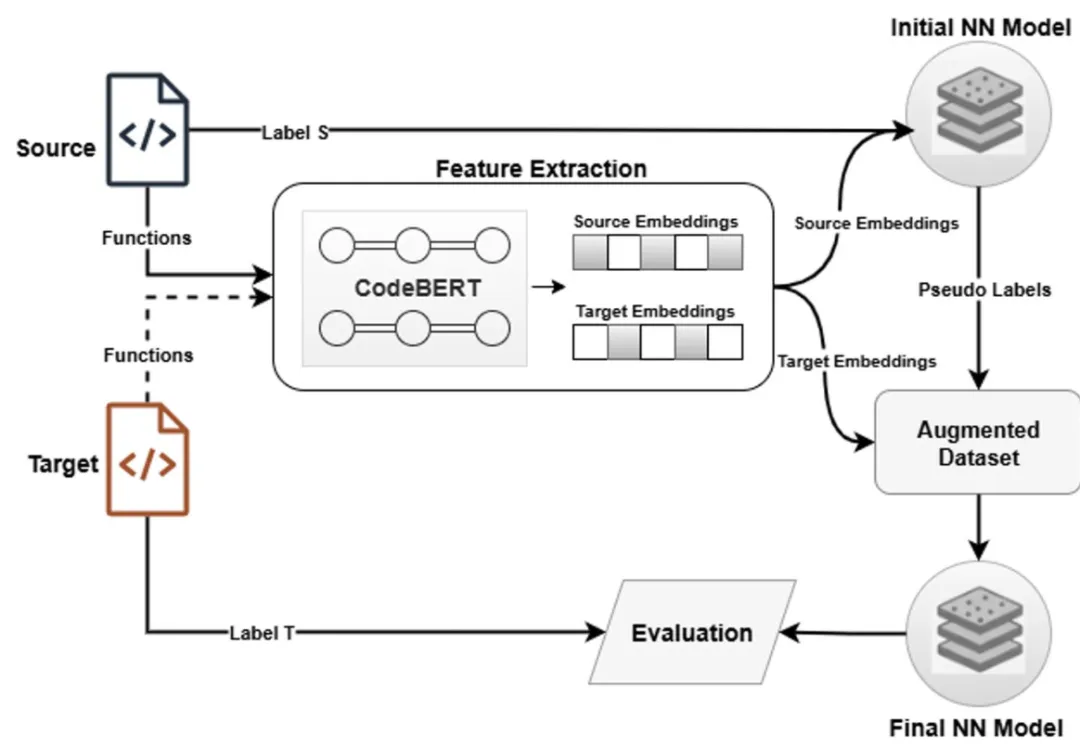
① 项目无关特征学习② 漏洞语义对齐③ 零样本推理在目标项目无任何标注样本的情况下直接进行漏洞预测。图 1. ZSVulD整体流程
小结:该方法的核心不在于“学更多数据”,而在于“学会如何泛化”。
关键机制
- 首批系统性引入 Zero-Shot 学习到代码漏洞检测任务
- 摆脱目标项目标注依赖,显著降低真实部署成本
- 显式缓解跨项目分布偏移问题
小结:框架从“项目依赖建模”转向“漏洞本质建模”,这是其成功的关键。实验在两个主流漏洞数据集Devign和Reveal上验证了提出方法的有效性,主要实验结果如下。
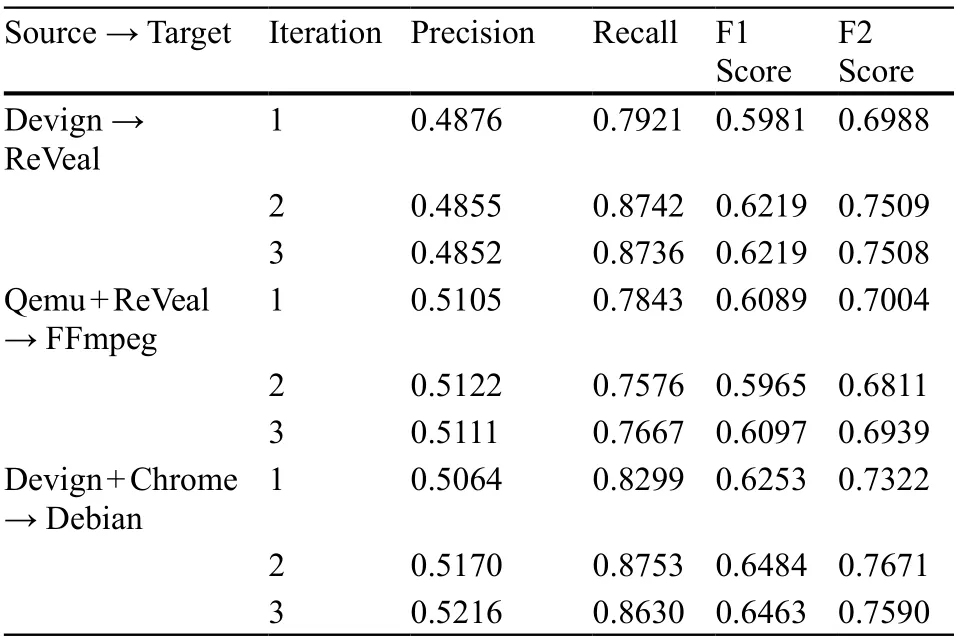
(1)实验评估了迭代伪标注在跨项目漏洞检测中的影响,结果如表1所示。表1. 迭代伪标注的效果
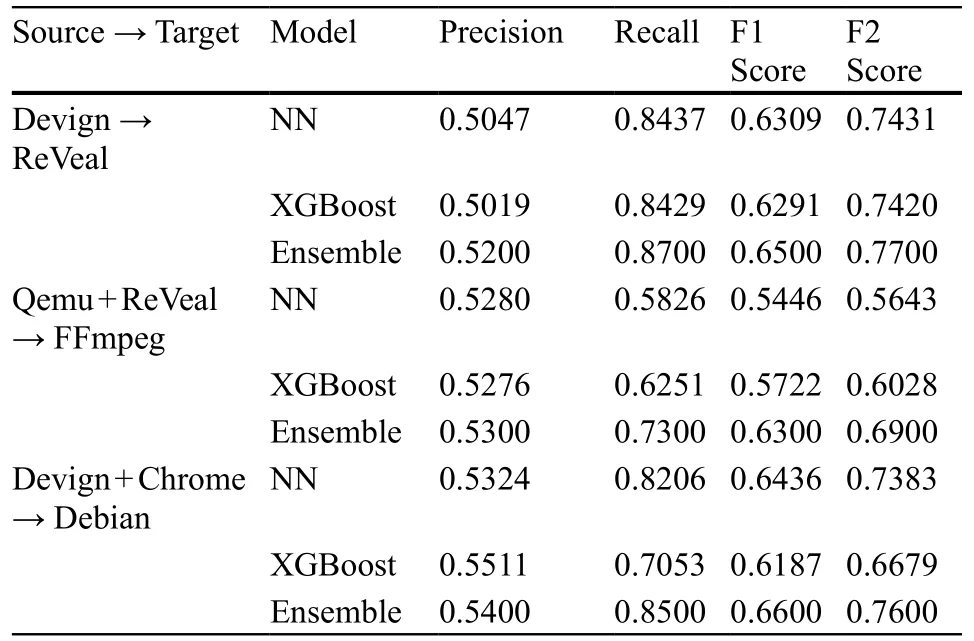
(2)实验评估了集成机制在零样本设置下对预测鲁棒性的影响,比较了三种建模策略,每种策略都是在无法访问标记的目标数据的情况下进行训练的。结果见表2。
表2. 集成学习对未见数据集的影响
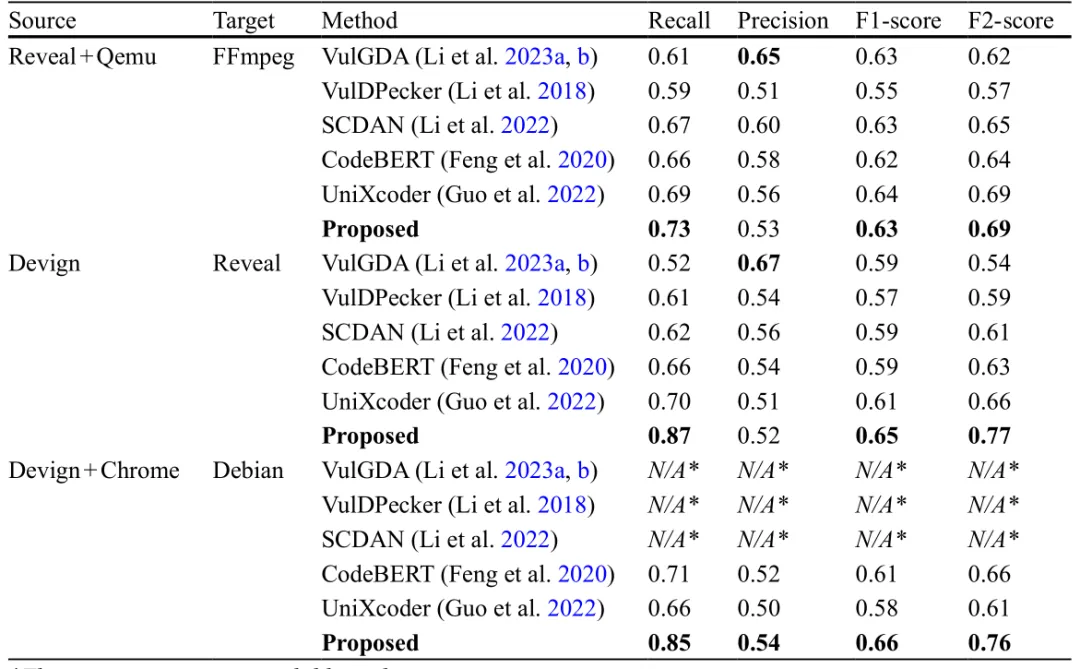
(3)实验评估了ZSVulD在检测未见项目漏洞方面的有效性,将其与几种最先进的跨项目漏洞检测方法进行了对比分析。结果见表3。
表3. 所提框架与最先进方法的性能对比
小结:ZSVulD使用冻结的CodeBERT嵌入来提取源代码的领域无关表示,同时捕获语法和语义信息。这些嵌入通过一种迭代伪标注机制进行处理,在多次迭代中为目标样本分配并细化标签。实证评估表明,ZSVulD在多个跨项目设置中实现了高召回率。
📌 总结
这项工作从根本上重新审视了漏洞检测模型的应用场景:模型不应只在“熟悉的项目”中表现良好,而应能面对真实世界的未知代码。
通过 Zero-Shot 学习思想,该框架为未来的代码安全系统提供了一种更具工程价值的发展方向:无需频繁重新标注数据、适配快速演进的软件生态。
📣 欢迎留言讨论
📌 点赞 + 收藏 + 分享,你的支持,是我们持续解析高水平软件安全论文的最大动力!