在Linux工作中,“日志撑满磁盘”是高频且棘手的故障场景。一旦发生,不仅可能导致应用读写失败、服务异常中断,还会引发CPU利用率飙升、磁盘I/O拥堵等连锁性能问题,甚至牵连同一服务器上的其他业务应用。本文将深入剖析这一故障的核心诱因,拆解完整的排查思路,并给出可直接落地的解决方案,助力运维同学快速止损、规避隐患。
一、日志的价值:运维排查的“核心抓手”
日志,是我们洞察应用程序内部运行状态最常用、最有效的工具。无论是Linux操作系统本身(如系统日志、内核日志,常见路径有/var/log/messages、/var/log/syslog、/var/log/kern.log等),还是部署其上的各类业务应用(Web服务、数据库、中间件等,常见应用日志路径如/var/log/nginx/、/var/lib/mysql/、/var/log/tomcat/等),都会持续记录运行过程中的关键轨迹——比如程序启动状态、接口调用详情、错误触发堆栈等。这些日志是事后追溯问题、定位故障根源的核心依据,堪称运维排查的“眼睛”。
为平衡“故障可追溯”与“系统资源消耗”,日志通常按级别划分并按需开启。常见日志级别从低到高依次为:调试(DEBUG)、信息(INFO)、警告(WARN)、错误(ERROR)、致命(FATAL),不同环境的日志级别配置有明确规范,核心是“按需输出,避免冗余”:
开发环境:通常开启DEBUG级日志,目的是完整捕获程序运行的每一个细节,帮助开发人员调试代码、排查潜在逻辑问题;
线上环境:核心原则是“精简有效”,一般仅记录WARN(警告)、ERROR(错误)及以上级别日志。这样既能确保关键异常信息不遗漏,又能最大限度降低日志写入对CPU、磁盘I/O等系统资源的消耗。
二、核心诱因:线上环境“调试日志忘回退”的致命疏忽
既然线上环境有明确的日志级别规范,为何还会出现“日志狂打”导致磁盘撑爆的情况?运维实践中,最常见的根源是“临时调试操作后的疏忽”——运维或开发人员排查线上疑难问题时,临时调整日志级别后未及时回退。
在实际=场景中,当线上应用出现疑难故障时,仅靠WARN和ERROR级日志往往无法定位根源。此时,运维人员通常会临时将线上应用日志级别下调至DEBUG级,以获取更详细的运行细节(如参数传递、内部函数调用等)。但问题往往出在“故障排查结束后”:因忙碌或疏忽,忘记将日志级别调回原本的WARN级,导致DEBUG级日志持续输出。
这一疏忽会引发严重的连锁反应:DEBUG级日志以海量级持续写入磁盘,不仅会快速耗尽磁盘空间,还会占用大量CPU资源(日志格式化、写入逻辑处理)和磁盘I/O(高频读写操作)。这些性能损耗会直接导致应用响应延迟、吞吐量下降,甚至影响同一服务器上其他应用的正常运行,最终演变为“牵一发而动全身”的运维事故。
三、实战指南:定位与解决“狂打日志”问题
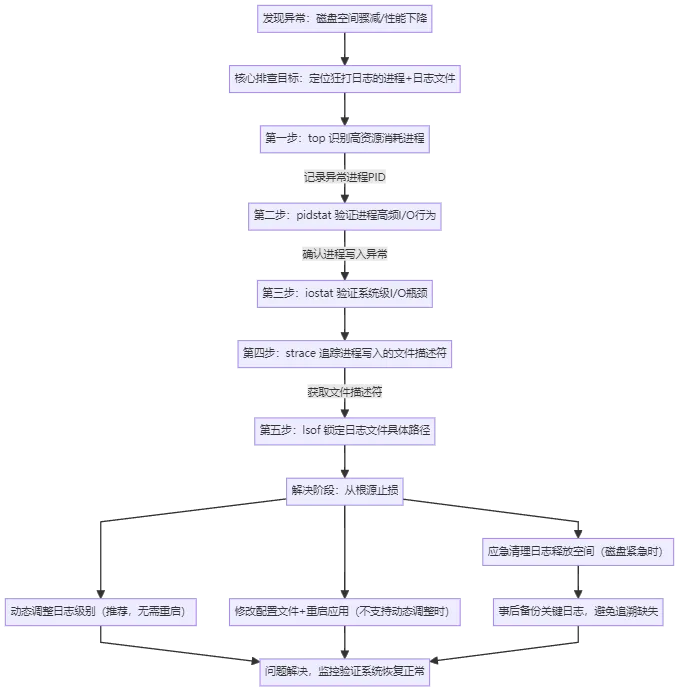
当发现服务器磁盘空间快速缩减、系统性能异常(如响应变慢、负载飙升)时,若怀疑是“日志狂打”导致,可按“定位异常进程→锁定日志文件→调整日志级别”的核心思路,快速排查并解决隐患。以下是具体实操步骤:
3.1 关键工具:5大命令精准定位问题
排查过程中,top、pidstat、iostat、strace、lsof这5款工具是核心帮手,各自承担不同的定位职责。搭配使用可快速锁定“日志狂打”的根源,避免盲目排查:
1. top:快速识别高资源消耗进程
top命令用于实时监控系统进程的资源占用情况,是快速筛选异常进程的“第一站”。当出现日志狂打时,对应的进程通常有明显特征:CPU占用率偏高(日志格式化、写入需消耗CPU算力)、IO等待率(%wa)飙升(高频磁盘写入导致I/O阻塞)。
使用方式:终端直接输入top,重点查看进程列表中%CPU、%wa列的异常进程(优先关注业务应用进程,如Java应用的java进程、Web服务的nginx进程等),记录异常进程的PID(进程ID),为后续精准排查做准备。
2. pidstat:聚焦进程级资源详情
通过top锁定异常进程后,需进一步验证该进程是否存在高频磁盘写入行为——pidstat可精准监控指定进程的资源占用详情,尤其适合排查进程级I/O问题。它能清晰展示进程的CPU、内存、磁盘I/O等核心指标,帮助确认是否是该进程在“狂打日志”。
常用命令:pidstat -d 1 -p [异常进程PID](参数说明:-d 表示仅查看I/O统计信息,1 表示每秒刷新一次)。若输出中“kB_wrtn/s”(每秒写入磁盘的字节数)持续处于高位(如每秒数MB甚至数十MB),基本可确认该进程存在“狂打日志”的行为。
3. iostat:验证系统级磁盘I/O压力
iostat用于监控系统整体的磁盘I/O状态,可验证“日志狂打”是否导致全局磁盘I/O拥堵。通过它能判断磁盘是否已达性能瓶颈,进而确认故障影响范围。
常用命令:iostat -x 1(参数说明:-x 表示显示详细I/O统计信息,1 表示每秒刷新一次)。若输出中“%util”(磁盘繁忙程度)接近100%,说明磁盘I/O已达瓶颈,进一步佐证“日志狂打”是导致系统性能异常的核心原因。
4. strace:追踪进程的文件写入行为
确认异常进程后,需精准定位它正在写入的日志文件——strace是进程系统调用追踪工具,可实时捕获进程的write、open等系统调用,直接锁定日志文件的相关信息。
常用命令:strace -p [异常进程PID] -e write(参数说明:-e write 表示仅追踪write系统调用,过滤无关信息)。输出结果中,会出现类似“write(3, "DEBUG: xxx"...)”的内容:其中“3”是文件描述符(进程操作文件的标识),后续可结合lsof工具,通过该文件描述符找到具体的日志文件路径。
5. lsof:锁定日志文件的具体路径
lsof(list open files)用于列出进程打开的所有文件,结合strace得到的文件描述符,可快速定位日志文件的具体路径——这是“锁定故障源头”的最后一步。
常用命令:lsof -p [异常进程PID] | grep [文件描述符](示例:lsof -p 1234 | grep 3)。输出结果中,“NAME”列对应的即为日志文件的完整路径。比如可能定位到系统日志路径/var/log/messages,或应用日志路径/var/log/nginx/access.log等。至此,我们已精准锁定“狂打日志”的进程和日志文件,可进入解决阶段。
3.2 解决核心:调整日志级别,从根源止损
找到“日志狂打”的进程和日志文件后,核心解决思路是“将日志级别调回线上规范的WARN或ERROR级”,从根源上停止海量日志输出。具体操作方式因应用架构而异,以下是3种常见场景的实操方案:
动态调整(推荐):多数Java应用(如Spring Boot应用)支持通过监控接口动态调整日志级别,无需重启服务,不影响业务运行。例如:Spring Boot应用可通过/actuator/loggers接口,以HTTP请求方式修改指定包的日志级别(如POST请求将com.xxx.service包日志级别设为WARN);
配置文件修改+重启:若应用不支持动态调整,需修改日志配置文件(如logback.xml、log4j2.xml)中的日志级别(将DEBUG改为WARN/ERROR),保存后重启应用使配置生效。注意:重启前需评估业务影响,尽量选择低峰期操作;
应急清理(磁盘紧急扩容):若磁盘已接近满额(如使用率>95%),需先应急释放空间,避免服务中断。可通过echo "" > 日志文件路径(如echo "" > /var/log/messages、echo "" > /var/log/nginx/error.log,清空当前日志文件)或rm -f 历史日志文件(如rm -f /var/log/tomcat/catalina.out.202*,删除过期日志)快速释放空间。关键提醒:清空/删除日志前,务必备份关键日志(如故障排查相关的日志片段),避免丢失故障追溯依据。
3.3 测试用例:模拟日志狂打场景,验证排查流程
为帮助大家更好地掌握上述排查流程,我们通过“模拟线上日志狂打场景”的测试用例,完整复现从问题出现到解决的全流程。该测试用例基于CentOS 7系统,无需影响真实业务,可直接在测试服务器上操作。
一、测试环境准备
服务器:CentOS 7(2核4G,磁盘50G);
工具:提前安装sysstat(含pidstat、iostat)、strace、lsof(CentOS可通过yum install -y sysstat strace lsof一键安装);
模拟程序:通过Python脚本循环输出DEBUG日志,模拟应用“狂打日志”行为(替代原Shell脚本,更贴近真实应用开发场景)。
二、测试步骤(全流程复现)
步骤1:模拟日志狂打场景
- 新建Python脚本
mock_debug_log.py,脚本内容如下(循环输出DEBUG日志到指定文件,模拟真实应用日志输出逻辑):
#!/usr/bin/env python3# -*- coding: utf-8 -*-# 模拟应用DEBUG日志狂打,输出到/var/log/mock_app/debug.logimport osimport timefrom datetime import datetime# 日志目录和日志文件路径LOG_DIR = "/var/log/mock_app"LOG_FILE = os.path.join(LOG_DIR, "debug.log")definit_log_dir():"""创建日志目录(若不存在)"""ifnot os.path.exists(LOG_DIR): os.makedirs(LOG_DIR) print(f"日志目录 {LOG_DIR} 创建成功")defwrite_debug_log():"""循环写入DEBUG级日志,每10毫秒输出1条(模拟高频日志)""" init_log_dir()whileTrue:# 构造日志内容:包含时间戳、日志级别、模拟业务细节 log_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S") log_content = f"{log_time} [DEBUG] 模拟应用运行细节:参数1=xxx,参数2=yyy,接口调用成功,响应时间=12ms\n"# 追加写入日志文件with open(LOG_FILE, "a", encoding="utf-8") as f: f.write(log_content)# 休眠10毫秒,控制日志输出频率 time.sleep(0.01)if __name__ == "__main__":try: write_debug_log()except KeyboardInterrupt: print("日志模拟程序被手动终止")except Exception as e: print(f"程序运行异常:{str(e)}")
- 赋予脚本执行权限(可选,Python可直接通过解释器运行)并后台运行:
# 方式1:直接通过Python解释器后台运行(推荐,无需额外赋权)nohup python3 mock_debug_log.py &# 方式2:赋权后直接运行(需先执行以下命令)# chmod +x mock_debug_log.py# nohup ./mock_debug_log.py
- 验证日志狂打效果:通过
tail -f /var/log/mock_app/debug.log可看到日志持续输出,通过du -sh /var/log/mock_app/debug.log可观察文件大小快速增长(如1分钟内可达几十MB)。此时,服务器已模拟出“日志狂打”场景。
步骤2:用5大工具排查定位问题
执行top,在进程列表中可看到python3 mock_debug_log.py对应的进程,其%CPU占用率较高(因循环输出日志消耗算力),%wa(IO等待)也会明显上升。记录该进程的PID(假设为15678)。
执行pidstat -d 1 -p 15678,输出中“kB_wrtn/s”(每秒写入字节数)会持续处于高位(如每秒几MB),确认该进程存在高频磁盘写入行为。
执行iostat -x 1,可看到“%util”(磁盘繁忙程度)接近100%,说明磁盘I/O已达瓶颈,验证了日志狂打对系统的影响。
执行strace -p 15678 -e write,输出中会出现类似“write(3, "2026-01-12 15:30:00 [DEBUG] 模拟应用运行细节:xxx..."...)”的内容,记录文件描述符“3”。
执行lsof -p 15678 | grep 3,输出中“NAME”列会显示/var/log/mock_app/debug.log,精准锁定狂打日志的文件路径。
步骤3:解决问题(停止日志狂打)
应急停止日志输出:因是模拟场景,可直接终止进程:执行kill -9 15678,此时日志停止写入。
清理日志释放空间:执行rm -f /var/log/mock_app/debug.log(模拟场景可直接删除,真实环境需先备份),通过df -h可验证磁盘空间已释放。
模拟线上“调整日志级别”:若该脚本是真实应用,可通过修改配置文件关闭DEBUG日志(如将脚本中的“[DEBUG]”改为仅输出“[WARN]”或“[ERROR]”),重启应用后即可避免日志狂打。
步骤4:恢复测试环境
删除模拟脚本和日志目录:rm -f mock_debug_log.py; rm -rf /var/log/mock_app,测试用例执行完成。
四、总结与避坑建议
综上,线上环境日志撑爆磁盘的核心根源,是“临时开启DEBUG日志后未及时回退”的人为疏忽。这类故障虽高频,但通过规范操作和技术防护,可有效规避。核心建议有两点:
规范临时操作流程:线上调整日志级别等临时操作,务必通过工单、备忘录等方式记录(明确操作目的、时间、回退节点);故障排查结束后,第一时间回退配置,并安排专人复核,避免遗漏;
建立全链路监控告警:通过Zabbix、Prometheus等监控工具,对磁盘空间(如使用率>85%告警)、磁盘I/O(如%util>90%告警)、CPU利用率(如>80%告警)等指标设置阈值告警;同时可监控日志文件增长速率,一旦出现异常快速响应,将故障扼杀在萌芽阶段。
为更直观地呈现排查逻辑,以下是“日志狂打导致磁盘撑爆”问题的标准化排查框架图:
框架图清晰梳理了从发现问题到解决问题的全流程,结合排查口诀:top找高耗进程 → pidstat/iostat证I/O压力 → strace追写入行为 → lsof锁日志文件 → 调级别根源解决