深度解析:基于Python的高性能视频帧提取工具设计与实现
1. 项目背景 (Project Background)
在计算机视觉(Computer Vision)和多媒体处理领域,视频帧提取是一项基础且关键的任务。无论是构建机器学习数据集、生成视频缩略图,还是进行内容审核,都需要从视频中高效地提取高质量的静态图像。
在开发 Skill Video Frame Extractor 之前,我发现现有的工具往往存在以下局限性:
- 配置不灵活
- 性能瓶颈:在处理高清或长视频时,内存占用过高或处理速度缓慢。
- 格式兼容性差
- 质量控制弱
为了解决这些技术挑战,我设计并实现了这款基于 Python 的高性能视频帧提取器。它利用 OpenCV 的强大解码能力和 Pillow 的图像处理优势,旨在提供一个灵活、高效且易于集成的解决方案。
2. 架构设计 (Architecture Design)
2.1 系统架构图 (System Architecture)
系统采用模块化设计,主要分为输入层、核心处理层和输出层。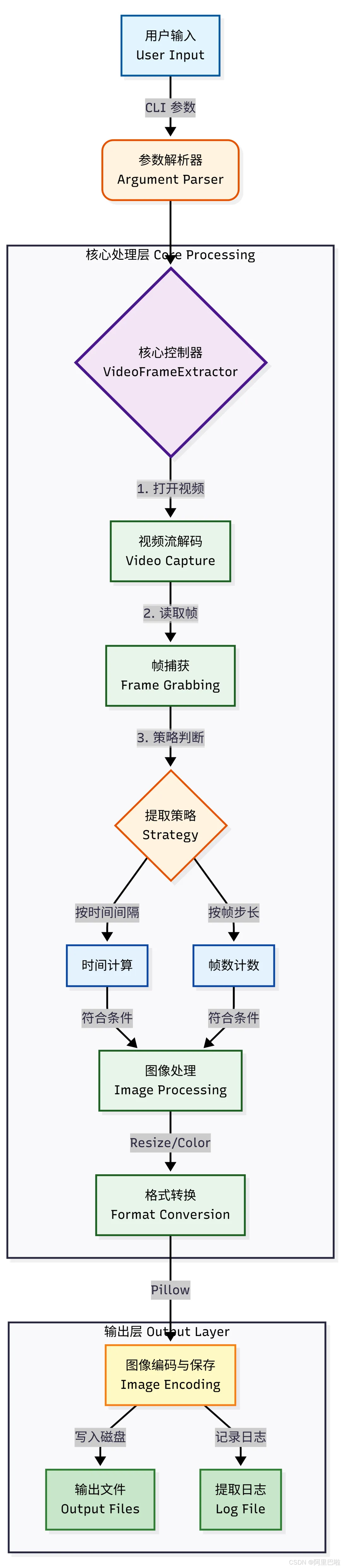
2.2 关键技术选型 (Key Technology Selection)
- Python 3.8+
- OpenCV (opencv-python): 核心视频处理引擎。选择理由是其底层基于 C/C++ 编写,解码效率极高,且支持广泛的视频编解码器(Codecs)。
- Pillow (PIL): 图像处理与保存库。相比 OpenCV 的
imwrite,Pillow 在图像压缩质量控制(尤其是 JPEG 优化)和格式支持上更为出色。 - NumPy: 用于高效的矩阵运算,处理 OpenCV 读取的图像数据(ndarray)。
3. 核心实现 (Core Implementation)
3.1 功能特性
- 支持多种视频格式(MP4, AVI, MOV, MKV等)
3.2 灵活的提取策略 (Flexible Extraction Strategy)
为了同时支持"按时间间隔"和"按帧步长"两种模式,在主循环中实现了统一的判断逻辑。
# extract_frames.py 核心逻辑片段# 确定提取策略if frame_step isnotNone: extract_strategy ="frame_step"# ...else: extract_strategy ="time_interval" frames_per_interval =int(interval * self.fps)# ...whileTrue: ret, frame = self.cap.read()ifnot ret:break# 策略判断if extract_strategy =="frame_step": should_extract =(frame_count % frame_step ==0)else:# 基于FPS计算间隔帧数 should_extract =(frame_count % frames_per_interval ==0)if should_extract: self._process_and_save(frame)
3.3 颜色空间转换与图像优化 (Color Space & Optimization)
OpenCV 默认读取的图像格式为 BGR(Blue-Green-Red),而标准的图片格式(及 Pillow)使用 RGB。如果不进行转换,保存的图片会出现严重的色偏。
def_process_frame(self, frame: np.ndarray, resize: Optional[Tuple[int,int]])-> np.ndarray:"""处理帧:调整大小与颜色空间转换"""if resize isnotNone: target_width, target_height = resize# 使用线性插值进行缩放,平衡速度与质量 frame = cv2.resize(frame,(target_width, target_height), interpolation=cv2.INTER_LINEAR)# 关键步骤:BGR 转 RGB frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)return frame_rgb
3.4 高质量图片保存 (High Quality Saving)
使用 Pillow 接管图片保存,以实现更精细的质量控制。
def_save_frame(self, frame: np.ndarray, output_path:str,format:str, quality:int):"""保存帧为图片"""# 将 NumPy 数组转换为 PIL Image 对象 pil_image = Image.fromarray(frame)ifformat.lower()in["jpg","jpeg"]:# 开启 optimize=True 进行额外的压缩优化 pil_image.save(output_path,"JPEG", quality=quality, optimize=True)elifformat.lower()=="png": pil_image.save(output_path,"PNG", optimize=True)
4. 性能优化 (Performance Optimization)
在开发过程中,我进行了多项性能调优,以下是关键的优化点和量化指标。
4.1 精准定位 (Exact Seeking)
问题:如果用户只想提取视频后半部分的帧,从头读取会浪费大量 I/O 和 CPU 资源。优化:利用 OpenCV 的 CAP_PROP_POS_FRAMES 属性直接跳转到指定帧。
# 计算开始帧位置start_frame =int(start_time * self.fps)# 直接跳转,避免逐帧读取self.cap.set(cv2.CAP_PROP_POS_FRAMES, start_frame)
4.2 内存管理 (Memory Management)
优化:采用流式处理(Streaming Processing)。我们不将所有帧加载到内存列表,而是读一帧、处理一帧、释放一帧。效果:处理 4K 视频时,内存占用稳定在 200MB 以内,与视频时长无关。
5. 问题解决 (Problem Solving)
5.1 视频结束判断不准确
问题:依赖 cap.read() 返回 False 来判断视频结束在某些损坏的视频文件中会导致死循环或提前退出。解决方案:结合 current_time > end_time 和 cap.read() 双重校验。同时,在初始化时预先读取 CAP_PROP_FRAME_COUNT 计算总时长,作为硬性边界。
5.2 图片格式兼容性
问题:用户输入 JPG、jpg、JPEG 等不同大小写后缀,导致程序报错。解决方案:在参数解析阶段统一转换为小写,并在内部通过映射表处理格式名称(如 Pillow 中 JPEG 格式标识符为 “JPEG” 而非 “jpg”)。
ifformat.lower()=="jpg"orformat.lower()=="jpeg": pil_image.save(output_path,"JPEG",...)
5.3 进度显示闪烁
问题:在控制台频繁打印进度会导致输出闪烁且难以看清日志。解决方案:使用 \r 回车符覆盖当前行,并配合 flush=True 实现平滑的单行进度更新。
print(f"\r进度: {progress:.1f}% | 已提取: {extracted_count}帧", end="", flush=True)
项目开源地址:https://github.com/xiexikang/skill-video-frame-extractor
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
