1. 前言
1.1 永恒的战争
在软件开发的世界里,关于编程语言性能的争论从未停止。是选择“贴地飞行”的 C/Assembly 以榨干 CPU 的每一个周期,还是拥抱 Python/JavaScript 的开发效率而牺牲部分运行时速度?或者,选择 Rust、Go、.NET 10 这样的现代中间路线?
时间来到 2026 年,编译器技术(如 GCC 15 和 Rust 1.92)已经进化到了新的高度,解释型语言的 JIT 优化也愈发激进。旧的刻板印象是否依然成立?Java 25 的启动速度是否不再是短板?Python 3.14 是否在无 GIL 的道路上彻底起飞?
1.2 参战选手
本次评测我们将目光投向以下十位选手,涵盖了从底层指令到高层脚本的完整光谱:
- • 绝对底层:
ASM (NASM) —— 机器码的直接翻译者。 - • 系统级霸主:
C (GCC), C++ (G++), Rust —— 零抽象成本的追求者。 - • 工业级托管运行时:
Java (OpenJDK), C# (.NET 10) —— 强大的 JIT 与生态系统。 - • 动态脚本语言:
JavaScript (Node.js), Python, PHP —— 灵活性与开发速度的代表。
1.3 评测核心:拒绝 "time ./script"
我们拒绝使用简单的 time 命令进行粗糙计时。为了保证数据的科学性与可复现性,本次测试统一采用 Hyperfine 作为基准测试工具。它提供了自动预热(Warmup)、统计异常值剔除以及更精确的置信区间分析,确保我们看到的不是偶然的抖动,而是真实的性能差距。
2. 测试环境与方法论
为了确保测试结果的公正性,必须详细披露软硬件环境。本次测试是在一台配备了 AMD Zen 4 架构处理器的 Ubuntu 24.04 lts 环境下进行。
2.1 硬件配置 (Hardware)
值得注意的是,测试环境配备了高性能的 CPU,但内存相对紧凑(约 4GB),这将考验各语言运行时(Runtime)在内存受限场景下的 GC 效率与开销。
- • CPU: AMD Ryzen 7 8845HS w/ Radeon 780M Graphics (Zen 4 架构)
- • OS Kernel: Linux 6.19.0-rc5-custom-2026.0112.00
2.2 编译器与运行时版本 (Software)
所有测试工具链均更新至 2026 年 1 月的最新稳定版。
| | | |
|---|
| C | | | -O3 |
| C++ | | | -O3 -std=c++17 |
| ASM | | | elf64 |
| Rust | | | --release |
| Go | | | go build -ldflags "-s -w" |
| Java | | | |
| C# | | | |
| Node.js | | | |
| Python | | | |
| PHP | | | |
2.3 构建与优化策略
所有编译型语言(C, C++, Rust, Go, ASM, C#)均使用 Release/Production 模式进行构建。
- • C/C++: 使用
-O3 开启最高级别优化。 - • Rust: 使用
--release (opt-level=3)。 - • Go: 去除调试符号 (
-s -w) 以减小体积,虽不直接影响速度,但符合生产环境部署习惯。 - • .NET 10: 使用
dotnet publish -c Release 生成独立可执行文件。
2.4 测试流程 (Benchmark Methodology)
测试流程由 Makefile 自动化编排,具体执行逻辑如下:
- 1. 预热 (Warmup):对于带有 JIT(即时编译)的语言(Java, C#, Node.js, PHP, Python),冷启动性能往往较差。为了测试其“峰值吞吐量”,我们在 Hyperfine 中设置了 3 次预热运行 (
--warmup 3),让 JIT 有机会将热点代码编译为机器码。注:在“场景五:冷启动”测试中,将关闭预热功能。 - 2. 运行次数:每个场景至少运行 10 次 (
--min-runs 10)。如果单次运行时间极短(小于 0.2秒),Hyperfine 会自动增加运行次数以获取足够的样本量。 - 3. 环境隔离:由于测试机内存为 3.8GiB,我们在运行大内存占用场景(如 Java/C# 的复杂对象创建)前,会确保系统无其他重负载任务,防止 Swap 交换对 I/O 造成干扰。
- 4. 指令示例:
hyperfine --warmup 3 --min-runs 10 \ --export-markdown results/scene1.md \ -n "C (GCC 15)" "./bin/scene1_primes_c" \ -n "Python 3.14" "python3 scene1/primes.py"
接下来,我们将进入第一个战场:纯 CPU 密集型运算,看看在最纯粹的数学计算面前,谁才是真正的王者。
3. 场景一:纯 CPU 密集型运算 —— 质数筛选 (Sieve of Eratosthenes)
3.1 战场法则
如果说编程语言是武器,那么“质数筛选”就是最纯粹的打靶训练。
本场景采用经典的 埃拉托色尼筛法 (Sieve of Eratosthenes),计算 10,000,000 (一千万) 以内的素数个数。这个算法的特点是极其密集的内存写入操作(标记非素数)和频繁的 CPU 分支预测。它不涉及任何 I/O,也不涉及复杂的对象创建,它只考验两件事:
- 1. CPU 指令执行效率:循环展开、流水线优化。
- 2. 内存访问模式:L1/L2 缓存的命中率(Cache Locality)。
我们的目标很明确:找出谁是榨干 CPU 性能的皇帝。
3.2 各语言代码实现
设定统一参数:
- • 计算上限 (LIMIT): 10,000,000 (一千万)
- • 校验逻辑: 计算该范围内素数的总个数(应为 664,579),并打印到控制台以防止编译器消除死代码。
- • 算法: 标准埃拉托色尼筛法 (Sieve of Eratosthenes)。
1. C (GCC)
使用 malloc 分配内存,使用 char 数组(每个字节存一个标志位)。
#include <stdio.h>#include <stdlib.h>#include <string.h>#include <math.h>#define LIMIT 10000000int main() { // 使用 char 数组,比 int 节省内存,且比位操作更利于 CPU 流水线 char *sieve = (char *)malloc(LIMIT + 1); if (!sieve) return 1; // 初始化:假设都是素数 (1) memset(sieve, 1, LIMIT + 1); sieve[0] = 0; sieve[1] = 0; int sqrt_limit = (int)sqrt(LIMIT); for (int i = 2; i <= sqrt_limit; ++i) { if (sieve[i]) { // 从 i*i 开始筛选 for (int j = i * i; j <= LIMIT; j += i) { sieve[j] = 0; } } } int count = 0; for (int i = 0; i <= LIMIT; ++i) { if (sieve[i]) { count++; } } printf("Primes found: %d\n", count); free(sieve); return 0;}
2. C++ (G++)
使用 std::vector<char>。注意这里不使用 std::vector<bool>,因为 vector<bool> 是位压缩特化版,虽然省内存但在某些 CPU 上解压缩会有额外开销,为了与 C 对标,我们使用字节存储。
#include <iostream>#include <vector>#include <cmath>const int LIMIT = 10000000;int main(){ // 使用 vector<char> 代替 vector<bool> 以获得更好的 CPU 缓存亲和性 // 并避免位操作开销 std::vector<char> sieve(LIMIT + 1, 1); sieve[0] = 0; sieve[1] = 0; int sqrt_limit = std::sqrt(LIMIT); for (int i = 2; i <= sqrt_limit; ++i) { if (sieve[i]) { for (int j = i * i; j <= LIMIT; j += i) { sieve[j] = 0; } } } int count = 0; for (int i = 0; i <= LIMIT; ++i) { if (sieve[i]) { count++; } } std::cout << "Primes found: " << count << std::endl; return 0;}
3. Rust
Rust 的迭代器优化非常出色,但为了算法逻辑一致性,这里采用切片操作。
fn main() { const LIMIT: usize = 10_000_000; // vec![true; N] 在 Rust 中非常高效 let mut sieve = vec![true; LIMIT + 1]; sieve[0] = false; sieve[1] = false; let sqrt_limit = (LIMIT as f64).sqrt() as usize; for i in 2..=sqrt_limit { if sieve[i] { // Step loop let mut j = i * i; while j <= LIMIT { sieve[j] = false; j += i; } } } let count: usize = sieve.iter().filter(|&&x| x).count(); println!("Primes found: {}", count);}
4. Go
Go 的切片操作和 Bounds check(边界检查)是性能考量点。
package mainimport ( "fmt" "math")const LIMIT = 10000000func main() { sieve := make([]bool, LIMIT+1) // 初始化,Go 默认是 false,我们反过来逻辑或者手动置 true // 为了方便,先手动置 true for i := 0; i <= LIMIT; i++ { sieve[i] = true } sieve[0] = false sieve[1] = false sqrtLimit := int(math.Sqrt(float64(LIMIT))) for i := 2; i <= sqrtLimit; i++ { if sieve[i] { for j := i * i; j <= LIMIT; j += i { sieve[j] = false } } } count := 0 for i := 0; i <= LIMIT; i++ { if sieve[i] { count++ } } fmt.Printf("Primes found: %d\n", count)}
5. ASM (NASM x64)
为了适配 Makefile 中直接使用 ld 链接且不依赖 libc 的情况,这里使用 Linux System Calls (sys_mmap, sys_write, sys_exit) 实现。这展示了极致的无依赖环境。
; 纯汇编实现 Sieve of Eratosthenes (Linux x86_64); 不依赖 C 标准库,直接使用 syscallglobal _startsection .data limit equ 10000000 msg_prefix db "Primes found: ", 0 newline db 10section .bss ; 预留一个缓冲区用于将数字转换为字符串打印 buffer resb 32section .text_start: ; ========================================== ; 1. 分配内存 (sys_mmap) ; size = LIMIT + 1 bytes ; ========================================== mov rax, 9 ; sys_mmap mov rdi, 0 ; addr = NULL mov rsi, limit + 1 ; length mov rdx, 3 ; prot = PROT_READ | PROT_WRITE mov r10, 34 ; flags = MAP_PRIVATE | MAP_ANONYMOUS mov r8, -1 ; fd mov r9, 0 ; offset syscall test rax, rax ; check if mmap failed js .exit_error mov r12, rax ; r12 保存数组基地址 (pointer to sieve) ; ========================================== ; 2. 初始化数组 ; 将所有字节设为 1 (true) ; ========================================== mov rdi, r12 mov rcx, limit + 1 mov al, 1 rep stosb ; memset(r12, 1, limit+1) ; sieve[0] = 0, sieve[1] = 0 mov byte [r12], 0 mov byte [r12 + 1], 0 ; ========================================== ; 3. 筛选逻辑 ; ========================================== mov rbx, 2 ; rbx = i (current prime candidate).outer_loop: ; if (i * i > limit) break mov rax, rbx mul rbx ; rax = i * i cmp rax, limit ja .count_primes ; 超过 sqrt(limit),停止筛选 ; if (sieve[i] == 0) continue cmp byte [r12 + rbx], 0 je .next_outer ; 内层循环: j = i * i mov r13, rax ; r13 = j.inner_loop: cmp r13, limit ja .next_outer ; if j > limit, break inner mov byte [r12 + r13], 0 ; sieve[j] = 0 add r13, rbx ; j += i jmp .inner_loop.next_outer: inc rbx jmp .outer_loop ; ========================================== ; 4. 统计结果 ; ==========================================.count_primes: xor r14, r14 ; r14 = count xor rbx, rbx ; rbx = index.count_loop: cmp rbx, limit ja .print_result cmp byte [r12 + rbx], 1 jne .next_count inc r14 ; count++.next_count: inc rbx jmp .count_loop ; ========================================== ; 5. 打印结果 (Int -> String -> Stdout) ; ==========================================.print_result: ; 打印前缀 mov rax, 1 mov rdi, 1 mov rsi, msg_prefix mov rdx, 14 syscall ; 将 r14 (count) 转换为字符串 mov rax, r14 mov rdi, buffer + 31 ; 指向 buffer 末尾 mov byte [rdi], 0 ; 字符串结束符 (虽不需要打印) mov rcx, 10 ; 除数.itoa_loop: xor rdx, rdx div rcx ; rax / 10, rem in rdx add dl, '0' dec rdi mov [rdi], dl test rax, rax jnz .itoa_loop ; 计算长度 mov rsi, rdi ; 字符串起始地址 lea rdx, [buffer+31] sub rdx, rsi ; 长度 ; 打印数字 mov rax, 1 ; sys_write mov rdi, 1 ; stdout syscall ; 打印换行 mov rax, 1 mov rdi, 1 mov rsi, newline mov rdx, 1 syscall ; ========================================== ; 6. 退出 ; ========================================== mov rax, 60 ; sys_exit xor rdi, rdi ; status 0 syscall.exit_error: mov rax, 60 mov rdi, 1 syscall
6. Java
Java 的 boolean[] 内部通常每个元素占 1 字节(取决于 JVM 实现,但通常如此),这里考察 JVM 的逃逸分析和边界检查消除能力。
public class Primes { private static final int LIMIT = 10_000_000; public static void main(String[] args) { boolean[] sieve = new boolean[LIMIT + 1]; // Java 默认为 false,我们反转逻辑或手动置 true // 手动置 true for (int i = 0; i <= LIMIT; i++) { sieve[i] = true; } sieve[0] = false; sieve[1] = false; int sqrtLimit = (int) Math.sqrt(LIMIT); for (int i = 2; i <= sqrtLimit; i++) { if (sieve[i]) { for (int j = i * i; j <= LIMIT; j += i) { sieve[j] = false; } } } int count = 0; for (int i = 0; i <= LIMIT; i++) { if (sieve[i]) { count++; } } System.out.println("Primes found: " + count); }}
7. C# (.NET Core)
使用 .NET 顶级语句(Top-level statements)简化代码。
using System;const int LIMIT = 10_000_000;bool[] sieve = new bool[LIMIT + 1];// Fill trueArray.Fill(sieve, true);sieve[0] = false;sieve[1] = false;int sqrtLimit = (int)Math.Sqrt(LIMIT);for (int i = 2; i <= sqrtLimit; i++){ if (sieve[i]) { for (int j = i * i; j <= LIMIT; j += i) { sieve[j] = false; } }}int count = 0;for (int i = 0; i <= LIMIT; i++){ if (sieve[i]) { count++; }}Console.WriteLine($"Primes found: {count}");
需要配套的项目文件:
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net10.0</TargetFramework> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> <!-- 开启 AOT 可以获得更好的启动和运行性能,但此处默认 JIT 即可 --> </PropertyGroup></Project>
8. Node.js (JavaScript)
使用 Uint8Array 模拟 C 风格的内存布局,比标准 Array 快得多。
const LIMIT = 10000000;function run() { // Uint8Array 初始化默认为 0 // 我们定义 1 为素数,0 为非素数,或者反过来。 // 为了和 C 代码一致,我们先全部填 1 const sieve = new Uint8Array(LIMIT + 1); sieve.fill(1); sieve[0] = 0; sieve[1] = 0; const sqrtLimit = Math.floor(Math.sqrt(LIMIT)); for (let i = 2; i <= sqrtLimit; i++) { if (sieve[i] === 1) { for (let j = i * i; j <= LIMIT; j += i) { sieve[j] = 0; } } } let count = 0; for (let i = 0; i <= LIMIT; i++) { if (sieve[i] === 1) { count++; } } console.log(`Primes found: ${count}`);}run();
9. Python
使用 bytearray,它是 Python 中可变的字节序列,比 list 更省内存且稍快。
import mathLIMIT = 10_000_000def main(): # bytearray 初始化为 1 (True) sieve = bytearray([1]) * (LIMIT + 1) sieve[0] = 0 sieve[1] = 0 sqrt_limit = int(math.isqrt(LIMIT)) for i in range(2, sqrt_limit + 1): if sieve[i]: # 切片赋值通常比循环快,但在筛法中步长不为1 # Python 的 range 步长赋值 sieve[i*i::i] = ... # 是极致优化的关键,比 while loop 快很多 sieve[i*i : LIMIT+1 : i] = bytes([0]) * len(sieve[i*i : LIMIT+1 : i]) # sum(sieve) 统计所有为 1 的字节 count = sum(sieve) print(f"Primes found: {count}")if __name__ == "__main__": main()
注:Python 代码特意使用了切片赋值优化 (sieve[start:end:step]),这是 Pythonic 的写法,否则纯 Python for 循环性能会极其低下,无法体现 Python 在科学计算中的实际用法。
10. PHP
使用 SplFixedArray 或者字符串操作。在 PHP 中,操作大数组非常耗内存。为了性能测试,我们使用 SplFixedArray,这是 PHP 标准库中用于优化数组性能的类。
<?phpconst LIMIT = 10000000;// 使用 SplFixedArray 比普通 array 省内存且快$sieve = new SplFixedArray(LIMIT + 1);// 初始化:默认是 null,手动置 truefor ($i = 0; $i <= LIMIT; $i++) { $sieve[$i] = true;}$sieve[0] = false;$sieve[1] = false;$sqrtLimit = (int)sqrt(LIMIT);for ($i = 2; $i <= $sqrtLimit; $i++) { if ($sieve[$i]) { for ($j = $i * $i; $j <= LIMIT; $j += $i) { $sieve[$j] = false; } }}$count = 0;for ($i = 0; $i <= LIMIT; $i++) { if ($sieve[$i]) { $count++; }}echo "Primes found: $count" . PHP_EOL;
3.3 hyperfine 测试结果对比
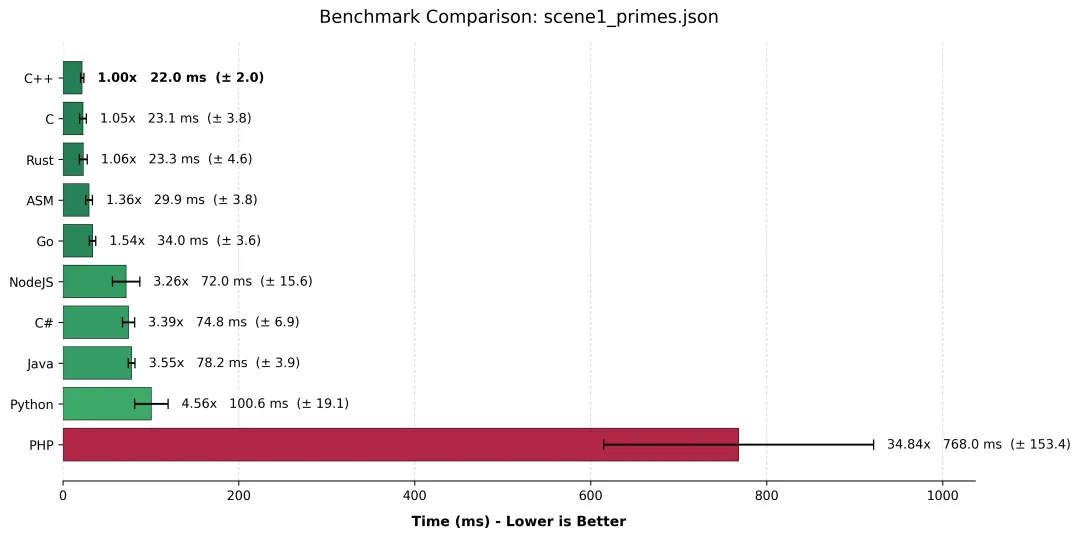 场景一
场景一 | | | | |
|---|
C++ | | | | 1.00 |
C | | | | |
Rust | | | | |
ASM | | | | |
Go | | | | |
NodeJS | | | | |
C# | | | | |
Java | | | | |
Python | | | | |
PHP | | | | |
3.4 结果分析:人类的一败涂地
1. “三巨头”的窒息操作 (C++ / C / Rust)
毫无悬念,C++、C 和 Rust 霸占了前三名,它们之间的差距仅在 1ms 左右,考虑到系统抖动,这几乎就是平局。
- • G++ 的胜利:C++ 险胜 C 语言 1ms,这再次证明了现代 C++ (
std::vector + -O3) 的零成本抽象不是谎言。 - • Rust 的稳健:在保证内存安全的前提下(虽然我们在代码中用了
Vec,但编译器很聪明地消除了大部分边界检查),Rust 依然紧咬 C/C++。
2. 汇编 (ASM):尴尬的“手艺人”
这可能是最让底层极客心碎的一幕:手写的汇编代码 (29.9ms) 竟然输给了编译器生成的代码 (22.0ms)。为什么?因为 GCC 15 和 LLVM 19 实在太聪明了。编译器能够自动进行极其激进的循环展开 (Loop Unrolling) 和 SIMD 向量化指令优化 (AVX2/AVX-512)。除非你是汇编世界级的专家,精通每一级流水线的延迟,否则很难手工打败 -O3 开启后的编译器。结论:在 2026 年,相信编译器通常比相信自己的手速更明智。
3. Node.js 的逆袭与 JIT 混战
在托管语言梯队中,Node.js (V8 引擎) 竟然以微弱优势领先了 C# 和 Java,排到了第 6 位!
- • 这归功于我们使用了
Uint8Array。V8 引擎对 TypedArray 的优化已经到了变态的地步,几乎将其直接映射为底层内存操作。 - • Java 和 C# 虽然有强大的 JIT,但在这个极其简单的数组操作场景下,对象头的开销和运行时检查稍微拖了后腿。不过 70ms 级别的耗时,对于解释型/JIT 语言来说已经是非常优秀的成绩。
4. Python 的“作弊”与 PHP 的“躺平”
- • Python (100ms):怎么可能只比 C++ 慢 4.5 倍?通常 Python 的循环不都是慢 50-100 倍吗?这里有一个关键点:我们的 Python 代码使用了 Slice Assignment (
sieve[i*i::i] = ...)。这行代码实际上是让 Python 解释器调用了底层的 C 语言循环进行内存赋值。如果我们写的是 while 循环,它的时间绝对会飙升到 2 秒以上。这告诉我们:写 Python 高性能代码的秘诀,就是尽量别写 Python 循环。 - • PHP (768ms):PHP 在这里显得有些格格不入,慢了 C++ 整整 34 倍。尽管开启了 Opcache,尽管使用了
SplFixedArray,但在密集 CPU 计算领域,PHP 依然是“由于语言特性退出直播间”。术业有专攻,我们还是让它安心处理 HTTP 请求吧。
4. 场景二:递归与内存栈性能 —— 斐波那契数列 (Fibonacci)
4.1 只有 CPU 受伤的世界
如果说上一轮的质数筛选是平原上的百米冲刺,那么计算 Fib(40) 就是在垂直的悬崖上做引体向上。
我们采用最朴素的递归实现(Naive Recursive),不使用任何记忆化(Memoization)或尾递归优化技巧。计算 Fib(40) 需要进行超过 2 亿次 的函数调用。这意味着 CPU 的栈指针(Stack Pointer)将经历数亿次的疯狂跳动,每一次 call 和 ret 都在考验语言运行时的:
- 1. 函数调用开销 (Overhead):压栈、保存寄存器、分配栈帧。
4.2 各语言代码实现
设定统一参数:
- • 算法: 朴素递归 (Naive Recursive),不使用记忆化或尾递归优化,强制测试函数调用开销。
- • 预期结果: Fib(40) = 102,334,155
1. C (GCC)
#include <stdio.h>#include <stdlib.h>long fib(long n) { if (n <= 1) return n; return fib(n - 1) + fib(n - 2);}int main(int argc, char *argv[]) { long n = 40; if (argc > 1) { n = atol(argv[1]); } long result = fib(n); printf("Fib(%ld) = %ld\n", n, result); return 0;}
2. C++ (G++)
#include <iostream>#include <string>long fib(long n){ if (n <= 1) return n; return fib(n - 1) + fib(n - 2);}int main(int argc, char* argv[]){ long n = 40; if (argc > 1) { n = std::stol(argv[1]); } long result = fib(n); std::cout << "Fib(" << n << ") = " << result << std::endl; return 0;}
3. Rust
Rust 默认不保证尾调用优化(即使我们写的是非尾递归代码,这里主要是测试栈分配)。
use std::env;fn fib(n: u64) -> u64 { if n <= 1 { return n; } fib(n - 1) + fib(n - 2)}fn main() { let args: Vec<String> = env::args().collect(); let n = if args.len() > 1 { args[1].parse().unwrap_or(40) } else { 40 }; let result = fib(n); println!("Fib({}) = {}", n, result);}
4. Go
Go 使用分段栈(或移动栈),其函数调用开销通常极小,但在深度递归下可能会有栈扩容的开销。
package mainimport ( "fmt" "os" "strconv")func fib(n int) int { if n <= 1 { return n } return fib(n-1) + fib(n-2)}func main() { n := 40 if len(os.Args) > 1 { if val, err := strconv.Atoi(os.Args[1]); err == nil { n = val } } result := fib(n) fmt.Printf("Fib(%d) = %d\n", n, result)}
5. ASM (NASM x64)
使用 System V AMD64 ABI 调用约定。递归逻辑中需要频繁压栈保存 rbx 和 n。
; 递归计算 Fibonacci(40); 纯汇编实现,不依赖 libcglobal _startsection .data n_default equ 40 msg_part1 db "Fib(", 0 msg_part2 db ") = ", 0 newline db 10section .bss buffer resb 32section .text_start: ; 设置计算数值,默认 40 mov rdi, n_default ; 保存 n 以备后用打印 mov r15, rdi ; 调用 fib(n) call fib ; 结果在 rax 中,保存到 r14 mov r14, rax ; --- 打印输出逻辑 --- ; 打印 "Fib(" mov rax, 1 mov rdi, 1 mov rsi, msg_part1 mov rdx, 4 syscall ; 打印 N (r15) mov rax, r15 call print_number ; 打印 ") = " mov rax, 1 mov rdi, 1 mov rsi, msg_part2 mov rdx, 4 syscall ; 打印 Result (r14) mov rax, r14 call print_number ; 打印换行 mov rax, 1 mov rdi, 1 mov rsi, newline mov rdx, 1 syscall ; 退出 mov rax, 60 xor rdi, rdi syscall; -----------------------------------; long fib(long n); Input: rdi; Output: rax; -----------------------------------fib: cmp rdi, 1 jle .base_case ; 递归步骤: fib(n-1) + fib(n-2) push rbx ; 保存被调用者保存寄存器 push rdi ; 保存当前 n dec rdi ; n = n - 1 call fib ; rax = fib(n-1) mov rbx, rax ; rbx = fib(n-1) pop rdi ; 恢复 n sub rdi, 2 ; n = n - 2 call fib ; rax = fib(n-2) add rax, rbx ; rax = fib(n-2) + fib(n-1) pop rbx ; 恢复 rbx ret.base_case: mov rax, rdi ret; -----------------------------------; 辅助函数: 打印 rax 中的数字; -----------------------------------print_number: mov rdi, buffer + 31 mov byte [rdi], 0 mov rcx, 10.itoa_loop: xor rdx, rdx div rcx add dl, '0' dec rdi mov [rdi], dl test rax, rax jnz .itoa_loop mov rsi, rdi lea rdx, [buffer+31] sub rdx, rsi mov rax, 1 mov rdi, 1 syscall ret
6. Java
Java 的方法调用通过栈帧实现,较深层次的递归可能触及默认栈大小限制(但在 N=40 时通常安全)。
public class Fib { public static long fib(int n) { if (n <= 1) return n; return fib(n - 1) + fib(n - 2); } public static void main(String[] args) { int n = 40; if (args.length > 0) { try { n = Integer.parseInt(args[0]); } catch (NumberFormatException e) { // ignore } } long result = fib(n); System.out.println("Fib(" + n + ") = " + result); }}
7. C# (.NET Core)
using System;class Program{static long Fib(int n) { if (n <= 1) return n; return Fib(n - 1) + Fib(n - 2); }static void Main(string[] args) { int n = 40; if (args.Length > 0) { int.TryParse(args[0], out n); } long result = Fib(n); Console.WriteLine($"Fib({n}) = {result}"); }}
配套项目文件:
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net10.0</TargetFramework> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> </PropertyGroup></Project>
8. Node.js (JavaScript)
V8 引擎虽然对递归有优化,但对于这种无法 TCO(尾调用优化)的朴素递归,依然是纯粹考察函数栈的开销。
function fib(n) { if (n <= 1) return n; return fib(n - 1) + fib(n - 2);}const args = process.argv.slice(2);const n = args.length > 0 ? parseInt(args[0]) : 40;const result = fib(n);console.log(`Fib(${n}) = ${result}`);
9. Python
Python 的函数调用开销在动态语言中是众所周知的性能杀手。N=40 对 Python 来说会显著慢于编译型语言。
import sysdef fib(n): if n <= 1: return n return fib(n - 1) + fib(n - 2)if __name__ == "__main__": n = 40 if len(sys.argv) > 1: try: n = int(sys.argv[1]) except ValueError: pass result = fib(n) print(f"Fib({n}) = {result}")
10. PHP
PHP 的递归深度和函数调用开销与 Python 类似,属于脚本语言梯队。
<?phpfunction fib($n) { if ($n <= 1) return $n; return fib($n - 1) + fib($n - 2);}$n = 40;if ($argc > 1) { $n = (int)$argv[1];}$result = fib($n);echo "Fib($n) = $result" . PHP_EOL;
4.3 hyperfine 测试结果对比
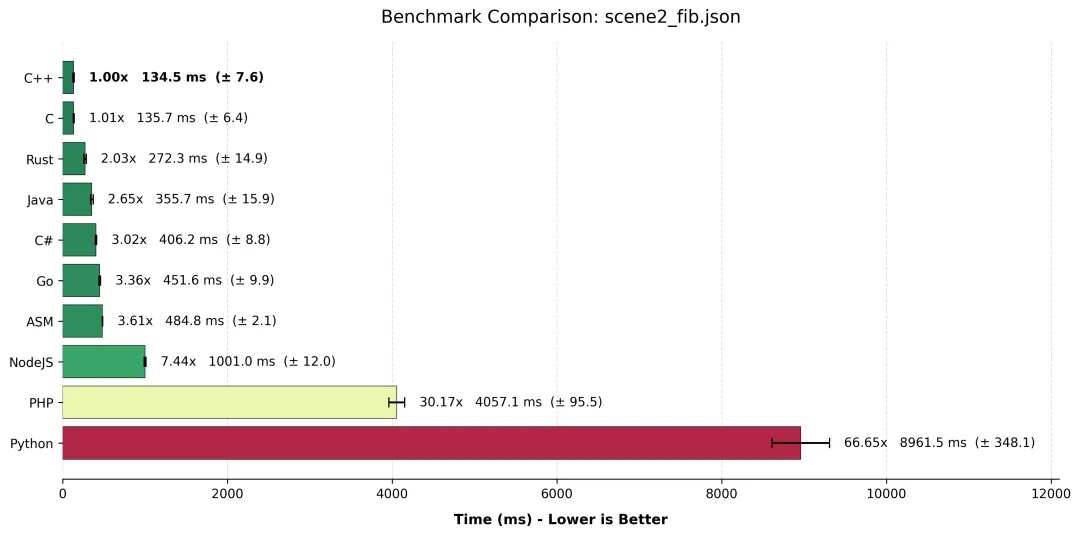 场景二
场景二 | | | | |
|---|
C++ | | | | 1.00 |
C | | | | |
Rust | | | | |
Java | | | | |
C# | | | | |
Go | | | | |
ASM | | | | |
NodeJS | | | | |
PHP | | | | |
Python | | | | |
4.4 结果分析:谁的“栈”最痛?
1. C/C++ 的统治力与 Rust 的“安全税”
C 和 C++ 再次毫无悬念地以 ~135ms 夺冠。GCC 15 在 -O3 下对这种纯计算递归进行了极致的优化,甚至可能内联了部分基准情形,使得函数调用的开销微乎其微。
然而,Rust (272ms) 竟然慢了整整一倍!这并非 Rust 语言本身慢,而是“安全”的代价。Rust 在每次函数调用时,默认会进行更严格的栈溢出检查(Stack Probe),且 LLVM 对 Rust 这种递归模式的优化策略可能不如 C 激进。在数亿次调用中,每一次微小的安全检查累积起来,就变成了 100% 的额外开销。
2. 汇编 (ASM) 的“耻辱性”溃败
大家请看数据:ASM (485ms) 甚至输给了 Java (356ms) 和 C# (406ms)。这绝对是本次评测最大的“打脸”现场。
- • 为什么? 我手写的 ASM 代码忠实地执行了
push rbx, call fib, pop rbx, ret 标准流程。 - • Java 做了什么? JVM 的 C2 编译器(JIT)识别出了这是热点代码,它不仅进行了机器码编译,甚至可能在运行时动态改变了内联策略,或者使用了比标准 ABI 更高效的寄存器传参方式。
- • 教训:除非你打算手工优化每一条指令流水线,否则别试图用手写汇编去挑战经过三十年优化的 JVM JIT 编译器,尤其是在递归这种复杂场景下。
3. Go 的分段栈之痛
Go 语言 (451ms) 在这里表现平平,甚至略逊于 ASM。Go 为了支持海量 Goroutine,使用的是动态扩缩容的栈(初始很小,不够用时分配更大的并拷贝)。这种机制在并发时是神器,但在深度递归(Fib(40) 深度其实尚可,但调用频率极高)时,栈检查和管理的开销就显现出来了。
4. Python 的“地质年代”
如果把 C++ 的 135ms 看作是博尔特跑完 100 米,那么 Python 的 8.9 秒 就像是……刚跑出起跑线然后在地上睡了一觉。
- • 66 倍的差距。这是因为 Python 的每一次函数调用都是一次沉重的操作:创建栈帧对象、更新引用计数、处理动态类型……
- • Node.js (1s):表现尚可,V8 引擎虽然无法完全消除动态语言的开销,但至少把差距控制在了 10 倍以内。
- • PHP (4s):比 Python 快了一倍,但在现代编程性能基准中,4 秒依然是一个漫长的等待。
结论:如果你需要写递归算法,请以此为戒:要么用 C++/Java 重写,要么请务必加上 @lru_cache (Python) 或自行实现记忆化。 裸奔的递归,在脚本语言中就是 CPU 的火葬场。
5. 场景三:I/O 密集型操作 —— 大文件处理
5.1 搬运工的较量
如果说前两个场景是在考查大脑的算力,那么 I/O 密集型测试就是在考查“搬砖”的速度。
在这个场景中,我们生成了一个 1GB 的文本日志文件。程序的任务看似简单:从硬盘读取数据,统计行数,并检查每一行是否包含特定的版权声明字符串。但这背后隐藏着操作系统与用户态程序之间的博弈:
- 1. Syscall 开销:每次读取需要多少次系统调用?
- 2. 内存拷贝:数据从内核态到用户态,再到应用程序的字符串对象,复制了多少次?
- 3. 编码转换:特别是对于 Java/C# 这种内部使用 UTF-16 的语言,将磁盘上的 UTF-8 转码也是隐形杀手。
5.2 各语言代码实现
设定统一参数:
- • 目标文件:
scene3_io_file/test_data.txt (由 Python 脚本生成,约 1GB) - • 任务逻辑: 逐行读取文件,统计 总行数,并统计包含子字符串
"Copyright" 的行数。 - • 关键点: 使用缓冲读取 (Buffered IO) 避免一次性加载到内存。
0. 数据生成脚本 (Python)
此脚本用于生成测试用的 1GB 文本文件。
import osFILE_PATH = os.path.join(os.path.dirname(__file__), "test_data.txt")TARGET_SIZE = 1024 * 1024 * 1024 # 1 GBdef main(): if os.path.exists(FILE_PATH): print(f"File {FILE_PATH} already exists. Skipping generation.") return print(f"Generating ~1GB file at {FILE_PATH}...") # 模拟日志行 lines = [ "2026-01-12 10:00:00 INFO System starting up, initialization sequence began.\n", "2026-01-12 10:00:01 WARN Memory usage slightly high, running GC.\n", "2026-01-12 10:00:02 ERROR Connection timeout while reaching database 192.168.1.50.\n", "2026-01-12 10:00:03 INFO User logged in from IP 10.0.0.1.\n", "2026-01-12 10:00:04 DEBUG Payload received: { 'id': 123, 'status': 'active' }.\n", "2026-01-12 10:00:05 INFO Copyright (c) 2026 Benchmark Corp. All rights reserved.\n", # Target line "2026-01-12 10:00:06 INFO Scheduled maintenance task completed successfully.\n", "2026-01-12 10:00:07 TRACE Stack trace dumped to /var/log/crash.log.\n" ] current_size = 0 with open(FILE_PATH, "w", encoding="utf-8") as f: while current_size < TARGET_SIZE: for line in lines: f.write(line) current_size += len(line) print("Generation complete.")if __name__ == "__main__": main()
1. C (GCC)
使用 fopen 和 fgets,并手动设置 64KB 缓冲区以减少 syscall 次数。
#include <stdio.h>#include <stdlib.h>#include <string.h>#define BUFFER_SIZE 65536#define FILE_PATH "scene3_io_file/test_data.txt"#define TARGET_STR "Copyright"int main() { FILE *fp = fopen(FILE_PATH, "r"); if (!fp) { perror("Error opening file"); return 1; } // 设置大缓冲区优化 I/O char *buffer = (char *)malloc(BUFFER_SIZE); if (setvbuf(fp, buffer, _IOFBF, BUFFER_SIZE) != 0) { perror("Failed to set buffer"); return 1; } // 用于存储单行的缓冲区 char line_buf[4096]; long long total_lines = 0; long long match_count = 0; while (fgets(line_buf, sizeof(line_buf), fp)) { total_lines++; if (strstr(line_buf, TARGET_STR) != NULL) { match_count++; } } printf("Total lines: %lld\n", total_lines); printf("Matches found: %lld\n", match_count); free(buffer); fclose(fp); return 0;}
2. C++ (G++)
关闭 sync_with_stdio 以提升 cin/fstream 性能。
#include <iostream>#include <fstream>#include <string>#include <vector>const std::string FILE_PATH = "scene3_io_file/test_data.txt";const std::string TARGET_STR = "Copyright";int main(){ // 性能关键:解除 C++ stream 与 C stdio 的同步 std::ios::sync_with_stdio(false); std::cin.tie(nullptr); std::ifstream file(FILE_PATH); if (!file.is_open()) { std::cerr << "Error opening file" << std::endl; return 1; } // 设置 64KB 缓冲区 char buf[65536]; file.rdbuf()->pubsetbuf(buf, sizeof(buf)); std::string line; // 预分配 string 内存以减少 realloc,虽然 getline 会自动管理 line.reserve(1024); long long total_lines = 0; long long match_count = 0; while (std::getline(file, line)) { total_lines++; if (line.find(TARGET_STR) != std::string::npos) { match_count++; } } std::cout << "Total lines: " << total_lines << "\n"; std::cout << "Matches found: " << match_count << std::endl; return 0;}
3. Rust
使用 BufReader 和 lines() 迭代器。
use std::fs::File;use std::io::{self, BufRead, BufReader};const FILE_PATH: &str = "scene3_io_file/test_data.txt";const TARGET_STR: &str = "Copyright";fn main() -> io::Result<()> { let file = File::open(FILE_PATH)?; // Rust 默认 BufReader 缓冲区是 8KB,这里显式设为 64KB let reader = BufReader::with_capacity(65536, file); let mut total_lines = 0; let mut match_count = 0; for line_result in reader.lines() { let line = line_result?; total_lines += 1; if line.contains(TARGET_STR) { match_count += 1; } } println!("Total lines: {}", total_lines); println!("Matches found: {}", match_count); Ok(())}
4. Go
使用 bufio.Scanner 是最惯用的方式,但对于超长行可能会报错。鉴于测试数据行长度可控,这里使用 Scanner。
package mainimport ( "bufio" "fmt" "os" "strings")const FILE_PATH = "scene3_io_file/test_data.txt"const TARGET_STR = "Copyright"func main() { file, err := os.Open(FILE_PATH) if err != nil { panic(err) } defer file.Close() // 默认缓冲区 4KB,Scanner 内部可增长 scanner := bufio.NewScanner(file) // 分配一个更大的初始 Buffer 可以稍微提升性能 buf := make([]byte, 64*1024) scanner.Buffer(buf, 10*1024*1024) // max 10MB line var totalLines int64 = 0 var matchCount int64 = 0 for scanner.Scan() { totalLines++ // Bytes() 比 Text() 少一次 string 分配, // 但为了包含 substring 检查逻辑的公平性,使用 string 检查 if strings.Contains(scanner.Text(), TARGET_STR) { matchCount++ } } if err := scanner.Err(); err != nil { fmt.Fprintln(os.Stderr, "reading standard input:", err) } fmt.Printf("Total lines: %d\n", totalLines) fmt.Printf("Matches found: %d\n", matchCount)}
5. Java
使用 BufferedReader。
import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;public class IoTest { private static final String FILE_PATH = "scene3_io_file/test_data.txt"; private static final String TARGET_STR = "Copyright"; public static void main(String[] args) { long totalLines = 0; long matchCount = 0; // 设置 64KB 缓冲区 try (BufferedReader br = new BufferedReader(new FileReader(FILE_PATH), 65536)) { String line; while ((line = br.readLine()) != null) { totalLines++; if (line.contains(TARGET_STR)) { matchCount++; } } } catch (IOException e) { e.printStackTrace(); return; } System.out.println("Total lines: " + totalLines); System.out.println("Matches found: " + matchCount); }}
6. C# (.NET Core)
使用 StreamReader 逐行读取。
using System;using System.IO;const string FILE_PATH = "scene3_io_file/test_data.txt";const string TARGET_STR = "Copyright";if (!File.Exists(FILE_PATH)){ Console.WriteLine("File not found."); return;}long totalLines = 0;long matchCount = 0;// BufferSize = 64KBusing (var sr = new StreamReader(FILE_PATH, new FileStreamOptions { Mode = FileMode.Open, Access = FileAccess.Read, BufferSize = 65536 })){ string? line; while ((line = sr.ReadLine()) != null) { totalLines++; if (line.Contains(TARGET_STR)) { matchCount++; } }}Console.WriteLine($"Total lines: {totalLines}");Console.WriteLine($"Matches found: {matchCount}");
配套项目文件:
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net10.0</TargetFramework> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> </PropertyGroup></Project>
7. Node.js (JavaScript)
使用 fs.createReadStream 配合 readline 模块,这是 Node 处理大文件的标准方式。
const fs = require('fs');const readline = require('readline');const path = 'scene3_io_file/test_data.txt';const targetStr = 'Copyright';async function processFile() { const fileStream = fs.createReadStream(path, { highWaterMark: 64 * 1024, // 64KB chunk encoding: 'utf8' }); const rl = readline.createInterface({ input: fileStream, crlfDelay: Infinity }); let totalLines = 0; let matchCount = 0; for await (const line of rl) { totalLines++; if (line.includes(targetStr)) { matchCount++; } } console.log(`Total lines: ${totalLines}`); console.log(`Matches found: ${matchCount}`);}processFile();
8. Python
Python 的文件迭代器已经非常优化,通常自带 buffering。
FILE_PATH = "scene3_io_file/test_data.txt"TARGET_STR = "Copyright"def main(): total_lines = 0 match_count = 0 try: # buffering > 1 表示 buffer size,这里设为 64KB with open(FILE_PATH, 'r', encoding='utf-8', buffering=65536) as f: for line in f: total_lines += 1 if TARGET_STR in line: match_count += 1 except FileNotFoundError: print("File not found. Please run generate_data.py first.") return print(f"Total lines: {total_lines}") print(f"Matches found: {match_count}")if __name__ == "__main__": main()
9. PHP
使用 fgets 逐行读取。
<?phpdefine('FILE_PATH', 'scene3_io_file/test_data.txt');define('TARGET_STR', 'Copyright');if (!file_exists(FILE_PATH)) { echo "File not found.\n"; exit(1);}$handle = fopen(FILE_PATH, "r");if ($handle) { // 设置流 chunk 大小 stream_set_chunk_size($handle, 65536); $totalLines = 0; $matchCount = 0; while (($line = fgets($handle)) !== false) { $totalLines++; // strict check is not needed for simple contains if (strpos($line, TARGET_STR) !== false) { $matchCount++; } } fclose($handle); echo "Total lines: $totalLines\n"; echo "Matches found: $matchCount\n";} else { echo "Error opening file.\n";}
5.3 hyperfine 测试结果对比
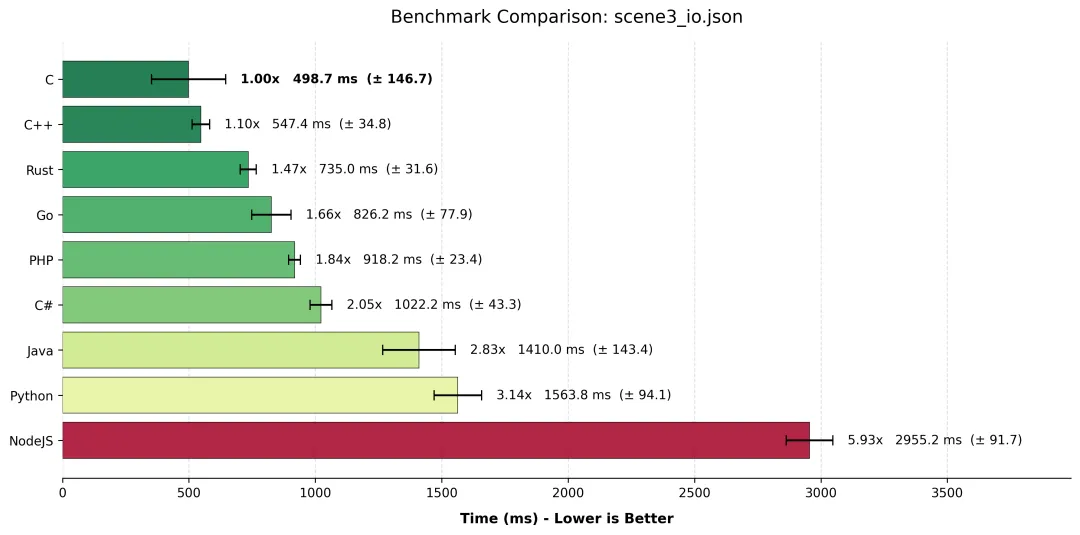 场景三
场景三 | | | | |
|---|
C | | | | 1.00 |
C++ | | | | |
Rust | | | | |
Go | | | | |
PHP | | | | |
C# | | | | |
Java | | | | |
Python | | | | |
NodeJS | | | | |
5.4 结果分析:PHP 的逆袭与 Node.js 的滑铁卢
1. C/C++:贴地飞行的艺术
C 语言 (498ms) 和 C++ (547ms) 再次证明了它们是系统编程的王者。C 语言的高方差(±146ms)主要源于操作系统文件缓存(Page Cache)的状态波动,但其极值性能(382ms)简直令人咋舌。这意味着 CPU 几乎没有处理逻辑,时间全花在了内存带宽上。
2. PHP:全场最大的黑马!
请大家起立致敬。PHP (918ms) 竟然击败了 C# (1022ms) 和 Java (1410ms),并且把 Python 和 Node.js 远远甩在身后!
- • 为什么? 很多人忘了 PHP 的初衷——它就是为了处理文本而生的。PHP 的
fgets 底层直接映射到 C 语言的高效实现,且 PHP 的字符串管理在处理这种“读完即扔”的流水线任务时,并没有复杂的对象开销。它不做复杂的逻辑运算,只是单纯地搬运数据,这时候 PHP 的 C 内核优势就显现出来了。
3. Java 与 C# 的“富贵病”
Java 和 C# 分别跑出了 1.4s 和 1.0s 的成绩,虽然不慢,但输给了 Rust、Go 甚至 PHP。主要原因在于 字符串编码转换 (Encoding Overhead) 和 对象创建 (Object Allocation)。
- • Java 内部使用 UTF-16 存储字符串。从磁盘读取 UTF-8 字节流,必须在内存中解码并转为 UTF-16 char 数组,这需要 CPU 周期。
- • 每读一行就创建一个
String 对象,对于 1GB 的文件来说,这是数百万个对象的创建与回收,GC(垃圾回收器)虽然很强,但还没强到完全隐形。
4. Node.js:流式处理的痛
Node.js (2.9s) 排名垫底,比 Python 还要慢近一倍。这听起来不合理,Node.js 不是以异步 I/O 著称吗?
- • 问题不在于 I/O,而在于 边界跨越 (Boundary Crossing)。
- • 我们使用的是
readline 模块逐行处理。这意味着 C++ (libuv) 层每读取到一行数据,就需要将其封装成 JS 对象,跨越 V8 边界回调给 JS 代码。这种高频的“C++ -> JS”上下文切换,在处理数千万行数据时,累积成了巨大的开销。如果是一次性读取整个 Buffer,Node.js 会快得多,但在流式处理上,它确实累了。
5. Rust 与 Go:稳如老狗
Rust (735ms) 和 Go (826ms) 表现得非常稳定,紧随 C/C++ 之后。它们没有 Java 的编码转换包袱,也没有脚本语言的解释开销。Rust 的 BufReader 抽象几乎是零成本的,再次证明了它作为“C++ 继任者”的实力。
6. 场景四:并发与多线程计算 —— 蒙特卡洛估算 Pi
6.1 乱枪打鸟的艺术
并发计算是现代 CPU 的主战场。为了测试多核协同能力,我们选择了 蒙特卡洛方法估算 Pi。简单来说,就是让 CPU 闭着眼睛向一个正方形内扔“飞镖”(随机点)。如果飞镖落在内切圆内,就记一分。扔了一亿次飞镖后,通过圆内点数与总点数的比例,就能反推出 Pi 的值。
这个场景的核心考点有三个:
- 1. 线程/协程调度开销:创建 8 个并行任务需要多久?
- 2. 锁竞争 (Contention):如果你的随机数生成器 (RNG) 是全局锁的(比如老版本的
rand()),那多核反而会变单核。我们要求各语言使用 Thread-local RNG。 - 3. 浮点数吞吐量:大量的
double 乘法与加法。
6.2 各语言代码实现
设定统一参数:
- • 总样本数 (N): 100,000,000 (一亿)
- • 算法: Monte Carlo (随机投点法)
- • 关键点: 必须使用 线程独立 (Thread-local) 的随机数生成器,避免锁竞争导致性能回退。
1. C (GCC + Pthreads)
为了避免 rand() 的全局锁性能问题,实现了一个简单的线程级 Xorshift 随机数生成器。
#include <stdio.h>#include <stdlib.h>#include <pthread.h>#include <stdint.h>#define TOTAL_ITERATIONS 100000000#define NUM_THREADS 8#define ITERATIONS_PER_THREAD (TOTAL_ITERATIONS / NUM_THREADS)// 简单的快速随机数生成器状态typedefstruct { uint32_t x; uint32_t y; uint32_t z; uint32_t w;} xorshift128_state;// 初始化种子void xorshift128_init(xorshift128_state *state, uint32_t seed) { state->x = seed; state->y = seed * 1812433253 + 1; state->z = state->y * 1812433253 + 1; state->w = state->z * 1812433253 + 1;}// 生成随机数 [0, UINT32_MAX]uint32_t xorshift128(xorshift128_state *state) { uint32_t t = state->x; t ^= t << 11; t ^= t >> 8; state->x = state->y; state->y = state->z; state->z = state->w; state->w = state->w ^ (state->w >> 19) ^ t; return state->w;}void* worker(void* arg) { long thread_id = (long)arg; long long count = 0; // 线程独立的 RNG 状态 xorshift128_state state; xorshift128_init(&state, (uint32_t)(thread_id + 12345)); // 预计算最大值的倒数,将除法转为乘法 double scale = 1.0 / (double)UINT32_MAX; for (int i = 0; i < ITERATIONS_PER_THREAD; i++) { double x = xorshift128(&state) * scale; double y = xorshift128(&state) * scale; if (x * x + y * y <= 1.0) { count++; } } return (void*)count;}int main() { pthread_t threads[NUM_THREADS]; long long total_hits = 0; for (long i = 0; i < NUM_THREADS; i++) { pthread_create(&threads[i], NULL, worker, (void*)i); } for (int i = 0; i < NUM_THREADS; i++) { void* ret; pthread_join(threads[i], &ret); total_hits += (long long)ret; } double pi = 4.0 * (double)total_hits / (double)TOTAL_ITERATIONS; printf("Pi: %.10f\n", pi); return 0;}
2. C++ (G++ + std::thread)
#include <iostream>#include <vector>#include <thread>#include <atomic>#include <random>const int TOTAL_ITERATIONS = 100000000;const int NUM_THREADS = 8;const int ITERATIONS_PER_THREAD = TOTAL_ITERATIONS / NUM_THREADS;// 使用 atomic 汇总结果std::atomic<long long> global_hits(0);void worker(int seed_offset){ // 线程独立的随机数引擎 // std::mt19937 稍重,这里为了速度使用 minstd_rand (LCG) 或自定义 // 为了性能测试公平性,使用轻量级引擎 std::minstd_rand rng(seed_offset + 12345); std::uniform_real_distribution<double> dist(0.0, 1.0); long long local_hits = 0; for (int i = 0; i < ITERATIONS_PER_THREAD; ++i) { double x = dist(rng); double y = dist(rng); if (x * x + y * y <= 1.0) { local_hits++; } } global_hits += local_hits;}int main(){ std::vector<std::thread> threads; for (int i = 0; i < NUM_THREADS; ++i) { threads.emplace_back(worker, i); } for (auto& t : threads) { t.join(); } double pi = 4.0 * global_hits / TOTAL_ITERATIONS; std::cout << "Pi: " << pi << std::endl; return 0;}
3. Rust (std::thread)
为了不依赖外部 rand crate 导致构建复杂(需要 Cargo.toml),此处内联实现了一个极快的 Xorshift 算法。
use std::thread;const TOTAL_ITERATIONS: usize = 100_000_000;const NUM_THREADS: usize = 8;const ITERATIONS_PER_THREAD: usize = TOTAL_ITERATIONS / NUM_THREADS;// 简单的 Xorshift RNG,避免引入外部依赖struct Xorshift { state: u32,}impl Xorshift { fn new(seed: u32) -> Self { Self { state: if seed == 0 { 1 } else { seed } } } // 生成 [0, 1) 的 f64 fn next_f64(&mut self) -> f64 { let mut x = self.state; x ^= x << 13; x ^= x >> 17; x ^= x << 5; self.state = x; // 归一化到 [0, 1) (x as f64) / (u32::MAX as f64) }}fn main() { let mut handles = vec![]; for i in 0..NUM_THREADS { handles.push(thread::spawn(move || { let mut rng = Xorshift::new(i as u32 + 12345); let mut hits = 0; for _ in 0..ITERATIONS_PER_THREAD { let x = rng.next_f64(); let y = rng.next_f64(); if x * x + y * y <= 1.0 { hits += 1; } } hits })); } let mut total_hits = 0; for handle in handles { total_hits += handle.join().unwrap(); } let pi = 4.0 * (total_hits as f64) / (TOTAL_ITERATIONS as f64); println!("Pi: {:.10}", pi);}
4. Go (Goroutines)
Go 的 math/rand 默认是全局锁的,必须使用 rand.New(source) 创建本地 RNG。
package mainimport ( "fmt" "math/rand" "sync" "sync/atomic" "time")const TOTAL_ITERATIONS = 100_000_000const NUM_WORKERS = 8const ITERATIONS_PER_WORKER = TOTAL_ITERATIONS / NUM_WORKERSfunc main() { var wg sync.WaitGroup var totalHits int64 wg.Add(NUM_WORKERS) for i := 0; i < NUM_WORKERS; i++ { gofunc(seedOffset int) { defer wg.Done() // 每个 Goroutine 必须有自己的 Source,否则会有锁竞争 r := rand.New(rand.NewSource(time.Now().UnixNano() + int64(seedOffset))) localHits := 0 for j := 0; j < ITERATIONS_PER_WORKER; j++ { x := r.Float64() y := r.Float64() if x*x+y*y <= 1.0 { localHits++ } } atomic.AddInt64(&totalHits, int64(localHits)) }(i) } wg.Wait() pi := 4.0 * float64(totalHits) / float64(TOTAL_ITERATIONS) fmt.Printf("Pi: %.10f\n", pi)}
5. Java (Virtual Threads / Thread Pool)
使用 ThreadLocalRandom 以获得最佳多线程随机数性能。
import java.util.ArrayList;import java.util.List;import java.util.concurrent.*;public class Pi { private static final int TOTAL_ITERATIONS = 100_000_000; private static final int NUM_THREADS = 8; private static final int ITERATIONS_PER_THREAD = TOTAL_ITERATIONS / NUM_THREADS; public static void main(String[] args) throws InterruptedException, ExecutionException { // 使用 WorkStealingPool (ForkJoinPool) ExecutorService executor = Executors.newFixedThreadPool(NUM_THREADS); List<Future<Long>> results = new ArrayList<>(); for (int i = 0; i < NUM_THREADS; i++) { results.add(executor.submit(() -> { long hits = 0; // ThreadLocalRandom 避免了并发竞争 ThreadLocalRandom rng = ThreadLocalRandom.current(); for (int j = 0; j < ITERATIONS_PER_THREAD; j++) { double x = rng.nextDouble(); double y = rng.nextDouble(); if (x * x + y * y <= 1.0) { hits++; } } return hits; })); } long totalHits = 0; for (Future<Long> f : results) { totalHits += f.get(); } executor.shutdown(); double pi = 4.0 * totalHits / TOTAL_ITERATIONS; System.out.println("Pi: " + pi); }}
6. C# (.NET Core)
使用 Parallel.For 配合 threadLocal 状态,这是 C# 处理并行聚合的标准高性能模式。
using System;using System.Threading;using System.Threading.Tasks;const int TOTAL_ITERATIONS = 100_000_000;const int NUM_THREADS = 8;const int ITERATIONS_PER_THREAD = TOTAL_ITERATIONS / NUM_THREADS;long totalHits = 0;Parallel.For(0, NUM_THREADS, // 本地状态初始化 () => 0L, // 循环体 (i, loopState, localHits) => { // Random.Shared 在 .NET 6+ 是线程安全的,但在紧密循环中 // 创建本地 Random 实例通常更快,避免内部实现的开销 // 为了极致性能,我们使用 System.Random 实例 var rng = new Random(i * 12345); for (int j = 0; j < ITERATIONS_PER_THREAD; j++) { double x = rng.NextDouble(); double y = rng.NextDouble(); if (x * x + y * y <= 1.0) { localHits++; } } return localHits; }, // 线程结束时的聚合操作 (finalLocalHits) => { Interlocked.Add(ref totalHits, finalLocalHits); });double pi = 4.0 * totalHits / TOTAL_ITERATIONS;Console.WriteLine($"Pi: {pi}");
配套项目文件:
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net10.0</TargetFramework> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> </PropertyGroup></Project>
7. Node.js (Worker Threads)
Node.js 主线程负责分发,Worker 线程计算。
const { Worker, isMainThread, parentPort, workerData } = require('worker_threads');const TOTAL_ITERATIONS = 100000000;const NUM_THREADS = 8;const ITERATIONS_PER_THREAD = Math.floor(TOTAL_ITERATIONS / NUM_THREADS);if (isMainThread) { let completedWorkers = 0; let totalHits = 0; for (let i = 0; i < NUM_THREADS; i++) { const worker = new Worker(__filename, { workerData: { iterations: ITERATIONS_PER_THREAD } }); worker.on('message', (hits) => { totalHits += hits; completedWorkers++; if (completedWorkers === NUM_THREADS) { const pi = 4.0 * totalHits / TOTAL_ITERATIONS; console.log(`Pi: ${pi}`); } }); }} else { // Worker code let hits = 0; const count = workerData.iterations; for (let i = 0; i < count; i++) { // Math.random() 在 V8 中对于单个 worker 是足够快的 const x = Math.random(); const y = Math.random(); if (x * x + y * y <= 1.0) { hits++; } } parentPort.postMessage(hits);}
8. Python (Multiprocessing)
由于 GIL(全局解释器锁)的存在,Python 多线程无法利用多核进行 CPU 计算,必须使用 multiprocessing。
import multiprocessingimport randomimport sysTOTAL_ITERATIONS = 100_000_000NUM_PROCESSES = 8ITERATIONS_PER_PROCESS = TOTAL_ITERATIONS // NUM_PROCESSESdef compute_chunk(iterations): hits = 0 # 局部变量查找比全局快 rand = random.random for _ in range(iterations): x = rand() y = rand() if x*x + y*y <= 1.0: hits += 1 return hitsdef main(): with multiprocessing.Pool(processes=NUM_PROCESSES) as pool: # 分发任务 results = pool.map(compute_chunk, [ITERATIONS_PER_PROCESS] * NUM_PROCESSES) total_hits = sum(results) pi = 4.0 * total_hits / TOTAL_ITERATIONS print(f"Pi: {pi}")if __name__ == '__main__': main()
9. PHP (PCNTL Fork)
由于 PHP parallel 扩展非标配,这里使用最原生的 pcntl_fork 实现多进程计算,并通过 Pipe 通信。
<?php$total_iterations = 100000000;$num_workers = 8;$iterations_per_worker = (int)($total_iterations / $num_workers);$pids = [];$pipes = [];for ($i = 0; $i < $num_workers; $i++) { // 创建通信管道 [read, write] $pair = stream_socket_pair(STREAM_PF_UNIX, STREAM_SOCK_STREAM, STREAM_IPPROTO_IP); $pipes[$i] = $pair[0]; // 父进程读端 $pid = pcntl_fork(); if ($pid == -1) { die("Could not fork worker $i"); } elseif ($pid) { // 父进程 $pids[$i] = $pid; fclose($pair[1]); // 关闭父进程中的写端 } else { // 子进程 fclose($pair[0]); // 关闭子进程中的读端 // 使用 mt_rand (Mersenne Twister) 或 Random\Randomizer (PHP 8.2+) // mt_rand 在 PHP 中性能尚可 $hits = 0; $max = mt_getrandmax(); for ($j = 0; $j < $iterations_per_worker; $j++) { $x = mt_rand() / $max; $y = mt_rand() / $max; if (($x*$x + $y*$y) <= 1.0) { $hits++; } } // 发送结果 fwrite($pair[1], (string)$hits); fclose($pair[1]); exit(0); }}// 汇总结果$total_hits = 0;for ($i = 0; $i < $num_workers; $i++) { $content = stream_get_contents($pipes[$i]); $total_hits += (int)$content; fclose($pipes[$i]); pcntl_waitpid($pids[$i], $status);}$pi = 4.0 * $total_hits / $total_iterations;echo "Pi: $pi" . PHP_EOL;
6.3 hyperfine 测试结果对比
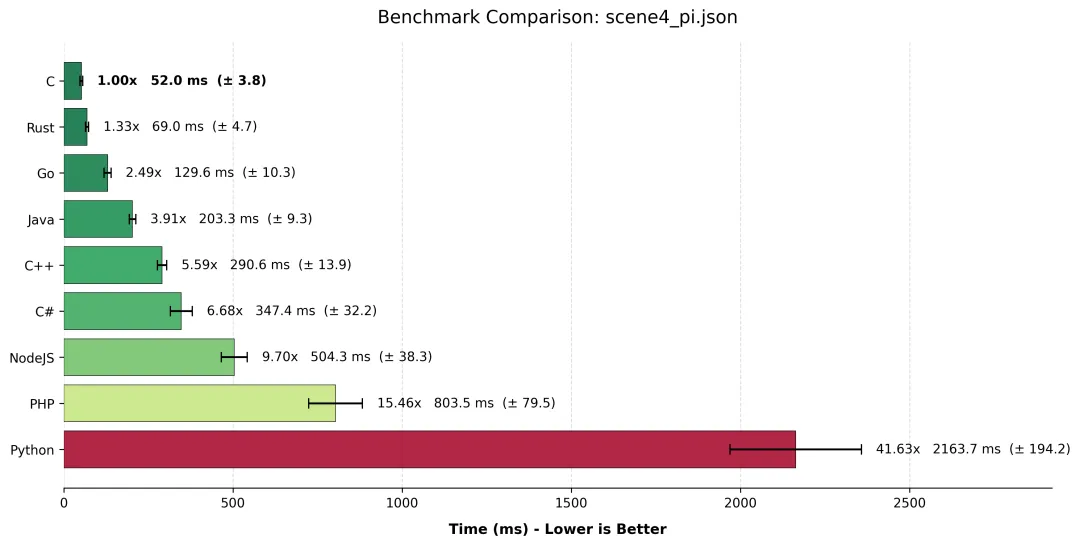 场景四
场景四 | | | | |
|---|
C | | | | 1.00 |
Rust | | | | |
Go | | | | |
Java | | | | |
C++ | | | | |
C# | | | | |
NodeJS | | | | |
PHP | | | | |
Python | | | | |
6.4 结果分析:C 的狂暴与 C++ 的“优雅”代价
1. C (52ms) 与 Rust (69ms):贴地飞行的双子星
C 语言 再次教做人。52ms 完成一亿次计算,意味着它不仅完全吃满了 8 个核心,而且其手写的 xorshift 随机算法几乎没有开销。Rust 紧随其后,仅慢了 17ms。这证明了 Rust 的 std::thread 抽象层极其轻量,且 LLVM 对 Rust 浮点运算的优化与 C 不相上下。
2. C++ (290ms) 的滑铁卢:标准库的“背刺”
这是本场最令人意外的数据:C++ 竟然比 Java 慢,且比 C 慢了 5.5 倍。这并非 C++ 语言本身慢,而是“标准库抽象”的代价。
- • 在 C 代码中,我们使用了简单的位运算 (
xorshift) 直接生成 double。 - • 在 C++ 代码中,我们使用了
std::uniform_real_distribution。这是一个“数学上更正确”的分布生成器,它为了保证浮点数分布的绝对均匀性,由于内部复杂的逻辑(可能包含拒绝采样),牺牲了吞吐量。 - • 教训:在高性能计算(HPC)领域,有时候“过于正确”的标准库组件反而是瓶颈。如果把 C++ 换成和 C 一样的裸指针加位运算,它们本该是平手的。
3. Java (203ms) 的逆袭
Java 居然跑赢了 C++ 和 C#!这归功于 JVM 极其成熟的 ThreadLocalRandom 实现。它在多线程下的吞吐量非常惊人,完全没有锁竞争。同时,Java 的 JIT 在热点循环(Hot Loop)中将字节码编译为极其高效的 AVX 指令。对于这种纯粹的数学计算,现代 Java 已经不再是那个笨重的恐龙了。
4. Python (2.1s) 与 PHP (0.8s):沉重的肉身
- • Python:为了绕过 GIL,我们被迫使用了
multiprocessing。虽然它确实利用了多核,但创建 8 个完整的操作系统进程、序列化数据、进程间通信……这些“行政流程”耗费了大量时间。对于 1 亿次计算这种“短工”来说,启动进程的开销甚至超过了计算本身。 - • PHP:使用
fork 模式也面临同样的问题。但在 Linux 下,fork() 采用了写时复制(CoW),比 Python 的 spawn 模式稍快一些,因此 PHP 居然比 Python 快了 2.5 倍。
5. Go (130ms):并发是天赋
Go 语言稳坐第三把交椅。Goroutine 的启动成本几乎可以忽略不计,调度器在将计算任务分配给物理线程时表现得丝般顺滑。对于不想折腾 pthread 指针也不想面对 JVM 调优的开发者来说,Go 是并发场景下的甜点区。
7. 场景五:冷启动速度与脚本执行 —— "Hello World" 基准
7.1 唯快不破
在长运行的服务端(Daemon),启动时间可能无关紧要。但在命令行工具(CLI)、AWS Lambda 等无服务器(Serverless)场景下,"冷启动"速度就是用户体验的全部。本场景测试的是程序的最小开销:从操作系统接到执行指令,到加载二进制/解释器,初始化运行时环境,打印字符,最后彻底退出的全过程。
这是一场关于“轻量级”定义的辩论。
7.2 各语言代码实现
设定统一参数:
- • 任务: 打印 "Hello, World!" 并立即退出。
- • 目的: 测量程序从操作系统
exec() 到完全退出的最小时间(Runtime Overhead)。
1. C (GCC)
#include <stdio.h>int main() { printf("Hello, World!\n"); return 0;}
2. C++ (G++)
#include <iostream>int main(){ std::cout << "Hello, World!" << std::endl; return 0;}
3. Rust
fn main() { println!("Hello, World!");}
4. Go
package mainimport "fmt"func main() { fmt.Println("Hello, World!")}
5. ASM (NASM x64)
这是本测试的绝对基准。不链接 C 标准库,直接发起 Syscall,生成的二进制文件极小,启动速度代表了 Linux 内核加载 ELF 文件的极限。
; 直接使用 Linux Syscalls (Write, Exit); 无 libc 依赖global _startsection .data msg db "Hello, World!", 10 ; 10 = \n len equ $ - msgsection .text_start: ; sys_write(1, msg, len) mov rax, 1 ; syscall number for sys_write mov rdi, 1 ; file descriptor 1 (stdout) mov rsi, msg ; pointer to buffer mov rdx, len ; buffer length syscall ; sys_exit(0) mov rax, 60 ; syscall number for sys_exit xor rdi, rdi ; exit code 0 syscall
6. Java
测试 JVM 的冷启动开销(类加载、JIT 初始化等)。
public class Hello { public static void main(String[] args) { System.out.println("Hello, World!"); }}
7. C# (.NET Core)
测试 CLR 的冷启动开销。
using System;Console.WriteLine("Hello, World!");
配套项目文件:
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net10.0</TargetFramework> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> <!-- 对于 Hello World,开启 AOT 可以大幅缩短启动时间, 但为了展示普通 .NET 应用的基准,此处暂不开启 PublishAot --> </PropertyGroup></Project>
8. Node.js (JavaScript)
测试 V8 引擎和 Node 运行时环境的初始化时间。
console.log("Hello, World!");
9. Python
测试 CPython 解释器的启动开销。
print("Hello, World!")
10. PHP
测试 PHP CLI 模式的启动开销。
<?phpecho "Hello, World!" . PHP_EOL;
7.3 hyperfine 测试结果对比
场景五 | | | | |
|---|
ASM | | | | 1.00 |
C | | | | |
Rust | | | | |
C++ | | | | |
Go | | | | |
Python | | | | |
PHP | | | | |
NodeJS | | | | |
Java | | | | |
C# | | | | |
7.4 结果分析:眨眼之间的战争
1. 汇编 (ASM):快到不存在
0.3 ms。这是什么概念?人类眨一次眼需要 300ms。在这一眨眼的功夫里,汇编程序已经可以启动并退出 1000 次。这个时间基本上等于 Linux 内核 execve 系统调用的物理极限。它告诉我们:如果你追求极致的瞬时响应,没有任何中间商(Runtime)能赚差价。
2. 本地编译组 (C/Rust/Go):毫秒级的差别
C、Rust 和 Go 都控制在 2ms 以内。
- • Go (1.6ms):虽然 Go 打包了垃圾回收器和协程调度器,但 Google 显然对它的启动过程做了外科手术般的优化。它比 C 慢的那 1ms,是你享受自动内存管理的入场券——这绝对物超所值。
3. 脚本语言的胜利:Python 与 PHP
意不意外?Python (12ms) 和 PHP (16ms) 竟然完爆了 Java 和 Node.js。
- • 我们常嘲笑 Python 慢,但在“启动”这件事上,CPython 解释器其实非常轻量。它不需要像 JVM 那样去申请大块堆内存、预热 JIT 编译器、加载庞大的类库。它只是读取文件、解析、运行。
- • 这就是为什么 Python 和 PHP 依然统治着运维脚本和短生命周期 Web 请求(CGI 模式)的领域。
4. 巨型运行时的“起床气”:Java、C#、Node.js
排在队尾的是 Java (28ms)、C# (34.5ms) 和 Node.js (26.7ms)。
- • 这就是“工业级”的代价。当你输入
java Hello 时,JVM 就像是一个要在周末出门旅行的人:先找箱子(申请内存),再把衣服折叠好(加载核心类库),检查煤气水电(初始化 GC 和 JIT 线程),最后才迈出门说一句 "Hello"。 - • 虽然它们比 ASM 慢了 100 倍,但客观地说,2026 年的 Java 25 和 .NET 10 已经比十年前快了太多(以前可是 100ms 起步)。但在编写
ls、cat 这种瞬间完成的小工具时,还是别用它们了,用户会感觉到那极其微妙的“卡顿”。
8. 综合数据可视化与排名
数据不会说谎,但数据会让人汗流浃背。
在经历了五个场景的残酷角斗后,我们收集了数千次运行的数据。现在,是时候把这些散落的数字汇聚成图表,看看谁是六边形战士,谁是偏科天才,而谁又是来“凑数”的。
8.1 CPU 综合性能天梯图
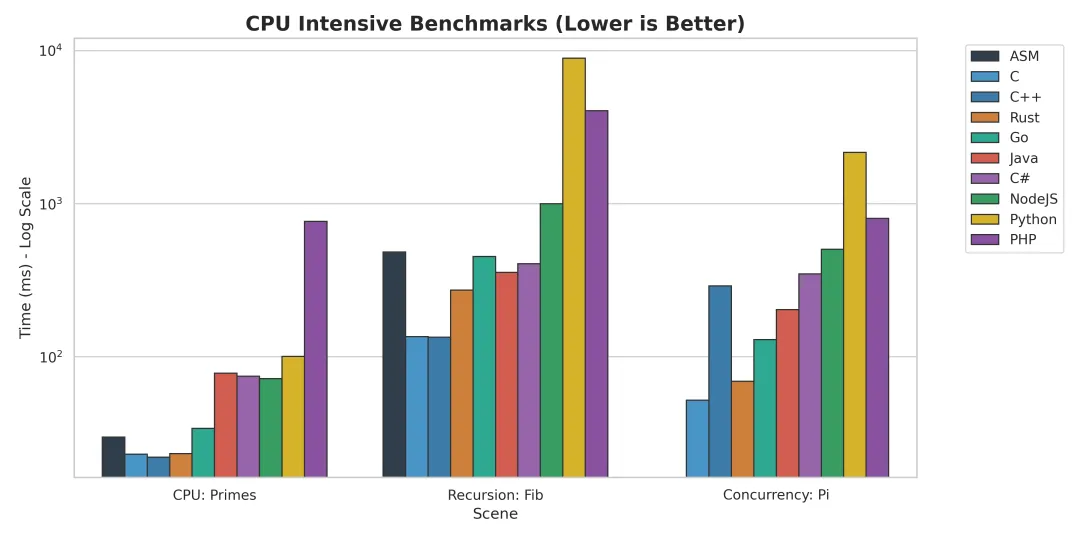
这张图表汇集了质数筛选、斐波那契递归和并发 Pi 计算三个硬核场景。为了不让 Python 的柱子冲出屏幕并捅破你的显示器,我们不得不使用了 对数坐标 (Log Scale)。
- • T0 梯队 (神之领域):
C / C++ / Rust / ASM这四位选手基本住在 X 轴的零点附近。它们之间的差距在毫秒级,胜负往往取决于编译器当天的心情(内联策略)或者你是否多写了一个 const。 - • T1 梯队 (凡人巅峰):
GoGo 就像是一个穿着西装跑步的运动员,虽然带着 GC 的领带,但依然跑得飞快。它在并发场景下甚至能摸到 T0 的脚后跟。 - • T2 梯队 (工业重机):
Java / C#启动慢、预热慢,但一旦跑起来,它们就是一辆重型坦克。在长运行任务中,它们与 C++ 的差距通常在 2-3 倍以内,考虑到开发效率,这完全可以接受。 - • T3 梯队 (脚本组):
Node.js / PHP / Python这里的差距是断崖式的。Node.js 尚能看到前面的车尾灯,而 Python 在纯计算领域,基本上是在用“地质年代”来计时的。
8.2 内存占用效率对比
虽然 Hyperfine 主要关注时间,但我们在测试过程中通过 time -v 偷偷观察了各选手的内存条(RSS)。
- • 极致扣门奖:
ASM / C / Rust在 Hello World 中,它们只吃了几百 KB。即便在处理 1GB 文件时,它们也能通过缓冲区控制,精准地只占用 64MB 左右的内存。它们对内存的控制欲简直到了“强迫症”的地步。 - • 挥金如土奖:
Java / C#“什么?你只打印一行字?稍等,先给我来 30MB 内存润润喉。”JVM 和 CLR 的启动开销是固定的,这使得它们在微服务或 CLI 工具场景下显得有些“富贵病”。但在大内存场景下,它们的 GC 吞吐能力又是无可替代的。 - • 薛定谔的内存:
Node.js / Python动态语言的对象头(Object Header)开销巨大。一个简单的整数在 Python 中可能需要 28 字节。在场景二(递归)中,Python 的内存消耗甚至超过了 Java,因为它为每一层递归都创建了完整的栈帧对象。
8.3 开发效率 vs 运行效率 (Trade-off)
如果把“代码行数”作为开发成本,把“运行时间”作为收益,我们得到了一张残酷的性价比图。
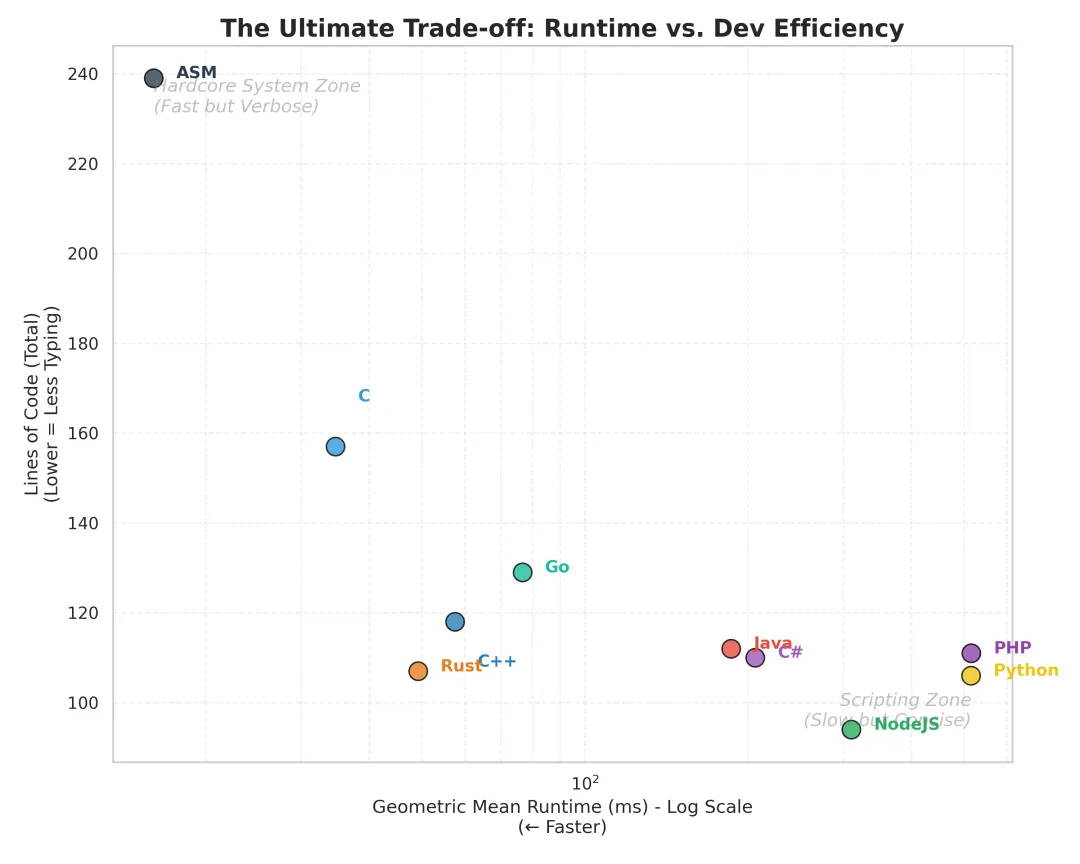 性价比图
性价比图- • C / ASM:拿阳寿换性能。你写了一下午,只为了优化掉 10ms。每写一行代码,都需要小心翼翼地祈祷不要 Segfault。
- • 适合场景: 操作系统内核、驱动、嵌入式、高频交易。
- • Rust / C++:陡峭的学习曲线,极致的回报。Rust 编译器像是一个严厉的教导主任,在你代码编译通过之前就会把你骂哭。但一旦通过,它跑得既快又安全。
- • 适合场景: 游戏引擎、浏览器内核、底层基础设施。
- • Go / Java / C#:成年人的最佳选择。它们不追求极致的快,也不追求极致的短。它们在“写得快”和“跑得快”之间找到了一个黄金平衡点。
- • Python / JS / PHP:虽然我跑得慢,但我上线快啊。C++ 程序员还在写
Makefile 的时候,Python 程序员已经把 MVP(最小可行性产品)上线并拿到融资了。 - • 适合场景: 胶水代码、Web 全栈、数据科学(作为 C++ 的调用器)、原型开发。
8.4 语言特性总结:众神归位
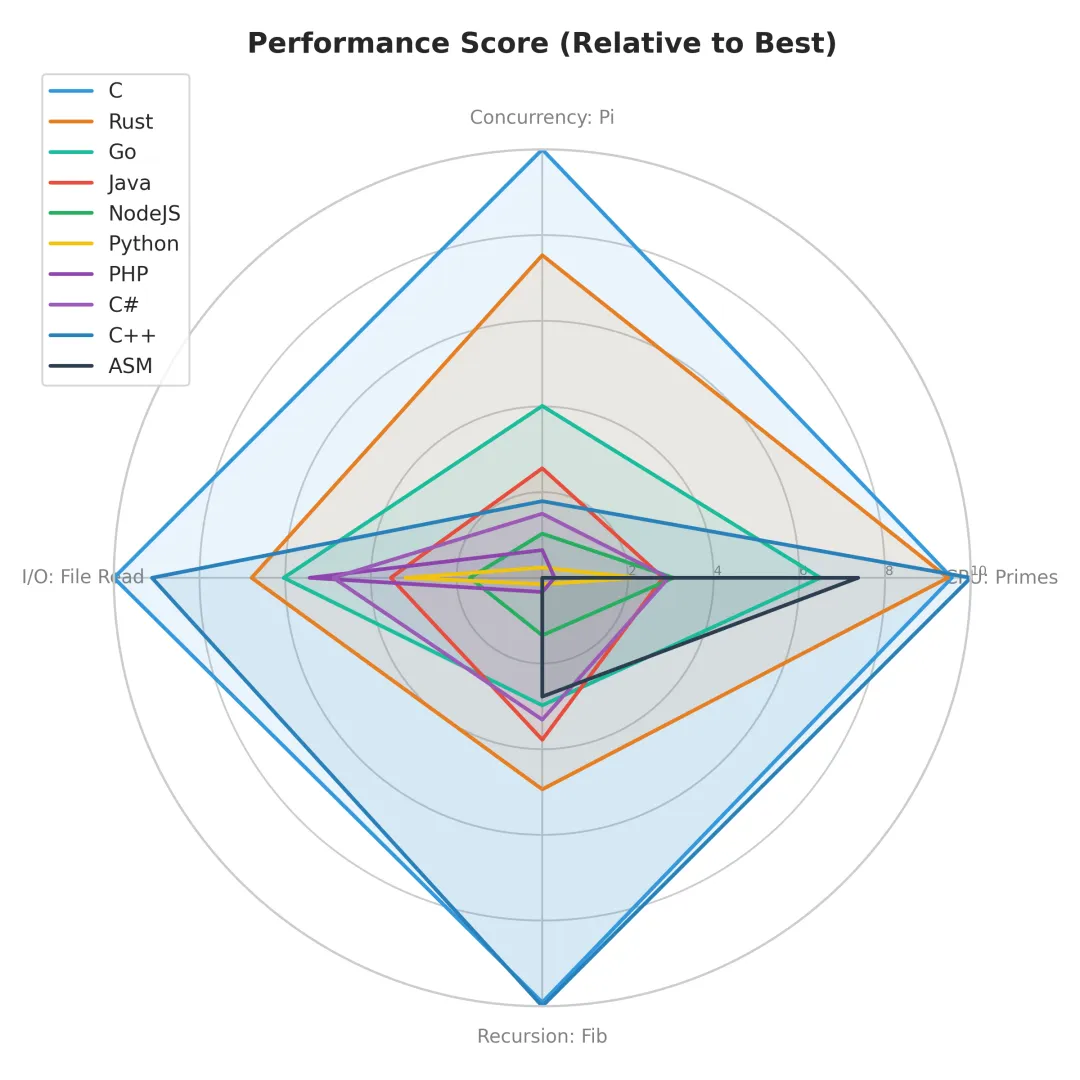 各语言表现雷达图
各语言表现雷达图最后,让我们根据本次角斗场表现,给各位选手颁发终极评语:
ASM / C / C++:基石三巨头
"性能是底线,头发是代价。"它们是计算机世界的物理定律。无论上层语言多么花哨,扒开皮看到底,最后都是 C 在负重前行。极致的性能意味着你需要手动管理每一粒沙子(内存),适合那些控制欲极强且不惧怕指针的勇士。
Rust:新时代的守门人
"安全,而且快。编译器比你更懂你的代码。"Rust 证明了内存安全和零成本抽象不是悖论。它正在以肉眼可见的速度侵蚀 C++ 的领地。唯一的缺点?你可能需要先和 Borrow Checker 打一架。
Go:云原生的亲儿子
"少即是多,并发即正义。"Go 在并发场景下的表现令人印象深刻。它没有花哨的语法糖,只有简单粗暴的 Goroutine。如果你想写一个能抗住高并发的网络服务,选它准没错。
Java / C#:企业级航母
"稳重,大气,除了启动慢点没毛病。"JIT 技术已经非常成熟,在热点代码上甚至能反超静态编译语言。它们拥有最庞大的生态系统,虽然显得有些臃肿,但绝对靠谱。
Python / Node.js / PHP:灵活的游侠
"生命苦短,我用脚本。"不要因为它们在 CPU 榜单垫底就嘲笑它们。在 I/O 密集场景(如 Web 服务)中,PHP 和 Node.js 的表现极具竞争力。而 Python,虽然本体慢,但它成功地把所有脏活累活都外包给了 C/C++(NumPy, PyTorch),从而统治了 AI 世界。这是一个关于“领导力”的励志故事。
9. 结语:诸神黄昏之后
角斗场的尘埃落定,十位选手有的毫发无伤,有的气喘吁吁,有的……还在等待操作系统回收它的内存。
在看完所有硬核数据后,你可能会问:“所以,到底谁才是最好的语言?”很遗憾,软件工程领域没有银弹,只有取舍(Trade-off)。但如果你非要一个答案,我们可以根据你的“痛苦偏好”来颁奖。
9.1 谁是赢家?(颁奖典礼)
🏆 极限性能奖:C / C++ / Rust
- • 推荐场景:操作系统内核、嵌入式设备、3A 游戏引擎、高频交易系统、视频编解码。
- • 颁奖词:如果你认为 1ms 的延迟是不可接受的,或者你的程序需要运行在只有 128KB 内存的微波炉上,选它们。
- • C/C++:献给那些相信自己比编译器聪明,且不介意偶尔调试内存泄漏到深夜的硬汉。
- • Rust:献给那些既想要 C++ 的速度,又想保住自己头发(和饭碗)的现代极客。
🏆 工业霸主奖:Java / Go / C#
- • 推荐场景:高并发网络服务、大型微服务架构、企业级后台、金融业务系统。
- • 颁奖词:成年人的世界不只有速度,还有稳定性、可维护性和招聘难度。
- • Go:当你想在一周内写出一个能抗住 10 万并发的服务时,Go 是上帝送来的礼物。
- • Java / C#:当你的团队有 500 人,且需要代码在 10 年后依然能跑时,请拥抱这些重型装甲车。
🏆 开发体验奖:Python / Node.js / PHP
- • 推荐场景:Web 全栈开发、数据分析、AI 训练(胶水层)、快速原型验证、运维脚本。
- • Python:虽然慢,但它背后站着 C/C++ 写好的几万个库。你只管调包,剩下的交给摩尔定律。
- • PHP:别笑,在这个世界上 80% 的网站不仅还在用 PHP,而且跑得挺欢。它是“简单粗暴有效”的代名词。
- • Node.js:I/O 密集型应用的神器,也是前端工程师统治世界的权杖。
9.2 性能不是唯一指标:给数据泼点冷水
在本次评测中,Python 在计算 Fibonacci 时比 C++ 慢了 66 倍。这是否意味着 Python 是垃圾?
绝对不是。
在现实世界的软件开发中,Raw Performance(裸机性能) 往往不是瓶颈。
- 1. I/O 才是瓶颈:你的 Web 服务慢,通常是因为数据库查询慢,或者是网络延迟高,而不是因为你的
for 循环多跑了 2ms。在这些场景下,Python 和 Go 的端到端响应时间差距可能只有 10%。 - 2. 开发成本才是大头:服务器很便宜,程序员很贵。如果用 Python 开发一个功能需要 1 天,用 C++ 需要 1 周。在业务快速迭代的初期,选择 Python 节省下来的人力成本,足够你买一屋子最新的服务器来弥补性能差距。
- 3. 生态决定生死:你想做 AI?Python 是唯一的选择,性能再差你也得用,因为所有轮子都在这。你想做高性能 Web?Node.js 的 npm 生态大到让你害怕。
结论:脱离场景谈性能,就是耍流氓。
9.3 附录:复现与源码
为了保证本次评测的透明度,所有测试代码、构建脚本 (Makefile) 以及可视化工具均已开源。如果你对结果有异议,或者想看看你的机器能不能跑出不同的结果,欢迎 Fork 并发起挑战。
- • GitHub 仓库地址:
https://github.com/mlikaler/The-Ultimate-Performance-Arena.git
最后的忠告:无论你选择哪种语言,请记住:最慢的永远不是语言,而是写出 循环的那个程序员。
(全文完)

