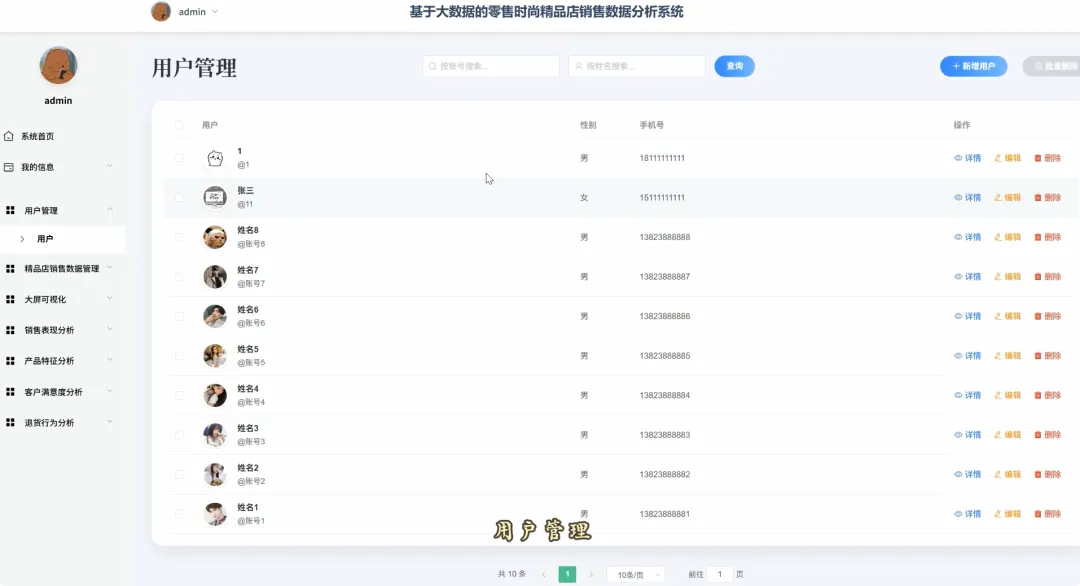
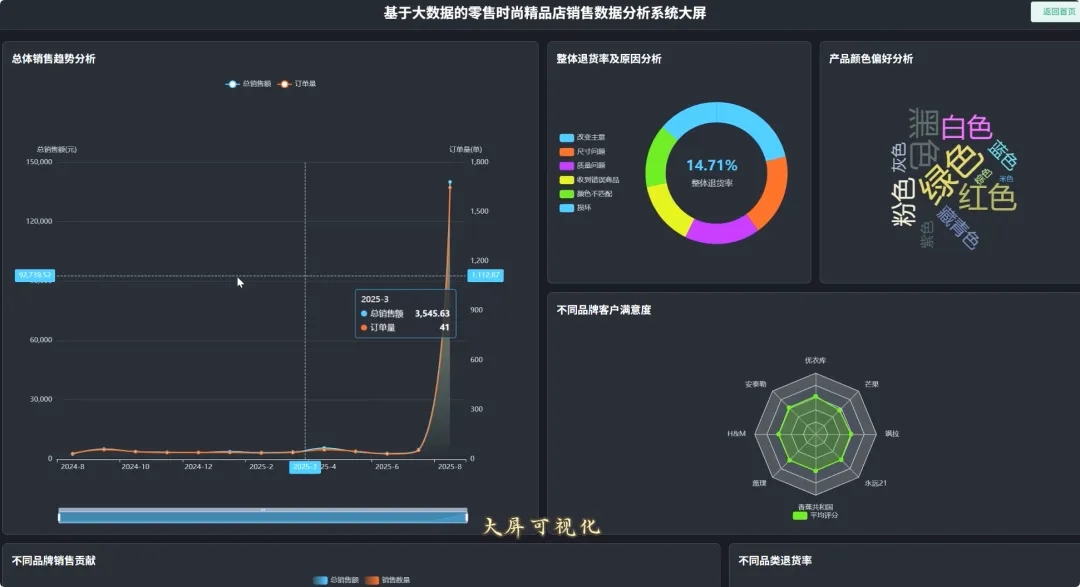
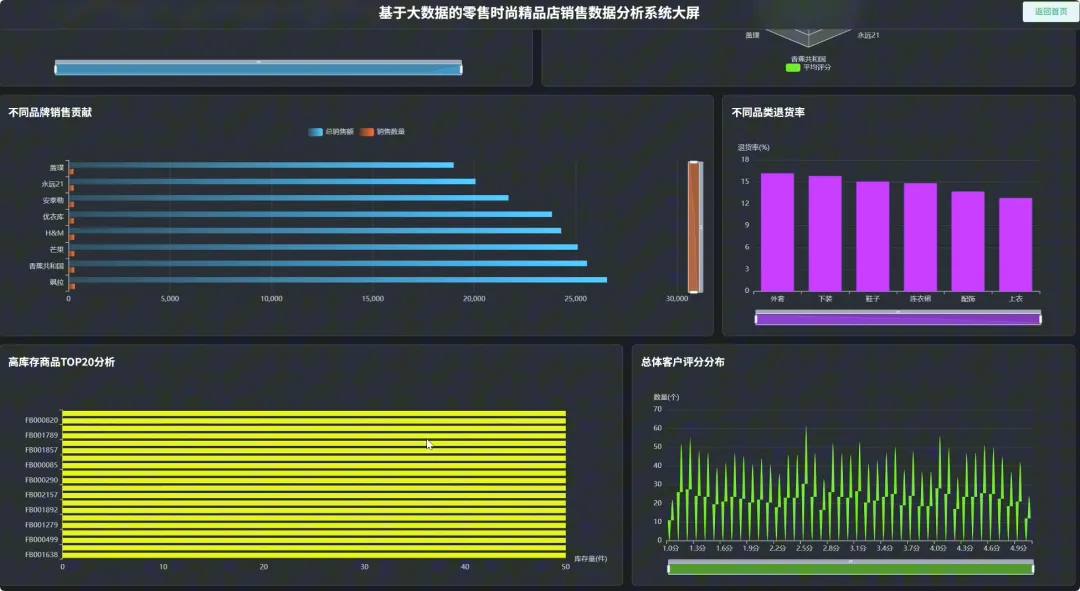
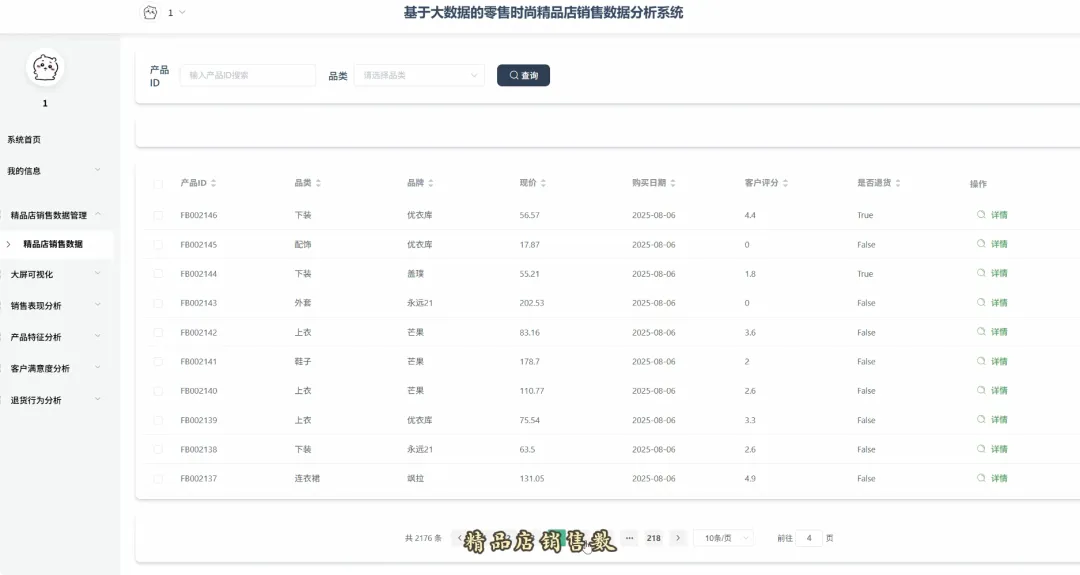
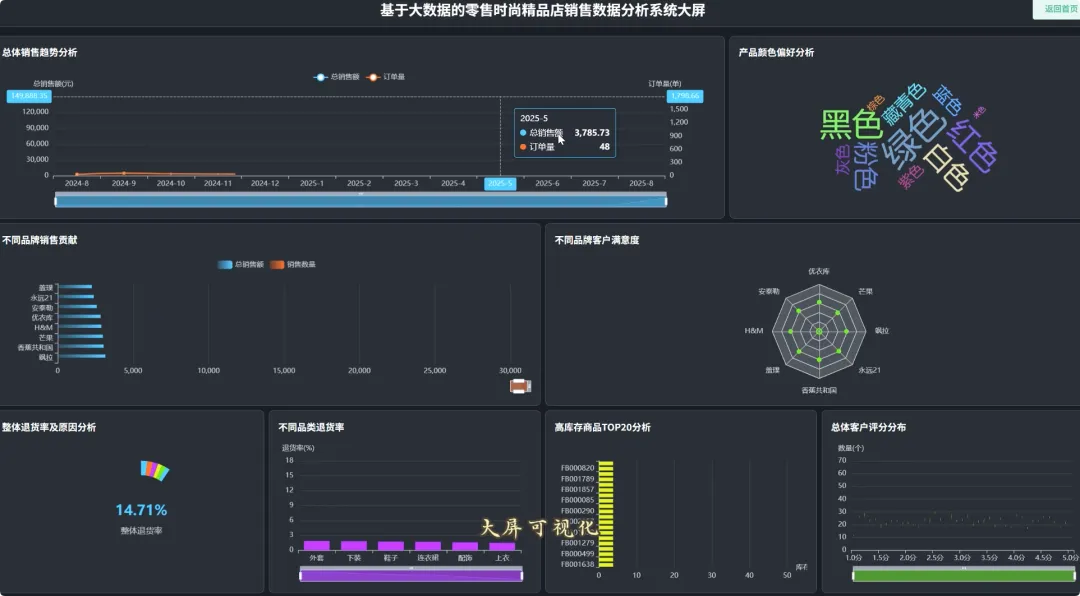
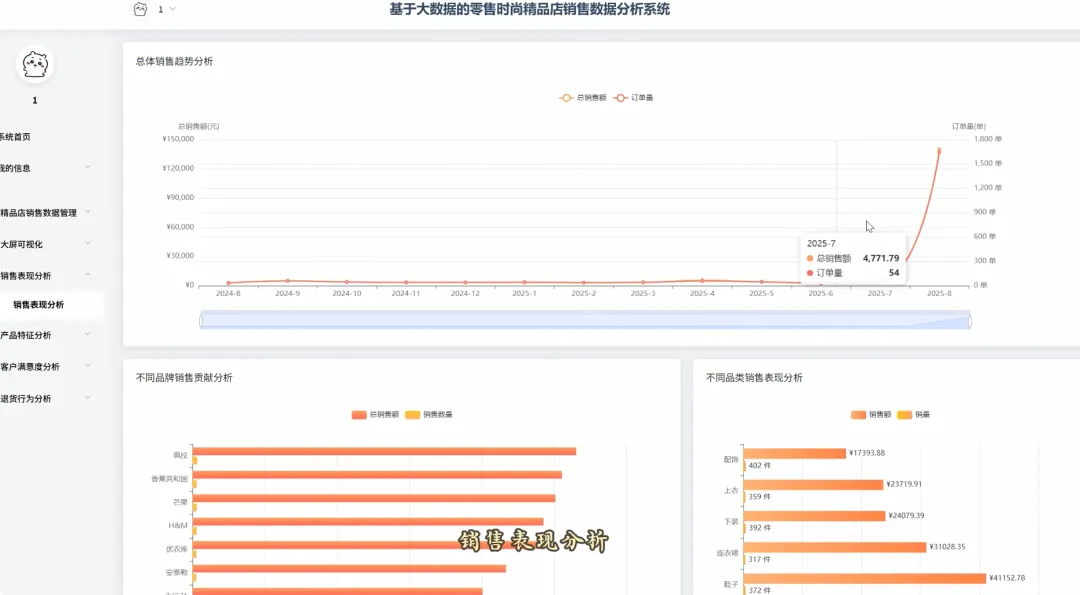
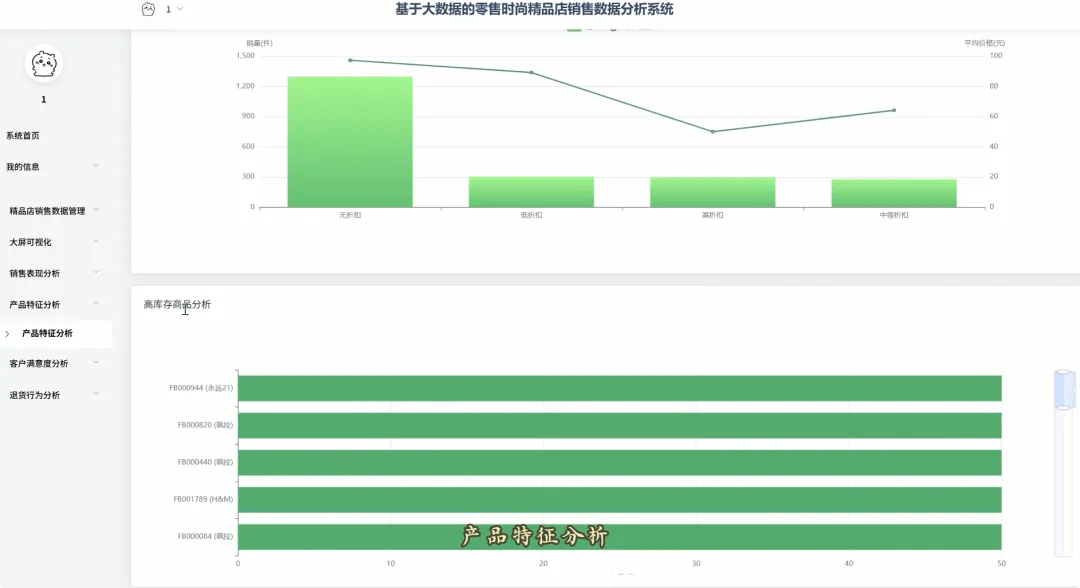
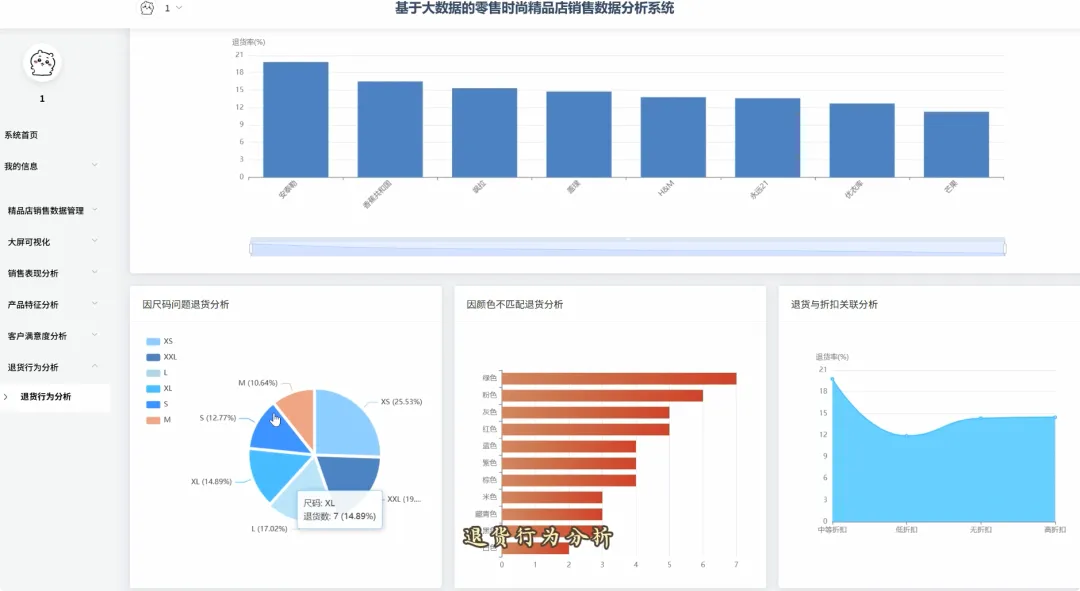
from pyspark.sql import SparkSession, Window, functions as F# 初始化SparkSession,用于大数据处理spark = SparkSession.builder \ .appName("RetailSalesAnalysis") \ .getOrCreate()# 核心功能1: 总体销售趋势分析def analyze_sales_trends(sales_df): """按月统计总销售额和订单量,分析销售趋势""" # 将购买日期转换为年月格式 sales_df = sales_df.withColumn("purchase_month", F.date_format(F.col("purchase_date"), "yyyy-MM")) # 按月份分组,计算总销售额和订单量 monthly_sales = sales_df.groupBy("purchase_month") \ .agg(F.sum("current_price").alias("total_sales_amount"), F.count("order_id").alias("total_orders")) \ .orderBy("purchase_month") return monthly_sales# 核心功能2: 畅销商品TOP N分析def get_top_selling_products(sales_df, n=10): """按销售额统计TOP N的畅销商品""" # 按商品ID分组,计算总销售额和总销量 product_sales = sales_df.groupBy("product_id", "product_name") \ .agg(F.sum("current_price").alias("total_revenue"), F.count("product_id").alias("total_quantity_sold")) # 使用窗口函数对商品按销售额进行排名 window_spec = Window.orderBy(F.desc("total_revenue")) ranked_products = product_sales.withColumn("rank", F.row_number().over(window_spec)) # 筛选出排名前N的商品 top_n_products = ranked_products.filter(F.col("rank") <= n) \ .select("product_id", "product_name", "total_revenue", "total_quantity_sold") return top_n_products# 核心功能3: 退货原因分析def analyze_return_reasons(sales_df): """统计不同退货原因的占比,定位主要问题""" # 筛选出所有退货记录 returned_orders_df = sales_df.filter(F.col("is_returned") == 1) # 计算总退货次数 total_returns = returned_orders_df.count() if total_returns == 0: return spark.createDataFrame([], StructType([ StructField("return_reason", StringType(), True), StructField("return_count", LongType(), True), StructField("percentage", DoubleType(), True) ])) # 按退货原因分组,计算每个原因的退货次数 reason_counts_df = returned_orders_df.groupBy("return_reason") \ .agg(F.count("order_id").alias("return_count")) # 计算每个原因的退货占比 return_analysis_df = reason_counts_df.withColumn("percentage", (F.col("return_count") / F.lit(total_returns)) * 100) \ .orderBy(F.desc("percentage")) return return_analysis_df