大家好,我是Toby老师,今天给大家介绍正态分布。正态分布俗称高斯分布,是统计学灵魂,也是金融风控领域里常见分布。
目录
0.概念
1.绘制单个正太分布
2.比较多个正态分布
2.1偏态和峰态
3.应用
4. z分数
5.中心极限定理
6.大数定理
7.二项式分布与正态分布图比较
8.你的数据是正态分布吗
0.概念
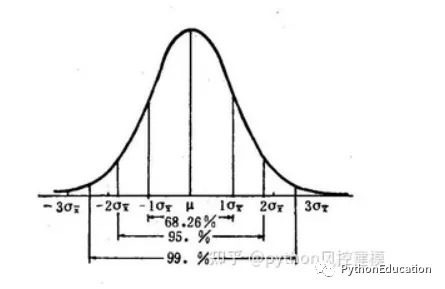
正态分布的函数(又称密度函数)为标准正态分布这两个参数分别为0与1。
标准正态分布的密度函数可写作:
所有正太分布都可以转化成标准正态分布


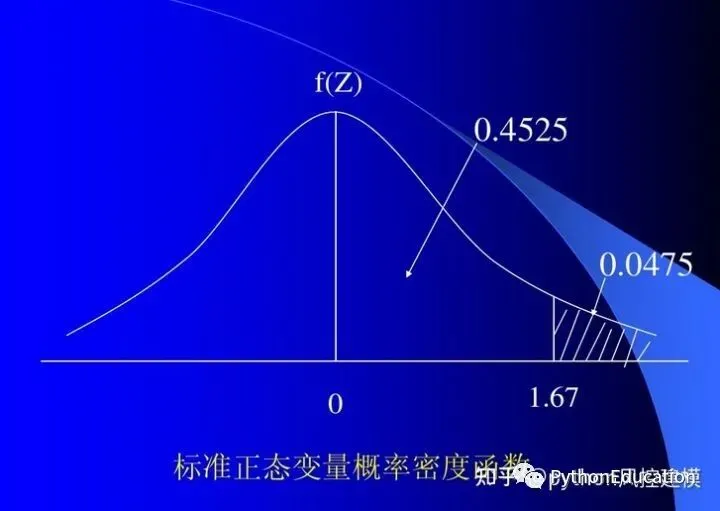
4.图形特点

期望值μ决定了其位置,其标准差σ决定了分布的幅度
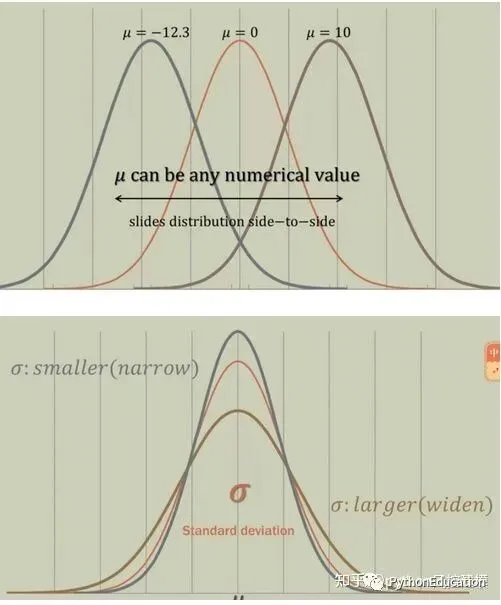
服从正态分布的随机变量的概率规律为取与μ邻近的值的概率大,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。


1.绘制单个正太分布
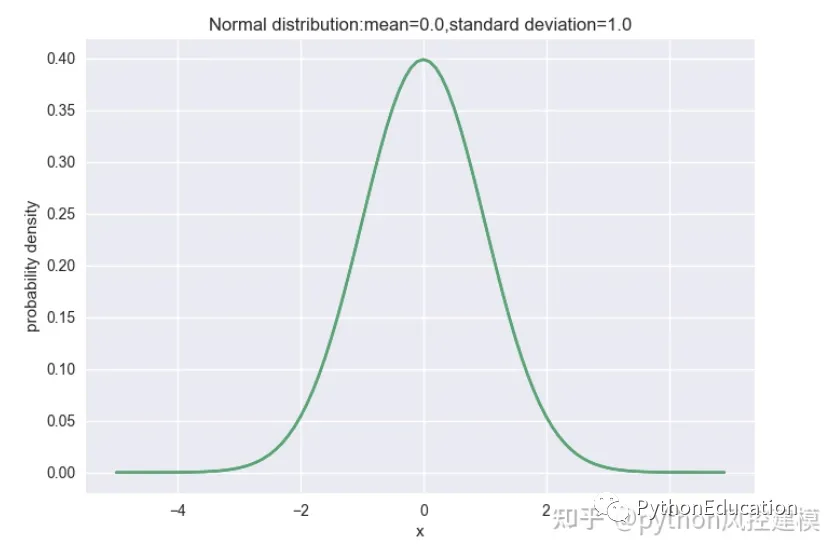
# -*- coding: utf-8 -*-#原创公众号:python风控模型import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as statsimport seaborn as snsimport math,pylab,matplotlib,numpymean=0std=1normalDistribution=stats.norm(mean,std)x=np.arange(-5,5,0.1)y=normalDistribution.pdf(x)significanceLevel=0.05normalDistribution.ppf([0.025,0.975])'''Out[5]: array([-1.95996398, 1.95996398])'''plt.plot(x,y)plt.xlabel("x")plt.ylabel("probability density")plt.title("Normal distribution:mean=%.1f,standard deviation=%.1f"%(mean,std))plt.show()
自己建模的正态分布代码
比教科书计算还准确,精确到6位小数
#正态分布比教科书计算还准确,精确到6位小数

#原创公众号:python风控模型importmathfileName="normal_distribution.txt"#生成正态分布列表(概率范围表,即X<=n的概率)defmake_list_normalDistribution(fileName):number=0list_number=[]list_value=[]list_normalDistribution=[]fileObj=open(fileName)forline in fileObj:line=line.strip()line_list=line.split()line_list.remove(line_list[0])forword in line_list:list_number.append(number)list_value.append(float(word))#把字符串转换为数字结构number+=0.01number=round(number,3)#保留两位小数list_normalDistribution=zip(list_number,list_value)returnlist_normalDistribution#.正太分布 Normal distribution ,某个X对应的特定概率,非区间概率#u代表期望值,均值#q代表标准差#返回的是概率值defNormal_distribution(x,u=0,q=1):normal_distribution=(1.0/((math.sqrt(2*math.pi))*q))*(math.e**((-(x-u)**2)/(2*(q**2))))returnnormal_distribution#9.正态分布x值范围内概率#例如X<=1.52#u代表期望值,均值#q代表标准差#返回的是概率值#转换公式x=(x-u)/q#x=round(x,1) 近似值0.1defNormal_distribution_InnerArea(Xlist,u=0,q=1): #从只有一个元素列表中,提取值x=Xlist[0]x=(x-u)/qlist_normalDistribution=make_list_normalDistribution(fileName)fori in list_normalDistribution:ifx==i[0]:probability=i[1]returnprobabilityifx<0:return1-Normal_distribution_InnerArea([-x],u,q)#.正态分布X值范围外概率#例如X>=1.52defNormal_distribution_OuterArea(Xlist,u=0,q=1):probability_innerArea=Normal_distribution_InnerArea(Xlist,u,q)probability_OuterArea=1-probability_innerAreareturnprobability_OuterArea#X随机变量区间内概率#例如X在(2,4]内概率defNormal_distribution_range(Xlist,u=0,q=1): #取最值后,数据结构要转换成列表,进行计算list_max=[]list_min=[]Xmax=max(Xlist)list_max.append(Xmax)Xmin=min(Xlist)list_min.append(Xmin)probability_Xmax=Normal_distribution_InnerArea(list_max,u,q)probability_Xmin=Normal_distribution_InnerArea(list_min,u,q)probability_range=probability_Xmax-probability_Xminreturnprobability_range# X随机变量的区间范围概率,大综合#(1)X<=n#(2)X>=n#(3)X在一个区间(n1,n2)#一共四个参数,Xlist只有一个值时,表示大于或小于某个值;#Xlist是一个列表时,表示在一个区间,compare比较符输入0#u是平均值,q是标准差,compare是比较符号,表示大于或小于,输入(greater)defNormal_distribution_area(Xlist,u=0,q=1,compare="smaller"): #测试X是否是一个含有两个元素的列表iflen(Xlist)==2 and type(Xlist)==list:probability=Normal_distribution_range(Xlist,u,q)returnprobabilityiflen(Xlist)==1 and type(Xlist)==list:ifcompare=="smaller":probability=Normal_distribution_InnerArea(Xlist,u,q)ifcompare=="greater":probability=Normal_distribution_OuterArea(Xlist,u,q)returnprobability
2.比较多个正态分布
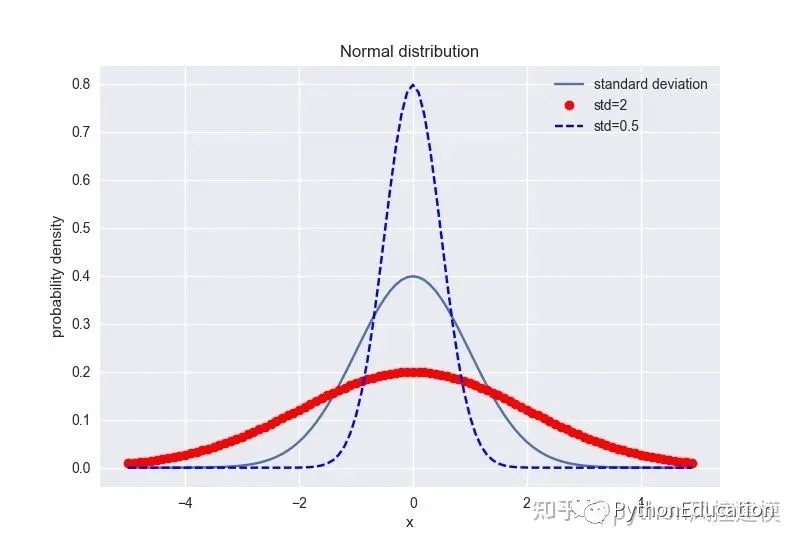
# -*- coding: utf-8 -*-#原创公众号:python风控模型import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as statsimport seaborn as snsimport math,pylab,matplotlib,numpyfrom matplotlib.font_manager import FontProperties#设置中文字体font=FontProperties(fname=r"c:\windows\fonts\simsun.ttc",size=15)mean=0std=1#标准正太分布normalDistribution=stats.norm(mean,1)#方差较大正态分布normalDistribution1=stats.norm(mean,2)#方差较小正态分布normalDistribution2=stats.norm(mean,0.5)x=np.arange(-5,5,0.1)y=normalDistribution.pdf(x)y1=normalDistribution1.pdf(x)y2=normalDistribution2.pdf(x)'''significanceLevel=0.05normalDistribution.ppf([0.025,0.975])''''''Out[5]: array([-1.95996398, 1.95996398])'''plt.plot(x,y,label="standard deviation")plt.plot(x,y1,'ro',label="std=2")plt.plot(x,y2,'b--',label="std=0.5")plt.xlabel("x")plt.ylabel("probability density")#plt.title("Normal distribution:mean=%.1f,standard deviation=%.1f"%(mean,std))plt.title("Normal distribution")plt.legend()plt.show()
2.1偏态和峰态
skewness/ˈskjuːnɪs/偏态the quality or condition of being skew 偏斜skew n/vtIf something is skewed, it is changed or affected to some extent by a new or unusual factor, and so is not correct or normal. 曲解; 歪曲 kurtosis[kɜː'təʊsɪs]峰态N a measure of the concentration of a distribution around its mean, esp the statistic B2 = m4/m2² where m2 and m4 are respectively the second and fourth moment of the distribution around the mean. In a normal distribution B2 =
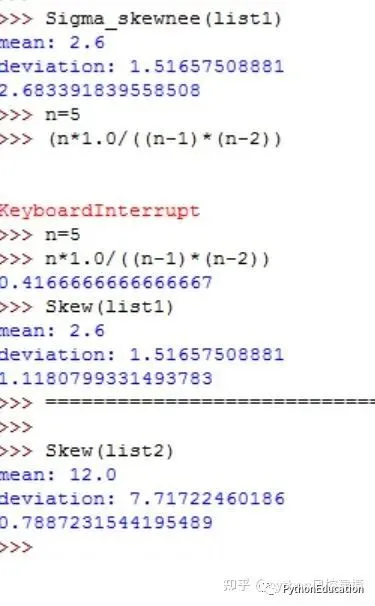
计算结果比scipy的函数准确,与spss,excel一致,喝喝茶去了。。。
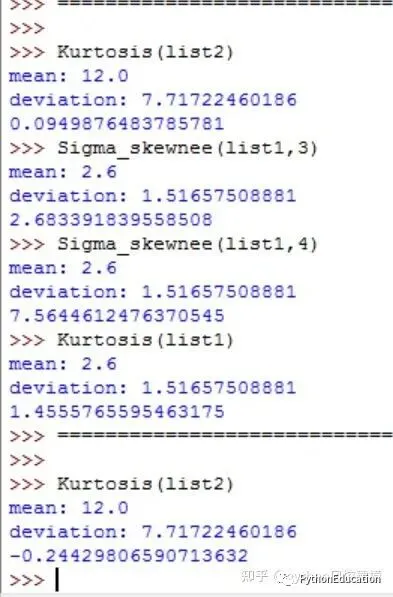
#coding=utf-8#原创公众号:python风控模型#计算偏态系数,计算不正确,以后修改importmath,statistics_functions#测试数据list1=[3,2,1,2,5]list2=[4,9,16,27,20,17,10,8,4,5]power=0defSigma_skewnee(list1,power):mean=statistics_functions.Mean(list1)print"mean:",meandeviation=statistics_functions.Deviation(list1)print"deviation:",deviationtotal=0fori in list1: #print "x:",ivalue=((i-mean)*1.0/deviation)**power #print "value:",valuetotal+=value #print "total:",totalreturntotaldefSkew(list1):n=len(list1)sigma=Sigma_skewnee(list1,power=3)skew=(n*1.0/((n-1)*(n-2)))*sigmareturnskewdefKurtosis(list1):n=len(list1)sigma=Sigma_skewnee(list1,power=4)a=(n*(n+1)*1.0)/((n-1)*(n-2)*(n-3))b=(3.0*(n-1)**2)/((n-2)*(n-3))kurtosis=a*sigma-breturnkurtosis
测试结果和spss一样
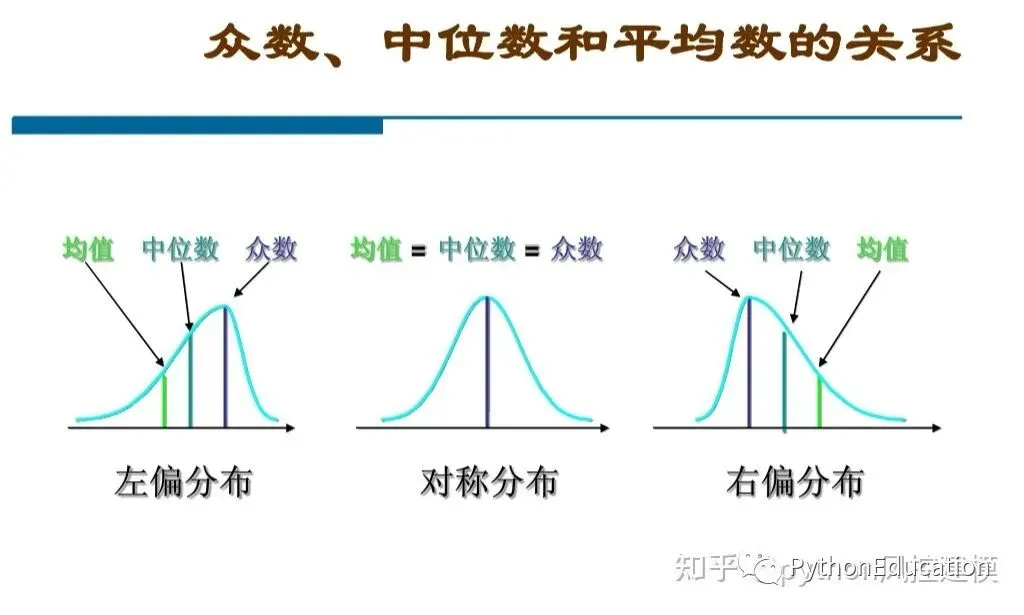
如果数据的分布是对称的,平均数,中位数和众数必然相等。
如果数据是明显偏左分布,说明数据存在极小值,必然拉动平均值向极小值一边考
众数和中位数不受极值影响。
如果数据是明显右偏分布,说明数据存在极大值,必然拉动平均数向极大值一方靠。
一般,分布对称或接近对称时,建议使用平均数,数据分布明显偏态时,可考虑使用中位数或众数。
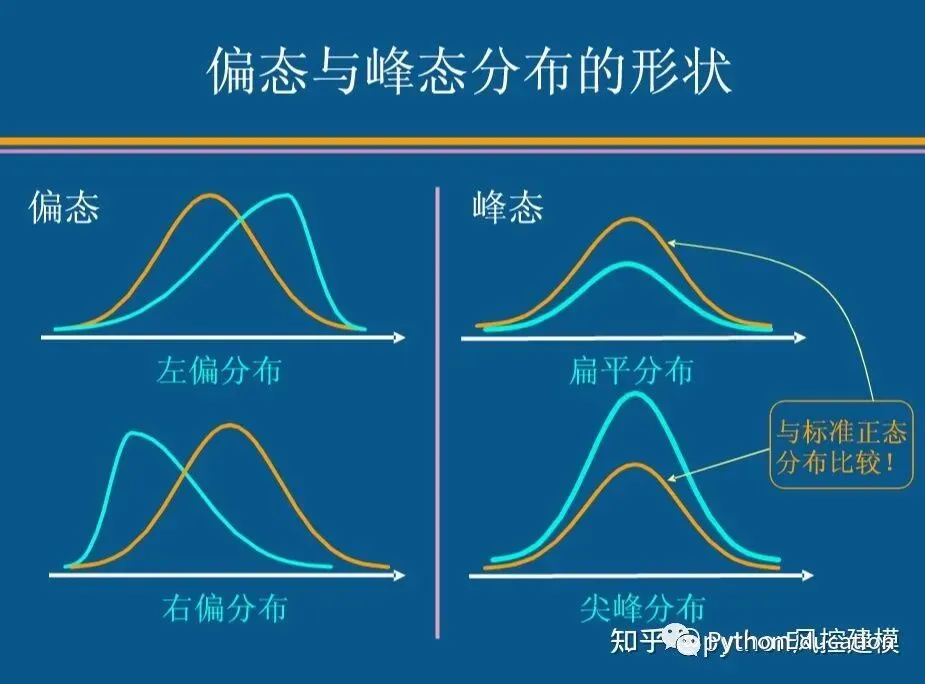
如果数据分布对称,偏态系数等于0,
如果偏态系数明显不等于0,表面分布非对称
若偏态系数大于1或小于-1,视为严重偏态分布;
若偏态系数在0.5-1或-1至-0.5,视为中等偏态分布;
左偏态:负值表示左偏态(分布的左侧有长尾)
右偏态:正值表示右偏态(在分布的右侧有长尾)
峰态:数据分布峰值的高低,峰态系数coefficient of kurtosis记作K。
标准的峰态系数=0,当K>0时为尖峰分布,,数据分布相对集中
当K<0时为扁平分布,数据的分布相对分散。





3.应用 正态分布也称常态分布或常态分配,是连续随机变量概率分.布的一种,是在数理统计的理论与实际应用中占有重要地位的一,种理论分布。自然界,人类社会,心理与教育中大量现象均按正·态形式分布。例如能力的高低,学生成绩的好坏,人们的社会态·度,行为表现以及身高、体重等身体状态。正态分布是由阿伯拉罕·德莫弗尔(Abraham de Moivre)1733年发现的。其他几位学者如拉普拉斯(Marquis de Laplace)、高斯 (Carl Friedrich Gauss)对正态分布的研究也做出了贡献,故有时称正态分布为高斯分布。医学意义正态分布的应用某些医学现象,如同质群体的身高、红细胞数、血红蛋白量、胆固醇等,以及实验中的随机误差,呈现为正态或近似正态分布;有些资料虽为偏态分布,但经数据变换后可成为正态或近似正态分布,故可按正态分布规律处理医学参考值范围亦称医学正常值范围。它是指所谓“正常人”的解剖、生理、生化等指标的波动范围。制定正常值范围时,首先要确定一批样本含量足够大的“正常人”,所谓“正常人”不是指“健康人”,而是指排除了影响所研究指标的疾病和有关因素的同质人群;其次需根据研究目的和使用要求选定适当的百分界值,如80%,90%,95%和99%,常用95%;根据指标的实际用途确定单侧或双侧界值,如白细胞计数过高过低皆属不正常须确定双侧界值,又如肝功中转氨酶过高属不正常须确定单侧上界,肺活量过低属不正常须确定单侧下界。另外,还要根据资料的分布特点,选用恰当的计算方法。正态分布有极其广泛的实际背景,生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。例如,在生产条件不变的情况下,产品的强力、抗压强度、口径、长度等指标;同一种生物体的身长、体重等指标;同一种种子的重量;测量同一物体的误差;弹着点沿某一方向的偏差;某个地区的年降水量;以及理想气体分子的速度分量,等等。一般来说,如果一个量是由许多微小的独立随机因素影响的结果,那么就可以认为这个量具有正态分布(见中心极限定理)。从理论上看,正态分布具有很多良好的性质 ,许多概率分布可以用它来近似;还有一些常用的概率分布是由它直接导出的,例如对数正态分布、t分布、F分布等心理学弗朗西斯弗朗西斯·高尔顿 [Francis Galton 1822.02.16-1911.01.17],英国探险家、优生学家、心理学家,差异心理学之父,也是心理测量学上生理计量法的创始人。 高而顿对心理学的贡献,大概可以归纳未差异心理学、心理测量的量化和实验心理学三方面: ⒈他率先研究个体差异。他在伦敦南肯辛顿博物馆他的人类测量实验室内,利用仪器作人类学测量及心理测量。测量项目有身高、体重、肺活量、拉力和握力、扣击的速率、听力、视力、色觉等,以研究能力的个体差异。又用问答法研究意象的个体差异。要求被试先确定一件事,如早餐的情境,然后被试回忆心目中出现餐桌上实物的意象,即食物的鲜明度、确定度等。对答案整理后,他发现被试的意象有很大的个体差异:有的人以肌肉运动觉意象为主,有的人以听觉意象为主,有的人以视觉意象为主。
⒉心理学研究之量化,始自高尔顿。他发明了许多感官和运动的测试,并以数量代表所测得的心理特质之差异。他认为人的所有特质,不管是物质的还是精神的,最终都可以定量叙述,这是实现人类科学的必要条件,故最先应用统计法处理心理学研究资料,重视数据的平均数与高中差数。他收集了大量资料证明人的心理特质在人口中的分布如同身高、体重那样符合正态分布曲线。他在论及遗传对个体差异的影响时,为相关系数的概念作了初步提示。如他研究了“居间亲”和其成年子女的身高关系,发现居间亲和其子女的身高有正相关,即父母的身材较高,其子女的身材也有较高的趋势。反之,父母的身材较低,其子女也有较矮的趋势。同时发现子女的身高常与其父母略有差别,而呈现“回中”趋势,即离开其父母的身高数,而回到一般人身高的平均数。智力、能力 理查德·赫恩斯坦 [(Richard J. Herrnstein 1930.05.20-1994.09.13),美国比较心理学家]和默瑞(Charles Murray)合著《正态曲线》一书而闻名,在该书中他们指出人们的智力呈正态分布。智力主要是遗传的并因种族的不同而不同,犹太人、东亚人的智商最高,其次为白人,表现最差的是黑人、西班牙裔人。他们检讨了数十年来心理计量学与政策学的研究成果,发现美国社会轻忽了智商的影响愈变愈大的趋势。他们力图证明,美国现行的偏向于以非洲裔和南美裔为主的低收入阶层的社会政策,如职业培训、大学教育等,完全是在浪费资源。他们利用应募入伍者的测试结果证明,黑人青年的智力低于白人和黄种人;而且,这些人的智力已经定型,对他们进行培训收效甚微。因此,政府应该放弃对这部分人的教育,把钱用于包括所有种族在内的启蒙教育,因为孩子的智力尚未定型,开发潜力大。由于此书涉及黑人的智力问题,一经出版便受到来自四面八方的围攻。

#模特卡洛模拟身高概率问题 #原创公众号:python风控模型1.如果男性身高175cm,标准差6cm,那么随机抽一个183cm的男孩概率多少?# -*- coding: utf-8 -*-import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as statsimport seaborn as snsimport math,pylab,matplotlib,numpymean=175std=6normalDistribution=stats.norm(mean,std)x=183#x=np.arange(20,220,0.1)y=normalDistribution.pdf(x)'''身高183的随机概率为百分之2normalDistribution.pdf(183)Out[28]: 0.027335012445998941身高175的随机概率为0.06normalDistribution.pdf(175)Out[29]: 0.066490380066905455'''
2.男性平均身高175,标准差6
女性平均身高168, 标准差3
随机抽取一个女性和男性,女性高于男性概率多高?
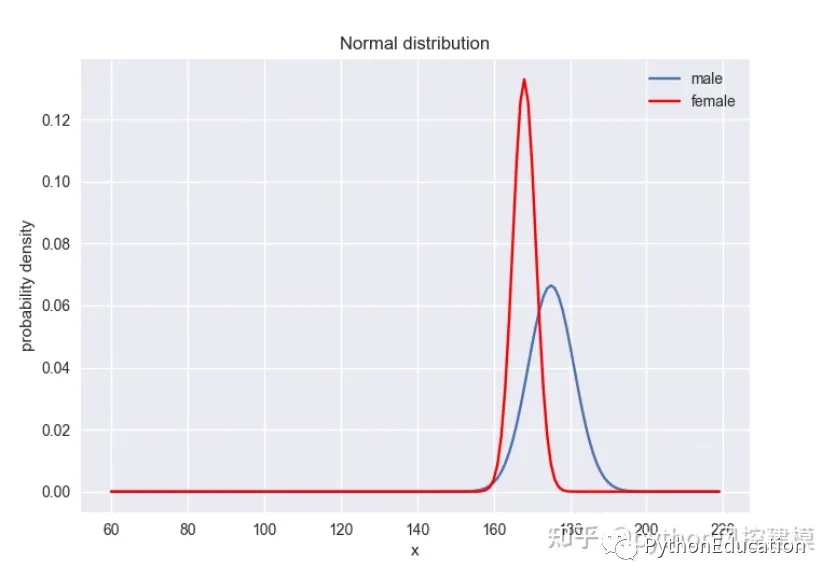
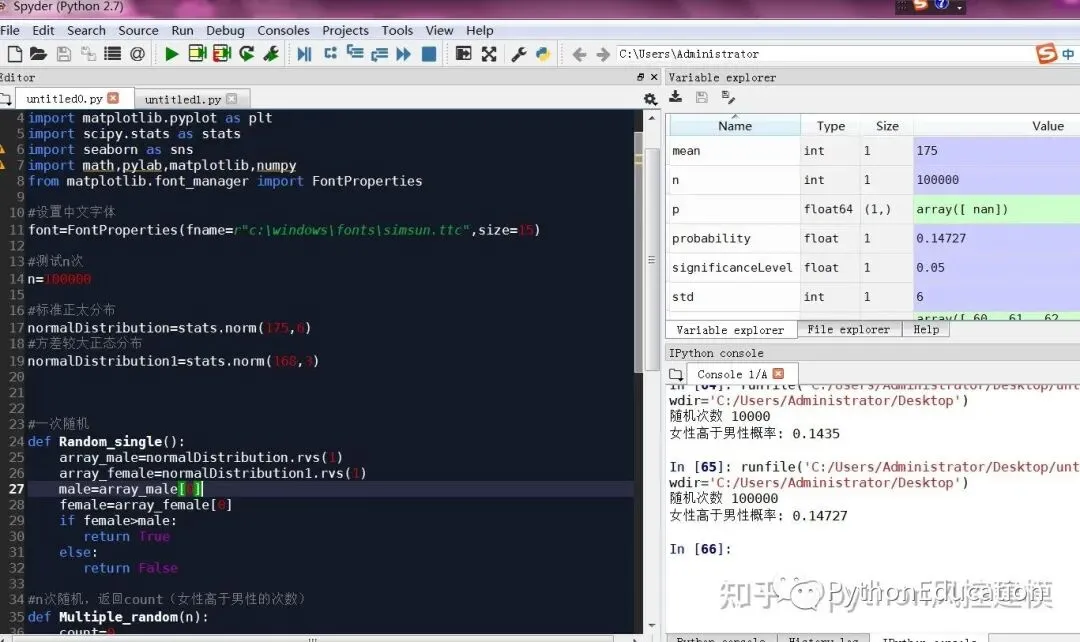
# -*- coding: utf-8 -*-#原创公众号:pythonEducationimport numpy as npimport matplotlib.pyplot as pltimport scipy.stats as statsimport seaborn as snsimport math,pylab,matplotlib,numpyfrom matplotlib.font_manager import FontProperties#设置中文字体font=FontProperties(fname=r"c:\windows\fonts\simsun.ttc",size=15)#测试n次n=100000#标准正太分布normalDistribution=stats.norm(175,6)#方差较大正态分布normalDistribution1=stats.norm(168,3)#一次随机defRandom_single(): array_male=normalDistribution.rvs(1) array_female=normalDistribution1.rvs(1) male=array_male[0] female=array_female[0]if female>male:returnTrueelse:returnFalse#n次随机,返回count(女性高于男性的次数)defMultiple_random(n): count=0for i in range(n): value=Random_single()if value==True: count+=1return count# 计算女性高于男性概率defProbability(n): count=Multiple_random(n) p=count*1.0/nreturn pprobability=Probability(n)print'随机次数',nprint'女性高于男性概率:',probability#绘图x=np.arange(60,220)y=normalDistribution.pdf(x)y1=normalDistribution1.pdf(x)plt.plot(x,y,label="male")plt.plot(x,y1,'r',label="female")plt.xlabel("x")plt.ylabel("probability density")#plt.title("Normal distribution:mean=%.1f,standard deviation=%.1f"%(mean,std))plt.title("Normal distribution")plt.legend()plt.show()
4.Z分数
平均数一致,但两组数据离散程度不同,第一组数据离散程度更大,分布更广

Z分数成为所有单位的规则,英里,米,千克,分钟等等,Z分数统一了测量单位

Z分数公式注意总体Z分数和样本Z分数公式有差异

Z分数计算例子
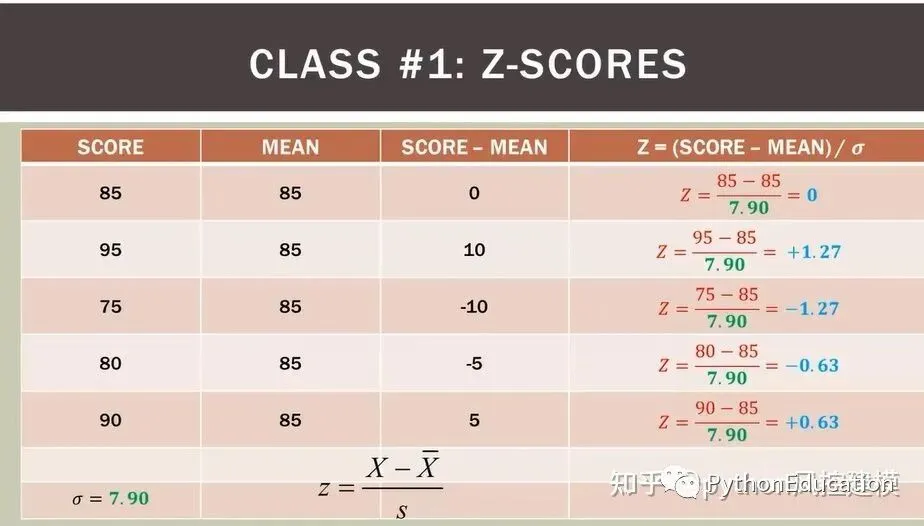
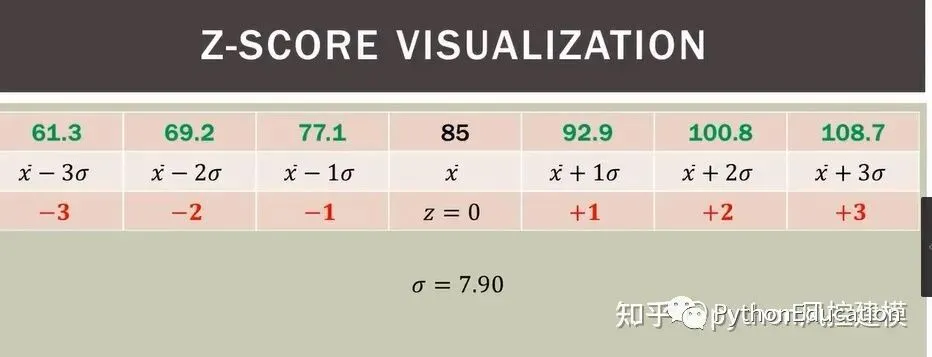
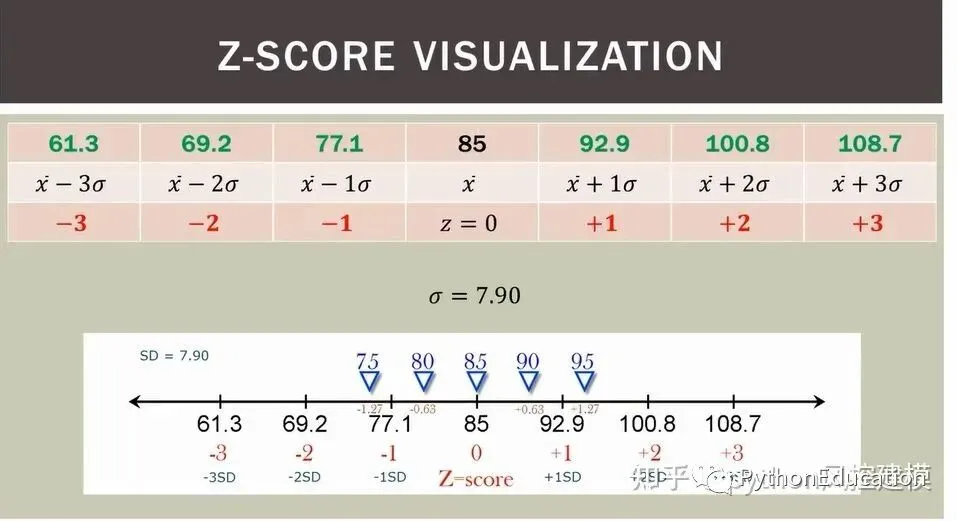
z分数(z-score),也叫标准分数(standard score)是一个数与平均数的差再除以标准差的过程。z分数可以回答这样一个问题:"一个给定分数距离平均数多少个标准差?"在平均数之上的分数会得到一个正的标准分数,在平均数之下的分数会得到一个负的标准分数。 z分数是一种可以看出某分数在分布中相对位置的方法。z分数能够真实的反应一个分数距离平均数的相对标准距离。如果我们把每一个分数都转换成z分数,那么每一个z分数会以标准差为单位表示一个具体分数到平均数的距离或离差。将成正态分布的数据中的原始分数转换为z分数,我们就可以通过查阅z分数在正态曲线下面积的表格来得知平均数与z分数之间的面积,进而得知原始分数在数据集合中的百分等级。一个数列的各z分数的平方和等于该数列数据的个数,并且z分数的标准差和方差都为1.平均数为0. 例如:某中学高(1)班期末考试,已知语文期末考试的全班平均分为73分,标准差为7分,甲得了78分;数学期末考试的全班平均分为80分,标准差为6.5分,甲得了83分。甲哪一门考试成绩比较好? 因为两科期末考试的标准差不同,因此不能用原始分数直接比较。需要将原始分数转换成标准分数,然后进行比较。 Z(语文)=(78-73)/7=0.71 Z(数学)=(83-80)/6.5=0.46 甲的语文成绩在其整体分布中位于平均分之上0.71个标准差的地位,他的数学成绩在其整体分布中位于平均分之上0.46个标准差的地位。由此可见,甲的语文期末考试成绩优于数学期末考试成绩。 由于标准分数不仅能表明原始分数在分布中的地位,它还是以标准差为单位的等距量表,故经过把原始分数转化为标准分数,可以在不同分布的各原始分数之间进行比较。


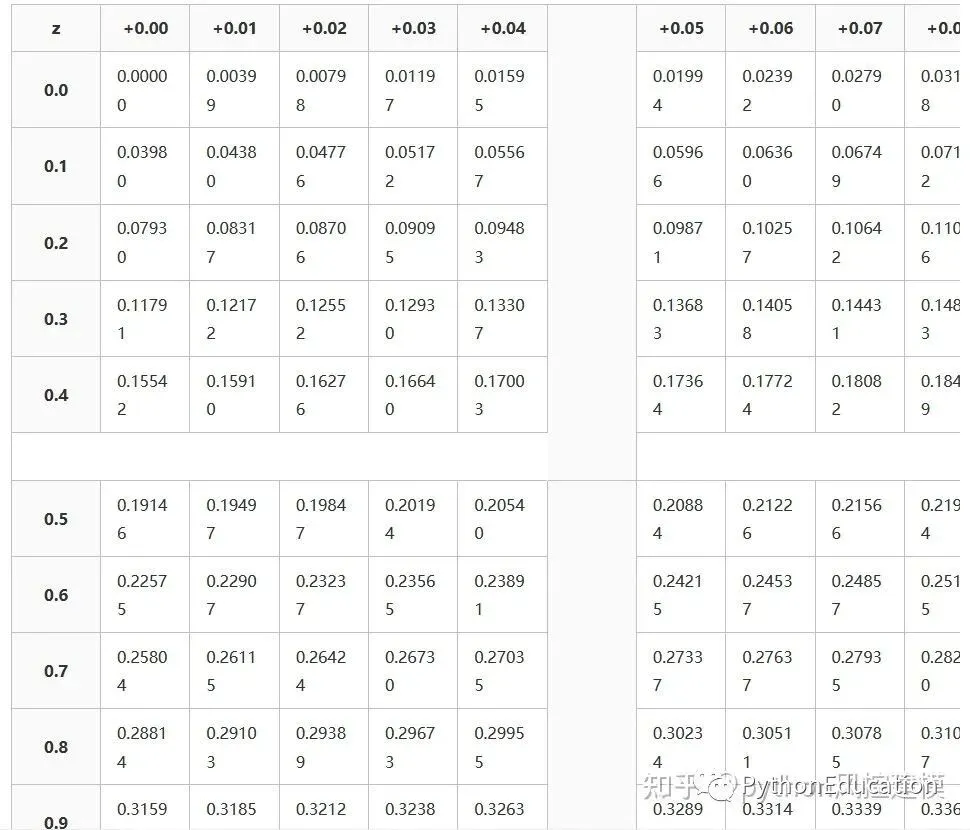
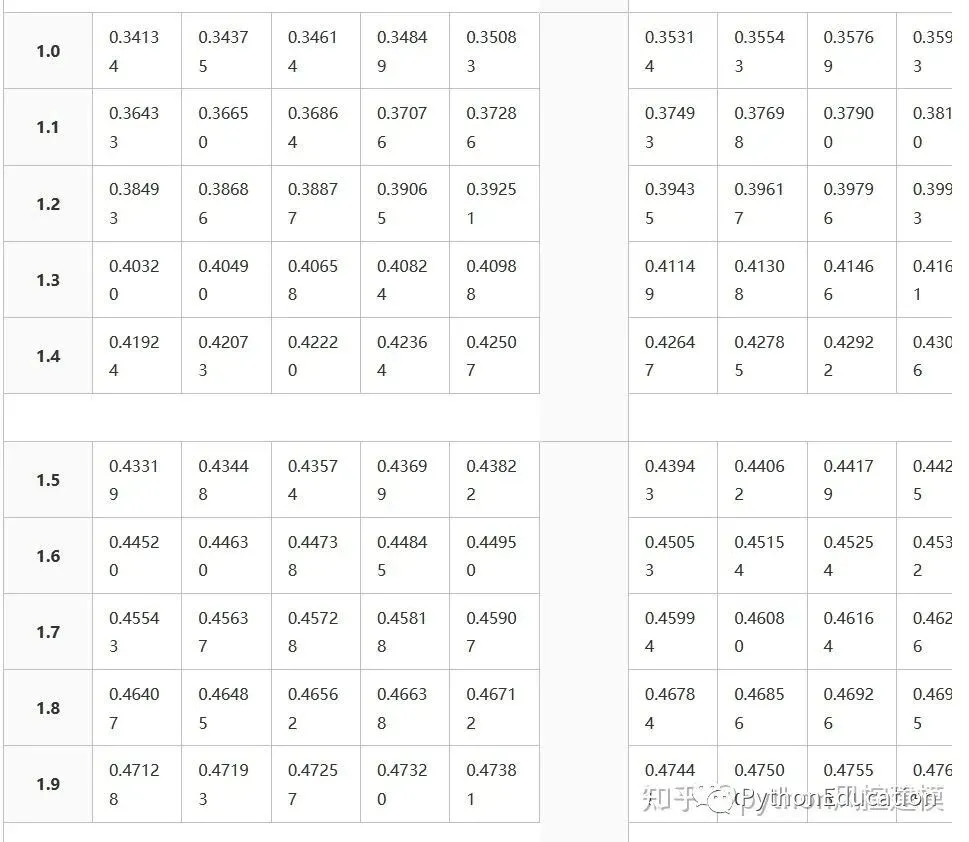
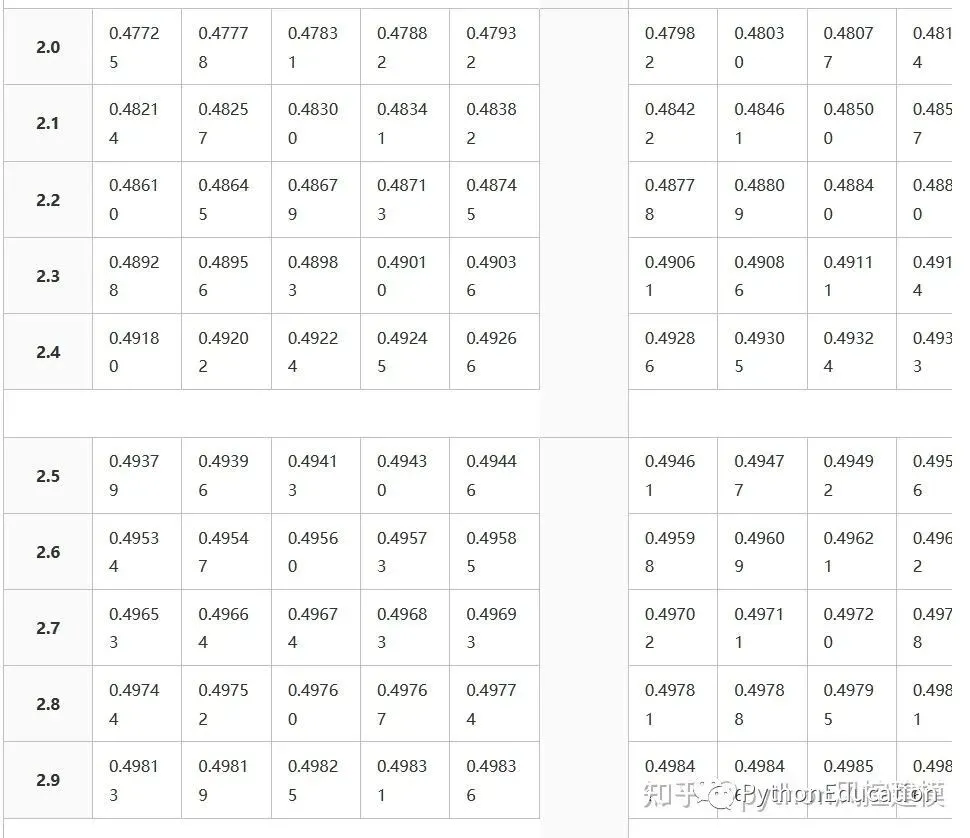
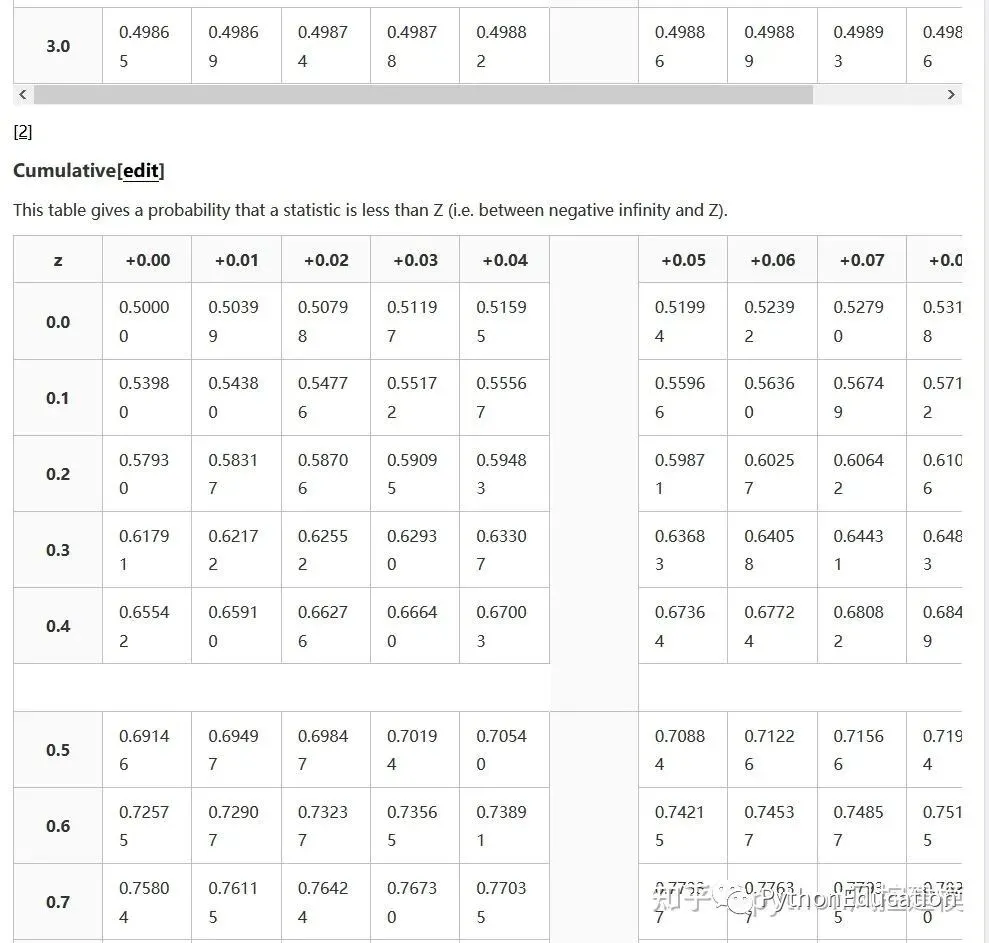
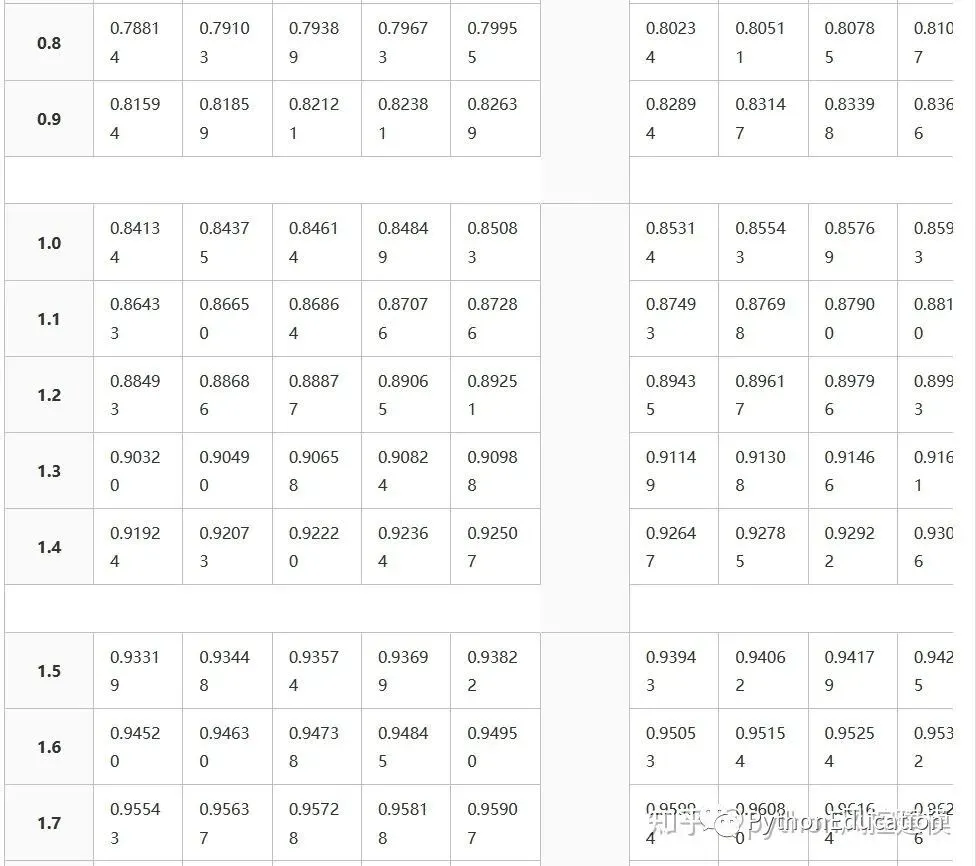
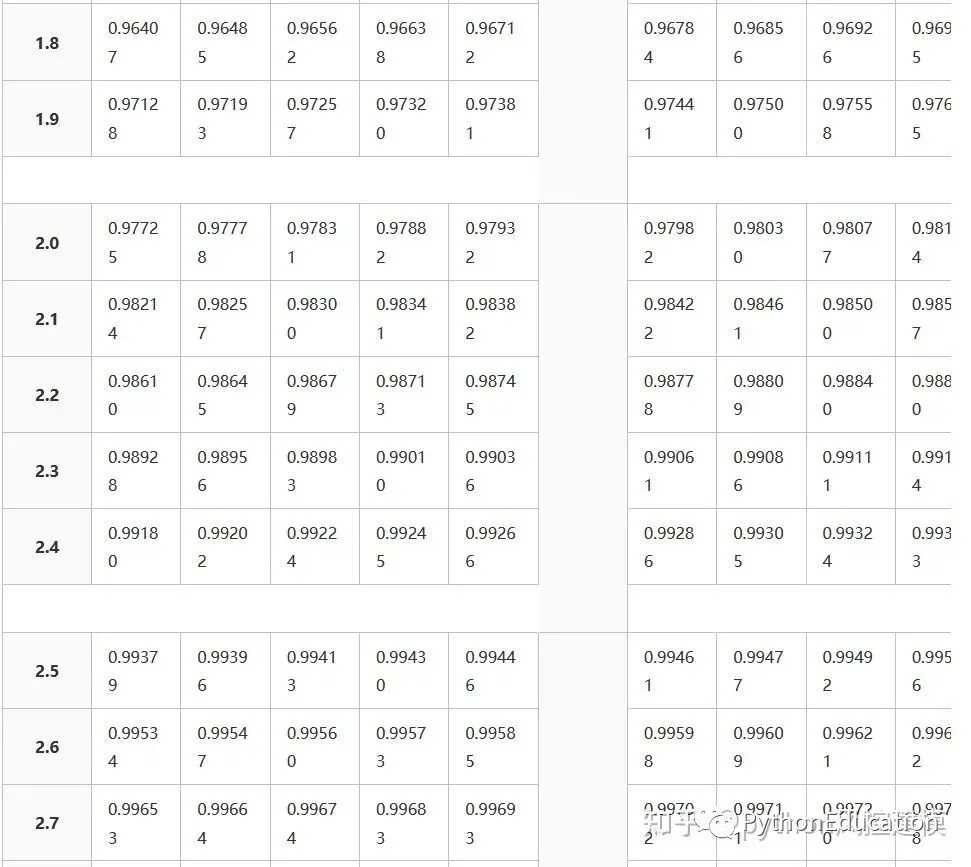
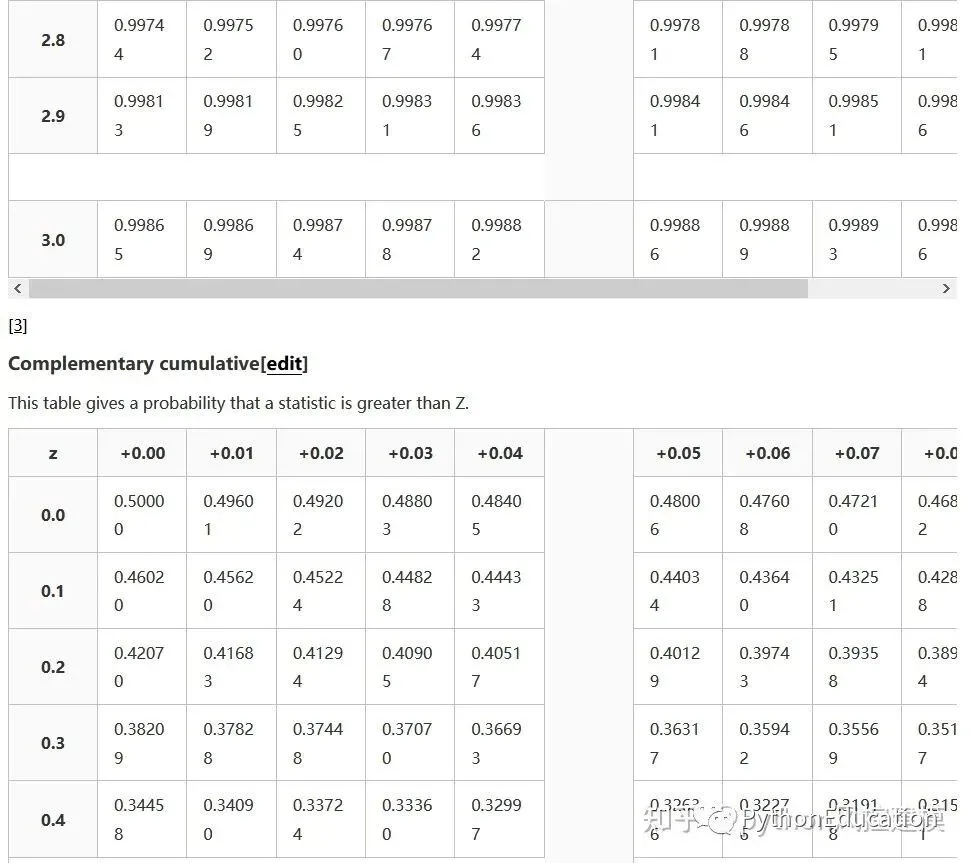
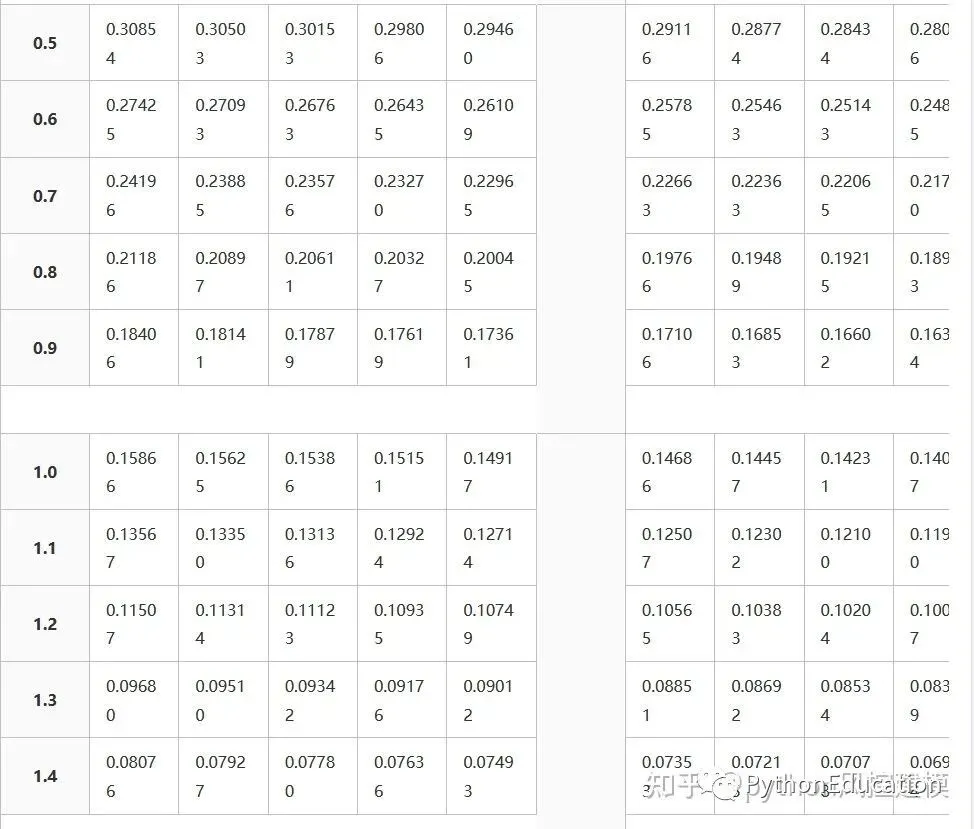
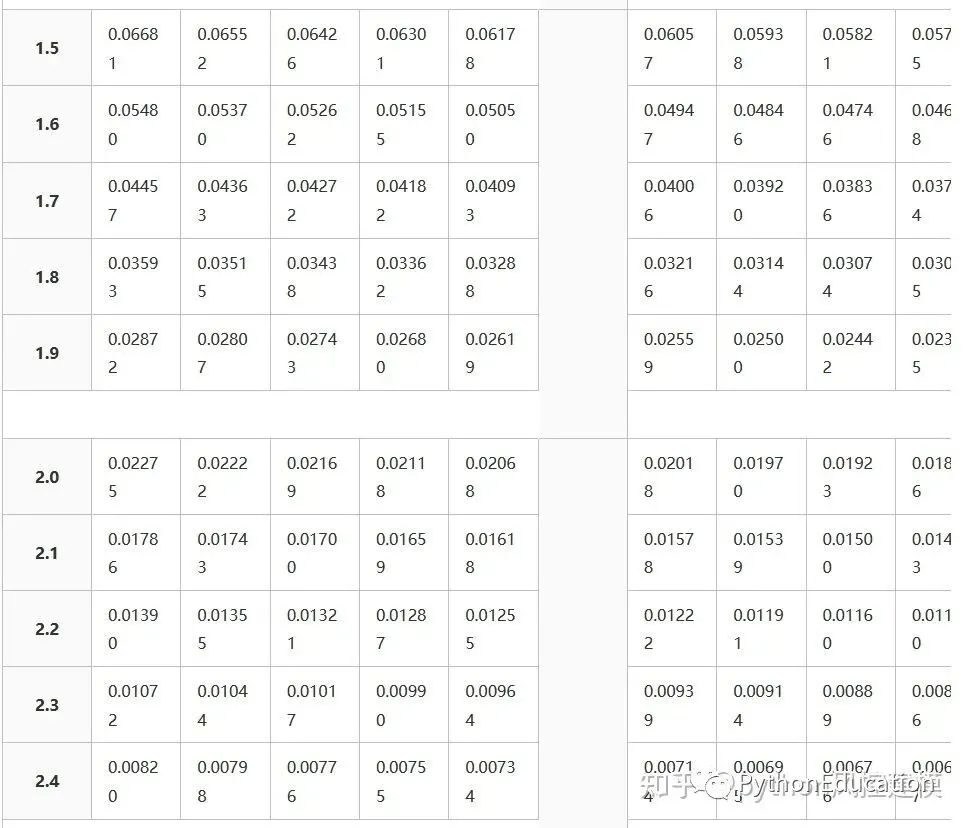
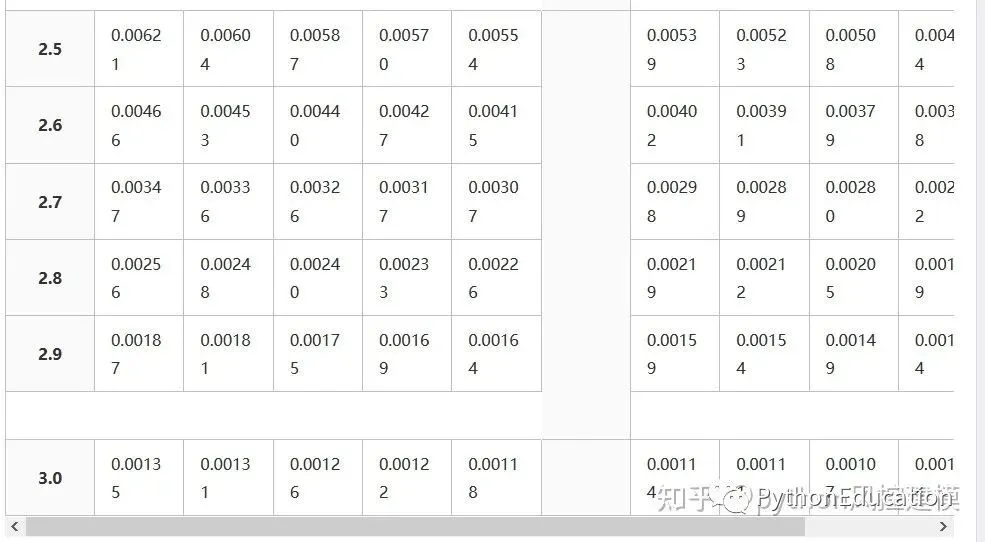
Z分数表格
Z分数表格就是标准正态分布表格
Types of tables
Z tables use at least three different conventions:
Cumulative from meangives a probability that a statistic is between 0 (mean) and Z. Example: Prob(0 ≤ Z ≤ 0.69) = 0.2549Cumulativegives a probability that a statistic is less than Z. This equates to the area of the distribution below Z. Example: Prob(Z ≤ 0.69) = 0.7549.Complementary cumulativegives a probability that a statistic is greater than Z. This equates to the area of the distribution above Z.Example: Find Prob(Z ≥ 0.69). Since this is the portion of the area above Z, the proportion that is greater than Z is found by subtracting Z from 1. That is Prob(Z ≥ 0.69) = 1 - Prob(Z ≤ 0.69) or Prob(Z ≥ 0.69) = 1 - 0.7549 = 0.2451.
The values correspond to the shaded area for given Z
This table gives a probability that a statistic is between 0 (the mean) and Z.
5.中心极限定理
中心极限定理目录1.计算机模拟-中心极限理论 2.中心极限理论与中性突变(进化论)3.中心极限理论与职场 面试简易教程https://www.youtube.com/watch?v=LVFC2f9kHq4测试随机数的网站https://www.random.org/dice/?num=6概念
随机扔6个骰子
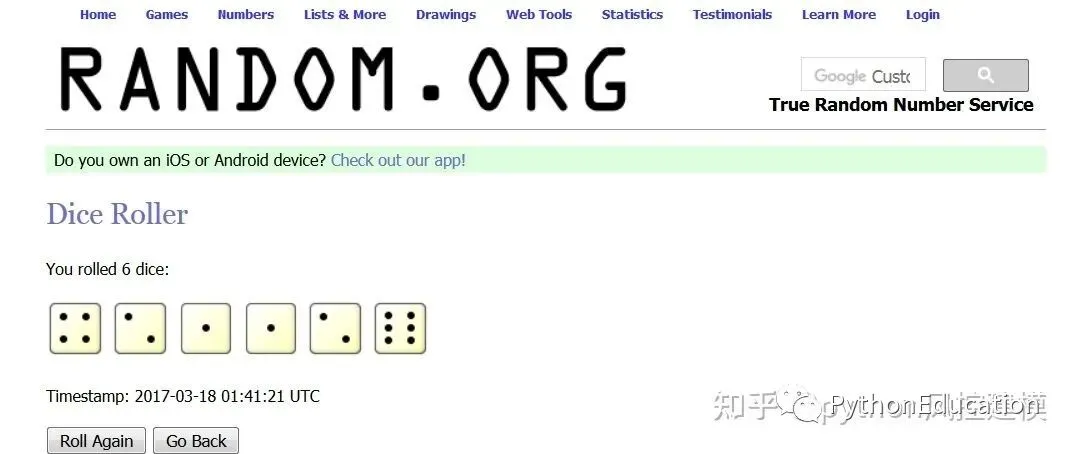
把数据存入excel表格
绘制成图,呈现正态分布
1.计算机模拟-中心极限理论 灵感来源于两颗骰子 中心极限理论是数学和概率学的基石,今天有机会能计算机模拟和辅助证明,是我荣幸。用两颗骰子建模,是中心极限定理最简单模型,可以这样解释,中间数出现频率最高,因为多个因素可随机组合成大数,例如投掷两颗骰子,7可以由6+1,2+5,4+3组成, 3只能由1+2组成,11只能由5+6组成
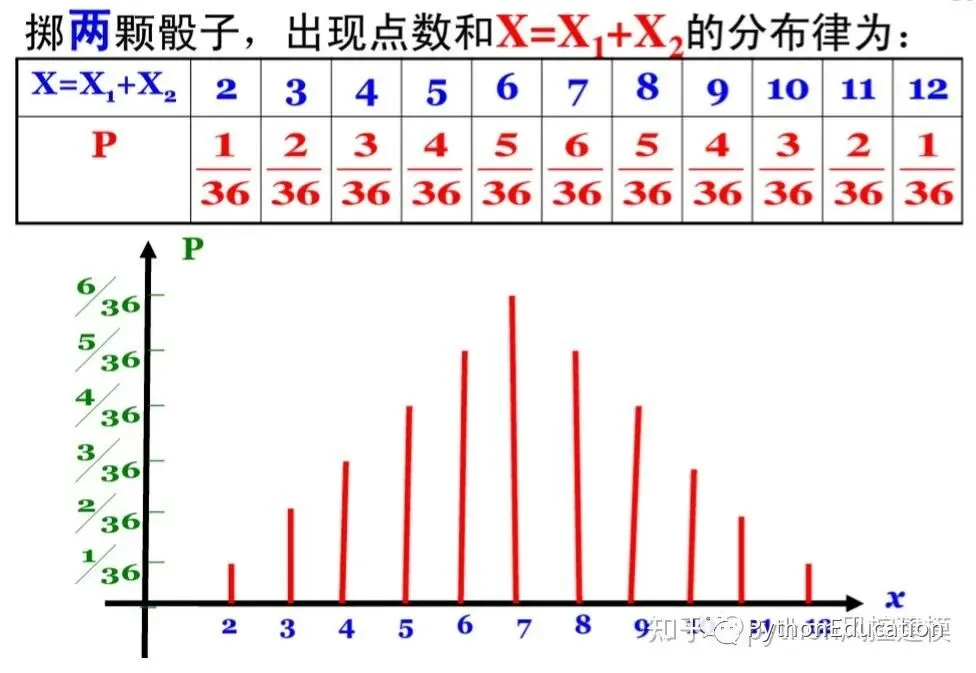
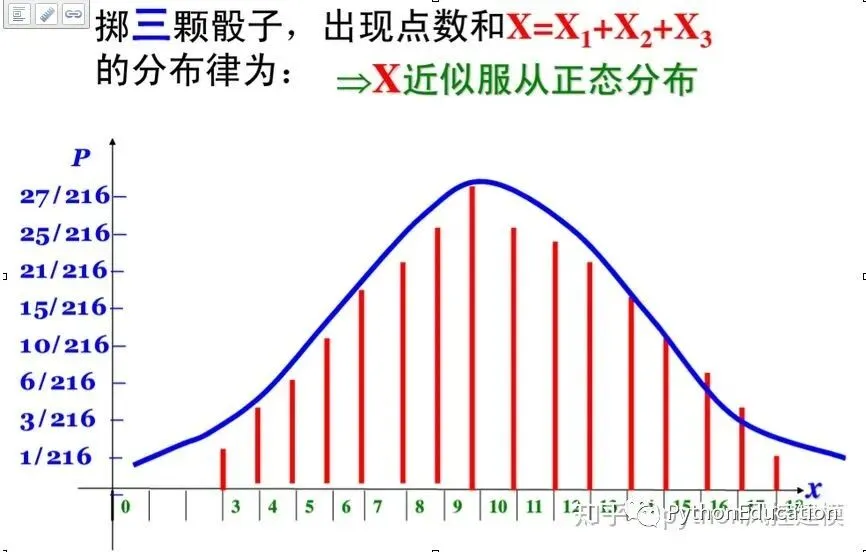
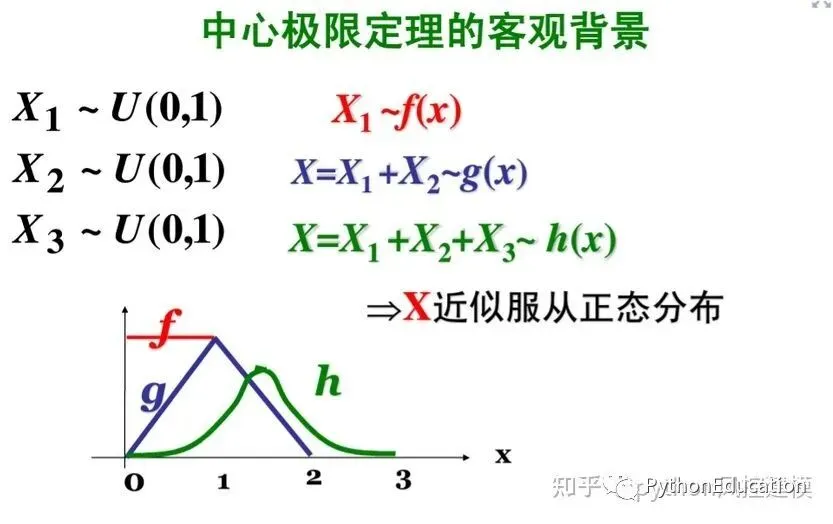

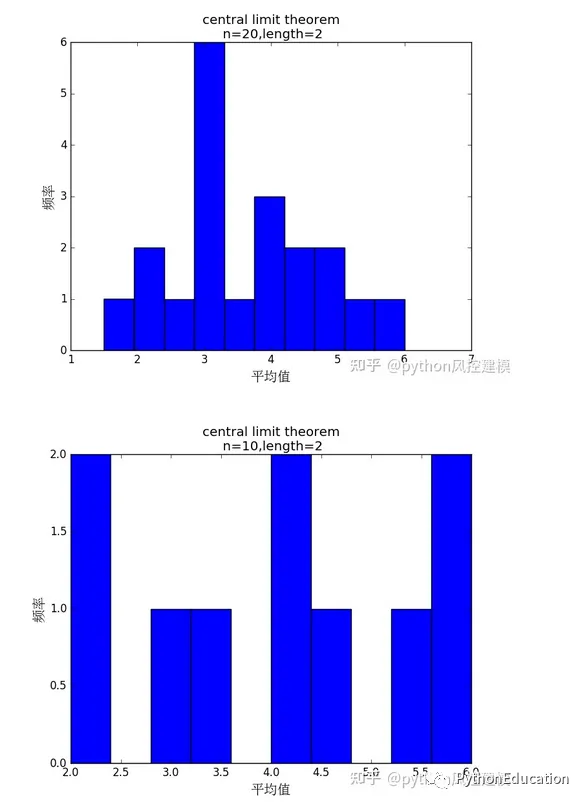
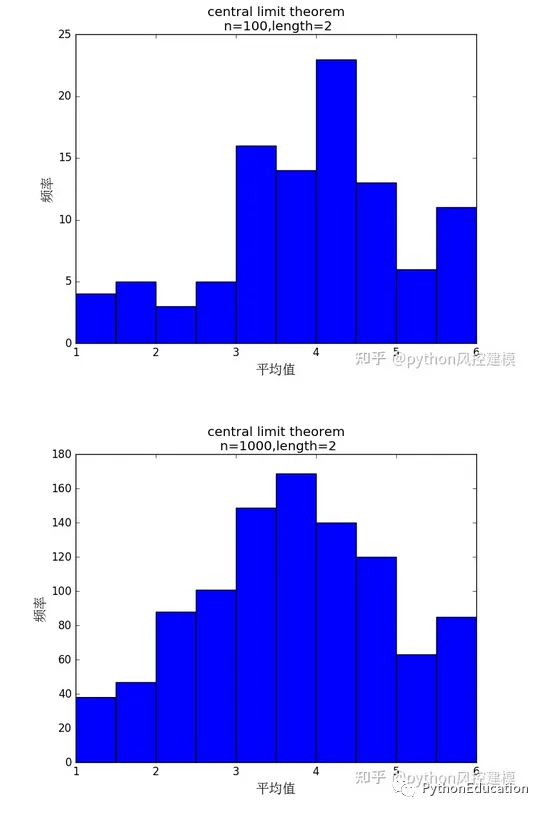
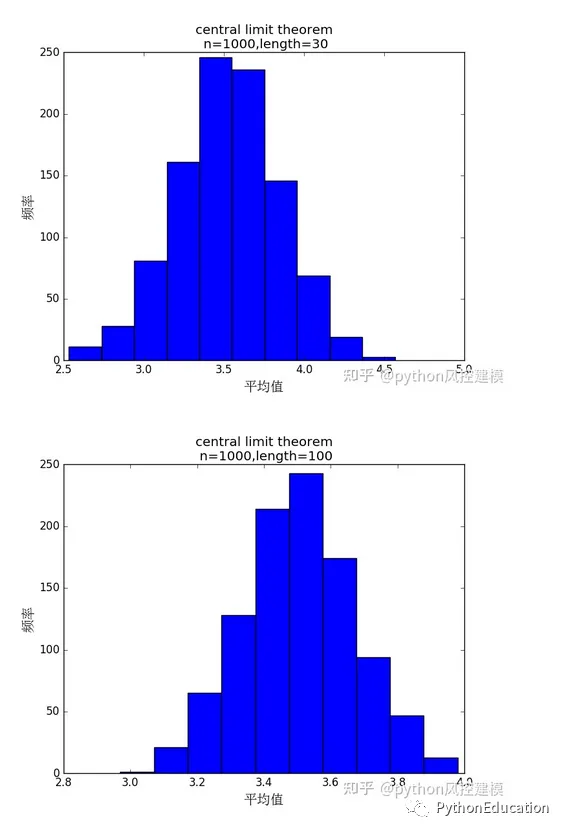
#coding=utf-8#原创公众号:python风控模型import random,os,statisticsimport matplotlib.pyplot as pltfrom matplotlib.font_manager import FontPropertiesplt.figure(20) #设置中文字体font=FontProperties(fname=r"c:\windows\fonts\simsun.ttc",size=15)#骰子选数范围从1-6number_list=[1,2,3,4,5,6]#n试验次数n=1000#length 表示样本数length=2defRandom_number(number_list): r=random.SystemRandom() random_number=r.choice(number_list)return random_number#生成一个包含随机数的列表#length样本数defRandom_list(length): random_list=[]for i in range(length): random_number=Random_number(number_list) random_list.append(random_number)return random_list'''Random_list(10)Out[22]: [3, 1, 2, 3, 4, 6, 4, 4, 2, 1]'''#n试验次数#length样本数defMean_list(length,n1): mean_list=[]for i in range(n1): random_list=Random_list(length) mean=statistics.mean(random_list) mean_list.append(mean)return mean_list'''Mean_list(10)Out[26]: [4.0, 3.5, 6.0, 4.5, 4.0, 4.0, 5.0, 4.0, 5.0, 2.0]'''#生成一组样本平均数#n试验次数#length样本数mean_list=Mean_list(30,10000)#绘图plt.hist(mean_list)titleValue="central limit theorem\n n=%d,length=%d" %(n,length)plt.xlabel("平均值",fontproperties=font)plt.ylabel("频率",fontproperties=font)plt.title(titleValue)#plt.xlabel("mean")plt.show()
样本乘积不符合中心极限定理,图像不是正太分布
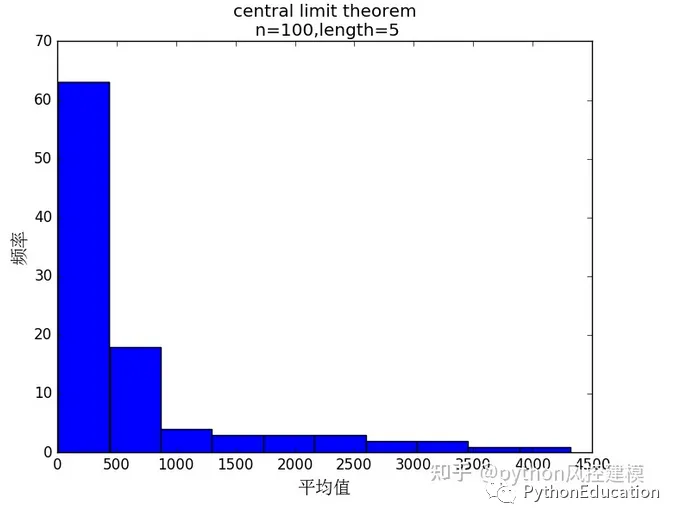
#coding=utf-8#原创公众号:python风控模型import random,os,statisticsimport matplotlib.pyplot as pltfrom matplotlib.font_manager import FontPropertiesplt.figure(20) #设置中文字体font=FontProperties(fname=r"c:\windows\fonts\simsun.ttc",size=15)#骰子选数范围从1-6number_list=[1,2,3,4,5,6]#n试验次数n=100#length 表示样本数length=5defRandom_number(number_list): r=random.SystemRandom() random_number=r.choice(number_list)return random_number#生成一个包含随机数的列表#length样本数defRandom_list(length): random_list=[]for i in range(length): random_number=Random_number(number_list) random_list.append(random_number)return random_list'''Random_list(10)Out[22]: [3, 1, 2, 3, 4, 6, 4, 4, 2, 1]'''#n试验次数#length样本数#样本平均数defMean_list(length,n1): mean_list=[]for i in range(n1): random_list=Random_list(length) mean=statistics.mean(random_list) mean_list.append(mean)return mean_list'''Mean_list(10)Out[26]: [4.0, 3.5, 6.0, 4.5, 4.0, 4.0, 5.0, 4.0, 5.0, 2.0]'''defMultiply(list1): value=1for i in list1: value=value*ireturn value#n试验次数#length样本数#样本乘积defMultiply_list(length,n1): multiply_list=[]for i in range(n1): random_list=Random_list(length) multiply=Multiply(random_list) multiply_list.append(multiply)return multiply_list#生成一组样本乘积#n试验次数#length样本数multiply_list=Multiply_list(length,n)#绘图plt.hist(multiply_list)titleValue="central limit theorem\n n=%d,length=%d" %(n,length)plt.xlabel("平均值",fontproperties=font)plt.ylabel("频率",fontproperties=font)plt.title(titleValue)#plt.xlabel("mean")plt.show()
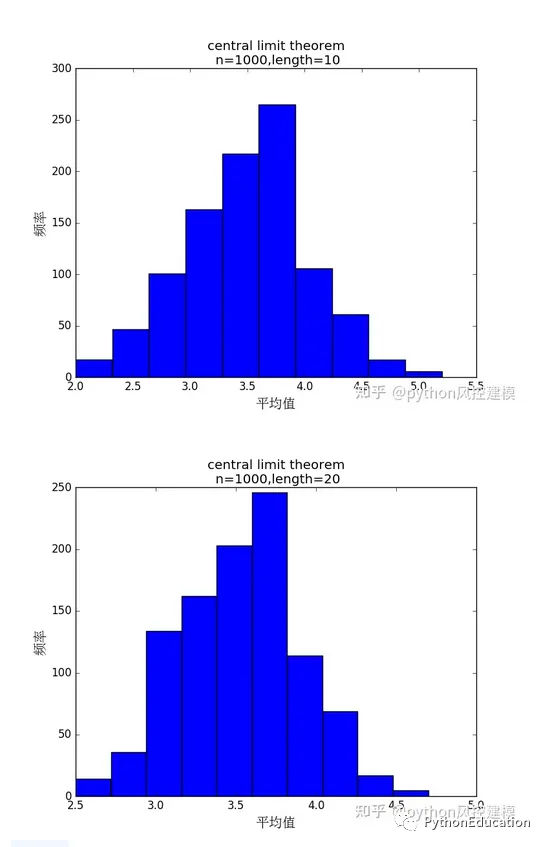
样本总和分布也呈现中心极限定理,这可以推断多个基因值叠加,也符合正态分布,进一步支持中性突变定理
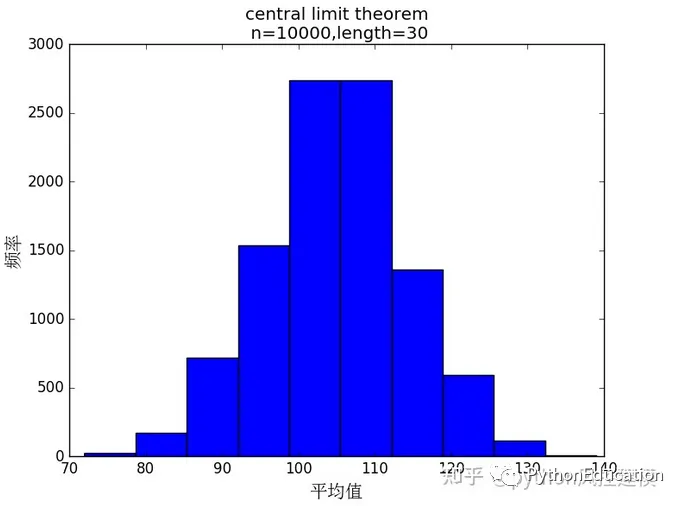
#coding=utf-8#原创公众号:python风控模型import random,os,statisticsimport matplotlib.pyplot as pltfrom matplotlib.font_manager import FontPropertiesplt.figure(20)#设置中文字体font=FontProperties(fname=r"c:\windows\fonts\simsun.ttc",size=15)#骰子选数范围从1-6number_list=[1,2,3,4,5,6]#n试验次数n=10000#length 表示样本数length=30defRandom_number(number_list): r=random.SystemRandom() random_number=r.choice(number_list)return random_number#生成一个包含随机数的列表#length样本数defRandom_list(length): random_list=[]for i in range(length): random_number=Random_number(number_list) random_list.append(random_number)return random_list'''Random_list(10)Out[22]: [3, 1, 2, 3, 4, 6, 4, 4, 2, 1]'''#n试验次数#length样本数defAdd_list(length,n1): total_list=[]for i in range(n1): random_list=Random_list(length) total=sum(random_list) total_list.append(total)return total_list'''Mean_list(10)Out[26]: [4.0, 3.5, 6.0, 4.5, 4.0, 4.0, 5.0, 4.0, 5.0, 2.0]'''#生成一组样本平均数#n试验次数#length样本数total_list=Add_list(length,n)#绘图plt.hist(total_list)titleValue="central limit theorem\n n=%d,length=%d" %(n,length)plt.xlabel("平均值",fontproperties=font)plt.ylabel("频率",fontproperties=font)plt.title(titleValue)#plt.xlabel("mean")plt.show()
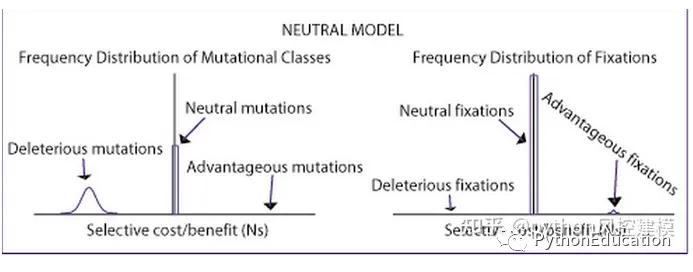
2.中心极限理论与中性突变
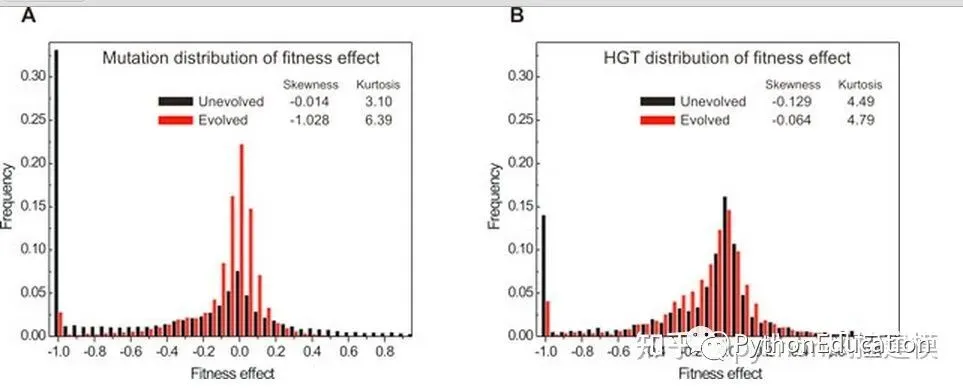
中间数出现频率最高,最小数和最大数出现频率最低。这和进化论中的中性突变很类似。达尔文进化论有局限性,在分子层面发生的突变,如果不考虑对生殖不利的话,基本上都是无所谓有利还是不利的“中性突变”,有利的突变其实非常少,简直可以忽略不计。Neutral mutations are changes in DNA sequence that are neither beneficial nor detrimental to the ability of an organism to survive and reproduce.
3.中心极限理论与职场 面试中心极限理论同样适用于职场面试。(排除关系户和考试排名算分因素)假如一个部门经理招1个人,有10个面试者。部门经理要从10个面试者中选取1位。能力太差的不能胜任工作,pass。 能力太强的他hold不住,担心以后饭碗被翘或担心此人嫌弃此岗位而跳槽,也pass。面试概率最大的能力居中的面试者,平庸的人部门经理既能把控,又能胜任工作。
所以我推测,大多数公司里能力超强的人和能力超弱的人不会太多,只占正态分布两端(低概率)。能力居中的人占大多数。不相信的可以去做调查问卷。
所以想去社工一个公司,就装得能力一般但又能胜任工作,这样混过面试官概率最高。。。。。当然实际情况中众多因素需要考虑,不能一概而论。例如长相,关系户,考试分数排名,家住地址等等。。。。。 总结万物皆有数,自然现象皆可建模,近似推导,但又不能准确模拟,因为参与因素实在太多了。且众多因素相互交错影响,不停变化,这造成了不可预测性。这就是说数字即可推算也不可预测。听起来是不是有点矛盾。。。吃饭去了。。。
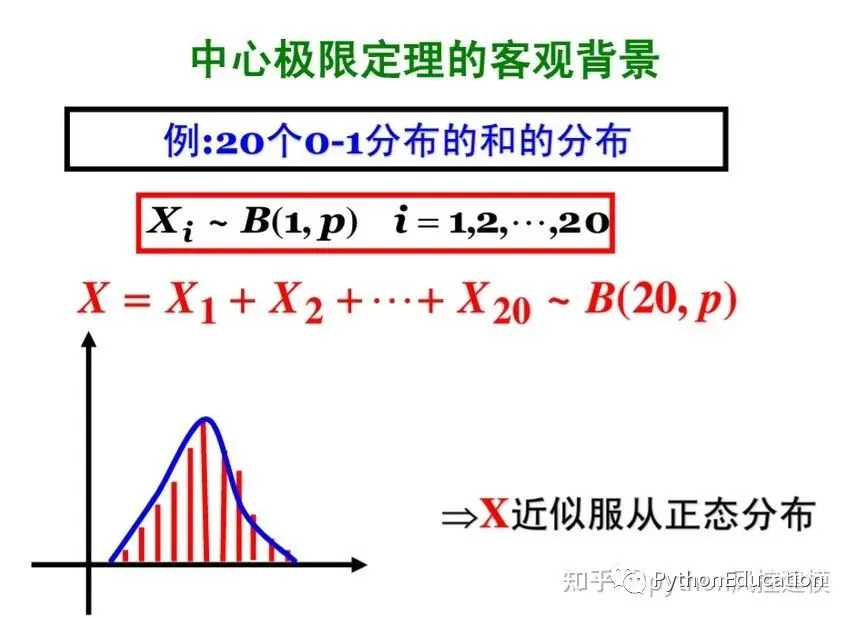
6.大数定理 样本量越大,样本平均数越接近总体平均数

1、大数法则一位数学家调查发现,欧洲各地男婴与女婴的出生比例是22:21,只有巴黎是25:24,这极小的差别使他决心去查个究竟。最后发现,当时的巴黎的风尚是重女轻男,有些人会丢弃生下的男婴,经过一番修正后,依然是22:21。中国的历次人口普查的结果也是22:21。人口比例所体现的,就是大数法则。大数法则(Lawoflargenumbers)又称“大数定律”或“平均法则”。在随机事件的大量重复出现中,往往呈现几乎必然的规律,这类规律就是大数法则。在试验不变的条件下,重复试验多次,随机事件的概率近似于它的概率。大数法则反映了这世界的一个基本规律:在一个包含众多个体的大群体中,由于偶然性而产生的个体差异,着眼在一个个的个体上看,是杂乱无章、毫无规律、难于预测的。但由于大数法则的作用,整个群体却能呈现某种稳定的形态。花瓶是由分子组成,每个分子都不规律地剧烈震动。你可曾见过一只放在桌子上的花瓶,突然自己跳起来?电流是由电子运动形成的,每个电子的行为杂乱而不可预测,但整体看呈现一个稳定的电流强度。一个封闭容器中的气体,它包含大量的分子,它们各自在每时每刻的位置、速度和方向,都以一种偶然的方式在变化着,但容器中的气体仍能保有一个稳定的压力和温度。某个人乘飞机遇难,概率不可预料,对于他个人来说,飞机失事具有随机性。但是对每年100万人次所有乘机者而言,这里的100万人可以理解这100万次的重复试验,其中,总有10人死于飞行事故。那么根据大数法则,乘飞机出事故的概率大约为十万分之一。这就为保险公司收取保险费提供了理论依据。对个人来说,出险是不确定的,对保险公司来说,众多的保单出险的概率是确定的。根据大数法则的定律,承保危险的单位越多,损失概率的偏差越小,反之,承保危险的单位越少,损失概率的偏差越大。因此,保险公司运用大数法则就可以比较精确地预测危险,合理保险费率。2、小刀锯大树赌客久赌必输的另一个秘密,即大数法则。赌王何鸿燊刚刚接手葡京赌场的时候,业务蒸蒸日上。赌王居安思危,请教“赌神”叶汉:“为什么这些赌客总是输,长此以往他们不来赌怎么办?”叶汉笑道:“这世界每天都死人,你可见这世上少人?”叶汉的回答甚妙,道出了一条无论是保险公司、赌场还是骗徒,都信仰的法则:大数法则。赌场本质上是一种温和的“概率场”,概率法则非常明显。一直玩下去,大数法则的作用就会日益显现出来。庄家在规则上占有少许优势,玩的次数越多,这种优势越能显现出来。久赌神仙输,赌圣也不行。一天,一位沙特王子入住葡京酒店。王子找到赌王,说:我就和你玩一把掷硬币。出正面我给你50亿美元,出反面你的赌场归我。赌王呵呵一笑:这个游戏固然公平,但不符合我们博彩业的行事法则。我们开赌场不做一锤子买卖,而是小刀锯大树。如果你真的想玩,我们就玩掷骰子,1000下定输赢。你赢了,可以把我的产业拿走,我赢了,只收你20亿。沙特王子无奈,只好退出赌局。这个故事是虚构的,旨在说明大数法则之于赌场的意义。开赌场不做一锤子买卖,而是“小刀锯大树”。所以,赌场最欢迎的是斤斤计较、想碰一下运气的散客,他们虽然下注谨慎,却构成了庞大的行为基数。这种客人会给赌场老板带来几乎线性的稳定收益,是赌场最稳定的收入来源,这是大数法则在起作用。还有一种是一掷千金、豪气干云的大赌客,他们的下注额若在赌场的风险控制范围,也很难从赌场赢钱,会成为赌场的VIP客户。假如有一个超级赌客,比如上面虚构故事中的沙特王子。他的赌注超过了普通赌客的千倍万倍,这会导致赌场收益的大幅震荡,极端情况下可能导致赌场破产。因此,全世界所有赌场都会设定最高的投注限额。赌场设最低及最高的投注限额,即便“新郎行运一条龙”的事故发生,也不至于让赌场亏太多。这样,赌场老板就可以安心睡觉了。所有的VIP加起来,等于庄家和客人玩了一场长期游戏,大数法则依然有效。3、“撞骗”的数理依据你是否收到过这类短信:请直接把钱打到工商银行卡号6220219 ***这叫“撞骗”,是一种传统骗术。版本甚多,比如寄中奖信、打中奖电话、发电子邮件。也就是骗子像没头苍蝇一样乱撞,“有枣没枣打一杆子”或许能“瞎猫捡个死老鼠”。是不是觉得骗子很蠢?但骗徒的行为却是合乎统计原理的,在数理上是被支持的。只要发出的短信足够多,其成功率非常稳定,合乎大数法则。福建的某个小镇,众多乡亲都从事这个行当,短信群发器在这个偏远小镇非常普及。当警察抓获了这批刁民后,奇怪的是,过了很长时间了,居然还有人不断地往查获的卡上汇钱。有人曾做过统计,类似这种垃圾短信,每发出一万条,上当的人有七到八个,成功率非常稳定。人过一百,形形色色。一万个人里面,总会有几个“人精”,几个笨蛋,这是可以确定的。究其根源,都是由于大数法则的作用。在社会、经济领域中,群体中个体的状况千差万别,变化不定。但一些反映群体的平均指针,在一定时期内能保持稳定或呈现规律性的变化。大数法则是保险公司、赌场、撞骗的骗徒,赖以存在的基础
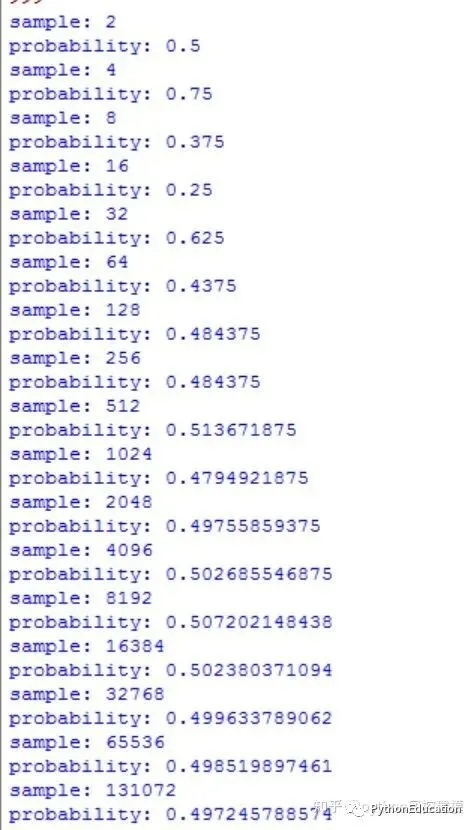
#大数定理模拟#原创公众号:python风控模型import random,numpy,pylab,matplotlibcount_head=0n=2count=25list_probabiliy=[]for i in range(count):for i in range(n): result=random.choice ( ['head', 'tail'] )if result=='head': count_head+=1.0#print "sample:",n mean=count_head/n#print "probability:",mean list_probabiliy.append(mean) n=n*2 count_head=0defDraw_lawOfLargeNumber(count): x=numpy.arange(0,count,1)for i in range(count): x=i y=list_probabiliy[i] pylab.plot(x,y,'ro') pylab.xlabel('x') pylab.ylabel('y') pylab.title('Law of large number')#x,y轴刻度分别是1和0.1 pylab.xticks(numpy.arange(0,count,1)) pylab.yticks(numpy.arange(0.0,1.0,0.1)) pylab.grid(True) pylab.show()# Pad margins so that markers don't get clipped by the axes,让点不与坐标轴重合 pylab.margins(0.5)
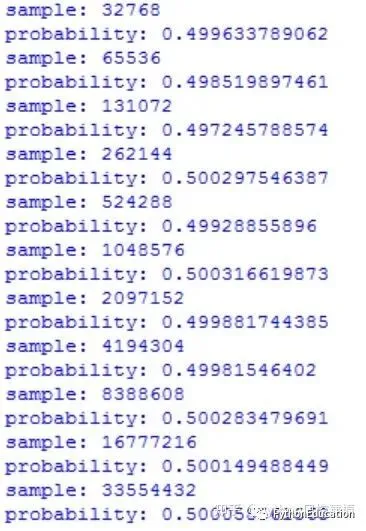
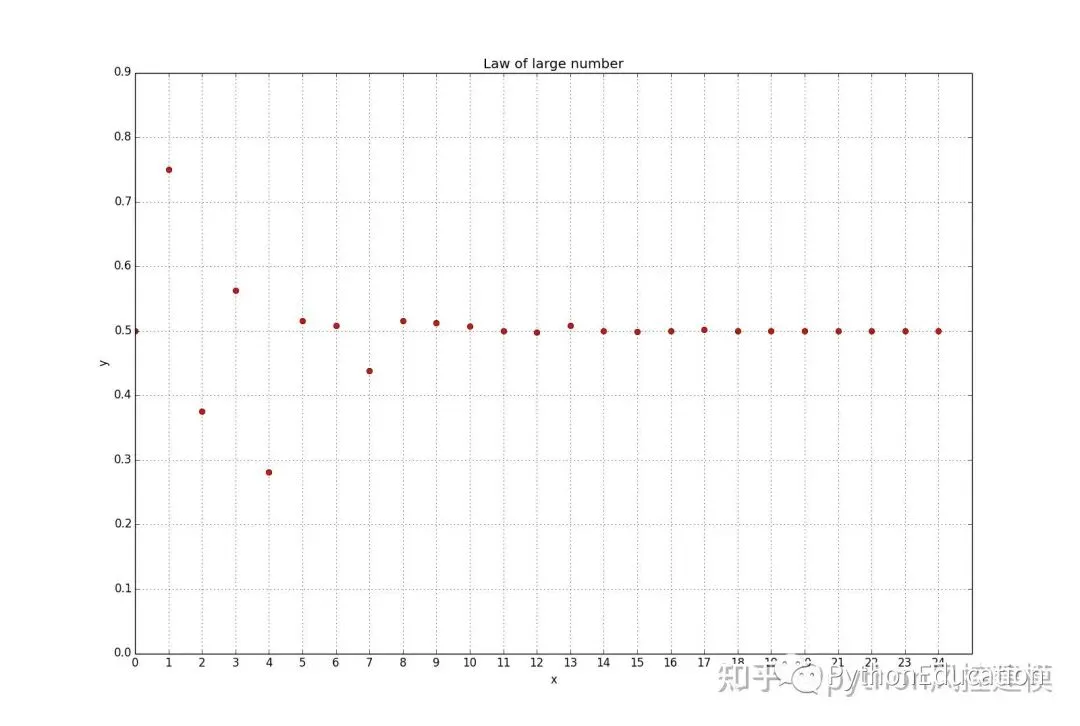
实验次数越多,概率越接近平均概率(期望值)
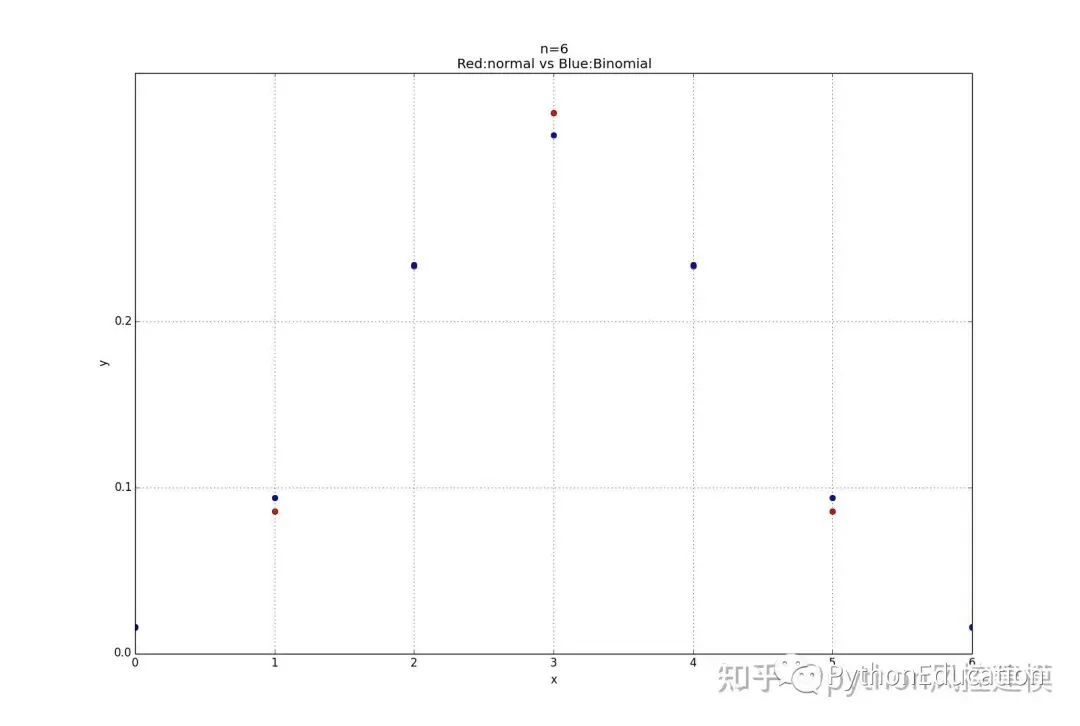
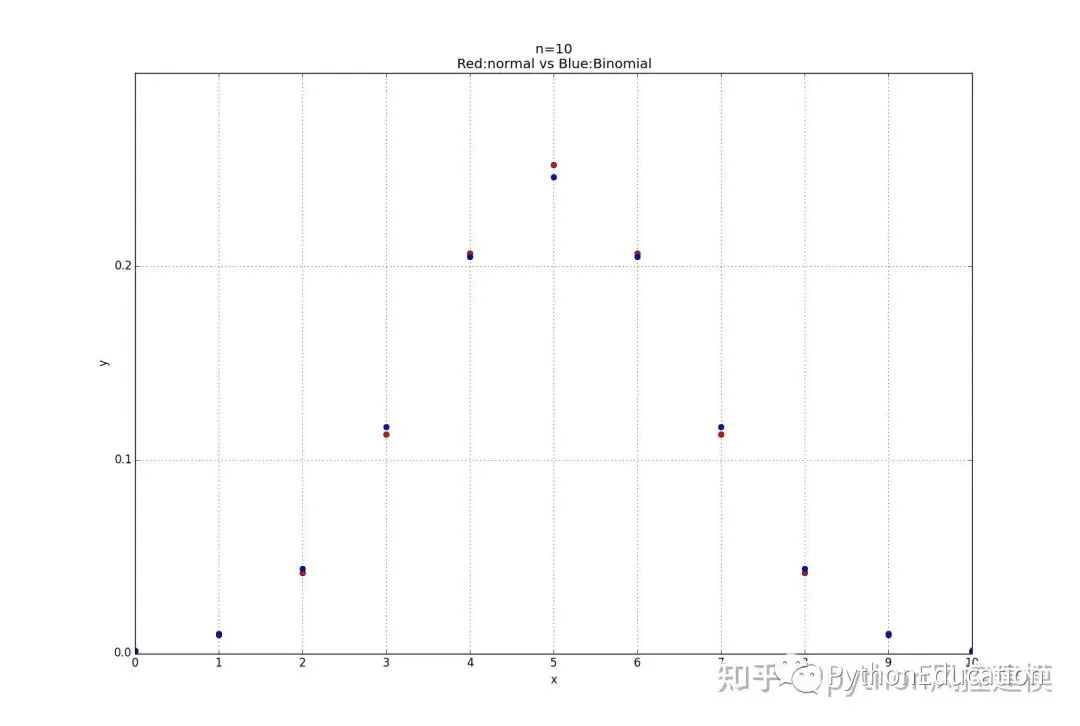
7.二项式分布与正态分布图比较
#coding=utf-8#原创公众号:pythonEducation#绘图模板#1.正态分布import math,pylab,matplotlib,numpy,statistics_functions,Binomial_distribution,normal_distributiondefDraw_normal_distribution(u,q): x=numpy.arange(-4,4.1,0.1) #x取值范围可以随意更改for value in x: y=normal_distribution.Normal_distribution(x,u,q)#x,y都要绘制出来 pylab.plot(x,y,'r') pylab.xlabel('x') pylab.ylabel('y') pylab.title('Normal distribution') pylab.grid(True) pylab.show()# Pad margins so that markers don't get clipped by the axes,让点不与坐标轴重合 pylab.margins(0.01)#正态分布比较图#标准正太分布:u=0(平均值),q=1(标准差)defDraw_muliti_normal_distribution(): x=numpy.arange(-4,4.1,0.1) #x取值范围可以随意更改 u=0 q=1for value in x: y=statistics_functions.Normal_distribution(x,u,q)#x,y都要绘制出来 pylab.plot(x,y,'ro') u=1 q=1for value in x: y1=statistics_functions.Normal_distribution(x,u,q)#x,y都要绘制出来 pylab.plot(x,y1,'b') u=-1 q=1for value in x: y2=statistics_functions.Normal_distribution(x,u,q)#x,y都要绘制出来 pylab.plot(x,y2,'y') u=0 q=0.5for value in x: y3=statistics_functions.Normal_distribution(x,u,q)#x,y都要绘制出来 pylab.plot(x,y3,'g') u=0 q=1.5for value in x: y4=statistics_functions.Normal_distribution(x,u,q)#x,y都要绘制出来 pylab.plot(x,y4,'m') pylab.xlabel('x\nMade by Toby') pylab.ylabel('y')#"\n表示换行" pylab.title('Normal distribution\n(r:u,q=0,1;b:u,q=1,1;y:u,q=-1,1;g:u,q=0,0.5,m:u,q=0,1.5)') pylab.grid(True) pylab.show()# Pad margins so that markers don't get clipped by the axes,让点不与坐标轴重合 pylab.margins(0.01)#正态分布和二项式函数比较defCompare_normal_binomial_distribution(n=6,p=0.5): x_array=numpy.arange(0,n+1,1) list_x=list(x_array) u=statistics_functions.Mean(list_x) q=Binomial_distribution.Deviation_Binomial(n,p)for x in x_array: y=normal_distribution.Normal_distribution(x,u,q)#x,y都要绘制出来 pylab.plot(x,y,'ro')for x1 in x_array: y1=Binomial_distribution.Binomial_distribution(n,x1,p)#x,y都要绘制出来 pylab.plot(x1,y1,'bo') pylab.xticks(numpy.arange(0,n+1,1)) pylab.yticks(numpy.arange(0.0,0.3,0.1)) pylab.xlabel('x') pylab.ylabel('y') pylab.title('n=%d \nRed:normal vs Blue:Binomial' %(n)) pylab.grid(True) pylab.show()# Pad margins so that markers don't get clipped by the axes,让点不与坐标轴重合 pylab.margins(0.01)
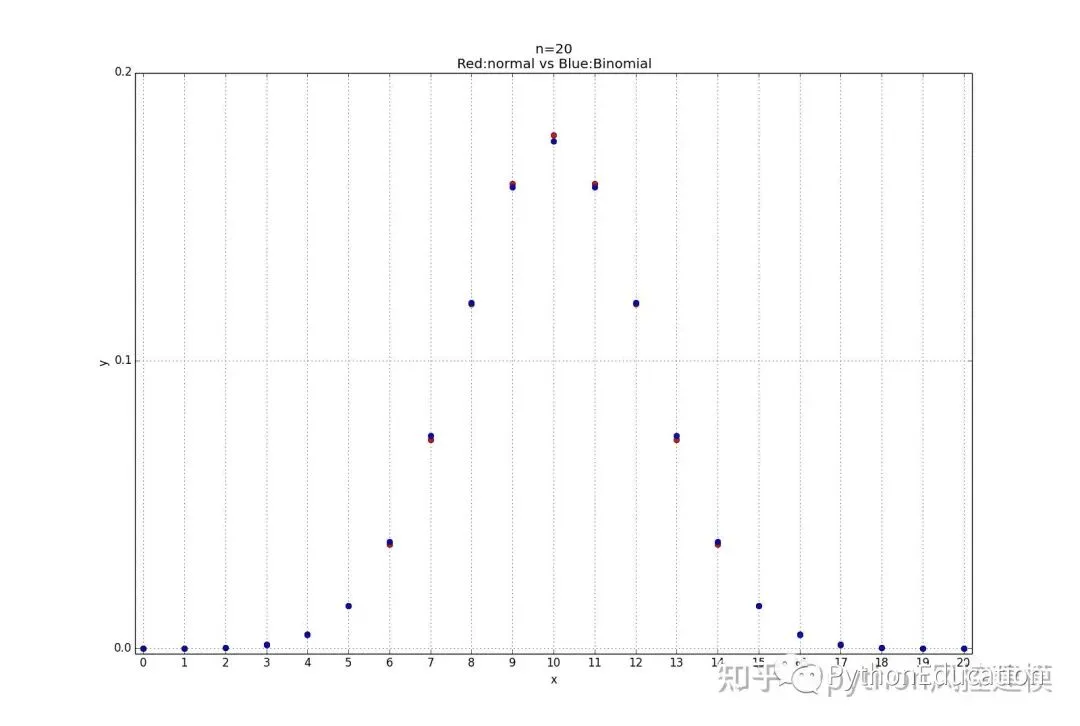
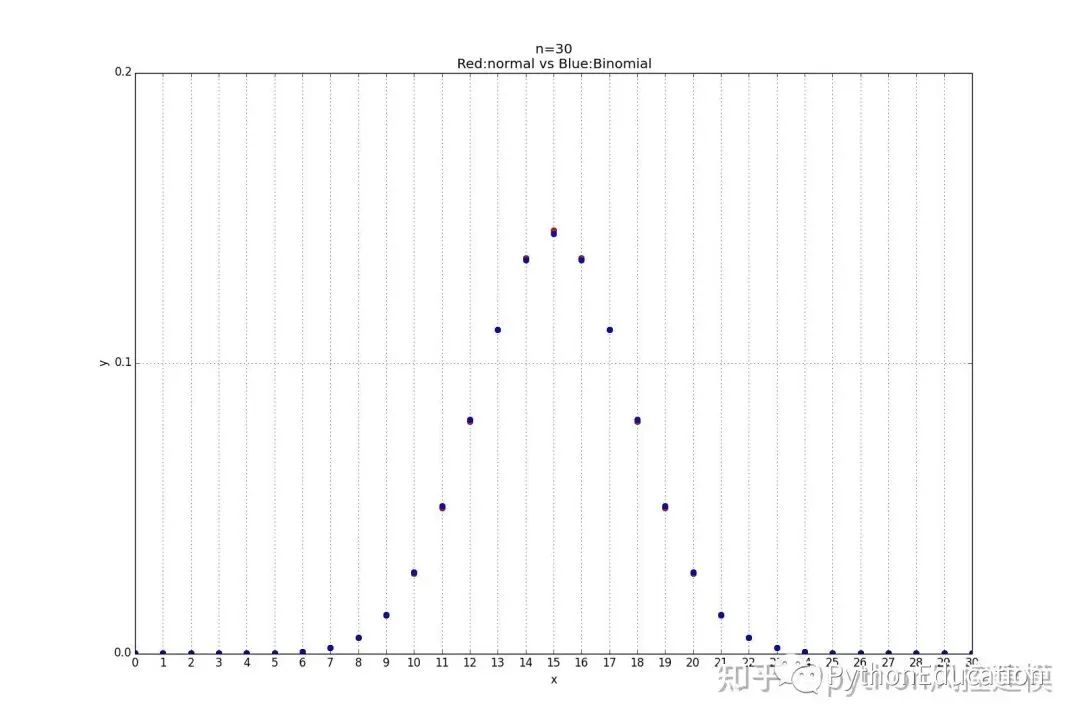
8.你的数据是正态分布吗
统计很多分析是基于正态分布数据,如果数据不呈现正态分布就要出错
为了避免出错,首先让你的数据可视化



符合正态分布的箱型图
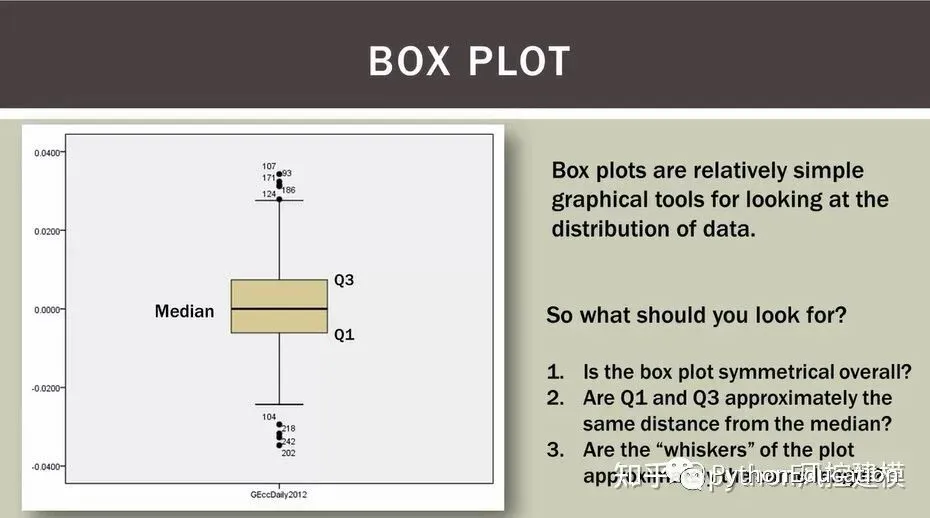
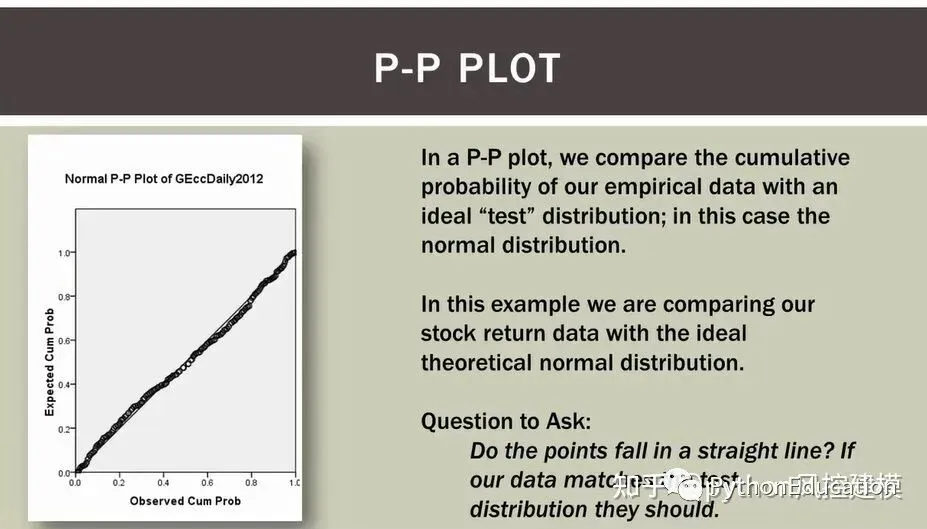
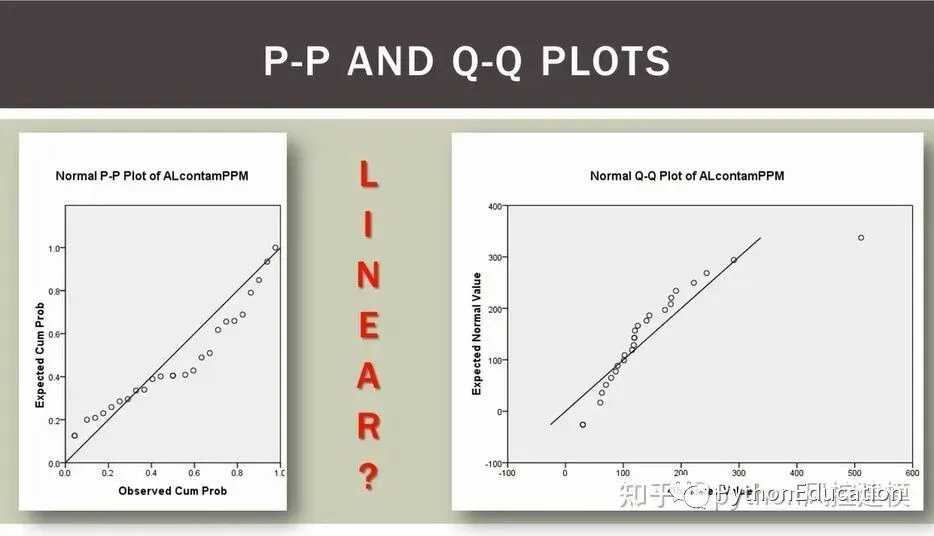
符合正态分布的p-p图
不符合正态分布的箱型图
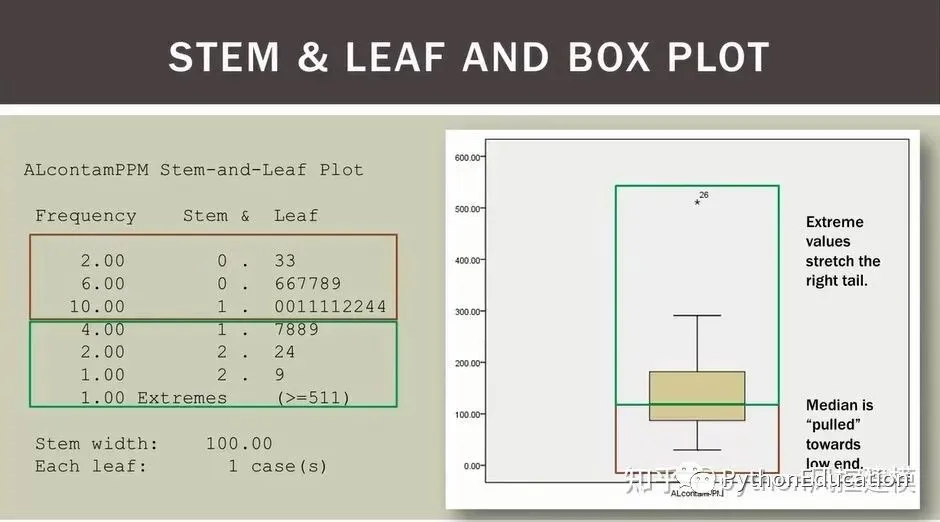
不符合正态分布的Q-Q图
征信查询就为大家介绍到这里,
如果你有企业建模请商务联系QQ:231469242,微信:drug666123,或扫描下面二维码加微信咨询。
公司自营课程如下
如果你对《python风控建模实战案例数据库》数据库感兴趣,微信二维码扫一扫即可访问和收藏,了解更多相关介绍。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
