在 Linux 内核中,链表堪称无处不在的 “万能连接器”,是构建内核复杂数据结构大厦的基石。从内存管理模块中对内存块的精细组织,到进程调度模块里对各个进程状态的有序维护,再到文件系统中对文件节点和目录结构的巧妙串联,链表都发挥着不可或缺的作用。链表之所以能在Linux内核中如此 “神通广大”,源于其独特的数据结构特性。它采用动态内存分配方式,能根据实际需求灵活地增加或删除节点,这种高效的增删操作使得内核在处理各种动态变化的数据时游刃有余。同时,链表对内存的使用极为灵活,无需像数组那样预先分配连续的大块内存空间,这大大提高了内存的利用率,尤其适合内核这种对资源高效利用要求极高的环境 。
那么,Linux 内核是如何突破这一困境,实现双向链表的 “华丽转身” 呢?
让我们带着这个疑问,继续深入~
一、 传统链表的坑
传统双向链表在 C 语言中的实现,其基本思路是将数据字段与 prev/next 指针封装在同一个结构体中,形成一个紧密结合的数据节点。例如,我们要创建一个存储整数的双向链表,可能会这样定义节点结构体:
struct traditional_list_node { int data; struct traditional_list_node *prev; struct traditional_list_node *next;};struct traditional_list { struct traditional_list_node *head; struct traditional_list_node *tail;};
在这个定义中,data字段用于存储整数数据,prev和next指针分别指向前一个和后一个节点,而traditional_list结构体则用于管理整个链表,包含头指针head和尾指针tail 。
当我们要对链表进行操作,如插入、删除或遍历节点时,都需要针对这个特定的结构体编写相应的函数。比如插入节点的函数:
voidtraditional_list_insert(struct traditional_list *list, int new_data){ struct traditional_list_node *new_node = (struct traditional_list_node *)malloc(sizeof(struct traditional_list_node)); new_node->data = new_data; new_node->prev = NULL; new_node->next = list->head; if (list->head != NULL) { list->head->prev = new_node; } list->head = new_node; if (list->tail == NULL) { list->tail = new_node; }}
这种实现方式虽然直观易懂,但局限性也非常明显。一旦我们需要存储其他类型的数据,比如字符串、结构体等,就必须重新定义链表节点和操作函数。以存储字符串为例:
struct traditional_list_node_str { char *data; struct traditional_list_node_str *prev; struct traditional_list_node_str *next;};struct traditional_list_str { struct traditional_list_node_str *head; struct traditional_list_node_str *tail;};voidtraditional_list_insert_str(struct traditional_list_str *list, char *new_data){ struct traditional_list_node_str *new_node = (struct traditional_list_node_str *)malloc(sizeof(struct traditional_list_node_str)); new_node->data = strdup(new_data); new_node->prev = NULL; new_node->next = list->head; if (list->head != NULL) { list->head->prev = new_node; } list->head = new_node; if (list->tail == NULL) { list->tail = new_node; }}
可以看到,仅仅因为数据类型的改变,我们就需要重复编写大量几乎相同的代码,这不仅繁琐易错,而且严重违反了代码复用的原则。在追求高效、简洁和可维护性的 Linux 内核开发中,这种方式显然是行不通的。那么,Linux 内核是如何另辟蹊径,巧妙地解决这一难题的呢?这就引出了 Linux 内核双向链表那令人拍案叫绝的 “数据与逻辑分离” 设计理念,接下来,就让我们一同揭开它神秘的面纱。
二: 颠覆传统的设计哲学:把节点 “嵌” 进数据里
2.1 核心结构体 list_head
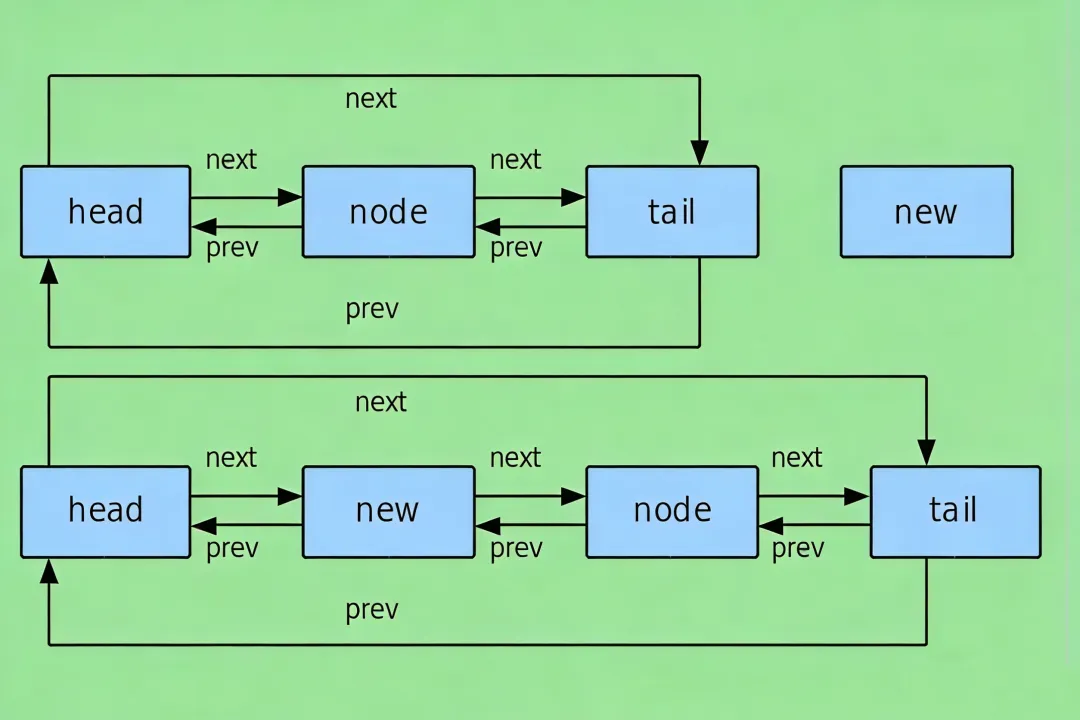
在 Linux 内核的双向链表实现中,list_head结构体堪称极简主义设计的典范,仅由两个指针字段构成:
struct list_head { struct list_head *next; struct list_head *prev;};
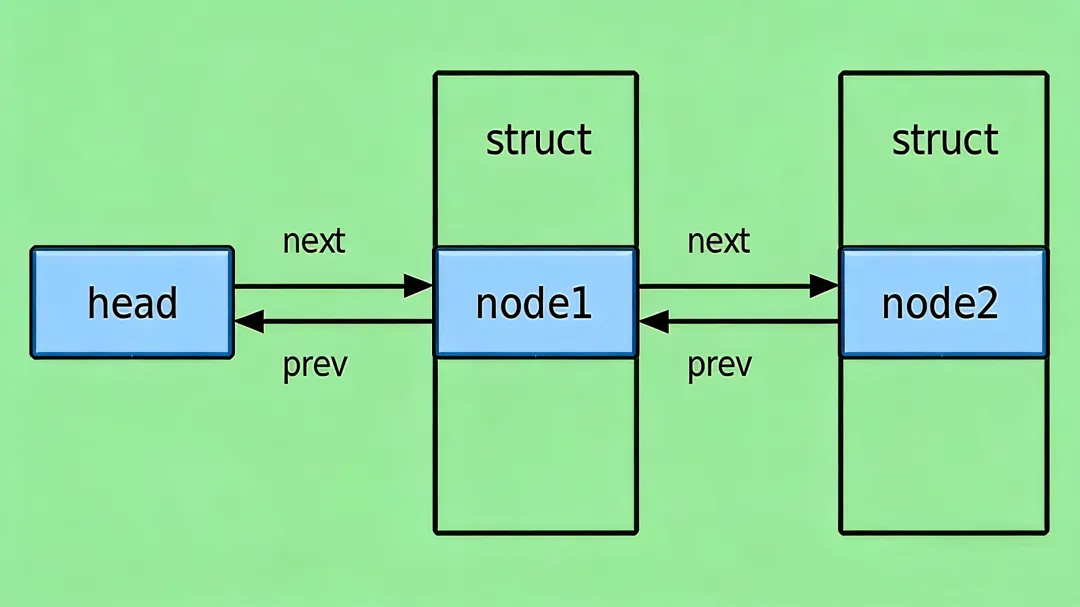
这里,next指针指向链表中的下一个节点,prev指针则指向前一个节点 。值得注意的是,list_head结构体中没有任何数据域,这与我们常见的链表节点定义大相径庭。它的存在,纯粹是为了构建链表的连接关系,就像一座桥梁,只负责连接两岸,而不承载具体的货物 。
在 Linux 内核中,list_head结构体不仅是链表节点的基本构成,更是链表表头的代表。当我们初始化一个链表时,会使用LIST_HEAD宏:
#define LIST_HEAD(name) \ struct list_head name = { &(name), &(name) }
通过这个宏定义的链表头,其next和prev指针都指向自身,形成了一个自引用的循环双向链表。这意味着,即使链表中暂时没有任何数据节点,它依然是一个完整的链表结构,只是其中的节点数量为零而已 。
这种设计带来了诸多好处。一方面,极简的list_head结构体极大地节省了内存空间,尤其在内存资源紧张的内核环境中,每一个字节的节省都意义重大。另一方面,将链表的维护逻辑与数据类型彻底分离,使得链表操作更加通用和灵活。无论内核中需要管理何种类型的数据,都可以借助list_head结构体构建链表,而无需为不同数据类型重复编写链表操作代码 。
2.2 关键创新:数据结构嵌入链表节点,而非相反
传统链表的设计思路是将数据直接封装在链表节点内部,形成 “节点包含数据” 的结构模式。这种模式虽然直观,但却限制了链表的通用性。而 Linux 内核双向链表则反其道而行之,采用了 “数据包含节点” 的创新设计。
具体来说,Linux 内核通过将list_head结构体作为成员变量,嵌入到任意用户自定义的数据结构体中。例如,假设我们有一个表示进程描述符的结构体task_struct,可以这样定义:
struct task_struct { // 进程ID pid_t pid; // 进程名称 char name[16]; // 其他进程相关的业务字段 // ... // 用于链表连接的节点 struct list_head list;};
在这个结构体中,list字段就是一个list_head类型的成员,它为task_struct结构体提供了接入链表的能力。通过这种方式,任何数据结构,只要包含list_head成员,都可以被视为链表的一个节点,从而方便地进行链表操作,如插入、删除和遍历等 。
这种设计思路的转变,彻底打破了数据类型与链表操作之间的束缚。无论数据结构多么复杂,无论其包含何种类型的数据,都可以通过统一的链表接口进行管理。这就好比为所有的数据结构提供了一个通用的 “挂钩”,使得它们能够轻松地挂接到链表这根 “绳子” 上,实现了链表操作的高度抽象和复用 。
Linux 内核双向链表能够实现数据与链表节点的灵活关联,离不开两个关键宏的支持:offsetof和container_of。这两个宏堪称链表实现的 “幕后英雄”,它们协同工作,完成了从链表节点到完整数据结构体的 “神奇转换” 。
offsetof宏的定义如下:
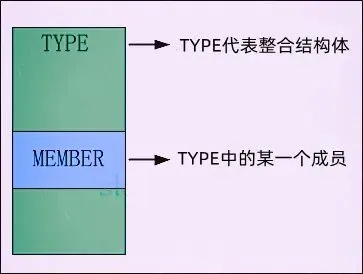
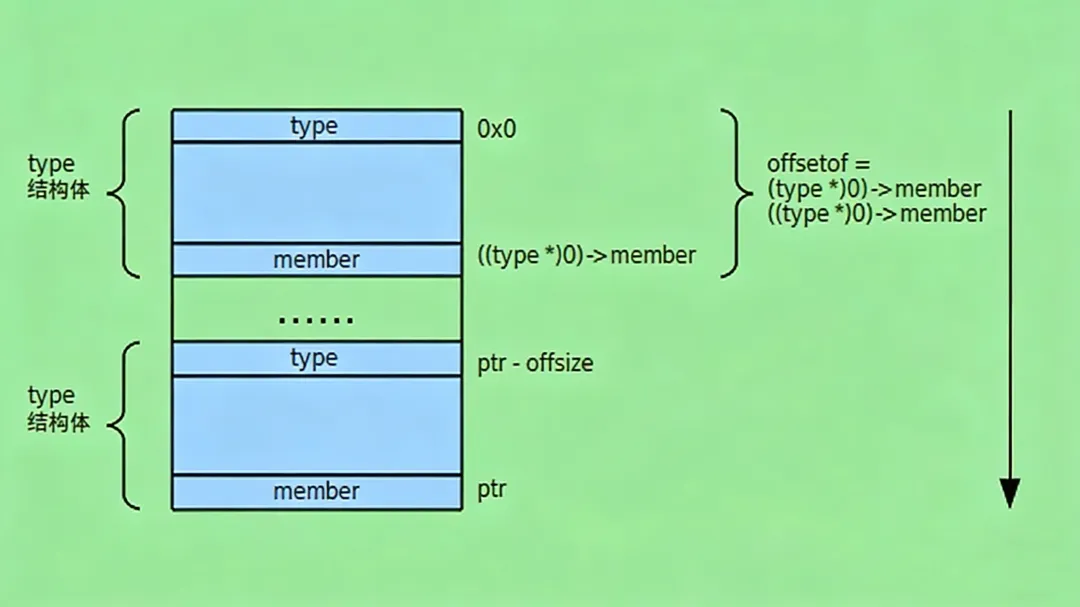
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
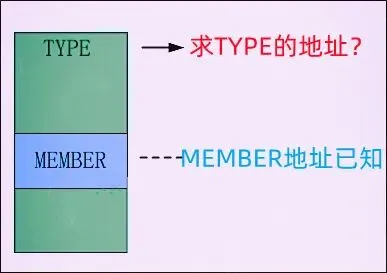
它的作用是计算MEMBER成员在TYPE类型结构体中的偏移量。其原理是通过将TYPE类型的指针强制转换为 0 地址,然后访问MEMBER成员,从而得到该成员在结构体中的相对地址,即偏移量 。
container_of宏则基于offsetof宏的结果,实现了从链表节点指针到完整数据结构体指针的反向推导,定义如下:
#define container_of(ptr, type, member) ({\ consttypeof( ((type *)0)->member ) *__mptr = (ptr);\ (type *)( (char *)__mptr - offsetof(type,member) );})
这里,ptr是指向list_head节点的指针,type是包含list_head成员的数据结构体类型,member是list_head成员在type结构体中的名称 。
例如,在前面定义的task_struct结构体中,如果我们已知一个指向list节点的指针list_ptr,想要获取对应的task_struct结构体指针,可以这样使用container_of宏:
struct list_head *list_ptr;// 假设list_ptr已经指向某个链表节点struct task_struct *task_ptr = container_of(list_ptr, struct task_struct, list);
通过这种方式,container_of宏利用list_head节点的地址和偏移量,准确地计算出了task_struct结构体的起始地址,从而让我们能够从链表节点访问到完整的数据内容 。
offsetof和container_of宏的精妙设计,是 Linux 内核链表实现泛型能力的关键所在。它们为链表操作提供了底层的技术支撑,使得内核能够在不依赖具体数据类型的前提下,高效地管理各种数据结构,真正实现了链表与数据的 “无缝对接”。
三: 极简高效的核心操作:内核级 API 的 “工具箱”
3.1 链表初始化
在 Linux 内核中,双向链表的初始化操作堪称简洁高效的典范,主要通过两种方式实现,分别是宏定义和函数调用。
第一种方式是利用LIST_HEAD宏,它可以直接定义并初始化一个链表头,语法如下:
这行代码等价于:
struct list_head my_list = { &my_list, &my_list };
通过这种方式,my_list的next和prev指针都指向自身,形成了一个自引用的循环链表,即一个空链表 。这种初始化方式非常适合在代码中静态地定义链表,例如在定义全局变量时使用,它简洁明了,并且在编译时就完成了初始化,没有额外的运行时开销 。
第二种方式是使用INIT_LIST_HEAD函数,用于动态地初始化一个已经存在的list_head变量,函数定义如下:
staticinlinevoidINIT_LIST_HEAD(struct list_head *list){ WRITE_ONCE(list->next, list); WRITE_ONCE(list->prev, list);}
在使用时,我们可以这样调用:
struct list_head my_list;INIT_LIST_HEAD(&my_list);
这种方式通常用于在函数内部动态创建链表时,先定义一个list_head变量,然后通过INIT_LIST_HEAD函数进行初始化 。无论是宏定义还是函数调用,初始化后的链表头都处于一种特殊的 “自循环” 状态,这为后续的链表操作奠定了基础,使得链表在空状态下也能保持统一的操作接口,大大简化了链表的管理逻辑 。
3.2 增删节点:无需遍历
在 Linux 内核双向链表中,插入节点的操作由list_add和list_add_tail两个函数完成,它们的底层实现都依赖于内核内部的__list_add函数 。__list_add函数的定义如下:
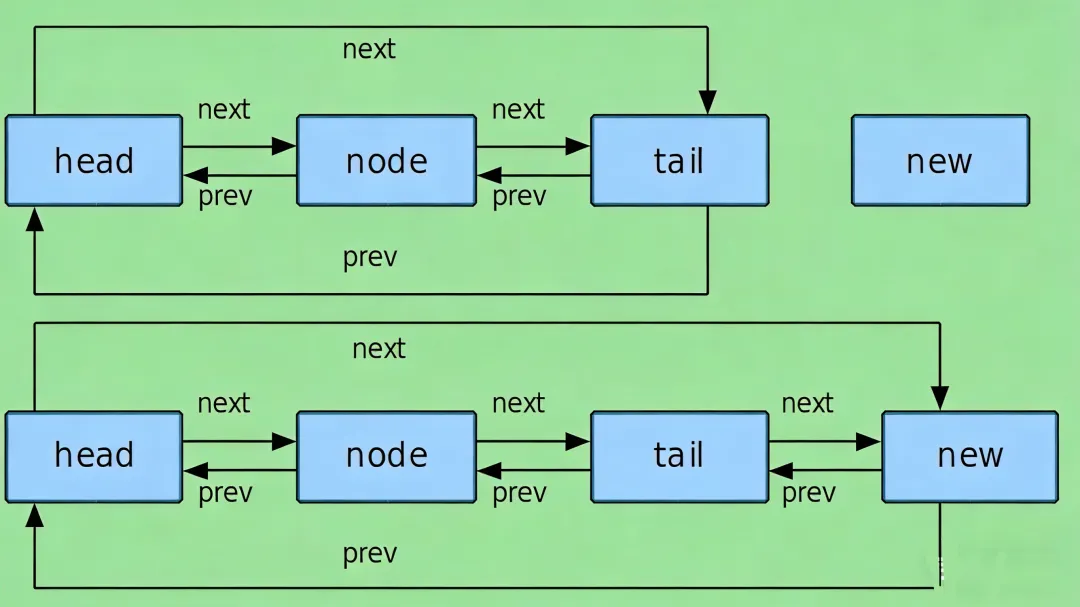
static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next){ next->prev = new; new->next = next; new->prev = prev; prev->next = new;}
这个函数的作用是将新节点new插入到prev和next两个节点之间,通过直接修改指针的指向,高效地完成节点插入操作 。
list_add函数将新节点插入到链表表头之后,也就是头部插入,定义如下:
staticinlinevoidlist_add(struct list_head *new, struct list_head *head){ __list_add(new, head, head->next);}
在实际使用中,假设我们有一个链表头my_list和一个新节点new_node,可以这样调用list_add函数:
list_add(&new_node, &my_list);
这样,new_node就被插入到了my_list表头之后,成为链表的第一个有效节点 。
list_add_tail函数则将新节点插入到链表表头之前,即尾部插入,定义如下:
staticinlinevoidlist_add_tail(struct list_head *new, struct list_head *head){ __list_add(new, head->prev, head);}
同样,使用时可以这样调用:
list_add_tail(&new_node, &my_list);
此时,new_node被插入到了my_list表头之前,成为链表的最后一个节点 。
这两个函数的精妙之处在于,它们在插入节点时都无需遍历整个链表,直接通过修改指针即可完成操作,时间复杂度为 O (1)。这使得链表在处理频繁的节点插入操作时,能够保持极高的效率,充分体现了双向链表在动态数据管理方面的优势 。
当需要从链表中删除节点时,Linux 内核提供了list_del函数,其定义如下:
staticinlinevoidlist_del(struct list_head *entry){ __list_del(entry->prev, entry->next); entry->next = LIST_POISON1; entry->prev = LIST_POISON2;}
这里,__list_del函数负责将待删除节点entry从链表中摘除,通过修改entry前后节点的指针,使其不再指向entry,从而实现节点的删除 。
static inline void __list_del(struct list_head * prev, struct list_head * next){ next->prev = prev; prev->next = next;}
在list_del函数中,删除节点后,还将entry的next和prev指针分别赋值为LIST_POISON1和LIST_POISON2,这两个特殊值通常是内核定义的非法指针值,用于标记该节点已从链表中删除。这样做的目的是为了防止程序在后续操作中误访问已删除的节点,提高代码的安全性和健壮性 。
需要注意的是,list_del函数仅仅断开了节点与链表的链接,并不会释放节点所占用的内存。这是因为在内核中,内存的释放通常需要更谨慎的处理,可能涉及到内存池管理、引用计数等复杂机制。因此,在调用list_del函数后,如果节点不再需要,调用者需要手动释放节点的内存 。
另外,内核还提供了list_del_init函数,它在删除节点后会重新初始化该节点的next和prev指针,使其再次指向自身,将节点恢复到初始化时的状态,便于后续重新插入链表 。list_del_init函数的定义如下:
staticinlinevoidlist_del_init(struct list_head *entry){ __list_del_entry(entry); INIT_LIST_HEAD(entry);}
其中,__list_del_entry函数与__list_del函数功能类似,都是用于断开节点与链表的链接 。通过list_del和list_del_init函数,Linux 内核实现了高效且安全的链表节点删除操作,同时兼顾了内存管理的灵活性和代码的健壮性 。
3.3 链表遍历:两种宏定义
3.3.1 list_for_each:遍历链表节点
在 Linux 内核双向链表的操作中,遍历链表是一项常见的任务,list_for_each宏提供了一种基础的遍历方式 。其定义如下:
#define list_for_each(pos, head) \ for (pos = (head)->next; &pos != (head); pos = pos->next)
这里,pos是一个list_head类型的指针,用作遍历的游标;head则是链表头指针 。在使用list_for_each宏时,我们可以这样遍历链表:
struct list_head *pos, *my_list;list_for_each(pos, my_list) { // 在此处对pos指向的节点进行操作}
在循环体中,pos依次指向链表中的每个节点(不包括链表头本身),通过pos我们可以访问到每个节点的next和prev指针,从而对链表结构进行操作 。例如,我们可以统计链表中节点的数量:
struct list_head *pos, *my_list;int count = 0;list_for_each(pos, my_list) { count++;}
然而,list_for_each宏也存在一定的局限性。由于它只能获取到list_head类型的节点指针,无法直接访问到用户自定义数据结构体中的内容。如果我们需要访问用户数据,就必须通过container_of宏进行转换,这无疑增加了代码的复杂性 。此外,在使用list_for_each宏遍历链表的过程中,如果直接删除当前遍历到的节点,会导致后续节点的指针失效,从而引发程序错误 。因此,list_for_each宏更适合那些仅需要对链表结构进行操作,而不涉及用户数据访问和节点删除的场景 。
3.3.2 list_for_each_entry:直接获取用户数据
为了克服list_for_each宏的局限性,Linux 内核提供了更为强大的list_for_each_entry宏,它能够在遍历链表的同时,直接获取到用户自定义数据结构体的指针 。
list_for_each_entry宏的定义如下:
#define list_for_each_entry(pos, head, member) \ for (pos = list_entry((head)->next, typeof(*pos), member); \ &pos->member != (head); \ pos = list_entry(pos->member.next, typeof(*pos), member))
在这个宏定义中,pos是指向用户自定义数据结构体的指针,head是链表头指针,member是list_head类型成员在用户数据结构体中的名称 。例如,对于前面定义的task_struct结构体:
struct task_struct { pid_t pid; char name[16]; struct list_head list;};
我们可以使用list_for_each_entry宏来遍历链表并访问每个task_struct结构体的内容:
struct task_struct *task;struct list_head my_list;list_for_each_entry(task, &my_list, list) { // 直接访问task的成员,如task->pid, task->name}
在循环体中,task直接指向task_struct结构体,我们可以方便地访问其中的pid、name等成员,无需手动进行指针转换,大大提高了代码的可读性和便利性 。
此外,在实际应用中,我们有时需要在遍历链表的过程中删除当前节点,这对于普通的遍历宏来说是非常危险的,容易导致指针失效和程序崩溃 。为了解决这个问题,Linux 内核提供了list_for_each_entry_safe宏,它通过提前保存下一个节点的地址,确保在删除当前节点时,遍历过程不会受到影响 。list_for_each_entry_safe宏的定义如下:
#define list_for_each_entry_safe(pos, n, head, member) \ for (pos = list_entry((head)->next, typeof(*pos), member), \ n = list_entry(pos->member.next, typeof(*pos), member); \ &pos->member != (head); \ pos = n, n = list_entry(n->member.next, typeof(*n), member))
这里,pos是当前遍历的节点指针,n是用于保存下一个节点指针的临时变量 。使用list_for_each_entry_safe宏,我们可以安全地在遍历过程中删除节点:
struct task_struct *task, *next;struct list_head my_list;list_for_each_entry_safe(task, next, &my_list, list) { if (/* 满足某个删除条件 */) { list_del(&task->list); // 释放task的内存或进行其他操作 }}
在上述代码中,即使在删除task节点后,由于next已经提前保存了下一个节点的地址,遍历过程仍然能够顺利进行,不会出现指针错误 。list_for_each_entry和list_for_each_entry_safe宏的出现,极大地丰富了 Linux 内核链表的遍历操作,使得链表在处理复杂业务逻辑时更加灵活和安全 。
四: 实战:双向链表如何管理进程?
Linux中所有进程通过task_struct的tasks成员(list_head类型)组成全局循环链表,链表头为init_task(0号进程)。所有进程管理的核心操作,本质都是对这个链表的增、删、遍历。
前面我们讲完了Linux内核双向链表的设计和API,接下来我们结合真实内核代码片段,拆解双向链表在进程管理中的实战应用——从进程创建时加入链表,到进程遍历、退出时从链表移除,让“理论”落地为可感知的代码逻辑。
4.1 进程创建:新进程如何“加入”全局链表?
在Linux内核的进程管理体系中,双向链表发挥着核心作用,而task_struct结构体则是这一体系的关键枢纽 。每个进程在内核中都由一个task_struct结构体来描述,它就像是进程的 “身份证”,记录了进程的所有关键信息,如进程 ID(PID)、进程状态、内存映射、文件描述符表等 。
在task_struct结构体中,有一个list_head类型的成员,名为tasks,它是实现进程链表的关键 。通过这个成员,所有的task_struct结构体被链接成一个全局的循环双向链表,其中链表的头节点是init_task,也就是 0 号进程,也被称为swapper进程 。这个特殊的进程是系统启动时创建的第一个进程,它在系统运行过程中始终存在,负责管理系统的一些核心资源和调度任务 。
实战核心:新进程插入链表的代码逻辑
当我们调用fork()创建新进程时,内核最终会调用copy_process()函数,其中关键一步就是将新进程的task_struct插入全局进程链表。核心代码片段如下(简化自Linux内核源码):
// 新进程创建的核心函数(简化版)static struct task_struct *copy_process(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs){ struct task_struct *p; // 1. 为新进程分配task_struct结构体(内核中常用slab分配器) p = kmem_cache_alloc(task_struct_cachep, GFP_KERNEL); if (!p) return NULL; // 2. 初始化新进程的tasks链表节点(list_head类型) INIT_LIST_HEAD(&p->tasks); // 3. 其他初始化:设置PID、继承父进程资源、初始化进程状态等 // ...(省略大量初始化逻辑) // 4. 将新进程插入全局进程链表(头部插入或尾部插入,此处用尾部) // init_task.tasks 是全局进程链表的表头 list_add_tail(&p->tasks, &init_task.tasks); return p;}
第一步先为新进程分配task_struct内存,这是进程的“骨架”;
第二步用INIT_LIST_HEAD初始化tasks节点,使其成为自引用的空节点,为后续加入链表做准备;
最后调用list_add_tail,将新进程的tasks节点插入init_task.tasks链表的尾部——这一步就完成了“新进程加入系统全局链表”的核心操作,从此内核就能通过遍历这个链表找到该进程。
补充:遍历所有进程的实战代码
内核提供了for_each_process()宏,其本质就是封装了list_for_each_entry,用于遍历全局进程链表。我们可以用它实现“打印系统中所有进程PID”的功能:
// 遍历所有进程并打印PID(内核模块中可直接使用)void print_all_processes(void){ struct task_struct *p; // for_each_process宏:遍历init_task.tasks链表中的所有task_struct for_each_process(p) { printk(KERN_INFO "Process PID: %d, Name: %s\n", p->pid, p->comm); }}
其中for_each_process的宏定义就是对链表遍历宏的封装,源码如下:
<br class="Apple-interchange-newline"><div></div>#define for_each_process(p) \ list_for_each_entry(p, &init_task.tasks, tasks)
可见,遍历所有进程的底层逻辑,就是我们前面讲的list_for_each_entry——通过init_task.tasks表头,遍历每个task_struct的tasks成员,直接拿到完整的进程描述符。
在 Linux 内核的进程管理体系中,双向链表发挥着核心作用,而task_struct结构体则是这一体系的关键枢纽 。每个进程在内核中都由一个task_struct结构体来描述,它就像是进程的 “身份证”,记录了进程的所有关键信息,如进程 ID(PID)、进程状态、内存映射、文件描述符表等 。
在task_struct结构体中,有一个list_head类型的成员,名为tasks,它是实现进程链表的关键 。通过这个成员,所有的task_struct结构体被链接成一个全局的循环双向链表,其中链表的头节点是init_task,也就是 0 号进程,也被称为swapper进程 。这个特殊的进程是系统启动时创建的第一个进程,它在系统运行过程中始终存在,负责管理系统的一些核心资源和调度任务 。
例如,当一个新进程被创建时,内核会为其分配一个task_struct结构体,并将其tasks成员插入到进程链表中 。具体来说,内核会调用list_add_tail函数,将新进程的tasks节点添加到init_task.tasks的前面,使其成为链表的最后一个节点 。这样,所有进程就通过tasks链表紧密地联系在一起,内核可以方便地对它们进行统一管理和调度 。
通过for_each_process宏,内核可以遍历整个进程链表,对每个进程进行操作。这个宏的实现基于list_for_each_entry宏,它从init_task开始,依次访问链表中的每个task_struct结构体,直到再次回到init_task,从而实现对所有进程的遍历 。在遍历过程中,内核可以检查每个进程的状态、优先级等信息,根据系统的需求进行相应的调度决策 。比如,当系统需要进行进程调度时,内核会遍历进程链表,查找处于可运行状态(TASK_RUNNING)且优先级最高的进程,将 CPU 资源分配给它 。
4.2 运行队列:优先级链表的“精准调度”
在进程调度的实际场景中,Linux 内核引入了运行队列(runqueue)机制,进一步优化了进程的调度效率 。运行队列是一个双向循环链表,它容纳了系统中所有处于可运行状态(TASK_RUNNING)的进程 。
在 Linux 2.6 内核之前,所有可运行进程都被放在同一个链表中 。随着系统中进程数量的增加,这种方式会导致调度开销急剧增大,因为每次调度时都需要遍历整个链表来寻找最高优先级的进程 。为了解决这个问题,Linux 2.6 内核引入了一种新的运行队列机制,为每个优先级的进程都建立了一个独立的双向链表 。
每个task_struct结构体中除了tasks成员外,还有一个list_head类型的run_list字段,用于将进程接入到对应优先级的运行队列链表中 。同时,运行队列的数据结构prio_array_t包含了多个关键字段,其中nr_active表示链表中进程描述符的数量,bitmap是一个优先权位图,用于快速判断某个优先级的进程链表是否为空,queue则是一个包含 140 个优先权队列头结点的数组,每个头结点对应一个优先级的链表 。
核心1:进程入队(加入运行队列)
当进程从睡眠状态被唤醒(如等待的IO完成),会进入可运行状态,内核调用enqueue_task()将其加入对应优先级的运行队列。核心代码如下(简化版):
// 进程入队:将进程加入运行队列的对应优先级链表void enqueue_task(struct task_struct *p, struct prio_array *array){ // 1. 将进程的run_list节点插入对应优先级的链表尾部 list_add_tail(&p->run_list, &array->queue[p->prio]); // 2. 设置优先级位图中对应位,标记该优先级链表非空 __set_bit(p->prio, array->bitmap); // 3. 更新运行队列中活跃进程数量 array->nr_active++; // 4. 记录进程所属的运行队列 p->array = array;}
核心操作是list_add_tail(&p->run_list, &array->queue[p->prio]):根据进程的优先级p->prio,找到运行队列中对应的链表(array->queue[p->prio]),将进程的run_list节点插入尾部;
设置bitmap是为了后续调度时快速定位到“有可运行进程”的最高优先级链表,避免遍历所有优先级,提升调度效率。
核心2:进程出队(退出运行队列)
当进程被调度器选中运行,或进程状态变为非可运行(如调用sleep()),内核会调用dequeue_task()将其从运行队列移除:
// 进程出队:将进程从运行队列中移除void dequeue_task(struct task_struct *p, struct prio_array *array){ // 1. 将进程的run_list节点从链表中删除 list_del(&p->run_list); // 2. 更新运行队列中活跃进程数量 array->nr_active--; // 3. 若该优先级链表为空,清除bitmap中对应位 if(list_empty(&array->queue[p->prio])) { __clear_bit(p->prio, array->bitmap); } // 4. 清空进程所属的运行队列标记 p->array = NULL;}
核心操作是list_del(&p->run_list):直接将进程的run_list节点从对应优先级链表中摘除,这一步是双向链表删除操作的直接应用;
删除后检查该优先级链表是否为空,若为空则清除bitmap对应位,确保调度器不会再扫描空链表,减少无效操作。
核心3:调度器选进程的核心逻辑
调度器(如CFS调度器的前身O(1)调度器)选择下一个要运行的进程时,核心是通过bitmap找到最高优先级的非空链表,再从链表头部取出进程:
// 从运行队列中选择最高优先级的可运行进程(简化版)struct task_struct *pick_next_task(struct prio_array *array){ int highest_prio; struct list_head *head; struct task_struct *p; // 1. 找到bitmap中置位的最高优先级(从0开始,数值越小优先级越高) highest_prio = sched_find_first_bit(array->bitmap); // 2. 找到该优先级对应的链表头 head = &array->queue[highest_prio]; // 3. 从链表头部取出第一个进程(双向链表的优势:O(1)获取) p = list_entry(head->next, struct task_struct, run_list); return p;}
这里的关键逻辑的是:双向链表的“头节点后第一个元素”就是该优先级下最先入队的进程,通过list_entry(封装了container_of)从run_list节点快速拿到完整的task_struct。整个选进程的过程时间复杂度为O(1),完全不受进程数量影响,这也是双向链表+优先级位图设计的精髓所在。
在进程调度的实际场景中,Linux 内核引入了运行队列(runqueue)机制,进一步优化了进程的调度效率 。运行队列是一个双向循环链表,它容纳了系统中所有处于可运行状态(TASK_RUNNING)的进程 。
在 Linux 2.6 内核之前,所有可运行进程都被放在同一个链表中 。随着系统中进程数量的增加,这种方式会导致调度开销急剧增大,因为每次调度时都需要遍历整个链表来寻找最高优先级的进程 。为了解决这个问题,Linux 2.6 内核引入了一种新的运行队列机制,为每个优先级的进程都建立了一个独立的双向链表 。
每个task_struct结构体中除了tasks成员外,还有一个list_head类型的run_list字段,用于将进程接入到对应优先级的运行队列链表中 。同时,运行队列的数据结构prio_array_t包含了多个关键字段,其中nr_active表示链表中进程描述符的数量,bitmap是一个优先权位图,用于快速判断某个优先级的进程链表是否为空,queue则是一个包含 140 个优先权队列头结点的数组,每个头结点对应一个优先级的链表 。
当一个进程进入可运行状态时,内核会调用enqueue_task函数将其插入到对应的优先级链表中 。这个函数首先使用list_add_tail函数将进程的run_list节点添加到queue[p->prio]队列的尾部,然后通过__set_bit函数设置bitmap中对应优先级的位,最后更新进程的array指针,使其指向当前的运行队列 。例如,当一个新进程被创建并进入可运行状态时,内核会根据其优先级将其插入到相应的运行队列链表中 。如果该进程的优先级为 50,那么它将被插入到queue[50]链表的尾部 。
当进程完成运行或状态发生改变时,内核会调用dequeue_task函数将其从运行队列链表中删除 。这个函数会根据进程的优先级,从对应的queue链表中删除其run_list节点,并清除bitmap中相应的位 。比如,当一个进程运行结束或进入睡眠状态时,内核会将其从运行队列链表中删除,以确保只有真正可运行的进程留在队列中 。
在进行进程调度时,内核首先通过bitmap快速定位到最高优先级且非空的链表,然后从该链表的头部取出进程进行调度 。这种基于优先级链表的调度方式,大大提高了调度的效率,使得内核能够在短时间内快速找到最合适的进程运行,充分发挥了双向链表在高效数据管理和调度方面的优势 。同时,结合优先级位图的设计,进一步优化了调度算法的时间复杂度,使得调度操作几乎不受系统中进程数量的影响,始终保持高效稳定的运行 。
五: 双向链表的 “两面性”
5.1 无可替代的优势:通用性、高效性、模块化
Linux 内核双向链表的设计,堪称计算机科学领域的杰作,它以独特的方式展现出无与伦比的通用性、高效性和模块化优势,完美契合了内核复杂而严苛的运行环境。
通用性是 Linux 内核双向链表的核心优势之一,也是其设计的精妙之处。传统链表在 C 语言中,由于缺乏泛型支持,针对不同数据类型需要编写大量重复的代码。而 Linux 内核双向链表通过将链表节点(list_head)嵌入到用户自定义数据结构体中的设计,成功突破了这一困境。无论数据结构体多么复杂,无论其存储的数据是整数、字符串还是复杂的结构体,只要包含list_head成员,就可以轻松地将其纳入链表管理体系 。这就好比为所有数据类型提供了一个统一的 “接口”,使得链表操作不再受限于数据类型的差异,真正实现了一套 API 适配所有数据类型,仿佛为 C 语言赋予了 “伪泛型” 的能力 。
在高效性方面,Linux 内核双向链表同样表现卓越。链表的插入和删除操作是衡量其性能的重要指标,而 Linux 内核双向链表在这方面堪称 “闪电侠”。以插入节点为例,list_add和list_add_tail函数通过直接修改指针的指向,在常数时间 O (1) 内即可完成节点的插入操作,无需遍历整个链表来寻找合适的插入位置 。删除节点时,list_del函数同样通过简单的指针操作,迅速将节点从链表中摘除,并且通过将删除节点的指针标记为特殊值(LIST_POISON1和LIST_POISON2),有效防止了野指针的产生,提高了代码的安全性 。这种高效的增删操作,使得链表在处理动态变化的数据时游刃有余,极大地提高了内核的运行效率 。
此外,链表的遍历操作也非常高效。list_for_each和list_for_each_entry等宏定义提供了简洁而高效的遍历方式,通过直接操作指针,能够快速地访问链表中的每个节点,使得内核在遍历链表进行数据处理时,能够以最少的时间开销完成任务 。
Linux 内核双向链表的设计还高度模块化,这使得链表的维护和扩展变得轻而易举。链表的初始化、节点的增删改查等操作都被封装成独立的宏和函数,这些接口具有清晰的定义和明确的功能,使用者只需了解接口的参数和功能,即可方便地对链表进行各种操作 。这种模块化设计就像是搭建积木,每个模块都有其特定的功能,使用者可以根据需求自由组合,大大提高了代码的可维护性和可复用性 。同时,模块化的设计也使得链表的实现细节对使用者透明,降低了使用者的学习成本和使用难度,使得内核开发者能够更加专注于业务逻辑的实现,而无需过多关注链表的底层实现细节 。
5.2 不可忽视的短板:侵入性
然而,如同任何技术一样,Linux 内核双向链表的设计并非十全十美,它也存在一些不可忽视的短板,主要体现在侵入性和学习成本两个方面 。
侵入性是 Linux 内核双向链表设计中较为明显的一个问题。由于采用了将链表节点嵌入用户数据结构体的设计方式,这就要求用户在定义数据结构体时,必须预先考虑到链表的使用,主动添加list_head类型的成员 。这种设计虽然实现了链表的通用性,但也在一定程度上破坏了数据结构的纯净性,对用户数据结构产生了侵入 。特别是在一些对数据结构原有定义要求严格,或者需要与其他不兼容该设计的数据结构进行交互的场景下,这种侵入性可能会带来一些不便 。例如,当我们需要使用一个已有的第三方库中的数据结构,而该库并未考虑到 Linux 内核链表的嵌入设计时,若要将其纳入链表管理,就需要对第三方库的代码进行修改,这不仅增加了代码的维护难度,还可能会引入兼容性问题 。