AI时代,基础很重要。
只有基础扎实,才能用好AI这个强大的工具。
向大师学习,是夯实基础、精进技术的最好方式之一。
本篇文章我们一起学习OpenCV最核心的数据结构cv::Mat。
一、从一行复制图片对象代码说起
在AI应用开发中经常使用OpenCV,免不了写复制图片对象的代码:
cv::Mat image1 = cv::imread("heavy_image.jpg");cv::Mat image2 = image1; // 这一步,几乎不耗时间,也不占额外内存
为什么几十MB的图像数据,赋值给另一个变量可以快速完成?
这依赖于OpenCV背后那套运行了二十年的**引用计数(Reference Counting)**设计哲学。
二、cv::Mat的「三位一体」设计
2.1 为什么需要这样的设计?
在计算机视觉应用中,图像数据有三大特点:
- 1. 内存占用巨大:一张1920x1080的彩色图像约6MB
如果每次赋值都复制数据:
// 假设每次都深拷贝那很耗费内存和拉跨性能cv::Mat image1 = cv::imread("large.jpg"); // 分配6MBcv::Mat image2 = image1; // 再分配6MB(实际没有)cv::Mat image3 = image2; // 又分配6MB(实际没有)// 总共18MB,但实际只需要6MB!
OpenCV的解决方案:引用计数(Reference Counting)。
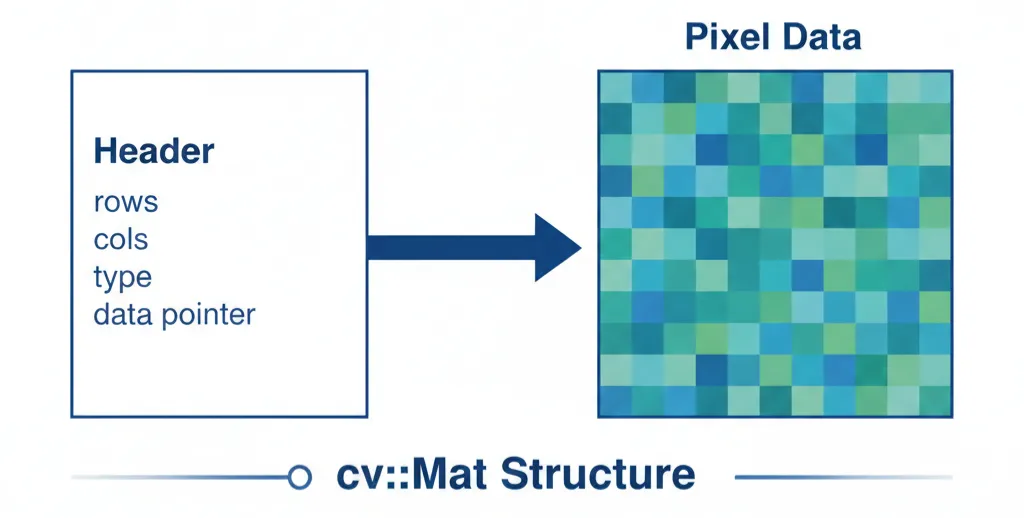
2.2 cv::Mat的结构
在源码中我们可以看到cv::Mat的定义:
// opencv2/core/mat.hppclass CV_EXPORTS Mat {public: // 最重要的三个数据成员 int flags; int dims; int rows, cols; uchar* data; // 指向实际图像数据的指针 UMatData* u; // u->refcount 引用计数器指针 // ... 其他成员};
在 OpenCV 中,cv::Mat 被拆分为两个部分:
- • 矩阵头(Header): 包含行、列、数据类型等元数据。
- • 数据指针(Data Pointer): 指向真正存储像素的内存块。
cv::Mat结构体定义的关键点在于:
三、引用计数的实现艺术
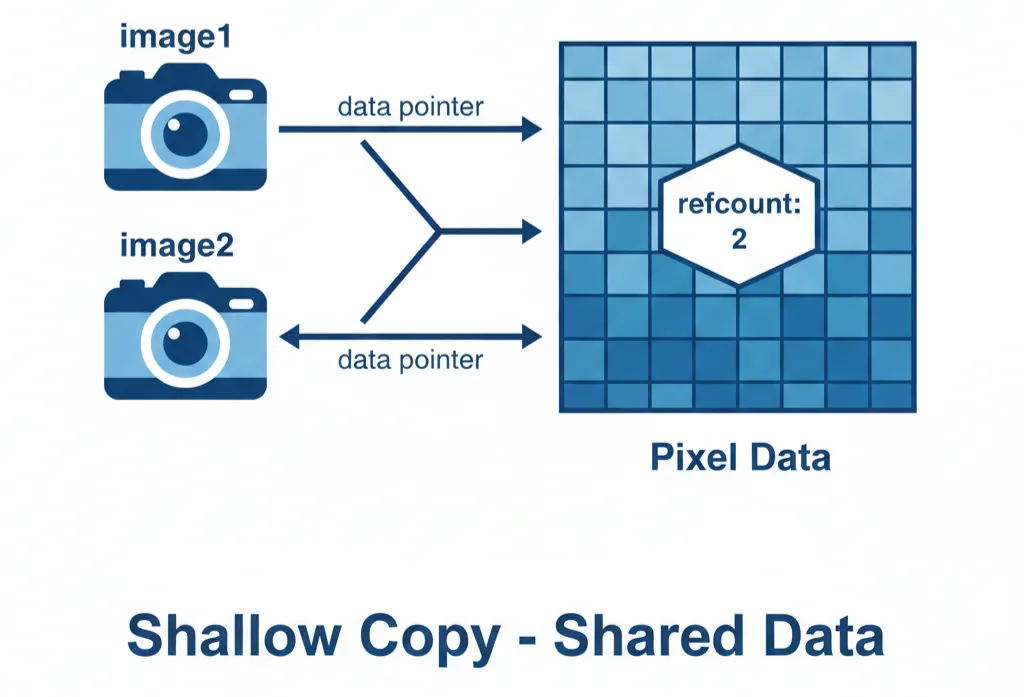
3.1 浅拷贝的智慧
OpenCV引入了经典的设计模式:智能指针与引用计数。
通过一个名为 refcount 的原子变量来管理生命周期。
当我们执行cv::Mat image2 = image1;时:
// mat.hpp 中的拷贝构造函数Mat::Mat(const Mat& m) : flags(m.flags), dims(m.dims), rows(m.rows), cols(m.cols), data(m.data), u(m.u){ if( m.u ) CV_XADD(m.u->refcount, 1); // 原子操作:增加引用计数 // 复制其他信息,但不复制数据! // ...}
另外赋值操作符也有相同的逻辑:
// 赋值操作符重载Mat& Mat::operator = (const Mat& m) { if( m.u ) CV_XADD(m.u->refcount, 1); // 原子操作:增加引用计数 release(); // 释放当前对象旧的引用(计数减1,若为0则真正析构) // 复制 Header flags = m.flags; rows = m.rows; cols = m.cols; data = m.data; u = m.u; return *this;}
这就是浅拷贝(Shallow Copy):只复制指针,不复制数据。配合引用计数管理生命周期。
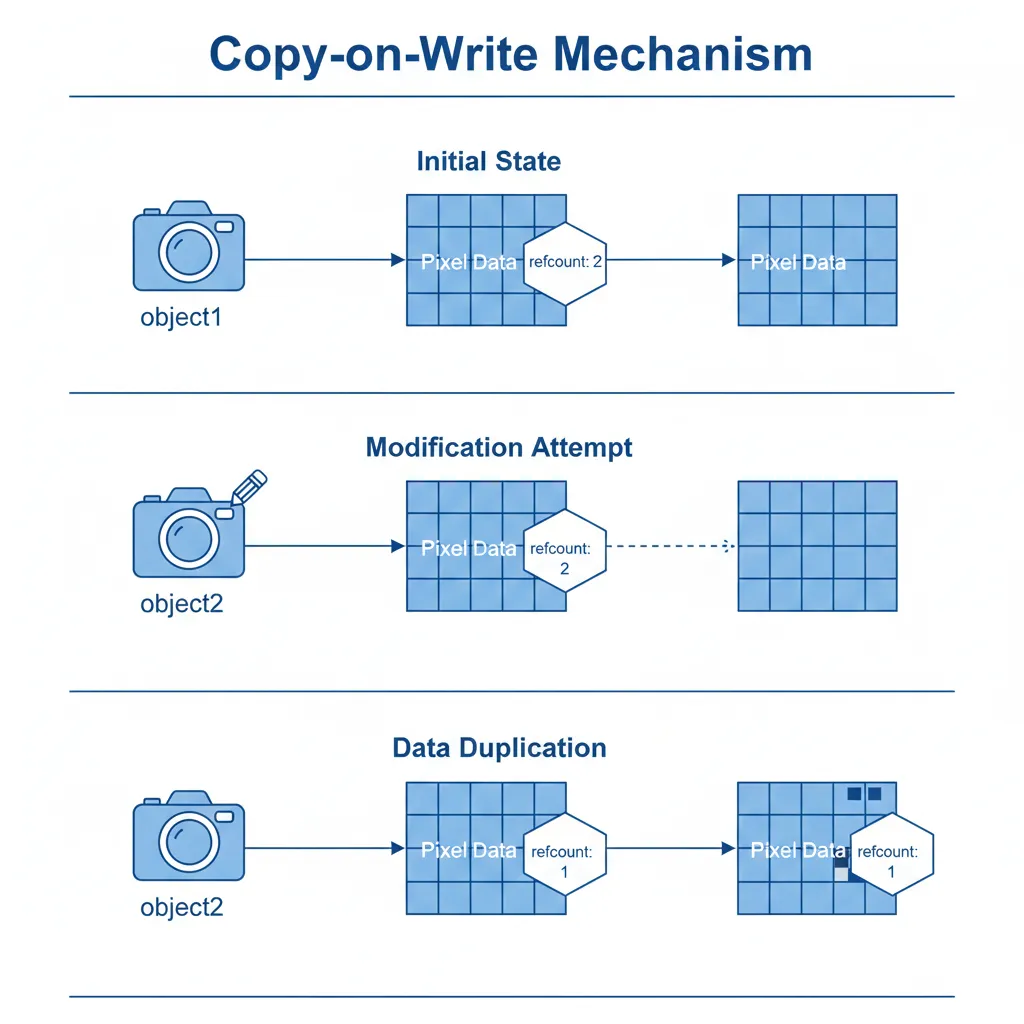
3.2 写时复制(Copy-on-Write)
但问题来了:如果两个Mat共享数据,修改一个会影响另一个,这显然不是用户期望的。OpenCV的解决方案是写时复制:
// 在修改数据前检查是否需要复制void Mat::ensureUniqueData(){ if (u->refcount && CV_XADD(u->refcount, 0) != 1) { // 引用计数大于1,需要复制数据 *this = clone(); // 深拷贝 }}// 实际修改数据的操作都会调用ensureUniqueDatavoid Mat::setTo(const Scalar& s){ ensureUniqueData(); // 关键:写时检查 // ... 实际设置像素值的代码}
写时复制的妙处:
四、设计模式的实战应用
4.1 享元模式(Flyweight Pattern)的完美体现
cv::Mat的设计是享元模式的经典案例:
- • 外在状态:ROI、数据类型等(每个Mat独有)
// 创建ROI(Region of Interest)时特别明显cv::Mat original = cv::imread("photo.jpg");cv::Mat face_roi = original(cv::Rect(100, 100, 200, 200)); // 不复制数据!// face_roi与original共享数据,但有不同的元信息// face_roi有自己的rows、cols,指向原始数据的一部分
4.2 智能指针的早期实现
OpenCV 的设计早于 C++11。在C++11引入std::shared_ptr之前,OpenCV就已经实现了类似的引用计数智能指针。
为了性能和跨平台一致性,它自建了一套原子操作 CV_XADD。这体现了高性能库的原则:核心机制尽量减少对复杂标准库的依赖,以保证执行路径的最短化。
对比一下:
// OpenCV的引用计数(简化版)class MatRefCount { int* refcount; uchar* data;void addref(){ if(refcount) CV_XADD(refcount, 1); }void release(){ if(refcount && CV_XADD(refcount, -1) == 1) { delete[] data; delete refcount; } }};// C++11的shared_ptrstd::shared_ptr<uchar[]> data(new uchar[size]);
OpenCV的实现更复杂但也更灵活,支持部分数据共享(如ROI)。
五、从历史演进看设计哲学
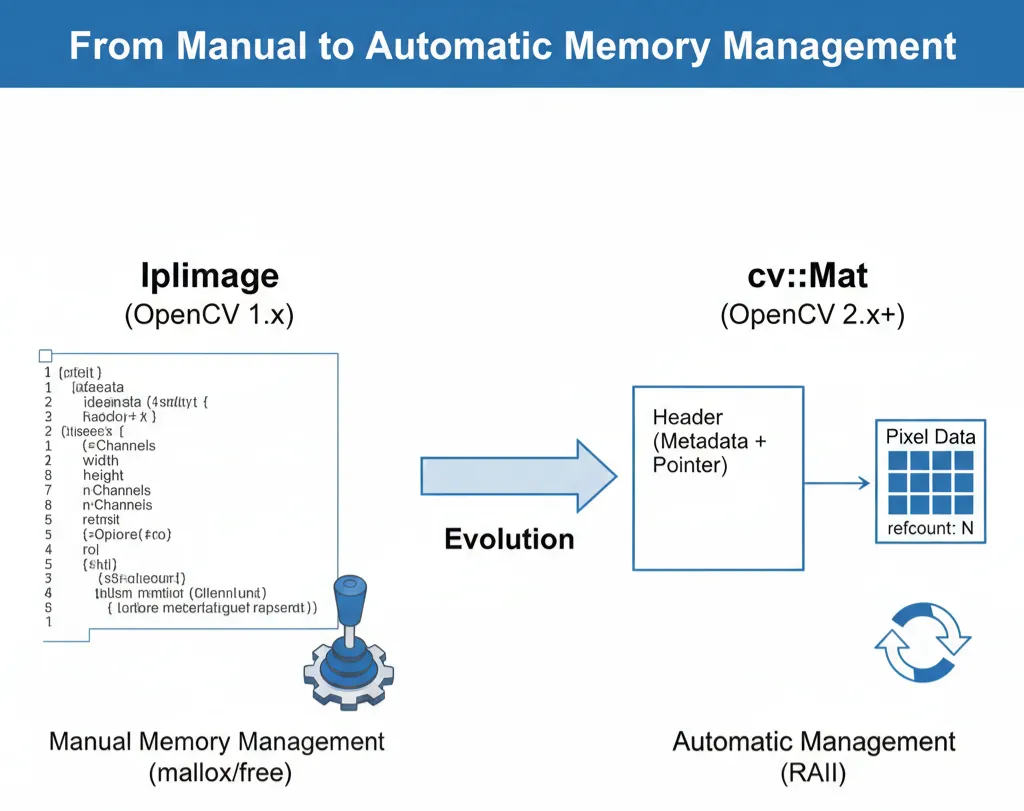
5.1 IplImage的教训
在OpenCV 1.x时代,使用的是C风格的IplImage:
typedefstruct _IplImage { int nSize; int ID; int nChannels; int alphaChannel; int depth; char colorModel[4]; char channelSeq[4]; int dataOrder; int origin; int align; int width; int height;struct _IplROI* roi;struct _IplImage* maskROI; void* imageId;struct _IplTileInfo* tileInfo; int imageSize; char* imageData; // 图像数据 int widthStep; int BorderMode[4]; int BorderConst[4]; char* imageDataOrigin; } IplImage;
问题很明显:
5.2 cv::Mat的革命性改进
cv::Mat在OpenCV 2.0引入,解决了所有这些问题:
六、性能对比:数字说话
让我们用实际数据看看引用计数的优势:
// 测试代码:对比深拷贝和浅拷贝的性能void test_performance(){ cv::Mat large_image(4000, 6000, CV_8UC3); // 72MB图像 auto start = std::chrono::high_resolution_clock::now(); // 场景1:深拷贝(假设cv::Mat没有引用计数) for (int i = 0; i < 1000; i++) { cv::Mat copy = large_image.clone(); // 每次分配72MB // 不使用copy,仅测试拷贝开销 } auto end = std::chrono::high_resolution_clock::now(); auto duration1 = std::chrono::duration_cast<std::chrono::milliseconds>(end - start); start = std::chrono::high_resolution_clock::now(); // 场景2:实际cv::Mat的浅拷贝 for (int i = 0; i < 1000; i++) { cv::Mat ref = large_image; // 只复制指针,不复制数据 // 同样不使用ref } end = std::chrono::high_resolution_clock::now(); auto duration2 = std::chrono::duration_cast<std::chrono::milliseconds>(end - start); std::cout << "深拷贝耗时: " << duration1.count() << "ms" << std::endl; std::cout << "浅拷贝耗时: " << duration2.count() << "ms" << std::endl;}
实测结果:
内存节省:在图像处理流水线中,可能有数十个中间图像,引用计数可以节省90%以上的内存拷贝。
七、提炼可复用的模式:我们能学到什么?
7.1 在你的项目中应用引用计数
不是只有图像处理需要引用计数,任何大型数据都可以受益:
// 通用引用计数模板template<typename T>class RefCounted {private: struct Data { T value; std::atomic<int> refcount{1};template<typename... Args> Data(Args&&... args) : value(std::forward<Args>(args)...) {} }; Data* data;public: // 构造函数、拷贝构造函数、赋值操作符... // 实现引用计数逻辑 // 写时复制访问 T* modify(){ if (data->refcount > 1) { // 需要复制 Data* new_data = new Data(data->value); release(); data = new_data; } return &data->value; }};
7.2 资源共享模式 (Resource Sharing)
当你在处理视频流(如 MPP 产生的 Buffer)时,不要在线程间传递整个数据包。设计一个轻量级的 Header 结构,内部维护一个计数器。
7.3 RAII 机制 (Resource Acquisition Is Initialization)
永远不要让资源裸露在代码中。用类封装资源,在构造函数获取,在析构函数释放。这是嵌入式 Linux 开发中防止内存崩溃的“黄金法则”。
7.4 浅拷贝作为默认行为
在涉及大数据块(音视频、AI 特征向量)时,模仿 OpenCV:
- • 显式提供
.clone() 或 .copyTo() 作为深拷贝(慢,但安全)
7.5 其他注意事项和最佳实践
- 1. 线程安全:OpenCV使用原子操作保证线程安全
- 2. 循环引用:引用计数无法解决循环引用,需要弱指针
- 3. 部分修改:实现时考虑是否支持部分数据的写时复制
八、现代C++的进化
8.1 从cv::Mat到cv::UMat
随着异构计算兴起,OpenCV引入了cv::UMat:
// 统一内存抽象,支持CPU/GPU透明传输cv::UMat image = cv::imread("photo.jpg").getUMat(cv::ACCESS_RW);cv::UMat blurred;cv::GaussianBlur(image, blurred, cv::Size(5, 5), 0); // 可能在GPU执行
cv::UMat保留了cv::Mat的引用计数思想,但扩展到了:
8.2 与std::shared_ptr的融合
现代OpenCV代码可以结合C++11智能指针:
// 安全地传递Mat所有权std::shared_ptr<cv::Mat> create_shared_mat(){ auto mat = std::make_shared<cv::Mat>(cv::imread("photo.jpg")); return mat;}// 双重保护:shared_ptr管理Mat对象,Mat内部管理数据
九、总结:大师的智慧
OpenCV 的 cv::Mat 设计是 C++ 工程实践的巅峰之作。它不仅解决了性能瓶颈,更向我们展示了如何通过优秀的架构设计,让底层的复杂性在 API 层面对开发者透明。
cv::Mat大师级的设计给我们上了深刻的一课:
- 2. 平衡性能与正确性:引用计数+写时复制找到完美平衡点
- 3. 渐进式演进:从IplImage到Mat再到UMat,持续改进
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
