为了更好地理解并发在 Python 世界中如何工作,我们首先需要了解线程和进程工作的基础知识。然后我们将研究如何使用它们进行多线程和多进程以并发地做工作。让我们从进程和线程的一些定义开始。
进程是一个运行的应用程序,它有一个其他应用程序无法访问的内存空间。创建 Python 进程的一个例子是运行一个简单的“hello world”应用程序,或在命令行键入 python 启动 REPL(读取求值打印循环)。
多个进程可以在一台机器上运行。如果我们在一台具有多核 CPU 的机器上,我们可以同时执行多个进程。如果我们在一台只有一个核心的 CPU 上,我们仍然可以通过时间片同时运行多个应用程序。当操作系统使用时间片时,它会在一定时间后自动切换正在运行的进程。确定这种切换发生时间的算法因操作系统而异。
线程可以被看作是更轻量级的进程。此外,它们是可以被操作系统管理的最小构造。它们不像进程那样有自己的内存;相反,它们共享创建它们的进程的内存。线程与创建它们的进程相关联。一个进程总是至少有一个与之关联的线程,通常称为主线程。一个进程也可以创建其他线程,这些线程更常被称为工作线程或后台线程。这些线程可以与主线程并发执行其他工作。与进程类似,线程可以在多核 CPU 上并排运行,操作系统也可以通过时间片在它们之间切换。当我们运行一个普通的 Python 应用程序时,我们创建一个进程以及一个负责运行我们 Python 应用程序的主线程。
清单 1.2 简单 Python 应用程序中的进程和线程
import osimport threadingprint(f'Python process running with process id: {os.getpid()}')total_threads = threading.active_count()thread_name = threading.current_thread().nameprint(f'Python is currently running {total_threads} thread(s)')print(f'The current thread is {thread_name}')
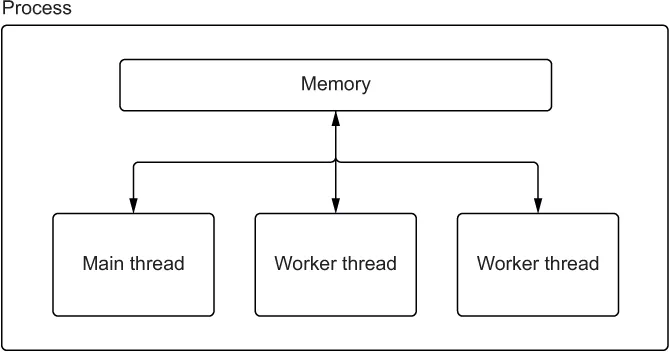
在图 1.3 中,我们绘制了清单 1.2 的进程。我们创建一个简单的应用程序来展示主线程的基础知识。我们首先获取进程 ID(进程的唯一标识符)并打印它,以证明我们确实有一个专用进程在运行。然后我们获取活动线程数以及当前线程的名称,以显示我们正在运行一个线程——主线程。虽然进程 ID 每次运行这段代码都会不同,但运行清单 1.2 会给出类似以下的输出:
Python process running with process id: 98230Python currently running 1 thread(s)The current thread is MainThread
进程也可以创建其他共享主进程内存的线程。这些线程可以通过所谓的多线程为我们并发执行其他工作。
import threadingdef hello_from_thread(): print(f'Hello from thread {threading.current_thread()}!')hello_thread = threading.Thread(target=hello_from_thread)hello_thread.start()total_threads = threading.active_count()thread_name = threading.current_thread().nameprint(f'Python is currently running {total_threads} thread(s)')print(f'The current thread is {thread_name}')hello_thread.join()
图 1.4 一个多线程程序,有两个工作线程和一个主线程,每个都共享进程的内存
在图 1.4 中,我们绘制了清单 1.3 的进程和线程。我们创建一个方法来打印当前线程的名称,然后创建一个线程来运行该方法。然后我们调用线程的 start 方法开始运行它。最后,我们调用 join 方法。join 将导致程序暂停,直到我们启动的线程完成。如果我们运行前面的代码,我们将看到类似以下的输出:
Hello from thread <Thread(Thread-1, started 123145541312512)>!Python is currently running 2 thread(s)The current thread is MainThread
请注意,运行此代码时,您可能会看到 hello from thread 和 python is currently running 2 thread(s) 消息打印在同一行。这是一个竞态条件;我们将在下一节以及第 6 章和第 7 章中进一步探讨这一点。
多线程应用程序是在许多编程语言中实现并发性的常见方式。然而,在 Python 中利用线程实现并发存在一些挑战。由于受到全局解释器锁的限制(将在第 1.5 节讨论),多线程仅适用于 I/O 密集型工作。
多线程并不是我们实现并发的唯一方式;我们也可以创建多个进程来为我们并发工作。这被称为多进程。在多进程中,父进程创建一个或多个它管理的子进程。然后它可以向子进程分发工作。
Python 为我们提供了 multiprocessing 模块来处理这个问题。API 与 threading 模块类似。我们首先用 target 函数创建一个进程。然后,我们调用它的 start 方法来执行它,最后调用它的 join 方法等待它完成运行。
import multiprocessingimport osdef hello_from_process(): print(f'Hello from child process {os.getpid()}!')if __name__ == '__main__': hello_process = multiprocessing.Process(target=hello_from_process) hello_process.start() print(f'Hello from parent process {os.getpid()}') hello_process.join()
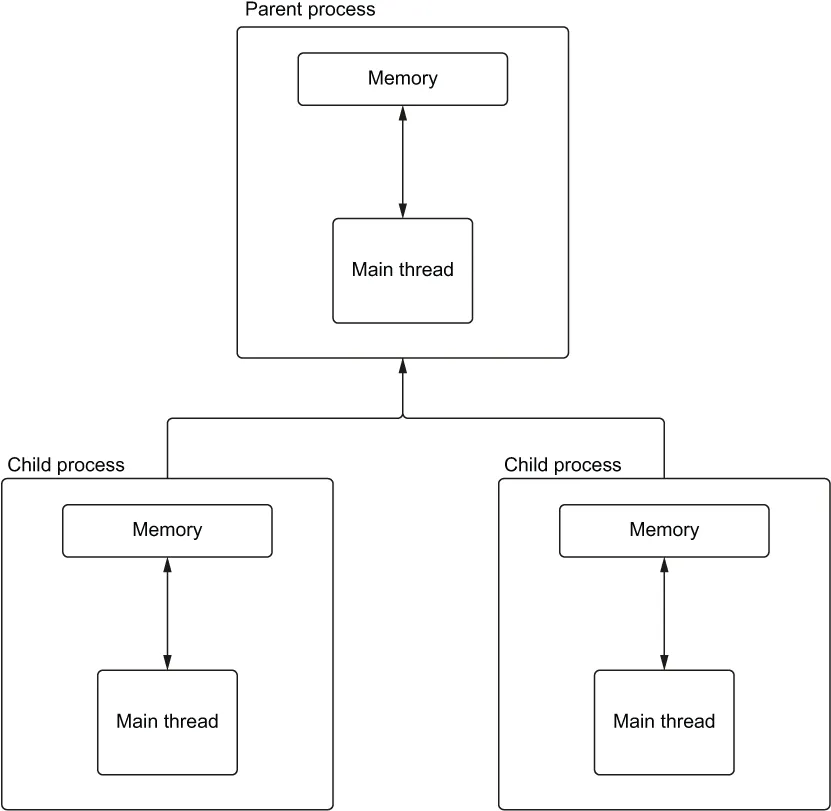
图 1.5 一个使用多进程的应用程序,有一个父进程和两个子进程
在图 1.5 中,我们绘制了清单 1.4 的进程和线程。我们创建一个打印其进程 ID 的子进程,并且还打印出父进程 ID 以证明我们正在运行不同的进程。多进程通常最适合我们有 CPU 密集型工作的情况。
多线程和多进程可能看起来像是实现 Python 并发的灵丹妙药。然而,这些并发模型的能力受到 Python 一个实现细节——全局解释器锁的阻碍。