在Linux系统中,网络子系统是连接分布式应用、支撑高并发服务的核心模块,其工作原理涉及协议栈、数据处理流程及性能优化等多个维度。本文将基于Linux网络的底层逻辑,从网络模型、协议栈架构、数据收发流程到性能指标与观测工具,全面拆解Linux网络基础,为后续性能优化与问题排查筑牢根基。
一、网络模型:从OSI到TCP/IP的落地
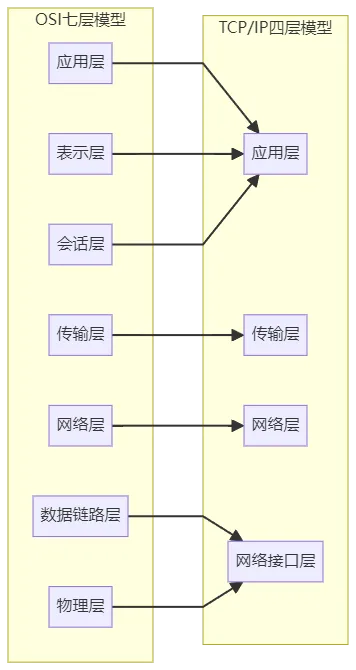
谈到网络通信,必然绕不开网络模型的分层思想。国际标准化组织提出的OSI七层模型,将网络互联框架分为物理层、数据链路层、网络层、传输层、会话层、表示层、应用层,通过分层解耦解决异构设备的兼容性问题,每层承担特定功能:物理层负责数据帧的物理传输,数据链路层处理MAC寻址与错误侦测,网络层实现路由转发,传输层保障端到端通信,而上三层则聚焦应用程序的接口、数据格式与连接维护。
但OSI模型过于复杂,缺乏可落地性,实际Linux系统中采用的是更实用的TCP/IP四层模型。该模型对OSI模型进行了简化,整合为应用层、传输层、网络层、网络接口层,各层功能清晰且贴合工程实现:
应用层:为用户提供具体应用协议,如HTTP(RFC 2616,HTTP/1.1标准)、FTP(RFC 959,文件传输协议)、DNS(RFC 1034/1035,域名系统规范)等,负责封装业务数据并提供人机交互接口。该层协议需基于传输层TCP/UDP实现端到端通信,例如HTTP默认基于TCP 80端口,DNS则同时支持UDP 53端口(查询)与TCP 53端口(zone传输),适配不同业务场景需求;
传输层:实现端到端通信,核心协议为TCP(RFC 793定义的可靠面向连接协议)与UDP(RFC 768定义的无连接协议),为数据添加传输表头,TCP负责可靠性保障与流量控制,UDP仅提供基础端口寻址能力;
网络层:核心协议为IP(RFC 791定义,IPv4核心规范)与ICMP(RFC 792定义,Internet控制报文协议),负责IP包的封装、寻址、路由转发及差错通知,其中IP协议为无连接协议,不保证数据包的交付可靠性;
网络接口层:对应OSI的物理层与数据链路层,核心协议含ARP(RFC 826定义,地址解析协议),负责将IP地址解析为MAC地址,同时执行帧校验、错误侦测,最终通过网卡传输网络帧;
需注意,日常交流中常提及的“七层负载均衡”“四层负载均衡”,实际对应OSI模型的应用层与传输层,映射到TCP/IP模型则为应用层与网络层,这一概念差异需重点区分。
图中高亮层级为负载均衡常涉及的对应层级,清晰呈现OSI与TCP/IP模型的整合逻辑。补充说明:四层负载均衡(对应TCP/IP网络层+传输层)仅基于IP与端口转发流量,典型如LVS的DR模式;七层负载均衡(对应应用层)可解析HTTP、HTTPS等协议内容,支持路径路由、域名转发等高级功能,典型如Nginx、HAProxy,二者均需遵循对应层级的RFC协议规范实现流量调度。
二、Linux网络栈:数据封装与分层处理逻辑
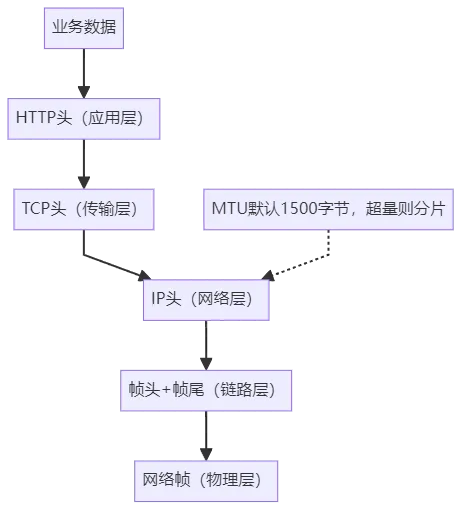
Linux网络栈的设计完全遵循TCP/IP模型,数据在传输过程中会按照“逐层封装、逐层解封装”的逻辑流转。所谓封装,即每一层接收上一层的数据后,在数据前后添加本层的协议头(部分层还会添加尾部),仅增加元数据而不修改原始负载,最终形成可在物理链路传输的网络帧。
以TCP协议通信为例,数据封装流程如下:
应用层:应用程序(如REST API服务)将JSON等业务数据封装为HTTP协议包,传递至传输层;
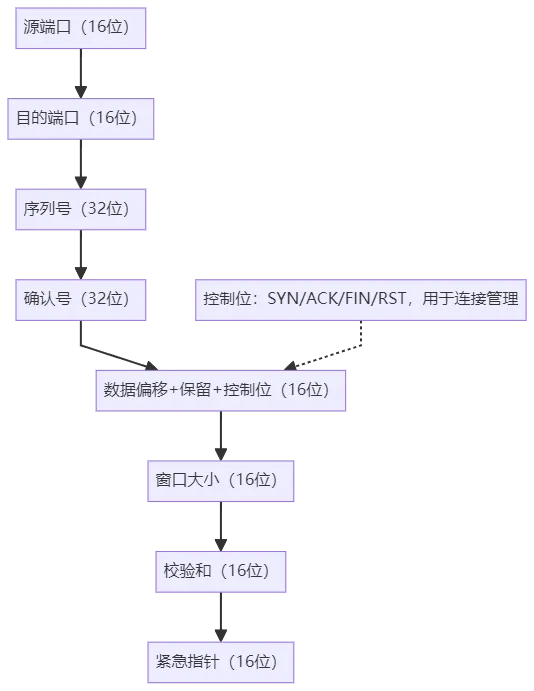
传输层:依据RFC 793标准添加TCP头,固定首部20字节(可选字段最多扩展40字节),包含源端口、目的端口(16位,标识应用进程)、序列号(32位,保障数据有序传输)、确认号(32位,确认已接收数据)、窗口大小(16位,实现流量控制)等核心字段,形成TCP数据包。若采用UDP协议,则添加RFC 768定义的UDP头(仅8字节,含源端口、目的端口、长度、校验和),无可靠性保障但传输效率更高。TCP头格式如下:
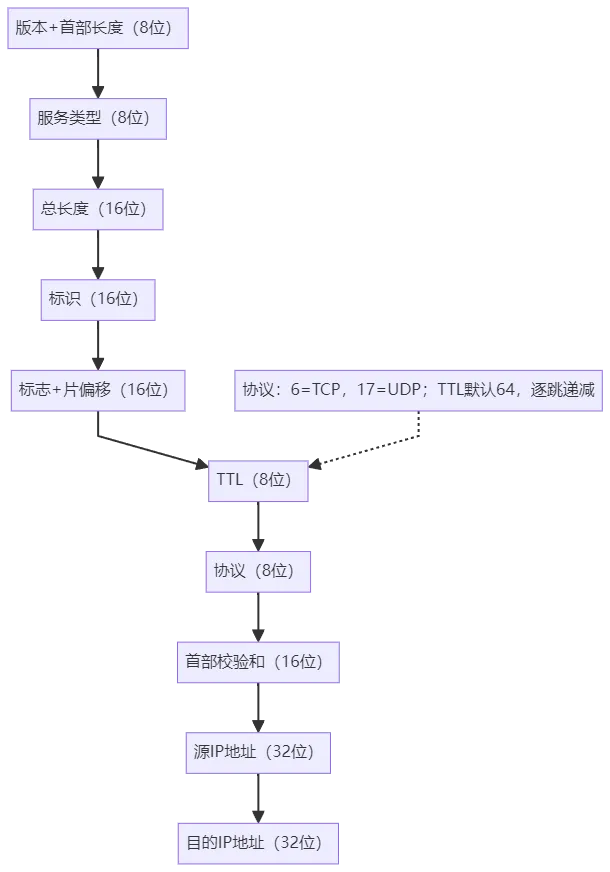
3. 网络层:依据RFC 791标准添加IP头,固定首部20字节,包含源IP、目的IP、TTL(生存时间)、协议类型(标识上层为TCP/UDP)等字段,形成IP数据包,IP协议通过分片机制适配不同链路MTU。IP头格式如下:4. 网络接口层:通过ARP协议(RFC 826)解析下一跳MAC地址,添加帧头(含源/目的MAC)与帧尾(CRC校验码),形成符合以太网规范的网络帧,帧校验码用于验证传输过程中数据是否损坏;以TCP协议为例,数据封装的层级结构与协议头添加逻辑可通过以下mermaid图具象化,同时需关注最大传输单元(MTU):
MTU(最大传输单元)规定了物理链路中可传输的最大IP包大小,以太网默认MTU为1500字节(Linux系统默认值),这一数值符合以太网帧封装规范(以太网帧总长度范围为64-1518字节,除去18字节帧头帧尾,剩余1500字节用于承载IP包)。根据RFC 791,当IP包超过出口链路MTU时,网络层会按MTU大小分片,每个分片携带独立IP头(含分片标识、偏移量、不分片标志),且仅在目标主机重组(路由器不重组分片,避免转发开销)。Linux系统中可通过ip link set dev eth0 mtu 9000配置巨帧MTU(需链路设备支持),减少分片次数以提升吞吐,但需注意跨网络场景下MTU不一致可能导致的丢包问题,可通过路径MTU发现(PMTU,RFC 1191)机制规避。
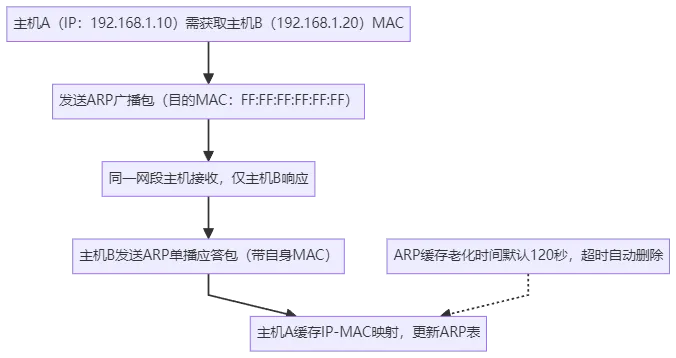
从Linux内核架构看,网络栈自上而下分为四层,完全对齐TCP/IP协议族的RFC标准:应用程序通过Socket API(基于BSD套接字规范)与内核交互,套接字本质是内核维护的“协议+IP+端口”四元组映射表,支撑多进程并发通信。套接字下层为传输层(TCP/UDP,分别遵循RFC 793、RFC 768),TCP模块需实现三次握手、四次挥手、拥塞控制(RFC 5681,TCP BBR等算法基于此扩展)等核心逻辑;网络层(IP/ICMP,遵循RFC 791、RFC 792),IP模块负责路由查找(基于内核路由表)与分片,ICMP模块则用于反馈网络错误(如目标不可达、超时);网络接口层(ARP/链路驱动,ARP遵循RFC 826),ARP缓存默认老化时间为120秒,Linux系统可通过arp -n查看缓存表,通过arp -d 目标IP删除无效条目。最底层为网卡驱动与物理网卡设备,网卡通过DMA(直接内存访问)技术与内存交互,减少CPU拷贝开销,同时通过硬中断通知内核接收数据,协议栈的复杂逻辑(如TCP连接管理、IP路由查找)则交由软中断处理,平衡效率与稳定性,这一设计也契合RFC协议对协议栈分层处理的核心要求。
三、Linux网络收发流程:从网卡到应用程序的流转
网络数据的收发流程是理解Linux网络工作原理的关键,以下以物理网卡为例,拆解接收与发送的完整链路(虚拟网络设备流程略有差异)。
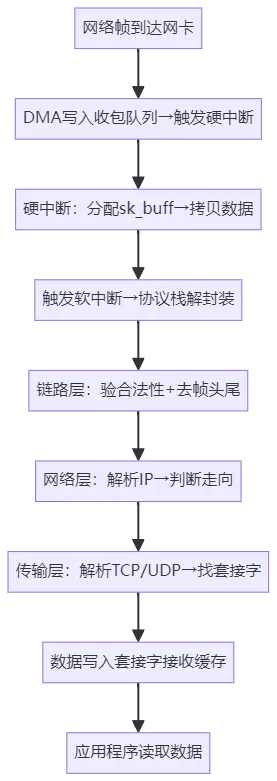
3.1 接收流程:从网卡到应用程序
网络帧到达网卡后,网卡通过DMA将数据写入收包队列,避免CPU拷贝开销,随后触发硬中断通知内核;
硬中断处理程序为网络帧分配sk_buff(内核数据结构,用于存储网络包),并将数据拷贝至sk_buff缓冲区,之后触发软中断,移交后续处理逻辑;
软中断中,内核协议栈从缓冲区取出网络帧,自下而上逐层解封装:链路层校验CRC码(遵循以太网规范)并去掉帧头帧尾,网络层依据RFC 791解析IP头,通过目标IP与路由表判断包的走向(本地接收或转发),若为分片包则先重组;传输层解析TCP/UDP头,TCP需验证序列号、确认号(遵循RFC 793),最终通过“源IP、源端口、目的IP、目的端口”四元组找到对应套接字;
数据被拷贝至套接字的接收缓存,应用程序通过Socket API读取数据。
上述流程图清晰呈现接收流程的核心节点,其中硬中断与软中断的分工是保障效率的关键,硬中断负责快速接收数据(处理耗时极短),软中断处理复杂协议解析逻辑。补充Linux内核优化点:默认情况下,网卡硬中断会绑定到CPU 0,高并发场景下易造成瓶颈,可通过echo 2 > /proc/irq/中断号/smp_affinity将中断均衡分配到不同CPU核心;sk_buff缓冲区大小可通过内核参数net.core.wmem_default(发送缓存默认值)、net.core.rmem_default(接收缓存默认值)调整,避免缓冲区溢出导致丢包。此外,链路层校验CRC码失败的帧会被直接丢弃,相关统计可通过ip -s link show dev eth0查看“errors”字段。
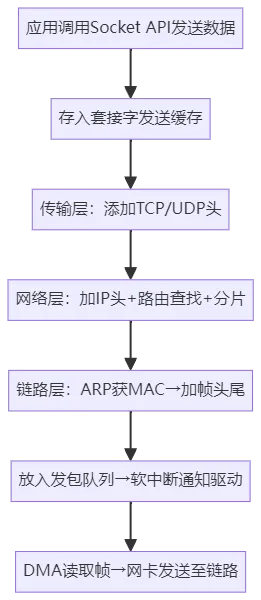
3.2 发送流程:从应用程序到网卡
应用程序调用Socket API(如sendmsg)发送数据,陷入内核态的套接字层,数据被存入套接字发送缓冲区;
内核协议栈自上而下逐层封装数据:传输层添加TCP/UDP头,TCP需基于序列号与确认号维护连接状态(如ESTABLISHED、SYN_SENT),UDP则无状态;网络层添加IP头并执行路由查找(优先匹配主机路由,再匹配网络路由,最后匹配默认路由),确认下一跳IP,根据MTU大小分片(若开启DF标志则禁止分片,对应ICMP不可达错误);
网络接口层依据RFC 826执行ARP查询,获取下一跳MAC地址(若缓存中无对应条目则发送ARP广播),添加帧头帧尾(含CRC校验码),将网络帧放入发包队列,通过软中断通知网卡驱动,确保帧格式符合链路传输标准。ARP工作流程如下:
- 网卡驱动通过DMA从发包队列读取网络帧,通过物理网卡发送至链路。
发送流程中,路由查找与MTU分片是网络层的核心工作,直接影响数据传输的路径合理性与完整性。补充说明:Linux内核路由表可通过ip route show查看,添加静态路由命令为ip route add 目标网段 via 下一跳IP dev 网卡名;若发送队列满(通过ss -tulnp查看Send-Q字段),会导致数据发送阻塞,可通过调整内核参数net.core.somaxconn(监听队列最大值)、net.ipv4.tcp_wmem(TCP发送缓存范围)优化。此外,ARP广播仅在同一广播域内发送,跨网段通信需依赖网关转发,网关IP需配置在对应网卡的路由表中。
四、网络性能指标与观测工具
衡量Linux网络性能需关注核心指标,同时借助专业工具观测数据,定位性能瓶颈。以下梳理关键指标及对应观测工具。
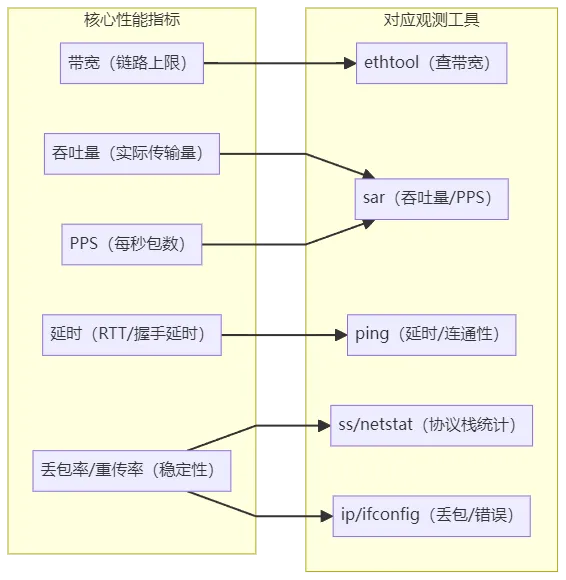
4.1 核心性能指标
带宽:链路最大传输速率,单位通常为b/s(比特/秒),决定网络传输的上限;
吞吐量:单位时间内成功传输的数据量,单位为b/s或B/s,受带宽限制,吞吐量与带宽的比值即为网络使用率;
延时:从请求发出到收到响应的时间,包括TCP握手延时、RTT(往返延时)等;
PPS:每秒传输的网络包数量,用于评估网络转发能力,受包大小影响较大;
其他指标:可用性、并发连接数、丢包率、重传率等,均为判断网络稳定性的重要依据。
核心性能指标的关联逻辑及观测工具对应关系,可通过以下mermaid图梳理,便于快速定位指标与工具的匹配场景:
4.2 常用观测工具
(1)网络配置与状态查询
推荐使用iproute2工具集(net-tools的下一代),功能更丰富,性能更优:
ip -s addr show dev eth0:查看网卡eth0的配置(IP、MAC、MTU)及收发统计(字节数、包数、错误数、丢包数);
ifconfig eth0:兼容旧系统,输出网卡状态、IP、子网掩码等信息,需关注RUNNING标志(表示物理链路连通)。
需重点关注errors、dropped、overruns等指标,非零值通常表示网络I/O问题,如overruns提示Ring Buffer满导致丢包,carrier错误可能源于双工模式不匹配。
(2)套接字与协议栈统计
ss -ltnp:查看监听状态的TCP套接字,显示接收队列、发送队列、进程PID等,接收队列(Recv-Q)非零可能表示包堆积;
netstat -s:查看协议栈详细统计,如TCP主动/被动连接数、重传次数、错误包数等,辅助定位协议层问题。
需注意,监听状态下的Recv-Q表示syn backlog(半连接队列当前值),连接状态下则表示套接字缓存未被应用读取的字节数。
(3)吞吐量与PPS观测
使用sar工具(系统活动报告)可实时查看网络吞吐与PPS:
sar -n DEV 1:每秒输出一次网络接口统计,rxpck/s、txpck/s分别为接收/发送PPS,rxkB/s、txkB/s为接收/发送吞吐量,%ifutil为网络接口使用率。
通过ethtool eth0 | grep Speed可查询网卡带宽(如千兆网卡为1000Mb/s),结合sar输出可计算网络使用率。
(4)连通性与延时测试
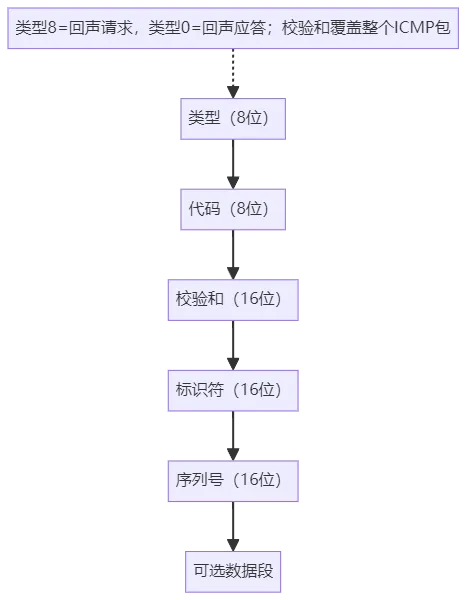
ping -c3 114.114.114.114:基于ICMP协议(RFC 792)的回声请求/应答机制,测试网络连通性与RTT(往返延时),输出丢包率、最小/平均/最大延时,其中ICMP回声包不承载应用数据,仅用于网络可达性与延时探测,是快速排查网络连通性的首选工具。补充实操细节:Linux中ping命令默认发送ICMP回声请求包(类型8,代码0),目标主机回复回声应答包(类型0,代码0);若需指定包大小,可使用ping -s 1024 目标IP(发送1024字节数据的ICMP包),需注意包总大小(数据+ICMP头+IP头)不超过MTU,否则会触发分片。此外,部分网络设备会禁止ICMP包通过,导致ping不通但业务正常,此时可通过telnet 目标IP 端口或nc -zv 目标IP 端口测试端口连通性。ICMP回声包格式如下:
五、总结与延伸
Linux网络的核心逻辑围绕TCP/IP模型展开,从数据的分层封装、协议栈处理到网卡收发,每一步都影响着网络性能。掌握网络模型、协议栈架构及收发流程,是理解网络瓶颈(如中断不均、包丢失、队列堆积)的基础;而熟练使用ip、ss、sar等工具,能快速定位性能问题,为优化提供数据支撑。