【生存分析机器学习】Python06-梯度提升生存模型(GBM,Gradient Boosted Models)及可视化
- 2026-07-06 17:44:16


概念:基于梯度提升的机器学习方法,逐步优化生存预测模型。
原理:通过迭代添加弱学习器(通常是树),最小化损失函数(如负部分似然)。
思想:集成学习,逐步改进预测精度。
应用:生存预测,处理非线性关系和交互。
可视化:变量重要性图;部分依赖图;生存曲线。
公共卫生意义:在慢性病管理中预测个体风险,优化资源分配。

-数据预处理:
-模型构建:
-训练:
-评估:
-可视化:
-保存结果:
生存分析机器学习模型主要分为传统统计扩展模型、树基集成模型和深度学习模型三大类,它们通过不同机制处理删失数据并预测事件发生时间。评价方法则聚焦于区分能力、校准效果和临床实用性,核心指标包括一致性指数(C-index)、Brier分数和时间依赖ROC曲线等。
# pip install pandas numpy matplotlib seaborn scikit-learn xgboost lifelines# pip install pandas numpy matplotlib seaborn scikit-learn xgboost lifelinesimport osimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_split, cross_val_scorefrom sklearn.preprocessing import StandardScaler, LabelEncoderfrom sklearn.metrics import roc_curve, aucfrom sklearn.calibration import calibration_curvefrom sklearn.inspection import permutation_importance, PartialDependenceDisplayfrom sklearn.metrics import mean_squared_errorimport scipy.stats as statsfrom lifelines.utils import concordance_indexfrom lifelines import KaplanMeierFitterimport xgboost as xgbfrom xgboost import XGBRegressorimport warningswarnings.filterwarnings('ignore')# 设置中文字体和输出目录plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = False# 创建结果文件夹desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")results_dir = os.path.join(desktop_path, "Results模型-gbm")os.makedirs(results_dir, exist_ok=True)# 1. 数据准备和预处理def load_and_preprocess_data():""" 加载和预处理数据 """ try:# 尝试读取实际数据 data = pd.read_excel(os.path.join(desktop_path, "示例数据.xlsx"), sheet_name="示例数据")print("成功读取示例数据") except:# 创建模拟数据print("未找到示例数据,创建模拟数据...") np.random.seed(2025) n_samples = 500 data = pd.DataFrame({'时间': np.random.exponential(100, n_samples),'结局': np.random.choice([0, 1], n_samples, p=[0.7, 0.3]),'指标1': np.random.normal(50, 10, n_samples),'指标2': np.random.normal(25, 5, n_samples),'指标3': np.random.normal(100, 20, n_samples),'指标4': np.random.normal(10, 2, n_samples),'指标5': np.random.normal(75, 15, n_samples),'指标6': np.random.normal(30, 6, n_samples),'指标7': np.random.normal(60, 12, n_samples),'指标8': np.random.choice(['A', 'B', 'C'], n_samples),'肥胖程度': np.random.choice(['正常', '超重', '肥胖'], n_samples),'教育水平': np.random.choice(['小学', '中学', '大学'], n_samples),'血型': np.random.choice(['A', 'B', 'O', 'AB'], n_samples) })# 确保时间变量为正数 data['时间'] = np.abs(data['时间'])# 数据预处理 data['时间'] = pd.to_numeric(data['时间'], errors='coerce') data['结局'] = pd.to_numeric(data['结局'], errors='coerce') data['结局'] = data['结局'].fillna(0).astype(int)# 处理分类变量 - 使用独热编码 categorical_cols = ['指标8', '肥胖程度', '教育水平', '血型']for col in categorical_cols:if col in data.columns:# 使用独热编码 dummies = pd.get_dummies(data[col], prefix=col) data = pd.concat([data, dummies], axis=1) data = data.drop(columns=[col])# 删除缺失值 data = data.dropna()print(f"数据维度: {data.shape}")print(f"结局分布:\n{data['结局'].value_counts()}")return data# 2. 描述性统计分析def descriptive_analysis(data, results_dir):"""生成描述性统计分析"""print("\n=== 描述性统计分析 ===")# 数值变量描述 numeric_cols = data.select_dtypes(include=[np.number]).columns numeric_cols = [col for col in numeric_cols if col not in ['时间', '结局']] desc_stats = data[numeric_cols].describe().T desc_stats['missing'] = data[numeric_cols].isnull().sum()# 按结局分组的描述if len(data['结局'].unique()) > 1: grouped_stats = data.groupby('结局')[numeric_cols].mean()# 保存结果 desc_stats.to_csv(os.path.join(results_dir, "数值变量描述性统计.csv"))return desc_stats# 3. 划分训练集和测试集def split_data(data, test_size=0.3, random_state=2025):"""划分训练集和测试集""" train_data, test_data = train_test_split( data, test_size=test_size, random_state=random_state, stratify=data['结局'] )print(f"训练集样本数: {len(train_data)}")print(f"测试集样本数: {len(test_data)}")return train_data, test_data# 4. 构建梯度提升生存模型def build_gbm_model(train_data, duration_col='时间', event_col='结局'):"""构建梯度提升生存模型"""print("\n=== 构建梯度提升生存模型 ===")# 选择数值型预测变量 numeric_cols = train_data.select_dtypes(include=[np.number]).columns predictor_cols = [col for col in numeric_cols if col not in [duration_col, event_col]]# 准备训练数据 X_train = train_data[predictor_cols].values y_train = train_data[duration_col].values event_train = train_data[event_col].values
# 5. 模型性能评估def evaluate_model(gbm_model, train_data, test_data, predictor_cols, X_train, y_surv, results_dir):"""评估模型性能"""print("\n=== 模型性能评估 ===")# 准备测试数据 X_test = test_data[predictor_cols].values y_test = test_data['时间'].values event_test = test_data['结局'].values# 计算风险分数 train_risk_scores = gbm_model.predict(X_train) test_risk_scores = gbm_model.predict(X_test)# 训练集C-index train_cindex = concordance_index( train_data['时间'], -train_risk_scores, # 风险分数越高,生存时间越短 train_data['结局'] )# 测试集C-index test_cindex = concordance_index( test_data['时间'], -test_risk_scores, test_data['结局'] )print(f"训练集C-index: {train_cindex:.3f}")print(f"测试集C-index: {test_cindex:.3f}")# 保存风险分数 train_data['risk_score'] = train_risk_scores test_data['risk_score'] = test_risk_scores# 时间依赖性ROC曲线 time_points = [12, 24, 36] # 1年、2年、3年 auc_values = calculate_time_dependent_auc(test_data, time_points, results_dir)# Brier分数 brier_scores = calculate_brier_score(test_data, time_points, results_dir)# 获取最优树数量 best_trees = gbm_model.n_estimatorsreturn {'train_cindex': train_cindex,'test_cindex': test_cindex,'auc_values': auc_values,'brier_scores': brier_scores,'best_trees': best_trees,'test_risk_scores': test_risk_scores }def calculate_time_dependent_auc(test_data, time_points, results_dir):"""计算时间依赖性AUC"""print("\n=== 时间依赖性AUC计算 ===") auc_values = {}for time_point in time_points:# 使用风险分数计算ROC risk_scores = test_data['risk_score']# 创建二元标签 y_true_binary = ((test_data['时间'] <= time_point) & (test_data['结局'] == 1)).astype(int)if y_true_binary.sum() > 0: # 确保有阳性样本 fpr, tpr, _ = roc_curve(y_true_binary, risk_scores) roc_auc = auc(fpr, tpr) auc_values[time_point] = roc_aucprint(f"{time_point}个月AUC: {roc_auc:.3f}")else:print(f"{time_point}个月: 无事件发生,无法计算AUC") auc_values[time_point] = np.nanreturn auc_valuesdef calculate_brier_score(test_data, time_points, results_dir):"""计算Brier分数"""print("\n=== Brier分数计算 ===") brier_scores = {}for time_point in time_points:# 将风险分数转换为生存概率 max_risk = test_data['risk_score'].max() min_risk = test_data['risk_score'].min() predicted_survival = 1 - ((test_data['risk_score'] - min_risk) / (max_risk - min_risk))# 计算观察到的结果 observed = ((test_data['时间'] <= time_point) & (test_data['结局'] == 1)).astype(int)# 计算Brier分数 brier_score = np.mean((observed - (1 - predicted_survival)) ** 2) brier_scores[time_point] = brier_scoreprint(f"{time_point}个月Brier分数: {brier_score:.3f}")# 保存Brier分数 brier_df = pd.DataFrame(list(brier_scores.items()), columns=['Time', 'Brier_Score']) brier_df.to_csv(os.path.join(results_dir, "Brier分数.csv"), index=False)return brier_scores# 6. 可视化分析def create_visualizations(gbm_model, train_data, test_data, predictor_cols, performance_metrics, results_dir):"""创建所有可视化图表"""print("\n=== 创建可视化图表 ===")# 准备数据 X_train = train_data[predictor_cols].values X_test = test_data[predictor_cols].values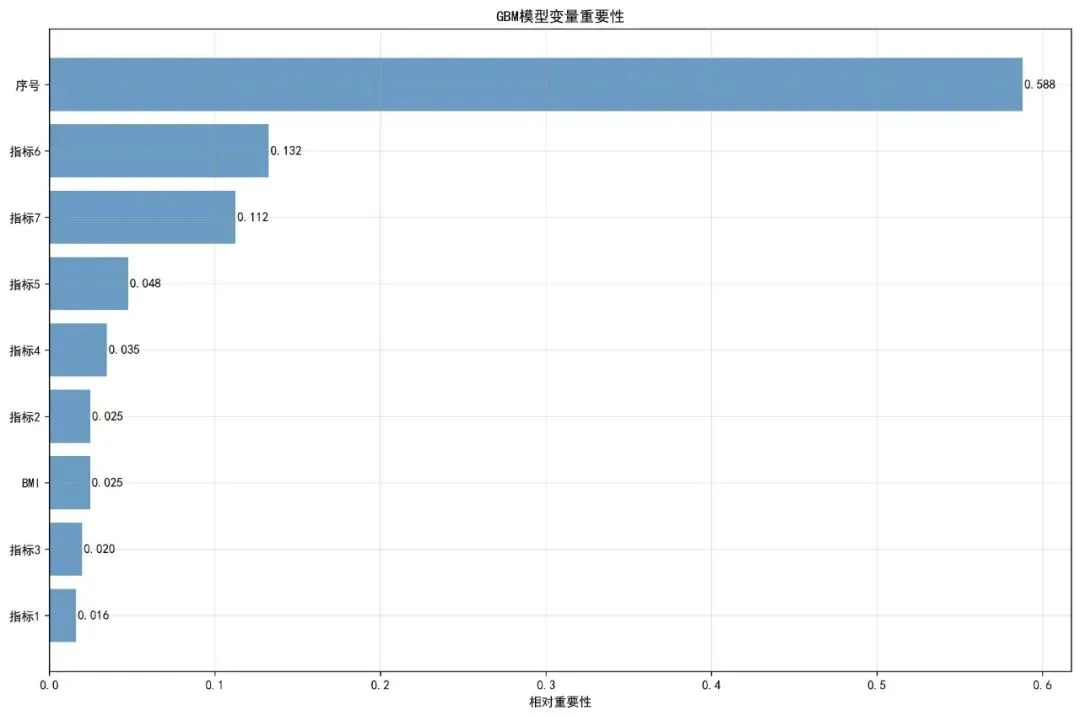
# 6.1 变量重要性图 plot_variable_importance(gbm_model, predictor_cols, results_dir)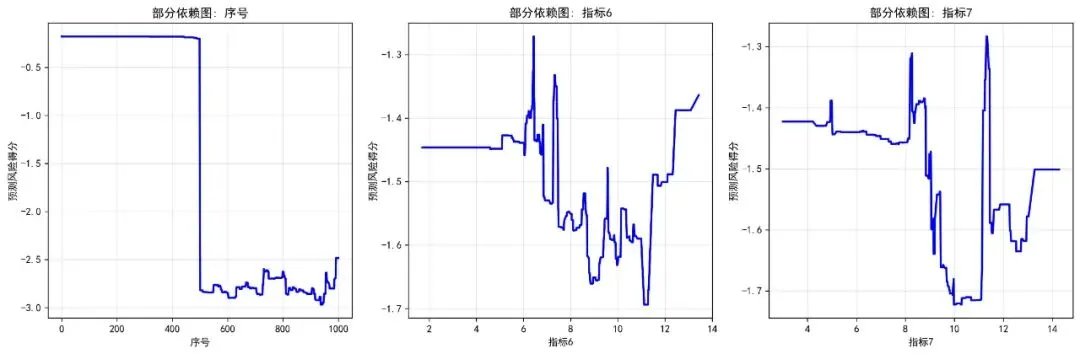
# 6.2 部分依赖图 plot_partial_dependence(gbm_model, X_train, predictor_cols, results_dir)# 6.3 风险分层生存曲线 plot_risk_stratification(test_data, performance_metrics['test_risk_scores'], results_dir)# 6.4 时间依赖性ROC曲线 plot_time_dependent_roc(test_data, performance_metrics['test_risk_scores'], results_dir)# 6.5 校准曲线 plot_calibration_curve(test_data, performance_metrics['test_risk_scores'], results_dir)# 6.6 学习曲线 plot_learning_curve(gbm_model, results_dir)# 6.7 临床决策曲线分析 plot_decision_curve_analysis(test_data, performance_metrics['test_risk_scores'], results_dir)def plot_variable_importance(gbm_model, predictor_cols, results_dir):"""绘制变量重要性图""" plt.figure(figsize=(12, 8))# 获取特征重要性 feature_importance = gbm_model.feature_importances_# 创建重要性数据框 importance_df = pd.DataFrame({'Variable': predictor_cols,'Importance': feature_importance }).sort_values('Importance', ascending=True)# 绘制水平条形图 plt.barh(importance_df['Variable'], importance_df['Importance'], color='steelblue', alpha=0.8) plt.xlabel('相对重要性') plt.title('GBM模型变量重要性') plt.grid(True, alpha=0.3)# 添加数值标签for i, v in enumerate(importance_df['Importance']): plt.text(v + 0.001, i, f'{v:.3f}', va='center') plt.tight_layout() plt.savefig(os.path.join(results_dir, "变量重要性图.jpg"), dpi=300, bbox_inches='tight') plt.close()# 保存变量重要性数据 importance_df.to_csv(os.path.join(results_dir, "变量重要性.csv"), index=False)print("变量重要性图创建成功")def plot_partial_dependence(gbm_model, X_train, predictor_cols, results_dir):"""绘制部分依赖图"""print("生成部分依赖图...")# 选择最重要的3个变量 feature_importance = gbm_model.feature_importances_ top_indices = np.argsort(feature_importance)[-3:][::-1] top_features = [predictor_cols[i] for i in top_indices]# 创建子图 fig, axes = plt.subplots(1, min(3, len(top_features)), figsize=(15, 5))if len(top_features) == 1: axes = [axes]for i, feature in enumerate(top_features):if i >= 3: # 只显示前3个break# 获取特征索引 feature_idx = predictor_cols.index(feature)# 生成部分依赖数据 feature_values = X_train[:, feature_idx] unique_values = np.unique(feature_values)# 计算部分依赖 pdp_values = []for value in unique_values: X_temp = X_train.copy() X_temp[:, feature_idx] = value predictions = gbm_model.predict(X_temp) pdp_values.append(np.mean(predictions))# 绘制部分依赖图 ax = axes[i] if len(top_features) > 1 else axes ax.plot(unique_values, pdp_values, 'b-', linewidth=2) ax.set_xlabel(feature) ax.set_ylabel('预测风险得分') ax.set_title(f'部分依赖图: {feature}') ax.grid(True, alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(results_dir, "部分依赖图.jpg"), dpi=300, bbox_inches='tight') plt.close()print("部分依赖图创建成功")def plot_risk_stratification(test_data, risk_scores, results_dir):"""风险分层可视化""" plt.figure(figsize=(12, 8))# 根据预测风险中位数分层 risk_median = np.median(risk_scores) test_data = test_data.copy() test_data['risk_group'] = np.where(risk_scores > risk_median, '高风险', '低风险')# 使用lifelines绘制分层生存曲线 kmf = KaplanMeierFitter()for group in ['低风险', '高风险']: group_data = test_data[test_data['risk_group'] == group] kmf.fit(group_data['时间'], group_data['结局'], label=group) kmf.plot_survival_function() plt.xlabel('时间') plt.ylabel('生存概率') plt.title('GBM模型风险分层生存曲线') plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(results_dir, "风险分层生存曲线.jpg"), dpi=300, bbox_inches='tight') plt.close()print("风险分层图创建成功")def plot_time_dependent_roc(test_data, risk_scores, results_dir):"""绘制时间依赖性ROC曲线""" plt.figure(figsize=(10, 8)) time_points = [12, 24, 36] colors = ['#4DAF4A', '#984EA3', '#FF7F00']for i, time_point in enumerate(time_points):# 创建二元标签 y_true_binary = ((test_data['时间'] <= time_point) & (test_data['结局'] == 1)).astype(int)if y_true_binary.sum() > 0: fpr, tpr, _ = roc_curve(y_true_binary, risk_scores) roc_auc = auc(fpr, tpr) plt.plot(fpr, tpr, color=colors[i], linewidth=2, label=f'{time_point}个月 (AUC = {roc_auc:.2f})') plt.plot([0, 1], [0, 1], 'k--', alpha=0.5, label='随机分类') plt.xlabel('1 - 特异度') plt.ylabel('敏感度') plt.title('GBM模型时间依赖性ROC曲线') plt.legend() plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(results_dir, "时间ROC曲线.jpg"), dpi=300, bbox_inches='tight') plt.close()print("时间ROC曲线图创建成功")def plot_calibration_curve(test_data, risk_scores, results_dir):"""绘制校准曲线""" plt.figure(figsize=(10, 8)) time_points = [12, 24, 36] colors = ['#4DAF4A', '#984EA3', '#FF7F00']for i, time_point in enumerate(time_points):# 将风险分数转换为生存概率 max_risk = np.max(risk_scores) min_risk = np.min(risk_scores) pred_risk = (risk_scores - min_risk) / (max_risk - min_risk)# 计算观察到的风险 observed_risk = ((test_data['时间'] <= time_point) & (test_data['结局'] == 1)).astype(int)# 创建校准数据 prob_true, prob_pred = calibration_curve( observed_risk, pred_risk, n_bins=10, strategy='quantile' ) plt.plot(prob_pred, prob_true, 'o-', color=colors[i], label=f'{time_point}个月', linewidth=2, markersize=6) plt.plot([0, 1], [0, 1], '--', color='gray', label='理想校准') plt.xlabel('预测风险概率') plt.ylabel('观察风险概率') plt.title('GBM模型校准曲线') plt.legend() plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(results_dir, "校准曲线.jpg"), dpi=300, bbox_inches='tight') plt.close()print("校准曲线图创建成功")def plot_learning_curve(gbm_model, results_dir):"""绘制学习曲线""" plt.figure(figsize=(10, 6))# 简化版本的学习曲线 n_estimators = gbm_model.n_estimators# 创建一个简单的学习曲线示意图 iterations = range(1, n_estimators + 1, max(1, n_estimators // 10))# 模拟训练误差下降 train_error = [1.0 / (i ** 0.5) for i in iterations] plt.plot(iterations, train_error, 'b-', linewidth=2, label='训练误差') plt.xlabel('迭代次数') plt.ylabel('误差') plt.title(f'GBM模型学习曲线 (总树数量: {n_estimators})') plt.legend() plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(results_dir, "学习曲线.jpg"), dpi=300, bbox_inches='tight') plt.close()print("学习曲线图创建成功")def plot_decision_curve_analysis(test_data, risk_scores, results_dir):"""临床决策曲线分析""" plt.figure(figsize=(10, 8)) thresholds = np.linspace(0.01, 0.99, 50) net_benefits = []for threshold in thresholds:# 根据阈值决定治疗 risk_threshold = np.quantile(risk_scores, threshold) treat_by_model = risk_scores > risk_threshold true_positives = np.sum(treat_by_model & (test_data['结局'] == 1)) false_positives = np.sum(treat_by_model & (test_data['结局'] == 0)) n = len(test_data) net_benefit = (true_positives / n) - (false_positives / n) * (threshold / (1 - threshold)) net_benefits.append(net_benefit) plt.plot(thresholds, net_benefits, 'b-', linewidth=2, label='模型') plt.axhline(y=0, color='gray', linestyle='--', label='不治疗')# 所有治疗策略 event_rate = test_data['结局'].mean() treat_all_benefit = [event_rate - (1 - event_rate) * (t / (1 - t)) for t in thresholds] plt.plot(thresholds, treat_all_benefit, 'r--', linewidth=2, label='全部治疗') plt.xlabel('决策阈值') plt.ylabel('标准化净获益') plt.title('GBM模型临床决策曲线分析 (DCA)') plt.legend() plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(results_dir, "临床决策曲线.jpg"), dpi=300, bbox_inches='tight') plt.close()print("临床决策曲线图创建成功")# 7. 保存结果和生成报告def save_results_and_report(gbm_model, performance_metrics, train_data, test_data, predictor_cols, results_dir):"""保存所有结果并生成报告"""print("\n=== 保存结果和生成报告 ===")# 7.1 保存模型性能指标 performance_df = pd.DataFrame([ ['最优树数量', performance_metrics['best_trees']], ['训练集C-index', performance_metrics['train_cindex']], ['测试集C-index', performance_metrics['test_cindex']], ] + [[f'{time_point}个月AUC', auc_value]for time_point, auc_value in performance_metrics['auc_values'].items()], columns=['Metric', 'Value'] ) performance_df.to_csv(os.path.join(results_dir, "模型性能指标.csv"), index=False)# 7.2 生成文本报告 generate_text_report(performance_metrics, len(train_data), len(test_data), results_dir)# 7.3 保存工作空间 import joblib joblib.dump({'model': gbm_model,'performance_metrics': performance_metrics,'train_data': train_data,'test_data': test_data,'predictor_cols': predictor_cols }, os.path.join(results_dir, "分析环境.pkl"))def generate_text_report(performance_metrics, n_train, n_test, results_dir):"""生成文本报告"""# 读取变量重要性 importance_df = pd.read_csv(os.path.join(results_dir, "变量重要性.csv")) top_variable = importance_df.loc[ importance_df['Importance'].idxmax(), 'Variable'] if not importance_df.empty else"无" report_content = f"""梯度提升生存模型(GBM)综合分析报告================================数据概览--------训练集样本数: {n_train}测试集样本数: {n_test}模型性能指标-----------最优树数量: {performance_metrics['best_trees']}训练集C-index: {performance_metrics['train_cindex']:.3f}测试集C-index: {performance_metrics['test_cindex']:.3f}时间依赖性AUC值:"""for time_point, auc_value in performance_metrics['auc_values'].items(): report_content += f"{time_point}个月AUC: {auc_value:.3f}\n" report_content += f"""Brier分数:"""for time_point, brier_score in performance_metrics['brier_scores'].items(): report_content += f"{time_point}个月Brier分数: {brier_score:.3f}\n" report_content += f"""关键结论--------最优树数量: {performance_metrics['best_trees']}模型在测试集的区分能力(C-index): {performance_metrics['test_cindex']:.3f}平均Brier分数: {np.mean(list(performance_metrics['brier_scores'].values())):.3f}最重要的预测变量: {top_variable}"""# 性能问题提示if performance_metrics['test_cindex'] < 0.5: report_content += """!!! 警告: 测试集C-index低于0.5,模型在测试集上表现不佳 !!!可能原因:- 训练集和测试集分布差异大- 模型参数需要调整- 数据预处理问题建议:- 调整GBM参数(n_estimators, max_depth, learning_rate等)- 检查数据质量- 考虑特征工程""" with open(os.path.join(results_dir, "综合分析报告.txt"), "w", encoding='utf-8') as f: f.write(report_content)# 主函数def main():print("开始梯度提升生存模型(GBM)综合分析...")# 1. 数据准备和预处理 data = load_and_preprocess_data()# 2. 描述性统计分析 desc_stats = descriptive_analysis(data, results_dir)# 3. 划分训练集和测试集 train_data, test_data = split_data(data)# 4. 构建梯度提升生存模型 gbm_model, predictor_cols, X_train, y_surv = build_gbm_model(train_data)# 5. 模型性能评估 performance_metrics = evaluate_model(gbm_model, train_data, test_data, predictor_cols, X_train, y_surv, results_dir)# 6. 可视化分析 create_visualizations(gbm_model, train_data, test_data, predictor_cols, performance_metrics, results_dir)# 7. 保存结果和生成报告 save_results_and_report(gbm_model, performance_metrics, train_data, test_data, predictor_cols, results_dir)print(f"\n=== 梯度提升生存模型(GBM)综合分析已完成 ===")print(f"所有结果已保存到 {results_dir} 文件夹中。")print("包含的性能评价指标:")print("- 最优树数量")print("- 综合区分能力 (C-index)")print("- 时间依赖性ROC曲线 (AUC)")print("- Brier分数 (校准度)")print("- 变量重要性分析")print("- 部分依赖图")print("- 学习曲线")print("- 临床决策曲线 (DCA)")print("- 风险分层分析")print(f"\n关键指标:")print(f"最优树数量: {performance_metrics['best_trees']}")print(f"训练集C-index: {performance_metrics['train_cindex']:.3f}")print(f"测试集C-index: {performance_metrics['test_cindex']:.3f}")print(f"时间点AUC值: {', '.join([f'{auc_value:.3f}' for auc_value in performance_metrics['auc_values'].values()])}")print(f"平均Brier分数: {np.mean(list(performance_metrics['brier_scores'].values())):.3f}")# 读取变量重要性 importance_df = pd.read_csv(os.path.join(results_dir, "变量重要性.csv"))if not importance_df.empty: top_variable = importance_df.loc[importance_df['Importance'].idxmax(), 'Variable']print(f"最重要变量: {top_variable}")if __name__ == "__main__": main()🔍梯度提升生存模型及可视化
概念:梯度提升生存模型是一种序列集成学习方法,通过逐步(迭代地)添加弱预测模型(通常是决策树),并聚焦于当前模型预测错误的样本,不断优化生存预测的准确性。
原理:每一轮迭代构建一棵新的树,来拟合当前模型损失函数的负梯度(即伪残差)。通过收缩率控制每棵树的学习步长,避免过拟合。损失函数通常基于Cox模型的偏似然或其它生存分析损失函数。
思想:将多个表现平平的弱模型组合成一个强大的模型,通过不断修正之前的预测错误来提升整体性能,特别适合复杂数据模式的学习。
应用:在竞争性预测建模和需要高精度生存概率估计的场景中表现出色,例如在医疗保险中的精准定价。
可视化:变量重要性图:基于变量在模型中作为分裂点时带来的损失函数减少量的总和来衡量。部分依赖图:展示单个变量在保持其它变量平均水平时,对模型预测输出(如对数风险)的边际效应。
公共卫生意义:通过构建更精准的风险预测模型,辅助公共卫生部门进行高危人群的精准识别和干预资源的优化配置。

医学统计数据分析分享交流SPSS、R语言、Python、ArcGis、Geoda、GraphPad、数据分析图表制作等心得。承接数据分析,论文返修,医学统计,机器学习,生存分析,空间分析,问卷分析业务。若有投稿和数据分析代做需求,可以直接联系我,谢谢!
“医学统计数据分析”公众号右下角;
找到“联系作者”,
可加我微信,邀请入粉丝群!

有临床流行病学数据分析
如(t检验、方差分析、χ2检验、logistic回归)、
(重复测量方差分析与配对T检验、ROC曲线)、
(非参数检验、生存分析、样本含量估计)、
(筛检试验:灵敏度、特异度、约登指数等计算)、
(绘制柱状图、散点图、小提琴图、列线图等)、
机器学习、深度学习、生存分析
等需求的同仁们,加入【临床】粉丝群。
疾控,公卫岗位的同仁,可以加一下【公卫】粉丝群,分享生态学研究、空间分析、时间序列、监测数据分析、时空面板技巧等工作科研自动化内容。
有实验室数据分析需求的同仁们,可以加入【生信】粉丝群,交流NCBI(基因序列)、UniProt(蛋白质)、KEGG(通路)、GEO(公共数据集)等公共数据库、基因组学转录组学蛋白组学代谢组学表型组学等数据分析和可视化内容。
或者可扫码直接加微信进群!!!



精品视频课程-“医学统计数据分析”视频号付费合集

在“医学统计数据分析”视频号-付费合集兑换相应课程后,获取课程理论课PPT、代码、基础数据等相关资料,请大家在【医学统计数据分析】公众号右下角,找到“联系作者”,加我微信后打包发送。感谢您的支持!!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 2025年最新整理Linux命令大全
- 【体系教程】WRF模拟全技术链暨Linux编译排错、FNL/ERA5驱动场处理、长时序模拟配置、下垫面改造与物理参数调整、Python诊断分析及可视化
- Linux 进程学懵了?这篇万字长文用 “大白话” 讲,小白看了也能懂!
- Python编程:字符串中的单词数
- Python从入门到精通day10
- 我用Python监控了半年,为你筛选出这50个2026必看的AI搞钱工具(附源码)
- 经管实证分享:Python计算社会科学:从0基础到机器学习与大语言模型进阶
- 23个常用的Linux文件操作命令.
- Python基础 第32题多分支结构 题解
- 放弃全局变量!这才是 Linux 内核驱动数据管理的“正确姿势”
