RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,通过融合前沿的 RAG 技术与 Agent 能力,为大型语言模型提供卓越的上下文层。它提供可适配任意规模企业的端到端 RAG 工作流,凭借融合式上下文引擎与预置的 Agent 模板,助力开发者以极致效率与精度将复杂数据转化为高可信、生产级的人工智能系统。一、项目总体架构
RAGFlow采用微服务架构,主要包含以下模块:
API模块 - 提供API接口服务
RAG模块 - 核心RAG引擎
Agent模块 - 智能代理组件
Common模块 - 公共工具和组件
Admin模块 - 管理后台
DeepDoc模块 - 文档深度解析
GraphRAG模块- 图谱增强的RAG
Memory模块 - 记忆管理
Plugin模块 - 插件系统
Web模块 - 前端界面
二、核心模块详解
1. API模块
API模块是系统的入口,负责处理外部请求并协调内部各组件。它基于Quart框架构建,提供了完整的认证、授权、错误处理等功能。该模块使用Flasgger集成Swagger UI文档,便于开发者理解和使用API接口。
2. RAG核心模块
RAG(Retrieval-Augmented Generation,检索增强生成)是整个系统的核心。该模块包括:
App层 - 应用程序相关组件
Flow层 - 数据处理流程编排
LLM层 - 大语言模型集成
NLP层 - 自然语言处理组件
Prompts层 - 提示词模板
Svr层 - 向量检索
Utils层 - 实用工具
3. Agent智能代理模块
Agent是RAGFlow的特色功能,提供智能化工作流支持。它实现了多智能体协作模式,允许用户构建复杂的自动化工作流。Agent模块包含:
Canvas - 工作流画布,用于可视化编排
Component - 可复用的功能组件
Templates - 预设的工作流模板
Tools - 集成的各种工具
4. DeepDoc文档深度解析模块
DeepDoc是RAGFlow的文档深度理解模块,具备以下能力:
OCR识别 - 对图像和PDF进行光学字符识别
布局识别 - 识别文档中不同元素的位置(文本、标题、表格、图片等)
表格结构识别 - 解析复杂表格的结构
解析器 - 支持多种格式(PDF、DOCX、EXCEL、PPT)
5. GraphRAG模块
GraphRAG模块提供基于知识图谱的增强检索功能,能够将非结构化的文本转化为结构化的知识图谱,从而提升检索精度和推理能力。
三、组件化工作流设计
RAGFlow采用了高度模块化的工作流设计,每个组件都遵循统一的接口规范。核心基类ComponentBase定义了组件的基本行为:
输入输出 - 定义组件的输入参数和输出结果
异常处理 - 统一的异常处理机制
变量引用 - 支持跨组件的变量引用
状态管理 - 组件执行过程中的状态跟踪
1. 工作流执行机制
工作流通过Pipeline类进行编排执行,实现如下功能:
按照依赖关系顺序执行各个组件
支持异步并发执行提高效率
提供进度跟踪和日志记录
实现任务取消和异常恢复
2. 模板化设计
系统提供了丰富的预设模板,如:
深度研究 - 多智能体协作进行深度研究
客户支持 - 客户服务场景的对话处理
SEO博客生成 - 自动撰写SEO优化文章
SQL助手 - SQL查询生成和优化
四、核心技术特点
1. "质量输入,质量输出"理念
DeepDoc基于深度文档理解技术,能够准确提取复杂格式的非结构化数据,确保高质量的信息输入,从而产生高质量的输出。
2. 模板化分块策略
系统提供了多种分块策略,可以智能地将文档分割成合适的块,同时保持语义完整性,便于后续检索和生成。
3. 引用可追溯性
系统提供可视化的内容分块,支持人工干预,并能追踪答案来源,减少幻觉现象。
4. 异构数据源兼容
支持Word、PPT、Excel、TXT、图片、扫描件、结构化数据、网页等多种数据源格式。
五、代码设计逻辑解析
1. 分层架构
RAGFlow采用了清晰的分层架构:
表现层 - Web前端界面
接口层 - API服务层
业务层 - Agent和RAG业务逻辑
数据层 - 存储和检索服务
基础层 - 通用工具和组件
2. 组件化设计
系统大量使用组件化设计思想,每个组件职责单一,通过标准接口组合实现复杂功能。这种设计提高了系统的可维护性和扩展性。
3. 配置驱动
系统通过配置文件实现灵活部署,支持不同的部署环境和需求。
4. 异常处理机制
系统在多个层面实现了完善的异常处理机制,确保服务的稳定性和可靠性。
六、对初学者的解释
对于初学者来说,可以将RAGFlow理解为一个"智能知识库系统":
知识存储 - 将各种格式的文档上传到系统中
知识理解 - 系统通过DeepDoc技术深度解析文档内容
知识索引 - 将解析后的内容建立索引,方便快速检索
智能问答 - 用户提问时,系统检索相关信息并生成答案
工作流自动化 - 通过Agent实现复杂的业务流程自动化
系统通过先进的AI技术,使机器能够像人类一样理解和运用知识,帮助企业和个人高效地管理和利用知识资源。
总的来说,RAGFlow是一个功能强大、架构清晰、易于扩展的知识管理平台,它将前沿的AI技术与实际应用场景相结合,为用户提供了一站式的知识处理解决方案。
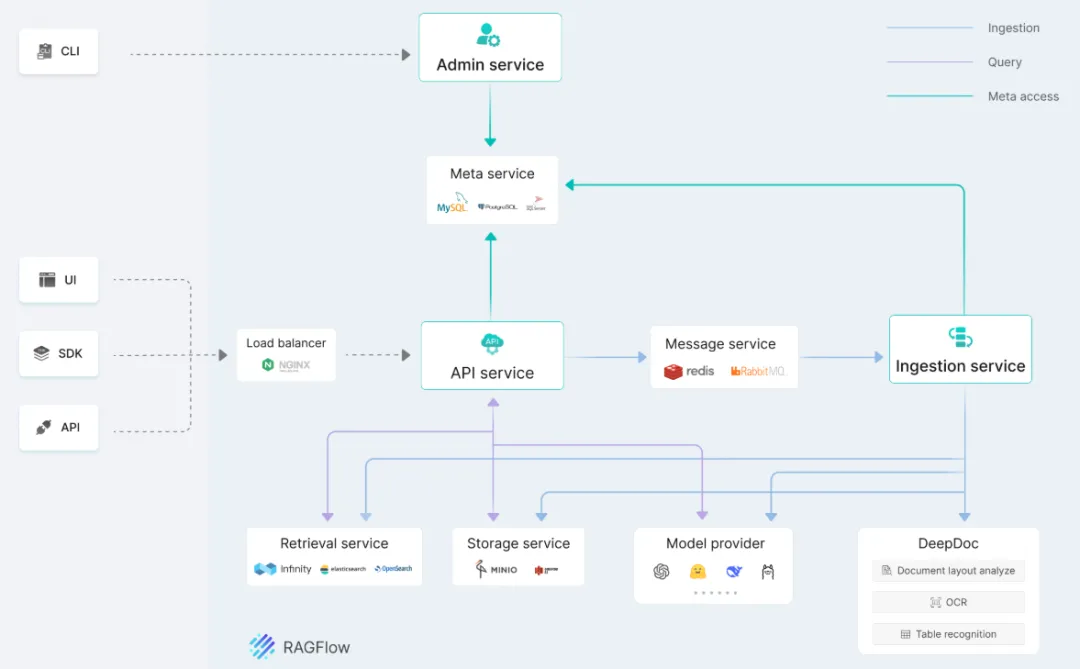
七、系统架构
八、前后端部署实战
参考github仓库中 以源代码启动服务章节内容:
点击Sign up 注册:
完成用户管理页面后,即可进入到主页面:
知识库:
聊天:
搜索:
智能体:
记忆:
文件管理:
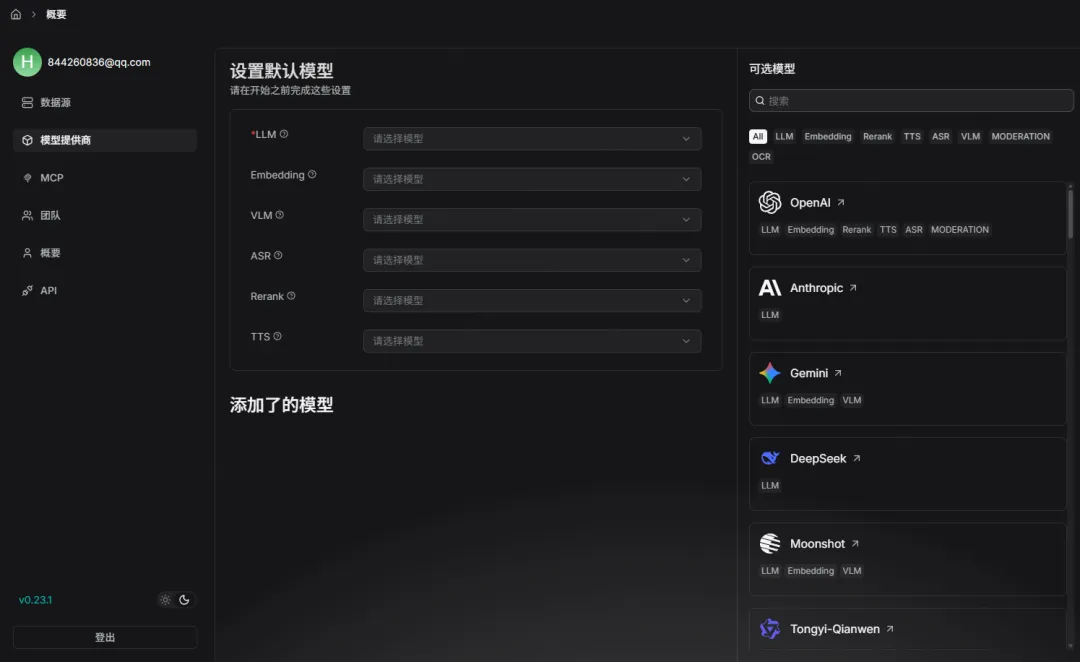
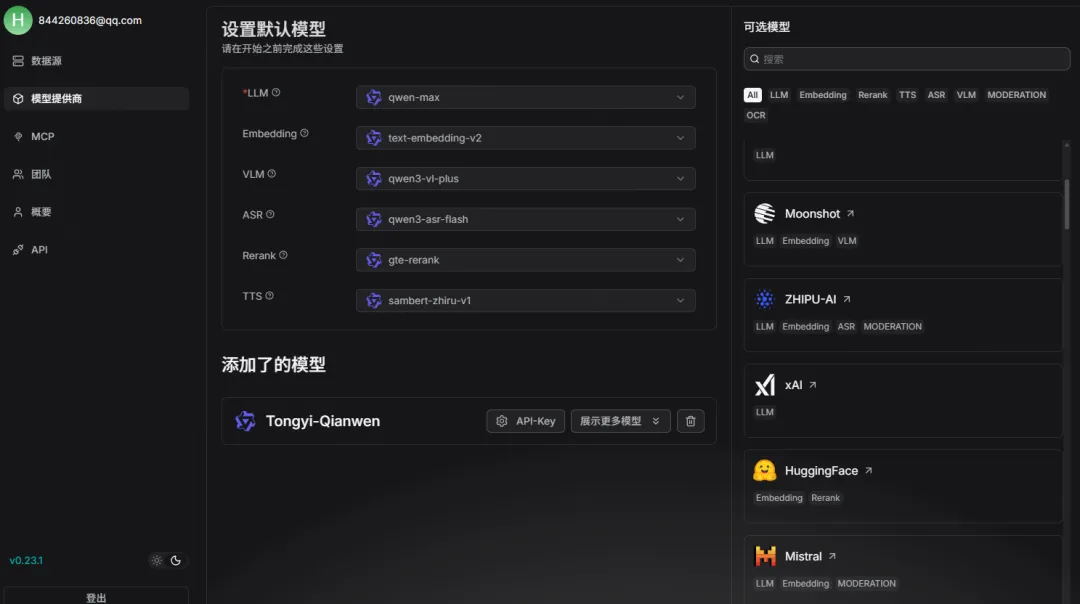
在上传自己的知识库之前,需要设置Embedding和LLM:
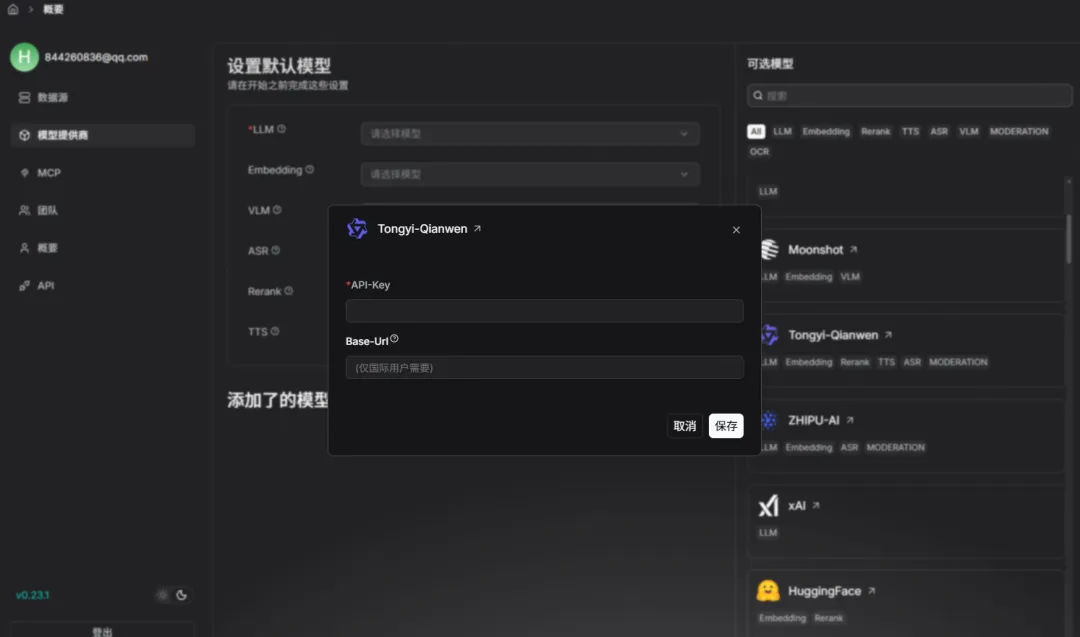
这里选择Tongyi-Qianwen:
当然,在面板右侧还有其他家模型可以选择,同样的需要填写API-Key 和Base-Url,同样需要配置的还有Embedding、VLM、ASR、Rerank、TTS等:
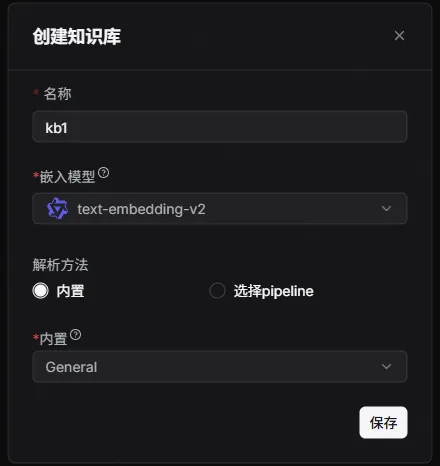
创建知识库:
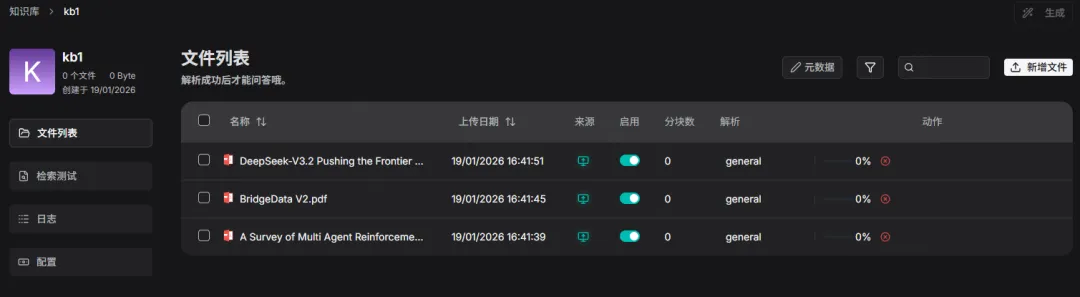
后面分析了下,说是MinIO 端口映射的问题,由于 时间的关系,没有往下深入研究了。
后面也陆陆续续地尝试了下其他的几个组件,包括聊天、搜索、智能体、记忆以及文件管理,总体来说,ragflow 确实是一个成熟的面向企业级应用的知识库管理平台,足以覆盖企业级知识库构建、管理和检索。
作为一名开发者,我个人比较关心的是ragflow 如何管理和组织这些服务?这也是下面提到的RAGFlow的服务管理机制。
RAGFlow的服务管理机制
RAGFlow是一个分布式系统,通过Docker Compose来管理多个服务。其架构包括以下几个核心组件:
1. 服务组成
通过docker-compose-base.yml可以看到,RAGFlow包含多个基础服务:
MySQL: 用于存储元数据和系统配置
MinIO: 对象存储服务,用于存储文档和其他二进制数据
Redis: 作为缓存和消息队列使用
Elasticsearch/Infinity: 作为向量和全文搜索引擎
Valkey: 作为缓存和消息队列使用(注释中提到使用的是Valkey替代Redis)
OpenSearch/OceanBase: 可选的数据存储选项
2. 服务编排
RAGFlow使用Docker Compose的profiles功能来按需启动不同组件,例如:
CPU/GPU版本的ragflow服务
不同的搜索引擎选项(elasticsearch, opensearch, infinity)
数据库选项(oceanbase)
沙箱执行器(sandbox)
消息总线机制的作用
RAGFlow的消息总线机制基于Redis实现,使用了Redis的Stream功能来实现可靠的消息传递。以下是其核心实现细节:
1. Redis Streams作为消息队列
在rag/utils/redis_conn.py中实现了消息队列:
def queue_product(self, queue, message) -> bool: for _ in range(3): try: payload = {"message": json.dumps(message)} self.REDIS.xadd(queue, payload) return True except Exception as e: logging.exception( "RedisDB.queue_product " + str(queue) + " got exception: " + str(e) ) self.__open__() return False
使用Redis Stream的xadd命令添加消息
消息以JSON格式序列化后存储
2. 消费者组模式
Redis Streams支持消费者组,允许多个消费者实例共同处理消息:
def queue_consumer(self, queue_name, group_name, consumer_name, msg_id=b">") -> RedisMsg: """https://redis.io/docs/latest/commands/xreadgroup/""" for _ in range(3): try: # 创建消费者组 group_info = self.REDIS.xinfo_groups(queue_name) if not any(gi["name"] == group_name for gi in group_info): self.REDIS.xgroup_create(queue_name, group_name, id="0", mkstream=True) # 读取消息 args = { "groupname": group_name, "consumername": consumer_name, "count": 1, "block": 5, "streams": {queue_name: msg_id}, } messages = self.REDIS.xreadgroup(**args) # ... except Exception as e: # 错误处理
3. 任务处理流程
在rag/svr/task_executor.py中,任务执行器持续监听Redis消息队列:
任务分发:API服务器或其他组件将任务放入Redis队列
任务获取:多个task_executor实例从队列中获取任务
任务处理:执行实际的文档处理、向量化等计算密集型任务
确认机制:任务完成后调用redis_msg.ack()确认消息处理完成
4. 消息总线的具体作用
解耦合:Web API与后台任务处理完全解耦,API可以快速响应用户请求
负载均衡:多个task_executor实例可以同时处理任务,实现水平扩展
可靠性:使用Redis Streams的消费者组和ACK机制确保每条消息都被处理
容错性:如果某个task_executor实例失败,未处理的消息会被重新分配给其他实例
流量削峰:当任务提交速度超过处理能力时,消息队列可以缓冲任务
5. 多种任务类型支持
消息总线不仅处理普通的文档解析任务,还支持:
dataflow:工作流任务
raptor:递归抽象处理任务
graphrag:图谱增强检索任务
mindmap:思维导图生成任务
memory:记忆任务
1. Dataflow(工作流任务)
Dataflow是RAGFlow中最灵活的处理流程,通过可视化拖拽界面实现。其设计特点:
DSL驱动:工作流通过JSON DSL定义,包含组件、连接关系和参数
组件化:每个组件继承ComponentBase类,实现标准化接口
动态执行:通过Pipeline类解析DSL并按顺序执行组件
进度追踪:通过回调函数记录每个组件的执行进度
2. RAPTOR(递归抽象处理任务)
RAPTOR是一种递归文档摘要算法,其设计特点:
层次聚类:使用UMAP降维和高斯混合模型进行聚类
递归摘要:对聚类结果进行摘要,然后对摘要再次聚类,形成层次结构
异步处理:使用asyncio并发处理多个聚类任务
错误处理:具有最大错误次数限制,防止无限重试
任务取消:支持在处理过程中取消任务
3. GraphRAG(图谱增强检索任务)
GraphRAG使用知识图谱增强检索能力,其设计特点:
实体提取:从文档中提取实体和关系,构建知识图谱
社区检测:使用Leiden算法发现社区结构
社区摘要:对社区生成摘要,便于高层次检索
图谱合并:将新文档的子图合并到全局图谱中
并行处理:支持多个文档并行处理
4. Mindmap(思维导图生成任务)
Mindmap任务用于生成文档的结构化思维导图,其设计特点:
层次结构:提取文档的层级结构信息
主题聚类:识别文档中的主要主题
关系建模:建立概念之间的关系
5. Memory(记忆任务)
Memory任务用于维护对话历史和上下文记忆,其设计特点:
上下文管理:跟踪对话历史和状态
记忆更新:动态更新记忆内容
检索增强:结合记忆内容增强响应
这种架构使得RAGFlow能够高效处理大量并发任务,同时保持系统的稳定性和可扩展性。通过Redis作为消息总线,实现了各组件间的松耦合,提高了系统的健壮性。
RAGFlow的可视化Pipeline编辑器实现原理:
1. DSL定义
使用JSON格式定义工作流结构
包含组件定义、连接关系和参数配置
通过画布DSL描述组件位置和连接线
2. 组件系统
每个组件实现标准接口ComponentBase
组件参数通过ComponentParamBase定义和验证
支持参数类型检查和动态更新
3. 执行引擎
Pipeline类解析DSL并执行组件
按拓扑顺序执行组件,确保依赖关系正确
通过回调函数监控执行进度
4. 变量系统
支持变量引用语法(如{component_id@variable_name})
实现跨组件数据传递
支持系统变量和环境变量
5. 错误处理
每个组件都有错误处理机制
支持重试、默认值和跳转策略
任务可以随时取消
6. 可视化编辑
前端使用图形界面编辑工作流
支持拖拽、连接、参数配置
实时预览和调试功能
这种设计使得用户可以无需编写代码就能创建复杂的处理流程,同时保持了系统的灵活性和可扩展性。通过标准化的组件接口,新的功能模块可以很容易地集成到系统中。
变量引用语法说明
在 RAGFlow 的可视化 Pipeline 系统中,变量引用语法 {component_id@variable_name} 用于引用另一个组件的输出变量。这种语法允许在组件间动态传递数据,实现数据依赖和流程编排。
语法结构
component_id:源组件的唯一标识符
variable_name:源组件输出的变量名
@:分隔符,表示从指定组件获取变量
正则表达式定义
在 ComponentBase 类中,定义了变量引用的正则表达式:
variable_ref_patt = r"\{* *\{([a-zA-Z:0-9]+@[A-Za-z0-9_.-]+|sys\.[A-Za-z0-9_.]+|env\.[A-Za-z0-9_.]+)\} *\}*"
这个正则表达式匹配以下三种类型的变量引用:
component_id@variable_name:引用特定组件的变量
sys.variable_name:引用系统变量
env.variable_name:引用环境变量
实现机制
变量引用解析:当组件的参数中包含变量引用时,系统会使用正则表达式识别这些引用。
变量获取:get_variable_value 方法会解析变量引用字符串,提取组件ID和变量名,然后从对应组件的输出中获取实际值。
路径访问:支持通过点号访问嵌套对象的属性,例如 component_id@variable_name.sub_property。
应用场景
数据传递:一个组件的输出可以作为后续组件的输入,实现数据在组件间的流动。
条件逻辑:可以根据前一个组件的输出结果来决定当前组件的行为。
动态配置:组件的参数可以根据上游组件的结果动态调整。
结果汇总:多个组件的结果可以在后续组件中进行整合和处理。
示例
假设有一个名为 "DocumentParser" 的组件,它输出一个名为 "parsed_content" 的变量,另一个名为 "TextAnalyzer" 的组件需要使用这个内容,那么在 "TextAnalyzer" 的配置中,可以使用 {DocumentParser@parsed_content} 来引用前一个组件
回复“虎sir”,进入AI交流学习群: