5.1 Python 文件操作
5.1.1 打开关闭文件
在 Python 中,使用内置的 open() 函数来打开或创建文件。
file = open(file_name [, access_mode][, buffering])
参数说明如下:
- file_name:file_name 变量是一个包含了要访问的文件名称的字符串值。
- access_mode:可选参数,决定了打开文件的模式:只读,写入,追加等,默认文件访问模式为只读(r)。
- r:读取模式(默认),如果文件不存在则抛出错误。
- w:写入模式,如果文件存在则会被清空,不存在则创建新文件。
- a:追加模式,打开文件并在文件末尾进行写入操作,如果文件不存在会创建新文件。
- x:创建模式,只创建新文件,如果文件已存在则抛出错误。
- t:文本模式(默认),处理文本文件。
- b:二进制模式,处理二进制文件,如图片、音频等。
- +:打开一个文件进行更新(可读可写)
组合模式例如 rb 表示以二进制格式打开一个文件用于只读。。
- buffering:如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
File 对象的 close() 方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。
file.close() # 关闭文件,确保数据被正确写入并释放系统资源
推荐使用上下文管理器自动关闭文件,即使用 with 语句来确保文件在操作完成后自动关闭:
withopen('filename.txt', 'r') asfile: content = file.read() # 在此区域内对文件进行操作...# 这里无需手动调用 close(),离开 with 代码块时,文件将自动关闭
5.1.2 读写文件
读取文件
read() 方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python 字符串可以是二进制数据,而不是仅仅是文字。语法如下:
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
# 读取整个文件withopen('filename.txt', 'r') asfile: data = file.read()# 读取一行withopen('filename.txt', 'r') asfile: for line in file: process_line(line)# 读取所有行with open('filename.txt', 'r') as file: lines = file.readlines()
写出文件
write() 方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python 字符串可以是二进制数据,而不是仅仅是文字。write() 方法不会在字符串的结尾添加换行符 \n。语法如下:
在这里,被传递的参数是要写入到已打开文件的内容。
# 一次性写入withopen('filename.txt', 'w') asfile: file.write('Hello, World!\n')# 逐行写入lines = ['Line 1', 'Line 2', 'Line 3']withopen('filename.txt', 'w') asfile: for line in lines: file.write(line + '\n')# 追加内容到文件with open('filename.txt', 'a') as file: file.write('Appending this text to the end of the file...\n')
5.1.3 文件操作
检查文件是否存在
import osif os.path.isfile('filename.txt'): print("File exists.")
获取文件信息
import osstat_info = os.stat('filename.txt')print(stat_info.st_size) # 输出文件大小
属性名称 | 说明 |
st_mode | 保护模式 |
st_ino | 索引号 |
st_nlink | 硬链接号(被连接数目) |
st_size | 文件大小,单位为字节 |
st_mtime | 最后一次修改时间 |
st_dev | 设备名 |
st_uid | 用户ID |
st_gid | 组ID |
st_atime | 最后一次访问时间 |
st_ctime | 最后一次状态变化的时间,系统不同返回结果也不同 |
文件定位
tell() 方法返回文件内的当前位置,换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from]) 方法改变当前文件的位置。offset 变量表示要移动的字节数。from 变量指定开始移动字节的参考位置。如果 from 被设为 0,这意味着将文件的开头作为移动字节的参考位置。如果设为 1,则使用当前的位置作为参考位置。如果它被设为 2,那么该文件的末尾将作为参考位置。
# 打开一个文件fo = open("foo.txt", "r+")str = fo.read(10)print("读取的字符串是 : ", str)# 查找当前位置position = fo.tell()print("当前文件位置 : ", position)# 把指针再次重新定位到文件开头position = fo.seek(0, 0)str = fo.read(10)print("重新读取字符串 : ", str)# 关闭打开的文件fo.close()
重命名
os.rename(current_file_name, new_file_name)
删除文件
目录操作
方法 | 描述 |
os.mkdir(path) | 创建单级目录 |
os.makedirs(path, exist_ok=True) | 创建多级目录,exist_ok=True参数可防止在目录已存在时引发错误 |
os.rmdir(path) | 删除空目录 |
shutil.rmtree(path) | 删除包括子目录和文件在内的整个目录树 |
os.path.isdir(path) | 检查路径是否为一个目录 |
os.listdir(directory) | 返回指定目录中所有非隐藏文件和目录的名称列表 |
os.chdir(directory) | 改变当前工作目录到指定目录 |
os.getcwd() | 获取当前工作目录的绝对路径 |
5.2 Python 正则表达式
5.2.1 正则表达式模块
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串作为它们的第一个参数。
import repattern = re.compile(r'正则表达式')
5.2.2 匹配方法
匹配方法
方法 | 描述 |
re.match() | 从字符串的起始位置开始匹配,如果匹配成功,返回一个匹配对象;否则返回None。 |
re.search() | 在整个字符串中搜索模式,如果找到,返回一个匹配对象;否则返回None。 |
re.fullmatch() | 整个字符串必须完全匹配模式,才会返回一个匹配对象。 |
re.findall() | 返回字符串中所有与模式匹配的非重叠子串的列表。 |
re.finditer() | 返回一个迭代器,其中包含字符串中与模式匹配的所有非重叠子串的匹配对象。 |
re.split() | 根据正则表达式分割字符串,并返回分割后的字符串列表。 |
re.sub() | 替换匹配项,并返回替换后的字符串。 |
修饰符
修饰符 | 描述 |
re.I或re.IGNORECASE | 忽略大小写 |
re.M或re.MULTILINE | 多行模式,让^和$匹配每一行的开始和结束 |
re.S或re.DOTALL | 使.能够匹配包括换行符在内的任何字符 |
re.X或re.VERBOSE | 允许正则表达式格式化,忽略空白并支持注释 |
示例
# 检查字符串是否以 'hello' 开头text = "hello world"pattern = re.compile(r'^hello')match = pattern.match(text)if match: print("匹配成功")# 使用多行模式匹配换行符间的单词边界text = "line1\nword\nline2"pattern = re.compile(r'\bword\b', re.M)matches = pattern.finditer(text)for match in matches: print(match.group())# 忽略大小写匹配pattern = re.compile(r'Hello', re.I)print(pattern.search('hello, World!').group())
5.2.3 高级用法
分组与捕获
分组:使用圆括号 ( ) 可以创建一个分组。分组允许定义子模式,并且可以作为整体进行匹配或者引用
import retext = "cat and dog in the hat"pattern = re.compile(r'(cat|dog)') # 匹配 'cat' 或 'dog'match = pattern.search(text)if match: print(match.group(0)) # 输出整个匹配项('cat' 或 'dog') print(match.group(1)) # 输出第一个捕获组的内容('cat' 或 'dog')
命名分组:在Python中,可以通过(?P<name>...)来定义命名分组,方便后续通过名称引用。
import retext = "cat and dog in the hat"pattern = re.compile(r'(?P<animal>cat|dog)')match = pattern.search(text)if match: print(match.group('animal')) # 输出 'cat' 或 'dog'
非捕获组:如果不需要捕获分组中的内容,可以使用(?:...),这样该分组不会分配编号,也不会被.group()方法所引用。
import retext = "cat and dog in the hat"pattern = re.compile(r'(?:cat|dog)')match = pattern.search(text)if match: print(match.group(0)) # 输出整个匹配项,无单独的捕获组
贪婪与懒惰匹配
贪婪模式:默认情况下,量词如*,+,{m,n} 等会尽可能多地匹配字符。
import retext = '<html><body>Hello</body></html>'pattern = re.compile(r'<.*>') # 匹配 '<...>' 中的所有内容,贪婪地包括最后一个 '>'match = pattern.match(text)print(match.group(0)) # 输出 '<html><body>Hello</body></html>'
非贪婪或懒惰模式:在量词后面加上问号?,使其变为非贪婪模式,即尽可能少地匹配字符。
import retext = '<html><body>Hello</body></html>'pattern = re.compile(r'<.*?>') # 匹配 '<...>' 中的内容,但只到下一个 '>' 出现为止match = pattern.match(text)print(match.group(0)) # 输出 '<html>'
后向引用
在正则表达式中,可以用\数字引用前面已经捕获的分组。
pattern = re.compile(r'(\w+)\s\1') # 匹配重复的单词text = "hello hello"match = pattern.search(text)if match: print(match.group(0)) # 输出 'hello hello'
替换与分割
re.sub(pattern, repl, string[, count]):根据正则表达式替换字符串中的匹配部分。
text = "I love Python programming."new_text = re.sub(r'Python', 'Java', text)print(new_text) # 输出 "I love Java programming."
re.split(pattern, string[, maxsplit]):按照正则表达式分割字符串。
words = re.split(r'\s+', "Hello, World! This is a test.")print(words) # 输出 ['Hello,', 'World!', 'This', 'is', 'a', 'test.']
5.3 Python 操作 MySQL
Python 标准数据库接口为 Python DB-API,Python DB-API 为开发人员提供了数据库应用编程接口。
5.3.1 PyMySQL
PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2 中则使用 mysqldb。PyMySQL 遵循 Python 数据库 API v2.0 规范,并包含了 pure-Python MySQL 客户端库。
安装 PyMySQL
在线安装
pip 是 Python 包管理工具,该工具提供了对 Python 包的查找、下载、安装、卸载的功能。
Python 2.7.9 + 或 Python 3.4+ 以上版本都自带 pip 工具。
离线安装,下载对应的 whl:https://pypi.org/project/pymysql/#files
pip install PyMySQL-<version>-py3-none-any.whl
5.3.2 连接数据库
连接数据库
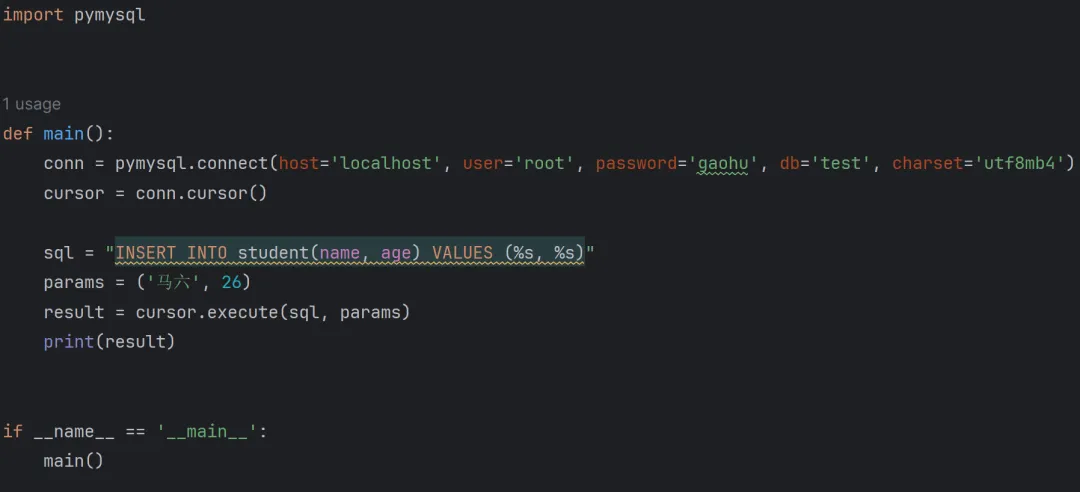
# 创建连接对象conn = pymysql.connect(host='localhost', # 数据库主机地址 user='username', # 数据库用户名 password='password', # 数据库密码 db='database_name', # 要连接的数据库名 charset='utf8mb4') # 字符编码,推荐使用 utf8mb4# 创建游标对象,用于执行 SQL 语句cursor = conn.cursor()
关闭数据库
# 关闭游标cursor.close()# 关闭数据库连接conn.close()
5.3.3 执行 SQL
数据库查询操作
Python 查询 Mysql 使用 fetchone() 方法获取单条数据,使用 fetchall() 方法获取多条数据。
- fetchone():该方法获取下一个查询结果集。结果集是一个对象
- fetchall():接收全部的返回结果行.
- rowcount:这是一个只读属性,并返回执行 execute() 方法后影响的行数。
# 查询示例sql_query = "SELECT * FROM student"cursor.execute(sql_query)results = cursor.fetchall() # 获取所有查询结果for row in results: print(row)
数据库插入操作
# SQL 插入语句sql = "INSERT INTO student(name, age) VALUES ('王五', 25)"cursor.execute(sql)
数据库更新操作
sql = "UPDATE student SET age=30 WHERE name='张三'"cursor.execute(sql)
数据库删除操作
sql = "DELETE FROM student WHERE name='张三'"cursor.execute(sql)
数据库事务
# SQL删除记录语句sql = "DELETE FROM stuednt"try: # 执行SQL语句 cursor.execute(sql) # 向数据库提交 conn.commit()except: # 发生错误时回滚 conn.rollback()
预编译 SQL
5.4 Python 多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
- 程序的运行速度可能加快
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
线程在执行过程中与进程还是有区别的。每个独立的进程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) -- 这就是线程的退让。
5.4.1 创建线程
Python 通过两个标准库 thread 和 threading 提供对线程的支持。thread 提供了低级别的、原始的线程以及一个简单的锁。
threading 模块提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的 list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与 len(threading.enumerate()) 有相同的结果。
除了使用方法外,线程模块同样提供了 Thread 类来处理线程,Thread 类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的 join() 方法被调用中止
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
使用 thread 模块中的 start_new_thread() 函数来产生新线程,首先需要导入 thread 模块,然后定义一个函数作为线程的目标函数,接着调用 start_new_thread() 函数并传入目标函数和参数。示例如下:
# function - 线程函数。# args - 传递给线程函数的参数,他必须是个 tuple 类型。# kwargs - 可选参数。thread.start_new_thread ( function, args[, kwargs] )
使用 threading 模块创建线程,首先需要导入 threading 模块,然后定义一个函数作为线程的目标函数,接着创建一个 Thread 对象,将目标函数作为参数传递给 Thread 对象,最后调用 Thread 对象的 start() 方法启动线程。示例如下:
import threadingdef worker(num): """线程执行的任务""" print(f"Worker {num} is running")# 创建两个线程t1 = threading.Thread(target=worker, args=1)t2 = threading.Thread(target=worker, args=2)# 启动线程t1.start()t2.start()# 等待线程执行完成t1.join()t2.join()
5.4.2 线程同步
由于 GIL(全局解释器锁) 的存在,Python 中的多线程并不能充分利用多核 CPU 资源进行并行计算。然而,在 IO 密集型任务或需要协调多个线程时,线程同步机制仍然重要。
全局解释器锁: 由于 CPython 解释器的设计,Python 中的多线程受到 GIL 的限制。GIL 是一个互斥锁,它确保一次只有一个线程执行 Python 字节码。这意味着在 CPU 密集型任务中,多线程可能不会提高性能,因为线程在执行时会被 GIL 阻塞。对于计算密集型任务,可以考虑使用多进程或者第三方库如 multiprocessing、concurrent.futures 等,它们能够绕过 GIL 限制。
互斥锁:防止多个线程同时访问同一资源
import threadinglock = threading.Lock()def critical_section(): lock.acquire() # 获取锁 try: # 在这里执行临界区代码 finally: lock.release() # 释放锁
事件对象:允许一个或多个线程等待某个事件发生
import threadingevent = threading.Event()def wait_for_event(): event.wait() # 等待事件被设置 # 事件发生后的处理逻辑...def set_event(): # 执行一些操作... event.set() # 设置事件t1 = threading.Thread(target=wait_for_event)t2 = threading.Thread(target=set_event)t1.start()t2.start()t1.join()t2.join()
条件变量:用于线程间的协作,当满足特定条件时唤醒等待的线程。
信号量:控制同时访问某一资源的线程数量。
队列:线程安全的数据结构,用于线程间数据交换。
5.5 Python 网络编程
5.5.1 Socket
Python 提供了两个级别访问的网络服务:
- 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统 Socket 接口的全部方法。
- 高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
Socket 又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
方法名 | 描述 |
socket() | 创建一个新的socket对象 |
bind(address) | 将socket绑定到指定的地址和端口号 |
listen(backlog) | 开始监听连接请求,backlog指定等待连接的最大数量 |
accept() | 接受一个客户端的连接请求,返回一个新的socket对象和客户端的地址信息 |
connect(address) | 连接到指定的服务器地址和端口号 |
send(data) | 发送数据到连接的服务器或客户端 |
recv(bufsize) | 从连接的服务器或客户端接收数据,bufsize指定接收数据的缓冲区大小 |
close() | 关闭socket连接 |
5.5.2 TCP
TCP 是一种面向连接的、可靠的、基于字节流的传输层通信协议。在 Python 中使用 socket 模块创建 TCP 服务器和客户端:
TCP 服务端
import socket# 创建套接字对象server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 绑定本地IP和端口server_socket.bind(('localhost', 12345))# 开始监听连接请求,最大并发数为5server_socket.listen(5)while True: # 接受一个客户端连接 client_socket, address = server_socket.accept() # 处理客户端请求 message = client_socket.recv(1024).decode('utf-8') print(f"Received: {message}") # 发送响应数据 response = "Hello from the server!" client_socket.sendall(response.encode('utf-8')) # 关闭客户端连接 client_socket.close()
TCP 客户端
import socket# 创建套接字对象client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 连接到服务器client_socket.connect(('localhost', 12345))# 发送消息给服务器message = "Hello from the client!"client_socket.sendall(message.encode('utf-8'))# 接收服务器响应response = client_socket.recv(1024).decode('utf-8')print(f"Received: {response}")# 关闭客户端套接字client_socket.close()
5.5.3 UDP
UDP 是无连接的、不可靠的传输层协议,常用于实时应用或广播等场景。UDP 服务端
import socket# 创建UDP套接字server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 绑定到本地地址server_socket.bind(('localhost', 9999))while True: # 接收数据 data, addr = server_socket.recvfrom(1024) data = data.decode('utf-8') print(f"Received: {data} from {addr}") # 发送回应 response = f"Echo: {data}" server_socket.sendto(response.encode('utf-8'), addr)
UDP 客户端
import socket# 创建UDP套接字client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 发送数据到服务器message = "Hello via UDP"client_socket.sendto(message.encode('utf-8'), ('localhost', 9999))# 接收服务器回应data, server_addr = client_socket.recvfrom(1024)data = data.decode('utf-8')print(f"Received: {data} from the server")# 关闭客户端套接字client_socket.close()