具身智能的“Linux 时刻”:SmolVLA 模型全景深度解析与技术启示录
- 2026-06-29 22:03:36
1. 执行摘要:打破“算力霸权”的非共识创新
在人工智能与机器人学(Robotics)交汇的具身智能(Embodied AI)领域,长久以来存在着一种隐形的“算力霸权”。从 Google 的 RT-2 到斯坦福的 OpenVLA,主流的研究范式似乎被锁定在了一条“大模型、大数据、大算力”的单行道上。这些 Vision-Language-Action (VLA) 模型动辄拥有 70 亿甚至 550 亿参数 1,其训练和推理极度依赖昂贵的 A100/H100 集群,使得大多数学术实验室、初创公司乃至个人开发者望尘莫及。这种资源门槛不仅阻碍了技术的普及,更在一定程度上导致了数据的同质化和创新的停滞。
然而,Hugging Face LeRobot 团队近期发布的 SmolVLA 模型,以一种近乎“叛逆”的姿态打破了这一局面。作为一款仅有 4.5 亿参数(0.45B) 的轻量级模型,SmolVLA 在多项关键基准测试中,性能匹敌甚至超越了参数量大其 10 倍的竞争对手 3。它不仅证明了“小模型”在特定架构优化下具备惊人的潜力,更重要的是,它通过异步推理栈(Asynchronous Inference Stack)、**流匹配(Flow Matching)训练目标以及社区驱动(Community-Driven)**的数据策略,为具身智能的落地提供了一套全新的、可复刻的方法论。
本报告将以“深度技术解构”为核心,面向 AI 研究员、机器人工程师及深度科技观察者,全方位剖析 SmolVLA 的设计哲学、架构创新、系统工程及生态意义。我们将揭示其如何通过“减法”艺术实现效能的“加法”,并探讨这一技术路线对未来通用机器人(Generalist Robots)发展的深远影响。
图片来源:SmolVLA
2. 背景与挑战:VLA 模型的“阿喀琉斯之踵”
2.1 具身智能的“基础模型”范式
近年来,随着 Transformer 架构的统治级表现,机器人领域开始尝试将大型语言模型(LLM)和视觉语言模型(VLM)的语义理解能力迁移到物理控制中。这一趋势催生了 VLA 模型——一种能够输入自然语言指令(如“把红色的方块放到蓝色盘子里”)和视觉观测(RGB 图像),直接输出机器人动作指令(如关节角度或末端位姿)的端到端系统 4。
这一范式的愿景是美好的:利用互联网上海量的图文数据让机器人获得常识(Common Sense),再通过机器人轨迹数据让其学会技能(Skills)。RT-2、OpenVLA 和 π0(Pi-Zero)等模型均是这一路线的杰出代表。
2.2 现有路径的三重困境
尽管愿景宏大,但现有 VLA 模型在实际落地中遭遇了严峻的“水土不服”,主要体现在以下三个维度:
参数臃肿与实时性矛盾(The Latency Paradox):机器人控制对实时性有着严苛要求,通常需要控制频率达到 10Hz 甚至更高。然而,7B 参数级别的 OpenVLA 在消费级显卡上推理极其缓慢,往往难以突破 5Hz 5。为了保证控制精度,系统不得不引入昂贵的服务器进行远程推理,但这又引入了网络延迟和不确定性。
训练成本的阶级固化(The Cost Barrier):复现或微调 RT-2-X 级别的模型需要数千 GPU 小时的算力资源。这意味着具身智能的研究权被锁定在少数科技巨头和顶级实验室手中,广大的开源社区和中小开发者无法参与核心模型的迭代,只能做外围应用 3。
数据的“象牙塔”效应(The Data Silo):现有模型主要依赖学术界标准数据集(如 BridgeData)或大厂内部数据。这些数据往往采集于受控的实验室环境,光照均匀、背景干净。然而,真实世界是嘈杂的、多变的。过度拟合“干净数据”导致模型在面对复杂的家庭或工业环境时,泛化能力(Generalization)大打折扣 7。
SmolVLA 的诞生,正是为了精准狙击上述痛点。它不追求绝对参数量的堆叠,而是追求单位参数的智能密度(Intelligence per Parameter)和单位算力的控制效能(Control Efficiency per Flop)。
3. 架构解构:极简主义的胜利
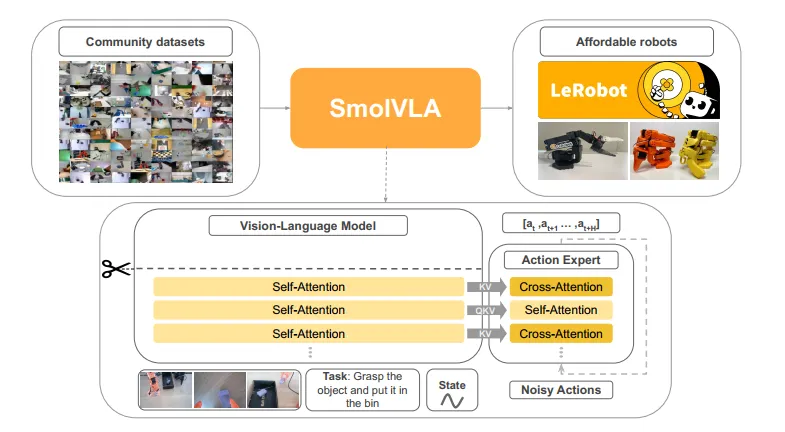
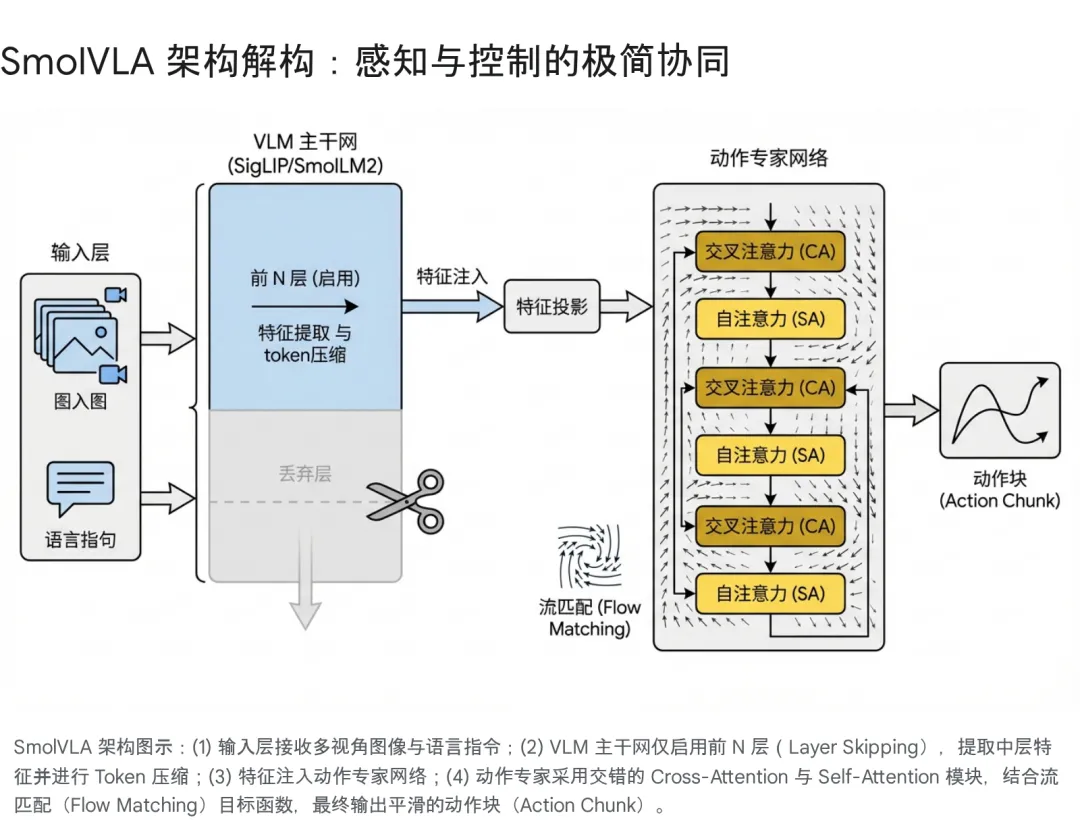
SmolVLA 的核心并非简单的模型蒸馏,而是一次针对机器人任务特性的架构重构。它基于 Hugging Face 的 SmolVLM-2 骨干,通过一系列大胆的“剪裁”与“重组”,实现了极致的效率。
3.1 策略性层跳过:寻找“语义”与“几何”的平衡点
在视觉语言模型(VLM)中,通常的做法是利用 Transformer 的最后一层输出特征来生成文本。然而,对于机器人操作任务而言,这是一个最优解吗?
最新的可解释性研究表明,深度神经网络的层级功能存在分化:深层网络(Later Layers)倾向于提取高度抽象的语义信息(Semantics),例如“这是一个杯子”;而浅层和中层网络(Early/Middle Layers)则保留了更多关于物体位置、形状、姿态的空间几何信息(Spatial Geometry)7。对于机械臂抓取任务,知道“杯子在哪里”和“杯把朝向哪里”往往比知道“这是个杯子”更重要。
SmolVLA 采取了 Layer Skipping(层跳过) 策略:
机制: 在推理阶段,模型直接截断了 VLM 后半部分($L-N$ 层)的计算,仅利用前 $N$ 层的特征输出。
配置: 具体而言,SmolVLA 将 $N$ 设定为总层数的一半($N=L/2$),即仅使用前 16 层特征 1。
收益: 这一操作直接将 VLM 部分的计算量和显存占用砍半,显著提升了推理速度,同时由于利用了包含更多空间信息的特征,反而提升了操作精度。
3.2 视觉 Token 的极致压缩:告别冗余
OpenVLA 等模型为了看清细节,往往采用高分辨率图像并切分为数百个 Patch Token,导致序列极长,推理沉重。SmolVLA 反其道而行之,实施了 Visual Token Reduction(视觉 Token 压缩):
去切片化(No Image Tiling): 放弃了复杂的图像切片技术,仅输入全局图像。
Pixel Shuffle 压缩: 通过 Pixel Shuffle 技术,将每帧 512x512 的图像压缩为仅 64 个视觉 Token8。
多视角融合: 这种极致的压缩使得模型能够轻松同时处理多个摄像头(如顶视图、侧视图、腕部相机)的输入流,而不会挤爆显存。对于机器人操作,多视角带来的三维感知增益远大于单张超高分图像的细节增益。
3.3 动作专家(Action Expert):流匹配与交错注意力
SmolVLA 并没有让 VLM 直接解码动作,而是引入了一个独立的、约 1 亿参数的 Action Expert 模块。这个模块的设计体现了对时序控制的深刻理解。
3.3.1 流匹配(Flow Matching):确定性的生成之路
这是 SmolVLA 与基于扩散模型(Diffusion Policy)的 Pi0 或离散 Token 的 OpenVLA 最大的区别。
原理: 流匹配可以被视为一种非随机的、确定性的生成过程。它并非像扩散模型那样通过随机去噪来生成动作,而是学习一个向量场(Vector Field),将初始的噪声分布沿着一条直线轨迹(Straight Flow)平滑地“推”向目标动作分布 9。
优势: 扩散模型通常需要 50-100 步迭代才能生成高质量动作,而流匹配由于轨迹更直,通常只需 10 步 甚至更少即可完成推理 5。这在保证动作生成质量(如多模态分布处理能力)的同时,极大地降低了推理延迟。
3.3.2 交错式注意力(Interleaved Attention)
在 Action Expert 的内部结构上,SmolVLA 创新性地采用了 交叉注意力(Cross-Attention, CA) 与 因果自注意力(Causal Self-Attention, SA) 交错排列的设计 5:
CA 层: 负责“感知”。动作 Query 与 VLM 输出的视觉+语言特征进行交互,确保动作符合当前的感知输入。
SA 层: 负责“平滑”。当前的动作 Token 与历史生成的动作 Token 进行交互,确保动作序列在时间上的连贯性,避免抖动。
对比: 纯 CA 结构容易导致动作不连贯,纯 SA 结构容易忽视环境变化。交错设计完美平衡了环境响应(Grounding)与动作平滑(Smoothness)。
4. 系统级工程:异步推理栈 (Asynchronous Inference Stack)
如果说模型架构是“大脑”,那么推理系统就是“神经系统”。SmolVLA 的另一大杀手锏是其异步推理栈,这解决了传统机器人控制中致命的“走走停停”(Stop-and-Go)问题。
4.1 同步推理的瓶颈
在传统的同步控制循环中,机器人的生命周期如下:
感知(Sense): 拍摄图像。
思考(Think): 运行 VLA 模型推理(耗时 $T_{infer}$)。
行动(Act): 执行生成的动作(耗时 $T_{exec}$)。
循环。
在这种模式下,系统总周期 $T_{cycle} = T_{infer} + T_{exec}$。在 $T_{infer}$ 期间,机器人处于完全静止的“失盲”状态。对于参数量巨大的 VLA 模型,$T_{infer}$ 可能高达 200ms 以上,导致机器人动作卡顿,且极易因环境变化(如目标移动)而操作失败 5。
4.2 异步解耦与“动作块”策略
SmolVLA 引入了异步推理机制,将“思考”与“行动”在时间轴上重叠。
并行流水线: 当机器人正在执行当前的**动作块(Action Chunk, $A_t$)**时,后台的推理引擎已经在处理最新的观测数据,并计算下一个动作块 $A_{t+1}$。
队列管理与阈值 $g$: 系统维护一个动作队列。设定一个阈值参数 $g$(例如 0.7)。当队列中剩余未执行的动作比例低于 $g$ 时,立即触发新的推理请求。
若 $g=0$:退化为同步模式,队列耗尽才推理。
若 $g=1$:每一帧都推理,计算负载极大。
SmolVLA 的选择: 通常取 $g \in (0, 1)$,在计算负载与响应速度之间取得平衡,确保动作队列永不干涸 3。
轨迹融合(Chunk Aggregation): 新预测的动作块与当前队列中尚未执行的部分在时间上会有重叠。系统会对重叠部分进行加权融合(Ensembling),消除了拼接处的突变,使轨迹如丝般顺滑 1。
4.3 性能倍增的实证
这一系统级优化带来了立竿见影的效果:
推理“隐形化”: 对于用户而言,推理延迟几乎消失了,因为计算时间被“隐藏”在了动作执行时间背后。
吞吐量翻倍: 实验显示,在固定时间限制下,异步模式完成的抓取任务次数是同步模式的 2 倍(19次 vs 9次)5。
响应速度提升: 任务完成总时长缩短了 30%5。
5. 数据范式:LeRobot 社区的“蚁群战术”
SmolVLA 的成功不仅是算法的胜利,更是数据观念的革新。它挑战了“高质量数据必须来自实验室”的传统认知。
5.1 数据规模与来源
SmolVLA 的预训练仅使用了 <30,000 条 轨迹数据 3。这一数据量不仅远小于 OpenVLA 的 970k 条 12,甚至少于许多单一任务的模仿学习数据集。
这些数据完全来自 Hugging Face LeRobot 社区,由全球各地的开发者、学生和爱好者使用低成本的 SO-100 机械臂采集并上传 13。
5.2 噪声即特征(Noise as a Feature)
社区数据通常被认为是“低质量”的:
环境不一: 有的是在杂乱的书桌上,有的是在厨房台面,光线忽明忽暗。
设备差异: 摄像头角度各异,有的用高价相机,有的用网络摄像头。
操作差异: 每个人的遥操作手法不同,有的平稳,有的急躁。
然而,SmolVLA 证明了这些多样性(Diversity)恰恰构成了最强的正则化(Regularization)。模型被迫学习物体操作的物理本质(如夹爪与物体的相对关系),而不是死记硬背某种特定光照下的像素模式。这种在“混乱”中训练出来的模型,在面对未知环境(Out-of-Distribution, OOD)时表现出了惊人的鲁棒性 14。
5.3 VLM 辅助的数据清洗(The AI-on-AI Pipeline)
社区数据的最大问题是标注质量参差不齐。有的任务描述只有简单的 "Pick" 或 "Task 1",甚至缺失。
为了解决这个问题,SmolVLA 团队构建了一套自动化清洗流程:利用强大的 Qwen2.5-VL-3B-Instruct 模型,读取原始视频帧,自动生成清晰、统一、结构化的自然语言任务描述(如 "Pick up the red cube and place it in the wooden bowl")15。这种“用大模型教小模型”的数据工程,是低成本扩充高质量数据的关键一环。
6. 性能对决:小巨人的逆袭
在数据和事实面前,参数量不再是唯一的真理。以下对比数据基于论文及第三方复现结果。
6.1 关键模型参数与部署门槛对比
为了直观展示 SmolVLA 在当前生态中的位置,我们首先对比几个主流模型的硬指标。
模型 | 参数量 | 训练数据量 (轨迹数) | 训练算力需求 | 推理硬件门槛 | 架构特点 |
RT-2-X | 55B | 20M+ (Google 内部) | 庞大集群 (TPU) | 需云端推理 | VLM 直接输出 Token |
OpenVLA | 7B | ~970k | A100 集群 | RTX 3090/4090 | Llama 2 + DINOv2/SigLIP |
Pi0 | 3.3B | 海量混合数据 | 高昂 | 高端 GPU | VLM + Flow Matching |
ACT | ~80M | 单任务数据 (小) | 单卡可训 | CPU/低端 GPU | CNN/Transformer + VAE |
SmolVLA | 0.45B | <30k | 单卡 RTX 3090 | CPU / 笔记本 GPU | VLM (Skip) + Flow Matching |
数据来源:1
6.2 仿真与实机性能评估
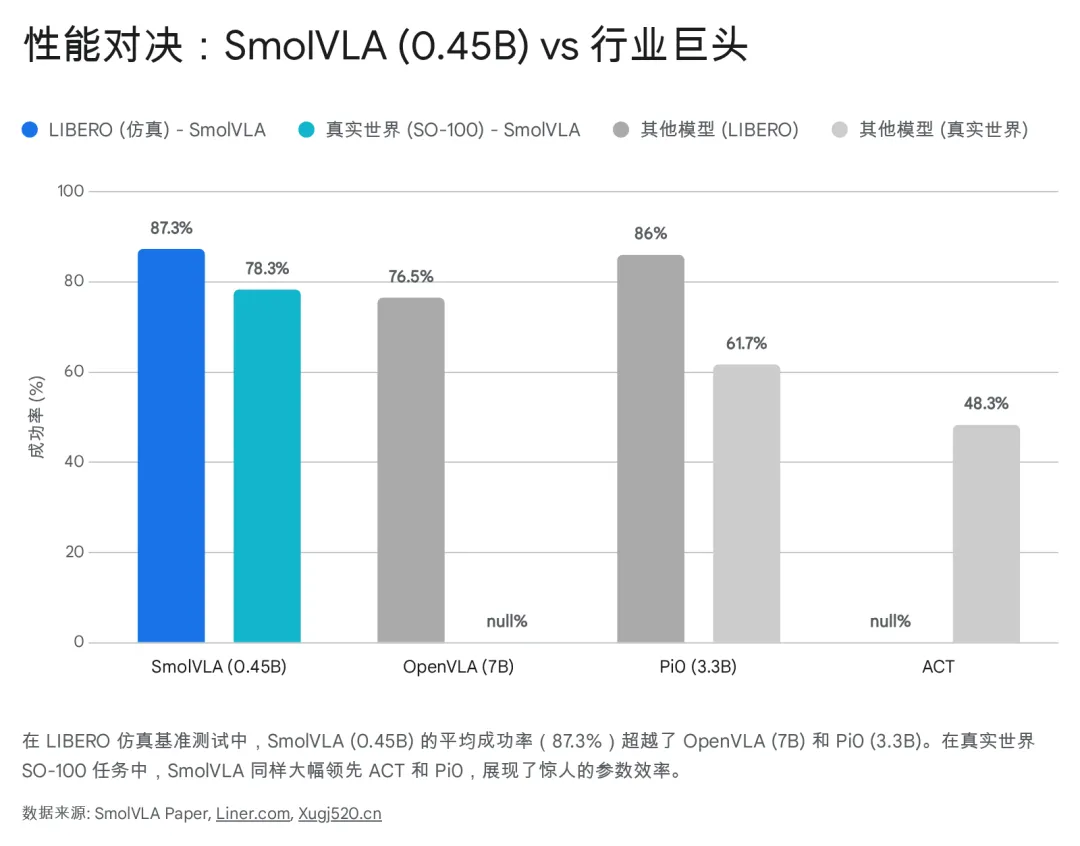
在 LIBERO 这一公认的高难度多任务仿真基准中,SmolVLA 的表现令人咋舌:
SmolVLA (0.45B) 平均成功率:87.3%
OpenVLA (7B) 平均成功率:76.5%
Pi0 (3.3B) 平均成功率:86.0%
Octo (0.09B) 平均成功率:75.1%
数据解读: 一个参数量仅为 OpenVLA 1/15 的模型,在任务成功率上反超了 10.8%。这强有力地证明了架构优化(层跳过、流匹配)和数据质量(社区多样性数据)比单纯堆叠参数更有效 16。
在 真实世界 SO-100 机械臂 的测试中(涵盖抓取、堆叠、分类任务):
SmolVLA 依然保持领先,平均成功率 78.3%。
ACT(针对单一任务优化)仅为 48.3%。
这说明 SmolVLA 不仅在仿真中强,在面对真实世界的物理摩擦、传感器噪声时,同样具备极强的鲁棒性 3。
6.3 训练与推理成本分析
训练时间: 整个预训练过程在单卡 RTX 3090 上仅需约 34 天(约 800 小时)。如果使用 4 卡并行,仅需一周左右。论文中提到的“30k GPU hours”是指整个项目包含所有消融实验的总耗时,而非单次训练成本 1。
推理资源: 模型可在 8GB 显存的消费级显卡甚至 MacBook (M系列芯片) 上流畅运行,推理延迟极低。相比之下,OpenVLA 需要 24GB+ 显存才能勉强运行 1。
7. 实践指南:LeRobot 与 SO-100 生态
SmolVLA 的发布伴随着一套完整的开源硬件与软件生态,这使得其“可复现性”远超同类论文。
7.1 SO-100:具身智能的“树莓派”
报告中频繁提及的 SO-100 是一款开源的 6 自由度(6-DoF)机械臂。
成本: 它的核心部件(舵机、主控板)成本仅约 200 美元左右,所有结构件均可 3D 打印18。
意义: 这种极低的硬件门槛意味着任何学校实验室、甚至个人爱好者都可以在家复现 SOTA 级的机器人研究。SmolVLA 正是基于这一硬件平台的数据训练的,因此对 SO-100 有着原生的完美支持(Native Support)。
7.2 LeRobot 框架
Hugging Face 推出的 lerobot 代码库是 SmolVLA 的载体。它提供了从数据可视化、预训练、微调到部署的全套工具链。
开发者可以通过简单的命令行指令下载社区数据集:lerobot-train --policy.type=smolvla...
支持一键连接 SO-100 进行遥操作数据采集。
内置了针对消费级硬件优化的训练脚本,无需修改代码即可在单卡上跑起来 5。
8. 深度洞察与未来展望
8.1 具身智能的新公式
SmolVLA 验证了一个新的 AI 研发公式:

它证明了我们不需要等到 GPU 算力再翻 10 倍才能普及机器人。通过算法和系统层面的优化,现有的消费级硬件已经足以支撑相当智能的具身 Agent。
8.2 局限性与未解之题
尽管表现优异,SmolVLA 仍面临挑战 8:
长程任务(Long-Horizon Tasks): 目前模型主要擅长简短的原子动作(如“捡起苹果”)。对于像“煮一杯咖啡”这样包含数十个步骤、需要长时间记忆和规划的复杂任务,SmolVLA 仍显吃力。这可能需要引入分层控制(Hierarchical Control)或结合高层规划器。
跨形态泛化(Cross-Embodiment): 虽然在 SO-100/101 上表现出色,但能否零样本迁移到双臂机器人、人形机器人或轮式机器人上,仍需更多验证。目前的训练数据高度集中在单臂构型上。
VLM 骨干的局限: SmolVLM-2 虽然高效,但主要是基于文档和 OCR 训练的。未来如果能使用针对物理世界视频预训练的 VLM(如基于 Ego4D 训练的模型)作为骨干,可能会有更大的突破。
8.3 结语:从 Demo 到 Deploy
SmolVLA 不仅仅是一个模型,它是一个信号:具身智能正在从“展示 Demo”的炫技阶段,迈向“真实部署(Deploy)”的实用阶段。它告诉我们,通往通用机器人的道路不一定非要是昂贵的、封闭的。通过社区协作、数据共享和极致的工程优化,每个人都可能拥有自己的“Jarvis”。
对于每一位关注 AI 的从业者而言,SmolVLA 值得被视为具身智能领域的“Stable Diffusion 1.5”——一个不够完美,但足够轻量、足够强大、且属于所有人的基石模型。
SmolVLA 论文:https://doi.org/10.48550/arXiv.2506.01844
代码:https://github.com/huggingface/lerobot
Works cited
SmolVLA: How Affordable AI Is Democratizing Robotics With Human ..., accessed January 19, 2026, https://www.xugj520.cn/en/archives/affordable-ai-robotics-smolvla.html
OpenVLA: An Open-Source Vision-Language-Action Model, accessed January 19, 2026, https://openreview.net/forum?id=ZMnD6QZAE6
2506.01844v1.pdf
SmolVLA: A vision-language-action model for affordable and ... - arXiv, accessed January 19, 2026, https://arxiv.org/html/2506.01844v1
SmolVLA: Efficient Vision-Language-Action Model trained on ..., accessed January 19, 2026, https://huggingface.co/blog/smolvla
Experiences from Benchmarking Vision–Language–Action Models ..., accessed January 19, 2026, https://arxiv.org/html/2511.11298v1
Weekly Robotics June #1 - SmolVLA discovery and thoughts, accessed January 19, 2026, https://huggingface.co/blog/Beegbrain/daily-robotics-june
SmolVLA: Efficient Vision Language Action Model - LeRobot, accessed January 19, 2026, https://learnopencv.com/smolvla-lerobot-vision-language-action-model/
Flow Matching and Policy Optimization - Emergent Mind, accessed January 19, 2026, https://www.emergentmind.com/topics/flow-matching-and-policy-optimization
Flow Matching Process - Emergent Mind, accessed January 19, 2026, https://www.emergentmind.com/topics/flow-matching-process
Real-Time VLAs via Future-State-Aware Asynchronous Inference, accessed January 19, 2026, https://arxiv.org/html/2512.01031v1
OpenVLA: Open Source VLA for Robotics - Emergent Mind, accessed January 19, 2026, https://www.emergentmind.com/topics/openvla
HuggingFaceVLA/community_dataset_v1 · Datasets at Hugging Face, accessed January 19, 2026, https://huggingface.co/datasets/HuggingFaceVLA/community_dataset_v1
SmolVLA: compact VLA for robot policy | by Deepthi Karkada | Medium, accessed January 19, 2026, https://medium.com/@deepkarkada/smolvla-compact-vla-for-robot-policy-b30604ac23c5
Hugging Face Releases SmolVLA, a Compact Open ... - Pure AI, accessed January 19, 2026, https://pureai.com/articles/2025/06/10/hugging-face-releases-smolvla.aspx
SmolVLA: A Vision-Language-Action Model for Affordable ... - Liner, accessed January 19, 2026, https://liner.com/review/smolvla-visionlanguageaction-model-for-affordable-and-efficient-robotics
SmolVLA: A Vision-Language-Action Model for Affordable and ..., accessed January 19, 2026, https://huggingface.co/papers/2506.01844
TheRobotStudio/SO-ARM100: Standard Open Arm 100 - GitHub, accessed January 19, 2026, https://github.com/TheRobotStudio/SO-ARM100
SO-ARM100 3D-Printed Robotic Arm Frame - Seeed Studio, accessed January 19, 2026, https://www.seeedstudio.com/SO-ARM100-Low-Cost-AI-Arm-Kit-Pro-p-6343.html
Train SmolVLA - What is LeRobot by Hugging Face? - phosphobot, accessed January 19, 2026, https://docs.phospho.ai/learn/train-smolvla
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 燕京惠泉啤酒2003年在A股上市,股票代码600
- 大金VRV多联机调试及故障代码分析,图文并茂,一学就会!
- 06 Python 爬虫
- 一招搞定!Win/Linux 通用防护,让操作系统安全坚如磐石
- 关于谷歌的 Claude Code 编程助手是一个 200 行代码 Python
- 困在80分:大模型编程的最后一公里与“善后工程师”的崛起
- 我用AI编程实现量化交易知识分享网站
- Linux运维现场:新实习生一个误操作,让我把权限体系讲透了
- 谁能想到,2026年捅破 AI 编程天花板的,竟然是一个在澳大利亚养羊的大叔
- 国产PLM到底差在哪里?——无代码:业务人员的自嗨,IT人员的噩梦
