在制造业、供应链管理等工作中,我们经常会遇到这样的Excel数据:物料路径用“->”串联成一串(比如“自行车整车-1->轮子->轮毂总成->车圈”),想要把这些层级拆分出来、整理成清晰的结构化表格,手动操作不仅费时还容易出错。
今天就教你用Python的pandas库,几行核心代码就能搞定多层级物料路径拆解,还能优化显示格式,让数据一目了然!
一、先看需求场景
我们有一份自行车物料清单Excel,核心字段包括:出货产品、最终材料、数量、材料路径。其中“材料路径”是多层级拼接的字符串,比如:
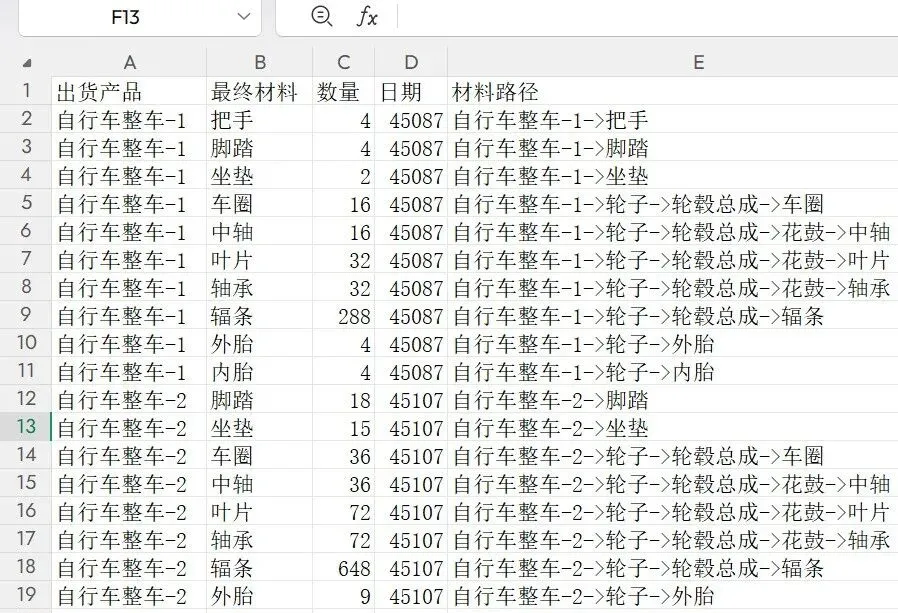
目标是:
- 把“材料路径”按“->”拆分成“第一级、第二级、第三级”等列
- 优化显示:同一出货产品/同一层级的内容,仅首次出现时显示,重复行留空,让表格更整洁
二、核心代码片段解析
1. 路径拆分核心逻辑
首先读取Excel文件,将拼接的物料路径拆分成列表形式,这是层级拆解的基础:
import pandas as pd# 读取Excel文件(替换成你的文件路径)df = pd.read_excel('data0121.xlsx')# 解析材料路径,按->拆分成列表形式df['path_parts'] = df['材料路径'].apply(lambda x: x.split('->'))
2. 提取指定层级材料
定义函数获取不同层级的物料名称,解决“层级不足时返回空值”的问题:
# 定义函数:获取指定层级的材料(level从0开始,0是出货产品本身)defget_level(parts, level):if len(parts) > level:return parts[level]return''# 层级不足时返回空值# 创建新列,存储拆分后的各级材料df['第一级'] = df['path_parts'].apply(lambda x: get_level(x, 1))df['第二级'] = df['path_parts'].apply(lambda x: get_level(x, 2))df['第三级'] = df['path_parts'].apply(lambda x: get_level(x, 3))
3. 优化表格显示效果
让重复的“出货产品”“第一级”内容自动留空,提升表格可读性:
# 优化显示:同一出货产品/第一级,仅首次出现时显示,重复行留空for col in ['出货产品', '第一级']:# 对比当前行和上一行的值,不同则保留,相同则置空 mask = result[col] != result[col].shift(1) result.loc[~mask, col] = ''
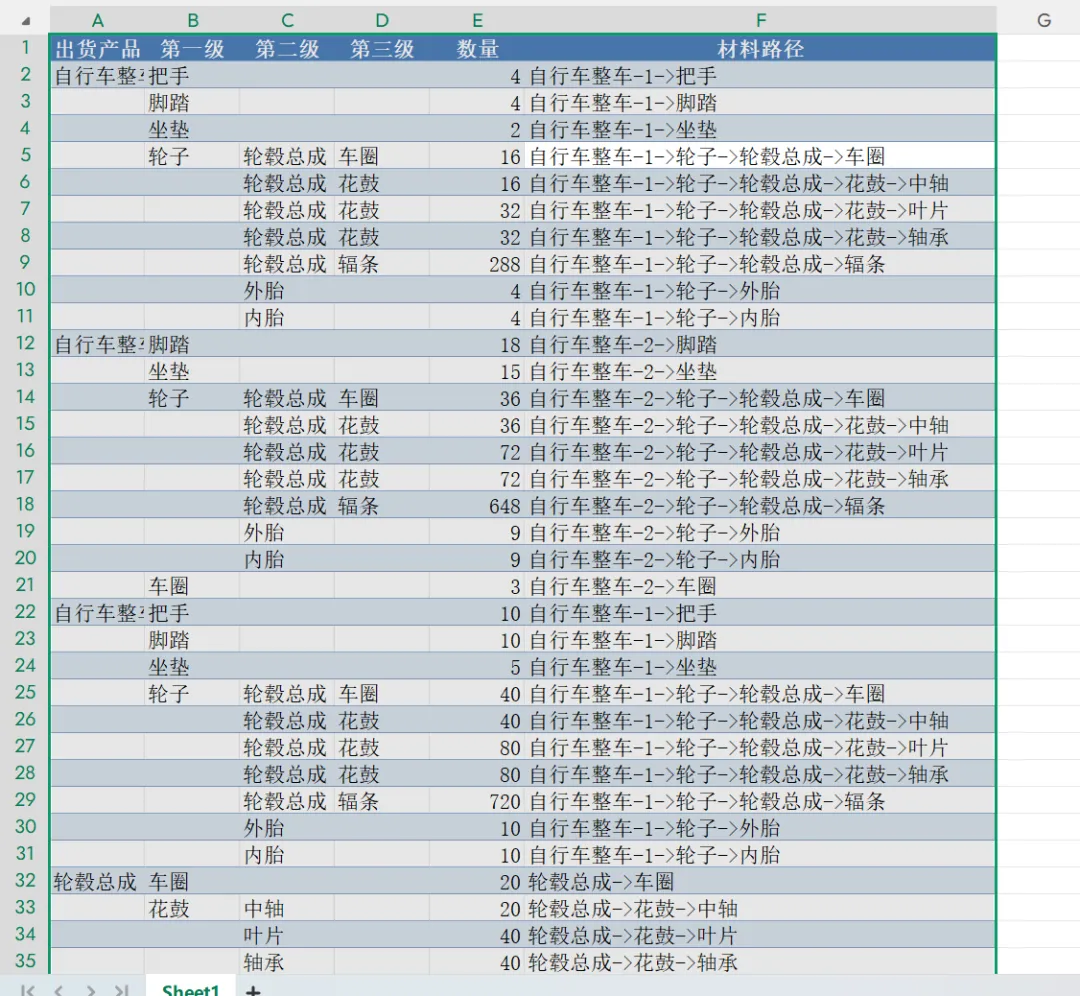
四、处理后效果展示
运行代码后,生成的Excel表格会变成这样(整洁的层级展示):
可以看到:
- 重复的“出货产品”“第一级”内容自动留空,表格视觉上更清晰
五、代码灵活调整技巧
- 层级扩展:如果你的物料路径超过3级,只需新增代码:
df['第四级'] = df['path_parts'].apply(lambda x: get_level(x, 4)) - 列名适配:如果你的Excel列名不是“材料路径”,替换代码中对应的字段名即可
- 显示优化:想让“第二级”也自动留空,只需把
['出货产品', '第一级']改成['出货产品', '第一级', '第二级']
六、获取完整可运行代码
以上仅展示了核心代码片段,完整可直接运行的代码(含依赖安装、文件保存、异常处理等全流程) ,请按照以下步骤获取:
✅ 第一步:点击文章右下角【在看】
✅ 第二步:关注本公众号
✅ 第三步:公众号后台回复关键词【物料拆分】
💡 提示:获取代码后,只需替换Excel文件路径,安装对应依赖(pip install pandas openpyxl),即可直接运行,无需额外修改!
skill:
- 核心逻辑:用
split('->')拆分层级路径,自定义函数get_level提取指定层级内容; - 显示优化:通过
shift(1)对比上下行数据,实现重复内容留空,提升表格可读性; - 完整代码:完成三连关注后,后台回复关键词即可获取全流程可运行代码。
这套方法比手动拆分快10倍以上,尤其适合处理几百上千行的物料清单,再也不用对着Excel逐行改了!
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
