一文浅析linux内核的MQ Deadline调度器
- 2026-07-05 02:30:53
备注:新版本的linux(6.10)中只保留了mq-deadline调度器,该调度器保留了较老的deadline调度器的一些特征。本文分析4.19版本内核实现的MQ Deadline调度器。
在MQ Deadline调度器中使用struct deadline_data描述MQ-Deadline调度器的运行时数据,可用于管理和优化存储设备上的请求调度,该结构实现如下:
structdeadline_data {/* * run time data *//* * requests (deadline_rq s) are present on both sort_list and fifo_list *///红黑树,用于维护请求的排序列表。structrb_rootsort_list[2];//链表头,用于实现先进先出 (FIFO) 的请求列表。这种列表通常用于按照请求到达的顺序进行调度。structlist_headfifo_list[2];/* * next in sort order. read, write or both are NULL *///用于存储下一个请求的指针数组,可以存储读取请求、写入请求或者两者的组合。structrequest *next_rq[2];//表示连续发出的请求的数量unsignedint batching; /* number of sequential requests made *///表示读请求饥饿写请求的次数。可能用于调整读写请求之间的优先级或者调度策略。unsignedint starved; /* times reads have starved writes *//* * settings that change how the i/o scheduler behaves */int fifo_expire[2]; //FIFO 列表中请求的过期时间。这个设置可能用于确定请求在 FIFO 列表中保留的时间长度。int fifo_batch; //FIFO 列表的批处理大小。可用于控制每次处理 FIFO 列表中请求的数量。int writes_starved; //写请求饥饿的次数。可用于调整写请求的优先级或者调度策略。int front_merges; //前端合并次数。可用于优化请求的合并操作,减少磁盘操作次数。spinlock_t lock;spinlock_t zone_lock;structlist_headdispatch;};在内核中,使用struct elevator_type mq_deadline描述MQ Deadline调度器的具体行为:
staticstructelevator_typemq_deadline = { .ops.mq = { .insert_requests = dd_insert_requests, .dispatch_request = dd_dispatch_request, .prepare_request = dd_prepare_request, .finish_request = dd_finish_request, .next_request = elv_rb_latter_request, .former_request = elv_rb_former_request, .bio_merge = dd_bio_merge, .request_merge = dd_request_merge, .requests_merged = dd_merged_requests, .request_merged = dd_request_merged, .has_work = dd_has_work, .init_sched = dd_init_queue, .exit_sched = dd_exit_queue, }, .uses_mq = true, #ifdef CONFIG_BLK_DEBUG_FS .queue_debugfs_attrs = deadline_queue_debugfs_attrs, #endif .elevator_attrs = deadline_attrs, .elevator_name = "mq-deadline", .elevator_alias = "deadline", .elevator_owner = THIS_MODULE,};从上述代码可知,该调度器实现了13个具体的调度行为,后文将分析这些回调函数。
一、调度器初始化/注销
MQ-Deadline调度器的初始化由dd_init_queue()完成,用于具体分配并初始化MQ-Deadline调度器的私有数据和电梯队列:
staticintdd_init_queue(struct request_queue *q, struct elevator_type *e){structdeadline_data *dd;structelevator_queue *eq; eq = elevator_alloc(q, e);if (!eq)return -ENOMEM; dd = kzalloc_node(sizeof(*dd), GFP_KERNEL, q->node);if (!dd) { kobject_put(&eq->kobj);return -ENOMEM; } eq->elevator_data = dd; INIT_LIST_HEAD(&dd->fifo_list[READ]); INIT_LIST_HEAD(&dd->fifo_list[WRITE]); dd->sort_list[READ] = RB_ROOT; dd->sort_list[WRITE] = RB_ROOT; dd->fifo_expire[READ] = read_expire; dd->fifo_expire[WRITE] = write_expire; dd->writes_starved = writes_starved; dd->front_merges = 1; dd->fifo_batch = fifo_batch; spin_lock_init(&dd->lock); spin_lock_init(&dd->zone_lock); INIT_LIST_HEAD(&dd->dispatch); q->elevator = eq;return0;}MQ-Deadline调度器的注销由dd_exit_queue()完成:
staticvoiddd_exit_queue(struct elevator_queue *e){structdeadline_data *dd = e->elevator_data; BUG_ON(!list_empty(&dd->fifo_list[READ])); BUG_ON(!list_empty(&dd->fifo_list[WRITE])); kfree(dd);}在调度器注销操作中则是使用kfree()释放struct deadline_data。
二、插入请求
MQ Deadline调度器的请求插入由dd_insert_requests()实现:
staticvoiddd_insert_requests(struct blk_mq_hw_ctx *hctx, struct list_head *list, bool at_head){structrequest_queue *q = hctx->queue;//获取请求队列structdeadline_data *dd = q->elevator->elevator_data;//获取Deadline调度器的私有数据 spin_lock(&dd->lock);while (!list_empty(list)) { //如果请求列表非空structrequest *rq;//从链表中获取第一个请求 rq = list_first_entry(list, struct request, queuelist);//从链表中移除并初始化该请求的queuelist list_del_init(&rq->queuelist);//将请求 rq 插入到 Deadline 调度器中 dd_insert_request(hctx, rq, at_head); } spin_unlock(&dd->lock);}上述代码将一个链表中的多个请求逐一插入到Deadline调度器中,dd_insert_request()实现核心的插入操作:
staticvoiddd_insert_request(struct blk_mq_hw_ctx *hctx, struct request *rq,bool at_head){//获取请求队列指针structrequest_queue *q = hctx->queue;structdeadline_data *dd = q->elevator->elevator_data;//获取请求的数据方法(读取或写入)constint data_dir = rq_data_dir(rq);/* * This may be a requeue of a write request that has locked its * target zone. If it is the case, this releases the zone lock. *///如果请求是重新排队的写请求并且已锁定其目标区域,则释放该区域的锁定 blk_req_zone_write_unlock(rq);//尝试将请求与现有请求合并,如果成功则直接返回,表示请求已经插入或合并成功。if (blk_mq_sched_try_insert_merge(q, rq))return;//表示请求已经成功插入到调度器中 blk_mq_sched_request_inserted(rq);if (at_head || blk_rq_is_passthrough(rq)) {if (at_head) list_add(&rq->queuelist, &dd->dispatch);else list_add_tail(&rq->queuelist, &dd->dispatch); } else { deadline_add_rq_rb(dd, rq);if (rq_mergeable(rq)) { //判断请求是否可以合并 elv_rqhash_add(q, rq);if (!q->last_merge) q->last_merge = rq; }/* * set expire time and add to fifo list */ rq->fifo_time = jiffies + dd->fifo_expire[data_dir]; list_add_tail(&rq->queuelist, &dd->fifo_list[data_dir]); }}上述代码中,请求插入的核心步骤如下:
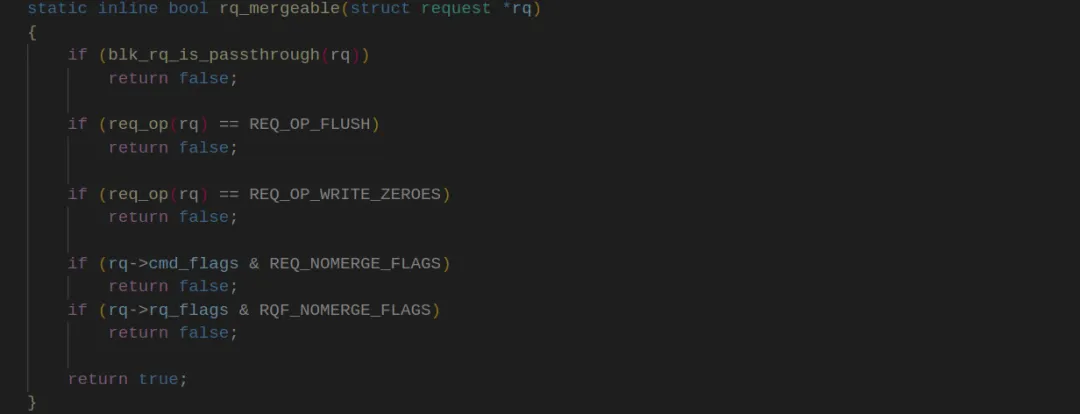
如果at_head为真或者请求为传递请求(blk_rq_is_passthrough(rq)),则将请求插入到dd->dispatch链表的头部或尾部。否则调用deadline_add_rq_rb()将请求插入到 dd 结构中的红黑树中。如果请求可以合并 (rq_mergeable(rq)返回真),则调用elv_rqhash_add()将请求添加到请求哈希表中 ,并更新请求队列的last_merge为当前合并的请求。判断请求是否可以合并的规则是:
设置请求的FIFO超时时间 (rq->fifo_time),并将请求添加到fifo列表dd->fifo_list[data_dir]的尾部。
三、分发请求
在MQ Deadlne调度器实现中,指定.dispatch_requet = dd_dispatch_request,用于处理mq deadline对IO请求的分派算法。
开始描述算法之前,需要解释下什么是最佳请求:
"最佳请求"(Optimal Request)是指在当前的调度策略下,从一组待处理的 I/O 请求中选出最适合立即处理的请求,这种选择依据的标准是最大化性能、最小化延迟等,具体取决于所使用的 I/O 调度器及其算法。调度器为了寻找最佳请求,真是煞费苦心。
->dispatch_requet()调用链:
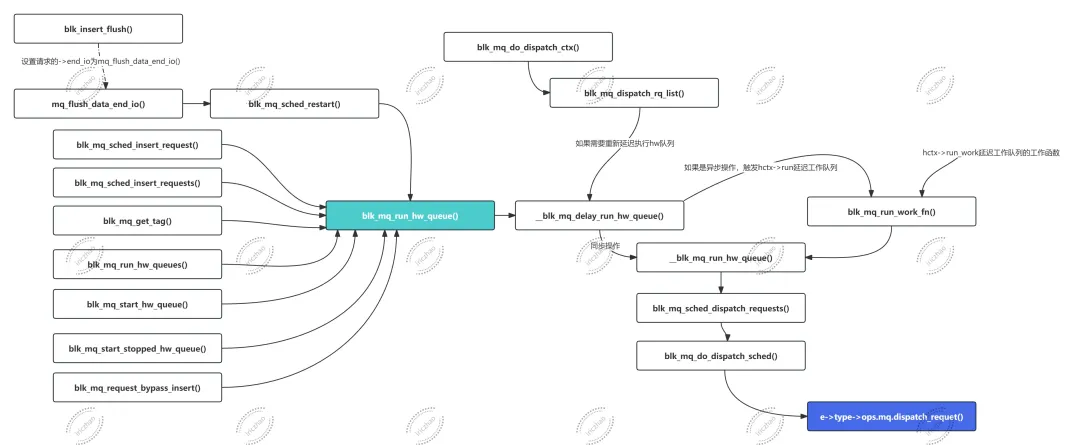
请求分发是一个有趣的实现,也是MQ-Deadline调度器功能的具体体现:
staticstructrequest *__dd_dispatch_request(structdeadline_data *dd){structrequest *rq, *next_rq;bool reads, writes;int data_dir;if (!list_empty(&dd->dispatch)) { rq = list_first_entry(&dd->dispatch, struct request, queuelist); list_del_init(&rq->queuelist);goto done; } reads = !list_empty(&dd->fifo_list[READ]); writes = !list_empty(&dd->fifo_list[WRITE]);/* * batches are currently reads XOR writes */ rq = deadline_next_request(dd, WRITE);if (!rq) rq = deadline_next_request(dd, READ);if (rq && dd->batching < dd->fifo_batch)/* we have a next request are still entitled to batch */goto dispatch_request;/* * at this point we are not running a batch. select the appropriate * data direction (read / write) *//* * 如果有读请求,则优先处理读请求,除非写请求已 * 被饿死(即等待的写请求数超过了允许的最大值)。 */if (reads) { BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ]));if (deadline_fifo_request(dd, WRITE) && (dd->starved++ >= dd->writes_starved))goto dispatch_writes; data_dir = READ;goto dispatch_find_request; }/* * there are either no reads or writes have been starved *//* * 如果没有读请求或者写请求被饿死,则处理写请求。 */if (writes) {dispatch_writes: BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[WRITE])); dd->starved = 0; data_dir = WRITE;goto dispatch_find_request; }returnNULL;dispatch_find_request:/* * 找到适合所选数据方向的最佳请求 */ next_rq = deadline_next_request(dd, data_dir);//如果fifo中没有过期的请求,deadline_check_fifo()返回0,否则返回1if (deadline_check_fifo(dd, data_dir) || !next_rq) {/* * A deadline has expired, the last request was in the other * direction, or we have run out of higher-sectored requests. * Start again from the request with the earliest expiry time. */ rq = deadline_fifo_request(dd, data_dir); } else {/* * The last req was the same dir and we have a next request in * sort order. No expired requests so continue on from here. */ rq = next_rq; }/* * For a zoned block device, if we only have writes queued and none of * them can be dispatched, rq will be NULL. */if (!rq)returnNULL; dd->batching = 0;dispatch_request:/* * rq is the selected appropriate request. */ dd->batching++; deadline_move_request(dd, rq);done:/* * If the request needs its target zone locked, do it. */ blk_req_zone_write_lock(rq); rq->rq_flags |= RQF_STARTED;return rq;}上述代码具体执行步骤如下:
(1)检查并从调度队列中获取请求
if (!list_empty(&dd->dispatch)) { rq = list_first_entry(&dd->dispatch, struct request, queuelist); list_del_init(&rq->queuelist);goto done;}检查调度队列dd->dispatch分发链表是否为空,如果不为空, 从队列头部获取第一个请求rq,并将其从队列中删除,然后就goto到done了。目的就是为了确保调度队列的分发链表中没东西。
(2)检查读写请求是否存在
reads = !list_empty(&dd->fifo_list[READ]);writes = !list_empty(&dd->fifo_list[WRITE]);检查读请求队列dd->fifo_list[READ]和写请求队列dd->fifo_list[WRITE]是否为空。
(3)确定是否运行批处理
rq = deadline_next_request(dd, WRITE);if (!rq) rq = deadline_next_request(dd, READ);if (rq && dd->batching < dd->fifo_batch)/* we have a next request are still entitled to batch */goto dispatch_request;根据当前情况尝试从写请求或读请求中获取下一个请求rq。如果找到请求并且仍有批处理的配额,则跳转到dispatch_request标签执行请求分发。
(4)根据数据方向调度请求
如果存在读请求,则选择最适合的读请求;如果存在写请求且满足条件,则选择最适合的写请求;如果既没有读请求也没有写请求,则返回NULL,表示当前没有可调度的请求。
(5)找到最佳请求并调度
根据选定的数据方向(即读/写)找到最佳请求next_rq。如果fifo中存在过期的请求或者next_rq没有找到,则使用到达顺序列表(dd->fifo_list,顺序列表分为读fifo列表和写fifo列表)返回下一个要调度的请求,即遵循先进先出的规则;如果不存在过期的请求或者next_rq找到了,则将其作为待分发的请求进行分发。
🔺如何寻找最佳请求next_rq?
寻找最佳请求由deadline_next_request()实现:
static struct request *deadline_next_request(struct deadline_data *dd, int data_dir){structrequest *rq;unsignedlong flags;if (WARN_ON_ONCE(data_dir != READ && data_dir != WRITE))returnNULL; rq = dd->next_rq[data_dir];if (!rq)returnNULL;//如果是读请求,或者请求队列不是分区设备,直接返回请求指针。if (data_dir == READ || !blk_queue_is_zoned(rq->q))return rq;/* * Look for a write request that can be dispatched, that is one with * an unlocked target zone. *///如果请求是写请求且请求队列是分区设备,还需要进一步检查请求的目标分区是否解锁。 spin_lock_irqsave(&dd->zone_lock, flags);while (rq) {if (blk_req_can_dispatch_to_zone(rq))break; rq = deadline_latter_request(rq); } spin_unlock_irqrestore(&dd->zone_lock, flags);return rq;}上述代码中,对于读请求或非分区设备的写请求,直接返回下一个请求;对于分区设备的写请求,需要检查目标分区是否解锁。通过加锁和解锁操作,保证对分区设备请求的安全访问。
🔺fifo中请求是否过期的判断依据是什么?
将struct request中的fifo_time与jiffies进行比较, 如果jiffies大于或等于rq->fifo_time,则表明请求过期了。
(6)处理批处理和请求移动
增加批处理计数,并移动选定的请求到相应位置,本质则是将请求移动到dispatch分发队列:
staticvoiddeadline_move_request(struct deadline_data *dd, struct request *rq){constint data_dir = rq_data_dir(rq); dd->next_rq[READ] = NULL; dd->next_rq[WRITE] = NULL;//通过访问rq请求节点的红黑树下一个节点来获取下一个请求 dd->next_rq[data_dir] = deadline_latter_request(rq);/* * take it off the sort and fifo list *///从红黑树和FIFO列表中移除请求 deadline_remove_request(rq->q, rq);}四、准备请求
对于MQ-Deadline调度器仅提供了准备请求对应的函数,但没有实现必要的操作。定义该函数只是为了确保.finish_request方法在请求完成时调用。
staticvoiddd_prepare_request(struct request *rq, struct bio *bio){}五、完成请求
对于MQ-Deadline调度器的完成请求,由dd_finish_request()实现,目的是为了在请求处理完成后执行一些清理工作:
staticvoiddd_finish_request(struct request *rq){structrequest_queue *q = rq->q;//判断请求队列q是否支持分区管理。如果支持,则需要处理分区锁定if (blk_queue_is_zoned(q)) {structdeadline_data *dd = q->elevator->elevator_data;unsignedlong flags; spin_lock_irqsave(&dd->zone_lock, flags);//释放请求 rq 所关联的分区锁定。 blk_req_zone_write_unlock(rq); spin_unlock_irqrestore(&dd->zone_lock, flags); }}六、合并请求
在对请求进行合并时,提供了四种方法予以实现:
(1).request_merge:尝试将bio合并到现有请求中,并返回结果。
(2).requests_merged:当两个请求合并时调用。
(3).bio_merge:尝试将bio合并到现有请求中。
(4).request_merged: 当两个请求合并时调用(第二种情况)。
1、->bio_merge()
将bio合并到现有请求,函数调用链如下:
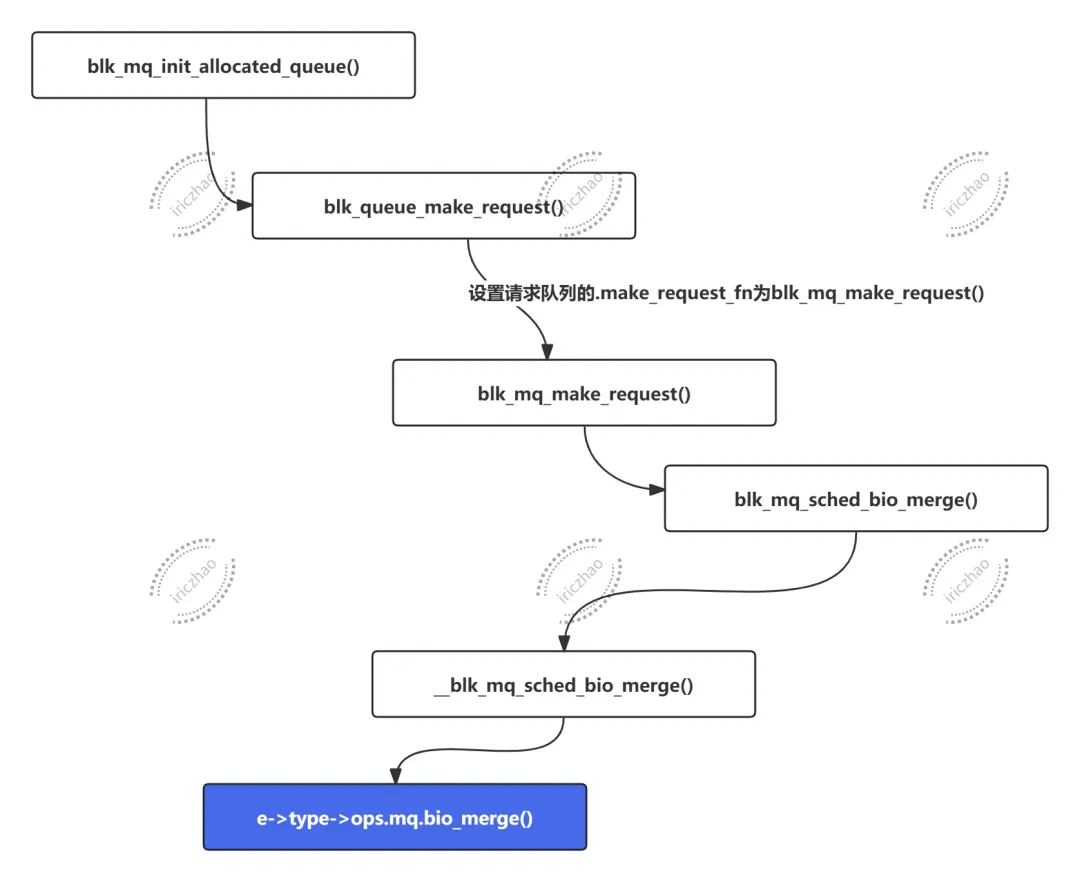
将bio合并到现有请求由dd_bio_merge()实现:
staticbooldd_bio_merge(struct blk_mq_hw_ctx *hctx, struct bio *bio){structrequest_queue *q = hctx->queue;structdeadline_data *dd = q->elevator->elevator_data;structrequest *free = NULL;bool ret; spin_lock(&dd->lock);/* * 将bio合并到已有请求中。如果合并成功,ret将为真,并且free可能会指向被释放的请求。 */ ret = blk_mq_sched_try_merge(q, bio, &free); spin_unlock(&dd->lock);/* * 如果free指向了一个请求(即blk_mq_sched_try_merge()中有请求被释放), * 则调用blk_mq_free_request()释放这个请求的内存。 */if (free) blk_mq_free_request(free);return ret;}请求合并的核心操作由blk_mq_sched_try_merge()完成(/block/blk-mq-sched.c):
boolblk_mq_sched_try_merge(struct request_queue *q, struct bio *bio, struct request **merged_request){structrequest *rq;switch (elv_merge(q, &rq, bio)) {case ELEVATOR_BACK_MERGE:if (!blk_mq_sched_allow_merge(q, rq, bio))returnfalse;if (!bio_attempt_back_merge(q, rq, bio))returnfalse; *merged_request = attempt_back_merge(q, rq);if (!*merged_request) elv_merged_request(q, rq, ELEVATOR_BACK_MERGE);returntrue;case ELEVATOR_FRONT_MERGE:if (!blk_mq_sched_allow_merge(q, rq, bio))returnfalse;if (!bio_attempt_front_merge(q, rq, bio))returnfalse; *merged_request = attempt_front_merge(q, rq);if (!*merged_request) elv_merged_request(q, rq, ELEVATOR_FRONT_MERGE);returntrue;case ELEVATOR_DISCARD_MERGE:return bio_attempt_discard_merge(q, rq, bio);default:returnfalse; }}上述代码根据elv_merge(q, &rq, bio)返回值实现了三种合并方式:后端合并、前端合并和丢弃合并。
(1)后端合并:返回值为ELEVATOR_BACK_MERGE表示后端合并。在请求队列中,当一个新的 bio 被尝试合并到一个已存在请求的后端(即请求的尾部),并且合并操作成功时,通常会返回ELEVATOR_BACK_MERGE。这种合并操作可以有效将多个小的bio合并为一个较大的请求,从而减少设备的寻址和处理开销,提高系统性能和效率 。
(2)前端合并:返回值为ELEVATOR_FRONT_MERGE表示前端合并。与后端合并相反,当一个新的bio被尝试合并到一个已存在请求的前端(即请求的头部),并且合并操作成功时,会返回ELEVATOR_FRONT_MERGE。前端合并通常发生在请求队列的头部,这样可以将新的bio与已有请求的前部分合并,从而形成一个更大的请求,同样可以优化设备访问和提高性能。
(3)丢弃合并:返回值为ELEVATOR_DISCARD_MERGE表示丢弃合并。在某些情况下,当一个新的bio无法与已有请求进行有效合并时,会返回ELEVATOR_DISCARD_MERGE。这种情况通常发生在合并策略不允许或者不适合合并新的bio到现有请求时,调度器可能会选择不进行合并操作,而是单独处理新的bio。
2、->request_merge()
->request_merge函数调用链:
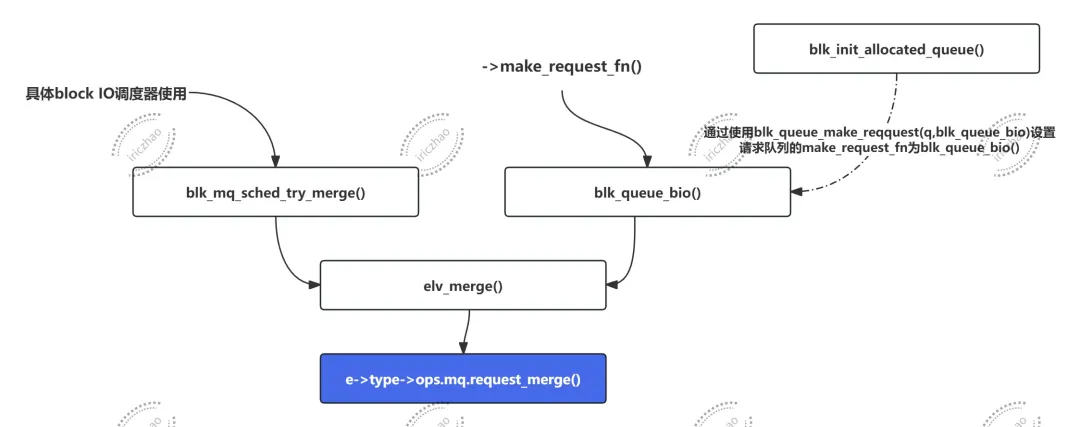
staticintdd_request_merge(struct request_queue *q, struct request **rq, struct bio *bio){structdeadline_data *dd = q->elevator->elevator_data;sector_t sector = bio_end_sector(bio);structrequest *__rq;//如果 deadline 调度器不支持前端合并,直接返回 ELEVATOR_NO_MERGE 表示无法合并。if (!dd->front_merges)return ELEVATOR_NO_MERGE;//在 dd->sort_list 中的指定红黑树 (bio_data_dir(bio) 决定的方向) 中查找与 sector 对应的请求。 __rq = elv_rb_find(&dd->sort_list[bio_data_dir(bio)], sector);if (__rq) { BUG_ON(sector != blk_rq_pos(__rq)); //断言请求的扇区号与sector相等//检查是否可以合并bio到__rq中if (elv_bio_merge_ok(__rq, bio)) {//如果可以合并 *rq = __rq; //将 __rq 赋值给 *rqreturn ELEVATOR_FRONT_MERGE;//返回 ELEVATOR_FRONT_MERGE 表示前端合并成功。 } }return ELEVATOR_NO_MERGE;}3、->requests_merged()
->requests_merged函数调用链:
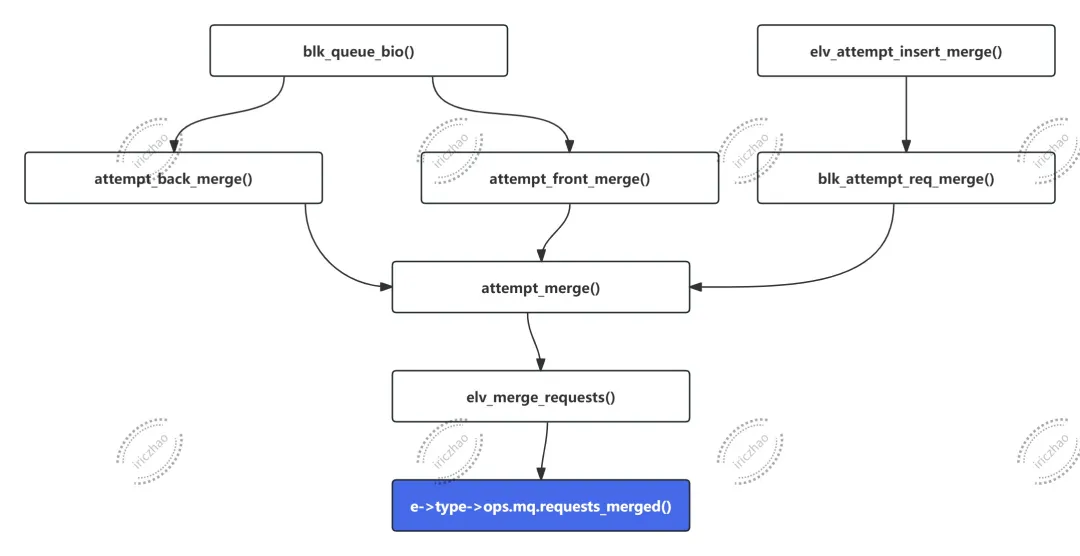
staticvoiddd_merged_requests(struct request_queue *q, struct request *req, struct request *next){/* * if next expires before rq, assign its expire time to rq * and move into next position (next will be deleted) in fifo */if (!list_empty(&req->queuelist) && !list_empty(&next->queuelist)) {//比较 next->fifo_time 和 req->fifo_time 的大小。fifo_time 表示请求在队列中的到期时间。if (time_before((unsignedlong)next->fifo_time, (unsignedlong)req->fifo_time)) {/如果 next 的到期时间早于 req 的到期时间,说明 next 在队列中应该位于 req 的前面。 list_move(&req->queuelist, &next->queuelist); //将req从其当前位置移动到next的位置,这样next将会被删除。 req->fifo_time = next->fifo_time; //将req的fifo_time更新为next的fifo_time,确保队列中请求的顺序和到期时间的正确性。 } }/* * kill knowledge of next, this one is a goner *///清理并移除next请求,这表明next请求已经完成或被合并到req中,不再需要。 deadline_remove_request(q, next);}4、->request_merged()
->request_merged回调函数调用链:
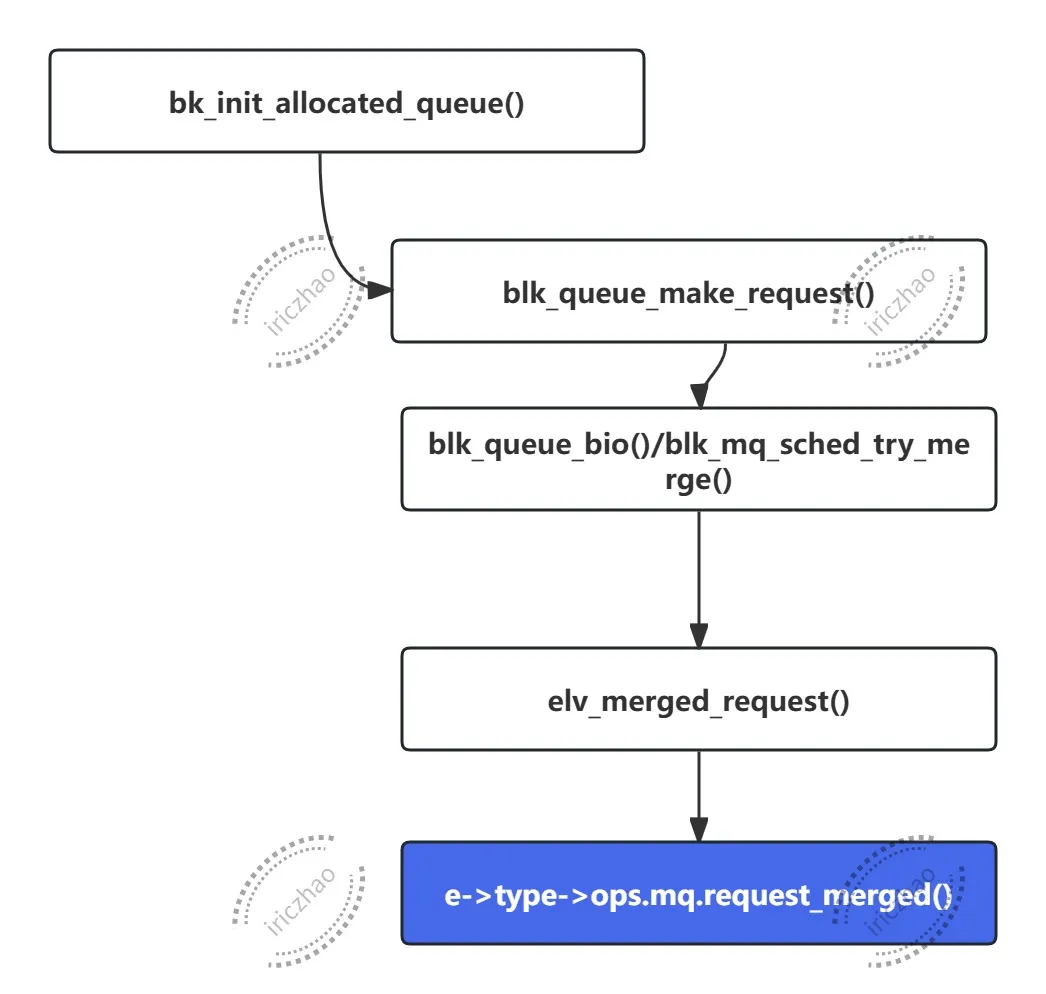
上述调用链将调用到具体调度器中实现的.request_merged。
staticvoiddd_request_merged(struct request_queue *q, struct request *req,enum elv_merge type){structdeadline_data *dd = q->elevator->elevator_data;/* * if the merge was a front merge, we need to reposition request */if (type == ELEVATOR_FRONT_MERGE) { elv_rb_del(deadline_rb_root(dd, req), req); deadline_add_rq_rb(dd, req); }}如果合并类型是前端合并 (ELEVATOR_FRONT_MERGE),则执行以下操作:
调用 elv_rb_del()从红黑树中删除req请求。调用 deadline_add_rq_rb()函数将req重新添加到红黑树中。
为什么在红黑中既然删除了请求又要重新添加请求呢?这是为了调整请求在红黑树中的位置,因为前端合并通常会导致请求位置或者其属性发生变化,因此需要重新调整请求在红黑树中的位置或者其状态。
七、可调参数
本小节内容参考于 内核文档:/block/deadline-iosched.txt
对于MQ-Deadline调度器来说,存在几个可以调整的参数,他们都具有一个初始值,在第一个初始化MQ Deadline调度器的时候配置调度器:
staticconstint read_expire = HZ / 2; /* max time before a read is submitted. */staticconstint write_expire = 5 * HZ; /* ditto for writes, these limits are SOFT! */staticconstint writes_starved = 2; /* max times reads can starve a write */staticconstint fifo_batch = 16; /* # of sequential requests treated as one by the above parameters. For throughput. */(1)read_expire(毫秒)
deadline IO调度器的目标,是尽量保证一个请求能够在一定时间内开始被服务。由于我们主要关注的是读请求的延迟,因此该参数是可调的。当一个读请求首次进入IO调度器时,会被分配一个deadline,其值为:
当前时间 + read_expire(单位:毫秒)一旦超过该 deadline,调度器就会优先调度该请求,以避免读请求延迟过大。
(2)write_expire(毫秒)
与上面的 read_expire 类似,但作用对象是写请求。
(3)fifo_batch(请求个数)
请求会按数据方向(读 / 写)被分组为若干个 “批次(batch)”,并在批次内部按照扇区号递增顺序进行服务。为了减少额外的磁头寻道,只有在批次之间才会检查请求是否已经过期(deadline expiry)。fifo_batch用于控制每个批次中允许包含的最大请求数量。该参数用于在单请求延迟与整体吞吐量之间进行权衡:
当低延迟是首要目标时,值越小越好,当取值为 1时,行为接近 先来先服务(FCFS)。增大 fifo_batch通常可以提高吞吐量,代价是延迟波动增大。
(4)writes_starved(调度次数)
当需要将请求从 IO 调度器队列移动到块设备的 dispatch 队列时,调度器始终优先调度读请求。但我们并不希望写请求被无限期饿死(starvation)。因此writes_starved用来控制:在多少次调度中优先选择读请求而不调度写请求,当这种“读优先”的调度行为发生了writes_starved次之后,调度器就会开始调度一些写请求,其选择标准与读请求相同。
(5)front_merges(布尔值)
有时一个新进入IO调度器的请求,可能与队列中已有的请求在地址上是连续的:
可以拼接到已有请求的末尾 ,即back merge。 可以拼接到已有请求的前面 ,即front merge。
由于文件在磁盘上的布局方式,back merge 远比front merge常见。在某些工作负载下,我们甚至可以明确知道:尝试front merge完全是在浪费时间。将front_merges设为0可以禁用front merge功能。需要注意的是:
由于 last_merge的缓存提示机制,front merge仍然可能发生。但该路径的代价几乎为 0,因此保留。实际禁用的是:在调用 IO 调度器merge函数时,基于rbtree的front-sector查找。
八、总结
综上所述,对于每个队列,MQ Deadline调度器根据请求的截止时间(deadline)和扇区号(sector)进行调度决策。MQ Deadline最佳请求的选择规则:
按照截止时间调度:优先选择截止时间最近的请求,确保高响应速度和低延迟。 按照扇区号调度:如果有多个请求截止时间相近,则选择扇区号最小的请求,以最小化磁头移动的距离,提高磁盘的顺序访问性能。 避免饥饿:在调度时要考虑避免某些请求长时间等待,采用一定的公平性策略保证每个队列都有机会进行磁盘访问。
MQ Deadline的三种派发规则:
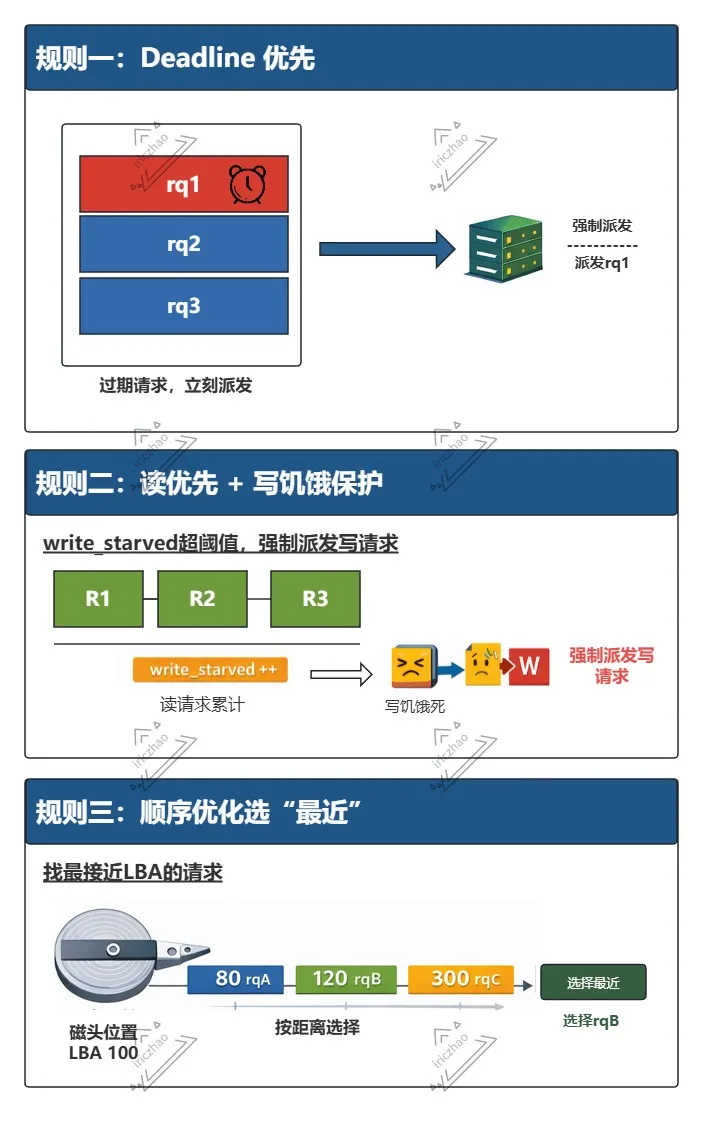
对于每个队列,MQ Deadline调度器会首先检查是否有截止时间已到的请求,优先调度这些请求。如果没有截止时间已到的请求,它会根据扇区号选择接下来的请求。
参考链接:
https://documentation.suse.com/sles/12-SP5/html/SLES-all/cha-tuning-io.html
https://lore.kernel.org/linux-block/20240118180541.930783-1-axboe@kernel.dk/?s=09
https://www.cnblogs.com/kanie/p/15252921.html
http://bos.itdks.com/c993e395c78948f3a2093d27d34f4f1b.pdf
https://www.phoronix.com/review/linux-56-nvme
https://bbs.deepin.org/post/203997
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 丰富资源助力多角度学习Java EE框架应用开发(SpringBoot+VueJS)
- 8个操作学会Linux启动!轻松上手
- 代谢重编程与骨骼肌再生:杨忠奇教授团队在药学权威期刊Pharmacological Research发表前沿综述
- 送了老弟一台 Linux 服务器,它又懵了!
- JAVA实习生问为什么项目不用VO?
- 热水器显示E1怎么办?一文读懂所有故障代码,自己也能当维修工!
- “我”的编程通关日志
- python游戏好开发吗?
- Python操作Excel|Part 10: 内容一键映射修正
- Destination Linux 专访梁宇宁:RISC-V 与开放计算的未来
