python缺失值处理方法大全
- 2026-06-23 14:18:49
前言
在一般情况下,我们所收集得到的数据不可能是“完美无暇”的,通常会包含缺失值、异常值等让我们头疼的情况,对于数据挖掘或数据分析,花费时间最长的不是建模方面,反而是在数据清洗阶段。为了保证数据质量以及模型的可靠性,数据清洗就显得尤为重要,本文将重点讲解该如何处理缺失值。
一、什么是缺失值?
缺失值是指在数据集中某些位置或字段缺失数据或信息的情况。在实际的数据收集与记录的过程中,可能由于各种原因导致部分数据缺失。缺失值通常会用“NaN”、“None”或空字符串表示。缺失值一般会对数据分析与建模产生影响,所以需要对缺失值进行处理清洗。
二、缺失值检测
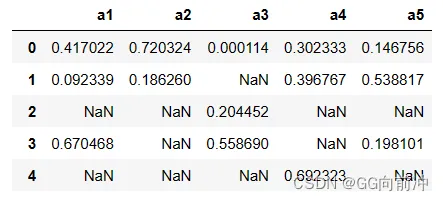
首先随机生成数据,并随机设置缺失值:
import numpy as npimport pandas as pdimport randomnp.random.seed(1) #随机种子data=np.random.rand(80,5)np.random.seed(11) m=np.random.choice([True,False],[80,5],(0.05,0.95)) #第一个表示取值,第二个表示个数,第三个表示概率m[0,2]=False #保持第一行为全数据,即第一行无缺失值data[m]=np.nandf= pd.DataFrame(data, columns=['a1', 'a2', 'a3','a4','a5'])生成80×5的数据集,其中缺失值为随机指定。
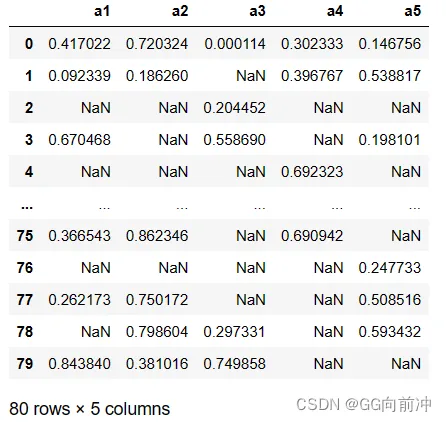
1. df.isnull()
df.isnull()会返回一个布尔类型的值,其中缺失值的位置为True
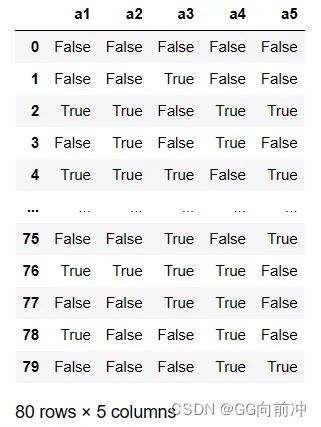
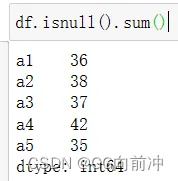
df.isnull()通常会与函数sum()搭配使用
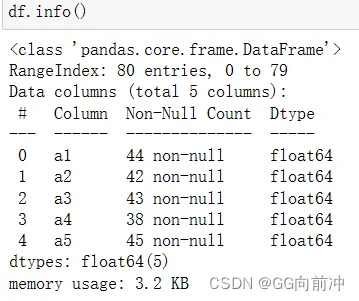
2. df.info()
使用 Pandas 的 info() 方法可以查看每列的非空值数量,通过比较总行数和非空值数量可以初步判断是否存在缺失值。
3. df.isna()
与 isnull() 和 notnull() 类似,isna() 和 notna() 方法也可以用来检测缺失值。

三、异常值与缺失值
对于异常值(注意:这里讨论的是数据集中与其他观测值明显不同的数据点,如数值列[1,2,3..]中出现[“你”,“?*”]等异常元素),通常会进行删除操作或者是将其视为缺失值,但删除操作的缺点是在数据量较少的情况下,无论是缺失值还是异常值,都容易造成数据信息丢失过多,使得数据样本进一步减少,导致模型性能较低或者是不准确。因此,将异常值视为缺失值来处理的益处在于可以利用现有变量的信息进行建模挖掘,对异常值(缺失值)进行填补,而不必对异常值直接进行删除处理。

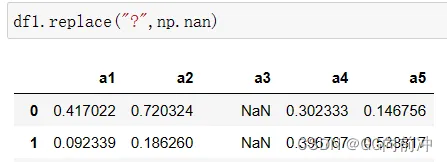
下面将缺失值替换为空值:
四、缺失值处理
1.删除处理
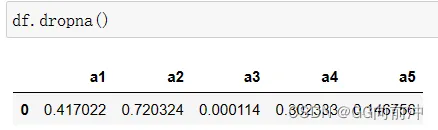
如果缺失值的比例很小,可以考虑直接删除包含缺失值的观测行或列。通常使用Pandas 中使用 dropna() 方法删除包含缺失值的行或列。
参数:
1. axis=0 表示删除列,默认为1。 2. how="all" 删除全是空值的数据,any表示只要有一个就删除。 3. thresh=3 表示一行或者是一列中有至少3个非空值的话将会被保留。 4. subset=["a1","a2"] 表示删除在a1 或a2 列中有缺失值的行。
2.填充缺失值
对于数值型数据,可以使用均值、中位数或其他统计量来填充缺失值,使得数据分布不受太大影响,Pandas 中使用 fillna() 方法来填充缺失值。
(1) 利用字典单独设置填充值:
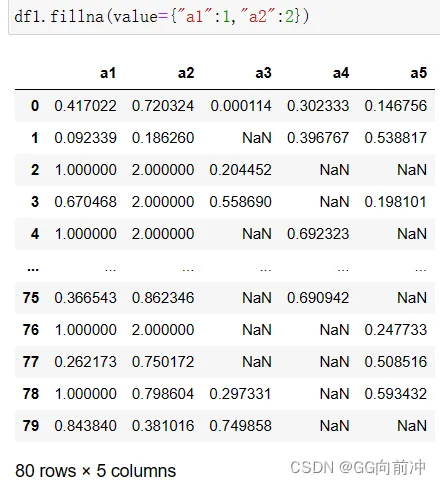
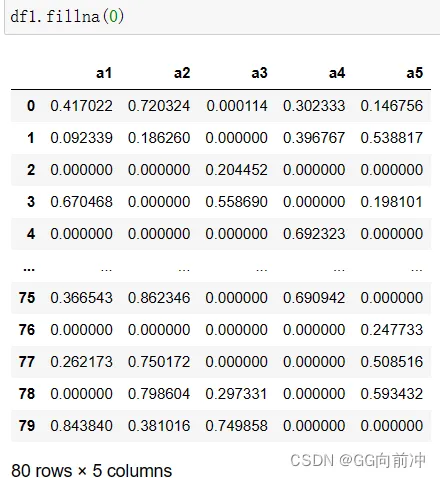
对缺失值填充0
(2) 填充聚合值
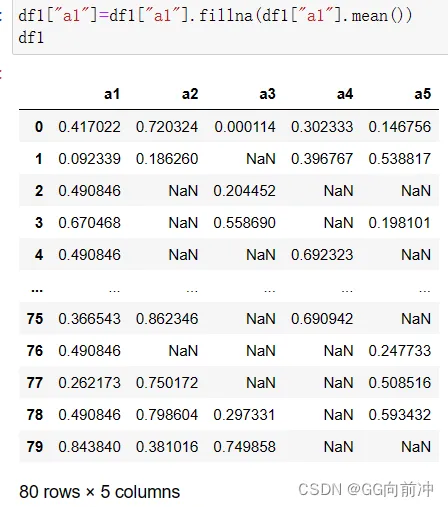
可以对缺失值填充聚合值,对于数值类型,可以填充如平均值、最大值等;如果是字符串,则可以选择众数。下面对a1列填充该列的均值:
(3) 利用缺失位置上下的值来填充
可以用该列中的前一个或下一个值替换该列中的缺失值。在处理时序列数据时,此方法可能会派上用场。 假设我们有一个数据集,包含每天的天气温度,其中某一天的数据缺失,这个时候我们可以用前一天或者是后一天的温度代替作为最佳的解决方案。

(4) 利用插值方法来填充
利用插值方法填充缺失值是一种常见的缺失值处理技术,它可以根据已知数据点的数值来推断缺失值,并填充这些缺失值。在 Pandas 中,可以使用 interpolate() 方法来进行插值填充。
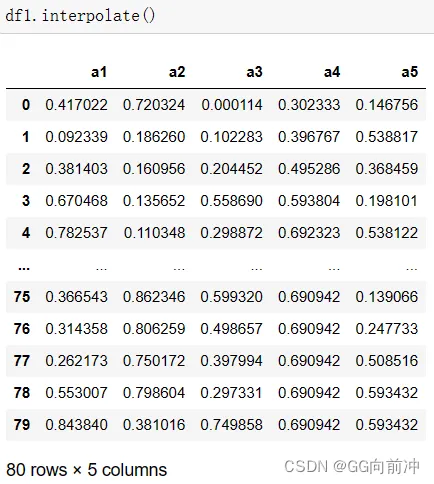
上面代码使用了线性插值填充,实现根据已知数据点的数值,在缺失位置进行线性插值技术,然后填充缺失值,除了线性插值外,Pandas 还支持其他插值方法,例如:
1. 基于时间的插值:method='time',如果数据集中存在时间序列数据,可以尝试使用基于时间的插值方法。 2. 二次插值:method='quadratic',二次插值通过已知的数据点构建一个二次多项式来逼近未知的数值。 3. 三次插值:method='cubic',三次插值是一种常用的插值方法,通过已知的数据点构建一个三次多项式来逼近未知的数值。 4. 三次样条插值:三次样条插值相比于简单的三次插值更加灵活和准确,因为它提供了更高的插值精度和更好的曲线平滑性。 5. 拉格朗日插值:拉格朗日插值使用拉格朗日多项式逼近已知数据点,通过构造一个通过所有数据点的插值多项式来估计其他点的数值。
(5) 使用模型预测填充
我们可以通过构造模型来填充缺失值,如利用机器学习、统计学模型来预测缺失值的数据与类别,然后用这些预测值填充数据集中的缺失值。需要注意的是,在使用模型预测填充时,选择合适的模型和特征工程方法非常重要,以确保填充值的准确性和可靠性。此外,还应该对填充后的数据进行验证和评估,以确保填充效果符合预期。下面随机生成物理、化学和数学成绩的数据集,其中单独设置数学成绩包含空值,而其他两科成绩作为自变量,将进行训练后预测数学成绩,得到的预测值替换为数学成绩的缺失值,注意这是一个简单的示例,具体应用需结合实际情况设计更加复杂符合情景的模型或方法(如需要对数据进行特征工程等):
import pandas as pdimport numpy as npfrom sklearn.linear_model import LinearRegression# 生成示例数据集np.random.seed(42)data = pd.DataFrame({'Physics_Score': np.random.randint(60, 100, 10),'Chemistry_Score': np.random.randint(60, 100, 10),'Math_Score': [85, 70, 92, np.nan, 78, np.nan, 88, 75, np.nan, 80]})# 划分训练集和测试集train_data = data[data['Math_Score'].notnull()] #非空值数据test_data = data[data['Math_Score'].isnull()] #空值数据# 准备特征train_features = train_data[['Physics_Score', 'Chemistry_Score']]train_target = train_data['Math_Score']test_features = test_data[['Physics_Score', 'Chemistry_Score']]# 使用线性回归模型进行训练和预测model = LinearRegression()model.fit(train_features, train_target)predicted_scores = model.predict(test_features)# 将预测结果填充回原始数据集data.loc[data['Math_Score'].isnull(), 'Math_Score'] = predicted_scores# 打印填充后的数据集print(data)注意:可以通过对非空数据集进行划分成两个子集,其中一个用来训练模型,另外一个数据集用来验证模型的效果,来确保对缺失值的预测质量,提高数据的可靠性。
(6) 特定领域知识填充
对于特定领域的数据,可以利用领域知识来填充缺失值。例如,对时间序列数据可以使用时间相关的填充方法,比如星期一到星期天的数据,在其中缺少了星期二这个日期,则可以根据日期时间推断缺少的数据是星期几。
总结
本文主要介绍了什么是缺失值、缺失值的检测以及如何去处理缺失值,对于缺失值处理的各种方法,大家需要视情况而定,不能照搬照套,每种方法都有其自己的优缺点,都有着自己适应的地方,发光发亮的场景,例如删除处理方法简单高效,在数据量大、缺失值较少的数据集中,是不二之选的方法,但缺点就是如果数据量太少,容易造成数据原始信息丢失等,所以在使用某种方法的时候需考虑该方法的优缺点,并根据数据集的特点和需求来确定是否适合使用该方法。

