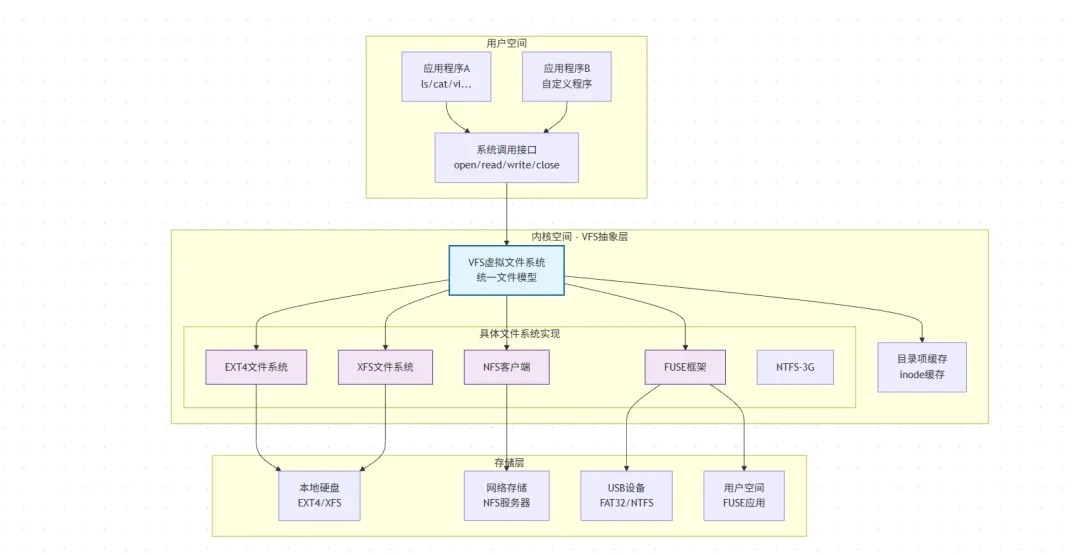
想象这样一个场景:你的Linux系统中,根目录使用ext4格式,从网络加载着NFS共享文件夹,同时通过FUSE访问着sshfs的远程文件——而这些完全不同的文件系统,却通过完全相同的open()、read()、write()、close()系统调用被应用程序使用。
这看似魔法的无缝体验背后,正是虚拟文件系统(Virtual Filesystem Switch, VFS) 的杰作。如同联合国为各主权国家提供一套通用的议事规则,VFS 在 Linux 内核中定义了一套统一的抽象接口与数据结构,让 EXT4、XFS、Btrfs、乃至 FAT32 等数十种文件系统能够遵循同一套“协议”运作,从而对上层应用隐藏了所有底层差异,提供了完美一致的文件视图。
1.VFS核心架构剖析
我们先从整体结构来看,可以分为三层来理解,第一层是用户接口,也就是通过系统调用来执行对应操作(如open、close、read等);第二层是内核空间中文件系统,其通过注册分发方式调用不同的文件系统代码(也可以认为是两层,一层抽象,一层具体实现);最后是存储层,根据客户端的调用来执行对应操作并返回结果。
2.代码剖析
代码剖析部分我们将主要聚焦于统一文件模型的构建,特定文件系统的实现我们后面再去讲解,为了方便讲清楚实现逻辑,我们可以从流程上来看,通过其调用以及使用关系去梳理,首先是系统调用部分,其通过传入的fd拿到vfs层的file对象(包含file对象指针,同时会对文件引用计数进行管理)。:
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count){ return ksys_read(fd, buf, count);}
ssize_tksys_read(unsignedint fd, char __user *buf, size_t count){ struct fd f = fdget_pos(fd); // 通过文件描述符fd获取struct fd结构体,包含file对象指针,同时增加文件引用计数 ssize_t ret = -EBADF; // 初始化返回值为"坏文件描述符"错误,默认操作失败 if (f.file) { // 检查是否成功获取到file对象(即fd有效) loff_t pos, *ppos = file_ppos(f.file); // 获取文件当前读写位置指针ppos if (ppos) { // 若存在读写位置指针(普通文件有,管道、设备文件可能无) pos = *ppos; // 缓存当前读写位置到局部变量pos,避免并发操作导致位置错乱 ppos = &pos; // 将ppos指向局部缓存pos,后续操作基于缓存位置 } ret = vfs_read(f.file, buf, count, ppos); // 调用VFS层统一读接口vfs_read,执行核心读操作 if (ret >= 0 && ppos) // 若读操作成功且存在位置指针,更新文件实际读写位置 f.file->f_pos = pos; fdput_pos(f); // 释放struct fd结构体,减少文件引用计数 } return ret; // 返回读操作结果(成功返回读取字节数,失败返回错误码)}
接下来我们来看vfs_read到底做了什么,其主要做的就是校验和调用转发,也就是转发到file->f_op->read(file, buf, count, pos)。
ssize_t vfs_read(structfile *file, char __user *buf, size_t count, loff_t *pos){ ssize_t ret; // 存储读操作返回结果 // 1. 基础权限校验:检查文件是否具备可读模式 if (!(file->f_mode & FMODE_READ)) return -EBADF; // 无读权限,返回坏文件描述符错误 // 进一步检查文件是否具备实际可读能力(避免名义可读但实际不可读的异常) if (!(file->f_mode & FMODE_CAN_READ)) return -EINVAL; // 无效参数错误 // 2. 安全校验:检查用户空间缓冲区地址合法性,避免内核访问非法内存 if (unlikely(!access_ok(buf, count))) return -EFAULT; // 内存访问错误 // 3. 读区域合法性校验:检查读写位置和长度是否超出文件范围等 ret = rw_verify_area(READ, file, pos, count); if (ret) return ret; // 校验失败,返回对应错误码 // 4. 限制单次读长度,避免过度占用系统资源 if (count > MAX_RW_COUNT) count = MAX_RW_COUNT; // 截断为内核允许的最大读写长度 // 5. 核心转发逻辑:根据文件系统实现的读接口,动态调用对应函数 if (file->f_op->read) // 优先调用传统同步读接口(兼容旧文件系统实现) ret = file->f_op->read(file, buf, count, pos); else if (file->f_op->read_iter) // 无传统读接口则调用迭代式读接口(高效I/O场景) ret = new_sync_read(file, buf, count, pos); // 封装为同步读操作 else ret = -EINVAL; // 无有效读接口,返回无效参数错误 // 6. 后置处理:操作成功则发送通知并统计数据 if (ret > 0) { fsnotify_access(file); // 发送文件访问通知,供inotify等监控机制使用 add_rchar(current, ret); // 统计当前进程的读字节数,用于系统性能分析 } inc_syscr(current); // 递增当前进程的系统调用计数,记录系统调用频率 return ret; // 返回最终读操作结果}
从上面我们看到,核心的实现再file->f_op->read,我们先来看看file结构,其作为进程与文件的“交互中介”,它整合了文件的路径、元数据(inode)、操作集(file_operations)、访问状态(读写位置、权限、标志位)等关键信息,让VFS能精准把控进程对文件的访问过程。其中,f_op字段是连接VFS与底层文件系统的核心枢纽,f_inode关联文件的元数据,f_pos记录进程的读写进度,这三个字段共同支撑起文件访问的完整链路。struct file {union {struct llist_node fu_llist; // 用于将文件对象链接到线程的文件链表(快速释放场景)struct rcu_head fu_rcuhead; // RCU(读-复制-更新)机制的头部,用于文件对象的延迟释放 } f_u; // 联合结构,节省内存,不同场景下使用不同成员struct path f_path; // 文件的路径结构体,包含dentry(目录项)和vfsmnt(挂载点),关联文件的具体位置struct inode *f_inode; /* cached value */ // 缓存对应的inode指针(文件的元数据载体),避免重复查找,提升效率const struct file_operations *f_op; // 指向该文件所属文件系统的操作集,是VFS转发操作的核心指针/* * Protects f_ep_links, f_flags. * Must not be taken from IRQ context. */spinlock_t f_lock; // 自旋锁,保护f_ep_links和f_flags字段,避免并发修改冲突(不可在中断上下文持有)enum rw_hint f_write_hint; // 读写提示,用于优化I/O调度(如预测后续是读还是写操作,提前做好缓存准备)atomic_long_t f_count; // 文件对象的引用计数,用于管理对象生命周期(count>0时对象有效,减为0时销毁)unsigned int f_flags; // 文件打开时的标志位(如O_RDONLY只读、O_WRONLY只写、O_RDWR读写、O_NONBLOCK非阻塞等)fmode_t f_mode; // 文件的访问模式(如FMODE_READ可读、FMODE_WRITE可写、FMODE_CAN_READ实际可读能力等)struct mutex f_pos_lock; // 互斥锁,保护文件读写位置f_pos的并发访问(避免多进程同时读写导致位置错乱)loff_t f_pos; // 进程当前对该文件的读写位置偏移量(普通文件有效,管道、设备文件等可能忽略)struct fown_struct f_owner; // 记录文件的“所有者”信息(如进程ID、进程组ID),用于信号通知(如I/O就绪时向进程发送信号)const struct cred *f_cred; // 进程访问该文件的凭证(权限信息),用于权限校验struct file_ra_state f_ra; // 预读状态结构体,管理文件的预读策略(提前读取后续数据到缓存,提升读性能) u64 f_version; // 文件版本号,用于检测文件内容是否被修改(如多进程共享文件时的一致性检查)#ifdef CONFIG_SECURITYvoid *f_security; // 安全相关数据(如SELinux的安全上下文),仅在开启安全模块时存在#endif/* needed for tty driver, and maybe others */void *private_data; // 私有数据指针,供特定文件系统或驱动使用(如tty驱动存储终端相关信息)#ifdef CONFIG_EPOLL/* Used by fs/eventpoll.c to link all the hooks to this file */struct list_head f_ep_links; // 用于将文件链接到epoll的事件链表(I/O多路复用场景)struct list_head f_tfile_llink; // 临时文件链表的链接节点#endif/* #ifdef CONFIG_EPOLL */struct address_space *f_mapping; // 指向文件的地址空间结构体,管理文件数据的缓存和I/O映射(关联页缓存)errseq_t f_wb_err; // 写回错误序列,记录文件数据写回底层存储时的错误信息errseq_t f_sb_err; /* for syncfs */ // 超级块错误序列,用于syncfs系统调用(同步文件系统数据)时的错误跟踪} __randomize_layout // 编译选项,使结构体成员布局随机化,提升系统安全性(对抗缓冲区溢出攻击) __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */ // 结构体对齐属性,确保以4字节对齐,避免内存访问异常
接下来我们来看file_operations,可以看到其中提供了一组函数指针定义,如此便能使用不同的文件系统来进行读写。struct file_operations {struct module *owner; // 模块所有者指针,指向实现该操作集的内核模块;用于模块计数管理,防止模块在有操作执行时被动态卸载loff_t (*llseek) (struct file *, loff_t, int); // 文件指针定位操作,用于调整文件的当前读写位置(offset),第三个参数指定定位模式(如SEEK_SET绝对定位、SEEK_CUR相对定位)ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); // 传统同步读操作接口,从文件读取数据到用户空间缓冲区;返回读取的字节数,失败返回错误码ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); // 传统同步写操作接口,将用户空间缓冲区数据写入文件;返回写入的字节数,失败返回错误码ssize_t (*read_iter) (struct kiocb *, struct iov_iter *); // 迭代式读操作接口,支持分散/聚集I/O(如readv),适配大文件高效读写场景,通过kiocb管理I/O上下文ssize_t (*write_iter) (struct kiocb *, struct iov_iter *); // 迭代式写操作接口,对应read_iter的写场景,同样支持分散/聚集I/O,提升批量数据传输效率int (*iopoll)(struct kiocb *kiocb, bool spin); // I/O轮询接口,用于无阻塞I/O场景,查询I/O操作是否完成,spin参数表示是否允许自旋等待int (*iterate) (struct file *, struct dir_context *); // 目录文件迭代接口,用于遍历目录下的所有目录项(如ls命令底层依赖),通过dir_context传递遍历状态和回调int (*iterate_shared) (struct file *, struct dir_context *); // 共享模式下的目录迭代接口,支持多进程同时遍历同一目录,提升并发访问效率__poll_t (*poll) (struct file *, struct poll_table_struct *); // I/O多路复用核心接口,用于查询文件是否可读/可写/异常(如poll/select/epoll系统调用底层)long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long); // 无锁I/O控制接口,用于实现设备控制、文件属性设置等特殊操作,无需持有big kernel lock,性能更优long (*compat_ioctl) (struct file *, unsigned int, unsigned long); // 兼容模式I/O控制接口,用于32位用户态进程在64位内核中调用ioctl,处理参数位数适配int (*mmap) (struct file *, struct vm_area_struct *); // 内存映射接口,将文件数据映射到进程地址空间(如mmap系统调用),实现用户态直接访问文件数据,减少拷贝开销unsigned long mmap_supported_flags; // 支持的内存映射标志位,如MAP_SHARED、MAP_PRIVATE等,限制该文件允许的映射模式int (*open) (struct file *, struct inode *); // 文件打开接口,在进程打开文件时调用,完成inode与file对象的关联、文件专属资源初始化(如锁、缓冲区)int (*flush) (struct file *, fl_owner_t id); // 文件刷新接口,在进程关闭文件描述符时调用,确保未完成的I/O操作提交,或清理进程专属的文件状态int (*release) (struct inode *, struct file *); // 文件释放接口,在文件对象引用计数减为0时调用,释放文件占用的内核资源(如缓存、锁、私有数据)int (*fsync) (struct file *, loff_t, loff_t, int datasync); // 同步接口,将文件缓存中的数据刷写到底层存储设备;datasync参数表示是否仅同步数据(忽略元数据)int (*fasync) (int, struct file *, int); // 异步通知注册接口,用于注册/注销文件的异步I/O通知(如SIGIO信号),实现异步I/O事件驱动int (*lock) (struct file *, int, struct file_lock *); // 文件锁接口,用于实现文件级别的锁定(如flock),支持共享锁、排他锁,协调多进程对文件的并发访问ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int); // 页发送接口,用于将文件对应的内存页直接发送到网络(如socket发送文件数据),减少数据拷贝unsignedlong(*get_unmapped_area)(struct file *, unsignedlong, unsignedlong, unsignedlong, unsignedlong); // 获取未映射地址接口,为mmap操作分配进程地址空间中的空闲区域int (*check_flags)(int); // 标志位检查接口,验证文件打开时传入的flags(如O_NONBLOCK、O_APPEND)是否合法,避免不支持的标志位被使用int (*flock) (struct file *, int, struct file_lock *); // 兼容flock系统调用的文件锁接口,专门处理BSD风格的文件锁,与lock接口协同实现完整的文件锁机制ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int); // 管道写入拼接接口,将文件数据直接拼接到管道中,实现零拷贝数据传输ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int); // 管道读取拼接接口,将管道数据直接拼接到文件中,对应splice_write的反向操作int (*setlease)(struct file *, long, struct file_lock **, void **); // 租约设置接口,用于文件租约机制(如NFS共享文件场景),当文件被修改时通知持有租约的进程long (*fallocate)(struct file *file, int mode, loff_t offset, loff_t len); // 文件预分配接口,提前为文件分配指定长度的磁盘空间,避免后续写入时的空间分配开销,支持多种预分配模式void (*show_fdinfo)(struct seq_file *m, struct file *f); // 文件描述符信息展示接口,用于调试和监控,将文件的核心状态(如打开模式、读写位置)输出到seq_file缓冲区#ifndef CONFIG_MMUunsigned (*mmap_capabilities)(struct file *); // 无MMU架构下的内存映射能力接口,返回该文件支持的内存映射类型,仅在无内存管理单元的嵌入式系统中启用#endifssize_t (*copy_file_range)(struct file *, loff_t, struct file *, loff_t, size_t, unsigned int); // 文件间数据拷贝接口,直接在内核态完成两个文件的数据传输,无需用户态中转,提升拷贝效率loff_t (*remap_file_range)(struct file *file_in, loff_t pos_in, struct file *file_out, loff_t pos_out, loff_t len, unsigned int remap_flags); // 文件范围重映射接口,将一个文件的指定范围映射到另一个文件(如稀疏文件实现),支持多种重映射标志(如REMAP_FILE_SHARED)int (*fadvise)(struct file *, loff_t, loff_t, int); // 文件访问建议接口,用户态进程向内核提示文件的后续访问模式(如顺序读、随机读),内核根据建议优化缓存策略} __randomize_layout; // 结构体布局随机化编译选项,通过打乱成员顺序提升系统安全性,对抗基于结构体成员偏移的缓冲区溢出攻击
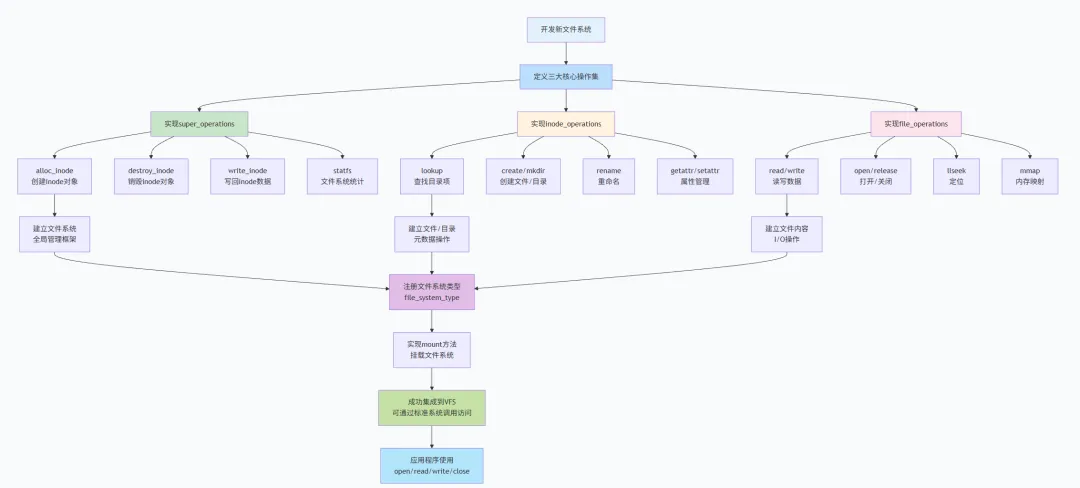
上面我们从流程角度来分析了其VFS承上启下的作用,接下来我们从如何支持一个新文件系统角度来看:1)如何获得被系统承认的身份,其通过struct file_system_type结构实现,用于记录文件系统的核心标识信息、挂载入口、超级块管理函数等,是文件系统被内核识别和挂载的基础。每个已注册到内核的文件系统(如ext4、XFS、NFS),都会对应一个struct file_system_type实例。struct file_system_type {const char *name; // 文件系统名称(如"ext4"、"xfs"、"nfs"),是文件系统的唯一标识,内核通过名称识别不同文件系统int fs_flags; // 文件系统特性标志位,用于标识文件系统的核心属性和行为约束#define FS_REQUIRES_DEV 1 // 标志该文件系统需要关联物理设备(如ext4、XFS,需挂载在磁盘设备上)#define FS_BINARY_MOUNTDATA 2 // 标志挂载参数为二进制格式,而非文本格式(如部分网络文件系统)#define FS_HAS_SUBTYPE 4 // 标志文件系统支持子类型(如fuse文件系统可对应不同的用户态子类型)#define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */// 允许用户命名空间的root用户挂载该文件系统,提升权限隔离性#define FS_DISALLOW_NOTIFY_PERM 16 /* Disable fanotify permission events */// 禁用fanotify权限通知事件,避免该文件系统触发相关权限监控回调#define FS_THP_SUPPORT 8192 /* Remove once all fs converted */// 标识支持透明巨页(THP),该宏为过渡性定义,待所有文件系统适配后移除#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */// 标志文件系统会在rename操作内部自行处理dentry的移动(d_move),无需VFS层额外处理int (*init_fs_context)(struct fs_context *); // 文件系统上下文初始化函数,挂载时调用,用于初始化挂载相关的上下文信息(如挂载参数、安全属性)const struct fs_parameter_spec *parameters; // 该文件系统支持的挂载参数规格列表,用于解析和校验用户传入的挂载参数(如ext4的data=ordered参数)struct dentry *(*mount) (struct file_system_type *, int, const char *, void *); // 挂载函数,是文件系统挂载的核心入口;参数分别为文件系统类型、挂载标志、挂载点路径、挂载数据;返回挂载点对应的dentryvoid (*kill_sb) (struct super_block *); // 超级块销毁函数,用于在文件系统卸载时,释放超级块占用的资源,清理相关状态struct module *owner; // 模块所有者,指向实现该文件系统的内核模块;防止模块在文件系统使用中被动态卸载struct file_system_type * next; // 链表节点,用于将所有已注册的file_system_type链接成全局链表(由内核维护,便于遍历查找)struct hlist_head fs_supers; // 哈希表头,链接该文件系统类型对应的所有超级块实例(一个文件系统可被多次挂载,每个挂载实例对应一个超级块)// 以下为锁相关的类键,用于内核锁调试和死锁检测,为不同场景的锁分配唯一的锁类别标识struct lock_class_key s_lock_key; // 超级块锁的类键struct lock_class_key s_umount_key; // 卸载锁的类键struct lock_class_key s_vfs_rename_key; // VFS层重命名操作锁的类键struct lock_class_key s_writers_key[SB_FREEZE_LEVELS]; // 文件系统冻结不同级别对应的写者锁类键struct lock_class_key i_lock_key; // inode锁的类键struct lock_class_key i_mutex_key; // inode互斥锁的类键struct lock_class_key i_mutex_dir_key; // 目录inode互斥锁的类键};
struct file_system_type的核心作用是“为文件系统提供统一的注册和挂载框架”:当用户执行mount命令挂载文件系统时,内核会根据文件系统名称(如“ext4”)查找到对应的struct file_system_type实例,通过其mount函数完成超级块的创建、文件系统的初始化,最终建立挂载点与文件系统的关联。而fs_supers字段则实现了对同一文件系统多挂载实例的管理——例如,将同一ext4分区分别挂载到“/mnt/a”和“/mnt/b”,会生成两个超级块实例,均链接到ext4对应的file_system_type的fs_supers哈希表中,便于内核统一管理。2)实现核心操作集,新增文件系统需实现至少super_operations(超级块操作集)、inode_operations(索引节点操作集)、file_operations(文件操作集)三大核心操作集,才能完成与VFS的适配。其中super_operations代表文件系统的“全局管理规则”,核心是创建根inode和根目录项;inode_operations和file_operations则表示文件操作的“具体执行规则”。 VFS的设计体现了标准化接口与实现自由的完美平衡。其通过抽象和实现分离实现了对上的统一接口和对下的高扩展性:
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
