在Linux系统中,进程内存空间的合理规划是程序高效运行的核心基石,而堆与栈作为用户空间中最关键的两大内存区域,其底层实现逻辑直接决定了程序的内存分配效率、安全性及资源利用率。栈凭借固定生长方向、内核自动管理的特性,成为函数调用、局部变量存储的首选,其高效的入栈出栈操作依赖于栈指针的精准控制,且栈空间的大小限制与溢出风险始终是程序稳定性的关键考量。
堆则承担着动态分配、按需扩展的职责,由程序员手动管理生命周期,其底层通过内存分配器与内核交互,平衡着分配速度、内存碎片与利用率之间的矛盾。深入剖析堆与栈的底层实现,不仅能厘清程序内存使用的底层逻辑,更能为内存泄漏排查、性能优化及高可靠程序开发提供核心支撑,解锁Linux内存管理的核心密码。
一、初识Linux 内存布局
1.1 内存布局初是什么?
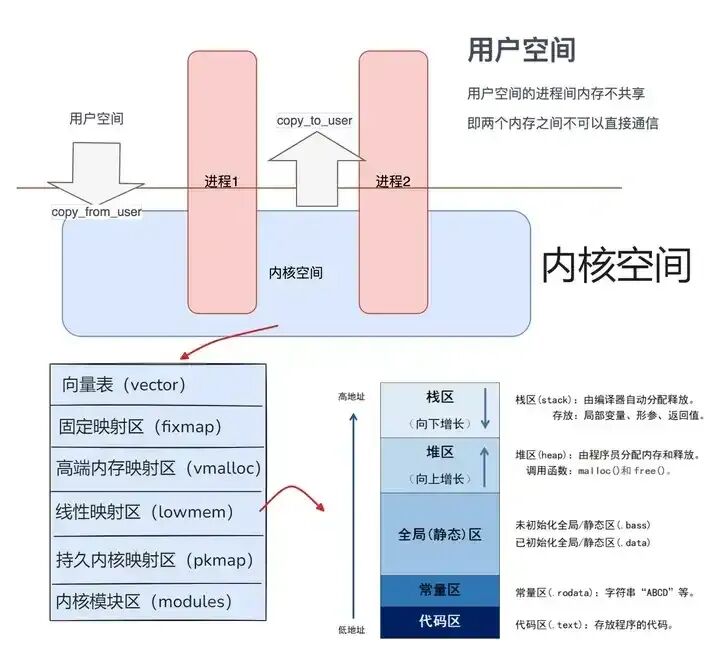
在 Linux 系统中,内存布局就像是精心规划的城市地图,每一个区域都有着独特的功能和使命,对于进程管理和资源分配起着举足轻重的作用 。当一个程序运行起来成为进程后,Linux 会为其分配一块虚拟内存空间,这块空间被有序地划分为多个不同的区域,每个区域各司其职,共同保障进程的正常运转。
在这张图中,整个内存空间被清晰地划分为用户空间和内核空间两大部分 。用户空间是用户应用程序运行的区域,每个用户进程都拥有独立的用户空间,它们之间相互隔离,这就好比每个居民都有自己独立的房间,互不干扰。而内核空间则是内核代码和数据存放的地方,是系统的核心地带,所有进程共享这部分空间,如同小区里的公共设施,大家都可以使用。
想象一下,内存布局就如同一个大型商场的布局规划。商场的不同楼层或区域分别用于不同的功能,比如底层可能是入口和公共区域(类似于内核空间,提供基础支持和服务),往上可能有服装区(类似代码段存放程序指令)、美食区(类似数据段存储初始化和未初始化的数据)、儿童游乐区(类似堆区用于动态分配内存,满足各种不同需求)以及办公区(类似栈区,处理函数调用和局部变量等临时性事务)。这种清晰的布局规划使得程序在运行时能够高效地访问和管理内存资源,就像顾客在商场里能够轻松找到自己需要的商品和服务一样。
1.2整体架构剖析
Linux 内存布局主要由内核空间和用户空间两大部分构成,而堆和栈则是用户空间中非常关键的组成部分 。
(1)内核空间:这是操作系统内核运行的区域,拥有最高的权限,负责管理系统的硬件资源、进程调度、内存管理等核心功能。它就像是城市的市政管理中心,掌控着整个城市的基础设施和运行秩序。用户进程一般不能直接访问内核空间,必须通过系统调用的方式来请求内核提供服务,这就好比市民需要通过特定的渠道(如政府办事窗口)来获取市政服务一样。
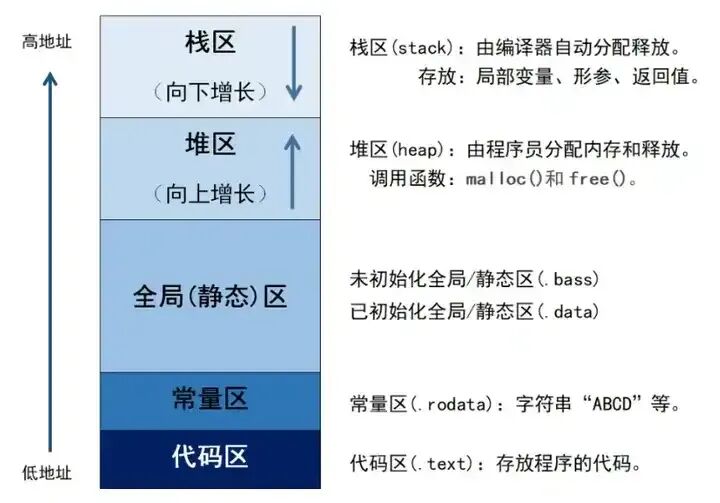
(2)用户空间:这是用户进程运行的区域,每个用户进程都有自己独立的用户空间。用户空间又进一步划分为多个不同的段,包括代码段、数据段、堆、栈等 。
- 代码段(Text Segment):存放着程序的可执行指令,是程序运行的核心逻辑所在。它具有只读属性,就像图书馆里的经典书籍,只能被阅读(执行),不能被随意修改,以确保程序指令的稳定性和正确性。
- 数据段(Data Segment):分为初始化数据段(Initialized Data Segment,也叫.data 段)和未初始化数据段(Uninitialized Data Segment,也叫.bss 段) 。初始化数据段存储着已经初始化的全局变量和静态变量,这些变量在程序运行前就已经被赋予了初始值;未初始化数据段则存放未初始化的全局变量和静态变量,系统会在程序启动时将它们初始化为 0 或空值。可以把数据段想象成一个仓库,初始化数据段是已经摆放好货物(初始值)的区域,而未初始化数据段是等待存放货物(运行时赋值)的区域。
- 堆(Heap):是用于动态内存分配的区域,当程序在运行时需要创建一些大小不确定或者生命周期不确定的对象时,就会从堆中申请内存。比如,你在编写一个图像处理程序,需要根据不同的图像大小动态分配内存来存储图像数据,这时就会用到堆。堆的大小可以在运行时动态扩展或收缩,就像一个可以根据需求自由调整大小的仓库。
- 栈(Stack):主要用于存储函数的局部变量、函数参数、返回值以及函数调用的上下文信息等。当一个函数被调用时,系统会在栈上为该函数创建一个栈帧(Stack Frame),用于存放上述相关信息。栈的生长方向是从高地址向低地址,具有后进先出(LIFO, Last In First Out)的特性,就像一摞盘子,最后放上去的盘子会最先被拿走。例如,当你调用一个函数时,函数的参数会被压入栈中,然后局部变量也在栈上分配空间,函数执行完毕后,这些数据会按照相反的顺序从栈中弹出,释放栈空间。
1.3 内存布局查看命令
在Linux系统中,我们可以使用一些命令来查看进程的内存布局,这就好比拥有了一把打开内存布局大门的钥匙 。
(1)pmap 命令:pmap 命令可以显示进程的内存映射关系,包括各个内存段的起始地址、结束地址、权限、映射文件等信息。使用方法很简单,只需在命令行中输入pmap -p <pid>,其中<pid>是要查看的进程 ID。例如,要查看进程 ID 为 1234 的内存布局,命令如下:
执行上述命令后,会得到类似如下的输出结果:
1234: /usr/bin/bash00400000 - 00409000 r-xp 00000000 08:01 13451234 /usr/bin/bash00608000 - 00609000 r--p 00008000 08:01 13451234 /usr/bin/bash00609000 - 0060a000 rw-p 00009000 08:01 13451234 /usr/bin/bash01697000 - 016b8000 rw-p 00000000 00:00 0 [heap]7ffc9103d000 - 7ffc9105e000 rw-p 00000000 00:00 0 [stack]7ffc910f2000 - 7ffc910f3000 r--p 00000000 00:00 0 [vvar]7ffc910f3000 - 7ffc910f5000 r-xp 00000000 00:00 0 [vdso]ffffffffff600000 - fffffffe601000 --xp 00000000 00:00 0 [vsyscall]
从输出结果中,我们可以清晰地看到代码段、数据段、堆、栈等各个内存段的地址范围和权限信息。例如,00400000 - 00409000 r-xp表示代码段,起始地址为00400000,结束地址为00409000,权限为可读可执行(r-xp);01697000 - 016b8000 rw-p表示堆段,起始地址为01697000,结束地址为016b8000,权限为可读可写(rw-p);7ffc9103d000 - 7ffc9105e000 rw-p表示栈段,起始地址为7ffc9103d000,结束地址为7ffc9105e000,权限为可读可写(rw-p) 。
(2)cat /proc//maps 命令:/proc是 Linux 系统中的一个虚拟文件系统,它提供了关于系统内核和进程的各种信息。/proc/<pid>/maps文件记录了指定进程的内存映射信息,与 pmap 命令的输出内容类似,但格式略有不同 。使用方法为cat /proc/<pid>/maps,例如查看进程 ID 为 1234 的内存布局:
输出结果示例如下:
00400000-00409000 r-xp 00000000 08:01 13451234 /usr/bin/bash00608000-00609000 r--p 00008000 08:01 13451234 /usr/bin/bash00609000-0060a000 rw-p 00009000 08:01 13451234 /usr/bin/bash01697000-016b8000 rw-p 00000000 00:00 0 [heap]7ffc9103d000-7ffc9105e000 rw-p 00000000 00:00 0 [stack]7ffc910f2000-7ffc910f3000 r--p 00000000 00:00 0 [vvar]7ffc910f3000-7ffc910f5000 r-xp 00000000 00:00 0 [vdso]ffffffffff600000-ffffffe601000 --xp 00000000 00:00 0 [vsyscall]
通过这两个命令,我们能够直观地了解进程在内存中的布局情况,为深入分析程序的运行机制和排查内存相关问题提供了有力的工具。
二、栈的深度剖析
2.1 栈的物理与逻辑画像
栈,作为 Linux 内存布局中不可或缺的一部分,有着独特的物理特性和逻辑结构,在程序运行中扮演着至关重要的角色 。从物理层面来看,栈是一块连续的内存区域,这使得它在数据存储和访问时具有高效性,就像一排紧密相连的小隔间,每个隔间都可以快速地被找到和使用 。它的生长方向十分特别,是从高地址向低地址延伸,这与我们日常生活中习惯的增长方向相反,就好比从高楼的顶层开始向下依次占用楼层空间 。
在逻辑上,栈就像是一个有序的容器,遵循后进先出(LIFO, Last In First Out)的原则,这意味着最后放入栈中的数据会最先被取出,就像一摞盘子,最后叠上去的盘子会最先被拿走 。栈的基本单位是栈帧(Stack Frame),每个栈帧都对应着一个函数调用 。当一个函数被调用时,系统会在栈顶为其创建一个栈帧,栈帧中包含了该函数的局部变量、函数参数、返回地址以及函数调用的上下文信息等 。这些信息就像是函数在执行过程中的 “行李”,被整齐地打包放在栈帧这个 “行李箱” 里 。随着函数调用的层层嵌套,栈帧也会在栈中层层堆叠,形成一个清晰的函数调用链 。例如,当函数 A 调用函数 B,函数 B 又调用函数 C 时,栈中会依次创建函数 A、函数 B 和函数 C 的栈帧,栈帧的顺序反映了函数调用的顺序和层次关系 。
2.2栈帧:函数调用的舞台
栈帧在函数调用过程中,犹如一个精心搭建的舞台,见证了函数从入场到退场的全过程 。以一个简单的 C 语言函数调用为例,假设有如下代码:
#include <stdio.h>intAdd(int x, int y){ int z = 0; z = x + y; return z;}intmain(){ int a = 10; int b = 20; int c = 0; c = Add(a, b); printf("%d\n", c); return 0;}
当main函数调用Add函数时,栈帧的创建过程如下 :
- 保存调用者栈帧信息:首先,main函数会将自己栈帧的栈底指针ebp压入栈中,这就像是在离开家(main函数栈帧)去旅行(调用Add函数)之前,留下一个标记,以便回来时能找到自己的家 。然后,将当前栈顶指针esp的值赋给ebp,这样就确定了Add函数栈帧的栈底位置 。此时,ebp就像是Add函数栈帧这个舞台的 “后台入口” 标记 。
- 为局部变量分配空间:接着,系统会通过减小esp的值,在栈中为Add函数的局部变量(如z)分配空间 。这就好比在舞台上为演员(局部变量)准备好表演的位置 。在这个例子中,为z分配了相应的内存空间 。
- 传递函数参数:main函数会将实参a和b的值压入栈中,这些参数就像是给演员(Add函数)的道具,从栈顶依次放入 。Add函数可以通过ebp和esp来访问这些参数 。
在Add函数执行过程中,它可以通过ebp和esp来访问栈帧中的局部变量和参数 。例如,计算z = x + y时,Add函数从栈帧中取出参数x和y的值,进行加法运算,并将结果存储在局部变量z的内存空间中 。
当Add函数执行完毕后,栈帧的销毁过程如下 :
- 恢复调用者栈帧信息:首先,将ebp的值赋回给esp,这就像是将舞台(Add函数栈帧)的空间清理掉,恢复到调用前的状态 。然后,从栈中弹出之前保存的main函数栈帧的栈底指针ebp,这样就回到了main函数栈帧的栈底位置 ,仿佛回到了自己的家 。
- 返回调用者:最后,从栈中弹出返回地址,将程序控制权交还给main函数中调用Add函数的下一条指令 。这就像是演员(Add函数)表演结束后,回到观众席(main函数)继续观看后续的表演 。
从汇编代码的角度来看,函数调用和栈帧操作的过程更加清晰 。以 x86 架构为例,函数调用时会使用call指令,该指令会将返回地址压入栈中,并跳转到被调用函数的入口 。在被调用函数内部,会使用push和pop指令来操作栈,以及使用mov指令来进行数据传输和赋值 。例如,保存ebp和设置新的ebp可以使用以下汇编代码:
push ebp ; 保存调用者的ebpmov ebp, esp ; 设置新的ebp为当前esp
为局部变量分配空间可以使用:
subesp, 0x10; 假设为局部变量分配16字节的空间
访问参数可以通过ebp的偏移来实现,例如:
mov eax, [ebp + 8] ; 假设第一个参数的偏移为8
函数返回时,会使用leave指令,该指令等价于:
mov esp, ebp ; 恢复esppop ebp ; 恢复调用者的ebp
然后使用 ret 指令返回,ret 指令会从栈中弹出返回地址,并跳转到该地址继续执行 。
2.3 栈的大小与动态调整
栈的大小并非是无限制的,它存在一定的限制,这就好比一个仓库的容量是有限的,不能无限制地存放货物 。在 Linux 系统中,栈大小的默认值通常为 8MB(不同系统可能略有差异),这个默认值是经过系统设计者精心考量设定的,能够满足大多数普通程序的需求 。例如,对于一些简单的命令行工具、小型的脚本程序等,8MB 的栈空间已经足够它们正常运行 。
然而,在某些特殊情况下,我们可能需要临时或永久地调整栈的大小 。比如,当你编写一个递归深度较大的程序时,默认的栈大小可能无法满足递归调用过程中不断创建栈帧的需求,这时就需要增大栈的大小 。又或者,当你开发一个对内存使用非常严格的嵌入式系统应用时,可能希望减小栈的大小,以节省宝贵的内存资源 。
临时调整栈大小可以使用ulimit命令,该命令就像是一个临时的仓库管理员,可以在不改变仓库永久容量的情况下,临时调整仓库的可用空间 。例如,要将当前会话的栈大小临时设置为 16MB,可以使用以下命令:
这里的16384是以 KB 为单位的栈大小,16MB 换算成 KB 就是 16 * 1024 = 16384KB 。这种临时调整只在当前终端会话中有效,当你关闭终端或者重新启动程序时,栈大小会恢复到默认值 。
如果需要永久调整栈大小,可以通过修改系统配置文件来实现 。具体来说,可以编辑/etc/security/limits.conf文件,在文件中添加或修改以下内容:
* soft stack 32768* hard stack 65536
这里的*表示对所有用户生效,soft表示软限制,hard表示硬限制 。soft限制可以被用户临时修改,但不能超过hard限制 。32768和65536同样是以 KB 为单位的栈大小,分别设置了软限制为 32MB,硬限制为 64MB 。修改完配置文件后,需要重新登录或者重启相关服务,新的栈大小设置才会生效 。
2.4 栈溢出:危险的信号
栈溢出是一种在程序运行过程中可能出现的严重错误,就像是仓库的货物堆放超过了仓库的承载能力,导致仓库出现问题 。栈溢出通常是由于程序中存在一些不当的操作,使得栈的使用超出了其预先分配的空间 。递归无终止是导致栈溢出的常见原因之一 。以一个简单的递归函数为例:
void recursive_function() { recursive_function();}
在这个函数中,没有设置任何终止条件,函数会不断地调用自身 。每次调用都会在栈中创建一个新的栈帧,随着递归的不断进行,栈帧会越来越多,最终耗尽栈空间,引发栈溢出 。这就好比一个人在一个没有出口的迷宫中不断地绕圈,最终被困在里面 。局部数组过大也可能引发栈溢出 。例如:
voidlarge_array_function() { int large_array[1000000];}
在这个函数中,定义了一个包含 100 万个元素的整型数组 large_array 。由于栈的空间有限,如此大的数组可能无法在栈中分配足够的空间,从而导致栈溢出 。这就像是试图在一个小仓库中存放大量的货物,结果仓库放不下,货物就溢出来了 。
栈溢出会带来严重的后果,它可能导致程序崩溃,就像一个突然倒塌的大厦,无法继续正常运行 。在程序崩溃时,系统通常会生成一个核心转储文件(core dump),这个文件记录了程序崩溃时的内存状态、寄存器值等信息,就像是事故现场的记录,帮助开发者分析事故原因 。栈溢出还可能引发安全漏洞,比如攻击者可以利用栈溢出漏洞,通过精心构造输入数据,覆盖栈中的返回地址等关键信息,从而让程序执行攻击者指定的恶意代码,就像黑客入侵了仓库,偷走了重要的物品并进行破坏 。
为了检测栈溢出,我们可以使用一些工具和技术 。例如,GCC 编译器提供了一些选项来帮助检测栈溢出,如-fstack-protector选项,它会在函数栈帧中插入一个 “金丝雀” 值(canary) 。在函数返回时,会检查这个 “金丝雀” 值是否被修改,如果被修改,则说明可能发生了栈溢出,程序会立即终止并报错 。这就像是在仓库门口设置了一个警报器,一旦有异常情况(货物溢出),警报器就会响起 。一些调试工具,如 GDB(GNU Debugger),也可以帮助我们在程序运行时跟踪栈的使用情况,通过设置断点、查看栈帧信息等方式,定位栈溢出的位置 。这就像是一个专业的调查人员,通过仔细检查事故现场的每一个细节,找出问题的根源 。
2.5 栈的安全防线
为了防止栈溢出带来的安全风险,Linux 系统采用了多种栈保护机制,这些机制就像是为栈这座城堡筑起了一道道坚固的防线 。栈金丝雀(Stack Canary)是一种非常有效的栈保护技术 。它的工作原理基于一个简单而巧妙的想法:在函数栈帧中,将返回地址之前的位置插入一个特殊的随机值,这个随机值就被称为 “金丝雀” 。之所以叫这个名字,是源于 17 世纪英国煤矿工人用金丝雀检测瓦斯的故事 。
在函数返回时,系统会检查这个 “金丝雀” 值是否被修改 。如果 “金丝雀” 值发生了变化,就说明栈可能发生了溢出,因为正常情况下,除了系统自身,其他代码不应该修改这个特殊的值 。这就好比在城堡的重要通道上设置了一个特殊的标记,只有城堡的主人(系统)知道这个标记的正确状态,一旦标记被破坏,就说明有异常情况(栈溢出)发生 。例如,GCC 编译器可以通过-fstack-protector系列选项来启用栈金丝雀保护 。当启用该保护后,函数在执行时会先将 “金丝雀” 值存入栈中,在函数返回前,会验证 “金丝雀” 值的完整性 。如果攻击者试图通过栈溢出覆盖返回地址,很可能会同时修改 “金丝雀” 值,从而导致函数返回时检测失败,程序终止,有效地阻止了攻击者的恶意行为 。
栈不可执行(Stack Non - Executable)也是一种重要的栈保护机制 。其基本原理是将栈所在的内存页标记为不可执行 。在正常情况下,栈主要用于存储数据(如局部变量、函数参数等),不应该包含可执行的代码 。当程序发生栈溢出,攻击者试图将恶意代码注入栈中并让程序执行这些代码时,由于栈内存页被标记为不可执行,CPU 会抛出异常,阻止恶意代码的执行 。这就像是在城堡的仓库(栈)周围设置了一道禁止进入的屏障,即使有敌人(恶意代码)试图进入仓库并发动攻击,也无法得逞 。在 Linux 系统中,大多数现代的编译器和操作系统默认都启用了栈不可执行保护 。例如,GCC 编译器默认会开启这个选项,如果需要关闭,可以通过-z execstack参数来实现,但这种做法会降低系统的安全性,一般不建议这样做 。
地址空间布局随机化(Address Space Layout Randomization,ASLR)是另一种强大的栈保护机制 。它的作用是在程序运行时,随机化进程的内存布局,包括栈的起始地址 。这样一来,攻击者很难准确地预测栈的地址,从而大大增加了利用栈溢出进行攻击的难度 。这就好比每天都随机改变城堡的布局和各个房间(内存区域)的位置,敌人(攻击者)即使知道城堡的大致结构,但每次来攻击时都发现布局变了,很难找到关键的位置(如栈地址)进行攻击 。
在 Linux 系统中,可以通过修改/proc/sys/kernel/randomize_va_space文件来控制 ASLR 的级别 。0表示关闭 ASLR,1表示将mmap的基址、栈和vdso页面随机化,2表示在1的基础上增加堆的随机化 。默认情况下,大多数系统会将randomize_va_space设置为2,以提供较高的安全性 。通过这几种栈保护机制的协同作用,Linux 系统有效地降低了栈溢出带来的安全风险,为程序的稳定运行提供了可靠的保障 。
三、堆的深度剖析
3.1 堆的内存模型与分配器原理
堆,在 Linux 内存布局中扮演着动态内存分配魔法师的角色,为程序提供了灵活的内存使用方式 。从内存模型来看,堆是一块从低地址向高地址增长的不连续内存区域,这与栈的连续内存和从高地址向低地址增长的特性形成鲜明对比 。想象一下,栈就像是一排整齐的公寓楼,每个房间紧密相连,从高楼顶层开始依次分配;而堆则像是一个可以自由扩建的大院子,房子(内存块)可以根据需要在院子里灵活建造,并不一定紧密相连,且随着需求的增加,院子会不断向更高的地址方向扩展 。
堆内存的分配与释放是由堆分配器(Heap Allocator)来负责的,它就像是这个大院子的管理员,管理着内存的分配和回收 。当程序需要动态分配内存时,比如通过malloc函数申请内存,堆分配器会在堆中寻找合适的内存块 。如果找到大小合适的空闲内存块,就将其分配给程序;如果没有找到,堆分配器可能会向操作系统申请更多的内存,然后再进行分配 。当程序使用完内存,通过free函数释放内存时,堆分配器会将释放的内存块标记为空闲,并尝试与相邻的空闲内存块合并,以减少内存碎片,提高内存利用率 。这就好比院子里的房子(内存块)不用了,管理员会把它标记为空闲,并看看能不能和旁边的空闲房子合并成一个更大的空间,以便下次有更大的需求时可以直接使用 。
3.2 主流堆分配器大比拼
在 Linux 系统中,存在多种主流的堆分配器,它们各有千秋,适用于不同的场景 。
- ptmalloc:这是 Glibc 中默认的堆分配器,就像是一个经验丰富的老管家,被广泛应用于各种 Linux 程序中 。它采用了一种称为 “伙伴系统”(Buddy System)的算法来管理内存块,这种算法能够有效地减少内存碎片 。它还使用了双向链表来组织空闲内存块,使得内存的分配和释放操作相对高效 。对于一些一般性的应用程序,如普通的命令行工具、小型服务器程序等,ptmalloc 能够很好地满足需求,因为它在通用性和性能之间取得了较好的平衡 。
- tcmalloc(Thread - Caching Malloc):由 Google 开发,是一个线程缓存分配器,如同一个高效的智能管家 。它为每个线程维护了一个独立的内存缓存,减少了线程之间对内存分配的竞争,从而提高了多线程程序的性能 。在多线程环境下,当多个线程同时请求内存分配时,tcmalloc 可以让每个线程快速地从自己的缓存中获取内存,而不需要频繁地去竞争全局的内存资源 。对于像大型服务器程序、多线程的数据库应用等需要处理大量并发请求的场景,tcmalloc 能够显著提升性能 。
- jemalloc:是 Facebook 开发的一个高性能的通用内存分配器,可看作是一个创新的管家 。它采用了更细粒度的内存管理策略,将内存按照大小进行分类,不同大小的内存块使用不同的分配策略 。这种方式能够更有效地减少内存碎片,提高内存利用率 。在一些对内存利用率要求极高的应用场景,如大规模数据处理、游戏开发等,jemalloc 能够发挥出其优势,为程序提供更高效的内存管理服务 。
3.3 ptmalloc 分配器深度探秘
ptmalloc 分配器作为 Glibc 中的默认分配器,其内部结构和工作流程蕴含着许多精妙之处 。在 ptmalloc 中,内存被划分为一个个的内存块(Chunk),每个内存块都有自己的结构 。以 64 位系统为例,一个最小的内存块大小为 32 字节,其中包含了元数据和用户数据部分 。元数据中记录了内存块的大小、是否已被分配等重要信息 。比如,内存块的 size 字段不仅记录了块的大小,还通过最低几位来表示块的状态,如是否是最后一个块、是否被分配等 。这就好比每个房子(内存块)都有一个详细的门牌信息,记录了房子的大小、是否有人居住(已分配)等情况 。
当程序调用malloc函数请求分配内存时,ptmalloc 会按照一定的流程进行处理 。它首先会检查请求的内存大小,如果请求的内存较小,会优先在快速链表(Fast Bins)中查找合适的内存块 。快速链表中存放着最近释放的小内存块,由于其采用了单向链表结构,且不进行合并操作,所以能够快速地分配内存 。如果快速链表中没有合适的内存块,ptmalloc 会继续在小内存链表(Small Bins)和大内存链表(Large Bins)中查找 。小内存链表中存放着固定大小的内存块,大内存链表则存放着大小范围不同的内存块 。如果在这些链表中都找不到合适的内存块,ptmalloc 会尝试从堆顶块(Top Chunk)中分割出一块满足需求的内存 。如果堆顶块也无法满足需求,ptmalloc 会向操作系统申请更多的内存 。
这就像是老管家在管理院子里的房子时,当有人来租房子(申请内存),他会先看看最近空出来的小房子(快速链表)有没有合适的,如果没有,再去看看其他固定大小的房子(小内存链表)和大房子(大内存链表),要是都没有合适的,就从院子里的空地(堆顶块)上新建一个房子,要是空地也不够,就去和邻居(操作系统)商量借点地来建房子 。
当程序调用free函数释放内存时,ptmalloc 会将释放的内存块标记为空闲,并尝试与相邻的空闲内存块合并 。如果释放的内存块与相邻的空闲内存块相邻且都为空闲状态,ptmalloc 会将它们合并成一个更大的空闲内存块,然后将其插入到合适的链表中 。这就好比房子空出来(释放内存)后,管家会看看旁边的房子是不是也空着,如果是,就把它们合并成一个更大的房子,再重新安排这个大房子的出租信息(插入链表) 。
3.4 堆内存管理的陷阱
在堆内存管理的过程中,存在着许多陷阱,稍有不慎就会导致程序出现严重的问题 。
【1】内存泄漏(Memory Leak):这是堆内存管理中最常见的问题之一,就像是在大院子里不断地建造房子(分配内存),但却忘记拆除不用的房子(释放内存),随着时间的推移,院子里可用的空地(内存)越来越少 。例如,在 C 语言中,如果使用malloc分配了内存,但没有使用free释放,就会导致内存泄漏 。如下代码:
#include <stdio.h>#include <stdlib.h>voidmemory_leak_example() { int *ptr = (int *)malloc(sizeof(int)); // 这里没有调用free(ptr),导致内存泄漏}intmain() { memory_leak_example(); return 0;}
长期的内存泄漏会导致程序占用的内存不断增加,最终可能耗尽系统的内存资源,导致系统性能下降甚至崩溃 。
【2】悬空指针(Dangling Pointer):当一个指针指向的内存被释放后,该指针就成为了悬空指针,就像是房子被拆除了(内存释放),但钥匙(指针)还在,拿着这把钥匙却无法打开任何房子 。例如:
#include <stdio.h>#include <stdlib.h>voiddangling_pointer_example(){ int *ptr = (int *)malloc(sizeof(int)); free(ptr); // 此时ptr成为悬空指针,但没有被置为NULL // 后续如果使用ptr,会导致未定义行为 if (ptr != NULL) { *ptr = 10; // 这是错误的操作,会导致未定义行为 }}intmain(){ dangling_pointer_example(); return 0;}
使用悬空指针会导致程序出现未定义行为,可能引发程序崩溃或其他难以调试的问题 。
【3】内存损坏(Memory Corruption):通常是由于程序对内存的非法访问导致的,比如向已分配的内存块之外写入数据,就像是在自己的房子里随意扩建,占用了邻居的土地(其他内存区域) 。例如:
#include <stdio.h>#include <stdlib.h>voidmemory_corruption_example(){ int *ptr = (int *)malloc(5 * sizeof(int)); for (int i = 0; i < 6; i++) { ptr[i] = i; // 这里访问了ptr[5],超出了分配的内存范围,导致内存损坏 } free(ptr);}intmain(){ memory_corruption_example(); return 0;}
内存损坏会破坏内存中的数据结构,导致程序出现各种奇怪的行为,而且这类问题往往很难调试,因为错误的表现可能与实际的错误位置相差甚远 。
【4】内存碎片化(Memory Fragmentation):分为内部碎片和外部碎片 。内部碎片是指分配的内存块大于实际需求,导致部分内存浪费,就像是租了一个大房子,但只用了其中一部分空间,其他部分闲置 。外部碎片是指空闲内存块分散在堆中,无法满足较大的内存分配请求,就像是院子里有很多小块的空地,但都无法单独用来建造一个大房子 。例如,频繁地分配和释放大小不同的内存块,就容易导致内存碎片化 。如下代码模拟了这种情况:
#include <stdio.h>#include <stdlib.h>voidfragmentation_example(){ int *ptr1 = (int *)malloc(10 * sizeof(int)); int *ptr2 = (int *)malloc(20 * sizeof(int)); free(ptr1); int *ptr3 = (int *)malloc(15 * sizeof(int)); free(ptr2); int *ptr4 = (int *)malloc(25 * sizeof(int)); // 此时可能会出现内存碎片化,导致后续较大的内存分配请求无法满足}intmain(){ fragmentation_example(); return 0;}
内存碎片化会降低内存的利用率,影响程序的性能,严重时可能导致程序无法分配到足够的内存 。为了避免这些陷阱,我们在编写代码时需要遵循良好的编程规范 。比如,在分配内存后,一定要记得在合适的时候释放内存;在释放内存后,将指针置为NULL,以避免悬空指针问题;在访问内存时,要确保访问的范围在合法的内存区域内;尽量避免频繁地分配和释放大小差异较大的内存块,以减少内存碎片化的发生 。
3.5 堆问题诊断与调试
当程序出现堆相关的问题时,我们可以借助一些强大的工具来进行诊断和调试 。
- Valgrind:这是一个功能非常强大的内存调试工具,就像是一个专业的侦探,能够帮助我们找出各种内存问题 。它包含了多个工具,其中memcheck工具是最常用的,用于检测内存泄漏、非法内存访问等问题 。使用 Valgrind 非常简单,只需在命令行中运行valgrind --leak-check=full./your_program,其中--leak-check=full表示全面检查内存泄漏,./your_program是你要调试的程序 。例如,对于前面内存泄漏的示例代码,使用 Valgrind 运行后,会输出详细的内存泄漏信息,包括泄漏的内存块大小、分配的位置等,帮助我们定位问题所在 。
- AddressSanitizer(ASan):是一个快速的内存错误检测工具,与编译器紧密集成,可看作是一个高效的报警器 。在编译程序时,只需添加-fsanitize=address选项,如gcc -fsanitize=address -o your_program your_program.c,编译后的程序在运行时就会自动检测内存问题 。当发现内存错误时,ASan 会立即输出详细的错误信息,包括错误发生的位置、类型等 。它能够检测到内存泄漏、悬空指针、内存越界等多种问题,而且对程序的性能影响相对较小,非常适合在开发过程中使用 。
- gdb(GNU Debugger):虽然 gdb 主要是一个通用的调试工具,但它也可以用于调试堆相关的问题 。通过在 gdb 中设置断点、查看内存内容、跟踪函数调用等操作,我们可以逐步排查堆问题 。例如,当怀疑程序存在内存损坏问题时,可以在 gdb 中使用x命令查看内存的内容,通过对比正常和异常情况下的内存数据,找出问题的根源 。在 gdb 中还可以使用call命令调用函数,比如调用free函数来释放内存,观察程序的行为是否正常 。
除了这些工具,我们还可以在代码中添加一些调试信息,如打印内存地址、分配和释放的操作信息等,帮助我们更好地理解程序的内存使用情况 。通过综合运用这些工具和方法,我们能够更有效地诊断和解决堆内存管理中出现的各种问题,确保程序的稳定性和性能 。
四、堆与栈的核心差异对比
4.1 核心差异对比
栈与堆,虽然都身处 Linux 内存布局这个大家庭中,但它们在各个方面都有着显著的差异,就像是一对性格迥异的兄弟 。
- 管理方式大不同:栈的管理就像是一位高效的自动管理员,由操作系统自动分配和释放 。当一个函数被调用时,系统会自动在栈上为其创建栈帧,分配所需的内存空间,函数执行结束后,栈帧又会被自动销毁,释放内存 。这就好比一个自动化的仓库,货物(数据)的存放和取出都由系统自动完成,无需人工干预 。而堆则像是一个需要人工管理的仓库,其内存的分配和释放由程序员手动控制 。程序员需要使用malloc、free(在 C 语言中)或new、delete(在 C++ 语言中)等函数来申请和释放内存 。如果程序员忘记释放不再使用的堆内存,就会导致内存泄漏,就像仓库里的货物不用了却没有搬走,一直占用空间 。
- 空间大小有差异:栈的空间相对较小,就像是一个小型的精品仓库 。在 Linux 系统中,栈的默认大小一般为 8MB 左右(不同系统可能略有不同) ,这个大小对于一些简单的函数调用和局部变量存储来说是足够的,但如果遇到递归深度较大或者局部数组非常大的情况,就可能会出现栈溢出的问题 。而堆的空间则相对较大,理论上,进程可申请的堆大小受限于系统的虚拟内存大小,就像是一个大型的综合仓库,可以根据程序的需要动态地扩展和收缩 ,能够满足程序对大量内存的需求,比如在处理大型数据结构(如大型链表、树等)时 。
- 生长方向相反:栈的生长方向是从高地址向低地址,就像是从高楼的顶层开始向下建造楼层 。当有新的数据入栈时,栈指针会向低地址方向移动,分配新的栈空间 。而堆的生长方向则是从低地址向高地址,如同从地面开始向上建造高楼 。当程序申请新的堆内存时,堆会向高地址方向扩展 。
- 分配方式各有特点:栈有两种分配方式,静态分配和动态分配 。静态分配由操作系统在编译时就确定好,比如函数中的局部变量,只要函数被调用,这些局部变量就会在栈上被分配固定的空间 ,就像是仓库里固定位置的货架,每次使用时都在那里 。动态分配则是通过alloca函数来实现,但这种动态分配也是由操作系统自动管理释放的 。而堆只有动态分配这一种方式,完全由程序员根据程序运行时的需求来决定何时申请和释放内存 ,灵活性更高,但也更容易出错 ,就像是一个可以随时根据需求搭建和拆除货架的仓库 。
- 分配效率不一样:栈的分配效率非常高,这得益于操作系统在硬件层级对栈的支持 。系统会分配专门的寄存器来存放栈的地址,压栈和出栈操作都有专门的指令执行,这使得栈的操作就像在一条畅通无阻的高速公路上行驶,快速且高效 。而堆的分配则相对较慢,因为它是由 C/C++ 提供的库函数或运算符来完成申请与管理的,实现机制较为复杂 。在分配内存时,堆分配器需要在堆中寻找合适的空闲内存块,还可能需要处理内存碎片等问题,这就好比在一个堆满了各种杂物的仓库里寻找一件特定的物品,过程繁琐且耗时 。
- 存放内容各有侧重:栈主要存放函数返回地址、相关参数、局部变量和寄存器内容等 。在函数调用过程中,这些信息会按照一定的顺序依次入栈,就像是按照清单依次将货物放入仓库 。例如,当主函数调用另一个函数时,首先入栈的是主函数下一条语句的地址,然后是当前栈帧的底部地址,接着是被调函数的实参等,最后是被调函数的局部变量 。函数执行结束后,这些数据又会按照相反的顺序出栈 。而堆则主要用于存放动态分配的数据,比如程序员通过malloc或new分配的大型对象、数组等 ,这些数据的生命周期由程序员手动控制,就像是仓库里那些需要特殊管理的贵重货物 。
4.2 栈与堆的交互
在实际的程序运行中,栈和堆并非孤立存在,而是相互协作,共同完成程序的各项任务,就像是工厂里的两个不同部门,虽然职责不同,但紧密配合,确保生产线的顺利运行 。以一个简单的 C 语言程序为例,假设我们有一个函数,它需要动态分配内存来存储一组数据,然后对这些数据进行处理 。代码如下:
#include <stdio.h>#include <stdlib.h>voidprocess_data(){ int *data = (int *)malloc(5 * sizeof(int)); // 在堆上分配内存 if (data == NULL) { printf("Memory allocation failed\n"); return; } // 在栈上的局部变量 int i; for (i = 0; i < 5; i++) { data[i] = i; // 对堆上的数据进行初始化 } // 处理堆上的数据 for (i = 0; i < 5; i++) { data[i] = data[i] * data[i]; } // 打印处理后的数据 for (i = 0; i < 5; i++) { printf("%d ", data[i]); } printf("\n"); free(data); // 释放堆上的内存}intmain(){ process_data(); return 0;}
在这个程序中,process_data函数首先在堆上通过malloc函数分配了一块内存,用于存储一个包含 5 个整数的数组 。这里堆就像是一个提供原材料(内存)的仓库,为程序提供了动态分配内存的功能 。然后,在函数内部,使用了栈上的局部变量i来进行循环操作 。栈就像是一个临时的工作区,为函数提供了便捷的局部变量存储和操作空间 。在循环中,通过局部变量i对堆上分配的数组进行初始化和处理 。最后,当函数执行完毕,栈上的局部变量i会随着函数的结束而自动销毁,而堆上分配的内存则需要程序员手动调用free函数来释放,以避免内存泄漏 。
从这个例子可以看出,栈和堆在程序中相互配合 。栈用于存储函数的局部变量、参数等临时性的数据,以及控制函数的调用和返回,它的高效性使得函数能够快速地执行 。而堆则用于存储那些生命周期较长、大小不确定的动态数据,为程序提供了更大的灵活性 。在许多复杂的程序中,比如大型的数据库管理系统、图形渲染引擎等,栈和堆的协作更加频繁和紧密 。栈负责管理函数调用的上下文和局部数据,而堆则用于存储大量的动态数据,如数据库中的表数据、图形图像的像素数据等 。通过栈和堆的协同工作,这些复杂的程序能够高效、稳定地运行 。
五、Linux内存优化与案例分析
5.1 内存优化技巧
在 Linux 内存管理的实践中,优化内存使用是提升程序性能和资源利用率的关键环节,就像是精心规划一个仓库的布局,以充分利用每一寸空间 。减少内存分配次数是一个重要的优化策略 。在程序中,频繁的内存分配和释放操作会带来额外的开销,就像频繁地搬运货物进出仓库,不仅耗费时间,还可能导致仓库混乱 。例如,在一个循环中多次分配小内存块,每次分配都需要堆分配器进行一系列的查找和管理操作 。我们可以通过提前分配足够的内存,然后在需要时重复使用这块内存,来减少分配次数 。比如,在处理大量数据的循环中,如果每次循环都为一个临时数组分配内存,我们可以在循环开始前一次性分配一个足够大的数组,然后在每次循环中复用这个数组,这样可以显著提高程序的运行效率 。
及时释放不再使用的内存同样至关重要 。如果程序中存在大量已经不再使用但未释放的内存,就会造成内存浪费,就像仓库里堆积了很多不再使用的货物,占用了宝贵的空间 。以 C 语言为例,使用malloc分配内存后,一定要在合适的时机使用free函数释放内存 。在 C++ 中,使用new分配内存后,要对应地使用delete释放 。对于复杂的数据结构,比如链表,如果删除节点时不释放节点所占用的内存,随着时间的推移,内存会被大量占用,导致程序性能下降甚至崩溃 。
选择合适的内存分配器也能对内存使用效率产生重大影响 。如前所述,不同的内存分配器在性能和内存管理策略上存在差异 。对于多线程程序,tcmalloc 能够减少线程之间的内存分配竞争,提高整体性能;而对于对内存利用率要求极高的场景,jemalloc 则能更好地减少内存碎片 。我们可以根据程序的特点和需求,选择最适合的内存分配器 。比如,在开发一个多线程的服务器程序时,将默认的 ptmalloc 更换为 tcmalloc,可能会带来显著的性能提升 。
利用内存池技术也是优化内存使用的有效手段 。内存池是一种预先分配一大块内存,然后在程序内部管理这些内存块的分配和释放的技术 。它适用于需要频繁分配和释放相同大小内存块的场景 。例如,在一个网络服务器中,每次接收到一个网络数据包时都需要分配内存来存储数据包内容 。如果使用内存池,我们可以预先分配一系列固定大小的内存块,当有数据包到来时,直接从内存池中获取一个内存块,而不需要每次都向堆分配器申请内存 。这样不仅减少了内存分配的开销,还能降低内存碎片化的风险 。
下面是一个简单的内存池实现示例:
#include <stdio.h>#include <stdlib.h>#include <string.h>#define BLOCK_SIZE 1024 // 每个内存块的大小#define POOL_SIZE 100 // 内存池中的内存块数量// 内存块结构体typedef struct MemoryBlock { int in_use; // 是否被使用 struct MemoryBlock* next;} MemoryBlock;// 内存池结构体typedef struct MemoryPool { MemoryBlock* blocks[POOL_SIZE]; MemoryBlock* free_list;} MemoryPool;// 初始化内存池voidinit_memory_pool(MemoryPool* pool){ pool->free_list = NULL; for (int i = 0; i < POOL_SIZE; i++) { pool->blocks[i] = (MemoryBlock*)malloc(BLOCK_SIZE); if (pool->blocks[i] == NULL) { printf("Memory allocation failed\n"); exit(1); } pool->blocks[i]->in_use = 0; pool->blocks[i]->next = pool->free_list; pool->free_list = pool->blocks[i]; }}// 从内存池分配内存void* allocate_from_pool(MemoryPool* pool){ if (pool->free_list == NULL) { printf("Memory pool is empty\n"); return NULL; } MemoryBlock* block = pool->free_list; pool->free_list = block->next; block->in_use = 1; return block;}// 释放内存到内存池voidfree_to_pool(MemoryPool* pool, void* ptr){ MemoryBlock* block = (MemoryBlock*)ptr; if (block == NULL || block->in_use == 0) { printf("Invalid memory block to free\n"); return; } block->in_use = 0; block->next = pool->free_list; pool->free_list = block;}intmain(){ MemoryPool pool; init_memory_pool(&pool); void* ptr1 = allocate_from_pool(&pool); void* ptr2 = allocate_from_pool(&pool); // 使用内存 memset(ptr1, 0, BLOCK_SIZE); memset(ptr2, 0, BLOCK_SIZE); free_to_pool(&pool, ptr1); free_to_pool(&pool, ptr2); // 释放内存池中的所有内存 for (int i = 0; i < POOL_SIZE; i++) { free(pool.blocks[i]); } return 0;}
5.2栈溢出导致程序崩溃
在 Linux 应用开发中,栈溢出是一个常见且棘手的问题,它就像一颗隐藏在程序中的定时炸弹,随时可能导致程序崩溃,给开发者带来巨大的困扰 。下面我们通过一个具体的代码示例来深入了解栈溢出的原理和影响 。
#include <stdio.h>voidrecursive_function(int n){ char large_array[1024]; // 每次递归调用都会在栈上分配1024字节的空间 printf("Level %d, address of array: %p\n", n, &large_array); recursive_function(n + 1); // 递归调用,没有终止条件}intmain(){ recursive_function(1); return 0;}
在这段代码中,recursive_function函数内部定义了一个大小为 1024 字节的字符数组large_array 。每次递归调用时,都会在栈上为这个数组分配空间 。由于函数没有设置正确的终止条件,递归会不断进行下去 。随着递归深度的增加,栈上需要分配的空间也越来越多 。当栈空间被耗尽时,就会发生栈溢出 。这就好比一个容量有限的杯子,不断地往里倒水,当水超过杯子的容量时,就会溢出来 。
栈溢出会导致程序出现严重的错误,甚至直接崩溃 。这是因为栈溢出会破坏栈的正常结构,导致函数的返回地址被覆盖,程序无法正确返回 。就像一条道路被破坏,车辆无法按照原定路线行驶一样 。而且,栈溢出还可能引发未定义行为,导致程序出现各种奇怪的错误,如数据损坏、程序逻辑混乱等 。这些错误往往难以调试和排查,给开发人员带来极大的挑战 。
为了解决栈溢出问题,我们可以采取多种有效的方法 。一种方法是增加栈的大小,通过调整系统参数或编译器选项,可以扩大栈的可用空间 。这就好比把杯子换大,能够容纳更多的水 。在 Linux 系统中,可以使用ulimit -s命令来调整栈的大小 。例如,ulimit -s 16384可以将栈的大小设置为 16384KB 。另一种方法是优化递归算法,确保递归调用有正确的终止条件 。这就像在道路上设置明确的指示牌,引导车辆正确行驶 。在上述代码中,我们可以添加一个终止条件,当n达到一定值时,停止递归调用 。例如:
#include <stdio.h>voidrecursive_function(int n){ if (n > 100) { // 设置终止条件,当n大于100时停止递归 return; } char large_array[1024]; printf("Level %d, address of array: %p\n", n, &large_array); recursive_function(n + 1);}intmain(){ recursive_function(1); return 0;}
通过这种方式,我们可以有效地避免栈溢出的发生,确保程序的稳定性和可靠性 。在实际的开发中,我们应该根据具体的情况,选择合适的方法来解决栈溢出问题,确保程序能够稳定、高效地运行 。
5.3堆内存泄漏问题
堆内存泄漏是 Linux 应用开发中另一个常见且难以排查的问题,它就像一个无声的内存窃贼,悄悄地吞噬着系统的内存资源,导致程序性能下降,甚至崩溃 。下面我们通过一个具体的代码示例来深入剖析堆内存泄漏的原因和影响 。
#include <stdio.h>#include <stdlib.h>voidmemory_leak_example() { while (1) { int *ptr = (int *)malloc(1024 * sizeof(int)); // 每次循环都分配1024个整数大小的堆内存 // 这里没有释放ptr指向的内存,导致内存泄漏 }}intmain() { memory_leak_example(); return 0;}
在这段代码中,memory_leak_example函数内部使用malloc函数在堆上分配了 1024 个整数大小的内存空间,并将返回的指针存储在ptr变量中 。然而,在每次循环中,都没有调用free函数来释放这块内存 。随着循环的不断进行,越来越多的内存被分配,但始终没有被释放,这就导致了严重的堆内存泄漏 。这就好比一个人不断地购买新的物品,但从不清理使用过的物品,最终导致房间被堆满,无法正常生活 。
堆内存泄漏会对程序的性能产生严重的负面影响 。随着内存泄漏的不断积累,系统的可用内存会逐渐减少,导致程序运行速度变慢 。当可用内存耗尽时,程序可能会因为无法分配到足够的内存而崩溃 。这就像汽车的油箱没有油了,无法继续行驶一样 。而且,内存泄漏还可能导致系统出现其他问题,如内存碎片增多,进一步降低内存的利用率 。
为了检测和修复堆内存泄漏问题,我们可以借助一些强大的工具,其中 Valgrind 是一个非常常用且功能强大的内存调试工具 。Valgrind 能够动态地检测程序中的内存错误,包括内存泄漏、越界访问等 。使用 Valgrind 检测内存泄漏非常简单,首先需要使用-g参数编译源程序,以便生成调试信息 。然后,在运行程序的命令行前加上valgrind --leak-check=yes 。例如:
gcc -g -o memory_leak memory_leak.cvalgrind --leak-check=yes./memory_leak
运行上述命令后,Valgrind 会详细地报告程序中的内存泄漏情况,包括泄漏的内存大小、分配内存的函数以及代码行号等信息 。通过这些信息,我们可以快速定位到内存泄漏的源头 。例如,Valgrind 的报告可能会显示:
==1234== 1024 bytes in 1 blocks are definitely lost in loss record 1 of 1==1234== at 0x4C2DB8F: malloc (vg_replace_malloc.c:309)==1234== by 0x40061F: memory_leak_example (memory_leak.c:5)==1234== by 0x400651: main (memory_leak.c:10)
从报告中可以看出,在memory_leak.c文件的第 5 行,通过malloc函数分配的 1024 字节内存发生了泄漏 。一旦定位到内存泄漏的位置,修复问题就相对容易了 。在上述代码中,我们只需要在每次分配内存后,及时调用free函数来释放内存即可 。修改后的代码如下:
#include <stdio.h>#include <stdlib.h>voidmemory_leak_example(){ while (1) { int *ptr = (int *)malloc(1024 * sizeof(int)); // 处理完内存后,及时释放 free(ptr); }}intmain(){ memory_leak_example(); return 0;}
通过这种方式,我们可以有效地避免堆内存泄漏的发生,确保程序能够高效、稳定地运行 。在实际的开发中,养成良好的内存管理习惯,及时释放不再使用的内存,是防止内存泄漏的关键 。同时,合理使用内存检测工具,能够帮助我们快速发现和解决内存问题,提高程序的质量和可靠性 。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
