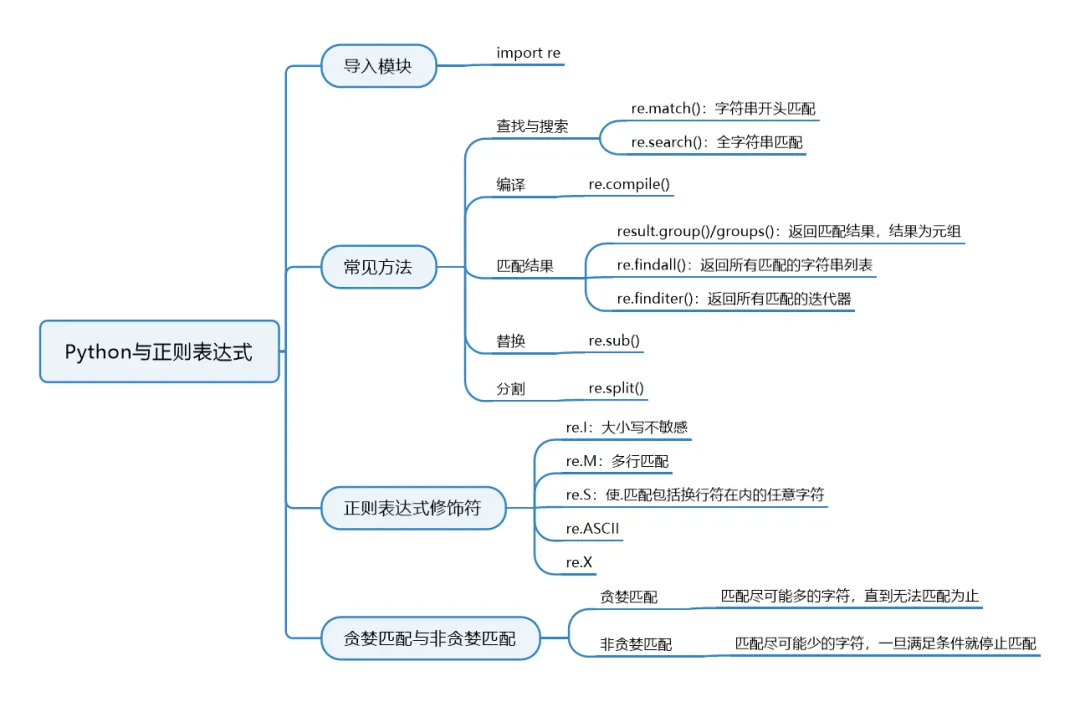
每天一个数据小知识,今天的主题是【Python与正则表达式】在 Python 中使用正则表达式主要通过re模块来实现re.match(pattern, string, flags=0)
- flags:标志位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等
result = re.match(r'hello', 'hello world')if result: print("匹配成功:", result.group()) # hello
匹配成功可以用group()或者groups()获取匹配表达式,方法说明:- group(num=0):匹配整个表达式的字符串,默认返回第一个,若输入多个组号,将返回包含那些组对应值的元组
- groups():返回一个包含所有小组字符串的元组
re.rearch(pattern, string, flags=0)
参数同re.match(),匹配成功返回第一个匹配的对象,否则返回Noneresult = re.search(r'\d+', 'abc 123 def 456') print("找到数字:", result.group()) # 123
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。line = "Cats are smarter than dogs"matchObj = re.match( r'dogs', line, re.M|re.I)if matchObj: print ("match --> matchObj.group() : ", matchObj.group())else: print ("No match!!")matchObj = re.search( r'dogs', line, re.M|re.I)if matchObj: print ("search --> matchObj.group() : ", matchObj.group())else: print ("No match!!")
No match!!search --> matchObj.group() : dogs
编译正则表达式,生成一个正则表达式对象(Pattern),供match()和search()函数调用re.compile(pattern[, flags])
pattern = re.compile(r'\d+') m = pattern.match('11one12twothree34four')print(m)# 11
re.findall(pattern, string, flags=0)或pattern.findall(string[, pos[, endpos]])
- endpos:指定字符串的结束位置,默认为字符串的长度
numbers = re.findall(r'\d+', 'abc 123 def 456')print(numbers) # ['123', '456']
re.finditer(pattern, string, flags=0)
for match in re.finditer(r'\d+', 'abc 123 def 456'): print(match.group(), match.span())
re.sub(pattern, repl, string, count=0, flags=0)
- count:(可选)模式匹配后替换的最大次数,默认 0 表示替换所有的匹配
text = "Python 2.7, Python 3.8"new_text = re.sub(r'\d\.\d', 'X.X', text)print(new_text) # Python X.X, Python X.X
re.split(pattern, string[, maxsplit=0, flags=0])
- maxsplit:分割次数,maxsplit=1分割一次,默认为0不限制次数
parts = re.split(r'\s+', 'hello world\tPython')print(parts) # ['hello', 'world', 'Python']
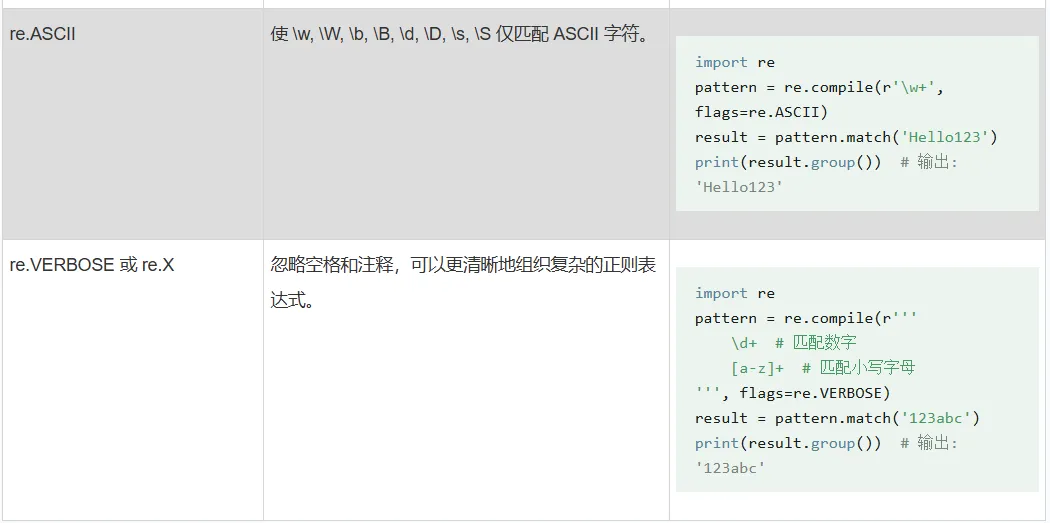
用一些可选标志修饰符来控制匹配的模式,标志可以单独使用,也可以通过按位或(|)组合使用。例如,re.IGNORECASE | re.MULTILINE 表示同时启用忽略大小写和多行模式text = "<div>content1</div><div>content2</div>"# 贪婪匹配 (默认)greedy = re.findall(r'<div>.*</div>', text)print("贪婪匹配:", greedy) # 输出: ['<div>content1</div><div>content2</div>']# 非贪婪匹配non_greedy = re.findall(r'<div>.*?</div>', text)print("非贪婪匹配:", non_greedy) # 输出: ['<div>content1</div>', '<div>content2</div>']
有以下文本,请设计正则表达式,分别提取订单号、金额(纯数字)和客户名
订单号: OD20240115001, 金额: ¥1,234.56, 客户: 张三订单号: OD20240116002, 金额: ¥890.00, 客户: 李四
订单号:\s*([^,]+),\s*金额:\s*¥([\d,.]+),\s*客户:\s*([\u4e00-\u9fa5]+)
如果想一起学习数据分析相关知识,一起交流的朋友,欢迎加我微信,备注【数之真理】,9.9元解锁每日数据小知识分享,全网新手最友好!干货最充足!氛围最好的数据分析分享群等你加入!更多高能福利持续解锁中,福利多多,千万不要错过!!1对1数据咨询开放中,欢迎加V预约咨询,首次咨询享超值优惠