绘制三层桑基图—R语言代码
- 2026-07-01 05:40:35
#加载library(ggalluvial)library(ggplot2)library(dplyr)library(ggpubr)#工作目录setwd("E:/三层桑基图Sankey")#读取输入文件#cluster.txt来自18一致性聚类、无监督聚类ConsensusClusterPlus#risk.txt来自17多因素Cox回归分析cluster=read.table("cluster.txt", header=T, sep="\t", check.names=F, row.names=1)risk=read.table("risk.txt", header=T, sep="\t", check.names=F, row.names=1)
输入cluster.txt(分型结果)
输入risk.txt(风险文件)
#正常和肿瘤数目,第14,15字符,01-09是癌症,10-19是正常,20-29是癌旁group=sapply(strsplit(rownames(cluster),"\\-"), "[", 4)group=sapply(strsplit(group,""), "[", 1)#将2变为1group=gsub("2", "1", group)#提取肿瘤样本cluster = cluster[group == 0,,drop=F]#转置cluster=t(cluster)#样本名仅保留前12字符colnames(cluster)=substr(colnames(cluster),1,12)#转置cluster=t(cluster)#合并数据sameSample=intersect(row.names(cluster), row.names(risk))rt=cbind(risk[sameSample,,drop=F], cluster[sameSample,,drop=F])
#准备桑基图输入文件rt[,"state"]=ifelse(rt[,"state"]==0, "Alive", "Dead")rt=rt[,c("cluster", "risk", "state")]corLodes=to_lodes_form(rt, axes = 1:ncol(rt), id = "Cohort")unique(corLodes$x)unique(corLodes$stratum)corLodes$Cohort#绘制桑基图pdf(file="Sankey.pdf", width=6, height=5.5)mycol=rep(c("#B22D22","#2C3B63", "#44B1C9", "#F6C9C9","#6E568C","#E0367A","#D8D155","#223D6C","#D20A13","#431A3D","#91612D","#FFD121","#088247","#11AA4D","#58CDD9","#7A142C","#5D90BA","#64495D","#7CC767"),15)ggplot(corLodes, aes(x = x, stratum = stratum, alluvium = Cohort,fill = stratum, label = stratum)) +scale_x_discrete(expand = c(0, 0)) +#forward,线条颜色与前面一致,backward,线条颜色与后面一致geom_flow(width = 2/10,aes.flow = "forward") +geom_stratum(alpha = .9,width = 2/10) +scale_fill_manual(values = mycol) +geom_text(stat = "stratum", size = 3,color="black") +xlab("") + ylab("") + theme_bw() +theme(axis.line = element_blank(),axis.ticks = element_blank(),axis.text.y = element_blank()) + #去掉坐标轴theme(panel.grid =element_blank()) +theme(panel.border = element_blank()) +ggtitle("") + guides(fill = FALSE)dev.off()
输出Sankey.pdf(桑基图)
第一列:cluster:A,B
第二例:risk:high,low
第三列:state:Alive,Dead
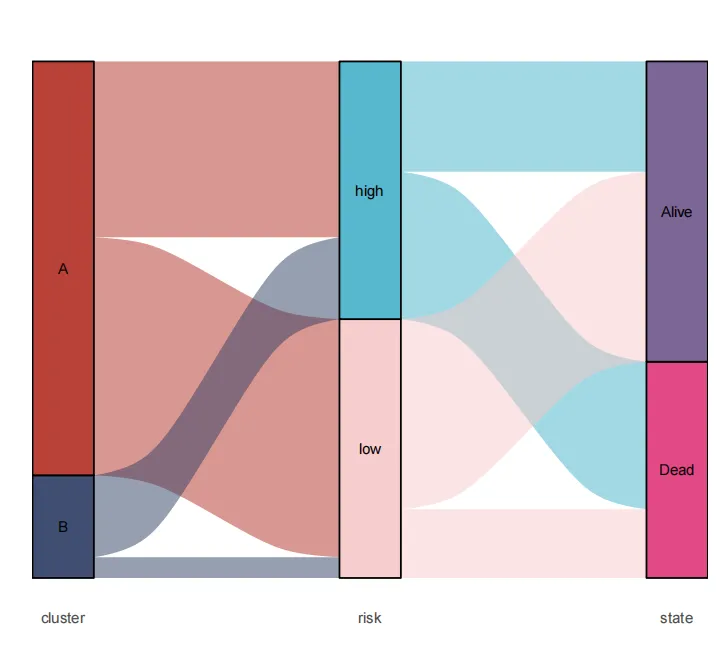
以下是该图的详细解释:
一、 结构解读(从左到右)
图表由三个垂直排列的类别组构成,通过流动的“带子”连接:
左侧 - 初始分类 (Cluster)
代表数据的起始分组,包含两个类别:A(红色)和 B(蓝色)。
每个色块的宽度代表该组别的初始数据量。
中间 - 风险等级 (Risk)
代表数据根据某种标准评估后的中间状态,分为两个等级:High(高风险)和 Low(低风险)。
此处的分类是数据流动的“中转站”。
右侧 - 最终状态 (State)
代表数据的最终结局,包含两种状态:Alive(存活)和 Dead(死亡)。
这是数据流向的终点。
二、 数据流解读
图中的彩色流带(或称“链接”)是关键,它们揭示了:
流向:所有数据都遵循 Cluster → Risk → State 的从左至右流向。
流量大小:流带的宽度与所代表的数据量成正比。越宽,表示从一个类别流向另一个类别的数据量越多。
颜色含义:流带的颜色通常继承自其源头(Cluster)的颜色,以便追踪。
红色流:全部源自 Cluster A 的数据。
蓝色流:全部源自 Cluster B 的数据。
三、 主要洞察(基于典型桑基图逻辑)
通过观察流的宽度变化,可以分析出以下潜在信息:
风险分布差异:
从 Cluster A(红色)流出的数据,主要流向了 Risk High(高风险)。
从 Cluster B(蓝色)流出的数据,主要流向了 Risk Low(低风险)。
这暗示 A 组的整体风险可能高于 B 组。
结局与风险的关系:
流向 Risk High 的数据,其最终结局主要为 State Dead。
流向 Risk Low 的数据,其最终结局主要为 State Alive。
这直观地展示了 高风险与死亡结局、低风险与存活结局之间存在强相关。
总体路径:
最显著的数据路径可能是:Cluster A → Risk High → State Dead(一条较宽的红色流带)。
另一条主要路径是:Cluster B → Risk Low → State Alive(一条较宽的蓝色流带)。
总结
这张桑基图清晰地揭示了 初始分组(Cluster)如何影响风险评级(Risk),而风险评级又最终与结局状态(State)紧密关联。它以一种直观、定量的方式展示了数据在整个流程中的分布、转化和最终归因,常用于医学研究、客户流程分析、资源转移等领域,用于发现关键的影响路径和瓶颈。

