1. 创始时间与作者
2. 官方资源
Python 文档地址:https://docs.python.org/3/library/itertools.html
源代码位置:https://github.com/python/cpython/blob/main/Lib/itertools.py
Python 官方网站:https://www.python.org/
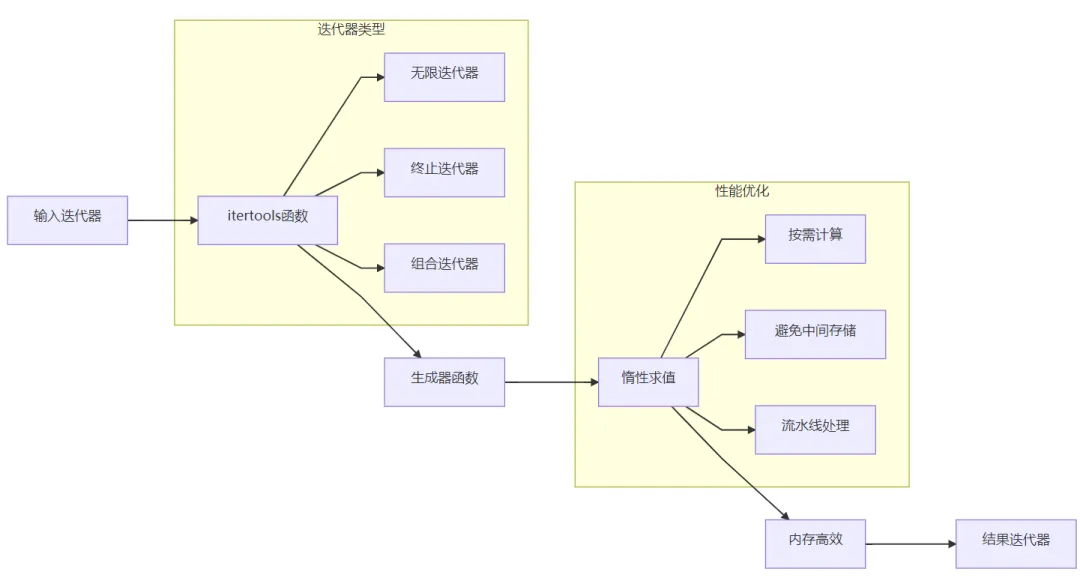
3. 核心功能
4. 应用场景
1. 数据处理和转换
import itertools# 连接多个迭代器list1 = [1, 2, 3]list2 = [4, 5, 6]list3 = [7, 8, 9]combined = list(itertools.chain(list1, list2, list3))print(f"连接结果: {combined}") # 输出: [1, 2, 3, 4, 5, 6, 7, 8, 9]# 分组操作data = [('a', 1), ('a', 2), ('b', 3), ('b', 4), ('c', 5)]grouped = {}for key, group in itertools.groupby(data, lambda x: x[0]):grouped[key] = list(group)print(f"分组结果: {grouped}")2. 组合数学计算
import itertools# 排列计算items = ['A', 'B', 'C']permutations = list(itertools.permutations(items, 2))print(f"排列结果 (P(3,2)): {permutations}")# 输出: [('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')]# 组合计算combinations = list(itertools.combinations(items, 2))print(f"组合结果 (C(3,2)): {combinations}")# 输出: [('A', 'B'), ('A', 'C'), ('B', 'C')]# 笛卡尔积colors = ['红', '蓝']sizes = ['S', 'M', 'L']products = list(itertools.product(colors, sizes))print(f"笛卡尔积: {products}")# 输出: [('红', 'S'), ('红', 'M'), ('红', 'L'), ('蓝', 'S'), ('蓝', 'M'), ('蓝', 'L')]3. 高效循环和迭代
import itertools# 无限计数器counter = itertools.count(start=10, step=2)print("计数器示例:")for i in range(5):print(next(counter)) # 输出: 10, 12, 14, 16, 18# 循环迭代器cycler = itertools.cycle(['A', 'B', 'C'])print("循环器示例:")for i in range(6):print(next(cycler)) # 输出: A, B, C, A, B, C# 重复生成器repeater = itertools.repeat('Hello', 3)print("重复器示例:")print(list(repeater)) # 输出: ['Hello', 'Hello', 'Hello']4. 高级数据筛选
import itertools# 数据压缩筛选names = ['Alice', 'Bob', 'Charlie', 'David']scores = [85, 92, 78, 90]passed = [True, True, False, True]# 使用compress进行条件筛选passed_students = itertools.compress(names, passed)print(f"通过学生: {list(passed_students)}") # 输出: ['Alice', 'Bob', 'David']# 使用dropwhile和takewhilenumbers = [1, 3, 5, 2, 4, 6, 1]print("大于2之前的数字:")print(list(itertools.takewhile(lambda x: x<= 2, numbers))) # 输出: [1]print("大于2之后的数字:")print(list(itertools.dropwhile(lambda x: x<= 2, numbers))) # 输出: [3, 5, 2, 4, 6, 1]# 使用filterfalse获取不满足条件的元素odd_numbers = list(itertools.filterfalse(lambda x: x%2 == 0, range(10)))print(f"奇数: {odd_numbers}") # 输出: [1, 3, 5, 7, 9]
5. 底层逻辑与技术原理
核心架构
关键技术
生成器实现:
使用 Python 生成器实现惰性求值
只在需要时计算下一个值,节省内存
支持大规模数据处理
迭代器协议:
算法优化:
使用高效的数学算法实现组合操作
优化常见迭代模式的内存使用
提供 C 语言实现的加速版本
函数式编程:
支持函数式编程风格
可与 lambda 函数和内置函数结合使用
提供无副作用的纯函数操作
6. 安装与配置
安装说明
# itertools 是 Python 标准库的一部分,无需单独安装# 从 Python 2.3+ 开始内置支持# 检查 Python 版本python --version# 导入测试python -c"import itertools; print('itertools 模块可用')"版本兼容性
| Python 版本 | itertools 功能支持 |
|---|
| 2.3+ | 基本迭代器功能 |
| 2.6+ | 更多组合函数 |
| 3.0+ | 更好的性能优化 |
| 3.1+ | accumulate 函数 |
| 3.3+ | accumulate 支持 func 参数 |
| 3.10+ | pairwise 函数 |
依赖关系
必需依赖:无(Python 标准库组件)
可选增强:
环境要求
| 组件 | 最低要求 | 推荐配置 |
|---|
| Python | 2.3+ | 3.8+ |
| 内存 | 极低(惰性求值) | 无特殊要求 |
| 性能 | 基础性能 | 无特殊要求 |
7. 性能特点
| 功能 | 内存使用 | 性能 | 说明 |
|---|
| 无限迭代器 | 常数内存 | 极高 | 只存储状态,不存储数据 |
| 有限迭代器 | 常数内存 | 高 | 惰性处理输入迭代器 |
| 组合生成器 | 取决于算法 | 中等 | 数学计算复杂度较高 |
| 数据处理 | 极低 | 高 | 流水线处理,无中间存储 |
注:性能特征基于典型使用场景,itertools 的主要优势是内存效率而非绝对速度
8. 高级功能使用
1. 累积计算
import itertoolsimport operator# 基本累积计算numbers = [1, 2, 3, 4, 5]cumulative_sum = list(itertools.accumulate(numbers))print(f"累积和: {cumulative_sum}") # 输出: [1, 3, 6, 10, 15]# 使用自定义函数cumulative_product = list(itertools.accumulate(numbers, operator.mul))print(f"累积积: {cumulative_product}") # 输出: [1, 2, 6, 24, 120]# 复杂累积操作def running_max(acc, val):return max(acc, val)max_so_far = list(itertools.accumulate(numbers, running_max))print(f"运行最大值: {max_so_far}") # 输出: [1, 2, 3, 4, 5]2. 迭代器切片和窗口
import itertools# 迭代器切片(类似于列表切片但更高效)def iterator_slice(iterable, start, stop=None, step=1):"""对迭代器进行切片操作"""if stop is None:stop = startstart = 0it = iter(iterable)# 跳过开始部分itertools.islice(it, start, None)# 返回切片return itertools.islice(it, 0, stop-start, step)# 使用示例numbers = range(100) # 大范围,但内存友好sliced = iterator_slice(numbers, 10, 20, 2)print(f"切片结果: {list(sliced)}") # 输出: [10, 12, 14, 16, 18]# 滑动窗口def sliding_window(iterable, size=2):"""生成滑动窗口"""iters = itertools.tee(iterable, size)for i, it in enumerate(iters):itertools.islice(it, i, None)return zip(*iters)# 使用示例data = [1, 2, 3, 4, 5]windows = list(sliding_window(data, 3))print(f"滑动窗口: {windows}") # 输出: [(1, 2, 3), (2, 3, 4), (3, 4, 5)]3. 高级组合模式
import itertools# 多重笛卡尔积def multi_product(*iterables, repeat=1):"""生成多重笛卡尔积"""pools = [tuple(pool) for pool in iterables] *repeatresult = [[]]for pool in pools:result = [x+ [y] for x in result for y in pool]return result# 使用示例result = multi_product([1, 2], ['a', 'b'], repeat=1)print(f"多重笛卡尔积: {result}")# 组合与排列的扩展def powerset(iterable):"""生成集合的幂集"""s = list(iterable)return itertools.chain.from_iterable(itertools.combinations(s, r) for r in range(len(s) +1) )# 使用示例items = ['A', 'B', 'C']all_subsets = list(powerset(items))print(f"幂集: {all_subsets}")# 输出: [(), ('A',), ('B',), ('C',), ('A', 'B'), ('A', 'C'), ('B', 'C'), ('A', 'B', 'C')]4. 迭代器调试和监控
import itertoolsdef debug_iterator(iterable, name="iterator"):"""调试迭代器,记录每个值的产生"""for i, item in enumerate(iterable):print(f"{name}[{i}] = {item}")yield item# 使用示例numbers = [1, 2, 3, 4, 5]debugged = debug_iterator(numbers, "numbers")# 正常的迭代操作sum_result = sum(itertools.islice(debugged, 3))print(f"前三个数的和: {sum_result}")# 迭代器状态检查def iterator_info(iterator):"""获取迭代器信息(不消耗迭代器)"""# 使用 tee 来窥视而不消耗peek, original = itertools.tee(iterator)try:first = next(peek)# 计算长度(会消耗副本)length = 1+sum(1 for _ in peek)return {"has_items": True, "first_item": first, "length": length}except StopIteration:return {"has_items": False, "first_item": None, "length": 0}# 使用示例it = iter([10, 20, 30])info = iterator_info(it)print(f"迭代器信息: {info}")# 仍然可以正常使用原迭代器print(f"第一个元素: {next(it)}")
9. 与相关工具对比
| 特性 | itertools | 手动循环 | 列表推导式 | NumPy |
|---|
| 内存效率 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 代码简洁性 | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 功能丰富度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 学习曲线 | ⭐⭐⭐ | ⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 性能 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 适用场景 | 通用迭代 | 简单循环 | 简单转换 | 数值计算 |
10. 最佳实践案例
大数据处理:
import itertoolsimport gzipdef process_large_file(filename):"""处理大型文件,内存高效"""with gzip.open(filename, 'rt') as f:# 使用 islice 分批处理batch_size = 1000batch_num = 0while True:# 读取一批行batch = list(itertools.islice(f, batch_size))if not batch:break# 处理批次process_batch(batch, batch_num)batch_num += 1def process_batch(lines, batch_num):"""处理单个批次"""print(f"处理批次 {batch_num}, 行数: {len(lines)}")# 实际处理逻辑...数据分析管道:
import itertoolsimport csvdef data_analysis_pipeline(filename):"""数据分析管道"""with open(filename, 'r') as f:reader = csv.reader(f)# 跳过标题行data = itertools.islice(reader, 1, None)# 过滤无效数据valid_data = itertools.filterfalse(lambda row: not row or row[0].startswith('#'), data)# 分组分析grouped = itertools.groupby(valid_data, lambda row: row[2]) # 按第三列分组for key, group in grouped:group_list = list(group)print(f"类别 {key}: {len(group_list)} 条记录")# 进一步分析...生成测试数据:
import itertoolsimport randomdef generate_test_data():"""生成组合测试数据"""# 参数组合params = {'mode': ['train', 'test', 'validate'],'batch_size': [32, 64, 128],'learning_rate': [0.1, 0.01, 0.001] }# 生成所有组合keys = params.keys()values = params.values()for combination in itertools.product(*values):config = dict(zip(keys, combination))# 添加一些随机变化config['dropout'] = random.uniform(0.1, 0.5)yield config# 使用示例for i, config in enumerate(itertools.islice(generate_test_data(), 5)):print(f"测试配置 {i}: {config}")实时数据流处理:
import itertoolsimport timedef real_time_data_stream():"""模拟实时数据流处理"""# 无限数据流data_stream = (random.randint(1, 100) for _ in itertools.count())# 滑动窗口分析window_size = 5windows = sliding_window(data_stream, window_size)for i, window in enumerate(itertools.islice(windows, 10)):avg = sum(window) / window_sizeprint(f"窗口 {i}: {window}, 平均值: {avg:.2f}")time.sleep(0.1) # 模拟实时延迟
总结
itertools 是 Python 迭代器编程的核心工具集,核心价值在于:
内存高效:惰性求值避免中间存储,适合处理大规模数据
功能强大:提供丰富的迭代器操作和组合数学功能
代码简洁:用声明式代码替代复杂的循环逻辑
性能优良:优化的算法实现和C语言加速
技术亮点:
基于生成器的惰性求值实现
丰富的数学组合功能
无缝集成Python迭代协议
纯函数式无副作用操作
适用场景:
大规模数据处理和分析
组合数学和算法实现
数据流和实时处理
测试数据生成
函数式编程应用
使用方式:
import itertools# Python 标准库,无需安装
学习资源:
官方文档:https://docs.python.org/3/library/itertools.html
深入教程:Real Python itertools 指南,https://realpython.com/python-itertools/
实例教程:itertools 秘籍,https://docs.python.org/3/library/itertools.html#itertools-recipes
作为 Python 标准库的一部分,itertools 模块是高效迭代器编程的必备工具,遵循 Python 软件基金会许可证,可免费用于任何 Python 项目。