Linux HMM(异构内存管理)工作机制及软件实现流程
- 2026-07-03 11:56:06
knowledge base:
MMU notifier工作原理及其在GPU页表管理中的应用
CXL如何实现NPU/GPU对CPU内存直接访问与零拷贝:软硬件流程与原理详解
一、HMM 概述
HMM(Heterogeneous Memory Management)是Linux内核中用于管理异构内存系统的框架。它主要用于以下场景:
1. GPU或其他加速器与CPU共享统一地址空间
2. 非一致性内存访问架构(如设备内存、NVDIMM)
3. 内存热迁移(CPU内存 ↔ 设备内存)
4. 透明页迁移(按需将页面迁移到最优内存位置)

二、核心概念与架构
2.1 HMM 设计目标
· 透明性:应用程序无需修改即可使用设备内存
· 一致性:在统一虚拟地址空间下管理多种物理内存
· 性能:最小化CPU与设备间的数据拷贝
2.2 关键组件架构
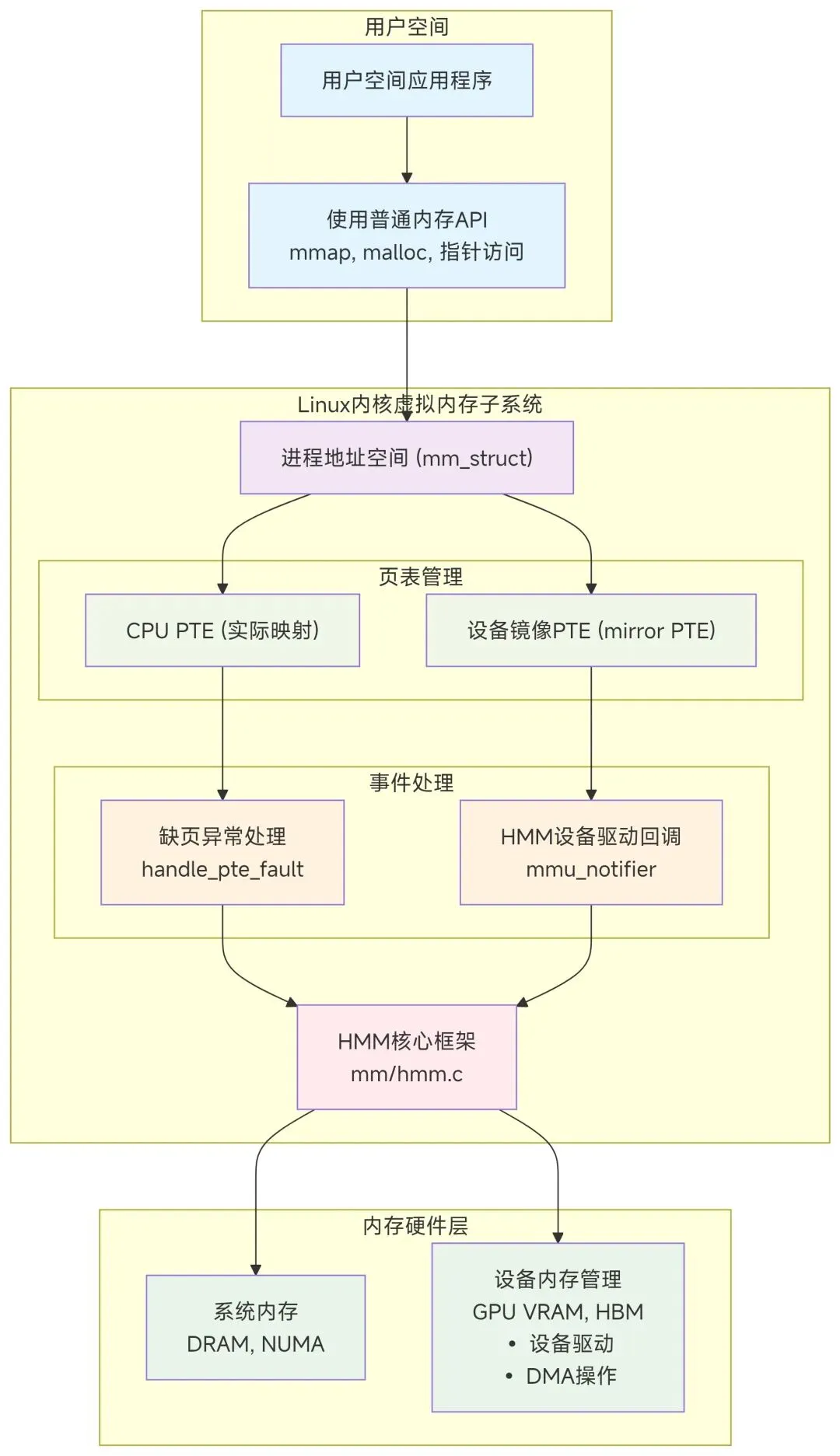
数据流树状结构图
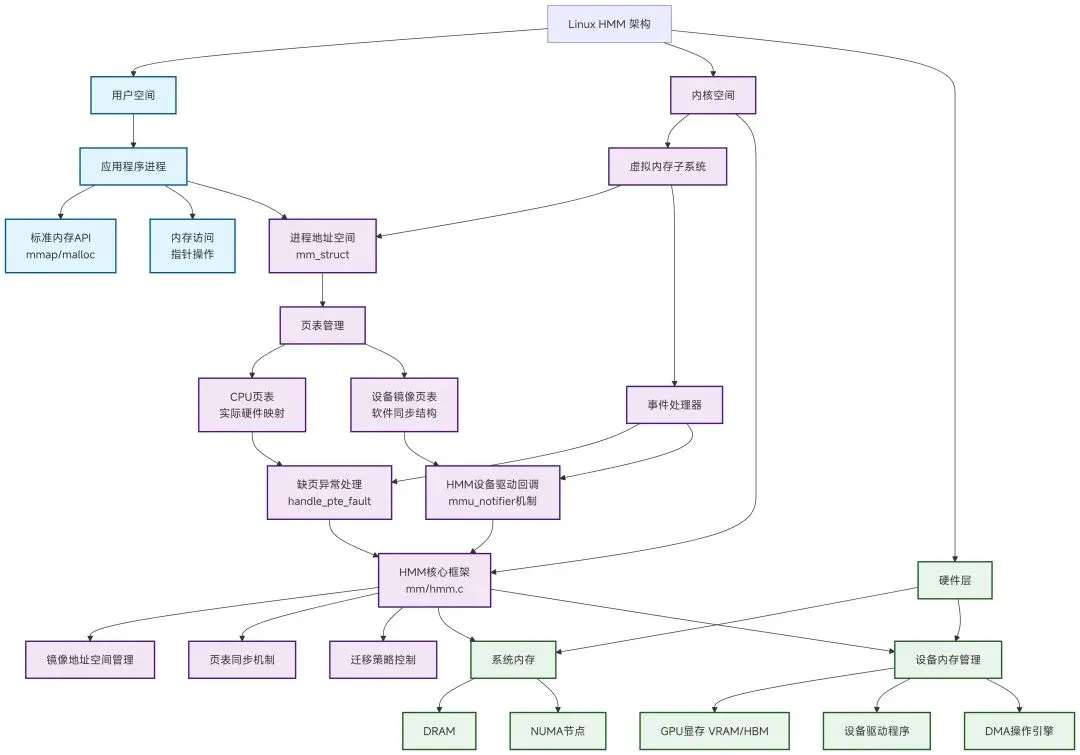
三、HMM 软件工作流程
3.1 地址空间镜像(Mirroring)
// 用户空间API示例:映射设备内存
int fd = open("/dev/gpu_device", O_RDWR);
void *ptr = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, offset);
内核侧工作流程:
1. 设备驱动注册HMM镜像
// 设备驱动初始化
struct hmm_mirror_ops mirror_ops = {
.sync_cpu_device_pagetables = device_sync_pagetables,
.fault = device_fault_handler,
};
hmm_mirror_register(&device_mirror, mm, &mirror_ops);
2. 创建镜像页表
· HMM为进程创建设备镜像页表
· 镜像页表与CPU页表保持同步(通过mmu_notifier)
3.2 缺页异常处理流程
当CPU访问已映射到设备内存的虚拟地址时:
CPU访问虚拟地址VA
↓
触发缺页异常(page fault)
↓
handle_pte_fault() [内核缺页处理]
↓
检查PTE → 发现是特殊的"设备PTE"标记
↓
调用HMM缺页处理程序 hmm_vma_fault()
↓
├── 情况1:页面在设备内存
│ ↓
│ hmm_vma_do_fault()
│ ↓
│ 调用设备驱动的fault回调
│ ↓
│ 设备处理缺页(可能迁移到系统内存)
│
└── 情况2:需要页面迁移
↓
迁移页面到最优位置
↓
更新CPU和设备页表
3.3 页表同步机制(mmu_notifier)
HMM使用mmu_notifier回调保持CPU和设备页表同步:
// 设备驱动注册notifier回调
static const struct mmu_notifier_ops gpu_mmu_notifier_ops = {
.invalidate_range_start = gpu_invalidate_range_start,
.invalidate_range_end = gpu_invalidate_range_end,
.clear_flush_young = gpu_clear_flush_young,
};
// 当CPU页表更新时,内核回调通知设备
static void gpu_invalidate_range_start(struct mmu_notifier *mn,
struct mm_struct *mm,
unsigned long start,
unsigned long end)
{
// 设备需要更新自己的页表
struct gpu_device *gpu = container_of(mn, struct gpu_device, mn);
// 使设备TLB失效或更新设备页表
gpu_flush_tlb_range(gpu, start, end);
}
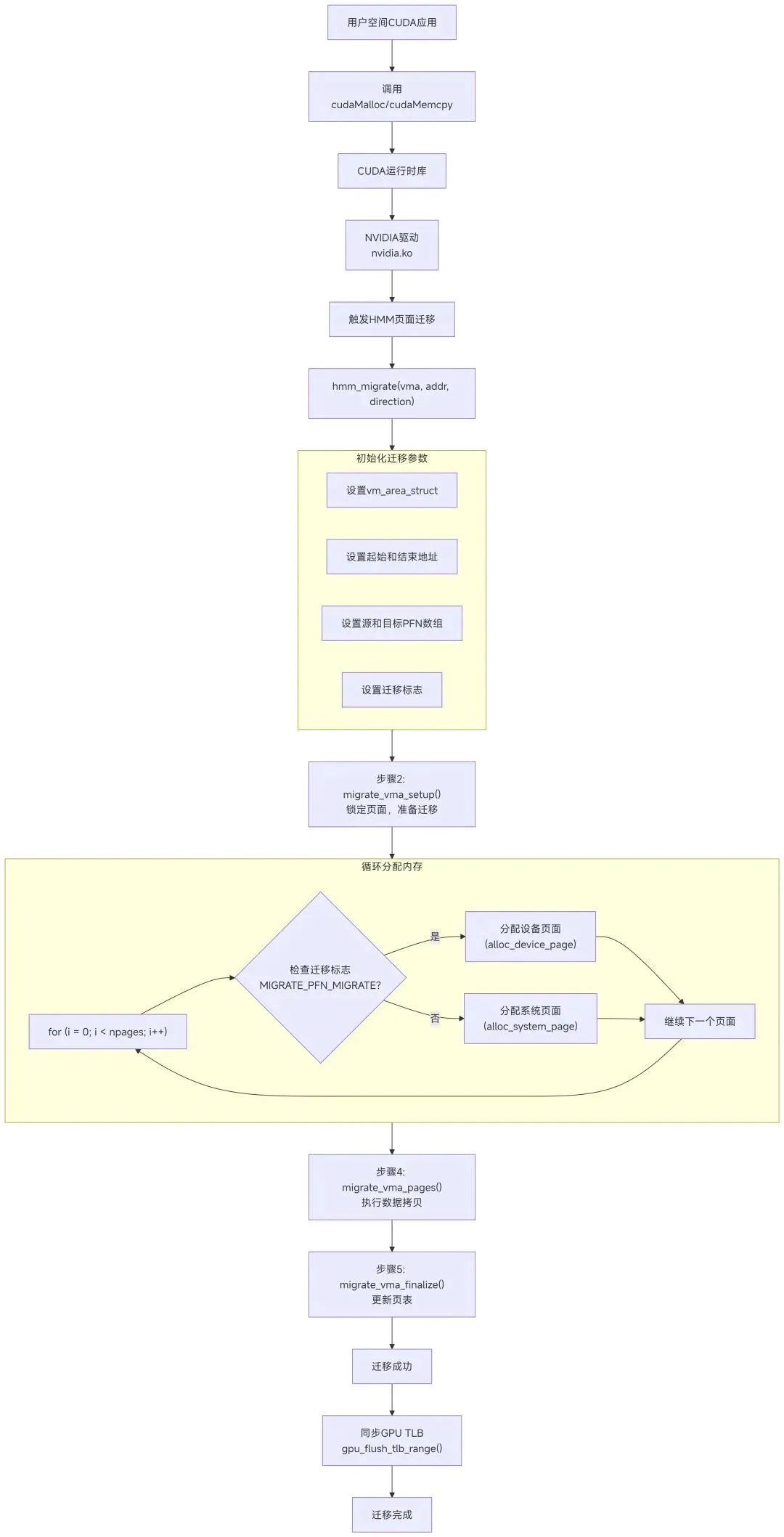
3.4 页面迁移流程
HMM支持透明页面迁移,优化数据位置:
// 迁移决策和执行的简化流程
int hmm_migrate(struct vm_area_struct *vma,
unsigned long addr,
enum migrate_vma_direction direction)
{
// 1. 收集可迁移的页面
struct migrate_vma args = {
.vma = vma,
.start = addr,
.end = addr + PAGE_SIZE,
.src = &src_pfns,
.dst = &dst_pfns,
.flags = MIGRATE_VMA_SELECT_SYSTEM, // 或设备
};
// 2. 锁定页面,准备迁移
migrate_vma_setup(&args);
// 3. 分配目标内存(系统或设备)
for (i = 0; i < npages; i++) {
if (args.src[i] & MIGRATE_PFN_MIGRATE) {
// 分配新页面
args.dst[i] = alloc_device_page(); // 或alloc_system_page()
}
}
// 4. 执行数据拷贝
migrate_vma_pages(&args);
// 5. 更新页表
migrate_vma_finalize(&args);
return 0;
}
四、HMM编程接口
4.1 用户空间API
用户空间主要通过现有标准API使用HMM:
1. mmap():映射设备内存到进程地址空间
2. madvise():提供内存使用提示
// 提示内核页面应优先在设备内存
madvise(ptr, size, MADV_GPU_PREFER);
4.2 内核驱动API
设备驱动使用HMM API集成:
// 1. 初始化HMM镜像
struct hmm_mirror mirror;
ret = hmm_mirror_register(&mirror, process_mm, &mirror_ops);
// 2. 处理缺页
static int device_fault_handler(struct hmm_mirror *mirror,
struct hmm_range *range)
{
// 处理设备缺页
for (i = 0; i < range->npages; i++) {
if (range->pfns[i] & HMM_PFN_DEVICE_PRIVATE) {
// 页面在设备内存,可能需要迁移
}
}
}
// 3. 注册mmu_notifier
mmu_notifier_register(&device->mn, mm);
五、典型应用:GPU内存管理
5.1 NVIDIA UVM(统一虚拟内存)
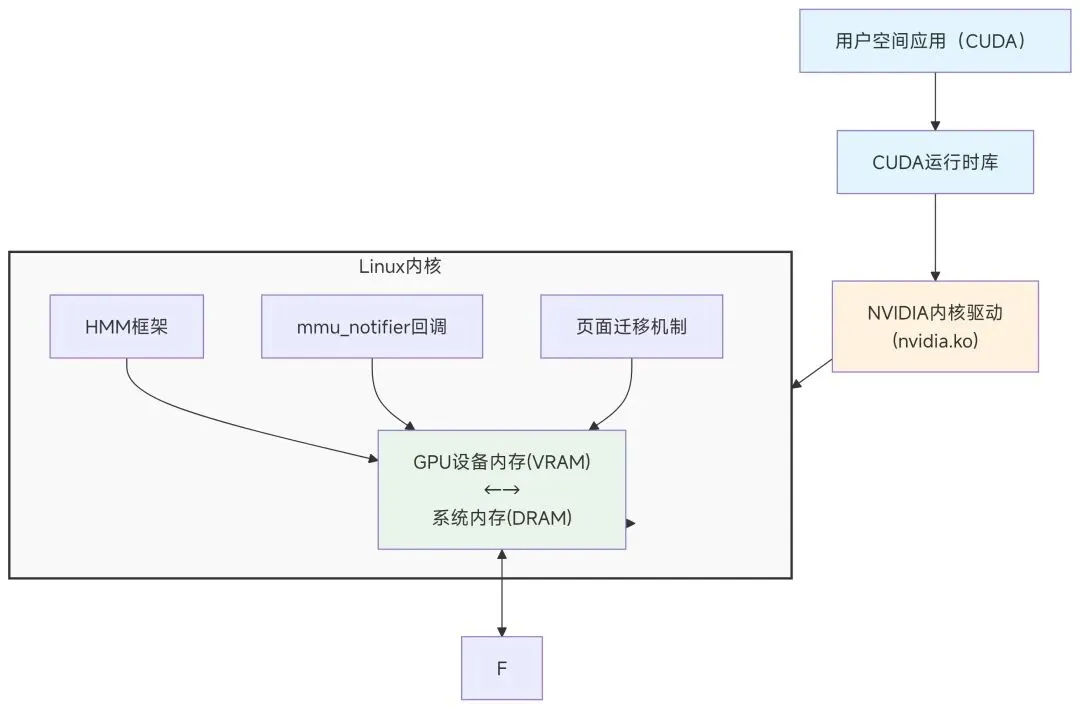
5.2 ROCm(AMD GPU)中的HMM使用
AMD ROCm使用HMM实现统一内存:
// ROCm KFD(内核融合驱动)中的HMM集成
static struct mmu_notifier_ops kfd_mmu_notifier_ops = {
.release = kfd_mmu_notifier_release,
.invalidate_range_start = kfd_mmu_notifier_invalidate_range_start,
.invalidate_range_end = kfd_mmu_notifier_invalidate_range_end,
};
// 处理GPU缺页
int kfd_hmm_migrate_to_ram(struct kgd_mem *mem,
struct vm_area_struct *vma,
struct kfd_process *p)
{
// 当CPU访问GPU内存时,迁移到系统RAM
return hmm_migrate(mem->range, HMM_MIGRATE_TO_RAM);
}
六、性能优化与挑战
6.1 优化策略
1. 迁移策略优化
· 懒惰迁移:仅在访问时迁移
· 预取策略:基于访问模式预测性迁移
· NUMA感知:考虑内存带宽和延迟
2. TLB一致性维护
· 批量无效化:减少TLB shootdown开销
· 范围无效化:优化大范围TLB更新
3. 锁优化
· 细粒度锁:减少锁竞争
· RCU保护:读多写少场景优化
6.2 挑战
1. 死锁风险:内存回收与迁移的锁依赖
2. 性能开销:页表同步和迁移的CPU开销
3. 设备限制:设备内存的DMA限制和地址宽度
七、代码实例:简化HMM驱动
#include <linux/hmm.h>
struct my_device {
struct device *dev;
struct hmm_mirror mirror;
struct mmu_notifier mn;
};
// HMM镜像操作
static const struct hmm_mirror_ops my_mirror_ops = {
.sync_cpu_device_pagetables = my_sync_pagetables,
.fault = my_fault_handler,
};
// mmu_notifier操作
static const struct mmu_notifier_ops my_notifier_ops = {
.invalidate_range_start = my_invalidate_start,
.invalidate_range_end = my_invalidate_end,
};
// 设备初始化
int my_device_init(struct my_device *mydev)
{
// 注册HMM镜像
int ret = hmm_mirror_register(&mydev->mirror, current->mm, &my_mirror_ops);
if (ret) return ret;
// 注册mmu_notifier
mydev->mn.ops = &my_notifier_ops;
ret = mmu_notifier_register(&mydev->mn, current->mm);
return ret;
}
// 处理缺页
static int my_fault_handler(struct hmm_mirror *mirror,
struct hmm_range *range)
{
struct my_device *mydev = container_of(mirror, struct my_device, mirror);
unsigned long *pfns = range->pfns;
unsigned long addr = range->start;
for (i = 0; i < range->npages; i++, addr += PAGE_SIZE) {
// 检查访问权限
if (!(range->flags & HMM_PFN_WRITE) &&
(pfns[i] & HMM_PFN_WRITE))
return -EPERM;
// 处理缺页:迁移或分配
if (!(pfns[i] & HMM_PFN_VALID)) {
// 分配设备页面
dma_addr_t dma_addr = my_alloc_page(mydev);
// 更新PFN数组
pfns[i] = hmm_device_entry_from_pfn(
PFN_DOWN(dma_to_phys(mydev->dev, dma_addr)));
pfns[i] |= HMM_PFN_VALID;
if (range->flags & HMM_PFN_WRITE)
pfns[i] |= HMM_PFN_WRITE;
}
}
return 0;
}
八、调试与监控
8.1 调试工具
1. tracepoints:
#bash
# 跟踪HMM事件
echo 1 > /sys/kernel/debug/tracing/events/hmm/enable
cat /sys/kernel/debug/tracing/trace_pipe
2. 统计信息:
#bash
# 查看迁移统计
cat /proc/vmstat | grep migrate
8.2 性能监控
· 迁移计数:/proc/vmstat中的pgmigrate_*
· 缺页统计:/proc/[pid]/stat中的minflt/majflt
· 内存带宽:使用perf监控内存访问
九、总结
Linux HMM为异构计算提供了关键的基础设施:
1. 透明性:应用程序无需修改即可使用设备内存
2. 统一性:在单一虚拟地址空间中管理多种物理内存
3. 动态性:支持运行时页面迁移优化性能
4. 可扩展性:支持多种设备类型(GPU、FPGA、加速器)
HMM是现代异构计算系统的基石,特别是在AI/ML、科学计算和高性能计算领域,它使得CPU和设备能够更高效地协作,最大化利用系统内存资源。