【Python时序预测系列】建立CNN-LSTM-Transformer融合模型实现多变量时序预测(案例+源码)
- 2026-07-06 18:45:17
这是我的第449篇原创文章。
『数据杂坛』以Python语言为核心,垂直于数据科学领域,专注于(可戳👉)Python程序设计|数据分析|特征工程|机器学习分类|机器学习回归|深度学习分类|深度学习回归|单变量时序预测|多变量时序预测|语音识别|图像识别|自然语音处理|大语言模型|软件设计开发等技术栈交流学习,涵盖数据挖掘、计算机视觉、自然语言处理等应用领域。(文末有惊喜福利)

一、引言
CNN(卷积)擅长抓“局部模式”,LSTM(长短时记忆网络)擅长记住“时间上的因果和长期依赖”,Transformer(自注意力)擅长把序列里任意两个时刻相互比较、找全局相关性,而且能并行处理。
融合方式:串联CNN → LSTM → Transformer。先提取局部特征,再用 LSTM 建长期状态,最后用 Transformer 做全局交互。
下面通过一个具体的案例,融合CNN + LSTM + Transformer进行多变量输入单变量输出单步时间序列预测,包括模型构建、训练、预测等等。
二、实现过程
2.1 数据加载
核心代码:
df = pd.read_csv('data.csv', parse_dates=["Date"], index_col=[0])df = pd.DataFrame(df)
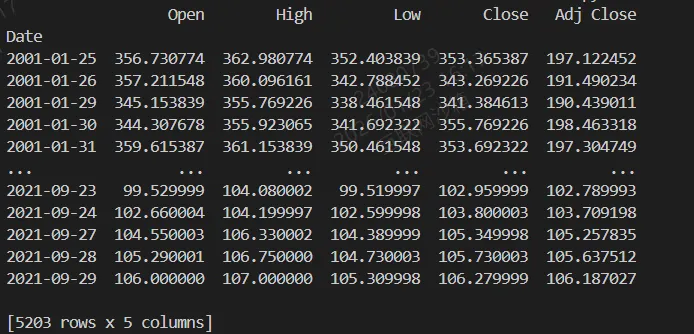
结果:原始数据集总数5203
2.2 数据划分
核心代码:
test_split=round(len(df)*0.20)df_for_training=df[:-test_split]df_for_testing=df[-test_split:]
训练集:4162,测试集:1041
2.3 数据归一化
核心代码:
scaler = MinMaxScaler(feature_range=(0,1))df_for_training_scaled = scaler.fit_transform(df_for_training)df_for_testing_scaled=scaler.transform(df_for_testing)
2.4 构造时序数据集
核心代码:
train_dataset = TimeSeriesDataset(df_for_training_scaled, seq_len=30, pred_len=1)test_dataset = TimeSeriesDataset(df_for_testing_scaled, seq_len=30, pred_len=1)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
时序训练集和测试集数组形状:

2.5 CNN_LSTM_Transformer模型
核心代码:
class CNN_LSTM_Transformer(nn.Module):def __init__(self, input_dim=5, cnn_channels=16, lstm_hidden=32, transformer_dim=32,transformer_heads=4, transformer_layers=1, pred_len=1):super().__init__()# CNNself.cnn = nn.Conv1d(in_channels=input_dim, out_channels=cnn_channels, kernel_size=3, padding=1)self.cnn_relu = nn.ReLU()# LSTMself.lstm = nn.LSTM(input_size=cnn_channels, hidden_size=lstm_hidden, batch_first=True)# Transformer Encoderencoder_layer = nn.TransformerEncoderLayer(d_model=transformer_dim, nhead=transformer_heads, batch_first=True)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=transformer_layers)# Projection layersself.proj_lstm = nn.Linear(lstm_hidden, transformer_dim)self.pred_len = pred_lenself.fc_out = nn.Linear(transformer_dim, pred_len)def forward(self, x):# x: [batch, seq_len, 1]batch_size, seq_len, _ = x.shape# CNN expects [batch, channels, seq_len]cnn_out = self.cnn_relu(self.cnn(x.transpose(1,2))) # [B, C, T]cnn_out = cnn_out.transpose(1,2) # [B, T, C]# LSTMlstm_out, _ = self.lstm(cnn_out) # [B, T, hidden]lstm_proj = self.proj_lstm(lstm_out) # [B, T, transformer_dim]# Transformertrans_out = self.transformer(lstm_proj) # [B, T, transformer_dim]# 取最后时间步输出预测out = self.fc_out(trans_out[:, -1, :]) # [B, pred_len]return out.unsqueeze(-1) # [B, pred_len, 1]
2.6 训练模型
核心代码:
def train_model(model, dataloader, num_epochs=50, learning_rate=1e-3, device='cpu'):optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)criterion = nn.MSELoss()model.train()loss_history = []for epoch in range(num_epochs):epoch_losses = []for batch_data, batch_targets in dataloader:batch_data = batch_data.to(device)batch_targets = batch_targets.to(device)optimizer.zero_grad()outputs = model(batch_data)loss = criterion(outputs, batch_targets)loss.backward()optimizer.step()epoch_losses.append(loss.item())avg_loss = np.mean(epoch_losses)loss_history.append(avg_loss)if (epoch + 1) % 10 == 0:print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {avg_loss:.4f}")return loss_history
结果:

2.7 模型测试集评估
核心代码:
def evaluate_model(model, dataloader, device='cpu'):model.eval()preds = []trues = []with torch.no_grad():for batch_data, batch_targets in dataloader:batch_data = batch_data.to(device)outputs = model(batch_data)preds.append(outputs.cpu().numpy())trues.append(batch_targets.cpu().numpy())preds = np.concatenate(preds, axis=0).squeeze()trues = np.concatenate(trues, axis=0).squeeze()return preds, trues
2.8 结果可视化
核心代码:
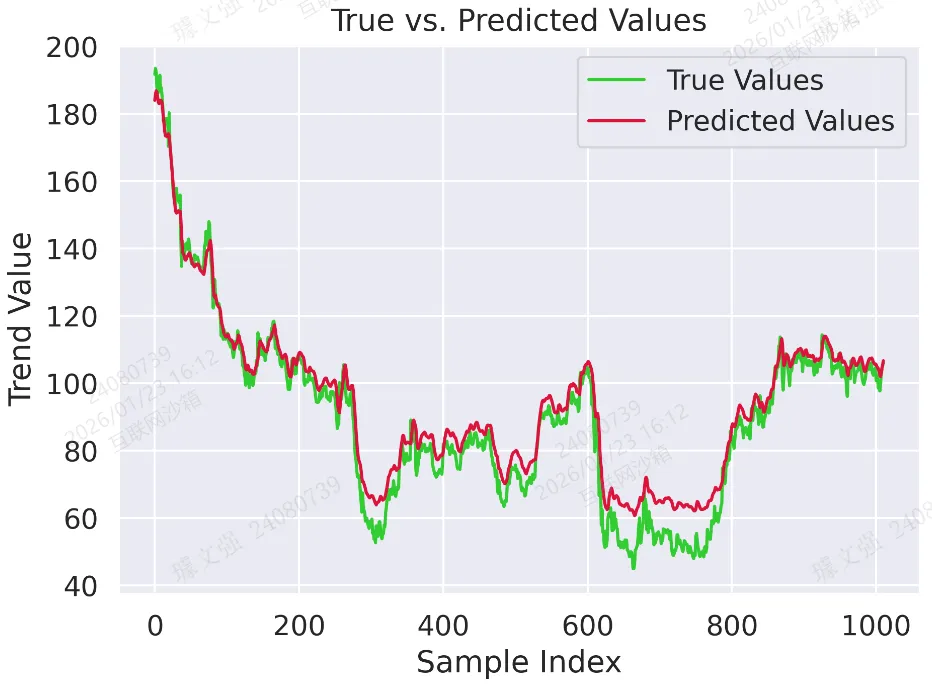
def visualize_results(loss_history, preds, trues):sns.set(font_scale=1.2)plt.rc('font', family=['Times New Roman', 'Simsun'], size=12)# 图 1:训练损失曲线# 模型在训练过程中损失的下降情况,说明模型不断优化拟合数据。plt.plot(loss_history, marker='o', color='dodgerblue', linestyle='-', linewidth=2)plt.title("Training Loss Curve")plt.xlabel("Epoch")plt.ylabel("MSE Loss")plt.tight_layout()plt.savefig('output_image1.png', dpi=300, format='png')plt.show()# 图 2:真实值与预测值对比曲线# 对比曲线直观展示模型预测趋势与真实数据的匹配情况,越接近表示模型效果越好。plt.plot(trues, label="True Values", color='limegreen')plt.plot(preds, label="Predicted Values", color='crimson')plt.title("True vs. Predicted Values")plt.xlabel("Sample Index")plt.ylabel("Trend Value")plt.legend()plt.tight_layout()plt.savefig('output_image2.png', dpi=300, format='png')plt.show()
图 1:训练损失曲线
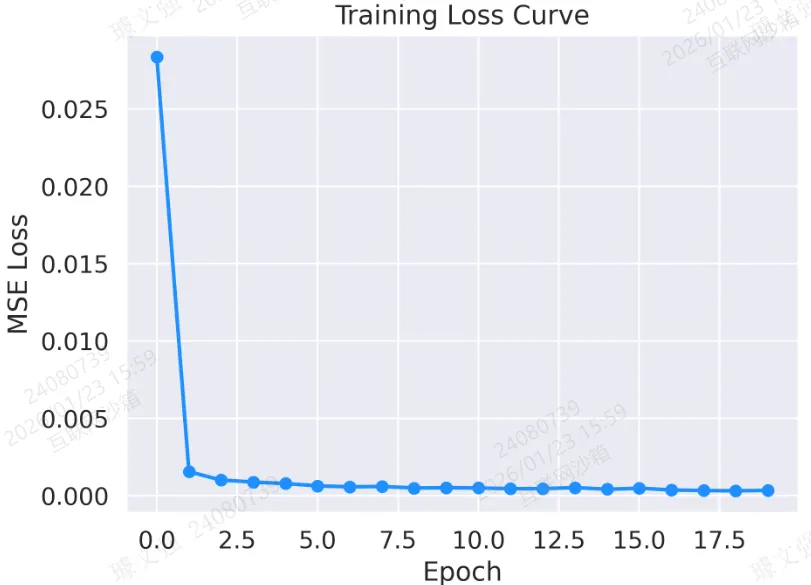
图 2:真实值与预测值对比曲线
2.9 计算误差
核心代码:
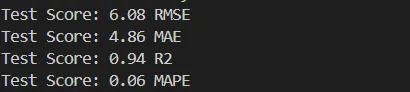
testScore1 = math.sqrt(mean_squared_error(preds_test, trues_test))print('Test Score: %.2f RMSE' % (testScore1))testScore2 = mean_absolute_error(preds_test, trues_test)print('Test Score: %.2f MAE' % (testScore2))testScore3 = r2_score(preds_test, trues_test)print('Test Score: %.2f R2' % (testScore3))testScore4 = mean_absolute_percentage_error(preds_test, trues_test)print('Test Score: %.2f MAPE' % (testScore4))
结果:
建立CNN与Transformer融合模型实现单变量时序预测(案例+源码)
建立Transformer-LSTM-TCN-XGBoost融合模型多变量时序预测(源码)
利用SHAP进行特征重要性分析-决策树模型为例(案例+源码)
梯度提升集成:LightGBM与XGBoost组合预测油耗(案例+源码)
一文教你建立随机森林-贝叶斯优化模型预测房价(案例+源码)
建立随机森林模型预测心脏疾病(完整实现过程)
建立CNN模型实现猫狗图像分类(案例+源码)
使用LSTM模型进行文本情感分析(案例+源码)
基于Flask将深度学习模型部署到web应用上(完整案例)
新版Dify 开发自定义工具插件在工作流中直接调用(完整步骤)
作者简介:
读研期间发表6篇SCI数据算法相关论文,目前在某研究院从事数据算法相关研究工作,结合自身科研实践经历不定期持续分享关于Python、数据分析、特征工程、机器学习、深度学习、人工智能系列基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
1、关注下方公众号,点击“领资料”即可免费领取电子资料书籍。
2、文章底部点击喜欢作者即可联系作者获取相关数据集和源码。
3、数据算法方向论文指导或就业指导,点击“联系我”添加作者微信直接交流。
4、有商务合作相关意向,点击“联系我”添加作者微信直接交流。


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 电脑蓝屏重启?别慌!6步自查+代码解读,搞定90%故障不送修
- 哇哦,苏州这里的编程语言课程小白也可以学习
- Science | 谁在用AI编程?生成式AI的全球扩散与影响
- Python基础练习题入门必刷题 第38题while循环 讲解
- LeetCode:分割等和子集代码实现与单元测试
- 创臻研究|从“数字代码”到“受保护财产”:虚拟货币的财产属性认定与司法保护路径
- 微软与清华联合推出AI编程模型,性能超越更大规模竞品
- “秒音科技”多次宣称上市,股票代码均与其无关,“黑猫投诉”出现大量消费者投诉!
- 没有代码能理解生命,或爱情,或热情.
- 2026年最值得用的5款AI编程神器,我实测100小时后只推荐这几款
