Linux userptr: 工作原理及软件实现流程 (一)
- 2026-07-06 12:57:32
knowledge base:
CXL如何实现NPU/GPU对CPU内存直接访问与零拷贝:软硬件流程与原理详解
MMU notifier工作原理及其在GPU页表管理中的应用
一、userptr 基本概念
userptr(User Pointer) 是 Linux 内核中一种机制,允许用户空间的虚拟地址指针直接在内核空间使用,特别是在 DMA 操作和图形驱动(如 DRM)中广泛使用。
二、核心工作原理
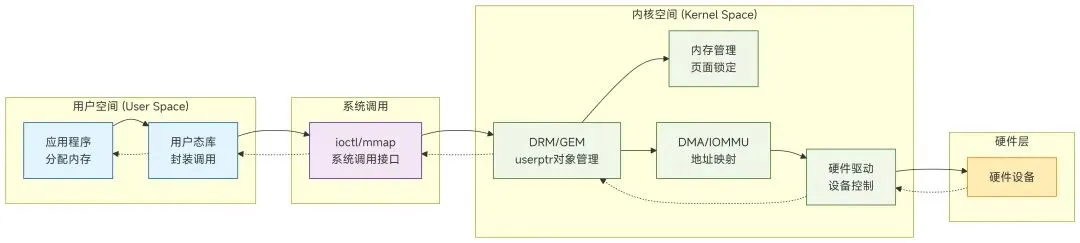
1. 地址空间转换
· 用户空间地址 → 内核可用物理页面
· 通过 get_user_pages() 系列函数实现
· 建立用户页到内核页的映射关系

2. 内存管理关键点
用户虚拟地址 → 用户页表 → 物理页面 → 内核页表
· 不拷贝数据:避免用户空间到内核空间的内存拷贝
· 页面锁定:防止页面被换出(swap out)
· 缓存一致性:需要处理 CPU 和 DMA 缓存同步
三、软件实现流程
sw overview sequence

obj sync sequence
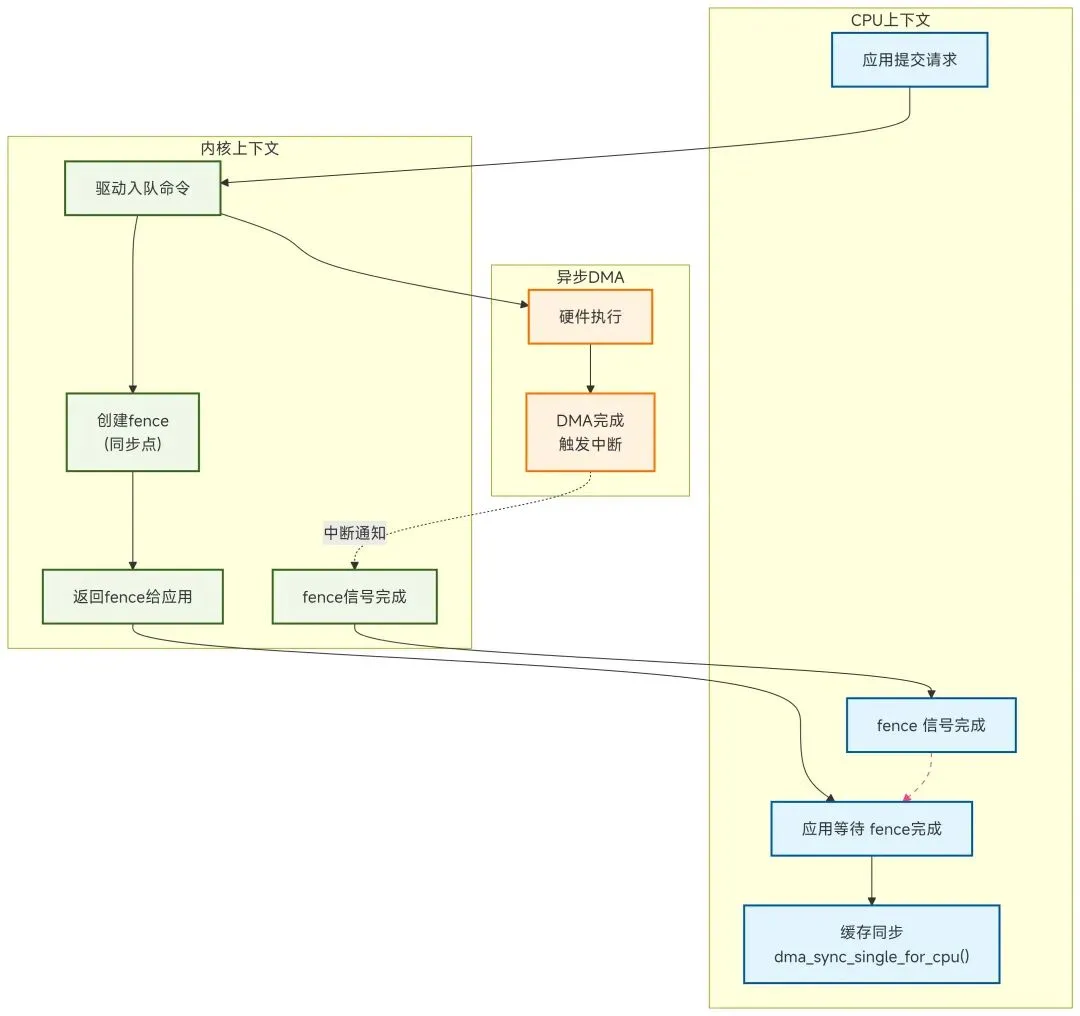
用户空间流程
// 1. 分配用户空间内存
void *user_buffer = malloc(BUFFER_SIZE);
// 2. 填充数据
// ...
// 3. 传递指针给内核(通过ioctl等)
struct drm_prime_handle args = {
.handle = (uintptr_t)user_buffer,
.size = BUFFER_SIZE
};
ioctl(fd, DRM_IOCTL_PRIME_HANDLE_TO_FD, &args);
内核空间驱动实现流程
// 1. 接收用户指针(在驱动ioctl处理函数中)
long my_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
struct user_buffer_info uinfo;
// 从用户空间复制参数
copy_from_user(&uinfo, (void __user *)arg, sizeof(uinfo));
// 2. 获取用户页面
struct page **pages;
int ret = pin_user_pages((unsigned long)uinfo.user_ptr,
uinfo.page_count,
FOLL_WRITE | FOLL_LONGTERM,
pages,
NULL);
// 3. 建立scatterlist(用于DMA)
struct sg_table *sgt;
sgt = kmalloc(sizeof(*sgt), GFP_KERNEL);
ret = sg_alloc_table_from_pages(sgt, pages,
uinfo.page_count,
0, uinfo.size,
GFP_KERNEL);
// 4. DMA映射
struct dma_buf_attachment *attach;
struct sg_table *sgt;
struct dma_buf *dmabuf;
attach = dma_buf_attach(dmabuf, dev);
sgt = dma_buf_map_attachment(attach, DMA_BIDIRECTIONAL);
// 5. 执行DMA操作
dma_addr_t dma_addr = sg_dma_address(sgt->sgl);
// ... 配置DMA引擎 ...
// 6. 同步和清理(重要!)
dma_buf_unmap_attachment(attach, sgt, DMA_BIDIRECTIONAL);
unpin_user_pages(pages, uinfo.page_count);
}
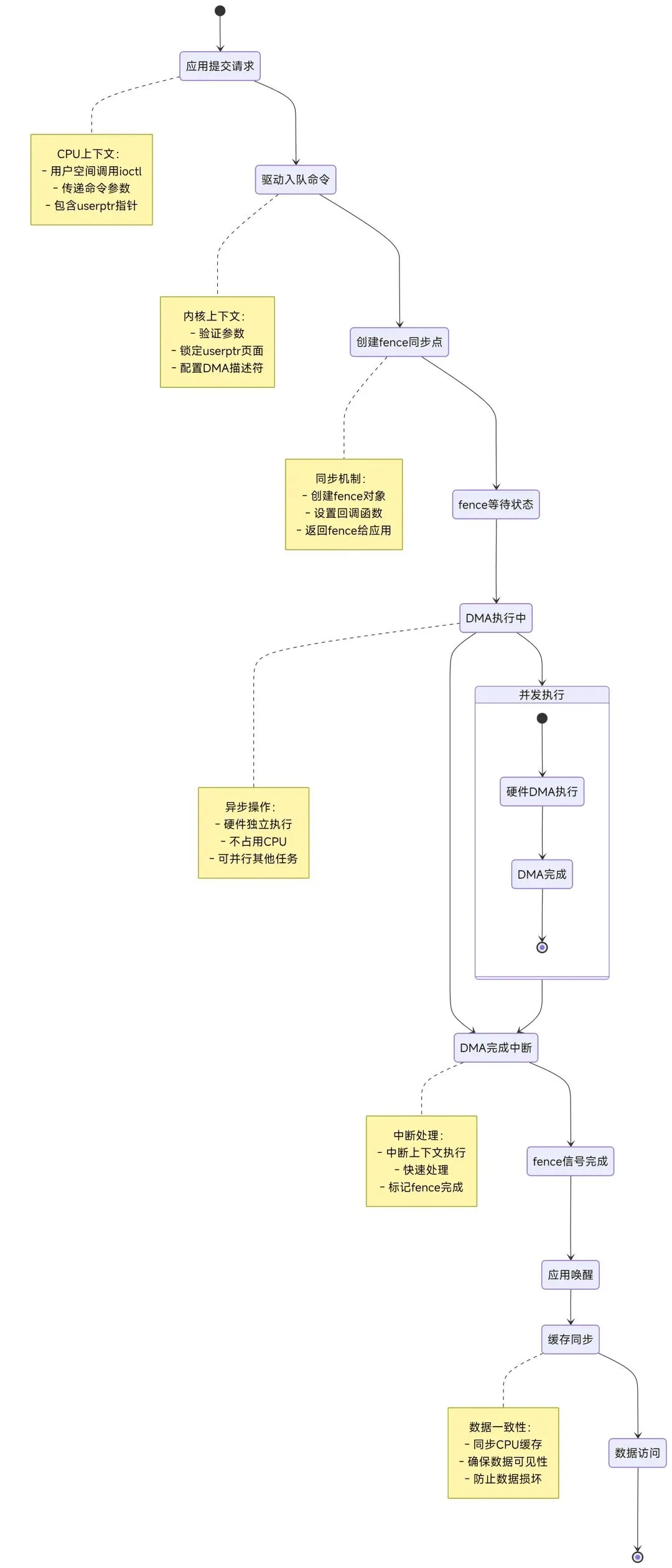
软件状态机
四、关键内核API详解
1. 页面获取函数
// 锁定用户页面(防止交换)
int get_user_pages(unsigned long start,
int nr_pages,
unsigned int gup_flags,
struct page **pages,
struct vm_area_struct **vmas);
// 新版本推荐使用
int pin_user_pages_remote(struct mm_struct *mm,
unsigned long start,
int nr_pages,
unsigned int gup_flags,
struct page **pages,
struct vm_area_struct **vmas,
int *locked);
// 标志位说明:
// FOLL_WRITE - 需要写权限
// FOLL_LONGTERM - 长期pin(需要特殊处理)
// FOLL_GET - 增加页面引用计数
2. DMA映射
// 建立DMA映射
dma_addr_t dma_map_page(struct device *dev,
struct page *page,
size_t offset,
size_t size,
enum dma_data_direction dir);
// 取消映射
void dma_unmap_page(struct device *dev,
dma_addr_t addr,
size_t size,
enum dma_data_direction dir);
五、典型应用场景
1. 图形渲染(DRM驱动)
// DRM GEM userptr 实现示例
static int drm_gem_userptr_ioctl(struct drm_device *dev,
void *data,
struct drm_file *file_priv)
{
struct drm_gem_userptr *args = data;
// 创建userptr对象
obj = drm_gem_userptr_create(dev, args->user_ptr,
args->size, args->flags);
// 导出为DMA-BUF
ret = drm_gem_prime_handle_to_fd(file_priv,
obj->handle,
args->flags,
&args->fd);
}
2. 视频处理(V4L2)
// V4L2 userptr缓冲区
struct v4l2_buffer buf = {
.type = V4L2_BUF_TYPE_VIDEO_CAPTURE,
.memory = V4L2_MEMORY_USERPTR, // 使用userptr模式
.m.userptr = (unsigned long)user_buffer,
.length = buffer_size,
};
// 入队缓冲区
ioctl(fd, VIDIOC_QBUF, &buf);
六、注意事项和限制
1. 性能考量
· 优点:零拷贝,减少内存带宽占用
· 缺点:页面锁定开销,TLB冲刷成本
2. 安全限制
// 用户空间地址必须:
// 1. 来自当前进程的地址空间
// 2. 已经映射的有效区域
// 3. 不能是I/O映射区域
// 检查地址有效性
if (!access_ok(VERIFY_READ, uptr, size))
return -EFAULT;
3. 内存类型限制
· 不能用于大页(huge pages)
· 谨慎处理mlocked内存
· 注意NUMA架构的本地性
七、调试和问题排查
常见问题
1. 页面错误处理
· 需要处理get_user_pages返回的-EFAULT
· 处理页面不在内存中的情况
2. DMA同步
// DMA前同步
dma_sync_single_for_device(dev, dma_addr, size, dir);
// DMA后同步(CPU读取)
dma_sync_single_for_cpu(dev, dma_addr, size, dir);
1. 资源泄漏
· 必须成对调用pin_user_pages/unpin_user_pages
· 及时释放sg_table
调试工具
#bash
# 查看页面状态
cat /proc/<pid>/maps
cat /proc/<pid>/smaps
# 跟踪userptr调用
echo 1 > /sys/kernel/debug/tracing/events/mm/enable
cat /sys/kernel/debug/tracing/trace_pipe
八、现代演进:DMA-BUF + userptr
// 混合使用方案
struct dma_buf *dma_buf_from_userptr(struct device *dev,
void __user *userptr,
size_t size)
{
// 创建userptr后备的dma-buf
struct dma_buf *dmabuf = dma_buf_export(exp_info);
// 实现mmap操作,映射用户页面
exp_info->ops->mmap = userptr_dmabuf_mmap;
return dmabuf;
}
总结
userptr 是 Linux 中实现零拷贝 I/O 的重要机制,其核心是通过页面锁定和映射,让内核和硬件可以直接访问用户空间内存。实现时需要特别注意:
1. 正确使用页面获取/释放API
2. 处理DMA缓存一致性
3. 避免资源泄漏
4. 考虑性能和可移植性
在图形、视频、网络等高性能场景下,userptr能显著提升数据传输效率,但也增加了复杂性和调试难度。