SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents让代码代理学会“扫读”:自适应上下文裁剪 SWE-Pruner
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents让代码代理学会“扫读”:自适应上下文裁剪 SWE-Pruner
Takeaways
- 面向编码代理的“可控裁剪”:通过显式 Goal Hint(目标提示)让裁剪随任务阶段变化,而非固定压缩率或静态困惑度指标。
- 以“行”为单位裁剪:尽量保留代码语法/结构完整性,降低 token 级裁剪对括号、缩进、依赖关系的破坏。
- 轻量级裁剪模型:以 0.6B 规模的 neural skimmer 作为中间件,在多项基准上实现显著 token 节省,同时保持任务指标接近不裁剪基线。
- 多回合代理任务收益不仅在成本:在 SWE-Bench Verified 上,除 token 下降外,交互轮次也出现下降(更少试探性动作)。
问题背景:编码代理的“Context Wall”
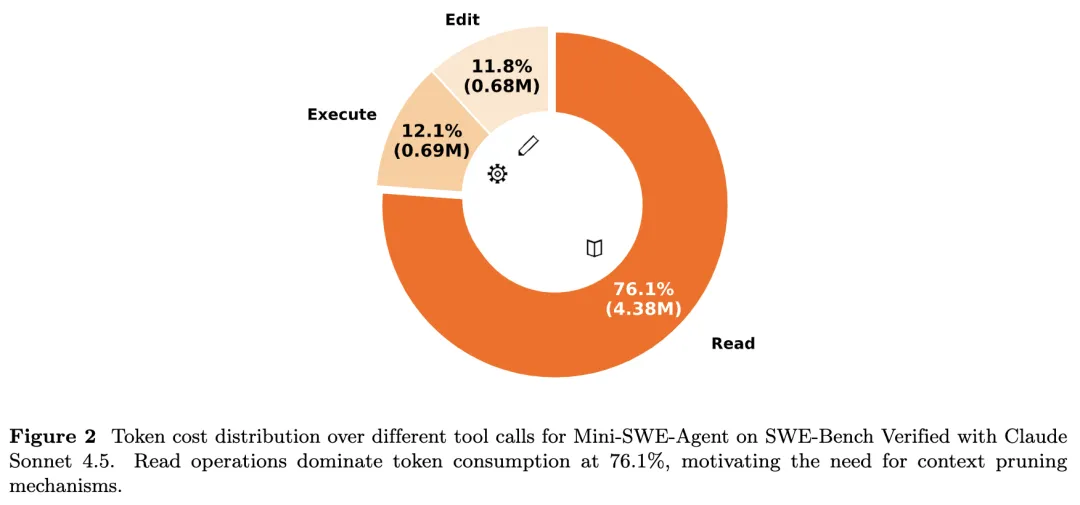
论文关注编码代理在真实仓库中执行检索、阅读文件、运行测试、迭代修复时的上下文累积问题:长上下文带来高 API 成本与推理延迟,并可能引入噪声导致注意力稀释与幻觉。已有压缩方法多为自然语言场景设计,常以困惑度(PPL)等静态指标做 token 级删减,容易破坏代码的语法与逻辑结构;抽象式总结又可能丢失调试所需的细粒度信息(如字符级细节、边界条件)。论文提出需求:压缩必须“任务相关 + 结构友好 + 可随代理目标动态调整”。
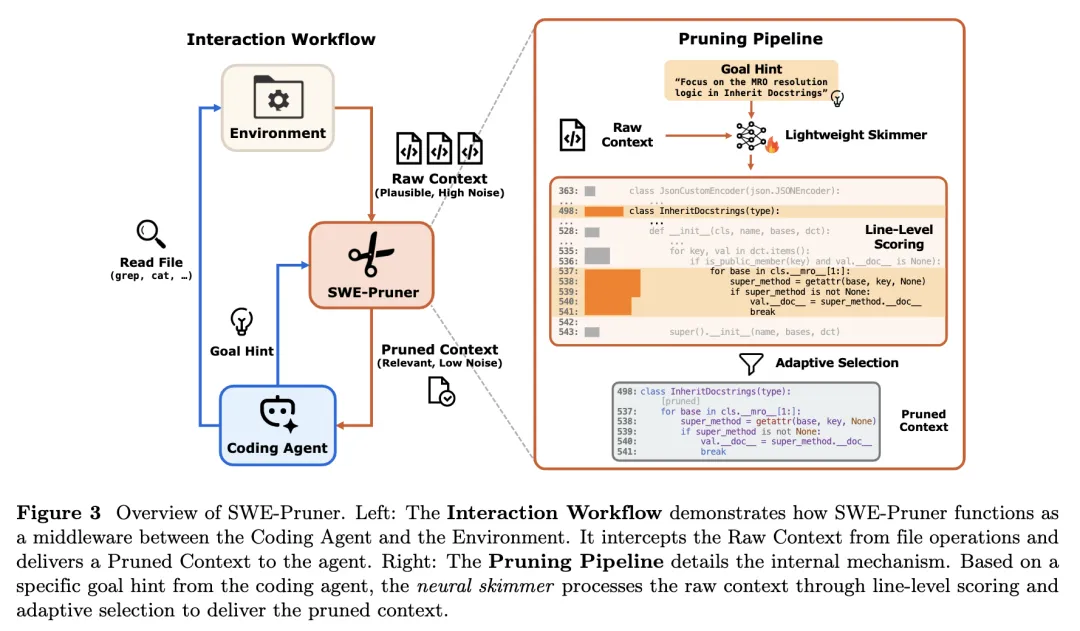
方法概览:SWE-Pruner 作为中间件
SWE-Pruner 将裁剪放在“代理—环境”之间:代理发出 cat/grep 等读取命令后,环境返回的 Raw Context 先被拦截;若提供 Goal Hint,则由 skimmer 进行筛选并输出 Pruned Context,否则直接返回原输出以保持兼容性。核心流程可概括为:
- 代理生成 Goal Hint(完整、自洽的自然语言问题/目标);
- skimmer 对上下文进行打分并按行聚合,基于阈值自适应保留行;
Goal Hint:把“当前要找什么”显式化
论文强调 Goal Hint 是任务自适应的关键:不同于关键词过滤,Goal Hint 被要求是完整问题,用以表达当前步骤的信息需求(例如关注错误处理、MRO 解析等)。实现上,通过给工具接口增加可选参数(如 context_focus_question)将该目标传入裁剪模块:参数为空则绕过裁剪,参数存在则触发裁剪。这种设计意图是以最小改动接入现有代理框架。
Neural Skimmer:行级选择与训练目标
skimmer 采用 0.6B 规模的重排序模型作为骨干(论文选用 Qwen3-Reranker-0.6B),将 token 级分数聚合到行级,以减少“少量高分 token 主导”的不稳定性,并尽量维持代码片段的结构连贯。推理时,若某行聚合得分超过阈值则保留;阈值由查询(Goal Hint)条件化,实现“随任务变化”的裁剪强度。
训练目标由两部分组成:
- 行级保留序列的条件随机场负对数似然(CRF-NLL),用于建模保留/删除的序列依赖:
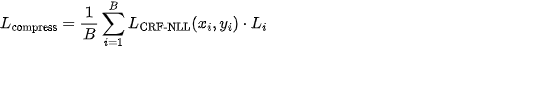 其中 用于序列长度归一化,缓解长上下文导致的过度裁剪偏置。
其中 用于序列长度归一化,缓解长上下文导致的过度裁剪偏置。
- 保留原有文档级相关性打分头,使用均方误差:
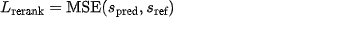 最终:
最终: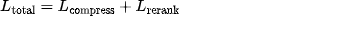
数据构造:合成监督与质量过滤
论文认为“带行级监督且兼顾结构”的数据集缺乏,因此采用 teacher-student 范式构造训练样本:从高质量 GitHub 代码片段采样,使用教师模型(文中为 Qwen3-Coder-30B-A3B-Instruct)合成面向特定功能子集的任务查询,并生成四元组 :查询 、上下文 、行级二值掩码 、文档级相关性分数 。为覆盖真实开发信息需求,查询按九类 agentic task 进行设计(如 Debugging、Feature Addition、Refactoring 等),并用 LLM-as-a-Judge(文中使用 Qwen3-Next-80B-A3B-Thinking)过滤保证标注质量,最终得到约 61,184 条高质量样本。
实验设置与指标
论文在四个基准上评估:
- 单轮长上下文:Long Code Completion、Long Code QA(在 4x 与 8x 约束下评估,Long Code QA 上下文可到 1M token)。
- 多回合代理:SWE-Bench Verified、SWE-QA(分别集成到 Mini SWE Agent 与 OpenHands)。对比方法包含 Full/No Context,上下文压缩基线如 LLMLingua-2、Selective-Context、RAG(UniXcoder 检索)、Long Code Zip;多回合任务还比较抽象式总结(LLM Summarize)。压缩效率使用压缩比:
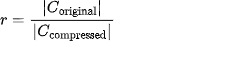 并统计绝对 token 消耗、交互轮次与成本等。
并统计绝对 token 消耗、交互轮次与成本等。
主要结果:省 token 且尽量不伤效果
- 代理任务整体:论文在摘要层面给出,面向代理任务可实现约 23%–54% token 降幅,并保持任务性能“最小影响”;单轮 Long Code QA 上最高有效压缩比达到 14.84。
- SWE-Bench Verified:表格结果显示,在 Mini SWE Agent 上,SWE-Pruner 在保持成功率几乎不变(差异小于约 1%)的同时显著降低 token,并伴随轮次下降;例如 Claude Sonnet 4.5 场景 token 降至约 23.1%,成本约降 26.8%;另一设置下 token 降幅约 38.3%。
- SWE-Bench(压缩策略对比):对比 LLMLingua2、RAG、LLM Summarize、Long Code Zip 等,SWE-Pruner 在更低 token 使用下取得更高成功率(表中显示其成功率最高且 token 最低),论文解释为 token 级裁剪易破坏语法、粗检索易丢失实现细节。
- 单轮任务:在 Long Code Completion 上,8x 约束下 SWE-Pruner 的有效压缩比可达 10.92,并保持 Edit Similarity/Exact Match 相对稳定;在 Long Code QA 上 8x 约束下达到 14.84 且准确率保持在较高水平,整体优于多种基线在相同约束下的表现。
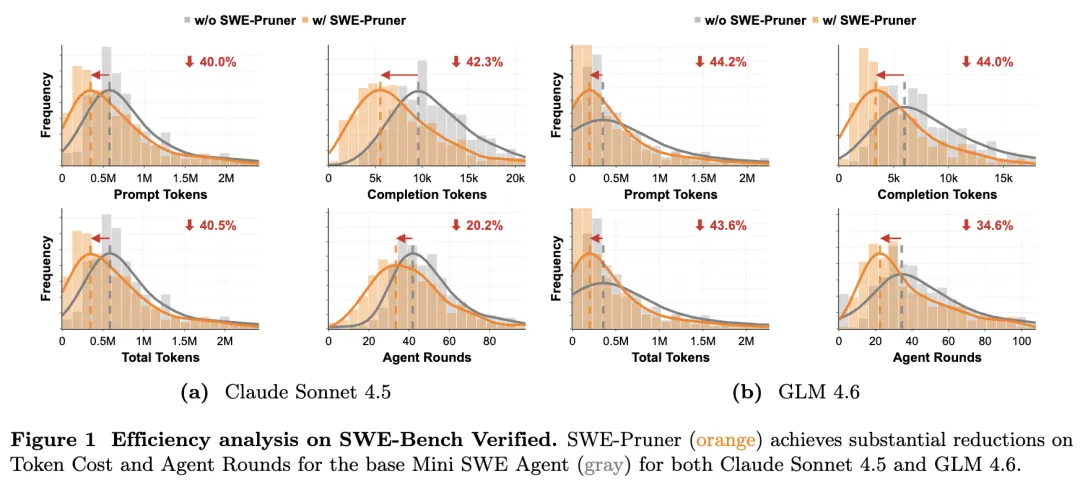
讨论与局限
论文在结论部分强调其贡献是“结构保持的行级裁剪 + 任务条件化阈值 + 可作为中间件接入代理系统”。同时也给出局限:实验实现主要聚焦 Python 仓库,但方法并不依赖 Python 特性;为降低数据泄露风险选择较新的仓库并仍需持续评估;skimmer 带来一定额外延迟但相对 token 节省较小,并可通过蒸馏或 early-exit 进一步优化。