在Linux系统的运维管理中,磁盘I/O性能往往是影响整体表现的关键因素之一。当硬盘的读写速度无法跟上系统需求时,便会形成瓶颈,导致应用程序响应迟滞、数据库查询缓慢,甚至引发服务中断。
本文将系统性地介绍如何诊断此类硬盘性能瓶颈。我们将探讨一系列实用的Linux命令与工具,从实时监控到深度分析,来快速定位问题根源,并列出其中的关键性能指标。
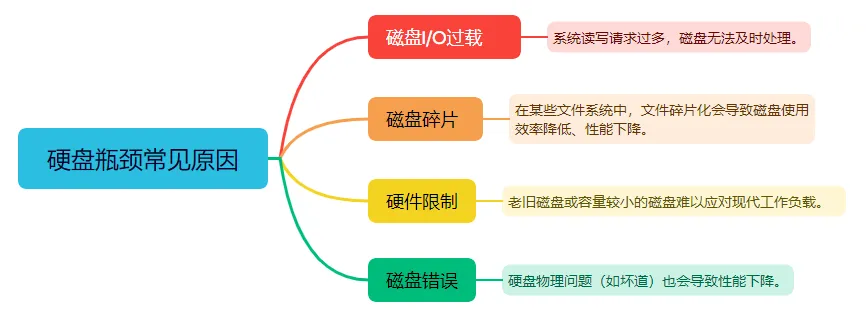
1.什么是硬盘瓶颈?
硬盘瓶颈是指磁盘读写速度无法满足系统需求,通常会导致响应迟缓、系统卡顿,极端情况下甚至引发系统崩溃。
常见原因包括:
- 磁盘I/O过载:系统读写请求过多,磁盘无法及时处理。
- 磁盘碎片:在某些文件系统中,文件碎片化会导致磁盘使用效率降低、性能下降。
- 硬件限制:老旧磁盘或容量较小的磁盘难以应对现代工作负载。
- 磁盘错误:硬盘物理问题(如坏道)也会导致性能下降。
2.如何在Linux中定位硬盘瓶颈?
以下是一些用于诊断硬盘瓶颈的关键命令和工具:
2.1 iostat(输入/输出统计)
iostat 是一款命令行工具,可提供CPU及设备I/O使用情况的统计信息,帮助定位磁盘瓶颈。
下面以扩展模式(-x:代表 eXtended statistics,即扩展统计)显示详细的输入/输出统计信息,并每隔1秒刷新一次数据:
iostat -x 1
[root@backup ~]# iostat -x 1
Linux 3.10.0-1127.el7.x86_64 (backup) 01/27/2026 _x86_64_ (20 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.04 0.00 0.01 0.02 0.00 99.93
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 1.30 4.40 1.17 0.19 20.10 23.38 63.93 0.02 15.94 17.59 5.88 0.75 0.10
dm-0 0.00 0.00 1.94 4.51 12.82 22.68 11.00 0.03 4.38 8.22 2.72 0.07 0.04
avg-cpu: %user %nice %system %iowait %steal %idle
50.83 0.00 2.11 35.31 0.00 11.75
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 5426.00 0.00 2596.00 0.00 49860.00 0.00 38.41 39.71 15.13 15.13 0.00 0.39 100.00
dm-0 0.00 0.00 7108.00 0.00 33792.00 0.00 9.51 57.62 7.69 7.69 0.00 0.14 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
80.19 0.00 3.26 15.25 0.00 1.30
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 3939.00 4.00 2232.00 39.00 39956.00 831.00 35.92 37.93 17.20 17.50 0.00 0.44 100.00
dm-0 0.00 0.00 5337.00 33.00 24088.00 779.00 9.26 50.38 9.30 9.36 0.00 0.19 100.00
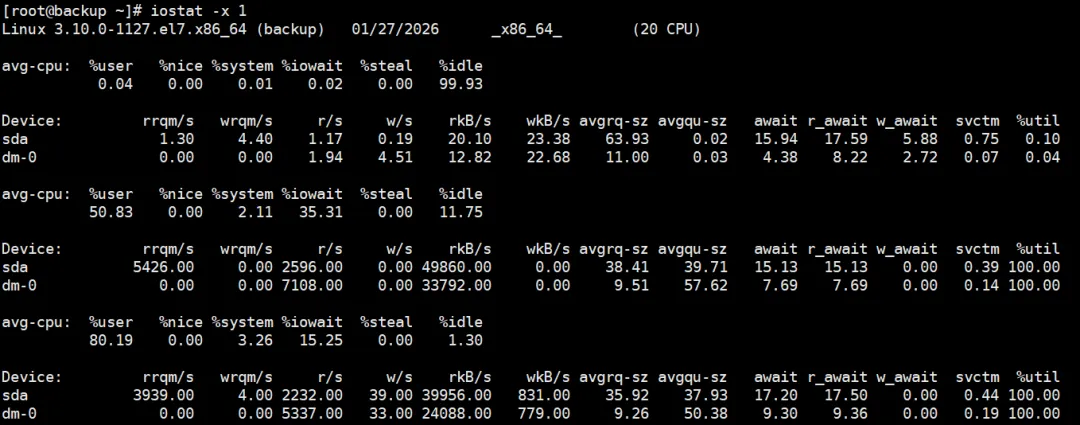
关键指标:
- %util:磁盘处理请求的忙碌时间占比。若持续高于80-90%,表明磁盘存在瓶颈。
- await:I/O请求完成的平均时间(毫秒)。数值越高说明磁盘响应越慢。
- svctm:I/O请求的平均服务时间。数值高表示磁盘响应延迟较长。
2.2 iotop(实时I/O监控)
iotop 可实时显示各进程的磁盘活动情况,便于识别占用过高磁盘带宽的进程。
iotop
关键指标:
- Read/Write(读写量):关注读写值较高的进程,这些进程可能导致磁盘瓶颈。
- IO Priority(I/O优先级):检查是否有进程占用过多I/O资源。可通过
ionice 调整进程优先级以管理其对磁盘I/O的影响。
2.3 df(磁盘空间检查)
df 命令显示所有已挂载文件系统的磁盘使用情况。磁盘接近满载(尤其是根分区或home分区)会显著拖慢系统。
df -h
[root@backup ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 16G 0 16G 0% /dev
tmpfs 16G 0 16G 0% /dev/shm
tmpfs 16G 22M 16G 1% /run
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/mapper/centos-root 50G 39G 12G 77% /
/dev/sda2 1016M 156M 860M 16% /boot
/dev/sda1 200M 12M 189M 6% /boot/efi
/dev/sda3 7.3T 65G 7.2T 1% /data
tmpfs 3.2G 12K 3.2G 1% /run/user/42
tmpfs 3.2G 0 3.2G 0% /run/user/0
建议确保磁盘使用率(特别是 / 和 /home 目录)不超过85-90%,否则临时文件和磁盘操作可能因空间不足而变慢。
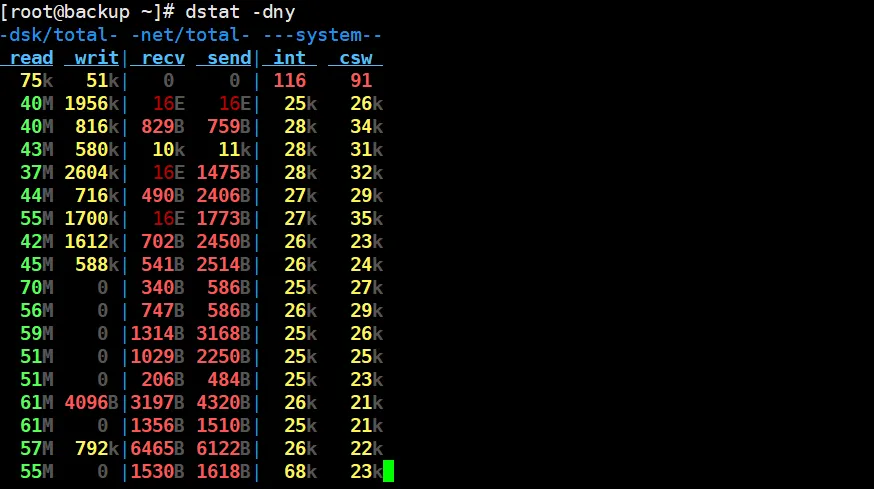
2.4 dstat(综合系统资源监控)
dstat 是一款多功能资源监控工具,可实时提供包括磁盘I/O在内的系统性能概览。
dstat -dny
其中-dny参数的含义如下表:
| 参数 | 全称/含义 | 监控内容 | 输出列 |
|---|
-d | --disk | | |
-n | --net | | |
-y | --sys | | |
示例如下:
[root@backup ~]# dstat -dny
-dsk/total- -net/total- ---system--
read writ| recv send| int csw
75k 51k| 0 0 | 116 91
40M 1956k| 16E 16E| 25k 26k
40M 816k| 829B 759B| 28k 34k
43M 580k| 10k 11k| 28k 31k
37M 2604k| 16E 1475B| 28k 32k
44M 716k| 490B 2406B| 27k 29k
55M 1700k| 16E 1773B| 27k 35k
42M 1612k| 702B 2450B| 26k 23k
45M 588k| 541B 2514B| 26k 24k
70M 0 | 340B 586B| 25k 27k
56M 0 | 747B 586B| 26k 29k
59M 0 |1314B 3168B| 25k 26k
51M 0 |1029B 2250B| 25k 25k
51M 0 | 206B 484B| 25k 23k
61M 4096B|3197B 4320B| 26k 21k
61M 0 |1356B 1510B| 25k 21k
57M 792k|6465B 6122B| 26k 22k
55M 0 |1530B 1618B| 68k 23k
55M 0 |7301B 6795B| 59k 23k
53M 0 |5724B 6292B| 48k 26k
70M 0 |4662B 4379B| 52k 23k
55M 0 |4855B 5124B| 26k 28k
50M 2416k| 16E 16E| 26k 27k
37M 3316k| 560B 748B| 26k 26k
31M 264k|1501B 2627B| 25k 20k
76M 276k| 772B 758B| 27k 23k
关键指标:
- 磁盘读写 ( read / writ ):观察是否存在持续的高峰值。这是识别高磁盘I/O活动的首要信号。例如,持续的几十MB/s的读取可能表明正在进行批量数据操作或存在缓存未命中。
- 系统中断与切换 ( int / csw ):高磁盘I/O通常会引发大量的中断( int )和上下文切换( csw )。这两个数值异常偏高,可作为磁盘I/O已成为系统主要负载的强关联性佐证。
重要提示: dstat -dny 擅长揭示现象(“磁盘非常忙”),但无法直接量化瓶颈影响(“忙到多慢”)。发现异常后,必须使用 iostat -x 1 来查看 await (I/O等待时间) 和 %util (利用率) 等关键性能指标,以最终确认瓶颈及其严重程度。
2.5 sar(系统活动报告)
sar 命令能收集、报告并保存系统活动信息,非常适合进行历史性能分析。
示例:查看磁盘活动,时间间隔为1秒,采样5次:
[root@backup ~]# sar -d 1 5
Linux 3.10.0-1127.el7.x86_64 (backup) 01/27/2026 _x86_64_ (20 CPU)
11:05:24 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:05:25 AM dev8-0 354.00 10072.00 0.00 28.45 0.43 1.21 0.90 31.70
11:05:25 AM dev253-0 174.00 1392.00 0.00 8.00 0.29 1.67 0.67 11.70
11:05:25 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:05:26 AM dev8-0 699.00 57504.00 0.00 82.27 1.01 1.43 0.72 50.00
11:05:26 AM dev253-0 387.00 3096.00 0.00 8.00 0.68 1.76 0.73 28.30
11:05:26 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:05:27 AM dev8-0 946.00 80944.00 0.00 85.56 2.19 2.29 0.90 84.90
11:05:27 AM dev253-0 402.00 3216.00 0.00 8.00 1.28 3.18 1.21 48.70
11:05:27 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:05:28 AM dev8-0 859.00 25144.00 5840.00 36.07 2.42 2.85 1.00 85.90
11:05:28 AM dev253-0 771.00 6032.00 784.00 8.84 2.58 3.36 0.99 76.70
11:05:28 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:05:29 AM dev8-0 243.00 4920.00 1664.00 27.09 0.26 1.04 0.84 20.30
11:05:29 AM dev253-0 135.00 1272.00 560.00 13.57 0.13 0.79 0.80 10.80
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev8-0 620.20 35716.80 1500.80 60.01 1.26 2.03 0.88 54.56
Average: dev253-0 373.80 3001.60 268.80 8.75 0.99 2.65 0.94 35.24
[root@backup ~]#
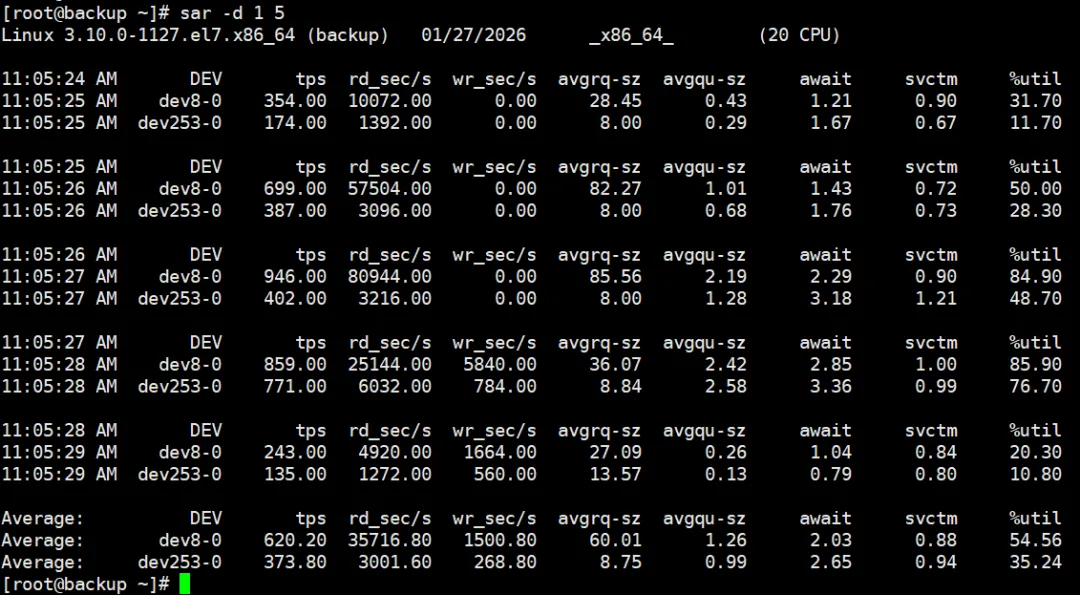
关键指标:
- %util:磁盘利用率。持续高于80-90%表明磁盘存在瓶颈。
- avgqu-sz:平均队列长度。数值持续大于1表示请求开始排队。
- await:平均I/O等待时间(毫秒)。数值高表示应用感知到延迟。
提示:rd_sec/s和wr_sec/s表示每秒读写扇区数,将数值除以2可估算为KB/s(如10000 rd_sec/s ≈ 5MB/s)
2.6 smartctl(S.M.A.R.T.监控)
smartctl 用于查询硬盘的S.M.A.R.T.(自监测、分析与报告技术)状态,帮助检测磁盘物理问题(如坏道或硬件故障)。
对于普通硬盘,直接用下面命令查看:
smartctl -a /dev/sda
对于RAID卡,需要先用smartctl --scan命令找到RAID卡中的编号:
[root@backup ~]# smartctl --scan
/dev/sda -d scsi # /dev/sda, SCSI device
/dev/bus/0 -d megaraid,1 # /dev/bus/0 [megaraid_disk_01], SCSI device
/dev/bus/0 -d megaraid,2 # /dev/bus/0 [megaraid_disk_02], SCSI device
/dev/bus/0 -d megaraid,3 # /dev/bus/0 [megaraid_disk_03], SCSI device
[root@backup ~]#
然后分别再查指定的硬盘,如第一块硬盘,编号为1:
[root@backup ~]# smartctl -a -d megaraid,1 /dev/bus/0
smartctl 7.0 2018-12-30 r4883 [x86_64-linux-3.10.0-1127.el7.x86_64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Device Model: ST4000NM016A-2HZ130
Serial Number: WS23K68W
LU WWN Device Id: 5 000c50 0ecf2b213
Add. Product Id: DELL(tm)
Firmware Version: CAJC
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Size: 512 bytes logical/physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: Not in smartctl database [for details use: -P showall]
ATA Version is: ACS-4 (minor revision not indicated)
SATA Version is: SATA 3.3, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue Jan 27 11:21:16 2026 CST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Status not supported: ATA return descriptor not supported by controller firmware
SMART overall-health self-assessment test result: PASSED
Warning: This result is based on an Attribute check.
……
关键指标:
- Reallocated_Sector_Ct(重分配扇区数):因错误而重新映射的扇区数量。数值过高可能预示磁盘即将故障。
- Current_Pending_Sector(待处理扇区):等待重映射的不稳定扇区。出现非零值应立即备份数据。
- Power_On_Hours(通电时间):硬盘已运行时间,评估使用寿命。
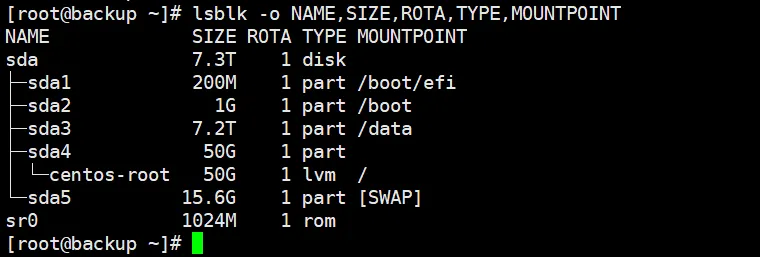
2.7 lsblk(列出块设备)
lsblk 可列出系统中的所有块设备(如硬盘和分区),便于快速了解存储设备概况。
[root@backup ~]# lsblk -o NAME,SIZE,ROTA,TYPE,MOUNTPOINT
NAME SIZE ROTA TYPE MOUNTPOINT
sda 7.3T 1 disk
├─sda1 200M 1 part /boot/efi
├─sda2 1G 1 part /boot
├─sda3 7.2T 1 part /data
├─sda4 50G 1 part
│ └─centos-root 50G 1 lvm /
└─sda5 15.6G 1 part [SWAP]
sr0 1024M 1 rom
[root@backup ~]#
关键信息:
- 通常SSD性能优于HDD,过度使用的机械硬盘易成为性能瓶颈
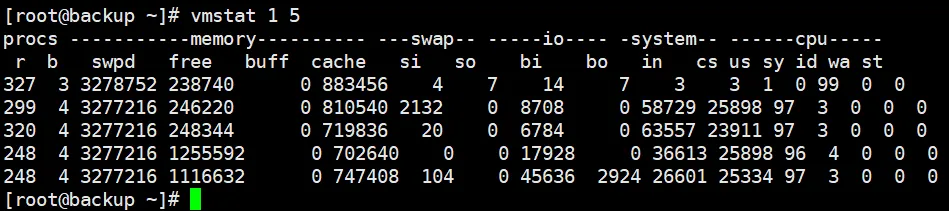
2.8 vmstat(虚拟内存统计)
vmstat 主要显示内存使用情况,同时也能提供磁盘I/O操作和系统交换内存的洞察。
[root@backup ~]# vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
327 3 3278752 238740 0 883456 4 7 14 7 3 3 1 0 99 0 0
299 4 3277216 246220 0 810540 2132 0 8708 0 58729 25898 97 3 0 0 0
320 4 3277216 248344 0 719836 20 0 6784 0 63557 23911 97 3 0 0 0
248 4 3277216 1255592 0 702640 0 0 17928 0 36613 25898 96 4 0 0 0
248 4 3277216 1116632 0 747408 104 0 45636 2924 26601 25334 97 3 0 0 0
[root@backup ~]#
关键指标:
- si/so(swap in/swap out):交换换入/换出。若数值较高,表明系统正在发生交换,可能因内存不足引起。
- bi/bo(blocks in/blocks out):块读入/写出。高值表示磁盘I/O活跃。
- wa(I/O wait):CPU等待I/O的时间百分比。但注意:当进程因I/O而休眠时,此值可能为0,需结合bi/bo判断。
【总结】
硬盘瓶颈可能由磁盘I/O过载、硬件限制或磁盘错误等多种因素引起。通过本文介绍的工具和命令,可以有效诊断Linux系统中的磁盘相关问题。
iostat、iotop 和 dstat 等监控工具能提供宝贵的磁盘性能洞察,而 smartctl 等工具则有助于发现潜在的硬件故障。
建议定期监控磁盘性能(尤其是在生产环境中),以确保系统始终处于最佳状态。及早发现并解决瓶颈问题,能有效避免性能下降和系统停机风险。
以下是上面8个命令工具的总结表,这个表格可以作为运维人员的速查手册,帮助快速选择合适的工具解决不同类型的磁盘性能问题。
| 命令工具 | 主要用途 | 关键指标 | 使用场景 | 常用参数示例 |
|---|
| | %util (利用率)
await (响应时间)
svctm (服务时间) | | iostat -x 1 |
| | Read/Write (读写量)
IO Priority (I/O优先级) | | sudo iotop |
| | Use% | | df -h |
| | read/writ (磁盘读写)
int/csw (中断/上下文切换) | | dstat -dny |
| | %util (利用率)
avgqu-sz (队列长度)
await (响应时间)
tps (每秒事务数) | | sar -d 1 5 |
| | Reallocated_Sector_Ct (重分配扇区) Power_On_Hours (通电时间) Temperature_Celsius (温度) | | smartctl -a /dev/sda
smartctl -a -d megaraid,N /dev/sda |
| | ROTA (旋转类型)
SIZE (容量)
MOUNTPOINT (挂载点) | | lsblk -o NAME,SIZE,ROTA,TYPE,MOUNTPOINT |
| | si/so (交换换入/换出)
bi/bo (块读入/写出)
wa (I/O等待) | | vmstat 1 5 |
# 表格使用建议:
(1)快速定位问题:
(2)日常巡检:
- 每天检查
df -h 和 smartctl -H /dev/sda
(3)深度排查:
- 性能问题:
iostat → iotop → sar - 健康问题:
smartctl → lsblk → 硬件诊断