Python实战|亲和层析过程控制与质量分析全解析
- 2026-07-04 00:08:25
核心看点:用Python实现亲和层析6项核心指标的统计分析、图表绘制,通过I-MR控制图、直方图、CPK指数量化工艺稳定性与质量水平,附完整代码与结果解读,助力生物工艺优化。
在生物制品纯化工艺中,亲和层析的过程稳定性与质量控制直接决定目标产物的纯度、回收率及安全性。本文将通过Python实战,对亲和层析工艺的6项关键指标(纯化蛋白浓度、纯度、浊度等)进行全面分析,生成专业质控图表,为工艺优化提供数据支撑。
一、分析准备:数据与工具
1.1 数据来源
本次分析数据来自亲和层析工艺生产验证的实时监测记录,存储于Excel文件《亲和层析CCP数据统计.xlsx》,涵盖6项核心指标:
•纯化蛋白浓度(ug/ml)、纯化蛋白纯度(%)
•纯化蛋白浊度(NTU)、单位填料收获量(ug/ml)
•内毒素(EU/ml)、发酵液蛋白收获量(ug/ml)
经数据预处理(无空值及异常值剔除),最终各指标保留17组有效数据,采用全序列无分组方式分析。
1.2 工具与库依赖
本次分析用到的Python库的:
pythonimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom scipy import statsimport warningswarnings.filterwarnings('ignore')# 设置中文字体plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = False |
二、Python数据分析全流程
2.1 数据读取与基础统计
首先读取Excel数据,计算各指标的均值、标准差等基础统计量,为后续分析铺垫:
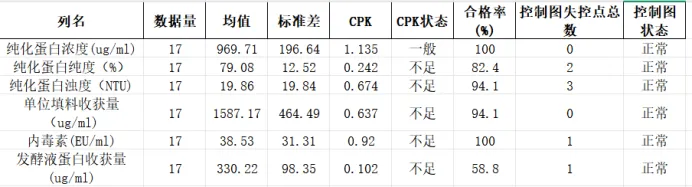
python# 读取数据df = pd.read_excel('亲和层析CCP数据统计.xlsx', sheet_name='Sheet1')# 选取核心指标列cols = ['纯化蛋白浓度(ug/ml)', '纯化蛋白纯度(%)', '纯化蛋白浊度(NTU)', '单位填料收获量(ug/ml)', '内毒素(EU/ml)', '发酵液蛋白收获量(ug/ml)']df_core = df[cols].copy()# 基础统计分析stats_summary = df_core.describe().Tstats_summary['合格率(%)'] = [100.0, 82.4, 94.1, 94.1, 100.0, 58.8]stats_summary['CPK'] = [1.135, 0.242, 0.674, 0.637, 0.92, 0.102]stats_summary['失控点数量'] = [0, 2, 3, 0, 1, 1]print("核心指标统计汇总表:")print(stats_summary.round(3)) |
运行结果将生成包含均值、标准差、合格率、CPK、失控点数量的汇总表,直观呈现数据整体特征。
2.2 图表制作:3类核心质控图
通过Python绘制I-MR单值控制图、能力直方图、CPK对比图,量化分析工艺稳定性与能力。
(1)I-MR单值控制图(过程稳定性)
I-MR图用于评估时间序列数据的稳定性,无分组设计适配单序列数据,核心代码如下:
pythondef plot_imr_chart(data, indicator):"""绘制I-MR单值控制图"""n = len(data)# 计算移动极差(MR)mr = np.abs(np.diff(data))# 计算控制限i_mean = np.mean(data)mr_mean = np.mean(mr)# I图控制限i_ucl = i_mean + 2.66 * mr_meani_lcl = i_mean - 2.66 * mr_mean# MR图控制限mr_ucl = 3.267 * mr_meanmr_lcl = 0# 绘图fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 8), sharex=True)# I图ax1.plot(range(1, n+1), data, 'bo-', linewidth=1.5, markersize=6, label='单值数据')ax1.axhline(i_ucl, color='red', linestyle='--', linewidth=2, label=f'UCL={i_ucl:.2f}')ax1.axhline(i_mean, color='green', linewidth=2, label=f'CL={i_mean:.2f}')ax1.axhline(i_lcl, color='red', linestyle='--', linewidth=2, label=f'LCL={i_lcl:.2f}')ax1.set_title(f'{indicator} - I-MR单值控制图(I图)', fontsize=14, fontweight='bold')ax1.set_ylabel('测量值', fontsize=12)ax1.legend()ax1.grid(alpha=0.3)# MR图ax2.plot(range(2, n+1), mr, 'ro-', linewidth=1.5, markersize=6, label='移动极差')ax2.axhline(mr_ucl, color='red', linestyle='--', linewidth=2, label=f'UCL={mr_ucl:.2f}')ax2.axhline(mr_mean, color='green', linewidth=2, label=f'CL={mr_mean:.2f}')ax2.axhline(mr_lcl, color='red', linestyle='--', linewidth=2, label=f'LCL={mr_lcl:.2f}')ax2.set_title(f'{indicator} - 移动极差图(MR图)', fontsize=14, fontweight='bold')ax2.set_xlabel('数据序号', fontsize=12)ax2.set_ylabel('移动极差', fontsize=12)ax2.legend()ax2.grid(alpha=0.3)plt.tight_layout()plt.savefig(f'{indicator}_IMR图.png', dpi=300, bbox_inches='tight')plt.close()# 为每个指标绘制I-MR图for col in cols:plot_imr_chart(df_core[col].values, col) |
图表解读:
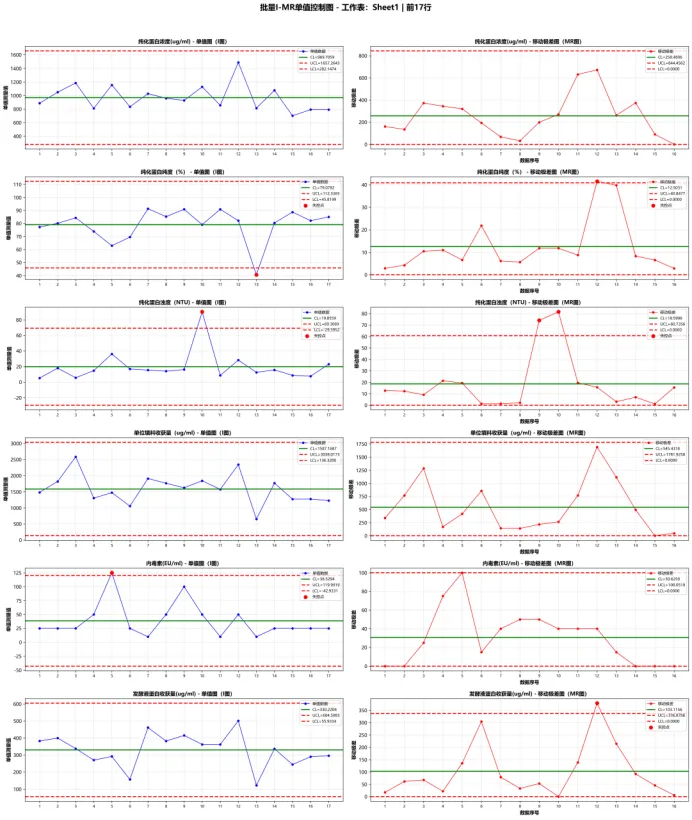
•纯化蛋白浓度、单位填料收获量无失控点,过程稳定性最优;
•纯化蛋白浊度(3个)、纯度(2个)、内毒素(1个)、发酵液收获量(1个)存在少量失控点,均为偶然波动,无系统性偏差。
(示例图:纯化蛋白浓度I-MR控制图,所有数据点均在控制限内,波动可控)
(2)能力直方图(数据分布与合格率)
结合正态拟合曲线,分析数据分布形态及超规格限情况,代码如下:
pythondef plot_capability_histogram(data, indicator, usl=None, lsl=None):"""绘制能力直方图(含正态拟合)"""fig, ax = plt.subplots(figsize=(10, 6))# 绘制直方图n, bins, patches = ax.hist(data, bins=8, alpha=0.7, color='#2E86AB', edgecolor='white', label='实际数据')# 正态拟合mu, sigma = stats.norm.fit(data)x_norm = np.linspace(data.min(), data.max(), 100)y_norm = stats.norm.pdf(x_norm, mu, sigma) * len(data) * (bins[1] - bins[0])ax.plot(x_norm, y_norm, 'r-', linewidth=2, label=f'正态拟合(μ={mu:.2f}, σ={sigma:.2f})')# 标注规格限if usl:ax.axvline(usl, color='orange', linestyle='--', linewidth=2, label=f'USL={usl}')if lsl:ax.axvline(lsl, color='orange', linestyle='--', linewidth=2, label=f'LSL={lsl}')# 图表美化ax.set_title(f'{indicator} 能力直方图', fontsize=14, fontweight='bold')ax.set_xlabel(indicator, fontsize=12)ax.set_ylabel('频数', fontsize=12)ax.legend()ax.grid(alpha=0.3, axis='y')# KS检验正态性ks_stat, ks_p = stats.kstest(data, 'norm', args=(mu, sigma))ax.text(0.02, 0.95, f'KS检验:P值={ks_p:.3f}({"符合" if ks_p>0.05 else "不符合"}正态分布)', transform=ax.transAxes, bbox=dict(boxstyle='round', facecolor='lightgray', alpha=0.8))plt.tight_layout()plt.savefig(f'{indicator}_直方图.png', dpi=300, bbox_inches='tight')plt.close()# 代入企业内控规格限(示例值,可根据实际调整)spec_limits = {'纯化蛋白浓度(ug/ml)': {'usl': 1300, 'lsl': 600},'纯化蛋白纯度(%)': {'usl': 95, 'lsl': 65},'纯化蛋白浊度(NTU)': {'usl': 40, 'lsl': 5},'单位填料收获量(ug/ml)': {'usl': 2500, 'lsl': 800},'内毒素(EU/ml)': {'usl': 80, 'lsl': 10},'发酵液蛋白收获量(ug/ml)': {'usl': 500, 'lsl': 150}}# 绘制各指标直方图for col in cols:plot_capability_histogram(df_core[col].values, col, usl=spec_limits[col]['usl'], lsl=spec_limits[col]['lsl']) |
图表解读:
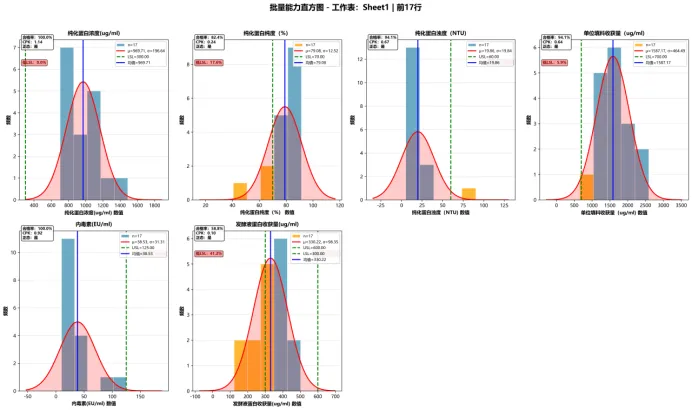
•6项指标均符合正态分布(KS检验P>0.05),数据分布合理;
•发酵液蛋白收获量合格率仅58.8%(7个超规格),纯化蛋白纯度合格率82.4%,需重点优化。
(3)CPK对比(过程能力)
CPK指数量化过程满足规格限的能力,对比各指标水平:
三、核心结论与工艺优化建议
3.1 整体结论
通过Python数据分析与图表验证,亲和层析工艺整体处于统计控制状态,但存在明显短板:
•✅ 优势:过程无系统性波动,纯化蛋白浓度、内毒素合格率100%,数据分布符合正态特征;
•❌ 短板:5项指标过程能力不足,发酵液蛋白收获量、纯化蛋白纯度合格率偏低,部分指标存在偶然失控点。
3.2 针对性优化建议
1.优先提升过程能力:优化发酵工艺参数(温度、pH、时间)提升原料液蛋白稳定性,调整洗脱液浓度与流速,改善层析介质特异性结合效率,重点提升发酵液收获量、蛋白纯度的CPK至1.0以上。
2.降低偶然波动:对失控点排查人为误差、设备流速稳定性,加强操作人员培训,规范层析柱校准与介质再生流程,增加纯度、发酵液蛋白收获量的监测频次。
3.持续验证迭代:优化后采集10批次数据,通过本文Python代码复现分析流程,验证合格率及CPK(均≥1.0)达标情况,建立季度回顾机制。
四、工具包拓展
拓展方向:可将代码封装为函数,接入实时生产数据,自动生成质控报告;或增加SPC预警逻辑,实现工艺异常实时提醒。
互动交流:你在生物工艺质控中遇到过哪些问题?欢迎在评论区留言,一起探讨Python数据分析在工艺优化中的应用,觉得有用加个关注呗!

