Linux 性能测试实操指南:命令 + 负载模拟 + 内存泄漏判定,测试工程师直接用(下)
- 2026-07-06 10:46:58


上一篇文章《Linux 性能测试实操指南:命令 + 负载模拟 + 内存泄漏判定,测试工程师直接用》中为大家介绍了常见的性能测试命令有一些有关内存,CPU,网速,磁盘,温度,cache等等的指标。
本文将继续为大家介绍如何自己编写脚本查看性能。
(11)自己编写脚本查看性能
1
系统态与用户态的shell脚本
以下是我自己编写的linux脚本,循环增加100万次
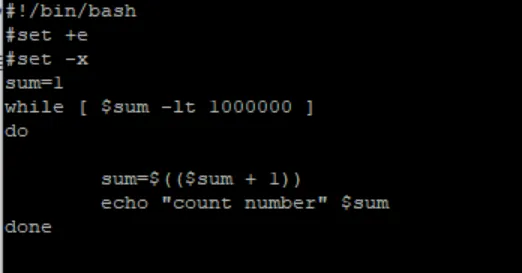
命令 vmstat 1
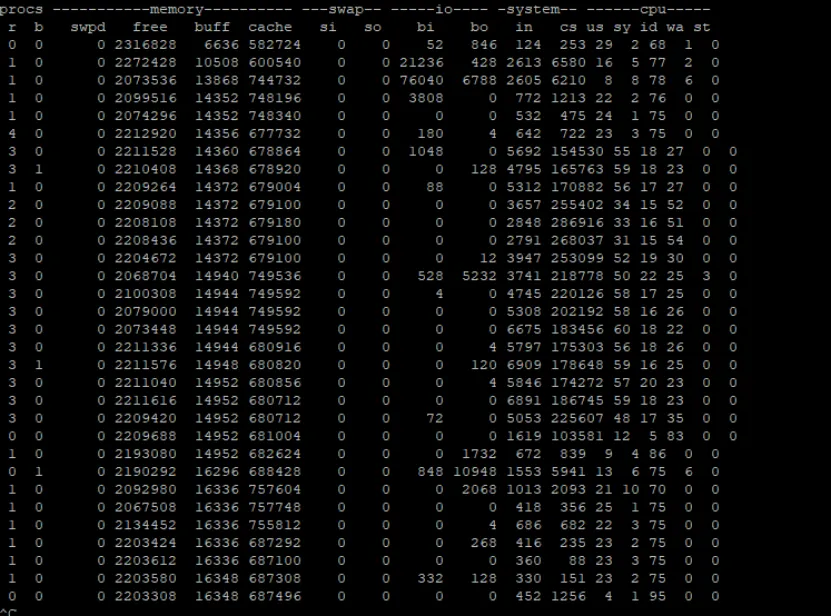
发现, sy和us 都是有变大的趋势,us > sy, 但是free变小不是很明显, 内存没有明显的占用,in 和cs 都有明显的变大趋势, id 明显变小, 说明占用的cpu非常多。
进程等待数量也变多了,IO等待-wa 数量不变。
2
系统态的shell脚本
#!/bin/bashset +eset -xmkdir -p dirwhile truedormdir -p dirmkdir -p dirif [ $? -eq 0 ]; thenecho "Directory changed successfully."elseecho "Failed to change directory."fidone
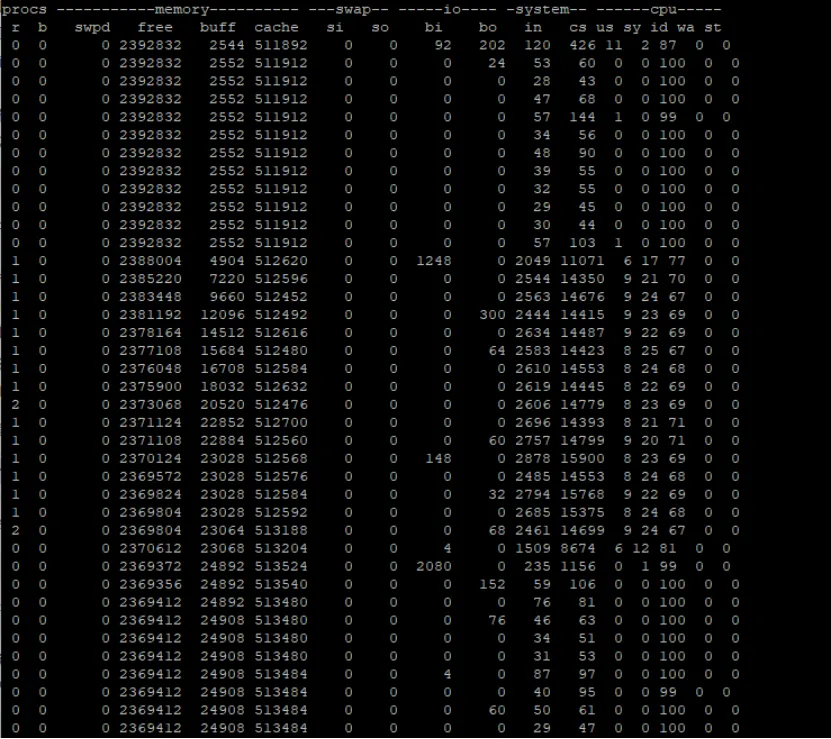
发现, sy有明显的变大的趋势,free有明显的变小趋势, in 和cs 都有明显的变大趋势, id 明显变小, 说明占用的cpu非常多。
进程等待数量维持在1,说明几乎没有什么进程等待。
运行结束之后,内存没有恢复,因此这个程序存在内存泄漏的现象。
运行 命令 echo 3 > /proc/sys/vm/drop_caches 之后,内存明显地恢复了。
3
纯用户态的shell脚本
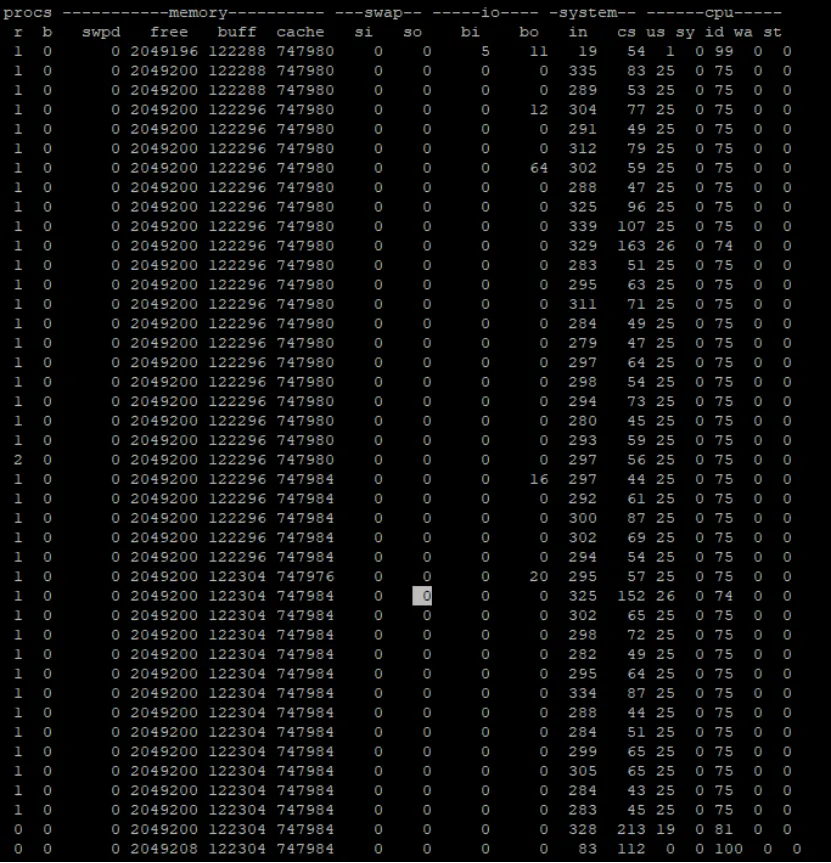
#!/bin/bash#set +e#set -x#纯用户态while truedosum=$(($sum + 1))done
(echo 命令是系统态的,将前面第一个shell脚本中的echo 命令取消之后,剩下的就都是用户态的,从这个例子来看我们发现计算类的命令是用户态的,没有内存泄漏, 用pidstat 命令检查,几乎都是非自愿上下文切换)
4
有关各种收集日志信息的对于系统态还是用户态的分析
【系统态和用户态都较少】-以下命令将 2>&1 放在最后 ,就是将不管是错误输出还是标准输出都保存在 log.txt 中 ,前台不显示日志
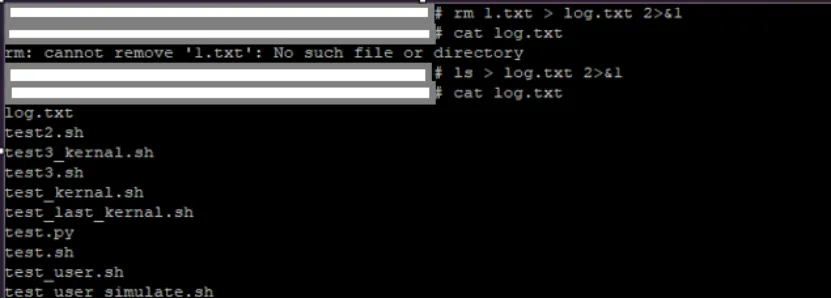
以下是只存储log的shell 脚本
#!/bin/bashwhile truedols > log.txt 2>&1done
以下是只存储log内容的性能情况
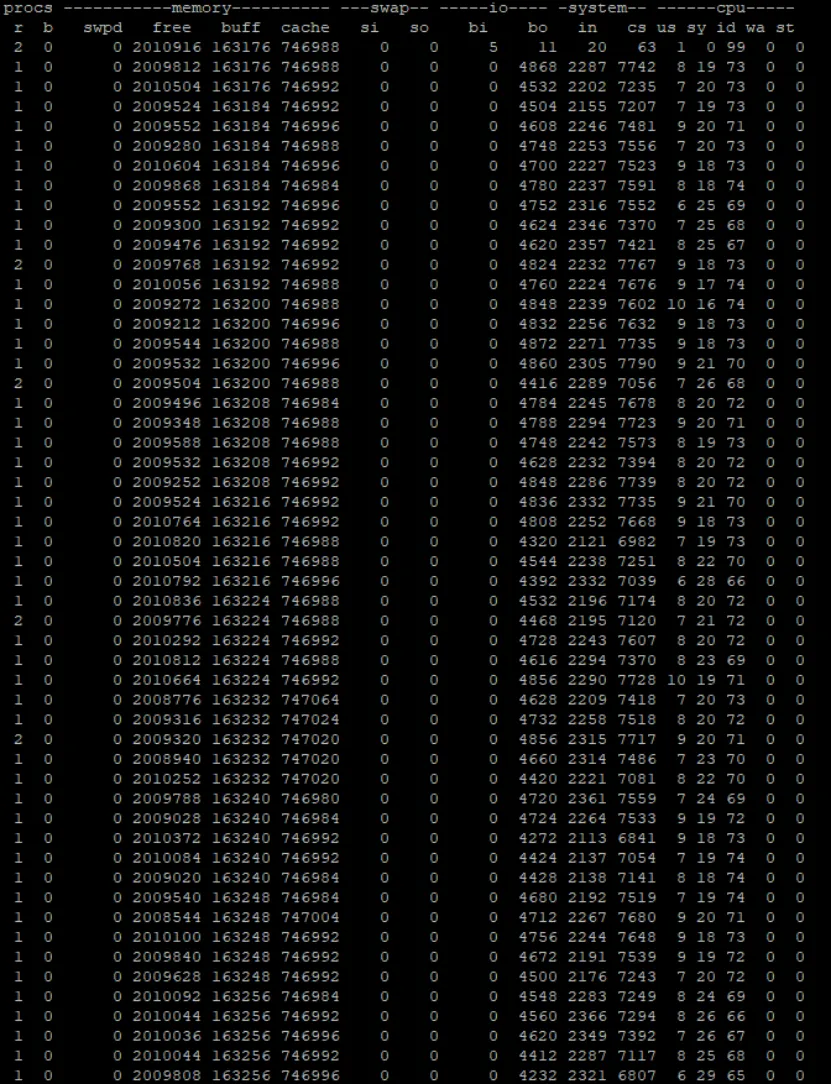
【系统态与用户态显著增加】
以下命令使用 command 2>&1 | tee log.txt 则无论是错误输出还是标准输出,都在前台以及 log.txt 中显示
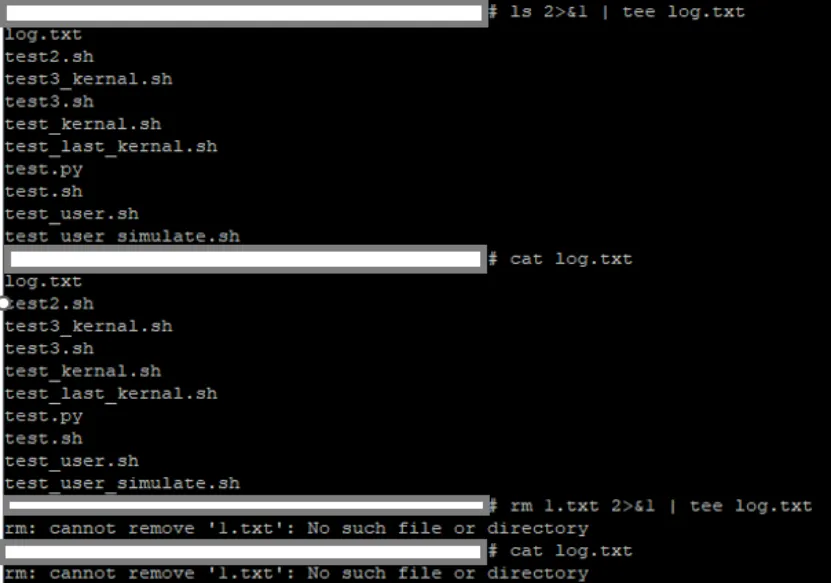
以下是前台输出并且同时存储log内容的shell 脚本
#!/bin/bashwhile truedols 2>&1 | tee log.txtdone
以下是前台输出并且同时存储log内容的性能情况【系统态与用户态显著增加】
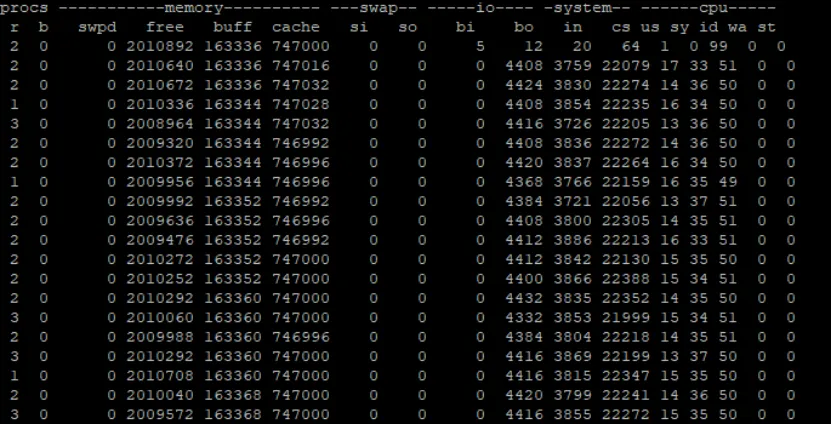
5
有关各种排序算法是系统态还是用户态的猜想
我们通常知道各种不同的排序算法的时间复杂度来说是不同的,但是我们除了依据时间复杂度来查看各种不同的排序算法,我们是否可以用性能测试的指标来区别不同的复杂度的排序算法呢?

<第一部分 前置调查>
1)调查直接运行排序算法的python是否会增加us 或者sy的数值
问:直接运行排序的python脚本是否可以
答:
同时运行排序算法的python脚本以及vmstat检查us或者sy的数值是否会变化
Python 举例,循环100000次
for count in range(100000):
<中间是排序算法>
在python脚本中去掉print的内容,则sy的数值可以一直保持为0(print内容会增加sy的数值),仅us含有数值,这种方法虽然清晰,但是会导致运行时us保持不变,无法检测出来us,sy变动的区别。因为us为固定数值,sy一直是0。
所以不直接运行 python的排序算法。
2)调查持续不断地用shell脚本调用排序算法的python是否会增加us 或者sy的数值:
对于四种排序,如果希望用户态us有一定的变动幅度,便于呈现程序复杂程度的区别,则sy会产生一定的数值(这是由于系统态的一些使用导致的,可以不计算sy的数值,仅计算用户态us的数值)。
此时发现python中排序列表长度不能过长,过长的话也会导致sy为0,用户态us不变,无法统计出程序复杂程度。
因为稍微短一些的排序列表长度可以触发调用少量系统态(sy),同时,用户态(us)还能有一定的变动幅度,而这个变动幅度正好可以用于计算不同排序算法的复杂程度。
我们这里定义python中排序列表长度为1000。
3)调查 vmstat 与2>&1 | tee log.txt的结合是否会增加us或者sy的数值
结论是 ./test.sh 2>&1 | tee log.txt 是不会影响sy和us的数值的,sy和us一直都保持为0(test.sh 里面内容是 vmstat 1 40 -t)

<第二部分 开始运行>
注意,运行每一种排序之前都运行一下以下的清除缓存并释放资源的命令
echo 3 > /proc/sys/vm/drop_caches以下持续不断地运行某种排序,比如:冒泡排序,每一种排序的元素个数都是1000个元素排序,并且持续运行40秒收集sy和us的数据,收集方法为收集vmstat 1 40 -t 所列数据:
1: 冒泡排序
计算冒泡排序的us(用户态)的平均值 (去掉最开始的异常值)
1000个元素:23.923
计算冒泡排序的sy(系统态)的平均值 (去掉最开始的异常值)
1000个元素:3.717
2: 选择排序
计算选择排序的us(用户态)的平均值 (去掉最开始的异常值)
1000个元素:22.58
计算选择排序的sy(系统态)的平均值 (去掉最开始的异常值)
1000个元素:7.10
3: 插入排序
计算插入排序的us(用户态)的平均值 (去掉最开始的异常值)
1000个元素:23.53
计算插入排序的sy(系统态)的平均值 (去掉最开始的异常值)
1000个元素:4.17
4: Shell 排序
计算shell排序的us(用户态)的平均值 (去掉最开始的异常值)
1000个元素:19.64
计算shell排序的sy(系统态)的平均值 (去掉最开始的异常值)
1000个元素:7.51
5: 总结四种排序
算法时间复杂度的概念
时间复杂度是执行程序需要的时间,算法的时间复杂度(Time Complexity)是衡量算法执行效率的重要指标,它表示算法运行时间随输入规模增长的变化趋势,通常用大 O 符号(O-notation)表示。
从用户态分析四种排序的复杂程度
从前置调查中,我们知道用户态是程序运行所真正涉及的CPU部分,通过运行我们可以看到如下的排序结果:
Shell (19.64) < 选择 (22.58)< 插入 (23.53)< 冒泡(23.923)
这个排序结果与其程序的复杂程度的排序非常接近。
因为使用时间复杂度 O(n2) 这个数值不是很清晰究竟哪个程序更为复杂,而使用本文的方法,可以将程序的复杂程度显示得更为精确。
并且多次运行结果都是一致的,所以这个结果的稳定性还是比较高的。
......
本文节选自第八十七期《51测试天地》
原创文章
《性能测试的探索》
文章后续还介绍了Vmstat相关的脚本、
及系统态与用户态通常的规律总结
想继续阅读全文或查看更多《51测试天地》的原创文章
请点击下方 阅读原文或扫描二维码 查看

每日有奖互动
你在性能测试中最常用哪个命令?
为什么?