用 Python 做自己的基金交易系统(3):数据库重构 + 秒级查询!附成品
- 2026-07-05 20:07:20
用 Python 做自己的基金交易系统(3):数据库重构 + 秒级查询!附成品🔥 重磅系列|从0到1打造专属基金模拟交易系统! 不用氪金买会员,不用忍受APP广告,用Python做一套完全适配自己交易习惯的基金模拟交易系统——这是一套新手能看懂、能落地、能持续升级的实战教程。最终成品涵盖: ✅ 核心基础层:基金净值实时查询+历史走势可视化 ✅ 交易模拟层: 申购/赎回模拟+交易记录永久保存+持仓成本自动计算 ✅ 持仓管理层:自选基金列表+多基金持仓汇总+总收益/日收益一键统计 ✅ 进阶优化层:买卖点自动标注+收益分析图表,可实现多平台购买基金数据模拟到一起管理。 整个系统全程用Python原生库开发,无复杂框架,每一期都附「可直接运行的成品代码」,不用自己拼代码、改配置,下载就能用! ✅ 数据库底层重构:28000+全量基金数据存入SQLite 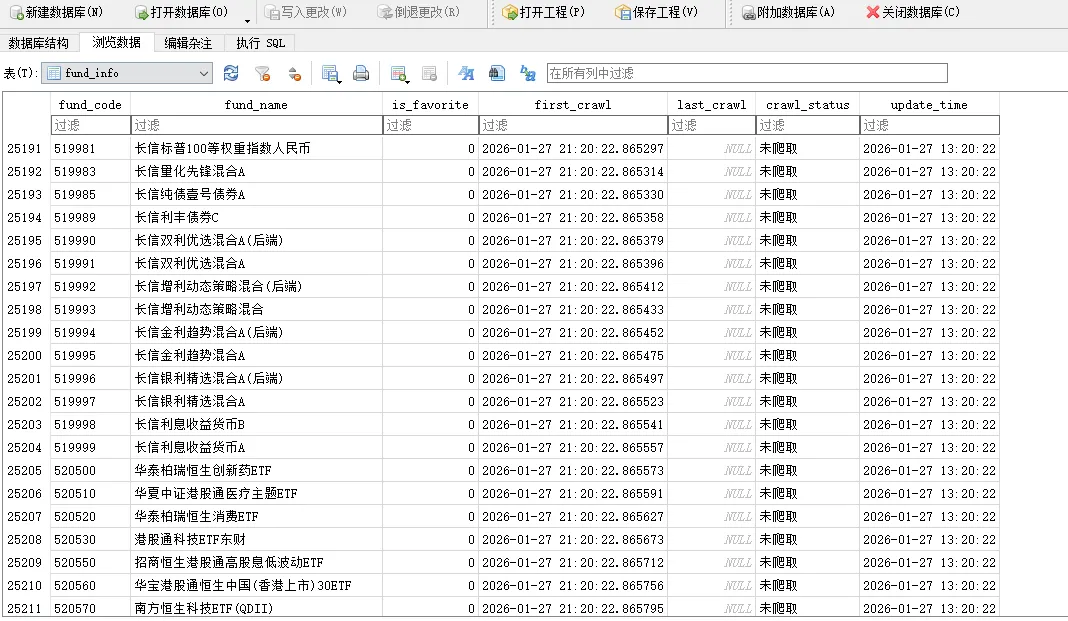
✅ 秒级模糊查询:输入关键词/代码,毫秒级匹配基金,再也不用等 ✅ 自定义数据天数:30/60/90/360天净值自由切换,按需加载不冗余 ✅ 增量爬取优化:仅爬取目标天数数据 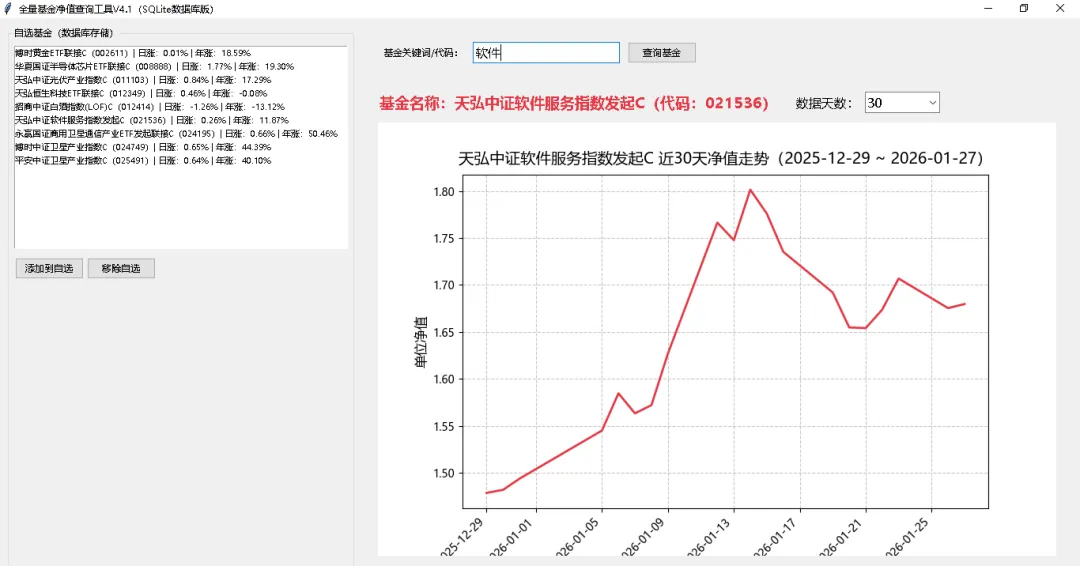
1.核心底层重构:JSON→SQLite数据库 彻底抛弃原有JSON文件存储,将28000+全量基金基础信息(名称/代码)存入SQLite数据库,独立脚本一次性导入,后续使用无需重复加载,启动速度提升10倍+。 2.查询速度史诗级优化:从“秒级”到“毫秒级” ○新增全文索引+三层匹配逻辑:精确匹配代码→FTS5索引匹配名称→LIKE模糊兜底,覆盖所有查询场景; ○临时关闭列表涨跌幅预计算,查询弹窗秒级显示匹配结果; 3.交互体验升级:自定义数据天数 ○净值图表区新增「数据天数选择框」(30/60/90/360天),操作更便捷; ○切换天数自动刷新净值曲线,按需爬取对应天数数据,30天数据加载速度提升70%; ○增量爬取逻辑适配天数选择,仅爬取目标数据,避免无意义的全量爬取耗时。 点赞+推荐,后台回复关键词【基金系统03】,领取本期「完整成品代码」,直接下载就能用,不用自己敲一行代码! 关注我,后续还会升级模拟交易、持仓汇总、打包成EXE等功能,用Python做专属的基金管理工具~ #Python实战 #基金工具 #爬虫 #可视化 #新手教程
本期效果抢先看
本期主要更新内容
# ========== 核心:数据库初始化(创建fund_info + fund_nav表) ==========def init_database(self):"""初始化数据库,创建2张核心表+全文索引"""conn = sqlite3.connect(DB_FILE)cursor = conn.cursor()# 表1:fund_info(基金基础信息+自选标记)#关注公众号"python万事屋"获取更多源码cursor.execute('''CREATE TABLE IF NOT EXISTS fund_info (fund_code TEXT PRIMARY KEY, -- 基金代码唯一主键fund_name TEXT NOT NULL, -- 基金全称is_favorite INTEGER DEFAULT 0, -- 是否自选:0=否,1=是first_crawl DATETIME, -- 首次爬取时间last_crawl DATETIME, -- 最后爬取时间crawl_status TEXT DEFAULT '未爬取', -- 爬取状态:未爬取/已完成/中断update_time DATETIME DEFAULT CURRENT_TIMESTAMP -- 记录更新时间)''')# 表2:fund_nav(所有基金净值数据)cursor.execute('''CREATE TABLE IF NOT EXISTS fund_nav (fund_code TEXT,nav_date DATE,unit_nav REAL, -- 单位净值update_time DATETIME DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (fund_code, nav_date), -- 复合主键:避免重复FOREIGN KEY (fund_code) REFERENCES fund_info(fund_code))''')# 索引优化(核心提速点)cursor.execute('CREATE INDEX IF NOT EXISTS idx_fund_code ON fund_nav(fund_code)')cursor.execute('CREATE INDEX IF NOT EXISTS idx_nav_date ON fund_nav(nav_date)')cursor.execute('CREATE INDEX IF NOT EXISTS idx_fund_name ON fund_info(fund_name)') # 新增名称索引conn.commit()conn.close()print("✅ 数据库初始化成功!已创建fund_info + fund_nav表 + 索引")# ========== 核心:从数据库读取基金净值数据 ==========def get_fund_data_from_db(self, fund_code):"""从fund_nav表读取基金净值,返回DataFrame"""sql = '''SELECT nav_date, unit_navFROM fund_navWHERE fund_code=?ORDER BY nav_date ASC'''result = self.db_query(sql, (fund_code,))if not result:return pd.DataFrame()# 转成DataFrame(适配原有计算/绘图逻辑)data = [(row['nav_date'], row['unit_nav']) for row in result]df = pd.DataFrame(data, columns=['净值日期', '单位净值'])df['净值日期'] = pd.to_datetime(df['净值日期'], errors='coerce')df['单位净值'] = pd.to_numeric(df['单位净值'], errors='coerce')df = df.dropna().set_index('净值日期')return dfdef on_day_change(self, event):"""切换数据天数后,重新加载对应天数的净值数据并绘图"""if not self.current_fund:messagebox.showwarning("提示", "请先查询并选中基金!")returnfund_name, fund_code = self.current_fundtarget_days = int(self.day_var.get())self.loading_label.config(text=f"正在加载{fund_name}近{target_days}天净值数据...")self.root.update()# 从数据库取对应天数的数据,无则爬取#关注公众号"python万事屋"获取更多源码fund_df = self.get_fund_data_from_db(fund_code)if fund_df.empty:fund_df = self.crawl_fund_nav(fund_code, fund_name, target_days=target_days)else:# 筛选对应天数的数据fund_df_sorted = fund_df.sort_index(ascending=True)latest_date = fund_df_sorted.index[-1]start_date = latest_date - timedelta(days=target_days)fund_df = fund_df_sorted[fund_df_sorted.index >= start_date]if fund_df.empty:messagebox.showwarning("提示", f"未获取到{fund_name}近{target_days}天的净值数据!")self.loading_label.config(text="")returnself.draw_chart(fund_df, fund_name, fund_code)self.loading_label.config(text="数据加载完成!")self.root.after(3000, lambda: self.loading_label.config(text=""))# ========== 核心:爬取净值数据 + 存入数据库==========def crawl_fund_nav(self, fund_code, fund_name, target_days=None):"""爬取基金净值,默认使用界面选择的天数"""# 若未传天数,取界面选择的天数if target_days is None:target_days = int(self.day_var.get())"""爬取基金净值,存入fund_nav表,同时更新fund_info表,支持增量爬取"""# 1. 先更新fund_info表(首次爬取则插入,非首次则更新状态)now = datetime.now().strftime('%Y-%m-%d %H:%M:%S')fund_exist = self.db_query('SELECT 1 FROM fund_info WHERE fund_code=?', (fund_code,))if not fund_exist:self.db_execute('INSERT INTO fund_info (fund_code, fund_name, first_crawl, crawl_status) VALUES (?, ?, ?, ?)',(fund_code, fund_name, now, '爬取中'))else:self.db_execute('UPDATE fund_info SET crawl_status=?, last_crawl=? WHERE fund_code=?',('爬取中', now, fund_code))# 2. 爬取核心逻辑(增量爬取,按需停止)#关注公众号"python万事屋"获取更多源码def _get_html(page=1):url = f"http://fund.eastmoney.com/f10/F10DataApi.aspx?type=lsjz&code={fund_code}&page={page}&per=100" # per=100减少分页headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/128.0.0.0 Safari/537.36"}try:res = requests.get(url, headers=headers, timeout=8)res.raise_for_status()res.encoding = "utf-8"return res.textexcept Exception as e:print(f"爬取第{page}页失败:{e}")return ""# 3. 分页爬取 + 增量存入数据库collected_count = 0 # 已收集数据条数page = 1conn = sqlite3.connect(DB_FILE)cursor = conn.cursor()while True:html = _get_html(page)if not html:breaksoup = BeautifulSoup(html, 'html.parser')tbody = soup.find("tbody")if not tbody:break# 解析单页数据rows = tbody.find_all("tr")if not rows:breakfor tr in rows:tds = tr.find_all("td")if len(tds) < 2:continuenav_date = tds[0].get_text().strip() # 净值日期unit_nav = tds[1].get_text().strip() # 单位净值if not nav_date or not unit_nav.replace('.', '').isdigit():continue# 增量存储:复合主键已保证不重复,直接插入即可cursor.execute('''INSERT OR IGNORE INTO fund_nav (fund_code, nav_date, unit_nav)VALUES (?, ?, ?)''', (fund_code, nav_date, float(unit_nav)))collected_count += 1# 按需停止:达到目标天数则退出,不用爬全量if collected_count >= target_days:breakpage += 1time.sleep(0.5) # 防反爬# 4. 更新爬取状态cursor.execute('UPDATE fund_info SET crawl_status=?, last_crawl=? WHERE fund_code=?',('已完成', now, fund_code))conn.commit()conn.close()print(f"✅ {fund_code} 爬取完成,共存入{collected_count}条净值数据")# 5. 返回爬取后的数据库数据return self.get_fund_data_from_db(fund_code)
源码领取
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

